annuaire
Dans K8S Tous les objets sont appelés ressources, telles que: pod, service, etc.
ressources Pod
pod est la plus petite unité K8S devant mentionné, K8S soutien à l' auto-guérison fonctionnalités avancées, extension flexible et ainsi de suite, donc si vous exécutez simplement docker d'affaires dans K8S noeud est aucun moyen de soutenir ces fonctionnalités avancées, il doit être conteneur personnalisé , alors, est - ce pod fonctionnaires ont préparé un bon supports de conteneur fonctionnalités avancées, lors du démarrage d' une nacelle, il y aura au moins deux conteneurs pod容器``和业务容器, le trafic de conteneurs partagera plus d'un conteneur pod (un conteneur de collecte), puis Pod dans un conteneur d'espace de noms réseau partagé,
Classement des conteneurs Pod
- Container Infrastructure: conteneur de base, l'entretien de l'ensemble de l'espace réseau Pod
- InitContainers: conteneur d'initialisation, avant l'entreprise de conteneurs ont commencé
- Conteneurs: activité conteneurs, lancé en parallèle
Le sens de l'existence Pod: pour fermer les applications existent
- l'interaction de fichiers entre les deux applications
- Deux applications nécessitent une communication par 127.0.0.1 ou socker
- Deux applications nécessitent l'appel apparition fréquente
Miroir stratégie tirant
imagePullPolicy
1、ifNotPresent:默认值,镜像在宿主机上不存在时才拉取
2、Always:每次创建Pod都会重新拉取一次镜像
3、Never:Pod永远不会主动拉取这个镜像 1.pod opérations de base
// 指定yaml文件创建pod
kubectl create -f [yaml文件路径]
// 查看pod基本信息
kubectl get pods
// 查看pod详细信息
kubectl describe pod [pod名]
// 更新pod(修改了yaml内容)
kubectl apply -f [yaml文件路径]
// 删除指定pod
kubectl delete pod [pod名]
// 强制删除指定pod
kubectl delete pod [pod名] --foce --grace-period=0le profil de 2.pod
apiVersion: v1
kind: Pod
metadata:
name: nginx01
labels:
app: web
spec:
containers:
- name: nginx01
image: reg.betensh.com/docker_case/nginx:1.13
ports:
- containerPort: 80Pod des relations avec les contrôleurs
- contrôleurs: gestion des objets et le fonctionnement du conteneur sur un cluster
- par
label-selectorassocié - Pod appliquée par le contrôleur pour obtenir un fonctionnement et d'entretien, tels que l'étirage, la mise à niveau de roulement.
RC contrôleur de copie
Contrôleur de copie de réplication contrôleur, l'application d'hébergement après avoir besoin Kubernetes, Kubernetes pour assurer que les applications peuvent continuer à fonctionner, c'est le contenu du travail RC, il veillera à ce que chaque fois Kubernetes à la fois un certain nombre de Pod est en cours d'exécution. Sur cette base, RC fournit également des fonctionnalités avancées, comme une mise à niveau de roulement, rollback mise à niveau et ainsi de suite.
ReplicaSet recommandée (appelée RS) dans la nouvelle version de Kubernetes en place de ReplicationController
1. Créez un rc
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: nginx01
image: reg.betensh.com/docker_case/nginx:1.13
ports:
- containerPort: 80Par défaut, pod名il sera rc名+随机值composé comme suit:
[root@k8s-master01 rc]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myweb-0lp57 1/1 Running 0 45s
myweb-zgfcf 1/1 Running 0 45sRC pour contrôler la nacelle par sélecteur de balises (étiquettes), le nom RC doit être le même nom et le sélecteur de balises
[root@k8s-master01 rc]# kubectl get rc -o wide
NAME DESIRED CURRENT READY AGE CONTAINER(S) IMAGE(S) SELECTOR
myweb 2 2 2 12m nginx01 reg.betensh.com/docker_case/nginx:1.13 app=mywebroulement 2.RC mise à niveau
Nous avons déjà créé une v1 la version serveur http de la nacelle dans un environnement K8S, comment faire si nous voulons faire une version mise à jour il? Est -ce le pod d' origine arrêté, puis utiliser la nouvelle image pour tirer vers le haut un nouveau pod il, ce serait clairement inapproprié.
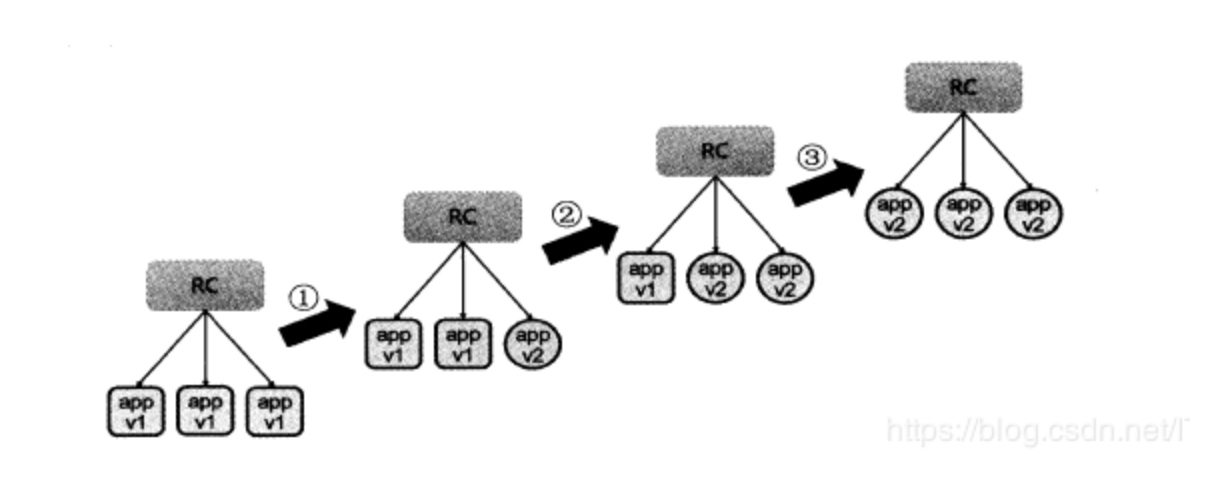
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=30s3.RC roulant fallback
Supposons maintenant mise à jour MyWeb à myweb2, est apparu bug, puis forcé d'interrompre la mise à niveau
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=50sPuis retour à la version de rouleau myweb2 myweb
kubectl rolling-update myweb myweb2 --rollback le déploiement des ressources
le déploiement est également un moyen de garder pod très disponible, il y a évidemment la raison pour laquelle RC également introduit le déploiement de celui - ci?
Parce que le déploiement permet de résoudre un point de douleur de la RC, lorsque le conteneur de mise à niveau de la version RC, l'étiquette changera, si étiquette ou svc l'original, donc vous devez modifier manuellement les fichiers de configuration svc.
Le déploiement de Podet ReplicaSetci - dessus, pour fournir un état défini dans la méthode de la formule (déclarative), utilisé pour remplacer précédent ReplicationControllerafin de faciliter l'application de gestion.
Il vous suffit de Deploymentvous décrire voulez 目标状态ce qui est que Deployment controllervous aidera Podet ReplicaSetl'état actuel du changement à votre 目标状态. Vous pouvez définir un nouveau Deploymentpour créer ReplicaSetou supprimer existants Deploymentet de créer un nouveau pour le remplacer. DeploymentC'est 管理多个ReplicaSet, comme indiqué ci - dessous:
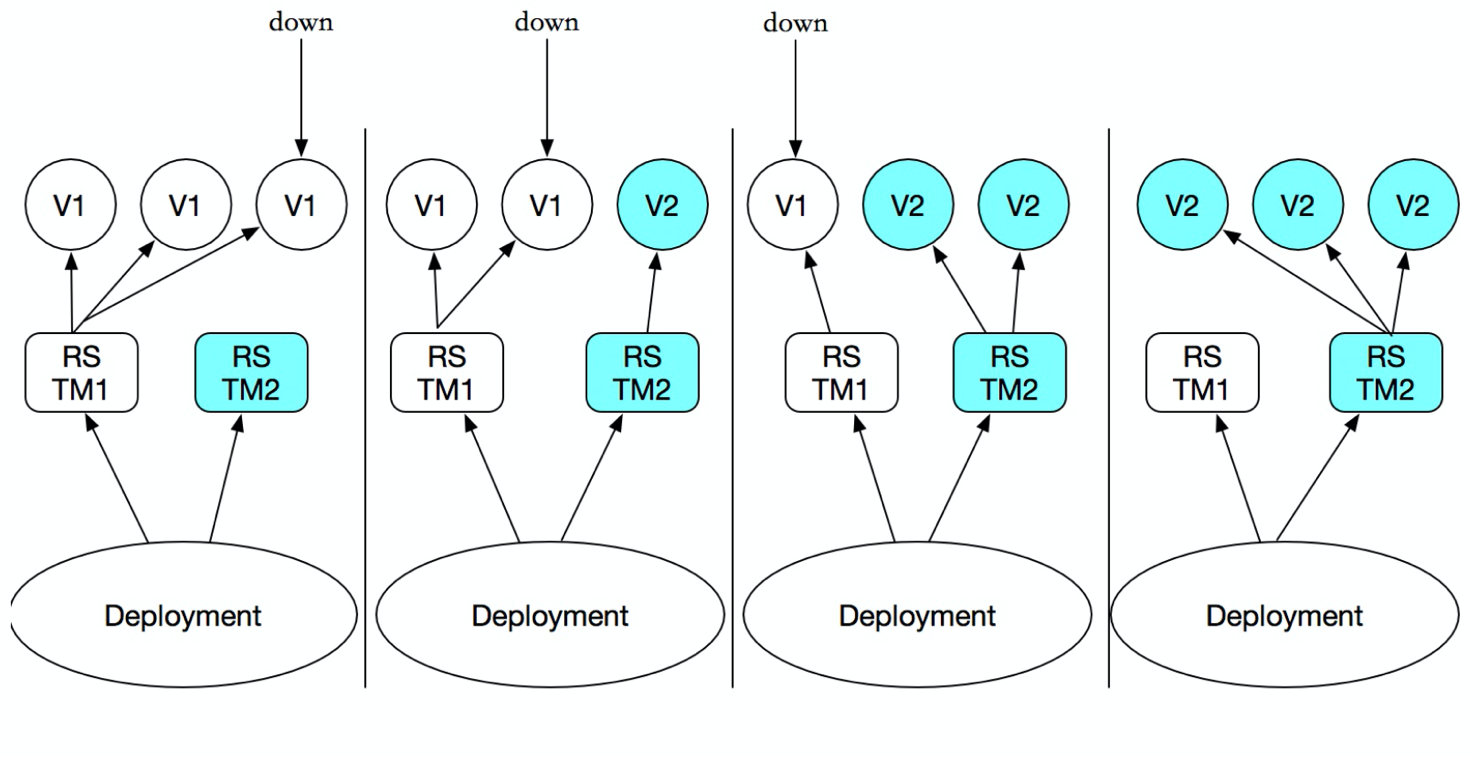
Bien que replicaSet peut être utilisé indépendamment, mais il est recommandé d'utiliser le déploiement pour gérer automatiquement replicaSet, donc pas besoin de vous soucier d'autres incompatibilités mécanismes
1. Créez un déploiement
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.13
ports:
- containerPort: 80
// 启动
[root@k8s-master01 deploy]# kubectl create -f nginx_deploy.yamlAfficher l'état du démarrage de déploiement
le déploiement va d'abord commencer rs, puis commencer pod
[root@k8s-master01 deploy]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-fcfcc984f-t2bk4 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-vg7qt 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-zhwxg 1/1 Running 0 33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 3/3 3 3 33s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-fcfcc984f 3 3 3 33s2. Le service associé
kubectl expose deployment nginx-deployment --port=80 --type=NodePortVoir svc
[root@k8s-master01 deploy]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 16h
nginx-deployment NodePort 10.96.171.141 <none> 80:31873/TCP 25sAdresse svc et accès au port
[root@k8s-master01 deploy]# curl -I 10.0.0.33:31873
HTTP/1.1 200 OK
Server: nginx/1.13.12
Date: Thu, 14 Nov 2019 05:44:51 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Mon, 09 Apr 2018 16:01:09 GMT
Connection: keep-alive
ETag: "5acb8e45-264"
Accept-Ranges: bytesmise à niveau 3.deployment
// 直接编辑对应deployment,并修改镜像版本
kubectl edit deployment nginx-deployment
// 通过 set image 发布新的镜像
kubectl set image deploy nginx-deployment nginx-deployment=nginx:1.174.deployment rollback
// 回滚到上一级版本
kubectl rollout undo deployment nginx-deployment
// 回滚到指定版本
kubectl rollout undo deployment nginx-deployment --to-revision=1
// 查看当前deploy历史版本
kubectl rollout history deployment nginx-deploymentLa version en ligne de commande pour obtenir une libération
# kubectl run nginx --image=nginx:1.13 --replicas=3 --record
# kubectl rollout history deployment nginx
deployment.extensions/nginx
# kubectl set image deployment nginx nginx=nginx:1.15 service de Headless
En K8S, la façon dont nous voulons accéder au service par un nom qui est Deploymentd'ajouter une couche au - dessus de Service, afin que nous puissions Service nameaccéder au service, et ce qui est le principe et CoreDNSpertinent, il sera Service nameanalysé dans Cluster IP, donc nous avons visité Cluster IPlorsque le par Cluster IP pour l' équilibrage de charge du trafic à travers 各个PODle haut. Je pense que la question est de CoreDNSsavoir si ce sera directement résoudre le nom de POD, le service dans le service, n'est pas possible car il y a le service de cluster IP, directement CoreDNS résolu, alors comment peut - il faire pour résoudre POD, un gros bétail élevé vous pouvez utiliser Headless Service, donc nous devons explorer ce qui est Headless Service.
Headless ServiceIl est une sorte de Service, sauf DÉFINISSANT spec:clusterIP: None, qui ont pas besoin Cluster IP的Service.
Nous pensons d' abord Service的Cluster IPdes travaux: un Servicepeut correspondre à plusieurs EndPoint(Pod), l' clientaccès est Cluster IPpar iptablesles règles vont Real Server, de manière à atteindre l' équilibrage de charge. opération spécifique est la suivante:
1, web-demo.yaml
#deploy
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web-demo
namespace: dev
spec:
# 指定svc名称
serviceName: web-demo-svc
replicas: 3
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
resources:
requests:
memory: 1024Mi
cpu: 500m
limits:
memory: 2048Mi
cpu: 2000m
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /hello
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
---
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo-svc
namespace: dev
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: web-demoVoir svc, a trouvé ClusterIPqueNone
$ kubectl get svc -n dev | grep "web-demo-svc"
web-demo-svc ClusterIP None <none> 80/TCP 12spod crée l'ordre
$ kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
web-demo-0 1/1 Running 0 7m2s
web-demo-1 1/1 Running 0 6m39s
web-demo-2 1/1 Running 0 6m15sConnectez-vous à l'intérieur du cluster pod
$ kubectl exec -it web-demo-0 sh -n dev
/ # nslookup web-demo-svc
Name: web-demo-svc
Address 1: 10.244.2.67 web-demo-0.web-demo-svc.dev.svc.cluster.local
Address 2: 10.244.3.12 web-demo-2.web-demo-svc.dev.svc.cluster.local
Address 3: 10.244.1.214 web-demo-1.web-demo-svc.dev.svc.cluster.localRésumé: accès dns, il retournera une liste des dosettes de back-end
StatefulSet
Tout d' abord, Deploymentseul un service sans état, et il n'y a pas d' ordre Pod indifférencié, l'ordre entre le support StatefulSet pluralité Pod, pour chaque Pod a son propre numéro, l' accès nécessaire à l'autre et de faire la distinction entre le stockage persistant
séquentielle Pod
1 sans tête-service.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot-web-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: springboot-web2, statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: springboot-web
spec:
# serviceName 该字段是告诉statefulSet用那个headless server去保证每个的解析
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: springboot-web
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5Voir pod
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
springboot-web-0 1/1 Running 0 118s
springboot-web-1 1/1 Running 0 116sEntrez une nacelle, et visiter un autre nacelle par nom pod
$ kubectl exec -it springboot-web-0 sh
/ # ping springboot-web-1.springboot-web-svc
PING springboot-web-1.springboot-web-svc (10.244.2.68): 56 data bytes
64 bytes from 10.244.2.68: seq=0 ttl=62 time=1.114 ms
64 bytes from 10.244.2.68: seq=1 ttl=62 time=0.698 msLe stockage persistant
est automatiquement créé sur la base pvc pod
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-demo
spec:
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/nginx:1.13
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: glusterfs-storage-class
resources:
requests:
storage: 1GiDaemonSet
DaemonSet dans Kubernetes1.2 nouvelle version d'un des objets de ressources
DaemonSetIl permet des 所有(或者一些特定)的Nodenœuds 仅运行一份Pod. Lorsqu'un nœud de cluster est ajouté aux Kubernetes, Pod sera (DaemonSet) prévu pour fonctionner sur le nœud, lorsque le noeud est retiré de Kubernetes cluster est (DaemonSet) prévu Pod sera supprimé si vous supprimez DaemonSet, avec tout cela DaemonSet pods connexes seront supprimés.
Quand exécuter l'application en utilisant Kubernetes, nous avons besoin de beaucoup de temps 区域(zone)ou en 所有Nodecours d' exécution 同一个守护进程(pod), par exemple, la scène suivante:
- Chaque nœud en cours d'exécution sur un daemons de stockage distribués, tels que glusterd, CEPH
- collecteur Run Log sur chaque nœud, par exemple fluentd, logstash
- terminal de contrôle du fonctionnement d'acquisition dans chaque noeud, par exemple prométhée noeud exportateur, collectd etc.
Pod DaemonSet d'expédition et RC est similaire, sauf que l'algorithme d'ordonnancement du système intégré dans chaque planification du noeud, ou peuvent être utilisés NodeSelector NodeAffinity Pod dans la définition pour spécifier une plage satisfaisant le nœud de planification de l'état
DaemonSet format de fichier de ressources
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:sont définis les exemples suivants le début de chaque nœud sur un filebeatconteneur, dans lequel les supports d'accueil du répertoire « / var / log / messages »
$ vi k8s-log-filebeat.yaml
apiVersion: v1
kind: ConfigMap # 定义一个config文件内容
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
# 填写filebeat读取日志相关信息
filebeat.yml: |-
filebeat.prospectors:
- type: log
paths:
- /messages
fields:
app: k8s
type: module
fields_under_root: true
output.logstash:
# specified logstash port (by default 5044)
hosts: ['10.0.0.100:5044']
---
apiVersion: apps/v1
kind: DaemonSet # DaemonSet 对象,保证在每个node节点运行一个副本
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.8.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
# 进行实际挂载操作
volumeMounts:
# 将configmap里的配置挂载到 /etc/filebeat.yml 文件中
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
# 将宿主机 /var/log/messages 路径挂载到 /messages中
- name: k8s-logs
mountPath: /messages
# 定义卷
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
type: File
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-configLe DeamonSet créé à l'aide kubectl commande create
$ kubectl create -f k8s-log-filebeat.yaml
configmap/k8s-logs-filebeat-config created
daemonset.apps/k8s-logs createdVérifiez la DeamonSet et Pod créé, peut être vu sur chaque nœud crée un Pod
$ kubectl get ds -n kube-system | grep "k8s-logs"
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
k8s-logs 2 2 0 2 0 <none> 2m15s
$ kubectl get pods -n kube-system -o wide | grep "k8s-logs"
k8s-logs-gw4bs 0/1 Running 0 87s <none> k8s-node01 <none> <none>
k8s-logs-p6r6t 0/1 Running 0 87s <none> k8s-node02 <none> <none>Dans la version 1.6 plus tard dans Kubernetes, DaemonSet peut effectuer une mise à niveau de roulement, cette mise à jour d'un modèle DaemonSet lorsque l'ancienne copie Pod sera automatiquement supprimé, tandis que la nouvelle copie Pod est automatiquement créé, cette fois DaemonSet stratégie de mise à jour (updateStrategy) est RollingUpdate, comme suit:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
updateStrategy:
type: RollingUpdateupdateStrategy Une autre valeur est OnDelete, qui est, seulement quand supprimer manuellement le Pod copie DaemonSet a créé une nouvelle copie Pod sera créé à partir, si vous ne définissez pas la valeur updateStrategy, puis dans les versions ultérieures de 1.6 Kubernetes sera le réglage par défaut RollingUpdate (mise à niveau de roulement).
Ressources services
Nous savons tous que dans Kubernetes à l'unité de planification minimum Pod, et sa caractéristique est l'incertitude, qui sera détruite à tout moment et recréez l'incertitude conduira chaque Pod sera déployé à différents N par le planificateur un nœud de nœud, cela provoquera l'adresse Pod va changer;
Par exemple, la scène web est divisé en arrière-plan frontal, les besoins frontaux aux ressources back-end d'appel, si le backend de Pod né de plomb d'incertitude à une adresse IP différente, de sorte que l'avant est certainement pas faire l'adresse IP au backend de connexion commutation automatique, il est donc nécessaire de découvrir par le service Pod et obtenir son adresse IP.
relation Pod avec le Service
- Pod empêcher le contact perdu., Pod obtenir des informations (via l'étiquette sélecteur associé)
- Pod définit un ensemble de politiques d'accès (équilibrage de charge TCP / UDP 4 couches)
- Soutenir trois types CLUSTERIP, NodePort et LoadBalancer
- implémentations de serveur sous-jacent iptables et il existe deux types de modes réseau IPVS
Chaque application est associée à un service
type de service
- CLUSTERIP: Par défaut, une distribution au sein du cluster peut accéder à l'adresse IP virtuelle (PAAC)
- NodePort: attribuer un port comme une entrée sur chaque accès externe Noeud
- LoadBalancer: travail sur un fournisseur Cloud spécifique, tel que Google Cloud, AWS, OpenStack
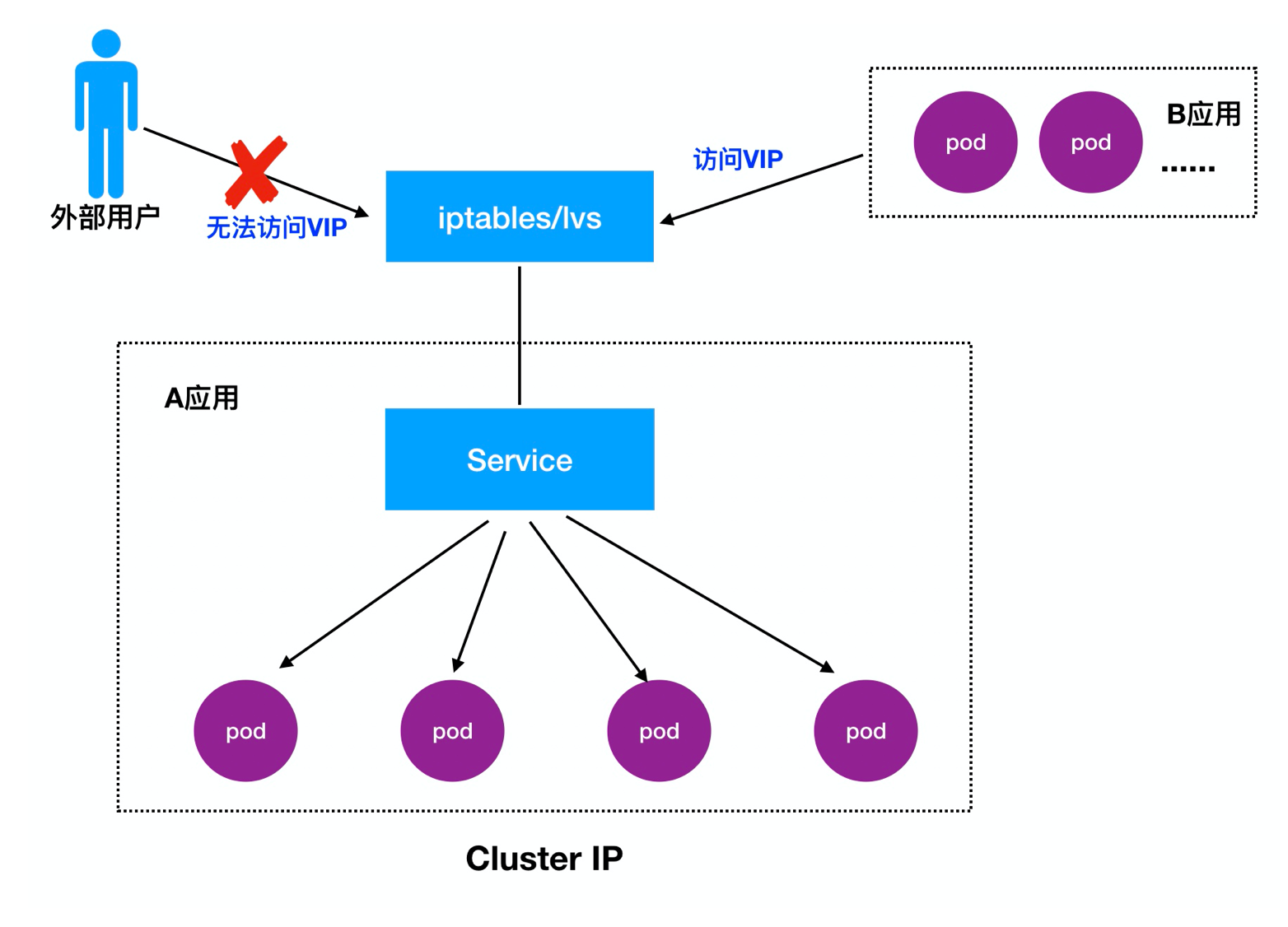
Détail 1.Cluster IP:
Cluster IP, également connu sous le VIP, la principale réalisation de visites entre les différents Pod
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCPOuvrir l' accès proxy
proxy kubectl pour permettre l' accès au réseau externe K8S service CLUSTERIP
kubectl proxy --address='0.0.0.0' --accept-hosts='^*$' --port=8009
http://[k8s-master]:8009/api/v1/namespaces/[namespace-name]/services/[service-name]/proxyDétails: https: //blog.csdn.net/zwqjoy/article/details/87865283
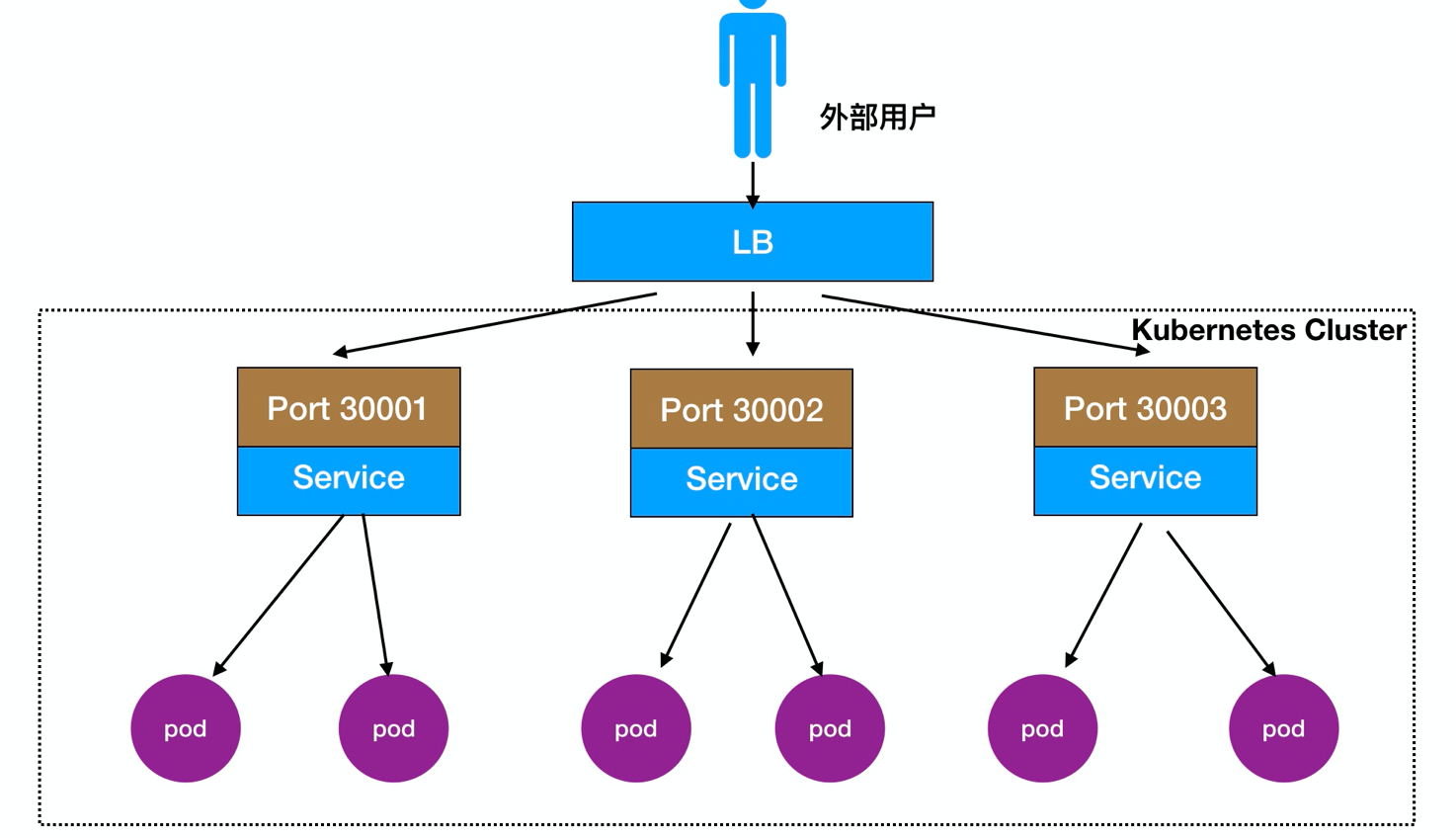
Détail 2.Node Port:
Les utilisateurs externes peuvent accéder à nœud mis en œuvre noeud, noeud noeud coulera vers l'avant dans l'intérieur de celui-ci Pod
Processus d'accès: Utilisateurs -> Domaine -> Load Balancer -> NodeIP: Port -> PodIP: Port
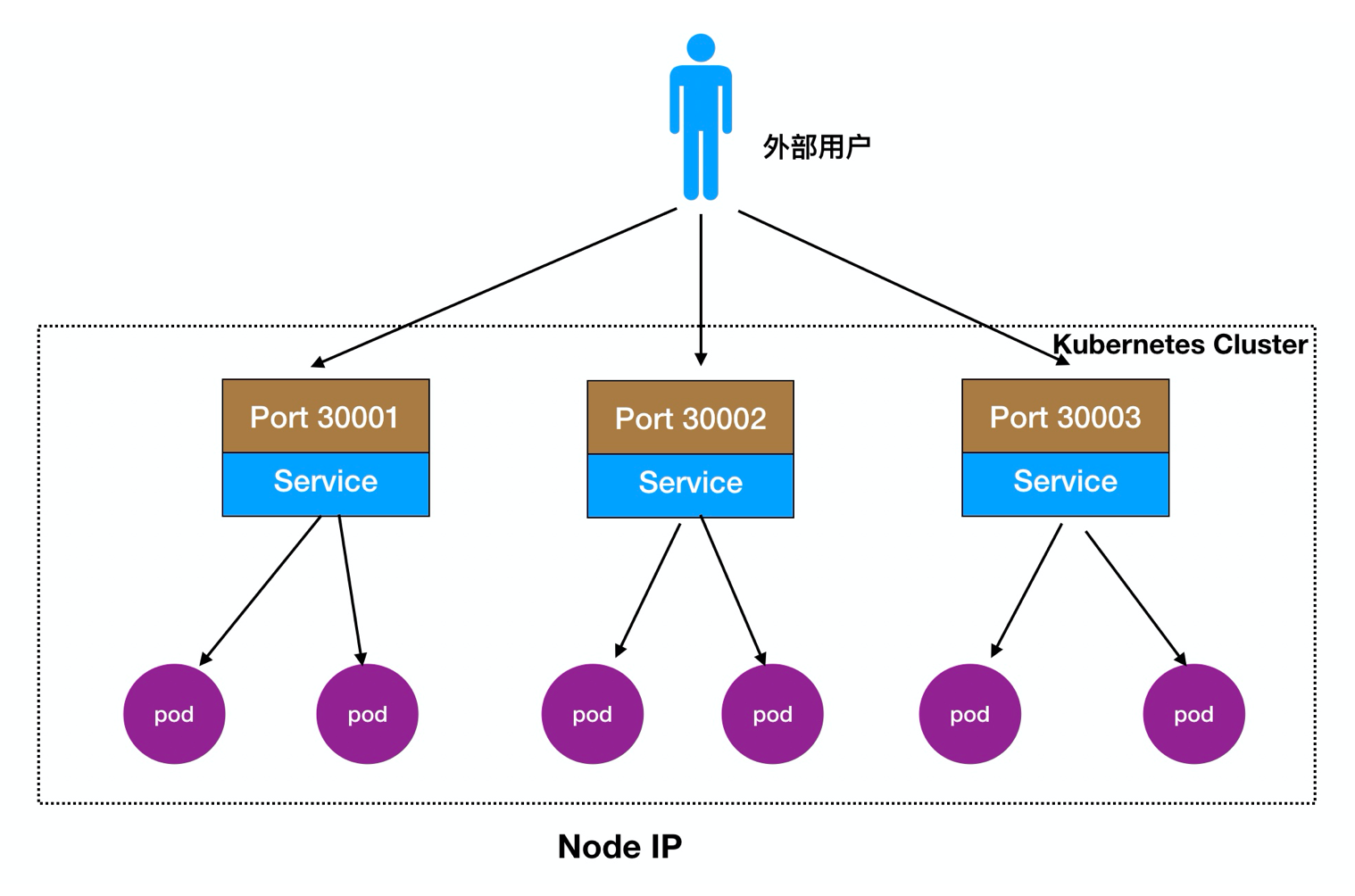
Il peut également être déployé en face d'un équilibrage de charge nœud LB directement, comme le montre:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30008
protocol: TCPdescription paramètre
spec.ports.port:vip端口(cluster ip)
spec.ports.nodePort:映射到宿主机的端口,即提供外部访问的端口
spec.ports.targetPort:pod 端口
spec.selector: 标签选择器Création d'un type nodePort de temps sera attribué une adresse IP cluster, offrant un accès pratique entre Pod
3, LoadBalancer Commentaires:
Processus d' accès: Utilisateurs -> Domaine -> Load Balancer -> NodeIP: Port -> PodIP : Port
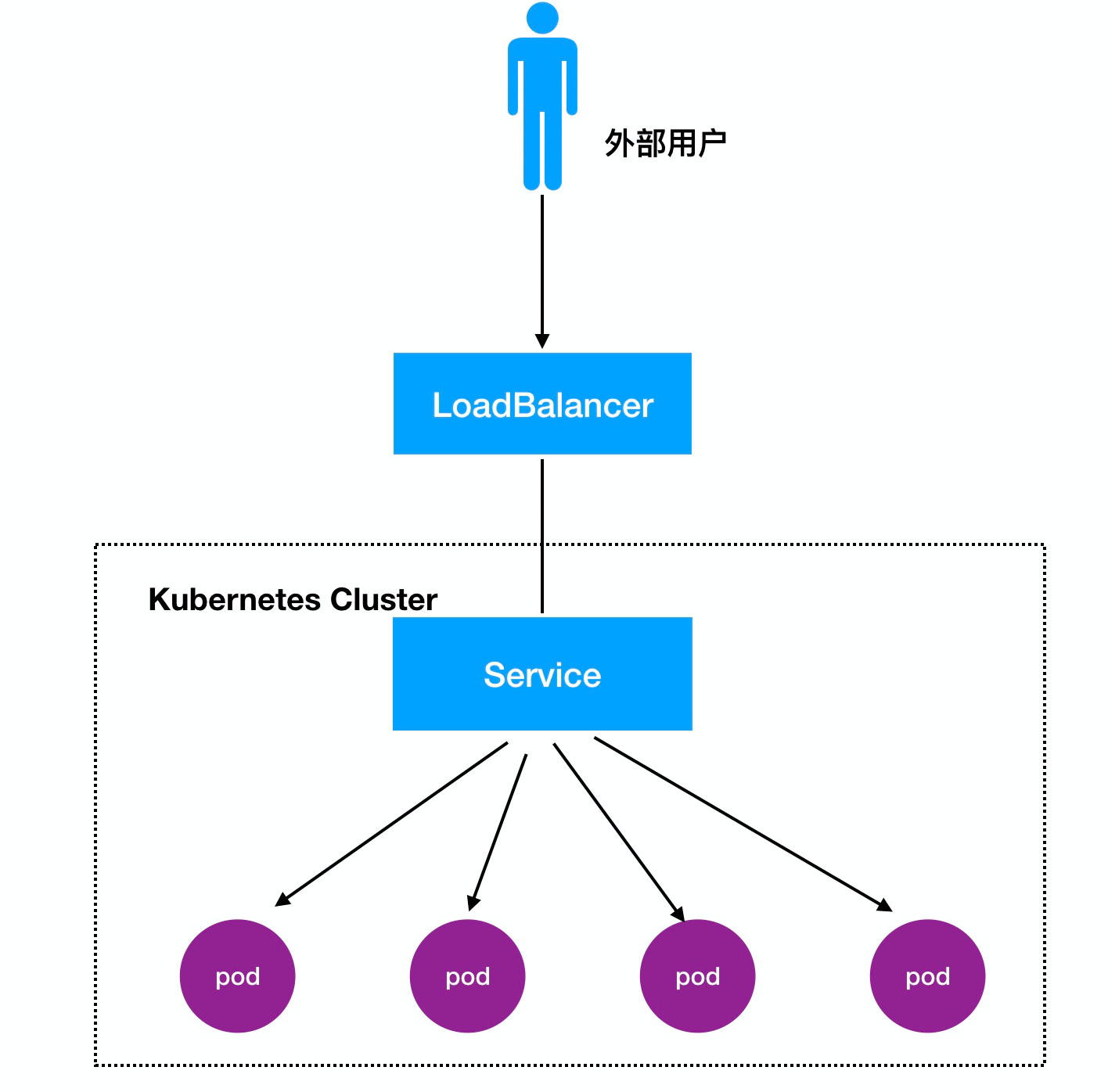
scénarios de cartographie classiques docker:
Accès -> nœud IP: 10.0.0.12 -> conteneur docker: 172.16.48.2
Si raccroché quand docker, docker, changement d'adresse IP du conteneur se produit dans le redémarrage, avant de le faire et la cartographie des noeuds de docker est valide, vous devez modifier manuellement la carte, il est donc très gênant
, ajoutez à K8S dans le IP du cluster, segment de réseau 10.254.0.0/16,series crée automatiquement l'adresse IP du cluster, également connu sous le nom vip, lorsque la nacelle est créé automatiquement enregistré dans le service et l'équilibrage de charge (la règle par défaut rr), si une nacelle suspendue, elle sera automatiquement rejetée
Accès - noeud> IP: 10.0.0.13 -> IP groupe: 10.254.0.0/16 (service) -> IP pod: 172.16.48.2
Créer un service
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 80
nodePort: 30000
targetPort: 80
selector:
app: myweb
// 启动
kubectl create -f nginx-svc.yamlService de prendre en charge la nacelle pour voir si les services de réseau normales:
[root@k8s-master01 svc]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 10.0.0.31:6443 2d
myweb 172.16.12.2:80,172.16.15.4:80 2mœuvres ipvs et iptables
service sous-jacent le transfert du trafic et équilibrage de charge pour atteindre:
- iptables
- ipvs
1, un service vont créer un grand nombre de règles iptables (mise à jour, non différentiels)
2, les règles iptables sont mis en correspondance une à une de haut en bas (grand retard).
Sauveur: IPVS (mode noyau)
LVS équilibrage de charge du module planificateur de IPVS mis en œuvre, tels que: le SLB Ali nuage, basé sur quatre LVS permettent d'atteindre l'équilibrage de charge.
iptables:
- Flexible, puissant (le paquet peut fonctionner à différentes étapes du paquet)
- Et traversal de mise à jour des règles de jeu, un retard linéaire
IPVS:
- Travailler en mode noyau, une meilleure performance
- algorithmes de planification riches: rr, WRR, lc, WLC, ip hachage ....