Présentation de raisons
- Lorsqu'un fichier ou sur l'existence de tables HDFS Hbase dans une requête est d'écrire manuellement un tas de code MapReduce
- Pour les tâches statistiques, ne peut comprendre par les programmeurs MapReduce peut obtenir du
temps, il est libéré plus d' énergie est pas efficace
Qu'est-ce que la Ruche
Hive est basée sur une couche uniforme d'analyse, les données sur les enquêtes de conduite HDFS, les statistiques et l' analyse par le biais d' instructions SQL
Hive est basée sur les outils d' entreposage de données Hadoop, vous pouvez cartographier la structure du fichier de données à une table de base de données, fournir des capacités de requête SQL.
Ruche a l'apparence d'une base de données SQL, mais le scénario est complètement différent, Hive ne convient que pour les applications où l' analyse statistique hors ligne massif, qui est, l'entrepôt de données.
Ruche est un moteur d'analyse syntaxique SQL, l'instruction SQL se traduit par M. Job, puis exécuté sur la plate-forme Hadoop, parvenir à un développement rapide
1) dans le stockage de données de traitement de la ruche HDFS
2) l'analyse des données sous-jacentes pour atteindre Hive est MapReduce
3) la mise en œuvre d'un programme en cours d'exécution sur fil
4) le contenu de la ruche est lue écrire moins, ne supporte pas la réécriture et d'effacement des données
5) tables sont ruche tableau purement logique, tout comme la table de définition, à savoir, les métadonnées de table. Hadoop est essentiellement un métadonnées répertoire / fichier pour atteindre l'objectif de la séparation de stockage de données
6) Ruche pas spécifiquement défini dans le format de données spécifié par l'utilisateur, pour spécifier trois propriétés:
- les espaces de séparation sur colonne, « » « \ T »
- délimiteur ligne « \ n- »
- données de fichier lues procédé
avantages et inconvénients Hive
avantages:
1, l' extensibilité, l' échelle de taille, les grappes de la ruche peut prolonger librement sans redémarrer le service échelle générale: échelle étendue par l' intermédiaire de la part de la grappe l'échelle de pression: une unité centrale de traitement de serveur de base i7-6700k 4 8 fil, 8 fils de base 16, la mémoire 64G => 128G
2, ductilité , support Hive pour les fonctions personnalisées, les utilisateurs peuvent mettre en œuvre vos propres fonctions en fonction de leurs besoins
3, une bonne tolérance aux pannes , peut garantir , même s'il y a un nœud de problème, les instructions SQL peuvent encore être complétées exécution
inconvénients:
. 1, Ruche ne supporte pas les opérations CRUD de niveau enregistrement , mais l'utilisateur peut créer une nouvelle table ou d'une requête par les résultats de la requête dans un fichier (ruche-2.3.2 version de l'insert de support de niveau enregistrement actuellement sélectionné)
2, la latence des requêtes Hive est très grave , parce que le processus de démarrage MapReduce Job consommé depuis longtemps, il ne peut pas être utilisé dans le système de recherche interactif. (Vérifiez lent)
3, Ruche ne supporte pas les transactions CRUD (CRUD non pas parce qu'ils ne le font pas, il est principalement utilisé pour OLAP (traitement analytique en ligne), au lieu de OLTP (traitement des transactions en ligne), qui est le traitement des données à deux niveaux).
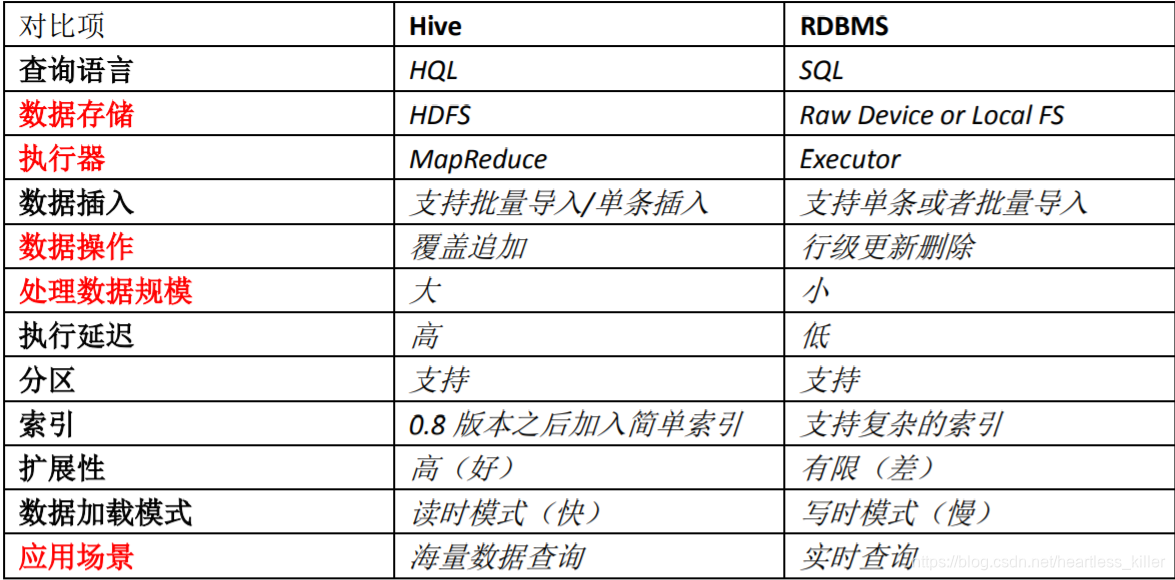
Contraste Ruche et le SGBDR
 Résumé:
Résumé:
Ruche a l'apparence d'une base de données SQL, mais le scénario est complètement différent, Hive ne convient que pour les applications où l'analyse statistique hors ligne massif, qui est, l'entrepôt de données.
Par rapport aux caractéristiques de données relationnelles traditionnelles
-
différent fichier ruche et système de stockage de base de données relationnelle, en utilisant ruche hadoop de HDFS (système de fichiers distribué de hadoop)
base de données relationnelle est locale sur le système de fichiers du serveur; -
Modèle de calcul ruche en utilisant MapReduce et le modèle de base de données relationnelle est le calcul de leur propre conception;
-
bases de données relationnelles sont conçues pour la requête en temps réel des affaires, et la ruche est de faire data mining conception de données massives, pauvres
-
Hive étendre facilement leur capacité de stockage et de puissance de calcul, ceci est hérité Hadoop et base de données relationnelle Hive bien pire que cela.
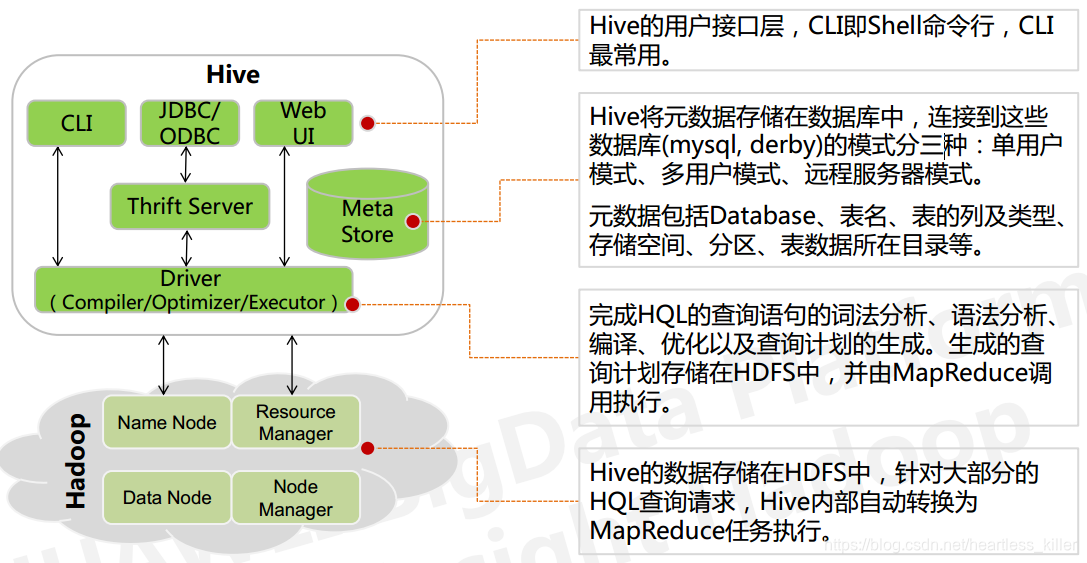
Architecture ruche
organisation de données Hive
1, la structure de mémoire ruche comprenant des bases de données, des tables, des vues et des données de table de partition. Bases de données, tables, cloisons, etc., correspondant à un répertoire sur HDFS. Tableau de données correspondant aux fichiers dans le répertoire correspondant aux HDFS.
2, toutes les données sont stockées dans la Ruche HDFS, pas de format de stockage de données spécialisées, car le mode de lecture est Hive (schéma A la lecture), prend en charge TextFile, SequenceFile, rcfile ou format personnalisé
3, il suffit de dire que les données Hive et séparateur ligne de séparation de la colonne, Ruche lors de la création d'une table, vous pouvez analyser les données
-
Ruche délimiteur de colonne par défaut: caractère de contrôle Ctrl + A, \ x01 Ruche de
-
Ruche séparateur de ligne par défaut: saut de ligne \ n
4, le modèle de la ruche contient les données suivantes:
- base de données: la performance de $ {} hive.metastore.warehouse.dir un répertoire de dossier dans HDFS
- Tableau: les performances de votre répertoire de base de données dans un dossier dans HDFS
- table externe: la table est similaire, mais qui peut indiquer tout le chemin du répertoire de l'emplacement de stockage de données HDFS
- partition: la performance sous-répertoire du répertoire de la table dans HDFS
- Après l'exécution de plusieurs fichiers dans HDFS est effectuée dans le même répertoire de table de hachage de hachage ou une partition de répertoire en fonction de la valeur d'un champ: seau
- Vue: similaire à la base de données traditionnelle, en lecture seule, créer une table basée sur la base
5, les métadonnées stockées dans la ruche du SGBDR, toutes les autres données à l'exception des métadonnées sont stockées sur HDFS. Par défaut, la Ruche des métadonnées stockées dans la base de données Derby intégrée, ce qui permet une seule connexion de session, ne convient que pour test simple. L'environnement de production réel, NA, afin de soutenir les sessions multi-utilisateurs, vous avez besoin d'une méta-base de données séparée, utilisation de MySQL pour la méta-base de données, Hive interne pour MySQL offre un bon support.
6, la table interne de la ruche dans une table, la table externe, la table de partition et le godet de la table
différence tables internes et externes:
- Suppression d'une table interne, supprimez les métadonnées de la table et les données
- create table table interne
- Dans les données d' importation à une table externe, les données ne sont pas déplacés vers l'entrepôt de données sous leur propre catalogue, ce qui signifie que la table de données externe n'est pas par son
propre réussi!
- Supprimer la table externe, supprimer les métadonnées, les données ne supprime pas
- créer emplacement de la table externe « hdfs_path » table externe (doit être un fichier)
- table externe est supprimée lorsque, Hive simplement supprimer les
métadonnées table externe, les données ne sont pas supprimées!
table interne et externe de la table utilisés pour sélectionner:
Dans la plupart des cas, la différence entre eux était pas évident, si toutes les données traitées dans la Ruche, ont alors tendance à choisir table interne, mais si la Ruche et d'autres outils à traiter pour le même ensemble de données, table externe est plus approprié.
Accès à des tables externes stockées dans les données initiales sur les HDFS, puis converties par des données dans une ruche coexistent table interne
L'utilisation des tables externes sont une pluralité de scènes pour un ensemble de données différent du schéma
On peut voir la différence entre la table externe et la table intérieure et utiliser la comparaison choisie, ruche en fait, juste les données stockées sur le HDFS fournit une nouvelle abstraction. Plutôt que de gérer les données stockées sur HDFS. Donc , peu importe créer une table interne ou une table externe, vous pouvez ajouter ou les opérations de suppression sur les données stockées dans la ruche de table de répertoire.
Partition Table
essence de la table des partitions est: créer une table dans les sous - répertoires de partition de répertoire de fichiers de données, de sorte que , au moment de la requête, le programme MR peut être traité pour les sous - répertoires de partition de données, de réduire la portée des données est lu.
Par exemple, la navigation sur le site web de l' histoire a produit chaque jour, l' historique de navigation doit être construit pour stocker une table, mais, parfois, on peut seulement besoin d'analyser l'histoire de une journée
de temps, vous pouvez construire cette table pour la table de partition, tous les jours dans laquelle une partition des données conduisons,
bien sûr, le répertoire de la partition quotidienne, il devrait y avoir un nom de répertoire (champ de partition)
tables de partition et des sous-tables différence de barillet :
table de données Hive peut être partitionné selon certaines opérations sur le terrain, la gestion des données détaillées, il peut permettre à certaines requêtes plus rapidement. tables Pendant ce temps et les partitions peuvent également être divisées en augets, les mêmes principes principes de table sous-baril HashPartitioner et la programmation MapReduce.
Les partitions et les données sous gestion à raffinent fois la baignoire, mais une table de partition est ajoutée manuellement à distinguer, car le mode de lecture Hive, les données ne sont pas ajoutées au mode de contrôle de la partition, la table de seau de données sont divisés selon certains seaux plusieurs champs de formulaire de hachage de hachage de fichiers, de sorte que la précision des données est beaucoup plus élevé
