

▐ Liste noire d'URL (filtre Bloom)
10 milliards d'URL de liste noire, chacune de 64 milliards, comment sauvegarder cette liste noire ? Déterminer si une URL est dans la liste noire
Table de hachage :
Si nous considérons la liste noire comme un ensemble et la stockons dans une hashmap, elle semble trop volumineuse, nécessitant 640G, ce qui n'est évidemment pas scientifique.
Filtre de floraison :
Il s'agit en fait d'un long vecteur binaire et d'une série de fonctions de cartographie aléatoire.
Il peut être utilisé pour déterminer si un élément fait partie d'un ensemble . Son avantage est qu’il n’occupe qu’une petite quantité d’espace mémoire et qu’il offre une efficacité de requête élevée. Pour un filtre Bloom, son essence est un tableau de bits : un tableau de bits signifie que chaque élément du tableau n'occupe que 1 bit, et chaque élément ne peut être que 0 ou 1.
Chaque bit du tableau est un bit binaire. En plus d'un tableau de bits, le filtre Bloom possède également des fonctions de hachage K. Lorsqu'un élément est ajouté au filtre Bloom, les opérations suivantes seront effectuées :
Utilisez les fonctions de hachage K pour effectuer K calculs sur la valeur de l'élément afin d'obtenir K valeurs de hachage.
Selon la valeur de hachage obtenue, la valeur d'indice correspondante est définie sur 1 dans le tableau de bits.
▐Statistiques de fréquence des mots (divisées en fichiers)
2 Go de mémoire pour trouver le nombre le plus fréquent parmi 2 milliards d'entiers
L'approche habituelle consiste à utiliser une table de hachage pour créer des statistiques de fréquence de mots pour chaque nombre qui apparaît. La clé de la table de hachage est un entier et la valeur enregistre le nombre de fois que l'entier apparaît. La quantité de données dans cette question est de 2 milliards. Il est possible qu'un nombre apparaisse 2 milliards de fois. Afin d'éviter un débordement, la clé de la table de hachage est de 32 bits (4B) et la valeur est également de 32 bits (4B). ). Ensuite, un enregistrement d'une table de hachage doit occuper 8B.
Lorsque le nombre d'enregistrements de table de hachage est de 200 millions, 1,6 milliard d'octets sont requis (8*200 millions) et au moins 1,6 Go de mémoire sont requis (1,6 milliard/2 ^ 30,1 Go == 2 ^ 30 octets == 1 000 000 000). ). Ensuite, 2 milliards d'enregistrements nécessitent au moins 16 Go de mémoire, ce qui ne répond pas aux exigences de la question.
La solution consiste à utiliser la fonction de hachage pour diviser le gros fichier contenant 2 milliards de nombres en 16 petits fichiers. Selon la fonction de hachage, les 2 milliards de données peuvent être réparties uniformément dans les 16 fichiers. Le même nombre ne peut pas être divisé par. la fonction de hachage. Sur différents petits fichiers, en supposant que la fonction de hachage soit suffisante. Utilisez ensuite une fonction de hachage pour chaque petit fichier afin de compter le nombre d'occurrences de chaque numéro, afin d'obtenir le numéro avec le plus d'occurrences parmi les 16 fichiers, puis sélectionnez la clé avec l'occurrence la plus élevée parmi les 16 nombres.
▐Nombre qui n'apparaît pas (tableau de bits)
Trouver le nombre qui n'apparaît pas parmi 4 milliards d'entiers non négatifs
Pour le problème initial, si une table de hachage est utilisée pour sauvegarder les nombres apparus, alors dans le pire des cas, 4 milliards de nombres sont différents, alors la table de hachage doit sauvegarder 4 milliards de données, et un entier de 32 bits nécessite 4B, puis 4 milliards * 4B = 16 milliards d'octets. Généralement, environ 1 milliard d'octets de données nécessitent 1 Go d'espace, ce qui ne répond pas aux exigences.
Changeons de méthode et demandons un tableau de bits. La taille du tableau est de 4294967295, soit environ 4 milliards de bits/8 = 500 millions d'octets, donc 0,5 G d'espace est nécessaire. 0 et 1. Alors, comment utiliser ce tableau de bits ? Haha, la longueur du tableau correspond juste à la plage de nombres de nos entiers, alors chaque valeur d'indice du tableau correspond à un nombre dans 4294967295 et traverse 4 milliards de nombres non signés un par un. Par exemple, si 20 est rencontré, alors bitArray. [20]= 1 ; lorsque 666 est rencontré, bitArray[666]=1, après avoir parcouru tous les nombres, changez la position correspondante du tableau en 1.
Trouvez un nombre qui n'apparaît pas parmi 4 milliards d'entiers non négatifs. La limite de mémoire est de 10 Mo.
Un milliard d'octets de données nécessite environ 1 Go d'espace pour être traité, donc 10 Mo de mémoire peuvent traiter 10 millions d'octets de données, soit 80 millions de bits. Pour 4 milliards d'entiers non négatifs, si vous demandez un tableau de bits, 4 milliards de bits. /080 millions de bits=50, alors cela coûtera au moins 50 blocs à traiter. Analysons et répondons en utilisant 64 blocs.
Résumer les solutions avancées
En fonction de la limite de mémoire de 10 Mo, déterminez la taille de l'intervalle statistique, qui correspond à la taille bitArr lors du deuxième parcours.
Utilisez le comptage par intervalles pour trouver l'intervalle avec des comptes insuffisants. Il doit y avoir des nombres dans cet intervalle qui n'apparaissent pas.
Effectuez un mappage bitmap des nombres dans cet intervalle, puis parcourez le bitmap pour trouver un nombre qui n'apparaît pas.
Ma propre opinion
Si vous recherchez simplement un nombre, vous pouvez effectuer des opérations de module de bits élevé, l'écrire dans 64 fichiers différents, puis le traiter en même temps via bitArray dans le plus petit fichier.
4 milliards d'entiers non signés, 1 Go de mémoire, trouvez tous les nombres qui apparaissent deux fois
Pour le problème d’origine, le bitmap peut être utilisé pour représenter l’occurrence de nombres. Plus précisément, il s'agit d'un tableau de types de bits bitArr d'une longueur de 4294967295×2. Deux positions sont utilisées pour représenter la fréquence des mots d'un nombre 1B occupant 8 bits, donc le tableau de types de bits d'une longueur de 4294967295×2. occupe 1 Go d'espace. Comment utiliser ce tableau bitArr ? Parcourez ces 4 milliards de nombres non signés. Si num est rencontré pour la première fois, définissez bitArr[num 2+1] et bitArr[num 2] sur 01. Si num est rencontré pour la deuxième fois, définissez bitArr[num 2+1 ] et bitArr[num 2] sont définis sur 10. Si num est rencontré pour la troisième fois, bitArr[num 2+1] et bitArr[num 2] sont définis sur 11. Lorsque je rencontre à nouveau num dans le futur, je constate que bitArr[num 2+1] et bitArr[num 2] ont été définis sur 11 pour le moment, donc aucun autre paramètre n'est effectué. Une fois le parcours terminé, parcourez bitArr dans l'ordre. S'il s'avère que bitArr[i 2+1] et bitArr[i 2] sont définis sur 10, alors i est le nombre qui apparaît deux fois.
▐URL en double (par machine)
Trouvez les URL en double parmi 10 milliards d'URL
La solution au problème d'origine utilise une méthode conventionnelle pour résoudre les problèmes du Big Data : attribuer des fichiers volumineux aux machines via une fonction de hachage, ou diviser des fichiers volumineux en petits fichiers via une fonction de hachage. Cette division est effectuée jusqu'à ce que le résultat de la division réponde aux contraintes de ressources. Tout d’abord, vous devez demander à l’intervieweur quelles sont les contraintes de ressources, y compris les besoins en mémoire, en temps de calcul, etc. Après avoir clarifié les exigences de restriction, chaque URL peut être attribuée à plusieurs machines via une fonction de hachage ou divisée en plusieurs petits fichiers. Le nombre exact de « plusieurs » est ici calculé en fonction de restrictions de ressources spécifiques.
Par exemple, un gros fichier de 10 milliards d'octets est distribué à 100 machines via une fonction de hachage, puis chaque machine compte s'il y a des URL en double dans les URL qui lui sont attribuées. En même temps, la nature de la fonction de hachage détermine si. la même URL est Il est impossible de distribuer l'URL sur différentes machines ; ou de diviser le gros fichier en 1000 petits fichiers via la fonction de hachage sur une seule machine, puis d'utiliser la table de hachage pour chaque petit fichier pour trouver les URL en double ; distribuez-le à la machine. Ou après avoir divisé les fichiers, triez-les, puis vérifiez s'il y a des URL en double après le tri. En bref, gardez à l'esprit que de nombreux problèmes liés au Big Data sont indissociables du déchargement. Soit la fonction de hachage distribue le contenu du gros fichier sur différentes machines, soit la fonction de hachage divise le gros fichier en petits fichiers puis traite chaque petit nombre. .
▐ Recherche TOPK (petit tas de racines)
Recherchez un grand nombre de mots et trouvez les mots TOP100 les plus populaires.
Au début, nous avons utilisé l'idée du hachage pour acheminer des fichiers de vocabulaire contenant des dizaines de milliards de données vers différentes machines. Le nombre spécifique de machines était déterminé par l'intervieweur ou par plusieurs restrictions. Pour chaque machine, si la quantité de données distribuées est encore importante, par exemple en raison d'une mémoire insuffisante ou d'autres problèmes, la fonction de hachage peut être utilisée pour diviser les fichiers distribués de chaque machine en fichiers plus petits à traiter.
Lors du traitement de chaque petit fichier, la table de hachage compte chaque mot et sa fréquence de mot. Une fois l'enregistrement de la table de hachage établi, la table de hachage est parcourue, un petit tas racine de taille 100 est utilisé pour sélectionner Obtenir le. top100 de chaque petit fichier (le top100 global non trié). Chaque petit fichier possède son propre petit tas racine de fréquence de mots (le top 100 global non trié). En triant les mots dans le petit tas racine en fonction de la fréquence des mots, le top 100 trié de chaque petit fichier est obtenu. Triez ensuite le top100 de chaque petit fichier en externe ou continuez à utiliser le petit tas racine pour sélectionner le top100 sur chaque machine. Les top100 entre différentes machines sont ensuite triés en externe ou continuent d'utiliser le petit tas racine, et finalement les top100 de l'ensemble des dizaines de milliards de données sont obtenus. Pour le problème Top K, en plus du détournement de fonction de hachage et des statistiques de fréquence de mots utilisant des tables de hachage, des structures de tas et un tri externe sont souvent utilisés pour le résoudre.
▐Médiane (recherche binaire unidirectionnelle)
10 Mo de mémoire, trouvez la médiane de 10 milliards d'entiers
Assez de mémoire : si vous disposez de suffisamment de mémoire, pourquoi vous inquiéter ? Triez simplement les 10 milliards d'éléments. Vous pouvez utiliser le bullage... et ensuite trouver celui du milieu. Mais pensez-vous que l’intervieweur vous donnera de la mémoire ? ?
Mémoire insuffisante : la question dit qu'il s'agit d'un entier, mais nous pensons qu'il s'agit d'un entier signé, il fait donc 4 octets et occupe 32 bits.
Supposons que 10 milliards de nombres soient stockés dans un fichier volumineux, lisez une partie du fichier en mémoire en séquence (sans dépasser la limite de mémoire), représentez chaque nombre en binaire et comparez le bit le plus élevé du binaire (bit 32, bit de signe, 0 est positif, 1 est négatif), si le bit le plus élevé du nombre est 0, le numéro est écrit dans le fichier file_0 ; si le bit le plus élevé est 1, le nombre est écrit dans le fichier file_1 ;
Ainsi, 10 milliards de nombres sont divisés en deux fichiers. Supposons qu'il y ait 6 milliards de nombres dans le fichier file_0 et 4 milliards de nombres dans le fichier file_1. Ensuite, la médiane se trouve dans le fichier file_0 et est le milliardième nombre après avoir trié tous les nombres dans le fichier file_0. (Les nombres dans file_1 sont tous des nombres négatifs et les nombres dans file_0 sont tous des nombres positifs. Autrement dit, il n'y a que 4 milliards de nombres négatifs au total, donc le 5 milliardième nombre après tri doit être situé dans file_0)
Il ne nous reste plus qu'à traiter le fichier file_0 (plus besoin de considérer le fichier file_1). Pour le fichier file_0, prenez les mêmes mesures que ci-dessus : lire une partie du fichier file_0 en mémoire en séquence (sans dépasser la limite de mémoire), représenter chaque nombre en binaire, comparer le deuxième bit le plus élevé du binaire (le 31ème bit), si le deuxième bit le plus élevé du nombre S'il est 0, écrivez-le dans le fichier file_0_0 ; si le deuxième bit le plus élevé est 1, écrivez-le dans le fichier file_0_1.
En supposant maintenant qu'il y a 3 milliards de nombres dans file_0_0 et 3 milliards de nombres dans file_0_1, la médiane est la suivante : le milliardième nombre après les nombres dans file_0_0 est trié du plus petit au plus grand.
Abandonnez le fichier file_0_1 et continuez à diviser le fichier file_0_0 selon le chiffre le plus élevé (la 30ème position). Supposons que les deux fichiers divisés cette fois sont : il y a 500 millions de nombres dans file_0_0_0 et 2,5 milliards de nombres dans file_0_0_1. est le 500 millionième nombre après avoir trié tous les nombres du fichier file_0_0_1.
Selon l'idée ci-dessus, jusqu'à ce que le fichier divisé puisse être directement chargé dans la mémoire, les nombres peuvent être rapidement triés directement pour trouver la médiane.
▐Système de noms de domaine courts (mise en cache)
Concevez un système de noms de domaine courts pour convertir les URL longues en URL courtes.
À l'aide de l'attributeur de numéro, la valeur initiale est 0. Pour chaque demande de génération de lien court, la valeur de l'attributeur de numéro est incrémentée, puis cette valeur est convertie en 62 hexadécimaux (a-zA-Z0-9), comme le premier requête Au moment de la requête, la valeur de l'assignateur de numéro est 0, correspondant à l'hexadécimal a. A la deuxième requête, la valeur de l'assignateur de numéro est 1, correspondant à l'hexadécimal b. l'attributeur de numéro est 10000, correspondant à La notation hexadécimale est sBc.
Concaténez le nom de domaine du serveur de liens courts avec la valeur hexadécimale 62 de l'assignateur sous forme de chaîne, qui est l'URL du lien court, par exemple : t.cn/sBc.
Processus de redirection : après avoir généré un lien court, vous devez stocker la relation de mappage entre le lien court et le lien long, c'est-à-dire sBc -> URL. Lorsque le navigateur accède au serveur de liens courts, il obtient le lien d'origine en fonction du. Chemin URL, puis effectue une redirection 302. Les relations de mappage peuvent être stockées à l'aide de KV, tel que Redis ou Memcache.
▐Stockage massif des commentaires (file d'attente des messages)
Supposons qu'un tel scénario existe. Il y a une nouvelle. Le nombre de commentaires sur l'actualité peut être important. Comment concevoir la lecture et l'écriture des commentaires ?
La page frontale est affichée directement à l'utilisateur et stockée dans la base de données de manière asynchrone via la file d'attente des messages.
▐Nombre d'utilisateurs en ligne/simultanés (Redis)
-
Idées de solutions pour afficher le nombre d'utilisateurs en ligne sur un site Web
-
Maintenir la table des utilisateurs en ligne -
Utiliser les statistiques Redis
-
Afficher le nombre d'utilisateurs simultanés du site Web
-
Chaque fois qu'un utilisateur accède au service, l'ID de l'utilisateur est écrit dans la file d'attente ZSORT et le poids est l'heure actuelle ; -
Calculer le nombre d'utilisateurs de l'organisation Zrange en une minute en fonction du poids (c'est-à-dire du temps) ; -
Supprimer les utilisateurs Zrem qui ont expiré depuis plus d'une minute ;
▐Chaînes populaires (arbre de préfixes)
Méthode HashMap
Bien que le nombre total de chaînes soit relativement important, il ne dépasse pas 300w après déduplication. Par conséquent, vous pouvez envisager de sauvegarder toutes les chaînes et leurs heures d'occurrence dans un HashMap. L'espace occupé est de 300w*(255+4)≈777M (dont. 4 Représente les 4 octets occupés par l'entier). On voit que 1 Go d’espace mémoire est tout à fait suffisant.
L'idée est la suivante
Tout d'abord, parcourez la chaîne si elle n'est pas dans la carte, stockez-la directement dans la carte, et la valeur est enregistrée comme 1 ; si elle est dans la carte, ajoutez 1 à la valeur correspondante. Cette étape a une complexité temporelle O(N).
Parcourez ensuite la carte pour créer un petit tas supérieur de 10 éléments. Si le nombre d'occurrences de la chaîne parcourue est supérieur au nombre d'occurrences de la chaîne en haut du tas, remplacez-la et ajustez le tas à un petit sommet. tas.
Une fois le parcours terminé, les 10 chaînes du tas sont les chaînes qui apparaissent le plus. La complexité temporelle de cette étape O(Nlog10).
méthode de l'arbre de préfixes
Lorsque ces chaînes ont un grand nombre de préfixes identiques, vous pouvez envisager d'utiliser une arborescence de préfixes pour compter le nombre d'occurrences de la chaîne. Les nœuds de l'arborescence enregistrent le nombre d'occurrences de la chaîne, et 0 signifie aucune occurrence.
L'idée est la suivante
Lors du parcours de la chaîne, recherchez dans l'arborescence des préfixes. Si trouvé, ajoutez 1 au nombre de chaînes stockées dans le nœud. Sinon, créez un nouveau nœud pour cette chaîne. Une fois la construction terminée, ajoutez l'occurrence de la chaîne dans le nœud. nœud feuille. Le nombre de fois est défini sur 1.
Enfin, le petit tas supérieur est toujours utilisé pour trier le nombre d'occurrences de la chaîne.
▐Algorithme de l'enveloppe rouge
Méthode de coupe linéaire, coupant N-1 couteaux dans un intervalle. Le plus tôt sera le mieux
Méthode à double moyenne, aléatoire dans [0~quantité restante/nombre restant de personnes*2], relativement uniforme

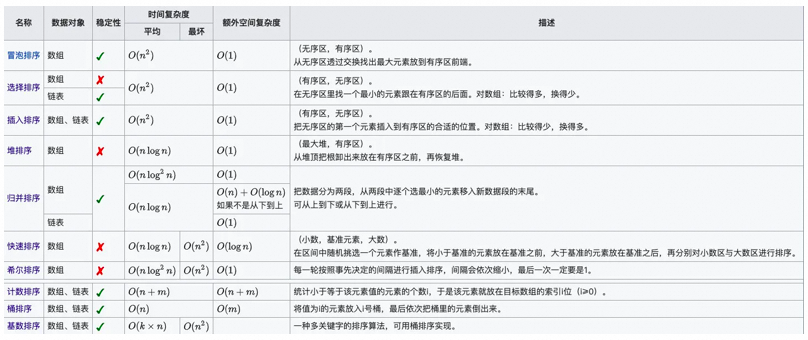
▐Tri rapide de l'écriture manuscrite
public class QuickSort {public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}/* 常规快排 */public static void quickSort1(int[] arr, int L , int R) {if (L > R) return;int M = partition(arr, L, R);quickSort1(arr, L, M - 1);quickSort1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) return -1;if (L == R) return L;int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R])swap(arr, index, ++lessEqual);index++;}swap(arr, ++lessEqual, R);return lessEqual;}/* 荷兰国旗 */public static void quickSort2(int[] arr, int L, int R) {if (L > R) return;int[] equalArea = netherlandsFlag(arr, L, R);quickSort2(arr, L, equalArea[0] - 1);quickSort2(arr, equalArea[1] + 1, R);}public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) return new int[] { -1, -1 };if (L == R) return new int[] { L, R };int less = L - 1;int more = R;int index = L;while (index < more) {if (arr[index] == arr[R]) {index++;} else if (arr[index] < arr[R]) {swap(arr, index++, ++less);} else {swap(arr, index, --more);}}swap(arr, more, R);return new int[] { less + 1, more };}// for testpublic static void main(String[] args) {int testTime = 1;int maxSize = 10000000;int maxValue = 100000;boolean succeed = true;long T1=0,T2=0;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);int[] arr3 = copyArray(arr1);// int[] arr1 = {9,8,7,6,5,4,3,2,1};long t1 = System.currentTimeMillis();quickSort1(arr1,0,arr1.length-1);long t2 = System.currentTimeMillis();quickSort2(arr2,0,arr2.length-1);long t3 = System.currentTimeMillis();T1 += (t2-t1);T2 += (t3-t2);if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {succeed = false;break;}}System.out.println(T1+" "+T2);// System.out.println(succeed ? "Nice!" : "Oops!");}private static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random())- (int) (maxValue * Math.random());}return arr;}private static int[] copyArray(int[] arr) {if (arr == null) return null;int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}private static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))return false;if (arr1 == null && arr2 == null)return true;if (arr1.length != arr2.length)return false;for (int i = 0; i < arr1.length; i++)if (arr1[i] != arr2[i])return false;return true;}private static void printArray(int[] arr) {if (arr == null)return;for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}}
▐Fusion d'écriture manuscrite
public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R)help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];while (p1 <= M)help[i++] = arr[p1++];while (p2 <= R)help[i++] = arr[p2++];for (i = 0; i < help.length; i++)arr[L + i] = help[i];}public static void mergeSort(int[] arr, int L, int R) {if (L == R)return;int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};mergeSort(arr, 0, arr.length - 1);printArray(arr);}
▐Piles manuscrites
// 堆排序额外空间复杂度O(1)public static void heapSort(int[] arr) {if (arr == null || arr.length < 2)return;for (int i = arr.length - 1; i >= 0; i--)heapify(arr, i, arr.length);int heapSize = arr.length;swap(arr, 0, --heapSize);// O(N*logN)while (heapSize > 0) { // O(N)heapify(arr, 0, heapSize); // O(logN)swap(arr, 0, --heapSize); // O(1)}}// arr[index]刚来的数,往上public static void heapInsert(int[] arr, int index) {while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// arr[index]位置的数,能否往下移动public static void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 左孩子的下标while (left < heapSize) { // 下方还有孩子的时候// 两个孩子中,谁的值大,把下标给largest// 1)只有左孩子,left -> largest// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largestint largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;// 父和较大的孩子之间,谁的值大,把下标给largestlargest = arr[largest] > arr[index] ? largest : index;if (largest == index)break;swap(arr, largest, index);index = largest;left = index * 2 + 1;}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};heapSort(arr1);printArray(arr1);}
▐Singleton manuscrit
public class Singleton {private volatile static Singleton singleton;private Singleton() {}public static Singleton getSingleton() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;}}
▐LRUcache manuscrit
// 基于linkedHashMappublic class LRUCache {private LinkedHashMap<Integer,Integer> cache;private int capacity; //容量大小public LRUCache(int capacity) {cache = new LinkedHashMap<>(capacity);this.capacity = capacity;}public int get(int key) {//缓存中不存在此key,直接返回if(!cache.containsKey(key)) {return -1;}int res = cache.get(key);cache.remove(key); //先从链表中删除cache.put(key,res); //再把该节点放到链表末尾处return res;}public void put(int key,int value) {if(cache.containsKey(key)) {cache.remove(key); //已经存在,在当前链表移除}if(capacity == cache.size()) {//cache已满,删除链表头位置Set<Integer> keySet = cache.keySet();Iterator<Integer> iterator = keySet.iterator();cache.remove(iterator.next());}cache.put(key,value); //插入到链表末尾}}
//手写双向链表class LRUCache {class DNode {DNode prev;DNode next;int val;int key;}Map<Integer, DNode> map = new HashMap<>();DNode head, tail;int cap;public LRUCache(int capacity) {head = new DNode();tail = new DNode();head.next = tail;tail.prev = head;cap = capacity;}public int get(int key) {if (map.containsKey(key)) {DNode node = map.get(key);removeNode(node);addToHead(node);return node.val;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {DNode node = map.get(key);node.val = value;removeNode(node);addToHead(node);} else {DNode newNode = new DNode();newNode.val = value;newNode.key = key;addToHead(newNode);map.put(key, newNode);if (map.size() > cap) {map.remove(tail.prev.key);removeNode(tail.prev);}}}public void removeNode(DNode node) {DNode prevNode = node.prev;DNode nextNode = node.next;prevNode.next = nextNode;nextNode.prev = prevNode;}public void addToHead(DNode node) {DNode firstNode = head.next;head.next = node;node.prev = head;node.next = firstNode;firstNode.prev = node;}}
▐Pool de threads d' écriture manuscrite
package com.concurrent.pool;import java.util.HashSet;import java.util.Set;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;public class MySelfThreadPool {//默认线程池中的线程的数量private static final int WORK_NUM = 5;//默认处理任务的数量private static final int TASK_NUM = 100;private int workNum;//线程数量private int taskNum;//任务数量private final Set<WorkThread> workThreads;//保存线程的集合private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务public MySelfThreadPool() {this(WORK_NUM, TASK_NUM);}public MySelfThreadPool(int workNum, int taskNum) {if (workNum <= 0) workNum = WORK_NUM;if (taskNum <= 0) taskNum = TASK_NUM;taskQueue = new ArrayBlockingQueue<>(taskNum);this.workNum = workNum;this.taskNum = taskNum;workThreads = new HashSet<>();//启动一定数量的线程数,从队列中获取任务处理for (int i=0;i<workNum;i++) {WorkThread workThread = new WorkThread("thead_"+i);workThread.start();workThreads.add(workThread);}}public void execute(Runnable task) {try {taskQueue.put(task);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void destroy() {System.out.println("ready close thread pool...");if (workThreads == null || workThreads.isEmpty()) return ;for (WorkThread workThread : workThreads) {workThread.stopWork();workThread = null;//help gc}workThreads.clear();}private class WorkThread extends Thread{public WorkThread(String name) {super();setName(name);}@Overridepublic void run() {while (!interrupted()) {try {Runnable runnable = taskQueue.take();//获取任务if (runnable !=null) {System.out.println(getName()+" readyexecute:"+runnable.toString());runnable.run();//执行任务}runnable = null;//help gc} catch (Exception e) {interrupt();e.printStackTrace();}}}public void stopWork() {interrupt();}}}package com.concurrent.pool;public class TestMySelfThreadPool {private static final int TASK_NUM = 50;//任务的个数public static void main(String[] args) {MySelfThreadPool myPool = new MySelfThreadPool(3,50);for (int i=0;i<TASK_NUM;i++) {myPool.execute(new MyTask("task_"+i));}}static class MyTask implements Runnable{private String name;public MyTask(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("task :"+name+" end...");}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "name = "+name;}}}
▐Modèle de producteur-consommateur manuscrit
public class Storage {private static int MAX_VALUE = 100;private List<Object> list = new ArrayList<>();public void produce(int num) {synchronized (list) {while (list.size() + num > MAX_VALUE) {System.out.println("暂时不能执行生产任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.add(new Object());}System.out.println("已生产产品数"+num+" 仓库容量"+list.size());list.notifyAll();}}public void consume(int num) {synchronized (list) {while (list.size() < num) {System.out.println("暂时不能执行消费任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.remove(0);}System.out.println("已消费产品数"+num+" 仓库容量" + list.size());list.notifyAll();}}}public class Producer extends Thread {private int num;private Storage storage;public Producer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.produce(this.num);}}public class Customer extends Thread {private int num;private Storage storage;public Customer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.consume(this.num);}}public class Test {public static void main(String[] args) {Storage storage = new Storage();Producer p1 = new Producer(storage);Producer p2 = new Producer(storage);Producer p3 = new Producer(storage);Producer p4 = new Producer(storage);Customer c1 = new Customer(storage);Customer c2 = new Customer(storage);Customer c3 = new Customer(storage);p1.setNum(10);p2.setNum(20);p3.setNum(80);c1.setNum(50);c2.setNum(20);c3.setNum(20);c1.start();c2.start();c3.start();p1.start();p2.start();p3.start();}}
▐File d'attente de blocage d'écriture manuscrite
public class blockQueue {private List<Integer> container = new ArrayList<>();private volatile int size;private volatile int capacity;private Lock lock = new ReentrantLock();private final Condition isNull = lock.newCondition();private final Condition isFull = lock.newCondition();blockQueue(int capacity) {this.capacity = capacity;}public void add(int data) {try {lock.lock();try {while (size >= capacity) {System.out.println("阻塞队列满了");isFull.await();}} catch (Exception e) {isFull.signal();e.printStackTrace();}++size;container.add(data);isNull.signal();} finally {lock.unlock();}}public int take() {try {lock.lock();try {while (size == 0) {System.out.println("阻塞队列空了");isNull.await();}} catch (Exception e) {isNull.signal();e.printStackTrace();}--size;int res = container.get(0);container.remove(0);isFull.signal();return res;} finally {lock.unlock();}}}public static void main(String[] args) {AxinBlockQueue queue = new AxinBlockQueue(5);Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {queue.add(i);System.out.println("塞入" + i);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});Thread t2 = new Thread(() -> {for (; ; ) {System.out.println("消费"+queue.take());try {Thread.sleep(800);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
▐ABC d'impression alternative multithread manuscrite
package com.demo.test;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class syncPrinter implements Runnable{// 打印次数private static final int PRINT_COUNT = 10;private final ReentrantLock reentrantLock;private final Condition thisCondtion;private final Condition nextCondtion;private final char printChar;public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {this.reentrantLock = reentrantLock;this.nextCondtion = nextCondition;this.thisCondtion = thisCondtion;this.printChar = printChar;}@Overridepublic void run() {// 获取打印锁 进入临界区reentrantLock.lock();try {// 连续打印PRINT_COUNT次for (int i = 0; i < PRINT_COUNT; i++) {//打印字符System.out.print(printChar);// 使用nextCondition唤醒下一个线程// 因为只有一个线程在等待,所以signal或者signalAll都可以nextCondtion.signal();// 不是最后一次则通过thisCondtion等待被唤醒// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁if (i < PRINT_COUNT - 1) {try {// 本线程让出锁并等待唤醒thisCondtion.await();} catch (InterruptedException e) {e.printStackTrace();}}}} finally {reentrantLock.unlock();}}public static void main(String[] args) throws InterruptedException {ReentrantLock lock = new ReentrantLock();Condition conditionA = lock.newCondition();Condition conditionB = lock.newCondition();Condition conditionC = lock.newCondition();Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));printA.start();Thread.sleep(100);printB.start();Thread.sleep(100);printC.start();}}
▐Imprimer alternativement FooBar
//手太阴肺经 BLOCKING Queuepublic class FooBar {private int n;private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);public FooBar(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.put(i);printFoo.run();bar.put(i);}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.take();printBar.run();foo.take();}}}//手阳明大肠经CyclicBarrier 控制先后class FooBar6 {private int n;public FooBar6(int n) {this.n = n;}CyclicBarrier cb = new CyclicBarrier(2);volatile boolean fin = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {while(!fin);printFoo.run();fin = false;try {cb.await();} catch (BrokenBarrierException e) {}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {try {cb.await();} catch (BrokenBarrierException e) {}printBar.run();fin = true;}}}//手少阴心经 自旋 + 让出CPUclass FooBar5 {private int n;public FooBar5(int n) {this.n = n;}volatile boolean permitFoo = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; ) {if(permitFoo) {printFoo.run();i++;permitFoo = false;}else{Thread.yield();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; ) {if(!permitFoo) {printBar.run();i++;permitFoo = true;}else{Thread.yield();}}}}//手少阳三焦经 可重入锁 + Conditionclass FooBar4 {private int n;public FooBar4(int n) {this.n = n;}Lock lock = new ReentrantLock(true);private final Condition foo = lock.newCondition();volatile boolean flag = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {lock.lock();try {while(!flag) {foo.await();}printFoo.run();flag = false;foo.signal();}finally {lock.unlock();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n;i++) {lock.lock();try {while(flag) {foo.await();}printBar.run();flag = true;foo.signal();}finally {lock.unlock();}}}}//手厥阴心包经 synchronized + 标志位 + 唤醒class FooBar3 {private int n;// 标志位,控制执行顺序,true执行printFoo,false执行printBarprivate volatile boolean type = true;private final Object foo= new Object(); // 锁标志public FooBar3(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(!type){foo.wait();}printFoo.run();type = false;foo.notifyAll();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(type){foo.wait();}printBar.run();type = true;foo.notifyAll();}}}}//手太阳小肠经 信号量 适合控制顺序class FooBar2 {private int n;private Semaphore foo = new Semaphore(1);private Semaphore bar = new Semaphore(0);public FooBar2(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.acquire();printFoo.run();bar.release();}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.acquire();printBar.run();foo.release();}}}
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。