
Note de l'éditeur : actuellement, le système Retrieval Enhanced Generation (RAG) est devenu l'une des technologies clés permettant d'intégrer des connaissances massives dans de grands modèles. Cependant, le traitement efficace des données semi-structurées et non structurées, en particulier les données tabulaires dans les documents, reste un problème majeur auquel sont confrontés les systèmes RAG.
L'auteur de cet article propose une nouvelle solution de traitement des données tabulaires pour résoudre ce problème. L'auteur trie d'abord systématiquement les technologies de base du traitement des tables dans le système RAG, y compris l'analyse des tables, la conception de la structure d'index, etc., et passe en revue certaines solutions open source existantes. Sur cette base, l'auteur a proposé sa propre innovation - utiliser l'outil Nougat pour analyser avec précision et efficacité le contenu du tableau dans le document, utiliser le modèle de langage pour résumer le tableau et son titre, et enfin construire une nouvelle structure d'index de synthèse du document, et donne des détails complets sur l’implémentation du code.
L'avantage de cette méthode est qu'elle peut analyser efficacement le tableau et prendre pleinement en compte la relation entre le résumé du tableau et le tableau. Elle ne nécessite pas l'utilisation d'un LLM multimodal et peut réduire les coûts d'analyse. Attendons de voir l’application et le développement ultérieurs de ce système dans la pratique.
Auteur | Florian Juin
Compilé | Yue Yang
La mise en œuvre d'un système RAG est une tâche difficile, en particulier lorsque les tableaux de documents non structurés doivent être analysés et compris. Pour les documents numérisés par opérations de numérisation (documents numérisés) ou les documents au format image (documents au format image), la mise en œuvre de ces opérations est encore plus difficile. Il y a au moins trois défis :
- Les documents numérisés par opérations de numérisation (documents numérisés) ou les documents au format image (documents au format image) sont relativement complexes , comme la diversité des structures du document, le document peut contenir certains éléments non textuels, et le document peut simultanément La présence de le contenu manuscrit et imprimé posera des défis en matière d’extraction précise et automatisée des informations des formulaires. Une analyse inexacte du document détruira la structure du tableau. La conversion d'informations incomplètes du tableau en représentation vectorielle (intégration) ne peut pas seulement capturer efficacement les informations sémantiques du tableau, mais peut également facilement causer des problèmes dans la sortie finale de RAG.
- Comment extraire les titres de chaque tableau et les associer au tableau spécifique auquel ils correspondent.
- Comment organiser et stocker efficacement les informations sémantiques clés dans des tableaux grâce à une conception raisonnable de la structure d'index.
Cet article présente d'abord comment gérer et traiter les données tabulaires dans le modèle Retrieval Augmented Generation (RAG). Ensuite, certaines solutions open source existantes sont examinées et, enfin, une nouvelle méthode de gestion de données tabulaires est conçue et mise en œuvre sur la base de la technologie actuelle.
01 Introduction aux technologies de base liées aux données des tables RAG
1.1 Analyse de table Analyse des données de table
La fonction principale de ce module est d'extraire avec précision les structures de tableaux de documents ou d'images non structurés.
Exigences supplémentaires : il est préférable d'extraire le titre du tableau correspondant pour permettre aux développeurs d'associer plus facilement le titre du tableau au tableau.
D'après ma compréhension actuelle, il existe plusieurs méthodes, comme le montre la figure 1 :
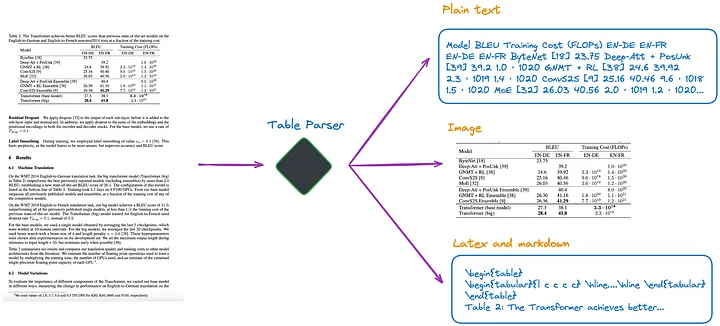
Figure 1 : Analyseur de table. Photo fournie par l'auteur original.
(a).Utilisez un LLM multimodal (tel que GPT-4V[1]) pour reconnaître les tableaux et extraire des informations de chaque page PDF.
- Entrée : page PDF au format image
- Sortie : données tabulaires au format JSON ou autres formats. Si le LLM multimodal ne parvient pas à extraire les données tabulaires, il doit résumer l'image PDF et renvoyer un résumé du contenu.
(b). Utilisez des modèles de détection de table professionnels (tels que Table Transformer [2]) pour identifier les structures de table.
- Entrée : image de la page PDF
- Sortie : image du tableau
(c) Utilisez des frameworks open source, tels que non structurés[3] ou d'autres frameworks qui utilisent également des modèles de détection d'objets (cet article[4] détaille le processus de détection de tables non structurées). Ces frameworks peuvent analyser entièrement l'intégralité du document et extraire le contenu lié aux tables des résultats analysés.
- Entrée : Document au format PDF ou image
- Résultat : tableau au format texte brut ou HTML (obtenu en analysant l'intégralité du document)
(d). Utilisez des modèles de bout en bout tels que Nougat[5] et Donut[6] pour analyser l'intégralité du document et extraire le contenu lié aux tables. Cette approche ne nécessite pas de modèle OCR.
- Entrée : Document au format PDF ou image
- Résultat : tableau au format LaTeX ou JSON (obtenu en analysant l'intégralité du document)
Il convient de noter que quelle que soit la méthode utilisée pour extraire les informations du tableau, le titre du tableau doit également être extrait. Parce que dans la plupart des cas, le titre du tableau est une brève description du tableau par l'auteur du document ou de l'article, qui peut résumer dans une large mesure le contenu du tableau entier.
Parmi les quatre méthodes ci-dessus, la méthode (d) permet de récupérer plus facilement les titres des tables. C'est un énorme avantage pour les développeurs car ils peuvent associer des titres de tableaux à des tableaux. Les expériences suivantes illustreront davantage cela.
1.2 Comment Index Structure indexe les données tabulaires
Il existe à peu près les types de méthodes d'indexation suivants :
(e). Uniquement les tableaux d’index au format image.
(f). Uniquement les tables d'index au format texte brut ou JSON.
(g). Uniquement les tables d'index au format LaTeX.
(h). Seul le résumé du tableau est indexé.
(i). Petit à grand (Note du traducteur : il inclut à la fois une indexation à granularité fine, telle que l'indexation de chaque ligne ou résumé de tableau, et une indexation à granularité grossière, telle que l'indexation de la table entière d'images, de texte brut ou de LaTeX. tapez data, formez une structure d'index hiérarchique, petite à grande.) Ou utilisez le résumé du tableau pour créer une structure d'index, comme le montre la figure 2.
Le contenu du petit bloc (Note du traducteur : bloc de données correspondant au niveau d'index à granularité fine), par exemple en traitant chaque ligne du tableau ou les informations récapitulatives comme un petit bloc de données indépendant.
Le contenu du gros morceau (Note du traducteur : le bloc de données correspondant au niveau d'index à granularité grossière) peut être un tableau entier au format image, au format texte brut ou au format LaTeX.
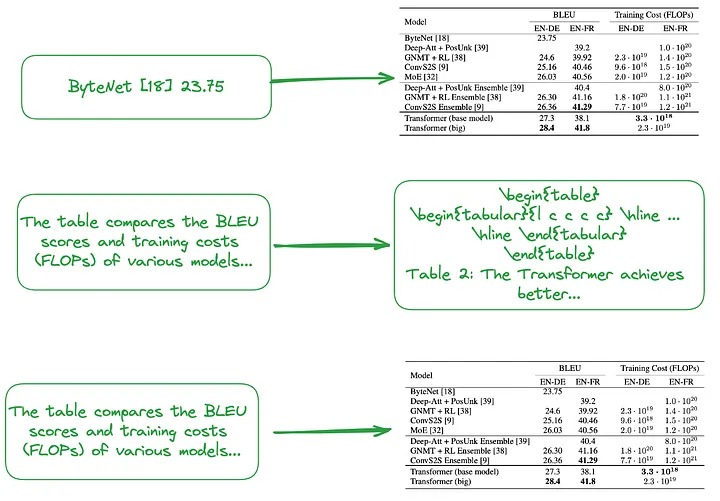
Figure 2 : Indexation de petit à grand (en haut) et utilisation de résumés de tableaux (au milieu, en bas). Photo fournie par l'auteur original.
Comme mentionné ci-dessus, les résumés tabulaires sont généralement générés à l'aide du traitement LLM :
- Entrée : format d'image, format de texte ou tableau au format LaTeX
- Résultat : résumé du tableau
1.3 Une approche qui ne nécessite pas d'analyse de tables, de création d'index ou d'utilisation de la technologie RAG
Certains algorithmes ne nécessitent pas d'analyse de données tabulaires.
(j). Envoyez l'image pertinente (page du document PDF) et la requête de l'utilisateur au modèle VQA (tel que DAN [7], etc.) (Note du traducteur : abréviation de modèle de réponse visuelle aux questions. Il s'agit d'une combinaison de modèles informatiques. de techniques de vision et de traitement du langage naturel qui peuvent être utilisées pour répondre à des questions en langage naturel sur le contenu de l'image) ou LLM multimodal et renvoyer des réponses.
- Contenu à indexer : Documents au format image
- Quoi envoyer au modèle VQA ou LLM multimodal : Requête + page de documentation correspondante sous forme d'image
(k). Envoyez la page PDF au format texte approprié et la requête de l'utilisateur à LLM, puis renvoyez la réponse.
- Contenu à indexer : Documents au format texte
- Contenu envoyé au LLM : Requête + page de documentation correspondante au format texte
(l). Envoyez les images du document pertinentes (pages du document PDF), les blocs de texte et la requête de l'utilisateur à un LLM multimodal (tel que GPT-4V, etc.), puis renvoyez directement la réponse.
- Contenu à indexer : documents au format image et fragments de documents au format texte
- Contenu envoyé au LLM multimodal : requête + document au format d'image correspondant + morceaux de texte correspondants
De plus, voici quelques méthodes qui ne nécessitent pas d'indexation, comme le montrent les figures 3 et 4 :
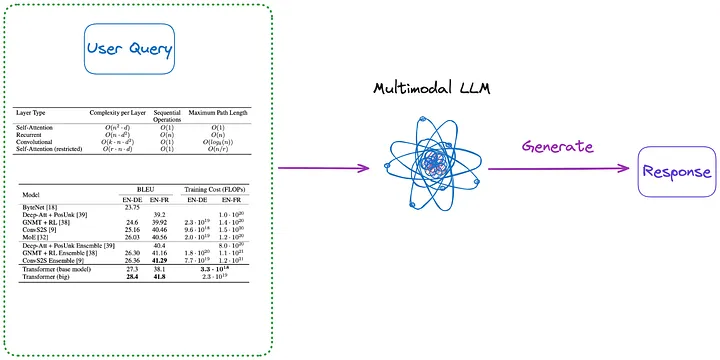
Figure 3 : Catégorie (m) (Note du traducteur : contenu introduit dans le premier paragraphe ci-dessous). Photo fournie par l'auteur original.
(m). Tout d’abord, analysez tous les tableaux du document sous forme d’image en utilisant l’une des méthodes de (a) à (d). Ensuite, toutes les images du tableau et la requête de l'utilisateur sont envoyées directement à un LLM multimodal (tel que GPT-4V, etc.) et la réponse est renvoyée.
- Contenu à indexer : Aucun
- Contenu envoyé au LLM multimodal : Requête + toutes les tables converties au format image
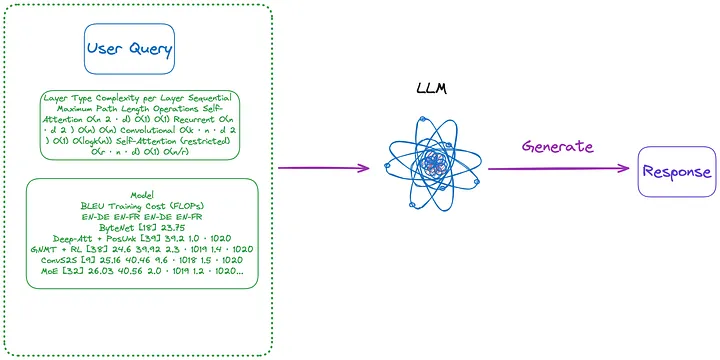
Figure 4 : Catégorie (n) (Note du traducteur : contenu introduit dans le premier paragraphe ci-dessous). Photo fournie par l'auteur original.
(n). Utilisez le tableau au format d'image extrait par la méthode (m), puis utilisez le modèle OCR pour identifier tout le texte du tableau, puis envoyez directement tout le texte du tableau et la requête de l'utilisateur à LLM. , et renvoie directement la réponse.
- Contenu à indexer : Aucun
- Contenu envoyé à LLM : Requête de l'utilisateur + tout le contenu du tableau (envoyé au format texte)
Il est à noter que lors du traitement des tableaux dans les documents, certaines méthodes n'utilisent pas la technologie RAG (Retrieval-Augmented Generation) :
- Le premier type de méthode n'utilise pas LLM, mais s'entraîne sur un ensemble de données spécifique, afin que les modèles d'IA (tels que d'autres modèles de langage basés sur l'architecture Transformer et inspirés de BERT) puissent mieux prendre en charge le traitement des tâches de compréhension de table, telles que TAPAS [8 ].
- Le deuxième type de méthode consiste à utiliser LLM, en utilisant des méthodes de pré-formation, de réglage fin ou d'ingénierie de mots rapides, afin que LLM puisse effectuer des tâches de compréhension de table, telles que GPT4Table [9].
02 Solutions open source existantes pour le traitement des tables
La section précédente a résumé et classé les technologies clés pour le traitement des données tabulaires dans les systèmes RAG. Avant de proposer la solution que nous allons mettre en œuvre dans cet article, explorons quelques solutions open source.
LlamaIndex propose quatre méthodes [10], dont les trois premières utilisent toutes des modèles multimodaux.
- Récupérez l'image de la page PDF pertinente et envoyez-la à GPT-4V en réponse à la requête de l'utilisateur.
- Convertissez chaque page PDF au format image et laissez GPT-4V effectuer un raisonnement d'image sur chaque page. Établissez un index Text Vector Store pour le processus de raisonnement de l'image (Note du traducteur : convertissez les informations textuelles déduites de l'image en forme vectorielle et créez un index), puis utilisez l'Image Reasoning Vector Store (Note du traducteur : il doit s'agir de l'index précédent. , Interrogez l'index Text Vector Store créé précédemment) pour trouver la réponse.
- Utilisez Table Transformer pour recadrer les informations de table à partir des images récupérées, puis envoyez ces images de table recadrées à GPT-4V pour obtenir des réponses à la requête (Remarque du traducteur : envoyez la requête au modèle et obtenez les réponses renvoyées par le modèle).
- Appliquez l'OCR sur l'image du tableau recadrée et envoyez les données à GPT4/GPT-3.5 pour répondre à la requête de l'utilisateur.
Pour résumer les quatre méthodes ci-dessus :
- La première méthode est similaire à la méthode (j) présentée dans cet article et ne nécessite pas d'analyse de table. Mais il s’avère que même si la réponse se trouve juste là dans l’image, elle ne produit pas la bonne réponse.
- La deuxième méthode implique l'analyse de tableaux et correspond à la méthode (a). Le contenu de l'index peut être un contenu tabulaire ou des résumés de contenu, en fonction entièrement des résultats renvoyés par GPT-4V, qui peuvent correspondre à la méthode (f) ou (h). L'inconvénient de cette approche est que la capacité de GPT-4V à identifier les tableaux et à extraire leur contenu des images du document est incohérente, en particulier lorsque l'image du document contient des tableaux, du texte et d'autres images (ce qui est courant dans les documents PDF).
- La troisième méthode est similaire à la méthode (m) et ne nécessite pas d'indexation.
- La quatrième méthode est similaire à la méthode (n) et ne nécessite pas non plus d'indexation. Les résultats ont montré que les mauvaises réponses étaient dues à l’incapacité d’extraire efficacement les informations tabulaires des images.
Grâce à des tests, il a été constaté que la troisième méthode avait le meilleur effet global. Cependant, d'après les tests que j'ai effectués, la troisième méthode avait du mal à détecter le tableau, et encore moins à extraire et associer correctement le titre et le contenu du tableau.
Langchain a également proposé des solutions pour la technologie RAG (Semi-structured RAG) [11] de données semi-structurées. Les technologies de base comprennent :
- Utilisez non structuré pour l'analyse de table, qui est une méthode de classe (c).
- La méthode d'indexation est l'index récapitulatif du document (Note du traducteur : utiliser les informations récapitulatives du document comme contenu d'index), qui appartient à la méthode de classe (i). Le bloc de données correspondant au niveau d'index à granularité fine : contenu récapitulatif de la table, et le bloc de données correspondant au niveau d'index à granularité grossière : contenu de la table d'origine (format texte).
Comme le montre la figure 5 :
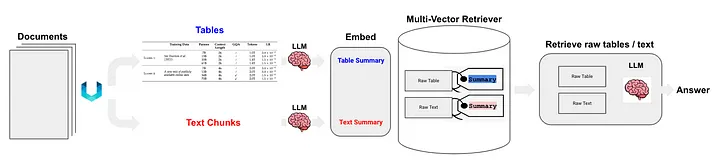
Figure 5 : Solution RAG semi-structurée de Langchain. Source : RAG semi-structuré[11]
RAG semi-structuré et multimodal [12] a proposé trois solutions, dont l'architecture est illustrée dans la figure 6.
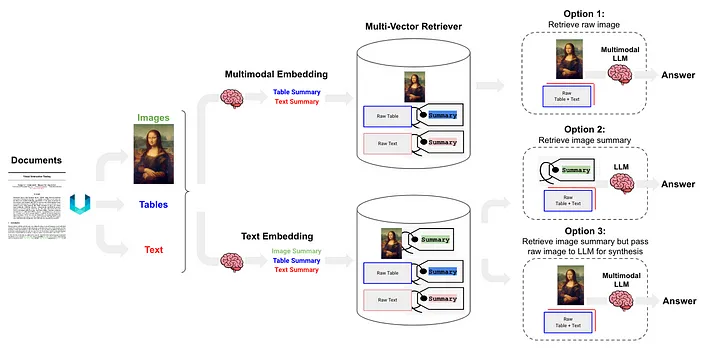
Figure 6 : Schéma RAG semi-structuré et multimodal de Langchain. Source : RAG semi-structuré et multimodal[12].
L’option 1 est similaire à la méthode (l) ci-dessus. Cette approche implique l'utilisation d'intégrations multimodales (telles que CLIP [13]) pour convertir les images et le texte en vecteurs d'intégration, puis l'utilisation d'un algorithme de recherche de similarité pour récupérer les deux et convertir les données d'image et de texte non traitées. Les données d'image et de texte sont transmises au LLM multimodal, leur permettant à traiter ensemble et à générer des réponses aux questions.
L'option 2 utilise un LLM multimodal (tel que GPT-4V[14], LLaVA[15] ou FUYU-8b[16]) pour traiter l'image afin de générer des résumés textuels. Les données textuelles sont ensuite converties en vecteurs d'intégration, et ces vecteurs sont utilisés pour rechercher ou récupérer du contenu textuel qui correspond à la requête posée par l'utilisateur, et transmis au LLM pour générer des réponses.
- Les données du tableau sont analysées à l'aide de la méthode non structurée, qui appartient à la classe (d).
- La méthode d'indexation est l'index récapitulatif du document (Note du traducteur : les informations récapitulatives du document sont utilisées comme contenu d'index), qui appartient à la méthode de classe (i) Le bloc de données correspondant au niveau d'index à granularité fine : le contenu récapitulatif du tableau et les données. bloc correspondant au niveau d'index à gros grain : texte Formater le contenu de la table.
L'option 3 utilise un LLM multimodal (tel que GPT-4V [14], LLaVA [15] ou FUYU-8b [16]) pour générer des résumés textuels à partir de données d'image, puis intégrer ces résumés textuels dans des vecteurs, en utilisant ces vecteurs d'intégration. , Les résumés d'images peuvent être récupérés (récupérer) efficacement. Dans chaque résumé d'image récupéré, une référence correspondante à l'image brute (référence à l'image brute) est conservée. Cela appartient à la méthode (i) ci-dessus. et des blocs de texte sont transmis au LLM multimodal afin de générer des réponses.
03 La solution proposée dans cet article
Les technologies clés et les solutions existantes sont résumées, classées et discutées dans l’article précédent. Sur cette base, nous proposons la solution suivante, comme le montre la figure 7. Par souci de simplicité, certains modules RAG tels que le reclassement et la réécriture de requêtes sont omis de la figure.
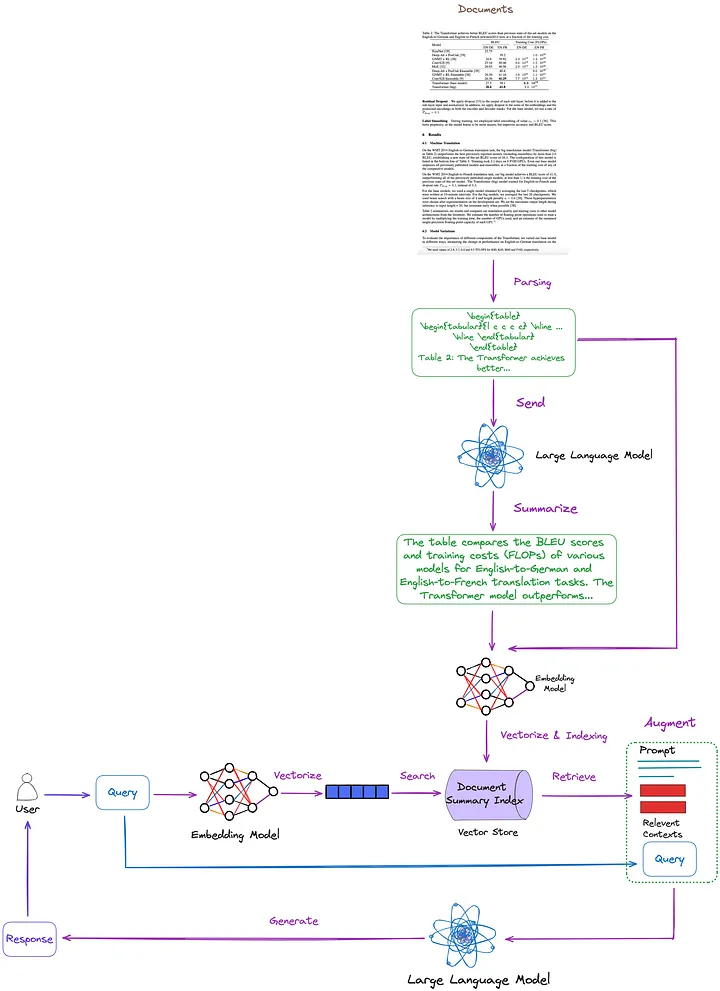
Figure 7 : La solution proposée dans cet article. Photo fournie par l'auteur original.
- Technique d'analyse de table : utilisation de Nougat (méthode de classe (d)). D'après mes tests, les capacités de détection de tables de cet outil sont plus efficaces que celles non structurées (une technique de type (c)). De plus, Nougat peut également très bien extraire les titres des tableaux, ce qui le rend très pratique à associer aux tableaux.
- Structure d'index pour l'indexation et la récupération de résumés de documents (méthodes de classe (i)) : le niveau d'index à granularité fine contient des résumés de contenu tabulaires, et le niveau d'index à granularité grossière contient les tableaux correspondants au format LaTeX et les titres des tableaux au format texte. Nous utilisons un récupérateur multi-vecteurs[17] (Note du traducteur : un récupérateur pour récupérer le contenu d'un index de résumé de document qui peut traiter plusieurs vecteurs en même temps afin de récupérer efficacement les résumés de documents liés à la requête.) pour remplir.
- Comment obtenir un résumé du contenu d'un tableau : Envoyez le tableau et le titre du tableau à LLM pour le résumé du contenu.
L'avantage de cette méthode est qu'elle peut analyser efficacement le tableau et prendre pleinement en compte la relation entre le résumé du tableau et le tableau. Élimine le besoin d’utiliser un LLM multimodal, ce qui entraîne des économies de coûts.
3.1 Comment fonctionne Nougat
Nougat [18] est développé sur la base de l'architecture Donut [19]. Cette approche utilise des algorithmes qui peuvent reconnaître automatiquement le texte de manière implicite sans aucune entrée ou module lié à l'OCR.
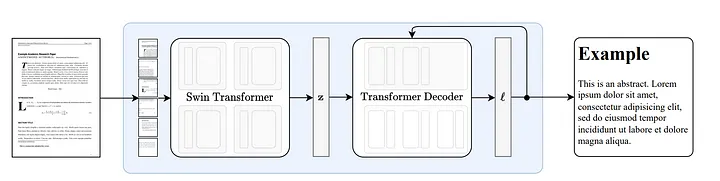
Figure 8 : Architecture de bout en bout selon Donut [19]. L'encodeur Swin Transformer prend une image de document et la convertit en intégrations latentes (Note du traducteur : les informations de l'image sont codées dans un espace latent), puis la convertit en une séquence de jetons de manière autorégressive. Source : Nougat : Compréhension optique neuronale pour les documents académiques.[18]
La capacité de Nougat à analyser des formules est impressionnante[20], mais sa capacité à analyser des tableaux est également exceptionnelle. Comme le montre la figure 9, il peut être associé à des titres de tableaux, ce qui est très pratique :

Figure 9 : Résultats d'exécution de Nougat Le fichier de résultats est au format Mathpix Markdown (peut être ouvert via le plug-in vscode) et le tableau est présenté au format LaTeX.
Lors d'un test que j'ai effectué sur une douzaine d'articles, j'ai constaté que les titres des tableaux étaient toujours fixés à la ligne suivante du tableau. Cette cohérence suggère que ce n’était pas un hasard. Par conséquent, nous sommes plus intéressés par la manière dont Nougat réalise cette fonctionnalité.
Étant donné qu'il s'agit d'un modèle de bout en bout dépourvu de résultats intermédiaires, ses performances dépendront probablement fortement de ses données d'entraînement.
Sur la base de l'analyse du code, l'emplacement et la manière dont la section d'en-tête du tableau est stockée semblent être cohérents avec (et immédiatement \end{table} après caption_parts ) le format organisationnel du tableau dans les données de formation.
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 Avantages et inconvénients du nougat
avantage:
- Nougat peut analyser avec précision les sections difficiles à analyser avec les outils d'analyse précédents, tels que les formules et les tableaux, dans le code source LaTeX.
- Le résultat de l'analyse de Nougat est un document semi-structuré similaire à Markdown.
- Possibilité d'obtenir facilement les titres des tableaux et de les associer facilement aux tableaux.
défaut:
- La vitesse d'analyse de Nougat est lente, ce qui peut entraîner des difficultés dans les applications à grande échelle.
- Étant donné que l'ensemble de données de formation de Nougat est essentiellement constitué d'articles scientifiques, cette technique fonctionne bien sur des documents ayant des structures similaires. Les performances se dégradent lors du traitement de documents texte non latins.
- Le modèle Nougat ne s'entraîne que sur une page d'un article scientifique à la fois et manque de connaissance des autres pages. Cela peut entraîner des incohérences dans le contenu analysé. Par conséquent, si l'effet de reconnaissance n'est pas bon, vous pouvez envisager de diviser le PDF en pages distinctes et de les analyser page par page.
- L'analyse des tableaux dans les articles à deux colonnes n'est pas aussi bonne que dans les articles à une seule colonne.
3.3 Mise en œuvre du code
Tout d’abord, installez les packages Python appropriés :
pip install langchain
pip install chromadb
pip install nougat-ocr
Une fois l'installation terminée, vous devez vérifier la version du package Python :
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
Mettre en place un environnement de travail et importer des packages :
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
Téléchargez l'article « L'attention est tout ce dont vous avez besoin » [21] sur le chemin YOUR_PDF_PATH, exécutez nougat pour analyser le fichier PDF et obtenez les données du tableau au format latex et le titre du tableau au format texte à partir des résultats de l'analyse. La première exécution du programme téléchargera les fichiers de modèle nécessaires dans l'environnement local.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
La fonction june_get_tables_from_mmd est utilisée pour extraire tout le contenu d'un fichier mmd (de \begin{table} à \end{table}, mais incluant également \end{table} la première ligne après), comme le montre la figure 10.

Figure 10 : Résultats d'exécution de Nougat. Le fichier de résultats est au format Mathpix Markdown (peut être ouvert via le plug-in vscode) et le contenu du tableau analysé est au format latex. La fonction de la fonction june_get_tables_from_mmd est d'extraire les informations du tableau dans la case rouge. Photo fournie par l'auteur original.
Cependant, il n'existe aucun document officiel indiquant que le titre du tableau doit être placé sous le tableau, ou que le tableau doit commencer par \begin{table} et se terminer par \end{table}. June_get_tables_from_mmd est donc une méthode heuristique.
Voici les résultats de l'analyse des tableaux du document PDF :
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
Utilisez ensuite LLM pour résumer les données tabulaires :
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
Ce qui suit est un résumé du contenu des quatre tableaux dans « L'attention est tout ce dont vous avez besoin » [21], comme le montre la figure 11 :
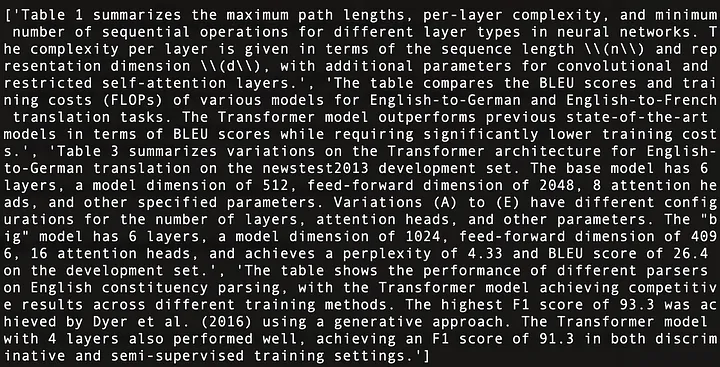
Figure 11 : Résumé du contenu des quatre tableaux dans « L'attention est tout ce dont vous avez besoin » [21].
Utilisez Multi-Vector Retriever (Note du traducteur : un récupérateur pour récupérer le contenu de l'index de résumé de document. Le récupérateur peut traiter plusieurs vecteurs en même temps pour récupérer efficacement les résumés de documents liés à la requête.) Créer une structure d'index de résumé de document [17] (Note du traducteur : une structure d'index utilisée pour stocker des informations récapitulatives sur les documents, et ces informations récapitulatives peuvent être récupérées ou interrogées selon les besoins).
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Une fois que tout est prêt, configurez un simple pipeline RAG et exécutez les requêtes de l'utilisateur :
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
Les résultats en cours sont les suivants. Ces questions ont reçu une réponse précise, comme le montre la figure 12 :

Figure 12 : Réponses à trois requêtes des utilisateurs. La première ligne correspond au tableau 1, la deuxième ligne au tableau 2 et la troisième ligne au tableau 4 dans Attention Is All You Need.
Le code global est le suivant :
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 Conclusion
Cet article discute des technologies clés et des solutions existantes pour les opérations de traitement de tables dans les systèmes RAG et propose une solution et sa mise en œuvre.
Dans cet article, nous avons utilisé Nougat pour analyser des tableaux. Cependant, nous envisagerons de remplacer Nougat si un outil d'analyse plus rapide et plus efficace devient disponible. Notre attitude envers les outils est d'avoir d'abord la bonne idée, puis de trouver les outils pour la mettre en œuvre, plutôt que de nous fier à un outil en particulier.
Dans cet article, nous saisissons tout le contenu de la table dans LLM. Cependant, dans des scénarios réels, nous devons prendre en compte la situation dans laquelle la taille de la table dépasse la longueur du contexte LLM. Nous pouvons résoudre ce problème en utilisant des méthodes de chunking efficaces.
Merci d'avoir lu!
——
Florian Juin
Chercheur en intelligence artificielle, il rédige principalement des articles sur les grands modèles linguistiques, les structures de données et les algorithmes, ainsi que le PNL.
FIN
Les références
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
Cet article a été compilé par Baihai IDP avec l'autorisation de l'auteur original. Si vous devez réimprimer la traduction, veuillez nous contacter pour obtenir une autorisation.
Lien d'origine :
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
Combien de revenus un projet open source inconnu peut-il rapporter ? L'équipe chinoise d'IA de Microsoft a fait ses valises et s'est rendue aux États-Unis, impliquant des centaines de personnes. Huawei a officiellement annoncé que les changements d'emploi de Yu Chengdong étaient cloués au « pilier de la honte FFmpeg » 15 ans. il y a, mais aujourd'hui il doit nous remercier—— Tencent QQ Video venge son humiliation passée ? Le site miroir open source de l'Université des sciences et technologies de Huazhong est officiellement ouvert à l'accès externe : Django est toujours le premier choix pour 74 % des développeurs. L'éditeur Zed a progressé dans la prise en charge de Linux. Un ancien employé d'une société open source bien connue . a annoncé la nouvelle : après avoir été interpellé par un subordonné, le responsable technique est devenu furieux et impoli, et a été licencié et enceinte. Une employée d'Alibaba Cloud publie officiellement Tongyi Qianwen 2.5 Microsoft fait un don d'un million de dollars à la Fondation Rust.