
Apprenez à visualiser l'utilisation de la mémoire des connexions MySQL.
Auteur : Benjamin Dicken
Source de cet article et couverture : https://planetscale.com/blog/, traduit par la communauté open source Axon.
Cet article compte environ 3 000 mots et sa lecture devrait prendre 10 minutes.
introduction
Lorsque l’on considère les performances de n’importe quel logiciel, il existe un compromis typique entre le temps et l’espace. Dans le processus d'évaluation des performances des requêtes MySQL, nous nous concentrons souvent sur le temps d'exécution (ou la latence des requêtes) comme principal indicateur des performances des requêtes. Il s'agit d'une bonne mesure à utiliser car, en fin de compte, nous souhaitons obtenir les résultats des requêtes le plus rapidement possible.
J'ai récemment publié un article de blog sur Comment identifier et analyser les requêtes MySQL problématiques , qui se concentrait sur la mesure des mauvaises performances en termes de temps d'exécution et de lectures de lignes. Cependant, la consommation de mémoire a été largement ignorée dans cette discussion.
Bien que cela ne soit pas souvent nécessaire, MySQL dispose également de mécanismes intégrés pour donner un aperçu de la quantité de mémoire utilisée par les requêtes et de l'utilisation de cette mémoire. Examinons cette fonctionnalité et voyons comment vous pouvez surveiller l'utilisation de la mémoire des connexions MySQL en temps réel.
Statistiques de mémoire
Dans MySQL, de nombreux composants du système peuvent être instrumentés individuellement. Le performance_schema.setup_instrumentstableau répertorie chaque composant, et il y en a plusieurs :
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
Ce tableau contient de nombreux outils pouvant être utilisés pour l'analyse de la mémoire. Pour voir ce qui est disponible, essayez de sélectionner dans le tableau et de filtrer par memory/.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
Vous devriez voir des centaines de résultats. Chacun d'eux représente une catégorie différente de mémoire et peut être détecté individuellement dans MySQL. Certaines de ces catégories incluent un court paragraphe documentationdécrivant ce que cette catégorie de mémoire représente ou à quoi elle est utilisée. Si vous souhaitez uniquement voir les types de mémoire avec des valeurs non nulles documentation, vous pouvez exécuter :
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
Chacune de ces classes de mémoire peut être échantillonnée à plusieurs granularités différentes. Différents niveaux de granularité sont stockés dans plusieurs tables :
SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- memory_summary_by_account_by_event_name : résumer les événements de mémoire par compte (le compte est une combinaison d'utilisateur et d'hôte)
- memory_summary_by_host_by_event_name : résume les événements de mémoire à la granularité de l'hôte
- memory_summary_by_thread_by_event_name : résumer les événements de mémoire avec la granularité des threads MySQL
- memory_summary_by_user_by_event_name : résumer les événements de mémoire selon la granularité de l'utilisateur
- memory_summary_global_by_event_name : résumé global des statistiques de mémoire
Notez qu'il n'existe pas de suivi spécifique de l'utilisation de la mémoire à chaque niveau de requête. Cependant, cela ne signifie pas que nous ne pouvons pas analyser l’utilisation de la mémoire de nos requêtes ! Pour y parvenir, nous pouvons surveiller l'utilisation de la mémoire sur n'importe quelle connexion qui exécute la requête qui nous intéresse. Par conséquent, nous nous concentrerons sur l’utilisation des tables memory_summary_by_thread_by_event_namecar il existe un mappage pratique entre les connexions MySQL et les threads.
Trouver le but de la connexion
À ce stade, vous devez configurer deux connexions distinctes au serveur MySQL sur la ligne de commande. La première est la requête qui exécute la requête pour laquelle vous souhaitez surveiller l’utilisation de la mémoire. Le second sera utilisé à des fins de surveillance.
Lors de la première connexion, exécutez ces requêtes pour obtenir l'ID de connexion et l'ID de thread.
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
Ensuite, obtenez ces valeurs. Bien sûr, le vôtre peut être différent de celui que vous voyez ici.
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
Ensuite, exécutez des requêtes de longue durée pour lesquelles vous souhaitez analyser l'utilisation de la mémoire. Pour cet exemple, je vais effectuer une opération volumineuse à partir d'une table de 100 millions de lignes, ce qui devrait prendre un certain temps car aliasil n'y a pas d'index sur la colonne SELECT :
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
Maintenant, pendant l'exécution, passez à une autre connexion de console et exécutez la commande suivante, en remplaçant l'ID de thread par l'ID de thread de votre connexion :
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
Vous devriez voir des résultats similaires à celui-ci, bien que les détails dépendent fortement de votre requête et de vos données :
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
Cela indique la quantité de mémoire utilisée par chaque catégorie lors de l'exécution de cette requête. Si vous SELECT alias...exécutez cette requête plusieurs fois lors de l'exécution d'une autre requête, vous risquez d'obtenir des résultats différents, car l'utilisation de la mémoire par la requête n'est pas nécessairement constante tout au long de son exécution. Chaque exécution de cette requête représente un échantillon à un moment donné. Ainsi, si nous voulons comprendre comment l’utilisation évolue au fil du temps, nous devons prélever de nombreux échantillons.
memory/sql/Filesort_buffer::sort_keysdocumentationest absent du tableau performance_schema.setup_instruments.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
Cependant, le nom indique qu'il s'agit de la mémoire utilisée pour trier les données du fichier. Cela est logique puisque la majeure partie du coût de cette requête consistera à trier les données afin qu'elles puissent être affichées par ordre décroissant.
Recueillir l'utilisation au fil du temps
Ensuite, nous devons être capables d’échantillonner l’utilisation de la mémoire au fil du temps. Cela ne sera pas très utile pour les requêtes courtes, car nous ne pouvons exécuter cette requête qu'une seule fois, ou un petit nombre de fois lors de l'exécution de la requête analytique. Ceci est plus utile pour les requêtes à exécution plus longue (requêtes qui prennent des secondes ou des minutes). Quoi qu'il en soit, ce sont les types de requêtes que nous souhaitons analyser, car ces requêtes sont susceptibles d'utiliser la majeure partie de la mémoire.
Cela peut être entièrement implémenté en SQL et appelé via des procédures stockées. Cependant, dans ce cas, nous utilisons un script distinct en Python pour assurer la surveillance.
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
Il s'agit d'une simple première tentative de ce type de script de surveillance. En résumé, ce code fait ce qui suit :
- Obtenez l'ID de thread fourni à surveiller via la ligne de commande
- Configurer une connexion à la base de données MySQL
- Exécutez une requête toutes les 250 ms pour obtenir les 4 catégories de mémoire les plus utilisées et imprimer la lecture
Cela peut être adapté de différentes manières en fonction de vos besoins d’analyse. Par exemple, ajustez la fréquence des pings vers le serveur ou modifiez le nombre de classes de mémoire répertoriées par itération. L'exécution de cette commande lors de l'exécution d'une requête fournit les résultats suivants :
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
C'est génial, mais il a quelques faiblesses. C'est bien de voir quelque chose au-delà des 4 premières catégories d'utilisation de la mémoire, mais augmenter ce nombre augmentera la taille de ce vidage de sortie déjà volumineux. Ce serait bien s'il existait un moyen plus simple de comprendre l'utilisation de la mémoire en un coup d'œil avec une visualisation. Cela peut être fait en demandant au script de vider les résultats au format CSV ou JSON, puis de les charger dans le visualiseur. Mieux encore, nous pouvons tracer les résultats en temps réel au fur et à mesure que les données arrivent. Cela fournit une vue mise à jour et nous permet d'observer l'utilisation de la mémoire telle qu'elle se produit en temps réel, le tout dans un seul outil.
Tracer l'utilisation de la mémoire
Afin de rendre l'outil plus utile et de fournir une visualisation, certaines modifications seront apportées.
- L'utilisateur fournira l'ID de connexion sur la ligne de commande et le script se chargera de trouver le thread sous-jacent.
- La fréquence à laquelle le script demande des données en mémoire peut également être configurée via la ligne de commande.
- Cette
matplotlibbibliothèque sera utilisée pour générer des visualisations de l'utilisation de la mémoire. Celui-ci contiendra un tracé de pile avec une légende indiquant la catégorie d'utilisation de mémoire la plus élevée et conservera les 50 derniers échantillons.
Cela représente beaucoup de code, mais il est inclus ici par souci d'exhaustivité.
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
Avec cela, nous pouvons effectuer une surveillance détaillée de l’exécution des requêtes MySQL. Pour l'utiliser, récupérez d'abord l'ID de connexion de la connexion que vous souhaitez analyser :
SELECT CONNECTION_ID();
Ensuite, l'exécution de la commande suivante démarrera la session de surveillance :
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
Lors de l'exécution de requêtes sur la base de données, nous pouvons observer l'augmentation de l'utilisation de la mémoire et voir quelles catégories contribuent le plus à la mémoire.
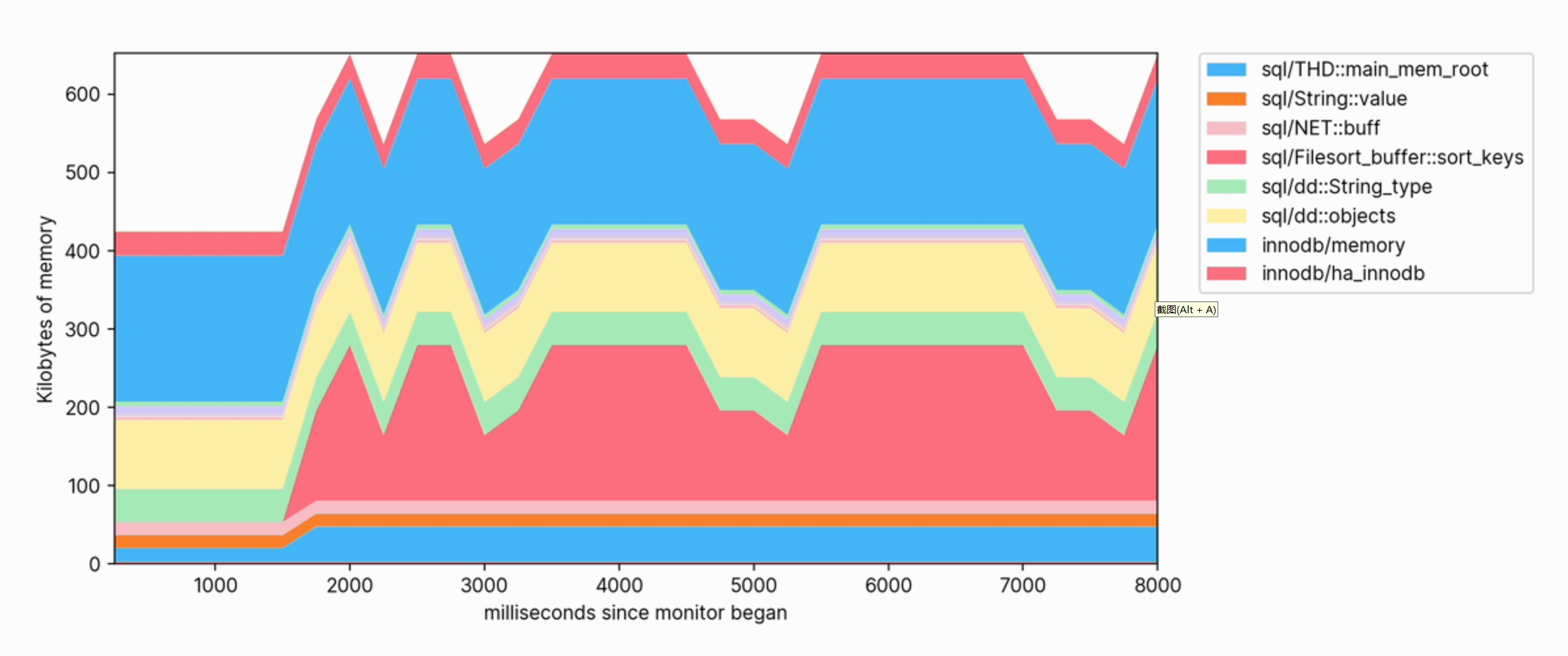
Cette visualisation nous aide également à voir clairement quelles opérations consomment de la mémoire. Par exemple, ce qui suit est un extrait du profil de mémoire utilisé pour créer un index FULLTEXT sur une grande table :
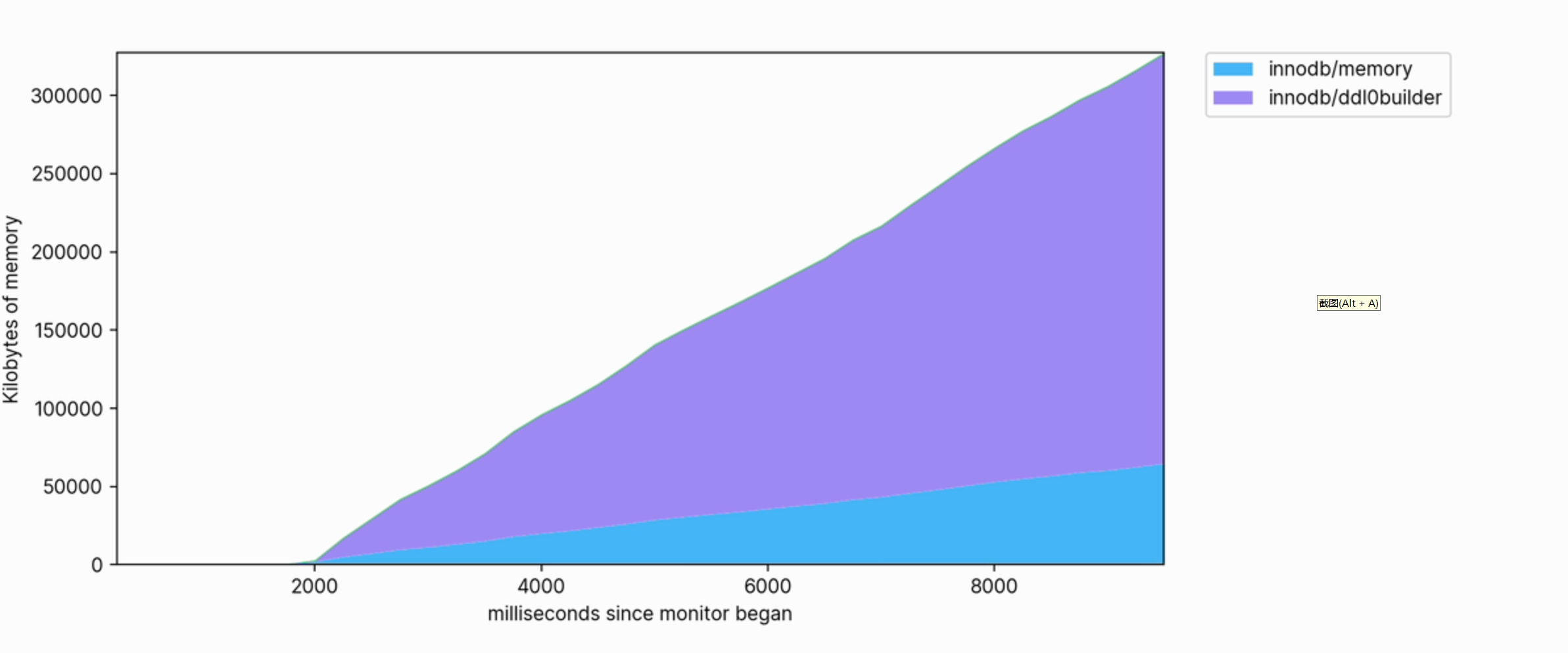
L'utilisation de la mémoire est importante et continue de croître pour atteindre des centaines de mégaoctets lors de son exécution.
en conclusion
Même si cela n'est pas souvent nécessaire, la possibilité d'obtenir des informations détaillées sur l'utilisation de la mémoire peut s'avérer extrêmement précieuse lorsqu'une optimisation détaillée des requêtes est requise. Cela peut révéler quand et pourquoi MySQL exerce une pression sur la mémoire du système, ou si une mise à niveau de mémoire est nécessaire sur le serveur de base de données. MySQL fournit de nombreuses primitives sur la base desquelles vous pouvez développer des outils analytiques pour vos requêtes et charges de travail.
Pour des articles plus techniques, veuillez visiter : https://opensource.actionsky.com/
À propos de SQLE
SQLE est une plateforme complète de gestion de la qualité SQL qui couvre l'audit et la gestion SQL, du développement aux environnements de production. Il prend en charge les bases de données open source, commerciales et nationales grand public, fournit des capacités d'automatisation des processus pour le développement, l'exploitation et la maintenance, améliore l'efficacité en ligne et améliore la qualité des données.
SQLE obtenir
| taper | adresse |
|---|---|
| Dépôt | https://github.com/actiontech/sqle |
| document | https://actiontech.github.io/sqle-docs/ |
| publier des nouvelles | https://github.com/actiontech/sqle/releases |
| Documentation de développement du plug-in d'audit des données | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |