
01 Aperçu du contexte
Dans le scénario où des données de séries chronologiques sont écrites dans la base de données, en raison de problèmes tels que des retards de réseau, il peut arriver que l'horodatage des données à écrire soit inférieur à l'horodatage maximum des données écrites. les données sont collectivement appelées données dans le désordre. La génération de données dans le désordre est presque inévitable. Dans le même temps, l'écriture de données dans le désordre affectera le tri et l'interrogation de toutes les données. Par conséquent, nous devons prendre en charge l'écriture de données dans le désordre. commander des données et prendre également en charge la requête de données en panne.
02 Aperçu du processus
Lors du traitement des données dans le désordre, les données dans le désordre dans une fenêtre de temps spécifiée (telle que 10 minutes ou 1 heure) seront traitées selon la stratégie de déduplication et stockées, et les données dans le désordre en dehors du temps la fenêtre sera supprimée. La figure suivante représente le processus de base d'écriture de données dans le désordre :

Parmi eux, 3 points clés doivent être clarifiés :
- La fenêtre temporelle fait référence à une période de temps précédant le point temporel du dernier horodatage des données dans la table. Lorsqu'aucune nouvelle donnée n'est écrite dans la table, sa fenêtre temporelle ne change pas.
- Il y a un paramètre dans le fichier de configuration : ts_st_iot_disorder_interval, qui est utilisé pour prendre en charge la fenêtre de temps d'écriture des données dans le désordre, unité : secondes. La valeur de cet élément de configuration ne peut pas dépasser la valeur de l'intervalle de partition.
- La base pour juger si les données sont en désordre est que l'horodatage des données écrites est inférieur ou égal à l'horodatage maximum de toutes les données stockées dans l'objet table écrit.
03 Exemple de scénario
1. Processus d'écriture normal
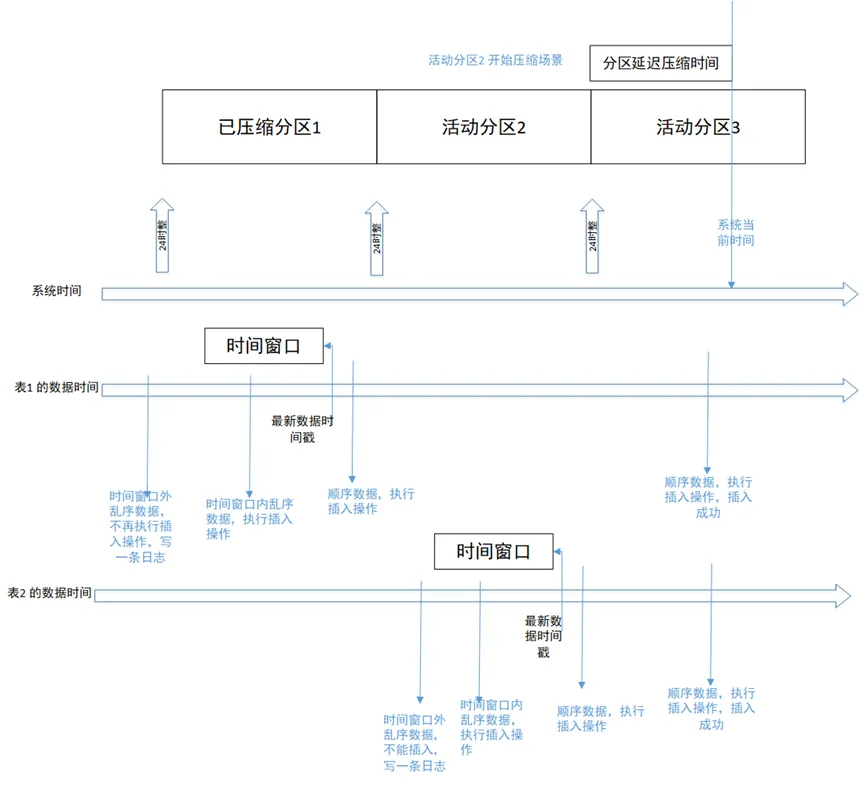
L'heure est divisée en deux lignes : l'heure du système et l'heure des données. L'heure des données est différente pour chaque table, elle est donc divisée en deux lignes : l'heure des données du tableau 1 et l'heure des données du tableau 2.
-
Scénario 1 : Le scénario d'écriture séquentielle des données il y a deux jours est tel qu'illustré dans la figure ci-dessus. Le scénario du tableau 1 écriture séquentielle sur la partition historique 1. Les données séquentielles écrites seront stockées dans la partition correspondante. la partition échoue et se lance mal.
-
Scénario 2 : écriture de données dans le désordre dans la fenêtre de temps Comme le montre la figure ci-dessus, le tableau 2 écrit des données dans le désordre dans la fenêtre de temps. Les données écrites seront stockées dans la partition active 2, qui est en cours de traitement. dans un autre thread de compression de partition, les opérations d'écriture réussiront également.
-
Scénario 3 : écriture de données dans le désordre qui dépassent la fenêtre horaire Lorsque la base de données active la fonction de compression et configure la fenêtre horaire dans le désordre sur 1 heure, écriture des données dans le désordre qui sont 1 heure plus tôt. que le dernier horodatage d'enregistrement dans la table échouera. Les données écrites seront filtrées et écrites dans le journal.
2. Processus d'importation des données
Il peut également y avoir des données dans le désordre dans les données importées. Dans ce scénario, le traitement des données dans le désordre est cohérent avec le processus d'écriture normal.
-
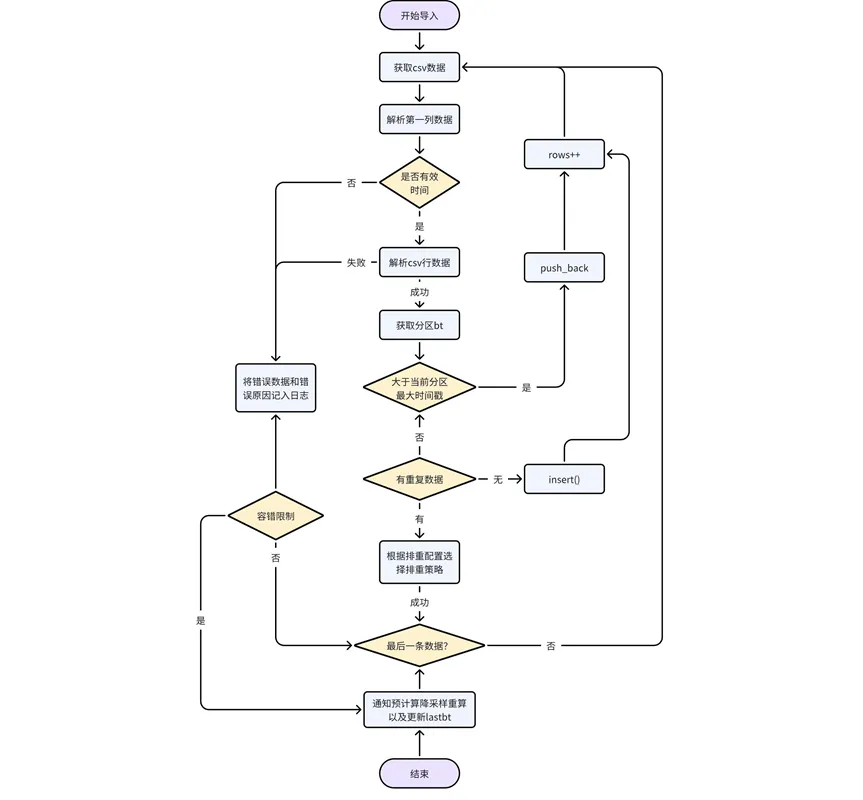
Traitement des données elles-mêmes : analyser les données du fichier CSV ligne par ligne, déterminer si la première colonne de données est d'un type d'horodatage valide et renvoyer une erreur si ce n'est pas le cas, déterminer la partition à utiliser ; à laquelle appartiennent les données, et obtenez la partition bt. Si l'horodatage des données est supérieur à l'horodatage maximum des données existantes dans la partition actuelle, repoussez-les directement ; sinon, les données dans le désordre doivent être traitées selon la logique de configuration de la déduplication.
-
Adapter la logique de sous-échantillonnage et de pré-calcul : pendant le processus d'importation des données, vous devez mettre à jour le statut d'enregistrement de l'URL dans la table des tâches système kaiwudb_jobs pour qu'il expire une fois l'importation terminée, notifier le pré-calcul/sous-échantillonnage, recalculer/traiter les données impliquées, ou attendre l'étape suivante. Une tâche de précalcul est recalculée lorsqu'elle est planifiée par le système.
Une fois l'importation terminée, le précalcul et le sous-échantillonnage sont informés de recalculer ou de mettre à jour les résultats, ainsi que de mettre à jour le dernier résultat.
3. Processus de sous-échantillonnage
Une fois les données dans le désordre écrites, les résultats du sous-échantillonnage doivent être mis à jour en fonction des dernières données.

-
Traitement des données dans le désordre importées dans des partitions historiques : lors de l'importation de données dans le désordre appartenant à des partitions historiques, mettez à jour le statut d'enregistrement de url=[database/partition/table_name] dans la table des tâches système kaiwudb_jobs pour qu'il soit expiré, et la table de partition sera ensuite téléchargée à nouveau en conséquence.
-
Traiter l'insertion et l'écriture des données de partition historique : lors de la décompression de la partition historique de la table de données d'insertion, mettez à jour l'état de l'enregistrement de url=[database/partition/table_name] dans la table des tâches système kaiwudb_jobs pour qu'il expire, et la table de partition sera re- correspondait dans le futur. Traitement des règles de sous-échantillonnage.
4. Une fois les données dans le désordre écrites dans le processus de précalcul, les résultats du précalcul doivent être mis à jour en fonction des données les plus récentes.
-
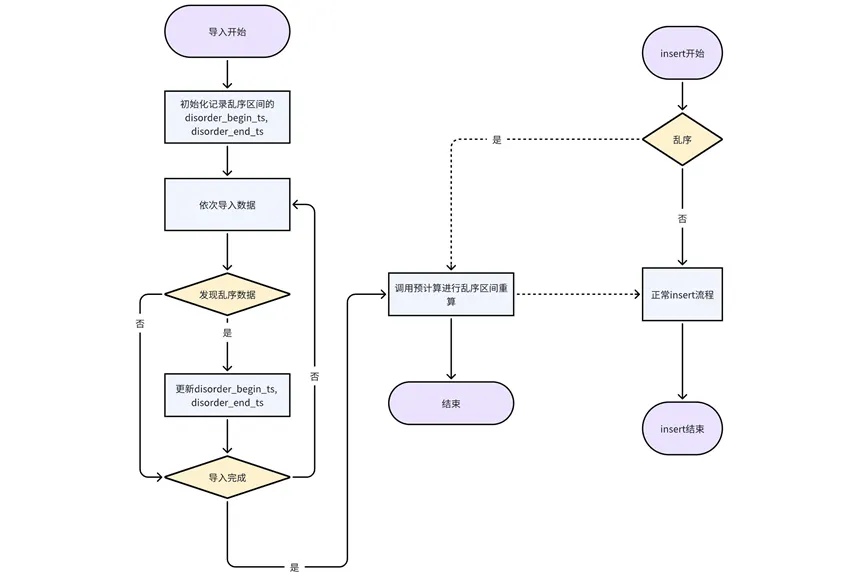
Traiter l'insertion et écrire des données dans le désordre : insérer chaque fois qu'une donnée dans le désordre apparaît dans l'insertion. Cette approche peut garantir dans une plus grande mesure l'exactitude des résultats du précalcul.
-
Traitement des données importées dans le désordre : L'importation est actuellement traitée en unités de tables de partition. Lors du processus d'importation de chaque table de partition, l'horodatage de début et l'horodatage de fin dans le désordre sont enregistrés après l'importation du courant. La table de partition est terminée, l'interface de pré-calcul est appelée pour le recalcul.
04 Résumé
Dans le scénario d'un traitement de données dans le désordre, de nombreuses fonctions et modules de liaison sont impliqués, qui doivent être synchronisés et mis à jour. Lorsque la base de données traite complètement les données dans le désordre, elle peut mieux s'adapter aux scénarios commerciaux des utilisateurs et améliorer considérablement l'applicabilité de la base de données dans plusieurs scénarios.
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.