
À l’ère du numérique, les données constituent l’un des actifs les plus précieux d’une entreprise. Cependant, à mesure que la quantité de données augmente, la complexité de la gestion des bases de données augmente également. Une défaillance de base de données peut entraîner une interruption des activités et entraîner d’énormes pertes financières et de réputation pour l’entreprise. Dans ce blog, nous partagerons comment KaiwuDB conçoit des outils de diagnostic de pannes et des exemples de démonstrations spécifiques.
01 Idées de conception
Suivre les principes fondamentaux
- Convivial : même les utilisateurs ayant des niveaux de compétence différents peuvent facilement utiliser nos outils ;
- Surveillance complète : Surveillance complète de tous les aspects du système de base de données, y compris les indicateurs de performance, les ressources système et l'efficacité des requêtes ;
- Diagnostics intelligents : utilise des algorithmes avancés pour identifier la cause première des problèmes ;
- Réparations automatisées : fournit des suggestions de réparation en un clic et, si possible, applique automatiquement ces réparations ;
- Extensibilité : permet aux utilisateurs d'étendre et de personnaliser les fonctionnalités de l'outil en fonction de leurs besoins spécifiques.
Soutenir la collecte d’indicateurs clés
Pour garantir un diagnostic complet, l'outil collectera une série d'indicateurs clés, notamment, mais sans s'y limiter :
- Configuration du système : version de la base de données, système d'exploitation, architecture et numéro du processeur, capacité de la mémoire, type et capacité du disque, point de montage, type de système de fichiers ;
- Situation de déploiement : qu'il s'agisse d'un déploiement nu ou en conteneur, le mode de déploiement et le nombre de nœuds de l'instance de base de données ; l'organisation des données : la structure du répertoire de données, la configuration locale et en cluster, les tables et paramètres système ;
- Statistiques des bases de données : nombre de bases de données métiers, nombre de tables sous chaque base de données et structure des tables ;
- Caractéristiques des colonnes : caractéristiques statistiques des colonnes numériques et des colonnes d'énumération, détection de la longueur et des caractères spéciaux des colonnes de chaînes ;
- Fichiers journaux : journal des relations, journal de synchronisation, journal des erreurs, journal d'audit ;
- Informations PID : le nombre de descripteurs ouverts par le processus de base de données, le nombre de MMAP ouverts, les statistiques et autres informations ;
- Données de performances : plan d'exécution SQL, données de surveillance du système (CPU, mémoire, E/S), utilisation et efficacité des index, modèles d'accès aux données, verrous (conflits de transactions et événements d'attente), événements système, etc.
Prend en charge différents modes de fonctionnement
L'outil proposera deux modes de fonctionnement pour répondre aux besoins de différents scénarios :
- Collecte unique : capturez rapidement l'état actuel du système et les données de performances, adaptées au diagnostic immédiat des problèmes ;
- Collecte planifiée : collectez périodiquement des données selon un plan prédéfini pour la surveillance des performances à long terme et l'analyse des tendances.
S'adapter à diverses analyses de tendances
Les données collectées seront utilisées pour effectuer une analyse des tendances, avec des fonctionnalités telles que :
- Tendances des performances : identifiez les tendances des performances des bases de données au fil du temps et prédisez les goulots d'étranglement potentiels en matière de performances ;
- Utilisation des ressources : suivez l'utilisation des ressources du système et aidez à optimiser l'allocation des ressources ;
- Analyse des journaux : analysez les fichiers journaux pour identifier les modèles anormaux et les erreurs fréquentes ;
- Optimisation des requêtes : fournir des suggestions d'optimisation des requêtes en analysant les plans d'exécution SQL ;
- Meilleures pratiques : fournissez des recommandations de configuration optimales grâce à une analyse complète de la distribution des données et des ressources matérielles.
02 Architecture globale
L'outil de diagnostic des pannes est divisé en deux parties : collecte et analyse :
- La partie collecte est connectée au système d'exploitation/base de données/serveur de surveillance cible, prend en charge l'analyse simplifiée des règles locales et génère des rapports en texte brut ;
- La partie analyse lit et formate les données collectées et les télécharge sur le serveur d'analyse pour assurer leur persistance. Elle prend en charge l'analyse détaillée et la prédiction des règles en ligne et génère des rapports détaillés via l'interface utilisateur.
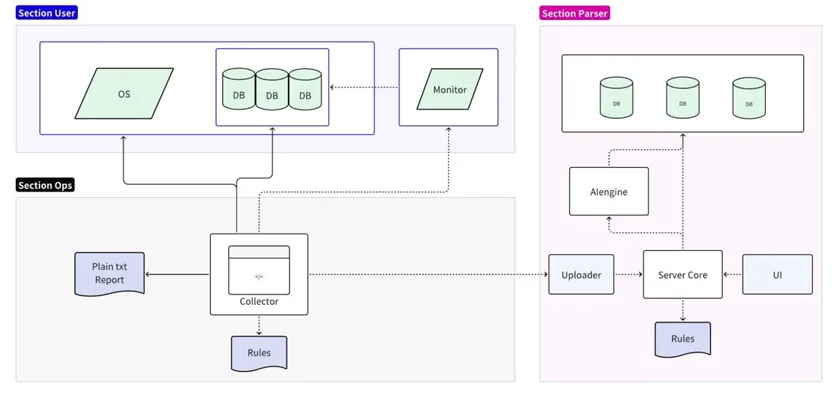
Implémentation du collecteur
Le collecteur est un outil utilisé directement par le personnel d'exploitation et de maintenance sur site. Il obtient diverses informations originales sur site grâce au système d'exploitation, à la base de données et aux services de surveillance. Par défaut, la compression et l'exportation directe après la collecte sont prises en charge. Vous pouvez également utiliser des règles locales pour effectuer l'analyse la plus élémentaire, comme rechercher et imprimer tous les messages d'erreur.

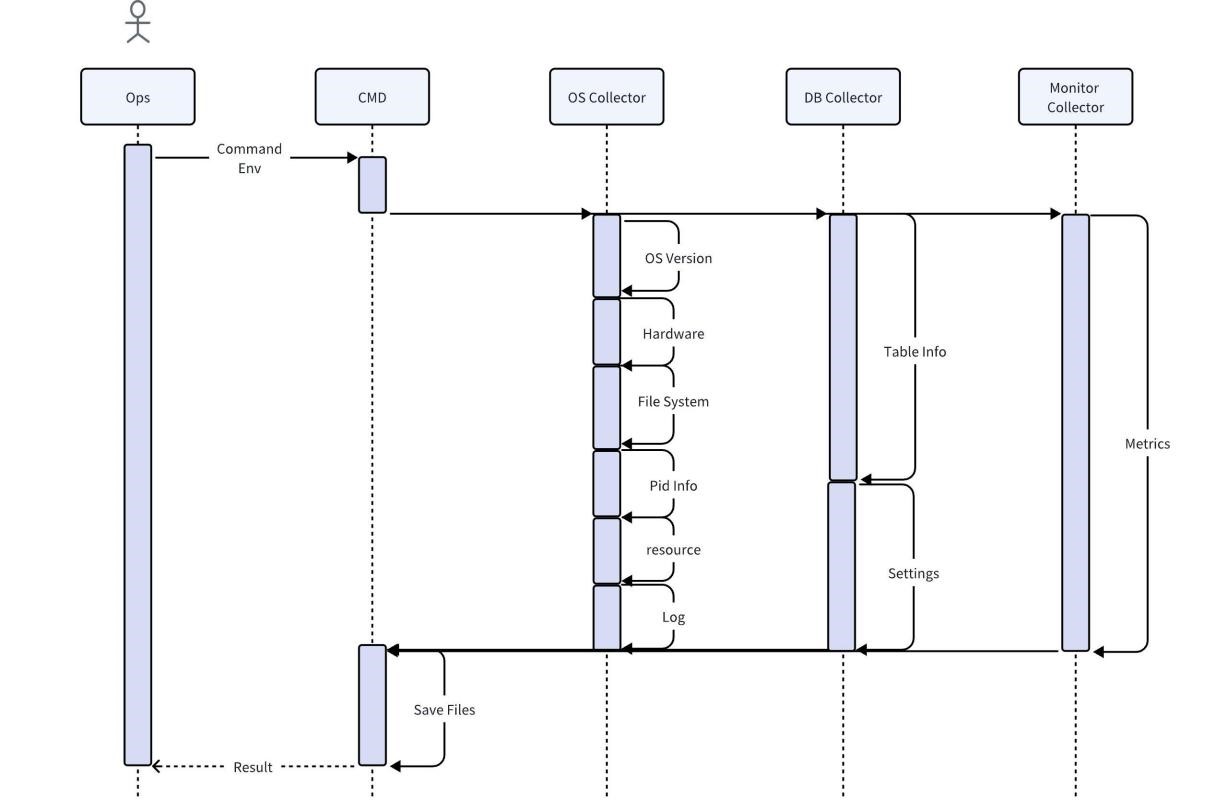
Étant donné que la collecte directe des données commerciales des utilisateurs peut entraîner le risque d'exposer les informations des utilisateurs, pendant le processus de collecte du collecteur de base de données, seules les caractéristiques des données de l'utilisateur seront capturées et aucune donnée ne sera copiée. Afin de garantir l'exhaustivité et l'exactitude des autres données, les données collectées ne seront en aucun cas traitées avant analyse, et les données nécessaires seront conservées pour fournir des informations complètes. Pour économiser de l'espace, les données collectées doivent être compressées. Dans le même temps, le collecteur doit être compatible avec la plupart des systèmes d'exploitation et ne nécessiter aucune dépendance supplémentaire.
Implémentation du moteur de règles
Pour l'analyse ultérieure des données, le moteur de règles doit être compatible avec le collecteur de données afin de fournir une sortie de données standardisée et avoir une certaine évolutivité. Par exemple, pour analyser l'augmentation de l'utilisation du processeur lorsqu'un SQL spécifique est exécuté, il est nécessaire d'afficher les métadonnées de la requête SQL (telles que le texte SQL, le temps d'exécution, etc.) et les indicateurs de performances (tels que l'utilisation du processeur) dans le format du moteur de chronométrage afin d'analyser les goulots d'étranglement des performances.
Afin de fournir une évolutivité suffisante et de pouvoir couvrir un ensemble de règles en constante expansion, y compris des problèmes fonctionnels tels que la vérification des codes d'erreur, le moteur de règles lit les règles à partir de fichiers externes, puis applique ces règles pour analyser les données. Voici quelques exemples de code :
Python
import pandas as pd
import json
# 加载规则
def load\_rules(rule\_file):
with open(rule_file, 'r') as file:
return json.load(file)
# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold):
# 比较当前行的CPU使用率是否超过阈值
return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold
# 应用规则
def apply\_rules(data, rules\_config, custom_rules):
for rule in rules_config:
data\[rule\['name'\]\] = data.eval(rule\['expression'\])
for rule\_name, custom\_rule in custom_rules.items():
data\[rule\_name\] = data.apply(custom\_rule, axis=1)
return data
# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')
# 加载规则
rules\_config = load\_rules('rules.json')
# 定义自定义规则
custom_rules = {
'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}
# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)
# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
Les fichiers de règles doivent être continuellement étendus avec des itérations de version et prendre en charge les mises à jour à chaud. Voici un exemple de fichier de configuration de règles au format JSON. Les règles sont définies sous forme d'objets JSON, chacun contenant un nom et une expression comprise par le Pandas DataFrame.
JSON
\[
{
"name": "high\_execution\_time",
"expression": "execution_time > 5"
},
{
"name": "general\_high\_cpu_usage",
"expression": "cpu_usage > 80"
},
{
"name": "slow_query",
"expression": "query_time > 5"
},
{
"name": "error\_code\_check",
"expression": "error_code not in \[0, 200, 404\]"
}
// 其他规则可以在此添加
\]
Prédiction réalisée
Les outils de diagnostic peuvent être connectés aux moteurs de prédiction pour détecter à l’avance les risques potentiels. L'exemple suivant utilise le classificateur d'arbre de décision scikit-learn pour entraîner un modèle et utilise le modèle pour effectuer des prédictions :
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score
# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')
# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到
# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]
# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X\_train, y\_train)
# 预测测试集
y\_pred = model.predict(X\_test)
# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')
# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')
# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time):
model = joblib.load('performance\_predictor\_model.joblib')
prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\])
return 'Issue' if prediction\[0\] == 1 else 'No issue'
# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 Exemple de démonstration
Scénario hypothétique : Vous êtes un expert en informatique dans une entreprise de l'Internet des objets. Vous constatez que le temps de réponse aux requêtes de la base de données de séries chronologiques pour le traitement des données sur l'état des appareils est très lent à certaines périodes. Comment pouvez-vous gérer cela ?
collecte de données
L'outil de diagnostic de base de données que vous utilisez commence à collecter les données suivantes :
1. Journal des requêtes : une requête apparaît fréquemment et le temps d'exécution est beaucoup plus long que les autres requêtes.
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2. Plan d'exécution : Le plan d'exécution de cette requête montre que ce SQL analysera la table entière puis filtrera le device_id.
3. Utilisation de l'index : le device_id sur la table device_readings n'a pas d'index TAG.
4. Utilisation des ressources : pic du processeur et des E/S lors de l'exécution de cette requête.
5. Événements de verrouillage et d'attente : aucun événement de verrouillage anormal n'a été trouvé.
Analyse et reconnaissance de formes
Les outils de diagnostic analysent les requêtes et les plans d'exécution pour identifier les modèles suivants :
- Des analyses fréquentes de tables complètes entraînent une augmentation des charges d'E/S et de CPU ;
- Sans index appropriés, les requêtes ne peuvent pas localiser efficacement les données.
Diagnostic du problème
L'outil utilise des règles intégrées qui correspondent au diagnostic suivant : L'inefficacité des requêtes est causée par un manque d'index appropriés.
Génération de suggestions
Sur la base de ce modèle, l'outil de diagnostic génère la recommandation suivante : Créez un index TAG sur le champ device_id de la table device_readings.
Mettre en œuvre les recommandations
L'administrateur de base de données exécute l'instruction SQL suivante pour créer l'index :
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
Résultats de validation
Une fois l'index créé, l'outil de diagnostic de base de données a collecté à nouveau les données et a découvert :
- Le temps d'exécution de cette requête particulière a été considérablement réduit ;
- Les charges du processeur et des E/S chutent à des niveaux normaux pendant l'exécution de la requête ;
- Le temps de chargement des pages du catalogue produits du site Internet est revenu à la normale.
Description de l'algorithme
Dans cet exemple, l'outil de diagnostic utilise l'algorithme et la logique suivants :
- Reconnaissance de formes : détecter la fréquence des requêtes et le temps d'exécution ;
- Analyse de corrélation : corrélez les requêtes à long temps d'exécution avec les plans d'exécution et l'utilisation de l'index ;
- Arbre de décision ou moteur de règles : Si une analyse complète de la table est trouvée et que le champ correspondant n'a pas d'index, il est recommandé de créer un index ;
- Surveillance des changements de performances : après avoir créé l'index, surveillez l'amélioration des performances pour déterminer l'efficacité des recommandations.