Construire et maintenir un moteur de recherche de niveau milliard n’est pas facile, et il n’existe pas de méthode de gestion optimale une fois pour toutes. Cet article est le résultat d'un apprentissage continu et d'une synthèse pratique.Il présente comment créer un système de recherche capable de prendre en charge des produits allant de dizaines de millions à des centaines de millions, de réaliser une augmentation du QPS total des requêtes de centaines à des milliers, et d'écrire. le QPS total Le processus d'augmentation du niveau 100 au niveau 10 000. Parmi eux, l'expansion des ressources ES est essentielle, mais en outre, cet article se concentrera également sur certains problèmes de performances ES qui ne peuvent pas être résolus par l'expansion. J'espère que grâce à cet article, vous pourrez obtenir plus de données et de références d'utilisation pour les scénarios d'utilisation d'ES. En raison de l'espace limité, la partie sur la gouvernance de la stabilité sera introduite dans le prochain article.
Présentation de l'entreprise
Le système de gestion des investissements de la plateforme sert le scénario d'investissement multi-entités des activités de la plateforme de commerce électronique Douyin. Il collectera et sélectionnera les produits via la plateforme d'investissement, puis distribuera les produits à divers systèmes C-end. Les entités qui attirent les investissements sont également très diverses, notamment les salles de diffusion en direct, les investissements dans les produits, les investissements dans les coupons, etc. Parmi elles, l'investissement dans les produits est notre plus grande entité d'investissement.
Structure des services de la plateforme d'investissement
centre de données
Le centre de données est un service de recherche basé sur ES qui fournit des services d'acquisition et d'orchestration de données configurables, évolutifs et universels. Il s'agit d'un service universel qui prend en charge la requête de données sur la plateforme d'investissement.
Concepts clés à comprendre :
-
Indicateurs
: Les indicateurs sont des métadonnées que nous utilisons pour décrire un attribut d'une entité ou d'un objet, tel que le nom du produit, le score d'expérience en magasin, le niveau d'expert, l'ID de l'enregistrement d'enregistrement. En même temps, il peut également s'agir de la mise à jour et de l'acquisition minimales d'un. objet. Unité, telle que les informations de comparaison des prix des produits. Nous pouvons définir tous les champs avec une sémantique claire comme indicateurs
.
-
Ensemble
: représente un ensemble qui peut être convergent par certains points communs, tels qu'un ensemble d'attributs de produit et un ensemble d'attributs de magasin, qui peuvent être obtenus respectivement par l'ID de produit et l'ID de magasin. Il peut également s'agir d'une collection d'enregistrements d'enregistrement de produit, qui peut être obtenue par. ID d'enregistrement d'enregistrement. En termes commerciaux, il exprime un ensemble d'indicateurs liés, et les indicateurs sont dans une relation un-à-plusieurs.
-
Solution
: Solution d'acquisition de données. Nous faisons abstraction des deux concepts d'indicateurs et de collections afin que les données puissent être obtenues dans la plus petite unité et puissent être continuellement étendues horizontalement. La solution nous aide à résumer comment obtenir des indicateurs dans différentes collections.
-
En-tête personnalisé
: l'en-tête personnalisé fait référence au titre à afficher dans toute liste de données de ligne bidimensionnelle. Il a une relation un-à-plusieurs avec l'indicateur ;
-
Élément de filtre
: l'élément de filtre fait référence à l'élément de filtre qui doit être utilisé dans toute liste de données de ligne bidimensionnelle. Il peut indiquer une relation 1 à 1 ;
-
Vue d'audit
: la vue d'audit fait référence à une page d'audit qui peut être rendue dynamiquement à partir d'un ensemble d'en-têtes personnalisés et d'un ensemble d'éléments de filtre dans un scénario métier d'audit.
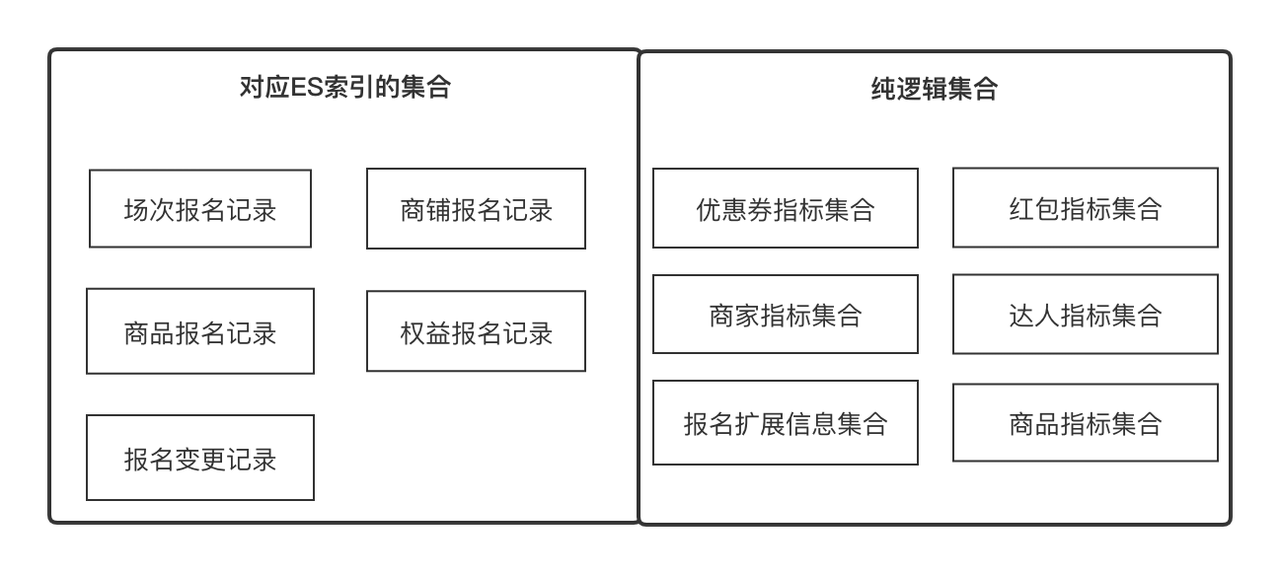
Dans la conception fonctionnelle, via l'indicateur-->[Éléments de filtre, en-tête personnalisé]-->Vue d'audit-->le processus de rendu enfin dynamique d'une page d'audit Puisque nous recrutons des investissements avec plusieurs entités et plusieurs scénarios, différentes entités. avoir différents scénarios. Différentes vues d'audit sont requises, de sorte que cette série de fonctionnalités que nous avons conçues peut combiner dynamiquement tous les effets de vue d'audit requis.
Le centre de données fournit des capacités générales d'acquisition de données aux entreprises de niveau supérieur, notamment la synchronisation et l'interrogation de données. Il existe actuellement deux sources de données, l'interface RPC externe et l'enregistrement d'enregistrement ES. Le centre de données intègre deux ensembles de solutions d'acquisition de données, qui ignorent totalement le monde extérieur, c'est-à-dire qu'il lui suffit d'obtenir quels indicateurs de données sous quels indicateurs. collection.
L'objectif de la création d'ES est de prendre en charge les capacités de filtrage et de statistiques des enregistrements d'enregistrement des investissements et de produire le contenu de données souhaité pour l'entreprise de niveau supérieur.
Construire un cluster ES de 0 à 1
Pour construire un système de 0 à 1, sur la base de la satisfaction des besoins de base de l'entreprise, la stabilité doit prendre en charge les deux points suivants : ;
-
Le mécanisme de base de reprise après sinistre signifie que lorsque les performances du système sont affectées en raison de modifications des composants de base et du trafic de lecture et d’écriture, l’entreprise peut s’adapter à temps.
-
La cohérence finale des données signifie que l'enregistrement d'enregistrement DB --> données de la salle multimachine ES est complet.
Recherche de programme
Évaluation des capacités du cluster ES
L'évaluation de la capacité du cluster ES vise à garantir que le cluster peut fournir des services stables pendant un certain temps après sa construction. Il doit principalement être capable de résoudre les problèmes suivants :
-
Combien de fragments doivent être définis pour chaque index, quel incrément de données ultérieur est attendu et estimations du trafic de lecture et d'écriture ;
-
Combien d'instances de données doivent être configurées dans un seul cluster et quelles spécifications doivent être utilisées pour une seule instance de données ;
-
Comprenez la différence entre l'expansion verticale et l'expansion horizontale, quelle est notre stratégie de réponse lorsque le volume de données augmente de manière inattendue ou lorsque le trafic augmente de manière inattendue, et comment concevoir la reprise après sinistre du cluster ES.
Solutions clés :
-
Une fois le nombre de fragments d'index ES défini, il ne peut pas être modifié. Il est donc important de déterminer le nombre de fragments. Généralement, le nombre de fragments est un multiple entier de l'instance ES pour garantir l'équilibrage de charge ;
-
La taille d'une seule partition est relativement raisonnable entre 10 et 30 Go. Une indexation excessive affectera les performances des requêtes ;
-
L'augmentation du trafic peut être résolue par l'expansion de la capacité, et l'augmentation des données peut être résolue en supprimant les anciennes données ou en augmentant le nombre de fragments ; est une salle des machines tolérante aux catastrophes.
Sélection du lien de synchronisation des données
Il résout principalement comment synchroniser les enregistrements d'enregistrement de la base de données avec ES, comment écrire d'autres indicateurs associés dans ES et comment mettre à jour et assurer la cohérence des données.
-
DB -> ES doit être un flux de données quasi-temps réel, et les modifications dans les dossiers d'enregistrement et autres informations doivent pouvoir être recherchées en temps quasi-réel ;
-
En plus de ses propres champs, l'enregistrement d'enregistrement doit également compléter ses champs d'attributs tels que les produits enregistrés, les magasins et les experts. Il est également écrit dans ES et
peut prendre en charge les mises à jour partielles
, de sorte que la méthode d'écriture ES ne peut être que la méthode Upsert. ;
-
Les mises à jour des dossiers d’inscription individuels doivent être régulières et ne doivent pas entrer en conflit.
Enquête sur la configuration de base de l'index ES
Comprendre les principes fondamentaux et les configurations essentiels d’ES.
-
{"dynamic": false} évite l'expansion automatique des mappages es ou l'ajout de types d'index inattendus ;
-
index.translog.durability=async, l'actualisation du translog de manière asynchrone contribuera à améliorer les performances d'écriture, mais il existe un risque de perte de données ;
-
L'intervalle de rafraîchissement par défaut d'ES est de 1 s, ce qui signifie que les données peuvent être trouvées dès une seconde après une écriture réussie.
Solution de synchronisation des données
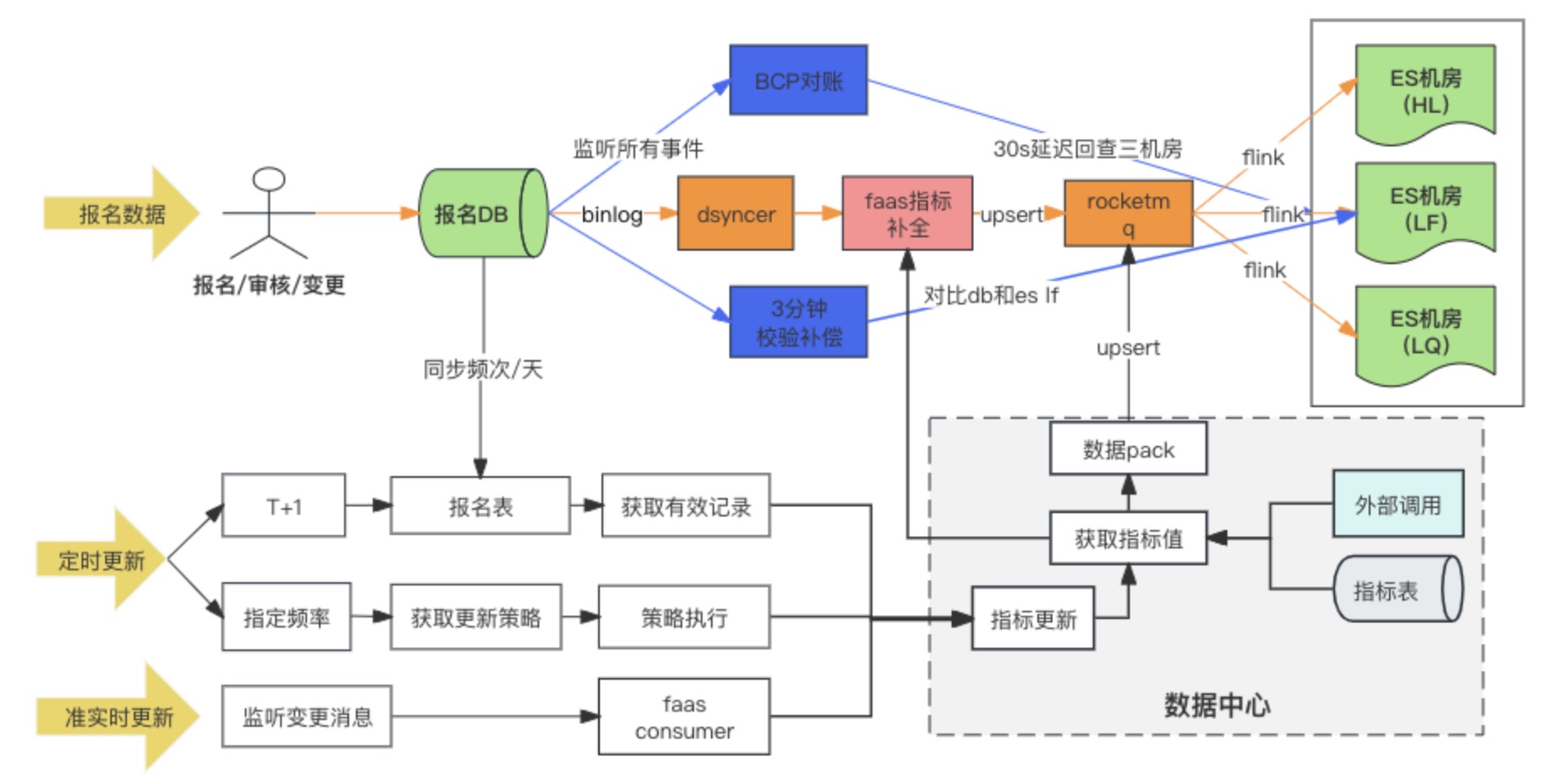
Schéma du lien de synchronisation des données
La solution de synchronisation de données DB --> ES adopte finalement la méthode d'écriture synchrone de données hétérogènes sur RocketMQ + Flink pour la consommation de plusieurs salles de machines. En même temps, lorsque l'enregistrement d'enregistrement est écrit pour la première fois, les indicateurs étendus sont remplis. via le script de conversion personnalisé Faas, et les dépendances de mise à jour des indicateurs étendus sont Changez les deux méthodes d'écoute des messages et de tâches planifiées. Au cours de la recherche, il y avait en fait trois options pour la salle multi-ordinateurs DB -> ES. Au final, nous avons choisi la troisième option. Nous comparons ici les différences entre les trois options :
Solution 1 : écrire directement dans la salle multimachine ES via une synchronisation de données hétérogène (Dsyncer)
défaut:
-
L'écriture directe est désavantagée pour répondre aux exigences d'ES pour déployer plusieurs salles informatiques simultanément, car elle ne peut pas garantir une écriture réussie dans plusieurs salles informatiques en même temps. Est-il acceptable de déployer plusieurs données hétérogènes et de les écrire séparément ? Oui, c'est-à-dire que la charge de travail est triplée pour atteindre environ une douzaine d'index.
-
La capacité d'écriture de l'écriture directe en masse est relativement faible et les pics d'écriture seront plus évidents à mesure que le trafic fluctue, ce qui n'est pas favorable aux performances d'écriture d'ES.
-
L'écriture directe ne peut pas garantir la mise à jour ordonnée d'un seul enregistrement d'enregistrement lorsque ES a plusieurs entrées de mise à jour. Puis-je augmenter la version globale ? Oui, mais trop lourd.
Avantages :
le chemin de dépendance le plus court, une faible latence d'écriture et un risque système minimal. Cela ne pose absolument aucun problème pour les entreprises à faible trafic et les entreprises disposant de scénarios de synchronisation simples.
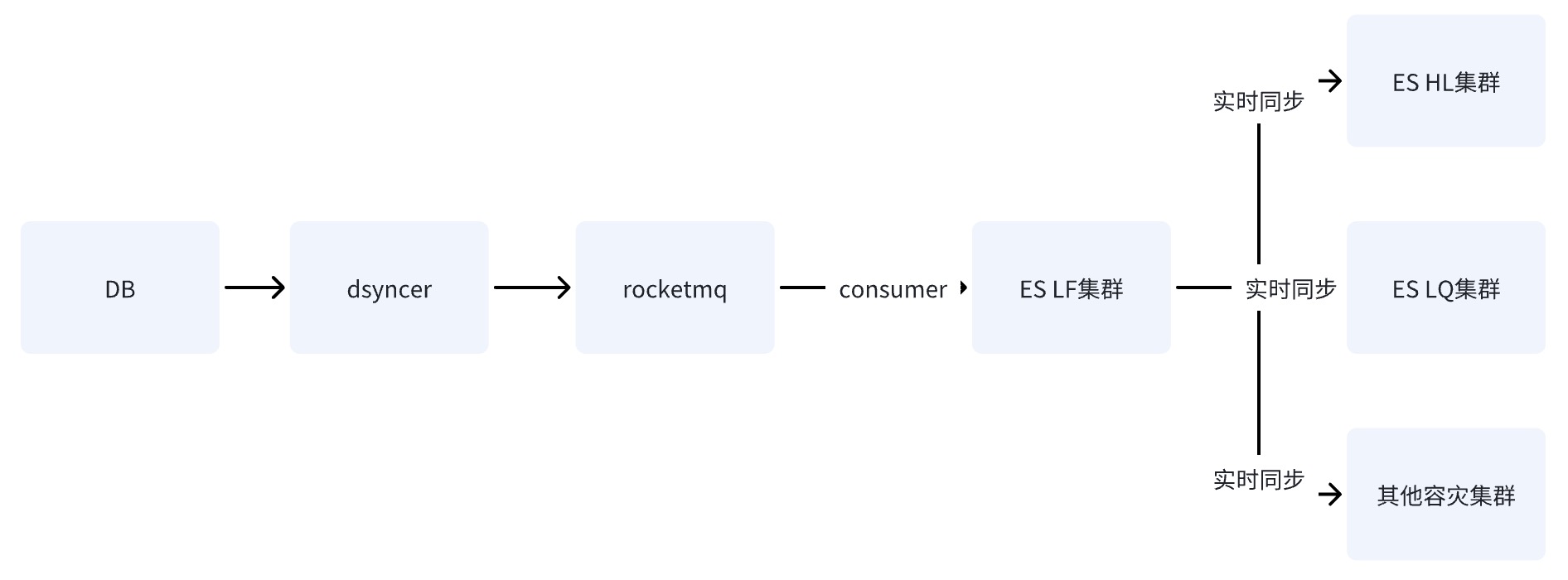
Option 2 : Écrire une salle informatique unique ES via RocketMQ
Une fois que la base de données écrit dans la salle informatique unique d'ES via RocketMQ, les données sont synchronisées avec d'autres salles informatiques grâce à la capacité de réplication de données entre clusters fournie par ES.
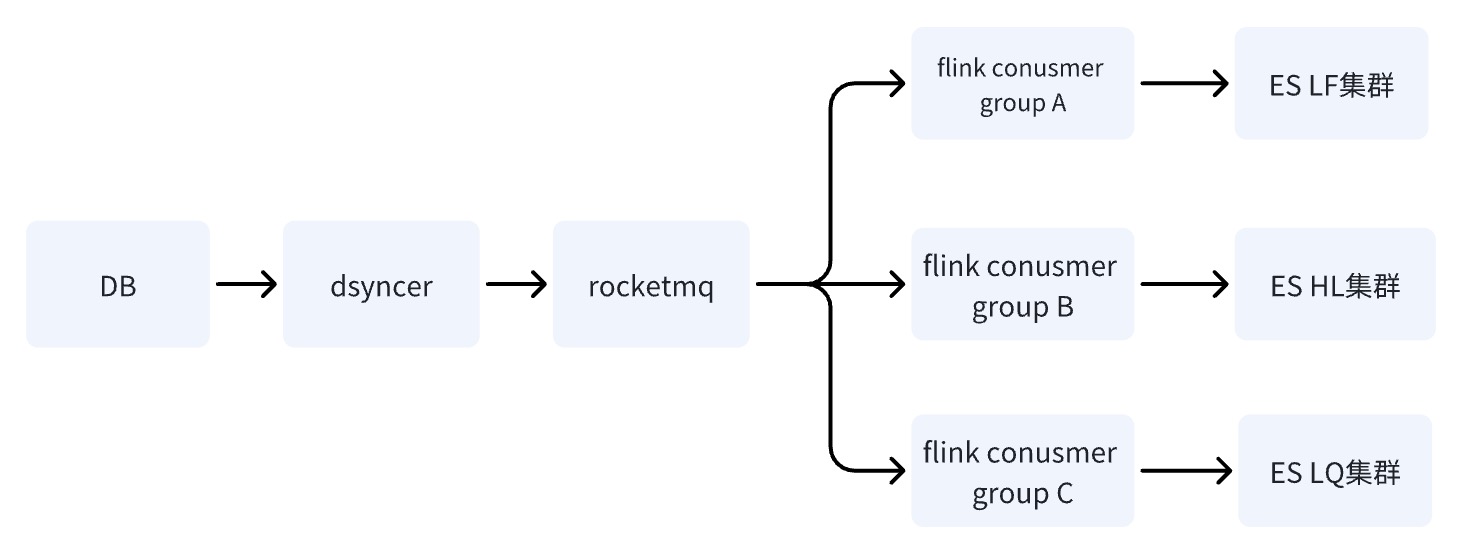
Option 3 : Écrire une salle multi-machines ES via RocketMQ + Flink ✅
Lorsque DB écrit sur le cluster ES via RocketMQ, plusieurs tâches indépendantes du groupe de consommateurs sont démarrées. Le système peut utiliser le système distribué Flink pour écrire des données dans plusieurs salles informatiques.
Il n'y a qu'une seule différence entre le schéma deux et le schéma trois : la manière d'écrire dans plusieurs salles informatiques est différente. Le schéma deux consiste à écrire dans une salle informatique, puis à synchroniser les données avec d'autres salles informatiques en temps quasi réel, tandis que le schéma deux consiste à écrire dans une salle informatique, puis à synchroniser les données avec d'autres salles informatiques en temps quasi réel. la troisième consiste à écrire plusieurs consommateurs indépendants dans la salle des machines.
Les inconvénients des options deux et trois sont les mêmes : le chemin de dépendance est le plus long et le délai d'écriture est facilement affecté par la gigue des composants de base. Cependant, l'inconvénient fatal de l'option deux est qu'il n'y a qu'un
seul point de risque. Le système
. En supposant que les données soient synchronisées avec HL et LQ via LF, Le système deviendra inutilisable après le raccrochage de LF.
L'avantage de la troisième option est que les liens d'écriture de plusieurs salles informatiques sont indépendants les uns des autres. Par rapport à la deuxième option, si un lien présente des problèmes, cela ne présentera pas de risques pour l'entreprise ; ,
ce qui n'est pas non plus souhaitable pour la première raison
.
Pourquoi l'écriture via RocketMQ peut-elle résoudre le problème du désordre et des conflits ?
-
Tout d'abord, l'écriture ES est contrôlée par un verrouillage optimiste basé sur le numéro de version. Si le même enregistrement est mis à jour simultanément en même temps, alors la version que nous obtenons en même temps est la même, en supposant qu'elle soit 1, alors tout le monde le fera. mettez à jour la version vers 2 pour écrire, des conflits se produiront et les conflits entraîneront toujours le problème des mises à jour perdues ;
-
Les scénarios commerciaux généraux nécessitent une consommation ordonnée basée sur l'ordre des clés et des partitions. La consommation ordonnée nécessite deux conditions nécessaires : lorsque les messages sont stockés, ils doivent être cohérents avec l'ordre dans lequel ils sont envoyés ; lorsque les messages sont consommés, ils doivent être cohérents avec l'ordre ; dans lequel ils sont stockés.
Par conséquent, si l'entreprise souhaite consommer les messages de manière ordonnée, elle doit s'assurer que les messages envoyés avec la même clé sont envoyés à la même partition, et que les messages consommés garantissent que les messages avec la même clé sont toujours consommés par l'utilisateur. même consommateur. Mais en fait, les deux conditions nécessaires mentionnées ci-dessus sont idéales. Dans certains cas, elles ne peuvent pas être complètement garanties, comme dans le cas du rééquilibrage du consommateur. Par exemple, l'écriture d'une certaine instance de Broker continue d'échouer. Les raisons et les solutions seront analysées ci-dessous.
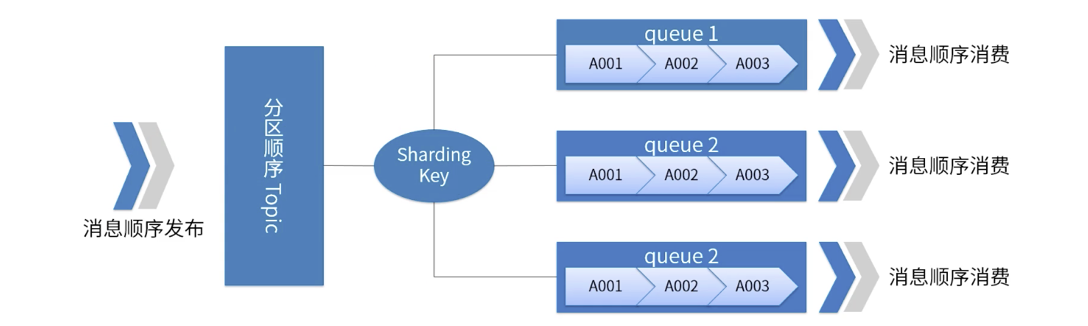
Une image illustre l'ordre des partitions RocketMQ
-
Pour un sujet spécifié, tous les messages sont divisés en plusieurs (file d'attente) en fonction de la clé de partage.
-
Les messages dans la même file d'attente sont publiés et consommés dans un ordre FIFO strict.
-
Sharding Key est un champ clé utilisé pour distinguer différentes partitions dans des messages séquentiels. C'est un concept complètement différent de la clé des messages ordinaires.
-
Scénarios applicables : Exigences de performances élevées. Déterminez à quelle file d'attente le message est envoyé en fonction de la clé de partitionnement du message. Généralement, un partitionnement ordonné peut répondre à nos exigences commerciales et offre des performances élevées.
Ce qu'il faut noter ici, c'est
que
RocketMQ a peut-être aidé l'entreprise à résoudre 99 % des problèmes de consommation hors service, mais ce n'est pas le cas à 100 %. Dans des cas extrêmes, les messages peuvent toujours avoir des problèmes de consommation hors service, tels que comme le phénomène ABA, par exemple lorsque Partiton échoue, le message est envoyé à plusieurs reprises à d'autres files d'attente de partition, etc., la réconciliation de cohérence est donc essentielle.
Mécanisme de réconciliation multicouche
Le mécanisme de réconciliation résout le problème de cohérence des données de DB->ES.Comme mentionné précédemment, DB --> ES est un flux de données quasi en temps réel et le lien de dépendance est relativement long.Nous avons besoin d'une surveillance correspondante dans différents états. stratégies de rapprochement et de compensation pour assurer la cohérence éventuelle des données.
Ici, nous avons effectué une réconciliation à trois niveaux. Nous utilisons la plate-forme de réconciliation pour réaliser une réconciliation au niveau minute et une réconciliation hors ligne. Les raisons de la nécessité d'une réconciliation multicouche seront expliquées une par une ci-dessous.
Diagramme d'analyse des échecs de liaison ES de synchronisation de base de données
Rapprochement de deuxième niveau de la plateforme de vérification des entreprises ( PCA )
En vous référant à la figure ci-dessus, vous constaterez que la synchronisation DB -> ES dépend de nombreux composants dépendants. Dans ce cas, nous avons besoin d'une
réconciliation dans une perspective globale
pour découvrir les problèmes de lien de synchronisation, c'est-à-dire une réconciliation en temps réel BCP.
La réconciliation BCP est une réconciliation à flux unique qui surveille le Binlog et vérifie directement la réconciliation de la salle multi-machine ES. Elle repose uniquement sur le flux Binlog. Les retards de synchronisation des données ou les blocages dans les liens intermédiaires peuvent être rapidement découverts grâce à la réconciliation BCP. Nous constaterons que si Binlog est coupé et que la réconciliation BCP ne peut pas être corrigée, nous discuterons plus tard de la façon de résoudre cette situation, mais au moins on peut voir qu'à l'exception de DB->DBus, la réconciliation BCP est suffisante pour trouver la plupart des délais de synchronisation. problèmes. Pourquoi un seul flux plutôt que plusieurs flux ?
-
Évitez les problèmes de retard incontrôlables causés par de longues liaisons de flux de données pour la réconciliation multi-flux, entraînant une faible précision de vérification.
-
Le coût de maintenance de la réconciliation BCP sera considérablement réduit, car si le multi-flux est utilisé, nous devons maintenir plusieurs réconciliations BCP pour la réconciliation multi-salles informatiques, qui repose sur des composants plus basiques pour la maintenance.
L'écriture de la base de données de réconciliation BCP déclenche toujours des requêtes ES Get, qui consomment certaines ressources de requête sur ES, mais les requêtes Get sont des méthodes de requête avec de très bonnes performances. Par exemple, nous n'avons aucun problème à écrire dans les 1 000 QPS.
La requête Get doit prêter attention à un paramètre Realtime, qui doit être défini sur False lors de la requête, sinon elle déclenchera une opération d'actualisation à chaque fois qu'elle est demandée, ce qui aura un impact sur les performances d'écriture du système.
mgetReq := EsClient.MultiGet().
Temps réel (faux)
Rapprochement au niveau minute
Comme mentionné dans la section précédente, le chemin qui ne peut pas être couvert par la réconciliation de la Business Verification Platform (BCP) est DB->DBus, ce qui correspond à la situation dans laquelle Binlog est coupé. Habituellement, une interruption de Binlog peut avoir entraîné un accident plus grave, mais ce que nous devons faire, c'est faire tout notre possible.
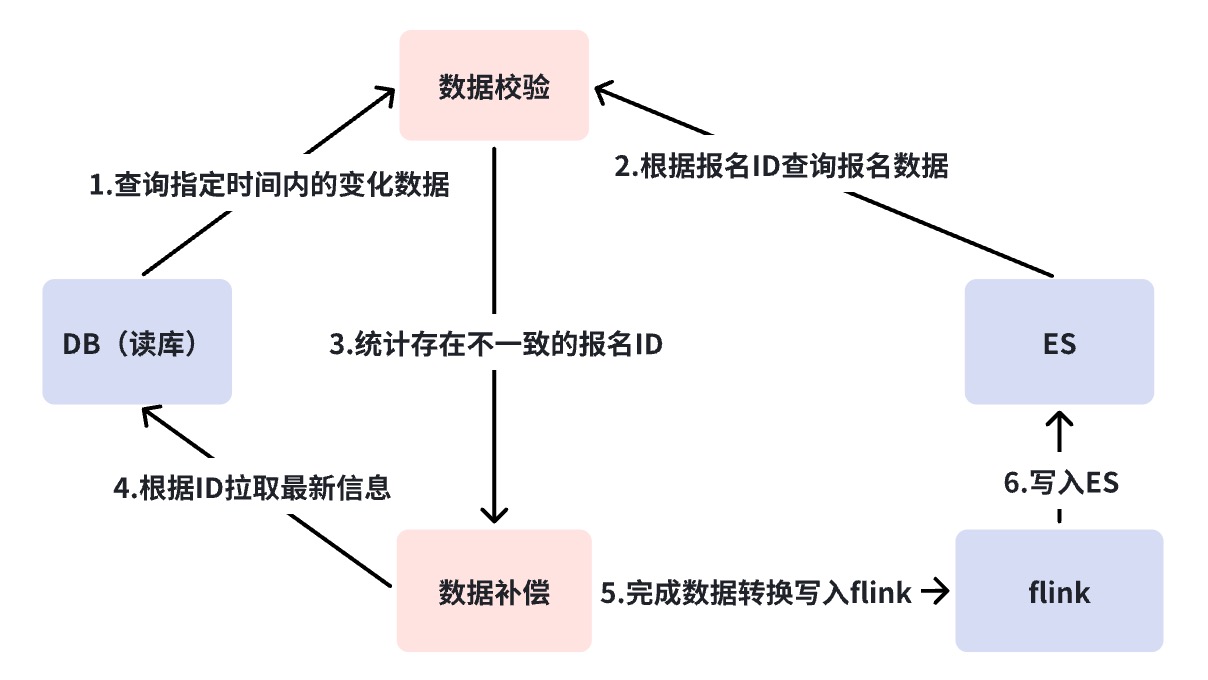
La réconciliation au niveau minute interroge directement DB et ES pour la réconciliation, sans s'appuyer sur aucun composant. Lorsque des incohérences surviennent, une compensation automatique est effectuée. D'une part, le rapprochement à la minute pallie les lacunes du rapprochement du BCP, et le deuxième point est d'ajouter un mécanisme de compensation. La raison pour laquelle BCP ne compense pas est que BCP sert principalement à découvrir des problèmes, il doit donc rester léger et rapide. De plus, il repose toujours sur des composants de base tels que RocketMQ et DBus. Ce type de compensation ne peut toujours pas couvrir tous les scénarios anormaux.
Par défaut, nous considérerons que la fonction du composant est intacte pour la réconciliation toutes les trois minutes, mais un court retard dans un nœud provoque une compensation. Si des alarmes de compensation se produisent fréquemment, nous devons analyser plus en détail quel est le problème avec la liaison ? À ce stade, dans notre scénario, je diviserai le lien en deux et confirmerai s'il y a un problème avec le lien précédent de RocketMQ ou un problème avec RocketMQ et les liens de consommation ultérieurs. Grâce au diagramme d'analyse des défauts, s'il y a un problème avec la liaison avant RocketMQ, tel qu'une interruption de Binlog, un composant hétérogène de la plate-forme de synchronisation de données suspendu, etc., les données de compensation seront écrites directement dans RocketMQ et consommées dans plusieurs salles informatiques. le temps, le trafic de lecture n'a pas besoin d'être coupé en flux et peut assurer la cohérence des données dans plusieurs salles informatiques. Mais si RocketMQ raccroche, il écrira directement dans ES. Car pour le moment, nous ne pouvons pas garantir que plusieurs salles informatiques puissent être écrites avec succès en même temps, notre décision est donc d'écrire uniquement dans une seule salle informatique et de transférer tout le trafic vers. la seule salle informatique.
Raccrocher RocketMQ est un très mauvais signal, et la situation ici est plus compliquée. En raison de l'écriture directe sur ES, si le trafic d'écriture est élevé, le système perd la protection de limitation actuelle à ce moment-là, et ES peut ne pas être en mesure d'y résister ; une seule salle informatique peut ne pas être en mesure de supporter tout le trafic de lecture ; en même temps ; si des conflits d’écriture se produisent fréquemment, le port d’écriture professionnel doit être rétrogradé. Par conséquent, si RocketMQ raccroche, on peut comprendre que le système central du lien d'écriture est paralysé.
C'est la dernière chose que vous voulez voir, donc le SLA de RocketMQ est la base de l'entreprise.
Rapprochement hors ligne T+1
La réconciliation hors ligne consiste à synchroniser quotidiennement les données de DB et ES avec Hive. Les données incrémentielles vérifient la cohérence finale. En cas d'incohérence, la réconciliation hors ligne est l'essentiel pour la cohérence des données du lien de synchronisation. les données doivent être T au plus tard +1 compensation réussie.
Résumer
Ci-dessus, nous avons terminé la première phase de construction, le déploiement de la reprise après sinistre, la réconciliation de la cohérence et les stratégies de base de réponse aux exceptions du système. À l'heure actuelle, ES peut prendre en charge les demandes de lecture et d'écriture pour des dizaines de millions d'index de produits. Le trafic d'une seule salle informatique oscille entre 500 et 100 QPS, et le trafic d'écriture est essentiellement maintenu à environ 500 QPS.
Cependant, avec le développement de l'activité, le cluster ES a connu à plusieurs reprises des surtensions de processeur, une ou plusieurs salles informatiques sont pleines en même temps et les délais de requête augmentent soudainement. Cependant, le trafic de lecture et d'écriture ne fluctue pas beaucoup, ou l'est. bien inférieur au pic du système. Ce risque Il est attribué aux problèmes de performances qui surviennent dans le cluster ES et à la posture d'utilisation de l'entreprise. Nous continuerons à introduire cette partie du contenu dans le prochain article sur la gestion de la stabilité du moteur de recherche ES.
Source de l'article | Plateforme commerciale ByteDance Wang Dan