L'état actuel d'Apache Spark dans iQiyi
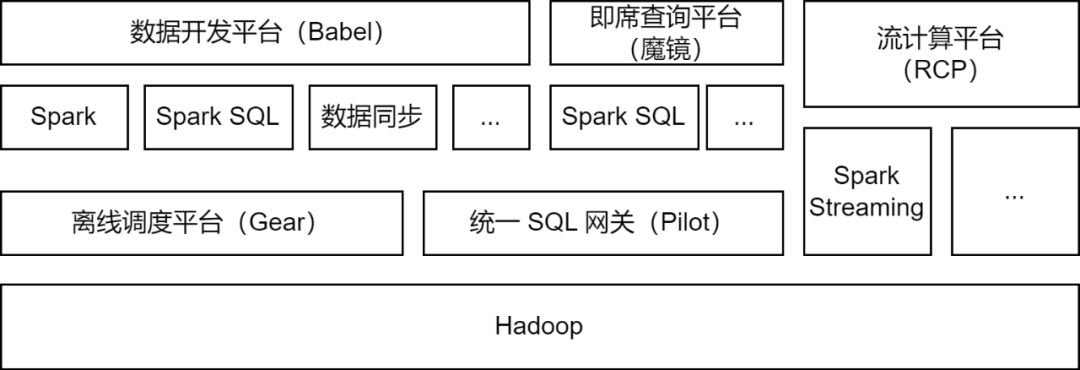
Apache Spark est le cadre informatique hors ligne principalement utilisé par la plateforme Big Data iQiyi et prend en charge certaines tâches de calcul de flux pour le traitement des données, la synchronisation des données, l'analyse des requêtes de données et d'autres scénarios :
-
Traitement des données : la plate-forme de développement de données aide les développeurs à soumettre des tâches de package Spark Jar ou des tâches Spark SQL pour le traitement ETL des données.
-
Synchronisation des données
: l'outil de synchronisation de données BabelX auto-développé par iQIYI est développé sur la base du framework informatique Spark. Il prend en charge l'échange de données entre 15 sources de données telles que Hive, MySQL et MongoDB, et prend en charge la synchronisation des données entre plusieurs clusters et plusieurs cloud. configuré Tâches de synchronisation de données entièrement gérées.
-
Analyse des données : les analystes de données et les étudiants en opérations soumettent du SQL ou configurent des requêtes d'indicateurs de données sur la plateforme de requêtes ad hoc Magic Mirror, et appellent le service Spark SQL via la passerelle SQL unifiée Pilot pour l'analyse des requêtes.
Actuellement, le service iQiyi Spark exécute plus de 200 000 tâches Spark chaque jour, occupant plus de la moitié des ressources informatiques globales du Big Data.
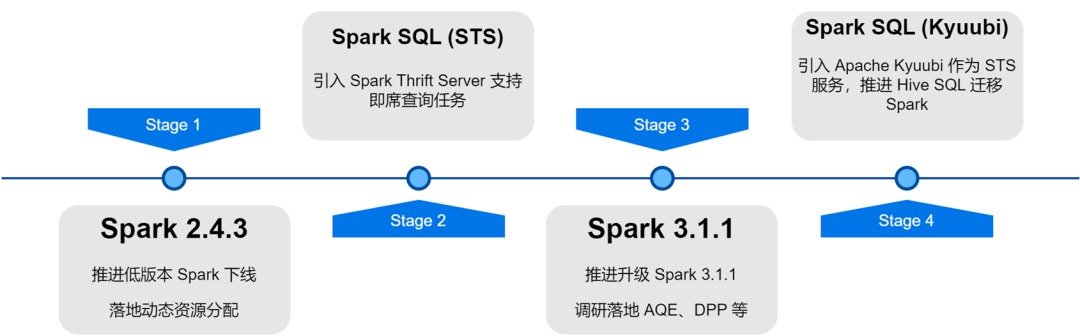
Dans le processus de mise à niveau et d'optimisation de l'architecture de la plate-forme Big Data iQiyi, le service Spark a subi une itération de version, une optimisation du service, une SQLisation des tâches et une gestion des coûts des ressources, etc., ce qui a considérablement amélioré l'efficacité informatique et l'économie des ressources des tâches hors ligne.
Optimisation des applications du framework Spark Computing
Avec la mise à niveau itérative de la version interne de Spark, nous avons étudié et implémenté d'excellentes fonctionnalités de la nouvelle version Spark : allocation dynamique des ressources, optimisation adaptative des requêtes, élagage dynamique des partitions, etc.
-
Allocation dynamique des ressources (DRA)
: il existe un aveuglement dans l'application des ressources par les utilisateurs, et les besoins en ressources de chaque étape des tâches Spark sont également différents. Une allocation déraisonnable des ressources entraîne un gaspillage de ressources de tâche ou une exécution lente. Nous avons lancé le service External Shuffle dans Spark 2.4.3 et activé l'allocation dynamique des ressources (DRA). Après avoir été activé, Spark démarrera ou libérera dynamiquement l'exécuteur en fonction des besoins en ressources de l'étape en cours d'exécution. Après la mise en ligne de DRA, la consommation de ressources des tâches Spark a été réduite de 20 %.
-
Optimisation adaptative des requêtes (AQE)
: L'optimisation adaptative des requêtes (AQE) est une excellente fonctionnalité introduite dans Spark 3.0. Basée sur les indicateurs statistiques pendant l'exécution de la pré-étape, elle optimise dynamiquement le plan d'exécution des étapes suivantes et sélectionne automatiquement le. Stratégie de jointure appropriée. Optimisez la jointure asymétrique, fusionnez de petites partitions, divisez de grandes partitions, etc. Après la mise à niveau de Spark 3.1.1, AQE a été activé par défaut, ce qui a efficacement résolu des problèmes tels que les petits fichiers et la distorsion des données, et a considérablement amélioré les performances informatiques de Spark. Les performances globales ont augmenté d'environ 10 %.
-
Élagage dynamique des partitions (DPP)
: dans les moteurs informatiques SQL, le refoulement des prédicats est généralement utilisé pour réduire la quantité de données lues à partir de la source de données, améliorant ainsi l'efficacité du calcul. Une nouvelle méthode de refoulement est introduite dans Spark3 : l'élagage dynamique des partitions et le filtre d'exécution. En calculant d'abord la petite table de la jointure, la grande table de la jointure est filtrée en fonction des résultats du calcul, réduisant ainsi la quantité de données lues par la grande. tableau. Nous avons effectué des recherches et des tests sur ces deux fonctionnalités et activé DPP par défaut dans certains scénarios commerciaux, les performances ont été multipliées par 33. Cependant, nous avons constaté que dans Spark 3.1.1, l'activation de DPP entraînerait une analyse SQL avec de nombreuses sous-requêtes particulièrement lente. Par conséquent, nous avons implémenté une règle d'optimisation : calculer le nombre de sous-requêtes, et lorsqu'il dépasse 5
, désactiver
l'optimisation DPP.
Lors de l'utilisation de Spark, nous avons également rencontré quelques problèmes. En suivant les derniers progrès de la communauté, nous avons découvert et installé quelques correctifs pour les résoudre. De plus, nous avons également apporté nous-mêmes quelques améliorations à Spark pour le rendre adapté à divers scénarios d'application et améliorer la stabilité du cadre informatique.
-
Prise en charge de l'écriture simultanée
Étant donné que Spark 3.1.1 convertit par défaut les tables au format Hive Parquet en Parquet Writer intégré de Spark, utilisez l'opérateur InsertIntoHadoopFsRelationCommand pour écrire des données (spark.sql.hive.convertMetastoreParquet=true). Lors de l'écriture d'une partition statique, le répertoire temporaire sera construit directement sous le chemin de la table. Lorsque plusieurs tâches d'écriture de partition statique écrivent simultanément sur différentes partitions de la même table, il existe un risque d'échec d'écriture de tâche ou de perte de données (lorsqu'une tâche est validée, l'intégralité du répertoire temporaire sera nettoyé, entraînant une perte de données). pour d'autres tâches).
Nous ajoutons un paramètre forceUseStagingDir à l'opérateur InsertIntoHadoopFsRelationCommand et utilisons le répertoire Staging spécifique à la tâche comme répertoire temporaire. De cette façon, différentes tâches utilisent différents répertoires temporaires, résolvant ainsi le problème de l'écriture simultanée. Nous avons soumis le problème pertinent [SPARK-37210] à la communauté.
-
Prise en charge des sous-répertoires d'interrogation
Une fois Hive mis à niveau vers 3.x, le moteur Tez est utilisé par défaut. Lorsque l'instruction Union est exécutée, le sous-répertoire HIVE_UNION_SUBDIR sera généré. Étant donné que Spark ignore les données des sous-répertoires, aucune donnée ne peut être lue.
Ce problème peut être résolu en utilisant Parquet/Orc Reader vers Hive Reader, en ajoutant les paramètres suivants :

Cependant, l'utilisation du Parquet Reader intégré à Spark offrira de meilleures performances, nous avons donc abandonné le projet de recourir à Hive Reader et avons transformé Spark à la place. Étant donné que Spark prend déjà en charge la lecture des sous-répertoires des tables non partitionnées via le paramètre recursiveFileLookup, nous l'avons étendu pour prendre en charge la lecture des sous-répertoires des tables partitionnées. Pour plus de détails, voir : [SPARK-40600]
-
Améliorations de la source de données JDBC
Il existe un grand nombre de tâches de source de données JDBC dans les applications de synchronisation de données. Afin d'améliorer l'efficacité opérationnelle et de s'adapter à divers scénarios d'application, nous avons apporté les modifications suivantes à la source de données JDBC intégrée de Spark :
Réduire les conditions de partitionnement
:
une fois que Spark a fragmenté la source de données JDBC, il insère les conditions de partitionnement via des sous-requêtes. Nous avons constaté que dans MySQL 5.x, les conditions de sous-requête ne peuvent pas être réduites, nous avons donc ajouté un espace réservé qui représente la position de la condition. , et lors de l'insertion de la condition de partitionnement dans Spark, elle est poussée vers l'intérieur de la sous-requête, réalisant ainsi la possibilité d'abaisser la condition de partitionnement.
Modes d'écriture multiples
:
Nous avons implémenté plusieurs modes d'écriture pour les sources de données JDBC dans Spark.
-
Normal : mode normal, utilisez l'INSERT INTO par défaut pour écrire
-
Upsert : Mise à jour lorsque la clé primaire existe, écrite en mode INSERT INTO...ON DUPLICATE KEY UPDATE
-
Ignorer : Ignorer lorsque la clé primaire existe, écrire en mode INSERT IGNORE INTO
Mode silencieux :
Lorsqu'une exception se produit lors de l'écriture JDBC, seul le journal des exceptions est imprimé et la tâche n'est pas terminée.
Type de carte pris en charge
: nous utilisons la source de données JDBC pour lire et écrire des données ClickHouse. Le type Map dans ClickHouse n'est pas pris en charge dans la source de données JDBC, nous avons donc ajouté la prise en charge du type Map.
-
Limite de taille d'écriture sur le disque local
Des opérations telles que Shuffle, Cache et Spill dans Spark généreront certains fichiers locaux. Lorsque trop de fichiers locaux sont écrits, le disque du nœud informatique peut être rempli, affectant ainsi la stabilité du cluster.
À cet égard, nous avons ajouté un indicateur de volume d'écriture sur disque dans Spark, générons une exception lorsque le volume d'écriture sur disque atteint le seuil, jugeons l'exception d'échec de tâche dans TaskScheduler et appelons DagScheduler lorsque l'exception de limite d'écriture sur disque est capturée. La méthode arrête les tâches avec une utilisation excessive du disque.
Dans le même temps, nous avons également ajouté l'indicateur d'utilisation du disque Executor dans ExecutorMetric pour exposer l'utilisation actuelle du disque de Spark Executor, facilitant ainsi l'observation des tendances et l'analyse des données.
Le service Spark consomme beaucoup de ressources informatiques. Nous avons développé une plate-forme de gestion des exceptions pour auditer et gérer les ressources informatiques pour les tâches de traitement par lots Spark et les tâches de calcul en flux, respectivement.
Lors de l'exploitation et de la maintenance quotidiennes, nous avons constaté qu'un grand nombre de tâches Spark présentent des problèmes tels qu'un gaspillage de mémoire et une faible utilisation du processeur. Afin de trouver les tâches présentant ces problèmes, nous fournissons des indicateurs de ressources lorsque les tâches Spark sont exécutées sur Prometheus pour analyser l'utilisation des ressources des tâches et obtenir les détails de configuration et de calcul des ressources en analysant Spark EventLog.
-
gouvernance des ressources
En optimisant les paramètres de ressources des tâches et en permettant une allocation dynamique des ressources, l'utilisation des ressources informatiques des tâches Spark est efficacement améliorée. La mise à niveau de la version Spark entraîne également de nombreuses économies de ressources.
L'optimisation des paramètres de ressources est divisée en optimisation de la mémoire et du processeur. La plate-forme de gestion des exceptions recommande des paramètres de ressources raisonnables en fonction de l'utilisation maximale des ressources de la tâche au cours des sept derniers jours, améliorant ainsi l'utilisation des ressources des tâches Spark.
En prenant l'optimisation de la mémoire comme exemple, les utilisateurs résolvent souvent le problème du débordement de mémoire (MOO) en augmentant la mémoire, mais ignorent l'enquête approfondie sur les causes du MOO. Cela entraîne un réglage trop élevé des paramètres de mémoire d'un grand nombre de tâches Spark et un déséquilibre du rapport entre la mémoire des ressources de file d'attente et le processeur. Nous obtenons des indicateurs de mémoire Spark Executor et envoyons des ordres de travail d'exception pour avertir les utilisateurs et les guider dans la configuration correcte des paramètres de mémoire et du nombre de partitions.
-
Avantages de la gouvernance
Après près d'un an de gestion d'audit des ressources, la plateforme de gestion des exceptions a émis plus de 1 600 bons de travail, économisant au total environ 27 % des ressources informatiques.
Implémentation et optimisation du service Spark SQL
Le service iQiyi Spark SQL est passé par plusieurs étapes, du service Thrift Server natif de Spark à Kyuubi 0.7 en passant par la version Apache Kyuubi 1.4, qui a apporté de grandes améliorations à l'architecture et à la stabilité du service.
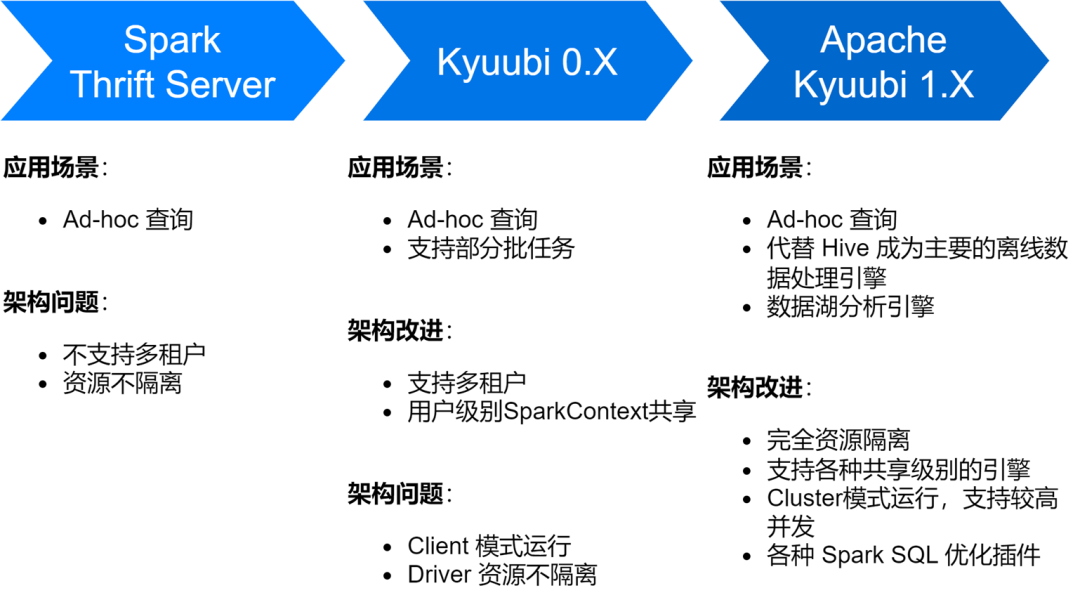
À l'heure actuelle, le service Spark SQL a remplacé Hive en tant que principal moteur de traitement de données hors ligne d'iQiyi, exécutant en moyenne environ 150 000 tâches SQL chaque jour.
-
Optimiser l’efficacité du stockage et du calcul
Nous avons également rencontré quelques problèmes lors de l'exploration du service Spark SQL, notamment la génération d'un grand nombre de petits fichiers, un stockage plus important et des calculs plus lents. Pour cette raison, nous avons également effectué une série d'optimisations de l'efficacité du stockage et du calcul.
Activer la compression ZStandard pour améliorer le taux de compression
Zstd est l'algorithme de compression open source de Meta. Comparé à d'autres formats de compression, il a un taux de compression et une efficacité de décompression plus élevés. Nos résultats de mesures réels montrent que le taux de compression de Zstd est équivalent à celui de Gzip et que la vitesse de décompression est meilleure que celle de Snappy. Par conséquent, nous avons utilisé le format de compression Zstd comme format de compression de données par défaut pendant le processus de mise à niveau de Spark, et avons également défini les données Shuffle sur la compression Zstd, ce qui a permis de réaliser d'importantes économies sur le stockage du cluster. Lorsqu'il est appliqué dans des scénarios de données publicitaires, le taux de compression a été amélioré de 3,3 fois. , économisant 76 % des coûts de stockage.
Ajoutez la phase de rééquilibrage pour éviter de générer des petits fichiers
Le problème des petits fichiers est un problème important dans Spark SQL : trop de petits fichiers exerceront une forte pression sur le Hadoop NameNode et affecteront la stabilité du cluster. Le framework informatique Spark natif ne dispose pas d’une bonne solution automatisée pour résoudre le problème des petits fichiers. À cet égard, nous avons également étudié certaines solutions industrielles et avons finalement utilisé la solution d'optimisation des petits fichiers fournie avec le service Kyuubi.
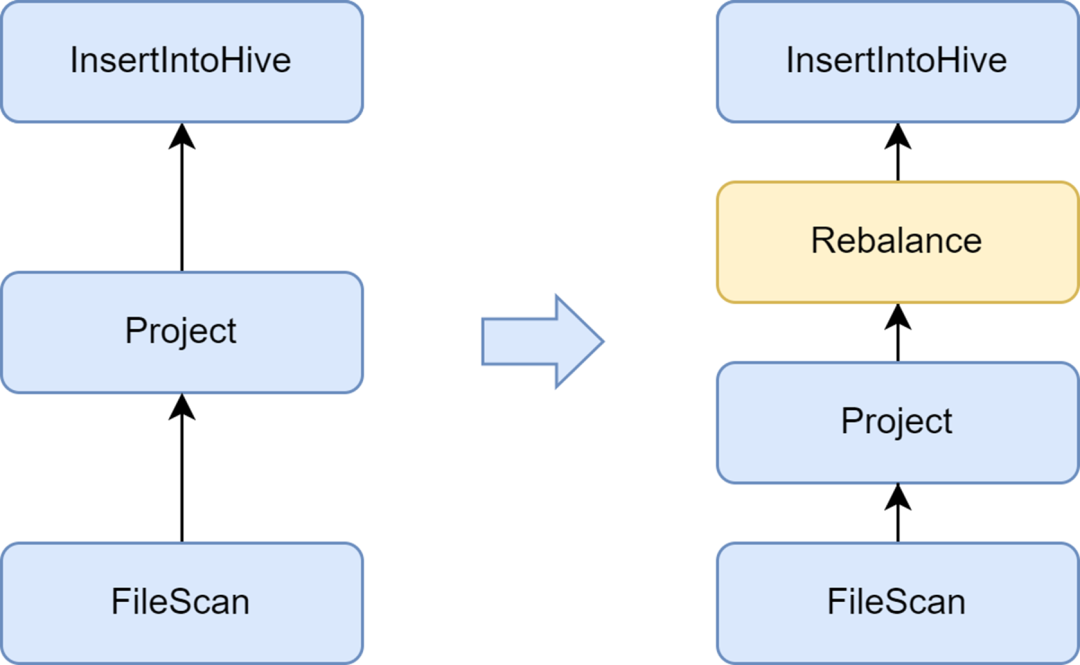
L'optimiseur insertRepartitionBeforeWrite fourni par Kyuubi peut insérer l'opérateur Rebalance avant l'opérateur Insert. Combiné avec la logique d'AQE pour fusionner automatiquement les petites partitions et diviser les grandes partitions, il réalise le contrôle de la taille du fichier de sortie et résout efficacement le problème des petits fichiers.
Après l'avoir activé, la taille moyenne du fichier de sortie de Spark SQL est optimisée de 10 Mo à 262 Mo, évitant ainsi la génération d'un grand nombre de petits fichiers.
Activer l'inférence du tri de répartition pour améliorer encore le taux de compression
Après avoir activé l’optimisation des petits fichiers, nous avons constaté que le stockage de données de certaines tâches devenait beaucoup plus volumineux. En effet, l'opération de rééquilibrage insérée dans l'optimisation des petits fichiers utilise des champs de partition ou des partitions aléatoires pour le partitionnement, et les données sont dispersées de manière aléatoire, ce qui entraîne une réduction de l'efficacité d'encodage du fichier au format Parquet, ce qui entraîne à son tour une réduction. dans le taux de compression du fichier.
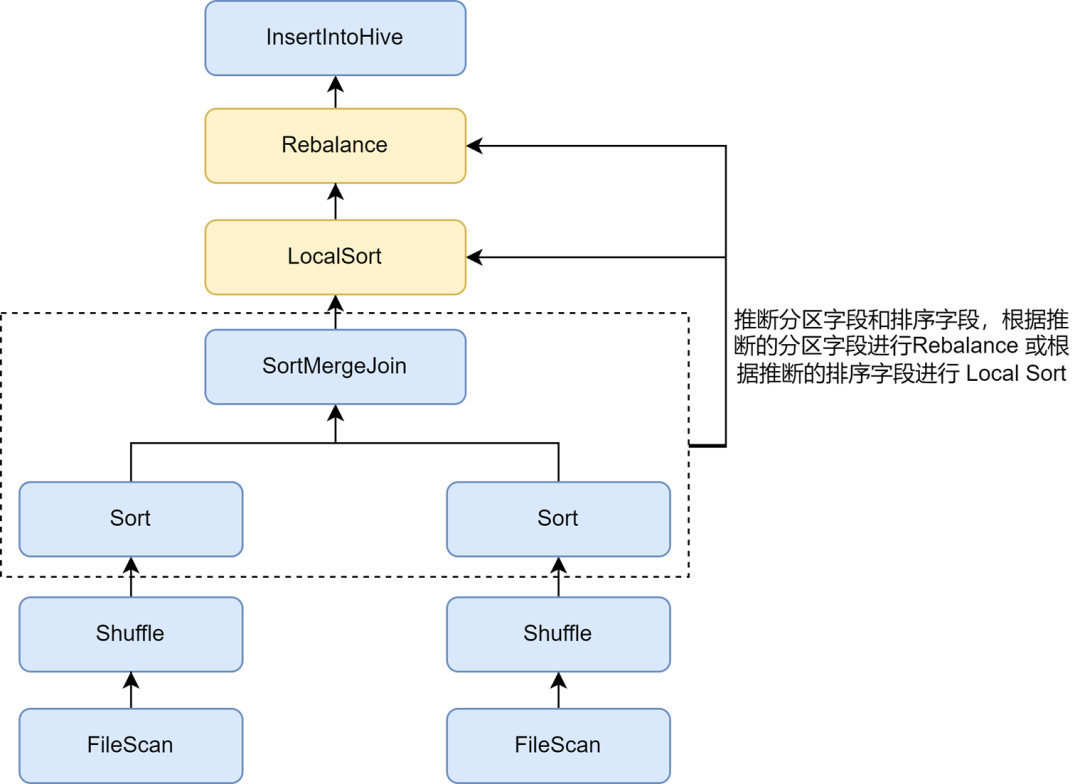
Dans les règles d'optimisation des petits fichiers Kyuubi, l'inférence automatique des partitions et des champs de tri peut être activée via le paramètre spark.sql.optimizer.inferRebalanceAndSortOrders.enabled Pour l'écriture de partition non dynamique, des opérateurs tels que Join, Aggregate et Sort dans le fichier. le plan de pré-exécution est utilisé. Les champs de partitionnement et de tri sont déduits des clés, et les champs de partition déduits sont utilisés pour le rééquilibrage, ou les champs de tri déduits sont utilisés pour le tri local avant le rééquilibrage, de sorte que la distribution des données du plan finalement inséré L'opérateur de rééquilibrage est aussi cohérent que possible avec le pré-plan et évite l'écriture. Les données entrantes sont dispersées de manière aléatoire, améliorant ainsi efficacement le taux de compression.
Activez l'optimisation de Zorder pour améliorer le taux de compression et l'efficacité des requêtes
Le tri Zorder est un algorithme de tri multidimensionnel. Pour les formats de stockage en colonnes tels que Parquet, des algorithmes de tri efficaces peuvent rendre les données plus compactes, améliorant ainsi le taux de compression des données. De plus, étant donné que des données similaires sont collectées dans la même unité de stockage, par exemple, la plage statistique min/max est plus petite, la quantité de données ignorées pendant le processus d'interrogation peut être augmentée, améliorant ainsi efficacement l'efficacité de l'interrogation.
L'optimisation du tri du clustering Zorder est implémentée dans Kyuubi. Les champs Zorder peuvent être configurés pour les tables, et le tri Zorder sera automatiquement ajouté lors de l'écriture. Pour les tâches existantes, la commande Optimiser est également prise en charge pour l'optimisation Zorder des données existantes. Nous avons ajouté l'optimisation Zorder en interne à certaines activités clés, réduisant ainsi l'espace de stockage des données de 13 % et améliorant les performances des requêtes de données de 15 %.
Introduire une configuration AQE indépendante dans la phase finale pour augmenter le parallélisme informatique
Au cours du processus de migration de certaines tâches Hive vers Spark, nous avons constaté que la vitesse d'exécution de certaines tâches ralentissait en fait. L'analyse a révélé que, parce que l'opérateur de rééquilibrage avait été inséré avant l'écriture et combiné avec Spark AQE pour contrôler les petits fichiers, nous avions modifié l'étincelle d'AQE. sql. La configuration adaptive.advisoryPartitionSizeInBytes est définie sur 1 024 Mo, ce qui entraîne une réduction du parallélisme de la phase Shuffle intermédiaire, ce qui ralentit l'exécution des tâches.
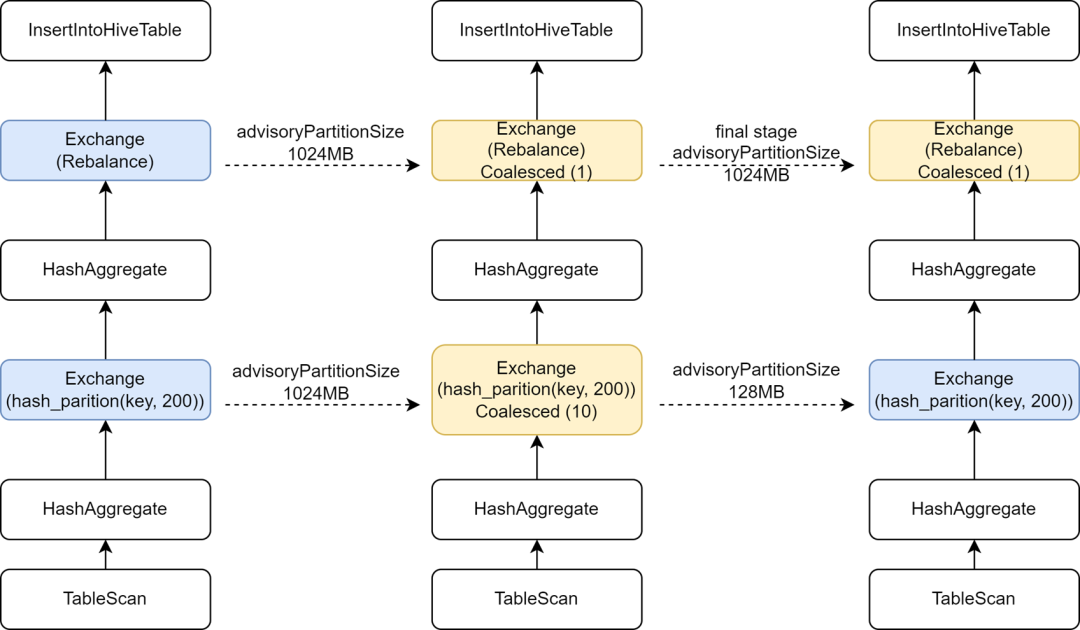
Kyuubi fournit une optimisation de la configuration de l'étape finale, permettant d'ajouter certaines configurations séparément pour l'étape finale, de sorte que nous puissions ajouter un AdvisoryPartitionSizeInBytes plus grand pour l'étape finale de contrôle des petits fichiers, et utiliser un AdvisoryPartitionSizeInBytes plus petit pour les étapes précédentes afin d'augmenter le parallélisme. de calculs et réduit le débordement du disque pendant l'étape Shuffle, améliorant ainsi l'efficacité du calcul. Après l'ajout de cette configuration, le temps d'exécution global des tâches Spark SQL est réduit de 25 % et les ressources sont économisées d'environ 9 %.
Déduire l'écriture dynamique de tâches sur une seule partition pour éviter des partitions aléatoires trop volumineuses
Pour l'écriture de partition dynamique, l'optimisation des petits fichiers Kyuubi utilisera le champ de partition dynamique pour le rééquilibrage. Pour les tâches qui utilisent le partitionnement dynamique pour écrire sur une seule partition, toutes les données Shuffle seront écrites sur la même partition Shuffle. iQIYI utilise en interne Apache Uniffle comme service de lecture aléatoire à distance. Les grandes partitions provoqueront un point de pression unique sur le serveur aléatoire, et déclencheront même une limitation de courant et entraîneront une réduction de la vitesse d'écriture. À cette fin, nous avons développé une règle d'optimisation pour capturer les conditions de filtre de partition écrites et déduire si les données d'une seule partition sont écrites de manière dynamique. Pour de telles tâches, nous n'utilisons plus de champs de partition dynamiques pour le rééquilibrage, mais utilisons des données aléatoires ; Rééquilibrer , cela évite de générer une partition Shuffle plus grande. Pour plus de détails, voir : [KYUUBI-5079].
-
Détection et interception SQL anormales
Lorsqu'il y a des problèmes de qualité des données ou que les utilisateurs ne sont pas familiers avec la distribution des données, il est facile de soumettre du code SQL anormal, ce qui peut entraîner un important gaspillage de ressources et une faible efficacité informatique. Nous avons ajouté des indicateurs de surveillance au service Spark SQL, et détecté et intercepté certains scénarios informatiques anormaux.
Limiter les requêtes volumineuses
Chez iQiyi, les analystes de données soumettent des analyses de requêtes SQL pour ad hoc via la plateforme de requêtes ad hoc Magic Mirror, qui offre aux utilisateurs des fonctionnalités de requête de deuxième niveau. Nous utilisons le moteur partagé de Kyuubi comme moteur de traitement back-end pour éviter de démarrer un nouveau moteur pour chaque requête, ce qui gaspille du temps de démarrage et des ressources informatiques. La présence permanente du moteur partagé en arrière-plan peut offrir aux utilisateurs une expérience interactive plus rapide.
Pour le moteur partagé, plusieurs requêtes s'approprieront les ressources les unes des autres. Même si nous activons l'allocation dynamique des ressources, il existe toujours des situations où les ressources sont occupées par certaines requêtes volumineuses, entraînant le blocage d'autres requêtes. À cet égard, nous avons implémenté la fonction d'interception des requêtes volumineuses dans le plug-in Spark de Kyuubi. En analysant des opérations telles que Table Scan dans le plan d'exécution SQL, nous pouvons compter le nombre de partitions interrogées et la quantité de données analysées. dépasse le seuil spécifié, il sera déterminé pour les requêtes volumineuses et l'exécution d'interception.
Sur la base des résultats de la détermination, la plateforme Magic Mirror bascule les requêtes volumineuses vers un moteur indépendant pour exécution. De plus, Magic Mirror définit un délai d'attente d'une minute. Les tâches qui utilisent le moteur partagé pour exécuter des heures supplémentaires seront annulées et automatiquement converties en exécution de moteur indépendant. L'ensemble du processus est insensible aux utilisateurs, empêchant efficacement le blocage des requêtes ordinaires et permettant aux requêtes volumineuses de continuer à s'exécuter en utilisant des ressources indépendantes.
Surveiller le gonflement des données
Certaines opérations telles que Explode, Join et Count Distinct dans Spark SQL entraîneront une expansion des données. Si l'expansion des données est très importante, cela peut provoquer un débordement de disque, un GC complet ou même un MOO, et également aggraver l'efficacité du calcul. Nous pouvons facilement voir si l'expansion des données s'est produite en fonction du nombre d'indicateurs de lignes de sortie des nœuds précédents et suivants dans le diagramme du plan d'exécution SQL de la page de l'onglet SQL de l'interface utilisateur Spark.

Les indicateurs du graphique du plan d'exécution Spark SQL sont signalés au pilote via les événements d'exécution de tâche et les événements Executor Heartbeat, et sont regroupés dans le pilote.
Afin de collecter les indicateurs d'exécution plus rapidement, nous avons étendu SQLOperationListener dans Kyuubi, écouté l'événement SparkListenerSQLExecutionStart pour maintenir sparkPlanInfo, et en même temps écouté l'événement SparkListenerExecutorMetricsUpdate, capturé les changements dans les indicateurs statistiques SQL du nœud en cours d'exécution. , et comparé le nombre d'indicateurs de lignes de sortie du nœud en cours d'exécution et l'indicateur de nombre de lignes de sortie des nœuds enfants précédents, calculer le taux d'expansion des données pour déterminer si une expansion importante des données se produit, et collecter des événements anormaux ou intercepter des tâches anormales lorsque. l'expansion des données se produit.
Position Rejoindre la touche d'inclinaison
Le problème d'asymétrie des données est un problème courant dans Spark SQL et affecte les performances. Bien qu'il existe certaines règles pour optimiser automatiquement l'asymétrie des données dans Spark AQE, elles ne sont pas toujours efficaces. De plus, le problème d'asymétrie des données est probablement dû à l'utilisateur. incompréhension des données. Une mauvaise logique d'analyse est écrite parce que la compréhension n'est pas assez profonde, ou que les données elles-mêmes ont des problèmes de qualité des données, il est donc nécessaire pour nous d'analyser la tâche de biais des données et de localiser la valeur clé asymétrique.

Nous pouvons facilement déterminer si une asymétrie des données s'est produite dans la tâche grâce aux statistiques des tâches de scène dans l'interface utilisateur Spark. Comme le montre la figure ci-dessus, la valeur maximale de la durée de la tâche et de la lecture aléatoire dépasse la valeur du 75e centile, il est donc évident que les données. un biais s’est produit.
Cependant, pour calculer les valeurs de clé qui provoquent une asymétrie dans la tâche d'asymétrie, il est généralement nécessaire de diviser manuellement le SQL, puis de calculer la distribution des clés à chaque étape à l'aide de Count Group By Keys pour déterminer la valeur de clé asymétrique. est généralement une tâche relativement longue.
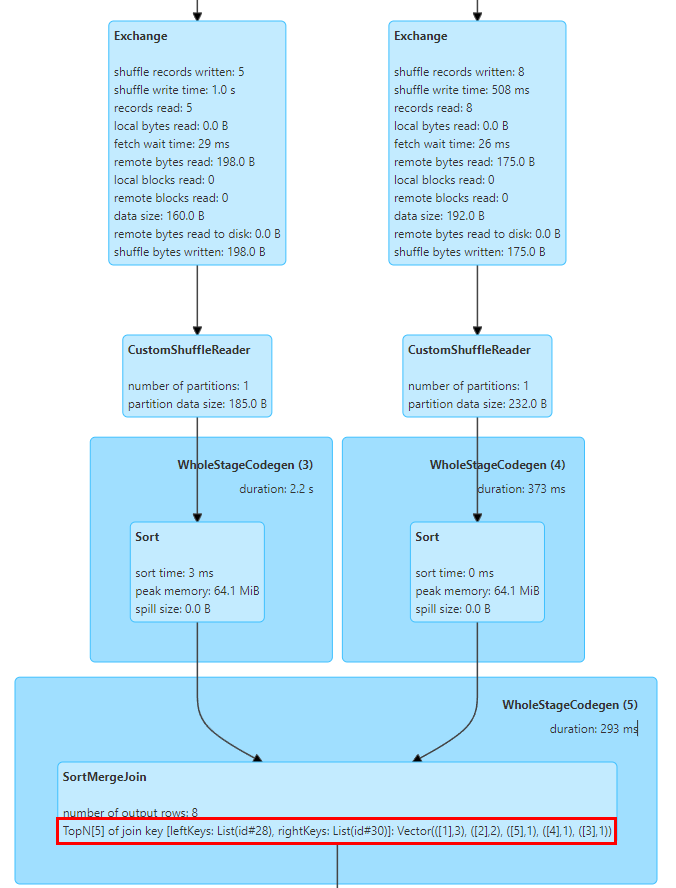
À cet égard, nous avons implémenté les statistiques TopN Keys dans SortMergeJoinExec.
L'implémentation de SortMergeJoin consiste à trier d'abord la clé, puis à effectuer l'opération Join, afin que nous puissions facilement compter les valeurs TopN de la clé par accumulation.
Nous avons implémenté un accumulateur TopNAccumulator, qui maintient en interne un objet de type Map[String, Long]. Il utilise la valeur de la clé de jointure comme clé de la carte et conserve la valeur Count de la clé dans la valeur de la carte, pour chaque ligne de données. Pour le calcul cumulatif, puisque les données sont en ordre, il suffit d'accumuler les clés insérées et, lors de l'insertion de nouvelles clés, de déterminer si la valeur N est atteinte et d'éliminer la plus petite clé.
De plus, Spark ne prend en charge que l'affichage des indicateurs statistiques de type Long. Nous avons également modifié la logique d'affichage des indicateurs statistiques SQL pour l'adapter aux valeurs de type Map.
La figure ci-dessus montre les 5 principales valeurs de clé de jointure des deux tables pour Join, où la clé est le champ id et il y a 3 lignes avec id=1.
Après une série de recherches et de tests, nous avons constaté que Spark SQL a considérablement amélioré les performances et l'utilisation des ressources par rapport à Hive. Cependant, nous avons également rencontré de nombreux problèmes lors de la migration de Hive SQL vers Spark. En apportant quelques modifications de compatibilité et adaptations au service Spark SQL, nous avons réussi à migrer la plupart des tâches Hive SQL vers Spark.
La prise en charge par Spark SQL de Hive UDF présente quelques problèmes en utilisation réelle. Par exemple, les entreprises utilisent souvent la fonction de réflexion pour appeler des méthodes statiques Java afin de traiter les données. Lorsqu'une exception se produit lors de l'appel de réflexion, Hive renvoie une valeur NULL et Spark SQL lève une exception et provoque l'échec de la tâche. À cette fin, nous avons modifié la fonction de réflexion de Spark pour capturer les exceptions d'appel de réflexion et renvoyer des valeurs NULL, cohérentes avec Hive.
Un autre problème est que Spark SQL ne prend pas en charge le constructeur privé de Hive UDAF, ce qui entraînera l'échec de l'initialisation de l'UDAF de certaines entreprises. Nous avons transformé la logique d'enregistrement des fonctions de Spark pour prendre en charge les constructeurs privés Hive UDAF.
-
Compatibilité des fonctions intégrées
Il existe des différences dans la logique de calcul de la fonction GROUPING_ID intégrée entre Spark SQL et Hive version 1.2, ce qui entraîne une incohérence des données pendant la phase de double exécution. Dans la version Hive 3.1, la logique de calcul de cette fonction a été modifiée pour être cohérente avec la logique de Spark, nous encourageons donc les utilisateurs à mettre à jour la logique SQL et à adapter la logique de cette fonction dans Spark pour garantir l'exactitude de la logique de calcul.
De plus, la fonction de hachage de Spark SQL utilise l'algorithme de hachage Murmur3, qui est différent de la logique d'implémentation de Hive. Nous recommandons aux utilisateurs d'enregistrer manuellement la fonction de hachage intégrée de Hive pour garantir la cohérence des données avant et après la migration.
-
Compatibilité de conversion de type
Spark SQL a introduit la spécification ANSI SQL depuis la version 3.0. Par rapport à Hive SQL, elle impose des exigences plus strictes en matière de cohérence des types. Par exemple, la conversion automatique entre les types String et numériques est interdite. Afin d'éviter les anomalies de conversion automatique causées par des définitions de types de données non standard dans l'entreprise, nous recommandons aux utilisateurs d'ajouter CAST à SQL pour une conversion explicite. Pour les transformations à grande échelle, la configuration spark.sql.storeAssignmentPolicy=LEGACY peut être temporairement ajoutée. pour réduire la vérification de type du niveau Spark SQL afin d'éviter les exceptions de migration.
La fonction str_to_map dans Hive conservera automatiquement la dernière valeur des clés répétées, tandis que dans Spark, une exception sera levée et la tâche échouera. À cet égard, nous recommandons aux utilisateurs de vérifier la qualité des données en amont ou d'ajouter la configuration spark.sql.mapKeyDedupPolicy=LAST_WIN pour conserver la dernière valeur en double, cohérente avec Hive.
-
Autre compatibilité syntaxique
La syntaxe Hint de Spark SQL et Hive SQL est incompatible et les utilisateurs doivent supprimer manuellement les configurations pertinentes lors de la migration. Les astuces courantes de Hive incluent la diffusion de petites tables Étant donné que la fonction Spark AQE est plus intelligente pour la diffusion de petites tables et l'optimisation de l'inclinaison des tâches, aucune configuration supplémentaire n'est généralement requise par l'utilisateur.
Il existe également des problèmes de compatibilité entre Spark SQL et les instructions DDL de Hive. Nous recommandons généralement aux utilisateurs d'utiliser la plateforme pour effectuer des opérations DDL sur les tables Hive. Pour certaines commandes d'opération de partition, telles que : la suppression de partitions inexistantes [KYUUBI-1583], les instructions Alter Partition inégales et d'autres problèmes de compatibilité, nous avons également étendu le plug-in Spark pour des raisons de compatibilité.
Résumé et perspectives
À l'heure actuelle, nous avons migré la plupart des tâches Hive de l'entreprise vers Spark, Spark est donc devenu le principal moteur de traitement hors ligne d'iQiyi. Nous avons réalisé des travaux préliminaires d'audit des ressources et d'optimisation des performances sur le moteur Spark, ce qui a permis à l'entreprise de réaliser des économies considérables. À l’avenir, nous continuerons d’optimiser les performances et la stabilité des services Spark et des frameworks informatiques. Nous favoriserons également davantage la migration des très rares tâches Hive restantes.
Avec la mise en œuvre du lac de données de l'entreprise, de plus en plus d'entreprises migrent vers le lac de données Iceberg. Alors qu'Iceberg continue d'améliorer les fonctions de Spark DataSourceV2, Spark 3.1 ne peut plus répondre à certains nouveaux besoins d'analyse de lacs de données, nous sommes donc sur le point de passer à Spark 3.4. Dans le même temps, nous avons également mené des recherches sur certaines nouvelles fonctionnalités, telles que le filtre d'exécution, la jointure partitionnée du stockage, etc., dans l'espoir d'améliorer encore les performances du framework informatique Spark en fonction des besoins de l'entreprise.
De plus, afin de promouvoir le processus de calcul Big Data cloud natif, nous avons introduit Apache Uniffle, un service de lecture à distance (RSS). Au cours de l'utilisation, nous avons constaté des problèmes de performances lorsqu'il est combiné avec Spark AQE, tels que l'optimisation du biais BroadcastHashJoin [SPARK-44065], le problème de grande partition mentionné précédemment et la manière de mieux effectuer la planification des partitions AQE. Nous continuerons à y travailler. à l’avenir, cela conduira à une recherche et une optimisation plus approfondies.
Peut-être que tu veux aussi voir

