
Introduction au contexte
Dans un système d'entreprise récent, la base de données esclave était dans un état retardé et ne pouvait pas rattraper la base de données principale, ce qui entraînait des risques commerciaux plus importants. Du point de vue des ressources, l'utilisation du processeur, des E/S et du réseau de la bibliothèque esclave est faible et il n'existe aucune situation dans laquelle la lecture est ralentie par une pression excessive du serveur. La lecture parallèle est activée sur la bibliothèque esclave. La bibliothèque montre qu'il n'y a pas de threads de lecture bloquants, la lecture continue ; l'analyse du fichier journal du relais révèle qu'il n'y a pas de lecture de transactions importantes.
l'analyse des processus
Confirmation du phénomène
J'ai reçu des commentaires de mes collègues d'exploitation et de maintenance selon lesquels un ensemble de bibliothèques esclaves était très retardé. J'ai fourni show slave statusdes informations de capture d'écran du retard.
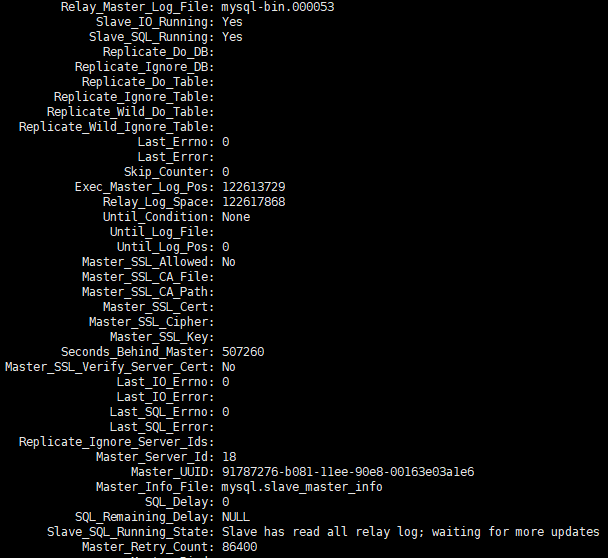
Après avoir continué à observer show slave statusles changements pendant un certain temps, j'ai découvert que les informations sur les points de vente changeaient constamment, que Seconds_Behind_master changeait également constamment et que la tendance globale continuait de croître.
L'utilisation des ressources
Après avoir observé l'utilisation des ressources du serveur, nous pouvons voir que l'utilisation est très faible.

En observant le processus esclave, vous ne pouvez voir qu'un seul thread lire le travail.
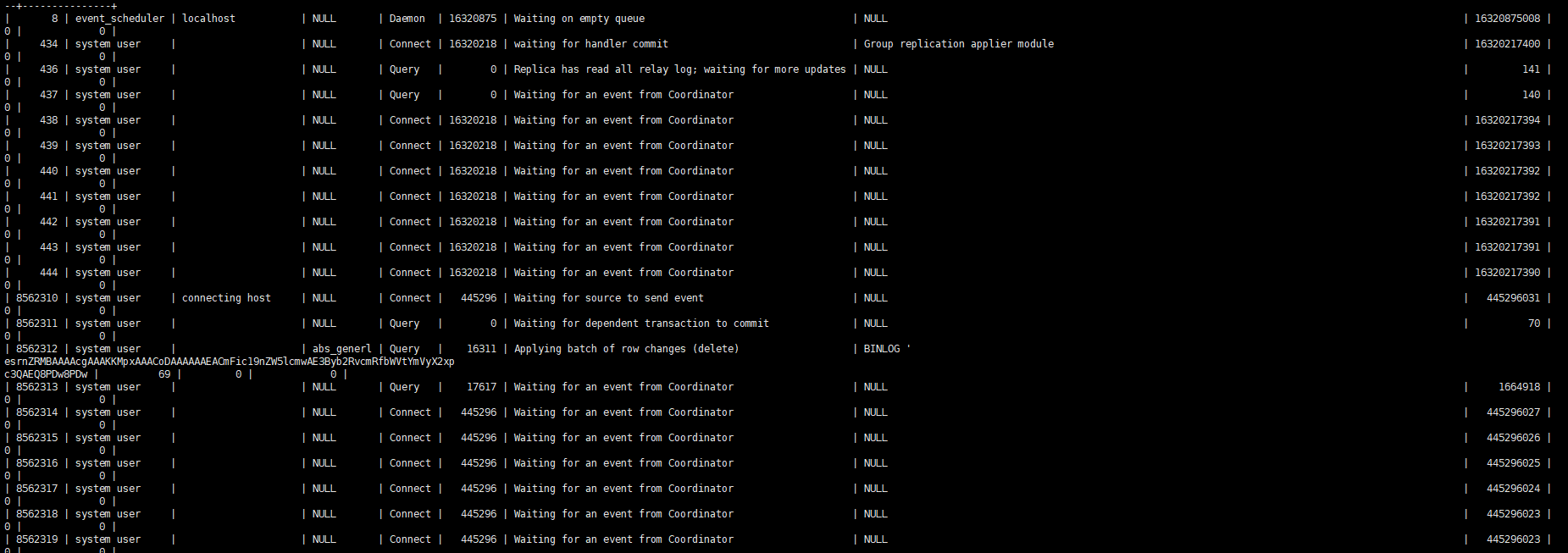
Description des paramètres de lecture parallèle
Situé dans la bibliothèque principalebinlog_transaction_dependency_tracking=WRITESET
Dans la bibliothèque des esclaves, slave_parallel_type=LOGICAL_CLOCKle etslave_parallel_workers=64
comparaison du journal des erreurs
Obtenez le journal de lecture parallèle à partir du journal des erreurs pour analyse
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
Pour une explication détaillée des informations ci-dessus, veuillez vous référer à Surveillance des performances MTS. Que savez-vous ?
Suppression des statistiques qui se produisaient moins souvent et affichage de la comparaison de certaines données clés.
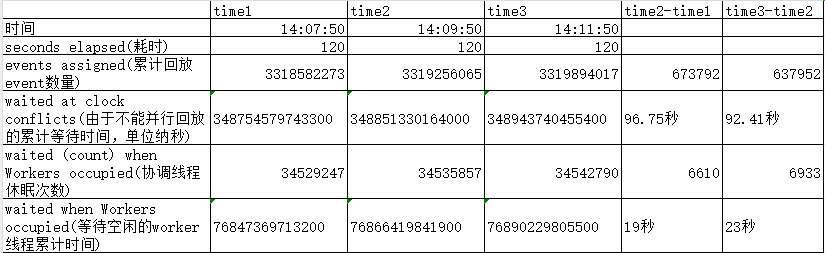
On peut constater qu'au temps naturel de 120, le thread de coordination de lecture attend plus de 90 secondes car il ne peut pas jouer en parallèle, et près de 20 secondes car il n'y a pas de thread de travail inactif à attendre. Cela se traduit par seulement environ 10 secondes. pour que le fil de coordination fonctionne.
Statistiques de parallélisme
Comme nous le savons tous, la lecture parallèle mysql à partir de la bibliothèque s'appuie principalement sur le dernier_commis dans le binlog pour porter des jugements. Si le dernier_commis de la transaction est le même, on peut essentiellement considérer que ces transactions peuvent être lues en parallèle. les statistiques approximatives d'obtention d'un journal de relais de l'environnement pour une lecture parallèle.
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
La première commande ci-dessus compte le nombre de transactions avec le même last_commit entre 1 et 10, c'est-à-dire que le degré de lecture parallèle est faible ou ne peut pas être lu en parallèle. Le nombre total de ces transactions est de 235 703, soit 43 %. Analyse détaillée des transactions avec un degré de lecture parallèle relativement faible. D'après la distribution des transactions, on peut voir que cette partie de last_commit est essentiellement une seule transaction. Ils doivent attendre la fin de la lecture de la transaction de pré-commande avant de pouvoir le faire. le lire. Cela empêchera l'attente du thread de coordination observée dans le journal précédent de lire en parallèle et d'entrer dans l'état d'attente lorsque le temps est relativement long.
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
La deuxième commande compte le nombre total de transactions avec plus de 10 transactions identiques last_commit, le nombre est 314694, représentant 57 %. Elle analyse en détail ces transactions avec un degré relativement élevé de lecture parallèle. entre 6500 et 9000. nombre de transactions
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
Introduction au mécanisme last_commit
Les paramètres de la bibliothèque principale binlog_transaction_dependency_trackingsont utilisés pour spécifier comment générer les informations de dépendance écrites dans le journal binaire pour aider la bibliothèque esclave à déterminer quelles transactions peuvent être exécutées en parallèle. Autrement dit, ce paramètre est utilisé pour contrôler le mécanisme de génération de last_commit. Les valeurs facultatives du paramètre sont COMMIT_ORDER, WRITESET et SESSION_WRITESET. À partir du code suivant, il est facile de voir les trois relations entre paramètres :
- L'algorithme de base est COMMIT_ORDER
- L'algorithme WRITESET est calculé à nouveau sur la base de COMMIT_ORDER
- L'algorithme SESSION_WRITESET est calculé à nouveau en fonction de WRITESET
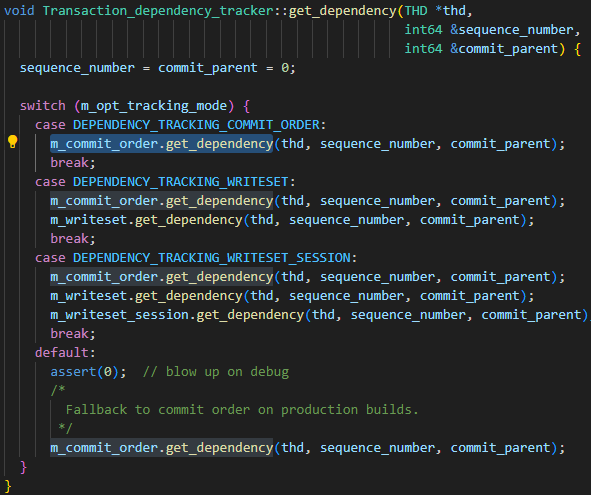
Puisque mon instance est définie sur WRITESET, concentrez-vous simplement sur l'algorithme COMMIT_ORDER et l'algorithme WRITESET.
COMMIT_ORDER
Règle de calcul COMMIT_ORDER : Si deux transactions sont soumises en même temps sur le nœud maître, cela signifie qu'il n'y a pas de conflit entre les données des deux transactions, alors elles peuvent également être exécutées en parallèle sur le nœud esclave. Un cas typique idéal. est comme suit.
| Session 1 | séance-2 |
|---|---|
| COMMENCER | COMMENCER |
| INSÉRER les valeurs t1 (1) | |
| INSÉRER les valeurs t2 (2) | |
| valider (group_commit) | valider (group_commit) |
Mais pour MySQL, group_commit est un comportement interne. Tant que la session-1 et la session-2 exécutent la validation en même temps, qu'elles soient ou non fusionnées en interne dans group_commit, les données des deux transactions sont essentiellement sans conflit ; un pas en arrière, tant que la session-1 exécute la validation et qu'aucune nouvelle donnée n'est écrite dans la session-2, les deux transactions n'ont toujours pas de conflits de données et peuvent toujours être répliquées en parallèle.
| Session 1 | séance-2 |
|---|---|
| COMMENCER | COMMENCER |
| INSÉRER les valeurs t1 (1) | |
| INSÉRER les valeurs t2 (2) | |
| commettre | |
| commettre |
Pour les scénarios avec davantage de threads simultanés, ces threads peuvent ne pas être en mesure de se répliquer en parallèle en même temps, mais certaines transactions le peuvent. En prenant la séquence d'exécution suivante comme exemple, après les validations de la session-3, la session-2 n'a pas de nouvelles écritures, donc les deux transactions peuvent être répliquées en parallèle ; après les validations de la session-3, la session-1 insère une nouvelle donnée, le conflit de données ne peut pas être déterminé pour le moment, donc les transactions de la session-3 et de la session-1 ne peuvent pas être répliquées en parallèle, mais une fois la session-2 soumise, aucune nouvelle donnée n'est écrite après la session-1, donc la session-2 et la session-1 ; sont à nouveau Peut être répliqué en parallèle. Par conséquent, dans ce scénario, la session 2 peut être répliquée en parallèle avec la session 1 et la session 3 respectivement, mais les trois transactions ne peuvent pas être répliquées en parallèle en même temps.
| Session 1 | séance-2 | séance-3 |
|---|---|---|
| COMMENCER | COMMENCER | COMMENCER |
| INSÉRER les valeurs t1 (1) | INSÉRER les valeurs t2 (1) | INSÉRER les valeurs t3 (1) |
| INSÉRER les valeurs t1 (2) | INSÉRER les valeurs t2 (2) | |
| commettre | ||
| INSÉRER les valeurs t1 (3) | ||
| commettre | ||
| commettre |
ÉCRITURE
Il s'agit en fait d'une combinaison de commit_order + writeset. Il calculera d'abord une valeur last_committee via commit_order, puis calculera une nouvelle valeur via writeset, et enfin prendra la valeur la plus petite entre les deux comme valeur last_committee de la transaction finale gtid.
Dans MySQL, writeset est essentiellement une valeur de hachage calculée pour nom_schéma + nom_table + clé_primaire/clé_unique. Lors de l'exécution de l'instruction DML, avant de générer row_event via binlog_log_row, toutes les clés primaires/clés uniques de l'instruction DML auront des valeurs de hachage calculées. séparément et ajouté à la liste writeset de la transaction elle-même. Et s'il existe une table sans clé primaire/index unique, has_missing_keys=true sera également défini pour la transaction.
Le paramètre est défini sur WRITESET, mais il ne peut pas être utilisé. Les restrictions sont les suivantes
- Instructions ou tables non-DDL avec des clés primaires ou des clés uniques ou des transactions vides
- L'algorithme de hachage utilisé par la session en cours est cohérent avec celui de la carte de hachage.
- Aucune clé étrangère utilisée
- La capacité de la carte de hachage ne dépasse pas le paramètre binlog_transaction_dependency_history_size. Lorsque les quatre conditions ci-dessus sont remplies, l'algorithme WRITESET peut être utilisé. Si l'une des conditions n'est pas remplie, il dégénère en méthode de calcul COMMIT_ORDER.
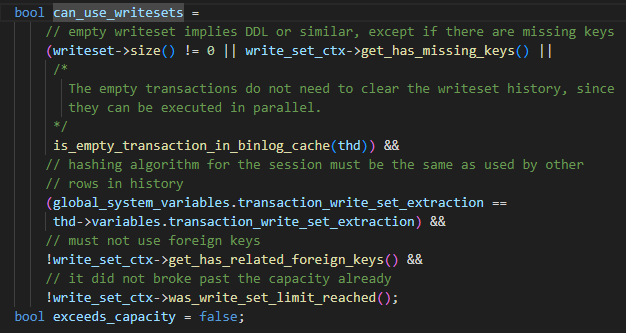
L'algorithme spécifique WRITESET est le suivant, lorsque la transaction est soumise :
-
last_commit est défini sur m_writeset_history_start, cette valeur est le plus petit numéro de séquence dans la liste m_writeset_history
-
Parcourez la liste des transactions d'écriture
a Si un writeset n'existe pas dans la liste m_writeset_history globale, construisez un objet pair<writeset, séquence_number> de la transaction en cours et insérez-le dans la liste globale m_writeset_history.
b. S'il existe, alors last_commit=max (last_commit, la valeur du numéro de séquence de l'ensemble d'écriture historique), et en même temps mettez à jour le numéro de séquence correspondant à l'ensemble d'écriture dans m_writeset_history avec la valeur de transaction actuelle.
-
Si has_missing_keys=false, c'est-à-dire que toutes les tables de données de la transaction contiennent des clés primaires ou des index uniques, alors la valeur minimale calculée par commit_order et writeset sera utilisée comme valeur finale last_commit.
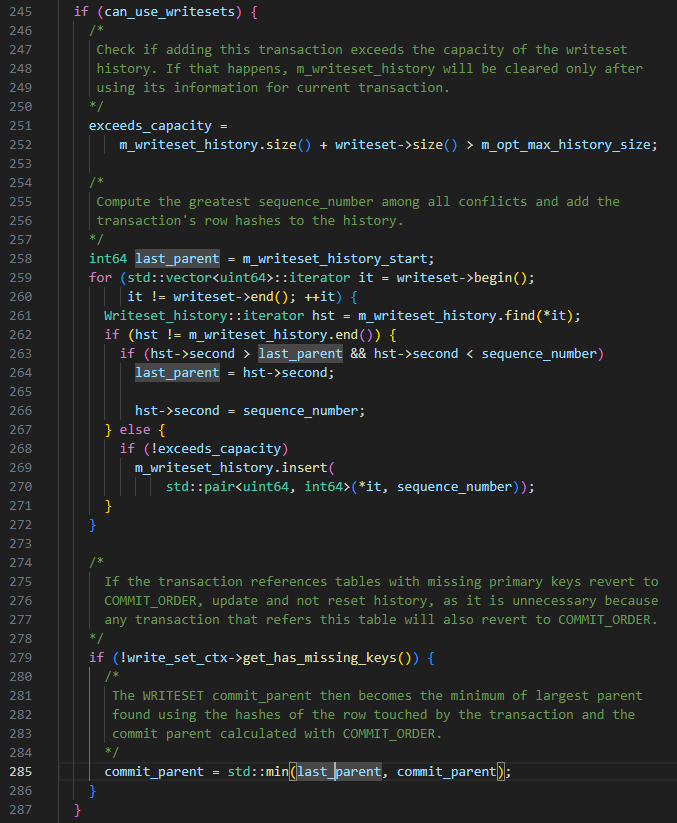
CONSEILS : sur la base des règles WRITESET ci-dessus, il y aura une situation dans laquelle le last_commit de la transaction soumise plus tard est plus petit que la transaction soumise en premier.
Analyse des conclusions
Description des conclusions
Selon les restrictions d'utilisation de WRITESET, nous avons comparé le journal de relais et les structures de table impliquées dans la transaction, et analysé la composition de la transaction d'un seul last_commit et avons trouvé les deux situations suivantes :
- Il existe un conflit de données entre les données impliquées dans la transaction unique last_commit et le numéro_séquence.
- La table impliquée dans une seule transaction last_commit n'a pas de clé primaire et il existe de nombreuses transactions de ce type.
De l'analyse ci-dessus, nous pouvons conclure qu'il y a trop de transactions dans la table sans clé primaire, ce qui entraîne la dégénérescence de WRITESET en COMMIT_ORDER. Puisque la base de données est une application TP, les transactions sont soumises rapidement et les soumissions multiples de transactions ne peuvent pas être garanties. être dans un cycle de validation, ce qui entraîne COMMIT_ORDER Les lectures répétées last_committe générées par le mécanisme sont très faibles. La bibliothèque esclave ne peut lire ces transactions qu'en série, ce qui entraîne des retards de lecture.
Mesures d'optimisation
- Modifiez les tables du côté métier et ajoutez des clés primaires aux tables associées lorsque cela est possible.
- Essayez d'augmenter les paramètres binlog_group_commit_sync_delay et binlog_group_commit_sync_no_delay_count de 0 à 10 000. En raison de restrictions environnementales particulières, cet ajustement ne prend pas effet. Différents scénarios peuvent avoir des performances différentes.
Profitez de GreatSQL :)
À propos de GreatSQL
GreatSQL est une base de données open source nationale indépendante adaptée aux applications financières. Elle possède de nombreuses fonctionnalités de base telles que des performances élevées, une fiabilité élevée, une grande facilité d'utilisation et une sécurité élevée. Elle peut être utilisée en remplacement facultatif de MySQL ou du serveur Percona. et est utilisé dans des environnements de production en ligne, entièrement gratuit et compatible avec MySQL ou Percona Server.
Liens connexes : Communauté GreatSQL Gitee GitHub Bilibili
Communauté GreatSQL :

Suggestions et commentaires de récompenses de la communauté : https://greatsql.cn/thread-54-1-1.html
Détails de la soumission primée du blog communautaire : https://greatsql.cn/thread-100-1-1.html
(Si vous avez des questions sur l'article ou si vous avez des idées uniques, vous pouvez accéder au site Web officiel de la communauté pour les poser ou les partager ~)
Groupe d'échange technique :
Groupe WeChat et QQ :
Groupe QQ : 533341697
Groupe WeChat : ajoutez GreatSQL Community Assistant (WeChat ID : wanlidbc) comme ami et attendez que l'assistant de communauté vous ajoute au groupe.