1.Résumé
La reconnaissance fine d’images d’oiseaux vise à obtenir une classification précise des images d’oiseaux et constitue un travail de base dans le suivi visuel des robots. Compte tenu de l’importance de la surveillance et de la conservation des oiseaux en voie de disparition pour protéger les oiseaux en voie de disparition, des méthodes automatisées sont nécessaires pour faciliter la surveillance des oiseaux. Dans ce travail, nous proposons une nouvelle méthode de surveillance des oiseaux basée sur le suivi visuel du robot, qui adopte un modèle sensible à l'affinité appelé TBNet, qui combine les architectures CNN et Transformer avec le module de sélection de fonctionnalités (FS). Plus précisément, CNN est utilisé pour extraire des informations de surface. Utilisez Transformers pour développer des affinités sémantiques abstraites. Le module FS est introduit pour révéler les caractéristiques d'identification .
Des expériences approfondies montrent que l'algorithme peut atteindre des performances de pointe sur l'ensemble de données cub-200-201 (91,0 %) et sur l'ensemble de données nabbirds (90,9 %).
2. Question
La reconnaissance fine d’images d’oiseaux est une tâche de base pour le suivi visuel et le traitement d’images des robots [1-3]. Le suivi autonome des oiseaux par des robots sans intervention humaine est crucial pour la conservation des oiseaux en voie de disparition. Actuellement, certains oiseaux en voie de disparition sont sur le point de disparaître en raison de la menace de dégradation de l'environnement. Par conséquent, la surveillance et la protection des oiseaux en voie de disparition revêtent une grande importance pour la conservation des oiseaux. Sachant que près de la moitié des populations d'oiseaux de la planète sont en déclin et que 13 % d'entre elles sont « dans une situation très grave » [4], la protection des oiseaux menacés fait l'objet d'une attention croissante. Afin de renforcer la protection des oiseaux, la surveillance des populations d'oiseaux est devenue un point chaud de la recherche. Cependant, cette tâche s’est avérée difficile en raison des conditions extrêmes sur le terrain, telles que les températures élevées sous les tropiques et l’humidité élevée dans les forêts tropicales. Traditionnellement, les ornithologues amateurs observent et enregistrent manuellement des informations sur les oiseaux en voie de disparition dans leurs habitats, ce qui représente une tâche longue et laborieuse. Ces dernières années, avec le développement de l’intelligence artificielle, de nombreuses méthodes d’apprentissage profond ont été proposées pour la classification fine des images d’oiseaux (FBIC). Par conséquent, les tâches en aval telles que la surveillance des oiseaux échouent.
Grâce à une observation minutieuse de l’apparence des oiseaux, nous avons découvert l’affinité entre différentes parties des oiseaux, ce qui est utile pour la recherche FBIC. Comme le montre la figure 1, la combinaison de la tête et du bec d'un oiseau ou le motif de couleur sur la tête, les ailes et la queue d'un oiseau. Ces relations d’affinité peuvent être utilisées comme caractéristiques discriminantes du FBIC.

2.1 Découverte
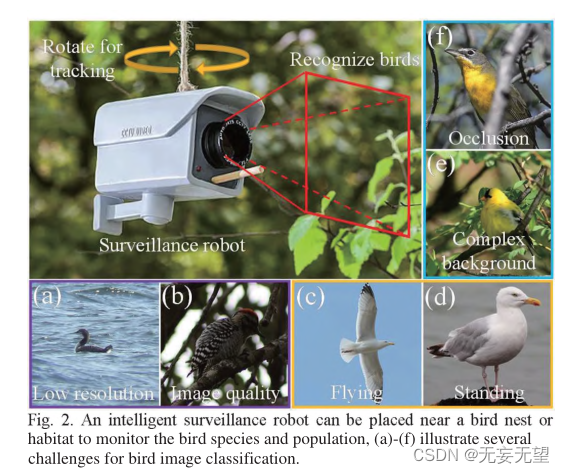
Cependant, l'identification des oiseaux dans la nature se heurte également à certains défis. Premièrement, la qualité de l’image varie en raison de l’environnement extrêmement sauvage. Par exemple, les images prises à distance peuvent donner une faible résolution (Figure 2(a)) ou des images prises sous un faible éclairage (Figure 2(a)). 2(b)), deuxièmement, il y a des poses d'oiseaux arbitraires. Par exemple, comme on peut le voir sur les figures 2(e) et 2(d), la première image montre un goéland argenté en vol, tandis que la deuxième image montre un goéland argenté debout. Sur chaque image, les oiseaux semblent avoir une apparence différente, une autre source de difficultés pour le FBIC. Troisièmement, en raison de la dissimulation et de la complexité des arrière-plans sauvages, les oiseaux peuvent se trouver parmi les branches et les feuilles (Figure 2(e)), ou peuvent être observés par les branches (Figure 2(f)), ce qui rend la classification des images d'oiseaux difficile. .
2.2 Développement
Puisqu'il est d'une grande importance d'identifier les affinités sémantiques dépendantes à long terme entre les images d'oiseaux, Transformer est un langage qui est intrinsèquement efficace pour explorer les détails microscopiques à grain fin et les relations sémantiques microscopiques dépendantes à long terme dans les images. Transformer[5] était à l’origine utilisé pour le traitement du langage naturel. Puis il s'est inspiré du domaine de la vision par ordinateur. Carion et al. [6] ont proposé une méthode de détection de cible de bout en bout basée sur Transformer. Dans [7], Dosovitskiy et al. ont proposé Vision Transformer (ViT), qui a été appliqué pour la première fois et a prouvé que le Transformer pur est une méthode qui peut rivaliser avec CNN et La structure qui occupe sa place. Par conséquent, la structure ViT est utilisée comme colonne vertébrale de notre modèle pour exploiter les affinités des tâches FBIC.
2.3 Innovations
Dans ce travail, nous proposons une méthode qui peut être utilisée pour les robots intelligents de surveillance des oiseaux (Fig. 2), qui peuvent être installés à proximité de mangeoires, de nids d'oiseaux ou d'habitats d'oiseaux. Le robot peut tourner verticalement et horizontalement pour offrir un champ de vision plus large pour détecter les oiseaux. Le robot enregistre des images à intervalles réguliers, augmentant ainsi la fréquence lorsqu'un oiseau est détecté dans l'image. Un grand robot est équipé d'une batterie de grande capacité qui permet une surveillance à long terme. Notre puce de programme modèle TBNet est également installée à l'intérieur du robot, qui peut classer les oiseaux en temps réel.
Pendant la période de surveillance, la fréquence d'occurrence des oiseaux étudiés sera calculée et enregistrée. Les informations recueillies peuvent ensuite être utilisées par les ornithologues amateurs pour estimer et conserver les populations d'oiseaux. Le modèle TBNet classe les images d'oiseaux en identifiant les relations d'affinité dans les images d'oiseaux, facilitant ainsi l'estimation de la population d'oiseaux en aval. En résumé, les principales contributions de ce travail sont les suivantes :
1) Une nouvelle méthode de suivi visuel par robot pour la protection des oiseaux est proposée. Le robot de surveillance intelligent peut tourner dans différentes directions et enregistrer le nombre d'oiseaux.
2) Un modèle TBNet efficace a été établi. À notre connaissance, cette affinité a été révélée pour la première fois dans l’imagerie des oiseaux. Par conséquent, ViT est utilisé pour exploiter ces affinités sémantiques abstraites. CNN est utilisé pour extraire des informations de surface et le module FS est introduit pour révéler des caractéristiques discriminantes. Pour la génération de cartes de fonctionnalités du modèle TBNet, une stratégie d'extraction de fonctionnalités (stratégie CPG) est proposée.
3) Mener des expériences sur deux ensembles de données sur les oiseaux, CUB-200-2011 et NABirds. Le TBNet proposé atteint de meilleures performances par rapport à plusieurs méthodes de pointe existantes, validant ainsi son efficacité.
3.Réseau
3.1 Structure globale
Le pipeline du modèle TBNet est illustré à la figure 3. La méthode comprend trois parties : le squelette d'extraction de fonctionnalités, le module FS et la tête de classification . La première partie est l’épine dorsale de l’extraction de caractéristiques, qui est utilisée pour extraire des informations fines et multi-échelles d’images d’oiseaux. De manière générale, plusieurs backbones actuels [1-3,7] peuvent être considérés comme candidats. Étant donné que CNN a une forte capacité à extraire des informations de surface et que Transformer est exceptionnel dans l'exploration des relations d'affinité sémantique abstraites, cette étude utilise la combinaison de CNN et ViT comme épine dorsale . Backbone a encore été modifié pour améliorer les performances. Pour atténuer le surajustement, le réseau développé dispose d'une couche d'abandon au niveau de la tête de classification du backbone. La deuxième partie est le module FS, qui extrait les caractéristiques discriminantes d'oiseaux spécifiques. La troisième partie est la tête de classification, dans laquelle la carte des caractéristiques est finalement utilisée pour la classification finale.
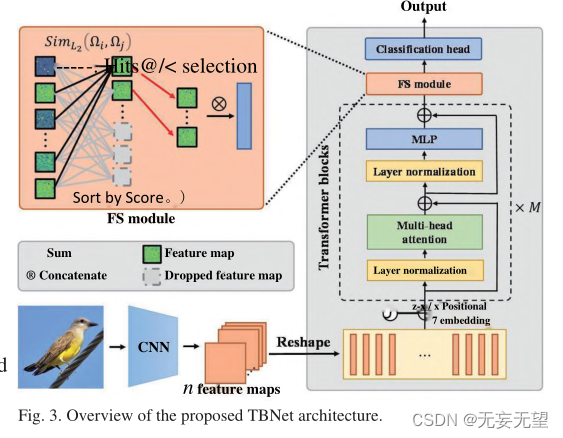
1. Utilisez le réseau CNN pour extraire les caractéristiques préliminaires de l'image, puis compressez-la dans un patch et saisissez-la dans le réseau vit, qui peut conserver davantage d'informations globales sur l'image, mais en même temps certaines informations de bas niveau. les informations détaillées sont ignorées en raison de la convolution couche par couche.
2. Le module FS équivaut à l'amélioration de l'image, il augmente le poids des zones significatives en supprimant les zones à faible contribution dans le bloc transformateur.
3.2 Génération de cartes de fonctionnalités
Les images d'oiseaux sont traitées via le squelette d'extraction de caractéristiques et des cartes de caractéristiques sont générées. Ce processus peut être résumé en trois étapes : traitement CNN, intégration de position et passage du bloc Transformer (stratégie CPG). Une fois le processus terminé, l'image d'entrée d'origine est convertie en une carte de caractéristiques pour la classification.
Étape I : traitement CNN. Au cours de cette étape, l'image d'entrée originale est initialement traitée via CNN pour générer n cartes de caractéristiques. Ensuite, chaque carte de caractéristiques t est planarisée en un vecteur unidimensionnel. Ensuite, appliquez une projection linéaire pour projeter pt dans p[. Ce processus s'exprime comme suit :

Dans la formule, pt est le i-ème patch, E est la projection linéaire et i est le vecteur visuel projeté en d dimensions.
Étape II : intégration de position. Étant donné que la couche Transformer est invariante par rapport à la disposition de la séquence de patchs d’entrée, des incorporations de positions sont nécessaires pour coder les positions spatiales et les relations des patchs. Plus précisément, ces correctifs sont ajoutés via une intégration positionnelle dans des vecteurs de correctifs. La formule d'intégration est la suivante :

Dans la formule, représente une matrice composée de vecteurs de patchs, n représente le nombre de patchs et
représente l'intégration de position. Le type d'intégration de position peut être choisi parmi plusieurs options, à savoir l'intégration de position sinusoïdale 2D, apprenable et relative.
Étape III : Parcourez le bloc Transformateur. Le patch d'intégration positionnelle est ensuite transmis à travers les blocs M Transformer. Chaque bloc Transformer est calculé comme suit :

où l et
sont les vecteurs de patch de sortie du module MSA et du module MLP du bloc de transformateur 1 respectivement. LN(-) indique la normalisation des couches. MLP représente plusieurs couches entièrement connectées. MSA signifie que les taureaux se surveillent. Ces blocs transformateurs peuvent être divisés en N niveaux.
3.3 Module FS
Le correctif d'origine peut introduire des fonctionnalités dommageables qui nuisent à la classification. La figure 4 montre la liste des mappages d'attributs dans le bloc Transformer. La dernière étape trie les cartes de caractéristiques en fonction de leurs scores de discrimination. Comme le montre la figure 4, dans les niveaux inférieurs, tels que les étapes 1 et 2, les fonctionnalités Hits@k n'ont presque aucune similitude les unes avec les autres, tandis que les fonctionnalités avec les scores les plus mauvais sont presque identiques les unes aux autres. Dans les couches supérieures, comme l'étape N, les fonctionnalités Hits@k sont plus similaires et hautement activées, tandis que les fonctionnalités avec les scores les plus mauvais semblent bruyantes. En général, à chaque étape, les caractéristiques saillantes des scores élevés sont plus importantes que les caractéristiques saillantes des scores faibles . Par conséquent, nous proposons le module FS pour utiliser davantage les informations fournies par ces fonctionnalités uniques et atténuer efficacement les effets néfastes des fonctionnalités destructrices.
Supposons qu'à l'étape i, la sortie soit n vecteurs de patch ID, notés Qj,ie[1,2,3,…,]. Tout d’abord, le module FS calcule la similarité entre n vecteurs. Sélectionnez la similarité parmi la similarité cosinus ou l’inverse de la distance L2. La similarité cosinus est définie comme suit
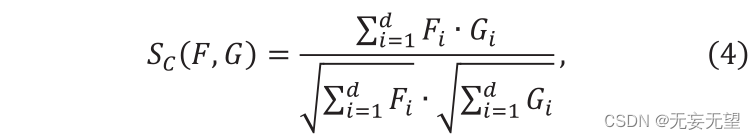
Où F ” et G ” sont deux vecteurs, Sc (F,G) ∈[0,1]. La valeur de Sc représente la similarité entre F et g, et sa distance L2 est construite comme suit :
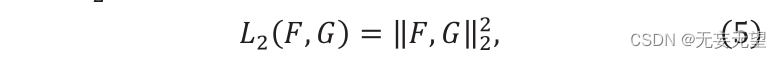
Où "F" et "G" représentent deux vecteurs de caractéristiques. La formule de calcul de similarité est la suivante :
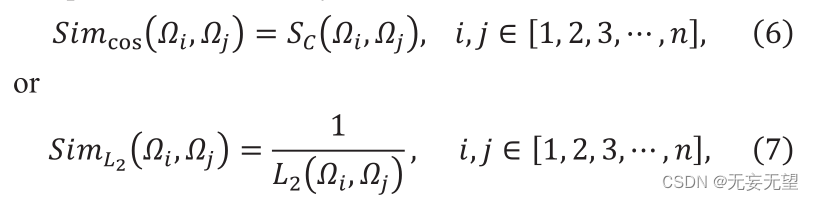
Parmi eux, et
représentent respectivement le i-ème et le j-ème vecteurs de patch. Sc représente la similarité cosinus,
qui représente
la distance. En calculant la similarité, la matrice de similarité peut être obtenue. La matrice de similarité contenant les similitudes entre tous les correctifs peut être exprimée comme suit :

Deuxièmement, chaque vecteur patch obtient un score discriminant en ajoutant sa similarité avec d'autres vecteurs patch et en effectuant une opération aller-retour. La formule de fonctionnement est la suivante :
 Enfin, le vecteur de patch Hits@k (k) avec le score le plus élevé est sélectionné et entré dans la couche suivante. Les vecteurs de patch restants sont ignorés car ils sont moins discriminants.
Enfin, le vecteur de patch Hits@k (k) avec le score le plus élevé est sélectionné et entré dans la couche suivante. Les vecteurs de patch restants sont ignorés car ils sont moins discriminants.

4. Expérimentez
4.1 Configuration expérimentale
4.1.1 Ensemble de données
CUB-200-2011,NABirds
4.1.2 Détails expérimentaux
Le modèle proposé est implémenté de la manière suivante. Tout d’abord, redimensionnez la résolution de l’image d’entrée entre 448 et 448 pour une comparaison équitable. Pour améliorer l'efficacité, la taille du lot est fixée à 8. L'optimiseur AdamW est utilisé et l'atténuation du poids est de 0,05. Le taux d'apprentissage est initialisé à 0,0001. Toutes les expériences ont été réalisées sur un GPU Nvidia TITAN à l'aide de la boîte à outils PyTorch.
4.2 Test comparatif


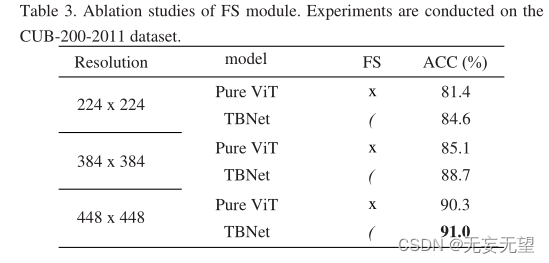
4.3 Expérience d'ablation
4.4 Visualisation

5. Conclusion
Dans ce travail, nous proposons une nouvelle méthode de suivi visuel pour les robots de protection des oiseaux. Le robot de surveillance intelligent peut tourner dans différentes directions et enregistrer le nombre d'oiseaux. Sur cette base, un modèle TBNet efficace est établi. À notre connaissance, des affinités dans les images d’oiseaux ont été révélées pour la première fois. Les CNN sont utilisés pour extraire des informations superficielles. Utilisez ViT pour exploiter des relations d'affinité sémantique abstraites. Le module FS est introduit pour révéler les fonctionnalités d’identification. Pour la génération de cartes de fonctionnalités du modèle TBNet, une stratégie d'extraction de fonctionnalités (stratégie CPG) est proposée. Nous avons testé TBNet sur deux ensembles de données FBIC. Les résultats expérimentaux montrent que cette méthode peut identifier des relations d'affinité et des caractéristiques discriminantes dans les images d'oiseaux. Avec les résultats prometteurs obtenus par TBNet, il est raisonnable de croire que le suivi visuel des oiseaux par des robots présente un grand potentiel.