
Préface
Je crois que tout le monde a déjà entendu parler de nombreux types de structures de données arborescentes.Je les ai toujours comparés par paires, c'est-à-dire d'un point de vue local, sans trier le contexte de développement de ces arbres dans leur ensemble, donc je les ai souvent oubliés rapidement après les avoir lu.. Il semble que nous devons vraiment repartir de l’origine, non seulement pour savoir ce qui se passe mais aussi pour savoir pourquoi. Comprendre les causes et les conséquences facilitera non seulement notre mémoire, mais contribuera également à approfondir notre compréhension. En fait, l'émergence de quelque chose est nécessaire : lorsque quelque chose rencontre un goulot d'étranglement, de nouvelles choses apparaissent inévitablement pour compenser ses lacunes. D'accord, ne disons pas de bêtises. Aujourd'hui, nous allons commencer avec un petit BST et assister à son parcours d'amélioration et de destruction de monstres.
Avant de commencer, voici deux arbres appétissants.
Arbre binaire complet :
Rien n'est parfait, et personne n'est parfait, mais un arbre binaire peut être parfait. Un arbre binaire dans lequel toutes les feuilles sont au même niveau est un arbre binaire complet.
Arbre binaire équilibré :
Les arbres ont aussi des niveaux. Tous les arbres ne sont pas parfaits. Par rapport aux arbres binaires parfaits, ceux qui sont un niveau inférieur aux arbres binaires parfaits sont appelés arbres binaires équilibrés. Le facteur d'équilibre de chaque nœud est compris entre . Bien qu'il ne soit pas complètement équilibré, il reste acceptable.-11
Arbre de recherche binaire (BST) :
Un arbre de recherche binaire (arbre de recherche d'équilibre) est un arbre organisé et discipliné qui satisfait à la condition selon laquelle les valeurs de tous les nœuds du sous-arbre de gauche sont inférieures à la valeur de la racine et les valeurs de tous les nœuds du sous-arbre de gauche. le sous-arbre droit est supérieur ou égal à la valeur de la racine . En termes simples, il est ordonné , La méthode de dichotomie peut donc être utilisée lors de l'interrogation ,Il a donc une efficacité de requête élevée.La meilleure complexité temporelle est o(log n), et le pire est lorsqu'un arbre de recherche binaire est Lorsqu'un ensemble ascendant ou des valeurs décroissantes sont obtenues, l'arbre de recherche binaire dégénérera en une liste à chaînage unique et la complexité du temps de recherche deviendra .O(n)。O(n)
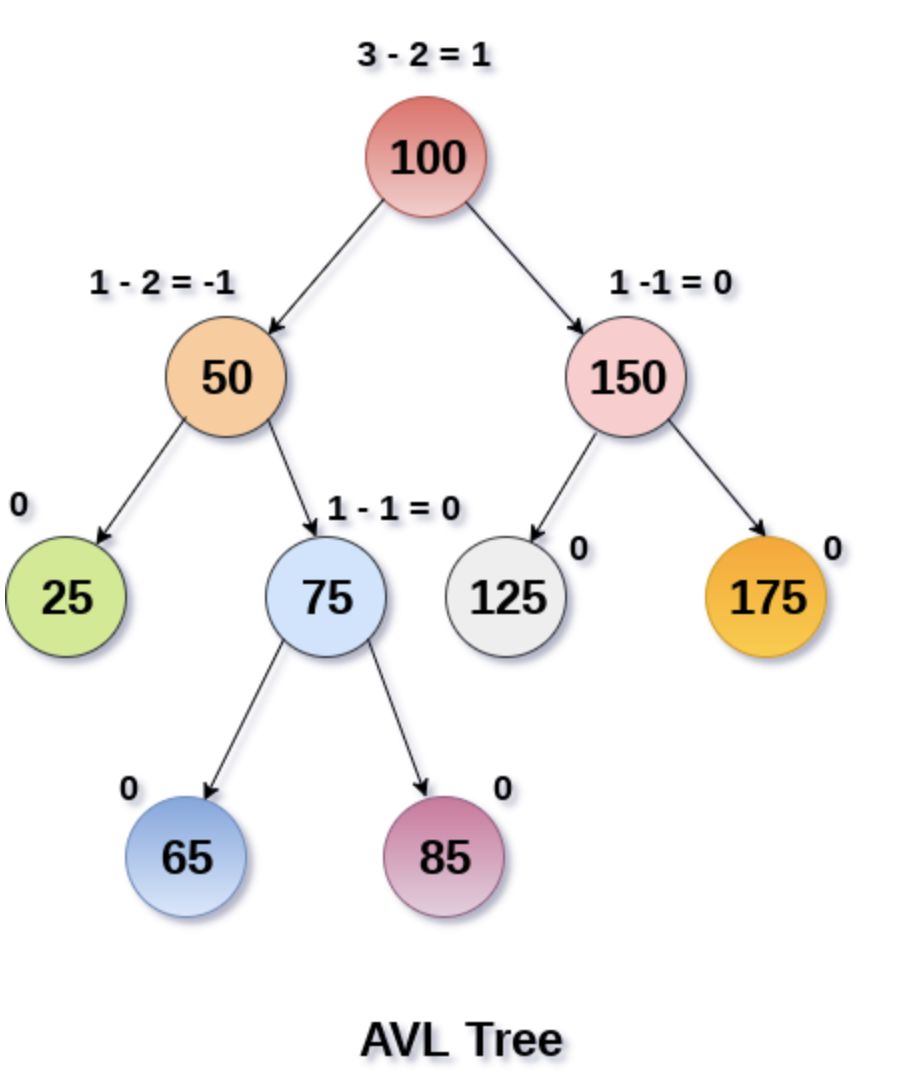
Arbre AVL
Pourquoi y a-t-il des arbres AVL ?
Comme mentionné précédemment, lorsqu'un ensemble de valeurs ordonnées est inséré dans BST, il dégénère en une liste à chaînage unique et les performances dégénèrent en O(n). La cause fondamentale est que lorsqu'elle était enfant, ses parents étaient relativement lâches et lui permettaient de se développer librement. , ce qui fait que la BST est partiale envers les matières et que les capacités ne sont pas développées de manière équilibrée, alors que devrions-nous faire ? Eh bien, c'est vrai, vous devez embaucher un tuteur, et si un seul ne suffit pas, il vous en faut deux. Établissez des règles pour la retenir. Même si elle ne peut pas obtenir des scores parfaits comme un arbre binaire parfait, au moins elle doit être équilibré, non ? Sinon elle ne pourra pas se marier. Après avoir embauché un tuteur, BST a directement changé le pistolet et s'est transformé en l'arbre AVL que nous présenterons ensuite.
Qu'est-ce qu'un arbre AVL
L'arbre AVL fait référence à un arbre de recherche binaire équilibré. Oui, c'est le résultat d'un croisement entre un arbre de recherche binaire et un arbre binaire équilibré . Il combine les excellentes caractéristiques des deux parents, est ordonné et équilibré et va directement au pic de croissance des arbres.
Pourquoi s’appelle-t-on l’arbre AVL ? Ce n'est pas l'abréviation de Balanced Binary Search Tree, mais parce que les noms des deux tuteurs de BST sont etG. M. Adelson-VelskyEvgenii Landis。
La complexité temporelle de la recherche, de l'insertion et de la suppression de l'arborescence AVL est fixée à O (log n), mais les opérations d'ajout et de suppression rendront l'arborescence déséquilibrée, l'arborescence doit donc être rééquilibrée via une ou plusieurs rotations d'arbre.
La rotation est divisée en quatre méthodes : LL, LR, RR et RL. Il existe de nombreuses insertions et suppressions spécifiques, je n'entrerai donc pas dans les détails ici. Le point clé est que plusieurs rotations peuvent être nécessaires pour maintenir l'équilibre, donc maintenir l' arbre Le coût du maintien de l'équilibre est encore assez élevé, ce qui est également l'inconvénient des arbres AVL.
arbre rouge noir
Pourquoi les arbres rouge-noir apparaissent-ils ?
La différence de hauteur entre les sous-arbres gauche et droit d'une arborescence AVL ne peut pas dépasser 1. Chaque fois qu'une opération d'insertion/suppression est effectuée, il est presque nécessaire de maintenir l'équilibre grâce à une opération de rotation. Dans les scénarios où l'insertion/suppression est fréquente, une rotation fréquente Les opérations réduisent considérablement les performances de l'AVL ... , d'où l'apparition d'arbres rouge-noir.
Qu'est-ce qu'un arbre rouge-noir
L'arbre rouge-noir est un arbre de recherche binaire auto-équilibré, très similaire à l'arbre AVL. La complexité temporelle de la recherche, de l'insertion et de la suppression dans l'arbre rouge-noir est O(log n). Cependant, l'arbre rouge-noir n'est pas un arbre binaire strictement équilibré. Il ne maintient pas strictement le facteur d'équilibre de 1 pour maintenir l'équilibre comme l'arbre AVL. Au lieu de cela, il conserve ses propres cinq caractéristiques à travers trois opérations : rotation à gauche, rotation à droite. et changement de couleur , garantissant que le chemin le plus long n'est pas plus de deux fois plus long que le chemin le plus court , obtenant ainsi un équilibre approximatif .
Comparaison entre les arbres rouge-noir et les arbres AVL :
La complexité temporelle de la recherche, de l'insertion et de la suppression est entièrement O(log n).Par rapport à l'arbre AVL, l'arbre rouge-noir sacrifie une partie de l'équilibre en échange de moins d'opérations de rotation lors de l'insertion et de la suppression, car la performance globale est mieux que celui de l'arborescence AVL, donc dans les scénarios avec de nombreux scénarios de requêtes et peu d'insertions et de suppressions, l'arborescence AVL a de meilleures performances. Lorsqu'il existe de nombreux scénarios d'insertion et de suppression, l'arborescence rouge-noir a de meilleures performances.
Arbre B
Pourquoi l'arbre B apparaît-il ?
Il existe de nombreux arbres binaires équilibrés traditionnellement utilisés pour la recherche, tels que les arbres AVL, les arbres rouge-noir, etc. Ces arborescences offrent de très bonnes performances de requête dans des circonstances normales, mais elles échouent lorsque les données sont très volumineuses. La raison en est que lorsque la quantité de données est très importante, la mémoire n'est pas suffisante, la plupart des données ne peuvent être stockées que sur le disque et seules les données requises sont chargées dans la mémoire. D'une manière générale, le temps d'accès à la mémoire est d'environ 50 ns, tandis que le temps d'accès au disque est d'environ 10 ms. La différence de vitesse est de près de 5 ordres de grandeur et le temps de lecture du disque dépasse de loin le temps de comparaison des données en mémoire. Cela montre que le programme sera bloqué sur le disque IO la plupart du temps. Alors, comment pouvons-nous améliorer les performances du programme ? Réduisez le nombre d'E/S de disque. Les arborescences binaires équilibrées telles que les arborescences AVL et les arborescences rouge-noir ne peuvent pas « répondre » aux disques de par leur conception.
Un arbre binaire équilibré est maintenu par rotation, et la rotation est une opération sur l'ensemble de l'arbre. Si une partie de l'arbre est chargée en mémoire, l'opération de rotation ne peut pas être terminée. Deuxièmement, la hauteur d'un arbre binaire équilibré est relativement grande comme log n (la base est 2), donc les nœuds logiquement proches peuvent en fait être très éloignés et la lecture anticipée du disque ne peut pas être bien utilisée (le principe de localité), donc ce type d'arbre binaire équilibré se trouve dans la base de données et les sélections du système de fichiers sont transmises.
Qu'est-ce qu'un arbre B
L'arbre B est un arbre de recherche équilibré à plusieurs voies. Comparé à l'arbre binaire, l'arbre B peut être considéré comme un arbre à plusieurs branches. Un arbre B d'ordre m signifie qu'un nœud a au plus m nœuds enfants.
Jetons un coup d'œil à la définition de B-tree.
- Chaque nœud possède au plus m-1 mots-clés (paires clé-valeur pouvant être stockées).
- Le noeud racine peut avoir au moins 1 mot - clé .
- Les noeuds non racine ont au moins m/2 Mots - clés .
- Les mots-clés de chaque nœud sont classés par ordre croissant.Tous les mots-clés du sous-arbre gauche de chaque mot-clé sont plus petits que lui et tous les mots-clés du sous-arbre droit sont plus grands que lui.
- Tous les nœuds feuilles sont situés au même niveau, ou la longueur entre le nœud racine et chaque nœud feuille est la même.
- Chaque nœud stocke l'index et les données , c'est-à-dire la clé et la valeur correspondantes.
Par conséquent, la plage du nombre de mots-clés du nœud racine est : , et la plage du nombre de mots-clés du nœud non racine : .1 <= k <= m-1m/2 <= k <= m-1
L'arbre B, comme l'arbre AVL et l'arbre rouge-noir, est également un arbre de recherche auto-équilibré. Lorsque le nœud nouvellement inséré ne répond pas aux exigences, il effectuera également un mouvement de protection des droits, mais l'arbre B ne fera pas de rotation, mais sera divisé. La condition critique principale est le nombre de mots-clés dans chaque nœud. Si le nombre dépasse les exigences, il sera divisé.
Parlons brièvement du processus de fractionnement. Par exemple, s'il existe un arbre B d'ordre 4, lorsqu'un nouvel élément est inséré, le nombre de mots-clés d'un nœud atteint 4, car chaque nœud a au plus m-1 mots-clés, c'est-à-dire qu'il y a au plus 3 nœuds et vous devez les diviser à ce moment-là. En supposant que la valeur clé est 5, 6, 7, 8, elle sera divisée en 3 parties basées sur m/2, 5---6---7, 8. La division mettra 6 dans le nœud parent, 5 et Les deux nœuds 7 et 8 pointent respectivement vers le nœud parent.
Cela signifie que la division du B-tree n'affectera que le nœud parent et le nœud actuel.
B+arbre
Qu'est-ce qu'un arbre B+
caractéristique:
- Les arbres B+ contiennent 2 types de nœuds : les nœuds internes (également appelés nœuds d'index) et les nœuds feuilles. Le nœud racine lui-même peut être un nœud interne ou un nœud feuille. Le nombre de mots clés du nœud racine peut être d'au moins 1 ;
- La plus grande différence entre l'arbre B+ et l'arbre B est que les nœuds internes ne stockent pas de données et ne sont utilisés que pour l'indexation. Toutes les données (ou enregistrements) sont stockées dans des nœuds feuilles ;
- L'arbre B+ d'ordre m indique que le nœud interne a au plus m-1 mots-clés (ou que le nœud interne a au plus m sous-arbres, ce qui est le même que l'arbre B). L'ordre m limite également les nœuds feuilles. pour stocker au maximum les enregistrements m-1 ;
- Les clés du nœud interne sont classées par ordre croissant. Pour une clé du nœud interne, toutes les clés de l'arborescence de gauche sont inférieures à elle et toutes les clés du sous-arbre de droite lui sont supérieures ou égales. Les enregistrements dans les nœuds feuilles sont également classés en fonction de la taille de la clé ;
- Chaque nœud feuille stocke des pointeurs vers les nœuds feuilles adjacents, et les nœuds feuilles eux-mêmes sont liés dans l'ordre du plus petit au plus grand en fonction de la taille de la clé ;
Comparaison entre l'arbre B+ et l'arbre B :
La principale différence entre l'arbre B+ et l'arbre B est que chaque nœud de l'arbre B stocke l'index et les données , tandis que l'arbre B+ stocke uniquement l'index et les données sur les nœuds feuilles, et les nœuds non-feuilles stockent uniquement l'index. Les B-tree sont : Il y a trois points comme suit :
- Quelques fois d'E/S disque
Étant donné que seuls les nœuds feuilles de l'arborescence B+ stockent les données, et que les autres nœuds non-feuilles enregistrent et indexent uniquement, le nombre d'E/S de disque unique de l'arborescence B+ est plus grand que celui de l'arborescence B. Cela signifie que l'arborescence B+ peut réduire la nombre d'E/S de disque, et nous savons tous que l'accès aux disques est plusieurs fois plus lent que l'accès direct à la mémoire, de sorte que le nombre d'E/S de disque devient souvent un goulot d'étranglement des performances. Par conséquent, le nombre d'E/S de disque est faible, ce qui peut améliorer considérablement l'efficacité d'insertion et de requête.
- Convient pour les requêtes de plage
Les nœuds feuilles de l'arbre B+ forment une liste chaînée ordonnée et les requêtes de plage sont converties en lectures séquentielles, ce qui est très efficace. Relativement parlant, le B-tree doit effectuer un parcours dans l'ordre pour prendre en charge les requêtes de plage.
- Les performances des requêtes sont stables
Étant donné que toutes les données de l'arbre B+ sont stockées sur les nœuds feuilles, elles doivent être transmises aux nœuds feuilles à chaque fois, de sorte que la complexité temporelle de la requête est fixée à O(log n), tandis que les données de l'arbre B+ sont directement stockées. sur chaque nœud, donc B La complexité temporelle de la requête de l'arbre est comprise entre O(1) et O(log n).
Inconvénients des arbres B+
Les arbres B+ présentent deux inconvénients principaux :
- Si les données écrites sont relativement discrètes, lors de la recherche de l'emplacement d'écriture, il existe une forte possibilité que le nœud enfant ne soit pas dans la mémoire et qu'un grand nombre d'écritures aléatoires se produisent éventuellement, ce qui entraîne une réduction des performances.
- Si l'arborescence B+ fonctionne depuis longtemps et que de nombreuses données ont été écrites, à mesure que les nœuds feuilles se divisent, leurs blocs correspondants ne seront plus stockés séquentiellement et seront dispersés. À ce stade, l'exécution de la requête de plage deviendra également une lecture aléatoire et l'efficacité sera réduite.
Arbre LSM
Pourquoi l'arborescence LSM apparaît-elle ?
L'arbre B+ est la structure d'indexation de MySQL.Pendant longtemps, l'utilisation courante de la structure d'indexation arborescente B+ pour réaliser une recherche rapide de données a de bonnes performances de lecture. Lorsque la quantité de données n'est pas trop importante, les performances de lecture et d'écriture de l'arborescence B+ sont également très bonnes. Cependant, dans le cas de données massives, une grande quantité de données est fréquemment écrite et mise à jour , et l'arborescence B+ devient de plus en plus haute. Puisque l'arborescence B+ met à jour et supprime les données, il est nécessaire d'effectuer un fractionnement et une fusion de pages le long du Arbre B+ couche par couche. Lorsqu'il y a un grand nombre de divisions, cela entraînera un grand nombre de recherches aléatoires sur le disque , affectant sérieusement les performances d'écriture des données. LSM-tree est une structure de stockage créée pour résoudre les problèmes ci-dessus.
Qu'est-ce qu'un arbre LSM
LSM Tree est apparu dans "Bigtable: A Distributed Storage System for Structured Data", une des troïkas de Google. Son nom complet est Log-Structured Merge Tree. Il s'agit d'un périphérique de stockage par blocs hiérarchique, ordonné et ciblé (disque dur mécanique et SSD). Structure de stockage des données conçue pour les caractéristiques.
Il est présent dans de nombreuses bases de données populaires, telles que les bases de données NoSQL telles que Cassandra, RocksDB, HBase et LevelDB, les bases de données newSQL telles que TiDB, et même les bases de données relationnelles traditionnelles telles que SQLite, les bases de données documentaires traditionnelles telles que MongoDB et Clickhouse. Le moteur basé sur LSM Tree est fourni en tant que moteur de stockage en option.
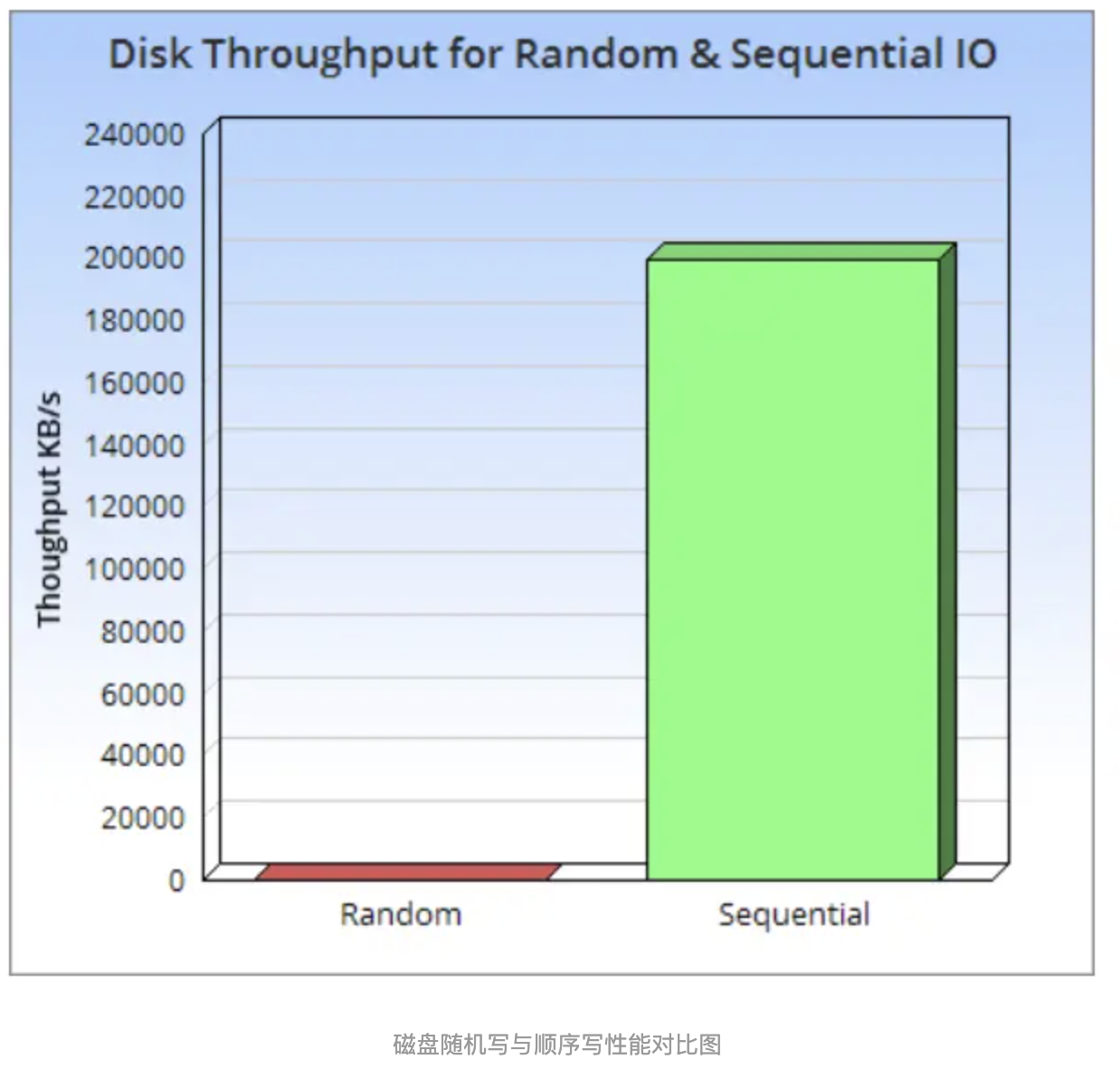
Sa base théorique principale est que la vitesse d'écriture séquentielle du disque est beaucoup plus rapide que la vitesse d'écriture aléatoire.Même pour les SSD, en raison de l'impact de l'effacement des blocs et du garbage collection, la vitesse d'écriture séquentielle est toujours beaucoup plus rapide que la vitesse d'écriture aléatoire. .
composant de base
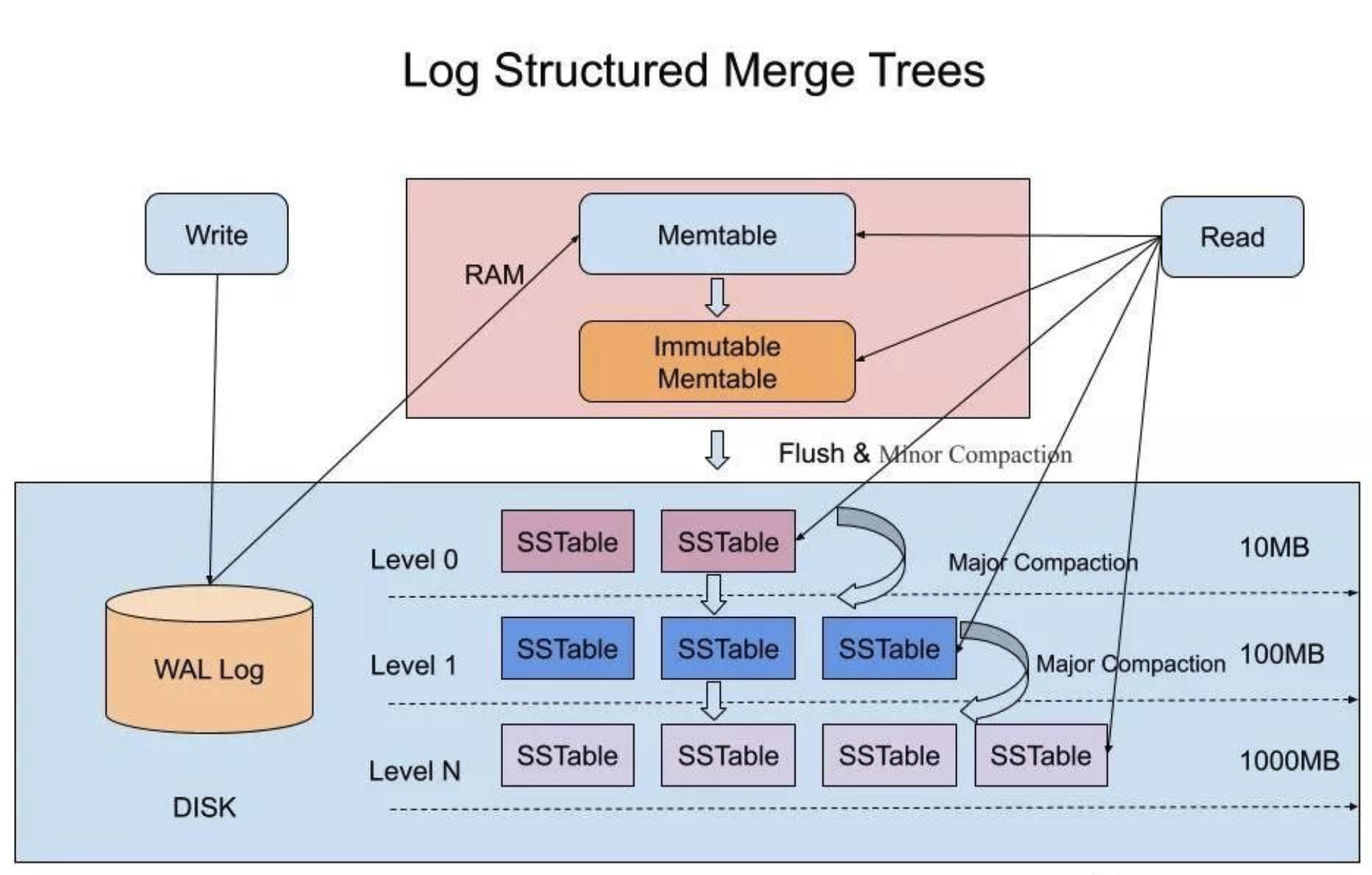
- WAL (journal d'écriture anticipée)
La structure et la fonction de WAL sont les mêmes que celles des autres bases de données. Il s'agit d'un fichier de structure de journal qui ne peut ajouter des enregistrements qu'à la fin en mode Append Only. Il est utilisé pour rejouer l'opération lorsque le système plante et redémarre, donc que MemTable et Immutable MemTable ne sont pas conservés sur le disque. Les données ne seront pas perdues.
- MemTable
MemTable est une structure de données en mémoire, utilisée pour écrire et lire des données récemment mises à jour. LSM n'a pas de contraintes fortes sur la structure de données spécifique de MemTable. Il peut s'agir d'un arbre rouge-noir ou d'une structure de table sautée. Il est nécessaire de prendre en charge une insertion dynamique efficace des données, un tri des données ainsi qu'une recherche précise et une recherche par plage de données efficaces.
- Table Mem immuable
Lorsque le MemTable atteint la taille seuil, il sera converti en un MemTable immuable. Immutable MemTable ne peut pas écrire de données, mais ne peut que lire des données. Les données d'Immutable MemTable seront régulièrement vidées sur le disque.
- SSTable (table de chaînes triées)
SSTable est une structure de stockage clé-valeur persistante, ordonnée et immuable. Ses clés et valeurs sont toutes deux des tableaux d'octets arbitraires, et elle permet une recherche par clé spécifiée et un parcours itératif de l'intervalle de clé dans la plage spécifiée. Le SSTable contient une série de blocs Block avec des tailles configurables. La taille typique est de 64 Ko. Les index de ces blocs Block sont stockés à la fin du SSTable pour aider à trouver rapidement des blocs spécifiques. Lorsqu'une SSTable est ouverte, l'index sera chargé dans la mémoire, puis une recherche binaire sera effectuée dans l'index de la mémoire en fonction de la clé. Après avoir trouvé le décalage du disque correspondant à la clé, les données du bloc correspondant seront lues à partir de le disque. Bien entendu, si la mémoire est suffisamment grande, la SSTable peut être directement mappée dans la mémoire via la technologie MMap pour permettre une recherche plus rapide.
processus d'écriture
Lorsque LSM-tree écrit des données, il écrira d'abord un enregistrement dans WAL, puis écrira les données dans la MemTable en mémoire . Bien sûr, la taille de la mémoire est définitivement limitée et il est impossible d'écrire tout le temps. Lorsque la taille du MemTable Après avoir atteint le seuil défini, le MemTable sera converti en un MemTable immuable, qui est un MemTable immuable comme son nom l'indique, puis un nouveau MemTable sera généré pour écrire de nouvelles données. Il n'y aura donc qu'un seul MemTable, mais il peut y avoir plusieurs MemTables immuables. Il y aura un thread séparé qui videra régulièrement les données de l'Immutable MemTable vers la SSTable sur le disque.
Lors de la suppression de données, cela revient à écrire de nouvelles données. Un nouvel enregistrement est écrit. Ce n'est que lors de la suppression de données qu'une marque de suppression sera ajoutée. Ce n'est que lors du compactage que les données portant la marque de suppression seront physiquement supprimées.
Processus de lecture
Il regarde d'abord dans la mémoire, puis dans la mémoire , puis dans et enfin dans .MemTableImmutable MemTablelevel 0 SSTablelevel N SSTable
Lors de la recherche d'un SSTable spécifique, le bloc de métadonnées du SSTable est généralement lu dans la mémoire en premier. BloomFilter peut être utilisé pour déterminer rapidement si les données existent dans le SSTable actuel. S'il existe, la méthode de dichotomie est utilisée pour déterminer quelles données bloc dans lequel se trouvent les données, puis les données sont stockées dans la mémoire. Le bloc de données correspondant est lu dans la mémoire pour une recherche précise.
À partir du processus de recherche de données, nous pouvons voir que pour trouver les données cibles, nous devons lire et trouver les SSTables qui ne contiennent pas les données cibles. Si les données cibles se trouvent dans le SSTable au niveau inférieur N, nous devons lisez et trouvez tous les SSTables ! Ce phénomène de lecture et de recherche de SSTables non pertinentes est appelé amplification de lecture ( ).LSM TreeLSM Treeread amplification
Le phénomène d'amplification de lecture affecte sérieusement les performances de recherche de données. L'article "BigTable" mentionne plusieurs méthodes pour améliorer les performances de recherche de données, telles que la compression, la mise en cache, l'indexation ( filtre Bloom ) et les opérations de compactage , qui ne seront pas abordées en détail ici.LSM Tree
Comparaison entre l'arbre LSM et l'arbre B+
La différence entre l'arbre LSM et l'arbre B+ réside principalement dans le compromis entre les performances de lecture et les performances d'écriture.
Lors de l'écriture de plus et de la lecture de moins , l'arborescence LSM a de meilleures performances que l'arborescence B. En raison du grand nombre d'opérations d'insertion, les nœuds sont divisés afin de conserver la structure arborescente B+. La probabilité de lecture et d'écriture aléatoires de lecture du disque augmentera et les performances s'affaiblissent progressivement.
En lisant plus et en écrivant moins, l'arbre B+ a de meilleures performances que l'arbre LSM . L'arborescence LSM améliore considérablement les performances d'écriture en sacrifiant une partie des performances de lecture, et grâce à certaines méthodes d'optimisation, telles que les filtres Bloom et les stratégies compactes, les performances de lecture ont été grandement optimisées et la complexité temporelle est également de niveau O(log n ) . .
Documentation de référence :
https://www.cnblogs.com/wxiaotong/p/14781753.html
https://www.jianshu.com/p/f911cb9e42de
Alibaba Cloud a subi une grave panne et tous les produits ont été affectés (restaurés). Tumblr a refroidi le système d'exploitation russe Aurora OS 5.0. La nouvelle interface utilisateur a été dévoilée Delphi 12 & C++ Builder 12, RAD Studio 12. De nombreuses sociétés Internet recrutent en urgence des programmeurs Hongmeng. L'heure d'UNIX est sur le point d'entrer dans l'ère des 1,7 milliards (déjà entrée). Meituan recrute des troupes et envisage de développer l'application du système Hongmeng. Amazon développe un système d'exploitation basé sur Linux pour se débarrasser de la dépendance d'Android à l'égard de .NET 8 sous Linux. La taille indépendante est réduit de 50 %. Sortie de FFmpeg 6.1 "Heaviside"Auteur : JD Logistique Yu Jianfei
Source : La communauté des développeurs JD Cloud justifie la technologie. Veuillez indiquer la source lors de la réimpression.