
1. Qu'est-ce que la visualisation de code ?
La visualisation du code est le processus de création de représentations graphiques du code source pour aider à le comprendre et à l'analyser.
Compréhension personnelle : En utilisant des moyens graphiques (schéma d'architecture, diagramme de dépendances, traçage distribué, diagramme de classes, diagramme de flamme, CallGraph, etc.) pour rendre le code observable sur certaines caractéristiques, il est utilisé pour aider les développeurs à comprendre et analyser des projets ou des constructions. Quelques outils d'automatisation.
2. Pourquoi la visualisation du code est-elle nécessaire ?
Scénario 1 : difficulté à comprendre la logique du code
Le projet comporte une grande quantité de code et une itération rapide des exigences, de sorte que les documents compilés à chaque fois deviendront rapidement obsolètes. Il est extrêmement difficile pour les nouveaux étudiants de démarrer, et il est difficile pour les vétérans d'avoir une compréhension globale de la logique métier globale du projet, et ils doivent souvent réorganiser la logique.
Scénario 2 : L'impact du changement est difficile à évaluer
La demande était de modifier la logique de la page A, mais comme le code back-end avait beaucoup de logique commune et que le niveau d'appel était très profond, on a découvert après la mise en ligne que cela affectait la logique de la page B, provoquant une erreur en ligne. accident.
Scénario 3 : La reconstruction du projet manque de point de départ
Les anciens projets ont subi de longues itérations et de multiples changements d'équipe, ce qui a entraîné une logique de code interne très confuse et personne ne peut pleinement comprendre toute la logique. Cependant, la demande de nouvelles itérations commerciales se poursuit et le coût des modifications des projets originaux est de plus en plus élevé. La reconstruction est nécessaire de toute urgence pour atteindre une plus grande efficacité en R&D.
Autres scénarios : la régression de cas automatisée ne peut souvent pas couvrir la nouvelle logique ; il est difficile de résoudre les problèmes en ligne et de localiser rapidement le code d'erreur...
3. Comment réaliser la visualisation du code ?
Call Graph est une représentation graphique de la relation entre les différents appels de fonction dans un programme. Il montre comment les fonctions d'un programme interagissent, permettant aux développeurs de comprendre le flux du programme et d'identifier les problèmes de performances potentiels.
Ce qui suit explique le schéma de génération de Call Graph, une méthode de visualisation du code, qui peut être divisée en analyse statique et dynamique :
3.1 Analyse du programme statique
1) Générer en fonction du code source
Avant d'expliquer le processus d'utilisation du code source pour générer CallGraph, passons d'abord en revue les connaissances pertinentes sur les principes de compilation.
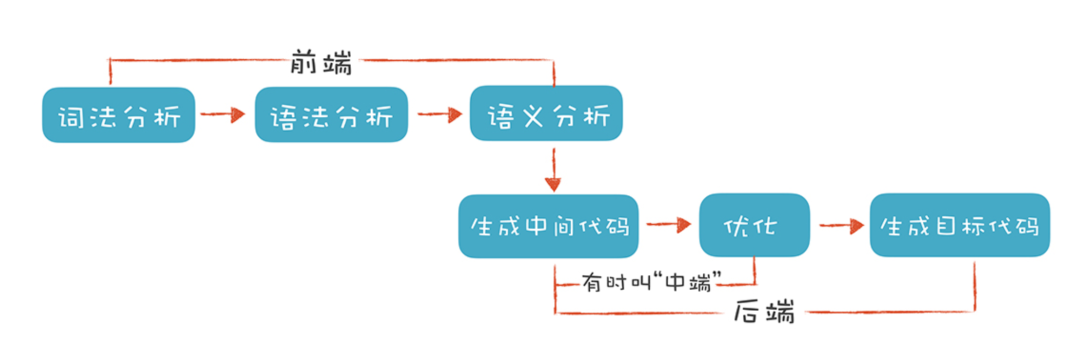
La partie front-end du compilateur est principalement liée au langage source et comprend principalement :
Analyse lexicale : Également appelée scanning, sa tâche principale est de scanner les caractères du programme source ligne par ligne de gauche à droite, d'identifier chaque mot, de déterminer le type du mot et de convertir les mots identifiés en une représentation unifiée sur machine. — — Forme de jeton. Cela peut être comparé au processus de combinaison de lettres anglaises en mots.

Analyse syntaxique : également appelée parsing. L'analyseur identifie diverses phrases à partir de la séquence de jetons produite par l'analyseur lexical, construisant ainsi un arbre syntaxique et déterminant si le programme source est structurellement correct. Cela peut être comparé à des mots anglais combinés en phrases.
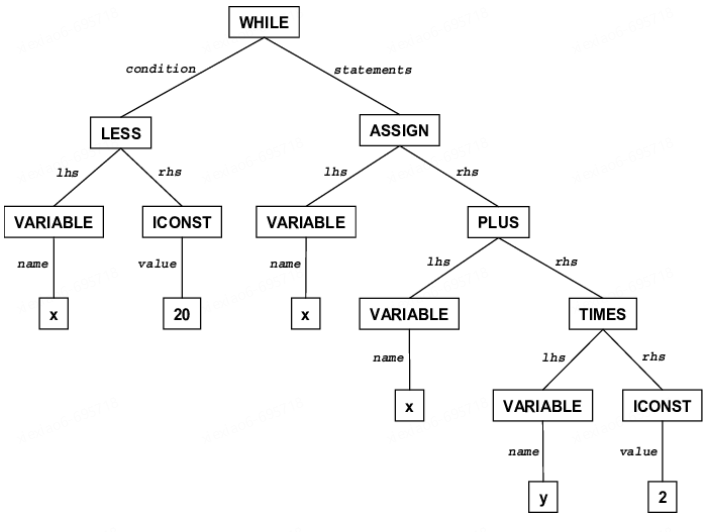
Analyse sémantique : Utilisez les informations de l'arbre syntaxique et de la table des symboles pour vérifier si le programme source est cohérent avec la sémantique définie par le langage, telles que : vérification de type, analyse contextuelle , etc. Cela peut être comparé à vérifier si une phrase anglaise a du sens (par exemple : Dog is cat, cette phrase est grammaticalement bonne mais sémantiquement incorrecte). Il collecte également les informations d'attribut de l'identifiant et stocke ces informations dans l'arbre syntaxique ou la table de symboles pour une utilisation dans le processus de génération de code intermédiaire ultérieur.
Code intermédiaire : Une représentation intermédiaire qui contient des informations à partir desquelles tous les faits sur un programme peuvent être dérivés. Le même code intermédiaire peut réutiliser la logique de l'optimiseur et utiliser directement les fonctions back-end du compilateur associées, rendant chaque lien plus indépendant et plus facile à développer. Structurellement, il existe des IR graphiques, des IR linéaires et des IR hybrides.
La partie back-end du compilateur est principalement liée au langage cible, y compris l'optimiseur de code et le générateur de code cible. Cette partie n'a pas grand-chose à voir avec la génération de CG. Sans approfondir davantage les principes, les étudiants intéressés peuvent en apprendre davantage sur LLVM et Graalvm .
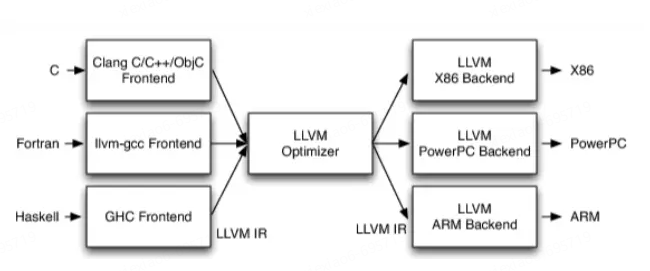
Avec les connaissances de base des principes de compilation, examinons le processus de production de CG à partir du code source :
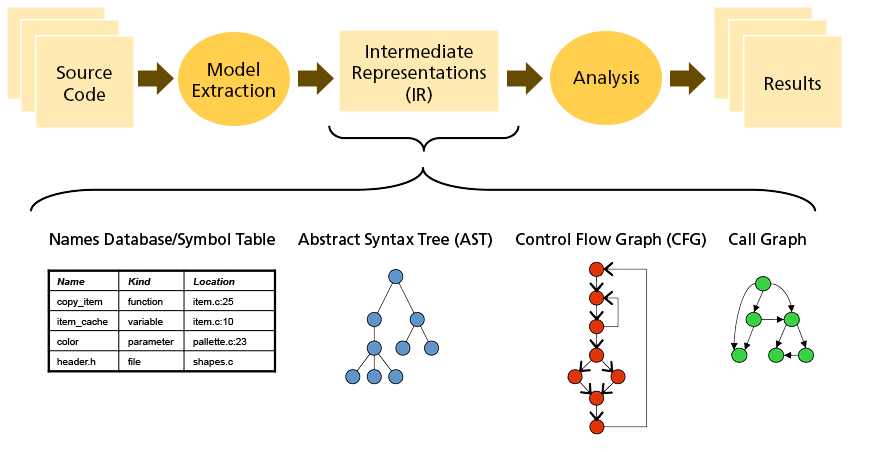
On peut constater que l'analyse est en fait une reproduction du processus frontal du compilateur, dans lequel AST, CFG et CG sont tous comptés comme graphiques IR. Les outils d'analyse de code source prêts à l'emploi incluent Antlr / javaparser /soot, etc. Ce qui suit utilise l'outil javaparser comme exemple pour décrire brièvement le processus de génération :
Étape 1 : Importez le code source et les packages de dépendances du projet qui doivent être analysés et utilisez des outils pour les analyser
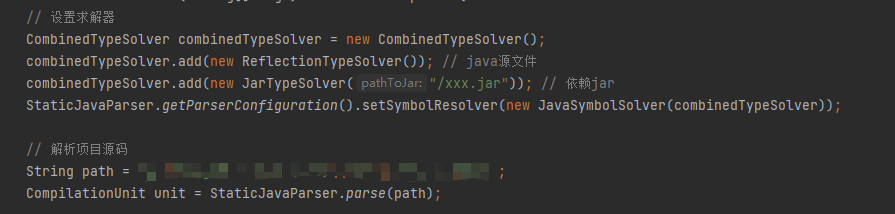
Étape 2 : Utilisez le mode visite pour obtenir toutes les informations sur la méthode et la méthode d'appel
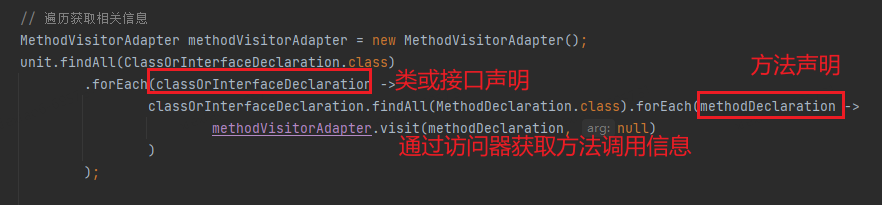
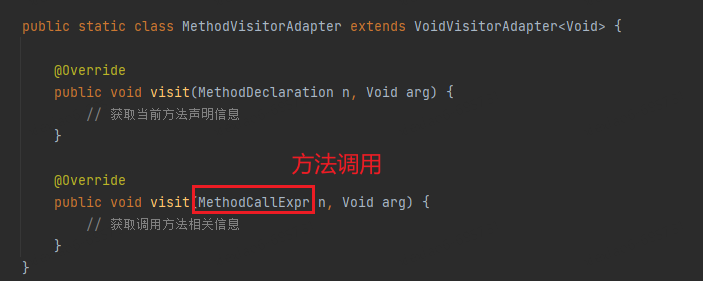
Étape 3 : Sélectionnez une méthode de démarrage et générez un CG en fonction de la méthode et de la relation d'appel.
Avantages : Indépendant de la langue et hautement évolutif. Inconvénients : La précision est mauvaise et doit être ajustée ; la vitesse d'analyse est lente ; il est difficile de maîtriser les outils linguistiques non Java.
2) Basé sur la génération de bytecode
Le développement personnalisé des fonctionnalités du langage peut conduire à des résultats plus rapides. Le bytecode Java peut en fait être considéré comme un IR linéaire, et le processus d'analyse est similaire. Dans le même temps, Java dispose d'un grand nombre d'outils de manipulation de bytecode (ASM, Javaassit, bcel, etc.), ce qui facilite l'analyse du bytecode.
L'idée de base est d'obtenir les informations de signature de classe et de méthode à partir du fichier .class, puis de trouver l'instruction d'invocation dans le bytecode pour obtenir la signature de la méthode appelante. Sur la base de ces deux informations, le CG peut être construit. Dans le même temps, étant donné que le bytecode contient la signature complète de la méthode, il n'est pas nécessaire d'introduire des fichiers JAR dépendants pour l'analyse comme l'analyse du code source, l'efficacité de l'analyse sera donc beaucoup plus rapide.
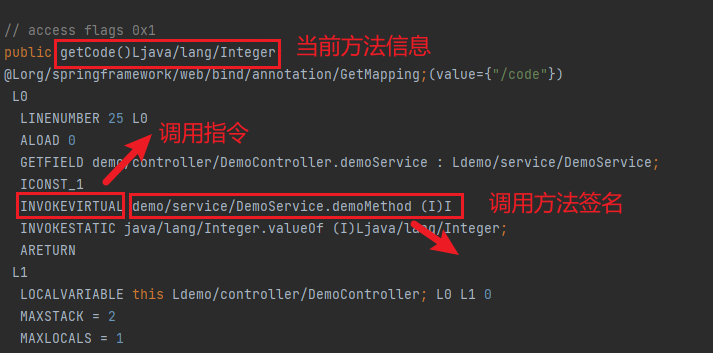
Ce qui suit utilise l'outil bcel comme exemple pour décrire brièvement le processus de génération :
Étape 1 : Analysez le projet cible, vous pouvez utiliser directement le package jar emballé
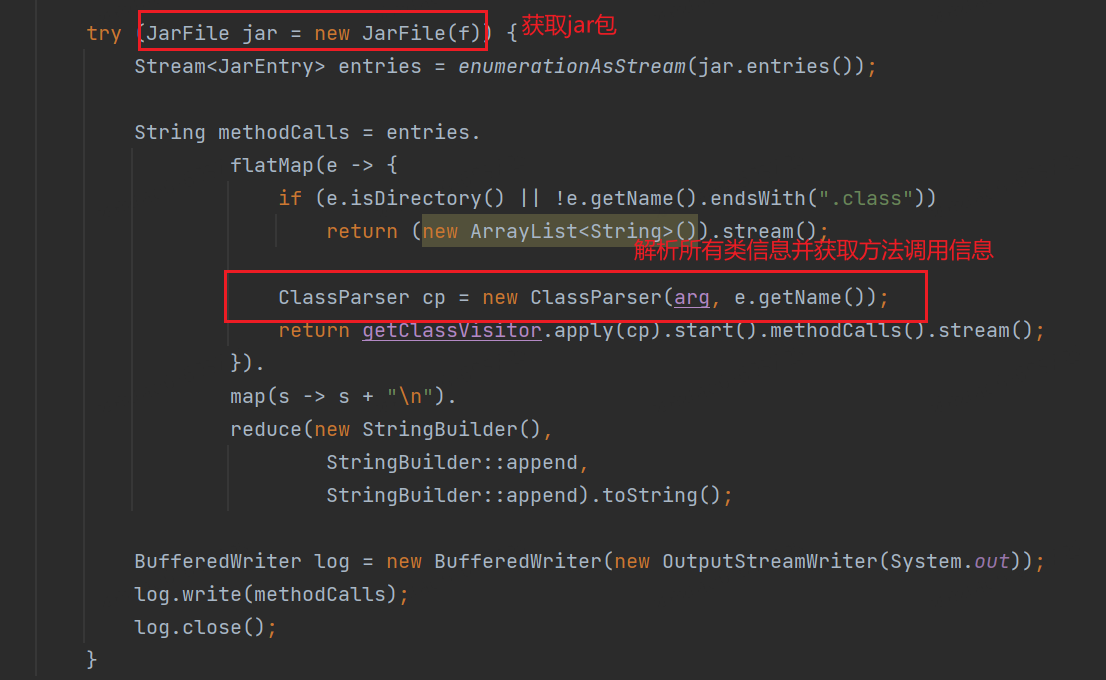
Étape 2 : Utilisez le mode visite pour obtenir toutes les informations sur la méthode et la méthode d'appel

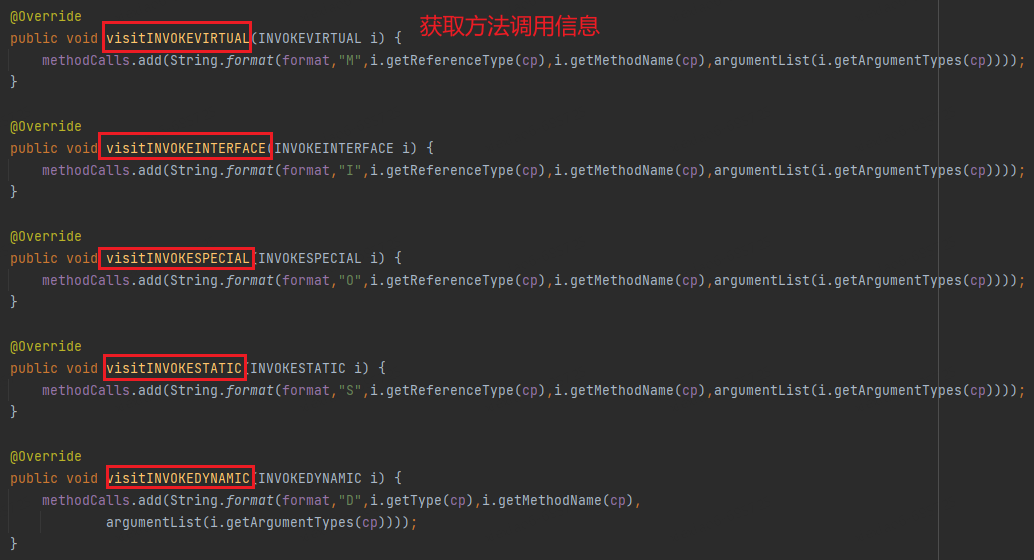
Étape 3 : Sélectionnez une méthode de démarrage et générez un CG en fonction de la méthode et de la relation d'appel.
Avantages : précision d'analyse élevée ; vitesse d'analyse rapide. Inconvénients : Lié au langage, mauvaise évolutivité.
PS : Je recommande un plug-in d'idée appelé call graph , qui est implémenté sur la base de la capacité psi de idea . L'analyse est assez précise lorsque la quantité de code du projet n'est pas importante.
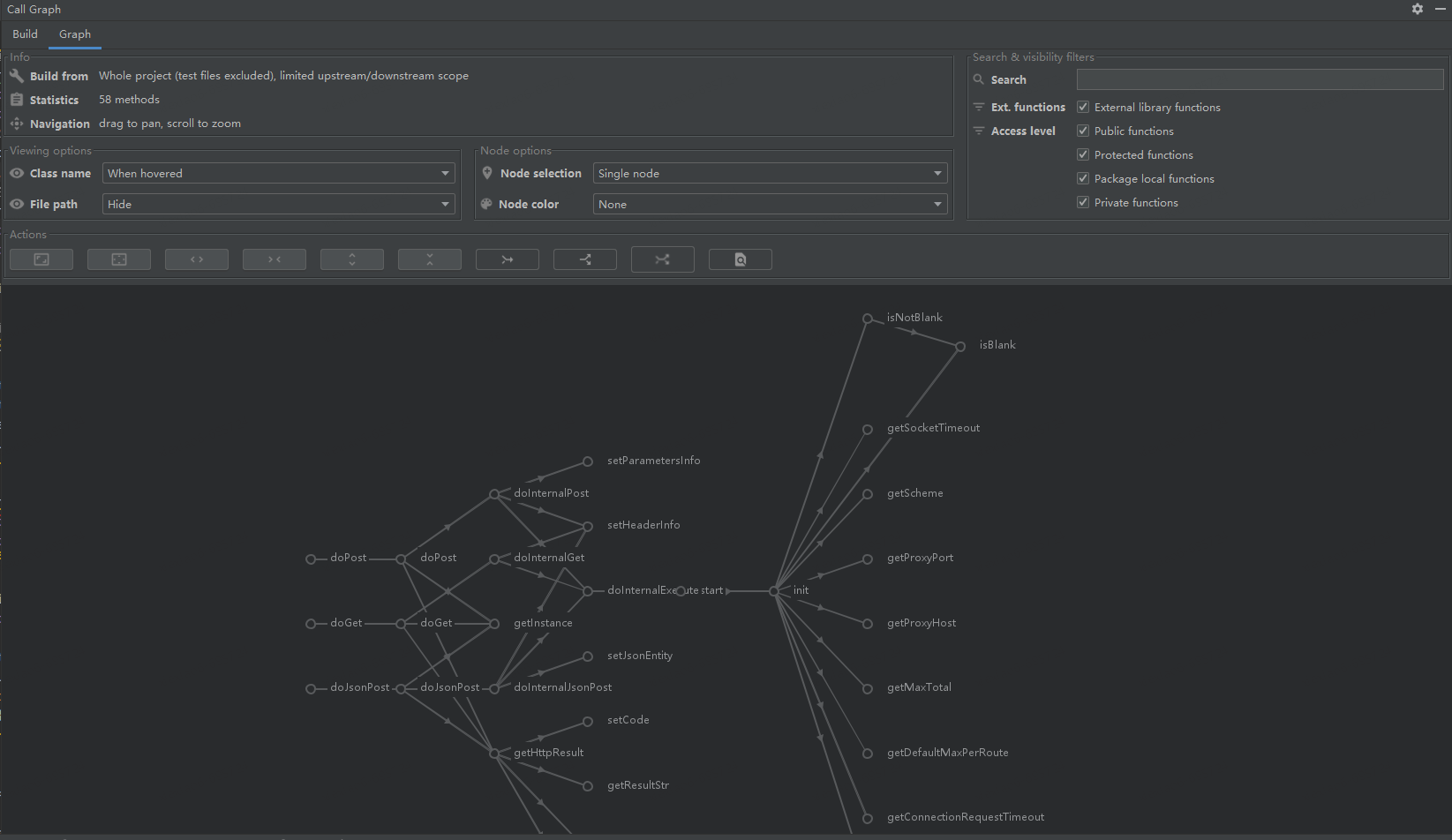
3.2 Analyse dynamique du programme
Aussi connue sous le nom d'analyse de programme d'exécution, elle est généralement implémentée sur la base de la méthode agent. Je ne l'expliquerai pas ici pour l'instant. J'écrirai un article séparé pour expliquer le principe lorsque j'en aurai l'occasion. Les étudiants intéressés peuvent essayer AppMap .
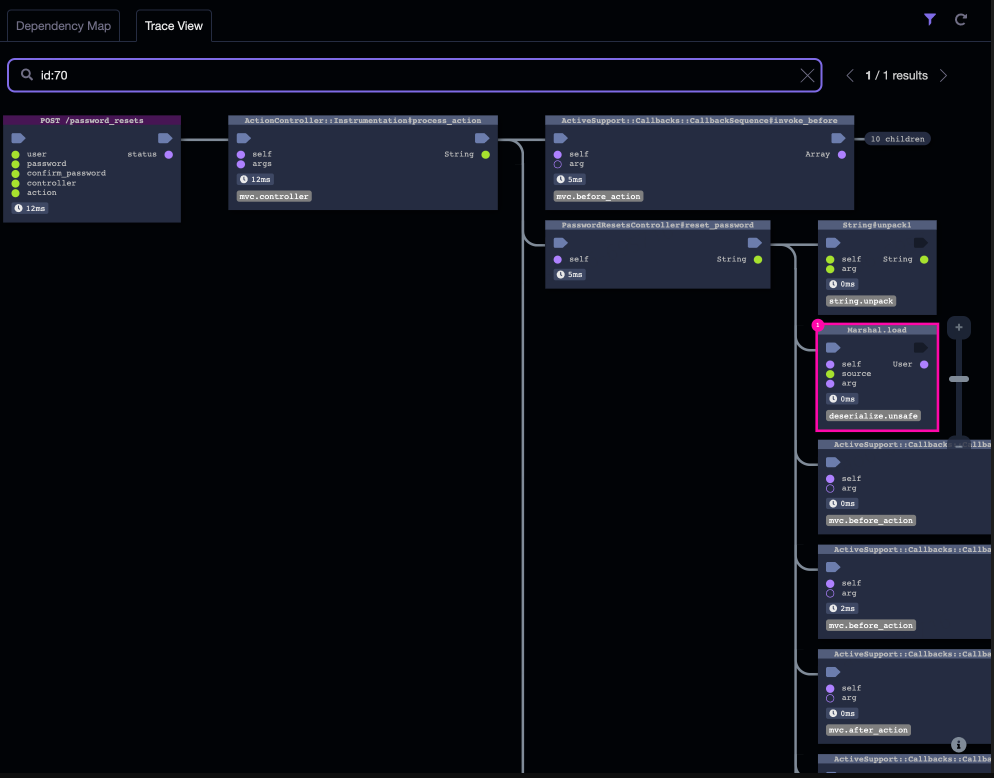
4. Quels sont les scénarios d’application ?
Scénario 1 : Modifier l'identification des risques
Contexte : Identifier les risques posés par les modifications apportées à l'infrastructure, les modifications externes au système et les modifications au sein du système.

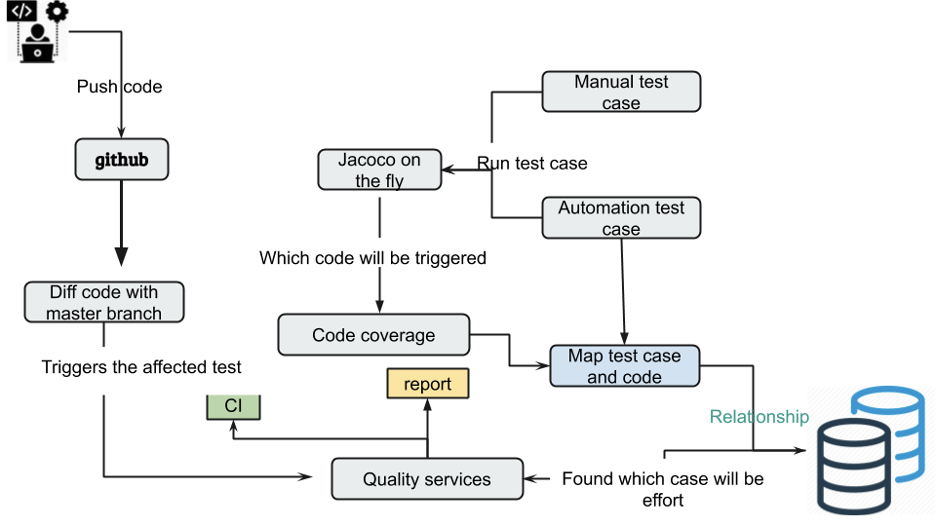
Scénario 2 : tests précis
Contexte : Des tests précis sont définis comme une série d'opérations qui utilisent des moyens techniques pour collecter, stocker, calculer, résumer et visualiser les données générées au cours du processus de test afin d'aider finalement l'équipe à améliorer l'efficacité des tests logiciels et à améliorer et optimiser l'ensemble. qualité du projet. Pour une explication détaillée, veuillez lire les deuxième et troisième chapitres de Accurate Testing.
Scénario 3 : Garde d'architecture
Contexte : Nous sommes confrontés à de nombreux défis en matière de gouvernance architecturale
1) Il existe un décalage entre la conception et la mise en œuvre. Il existe une énorme différence entre l’architecture logicielle conçue et l’architecture réellement mise en œuvre. Cette différence nécessite souvent que le codage soit mis en ligne ou même découvert après un certain temps ;
2) Absence de normes/non-respect des normes. En tant que développeur senior, nous avons développé une série de spécifications, mais peu de membres de l'équipe sont prêts à s'y conformer ;
3) La quantité de code est énorme et il est difficile d'identifier les problèmes. Dans un système créé par une douzaine ou des dizaines de microservices, il est souvent difficile de découvrir rapidement les relations complexes entre eux ;
4) Des erreurs peuvent survenir à tous les niveaux du modèle architectural. Tels que le couplage API entre services, le couplage entre codes, le couplage de bases de données, etc. ;
5) Les architectes et les développeurs eux-mêmes manquent d’une riche expérience. Je sais qu'il y a un problème, mais je ne peux pas dire quel est le problème et je ne sais pas comment l'améliorer.
Par conséquent, nous avons besoin d’une plateforme/outil pour nous aider à résoudre ces problèmes.
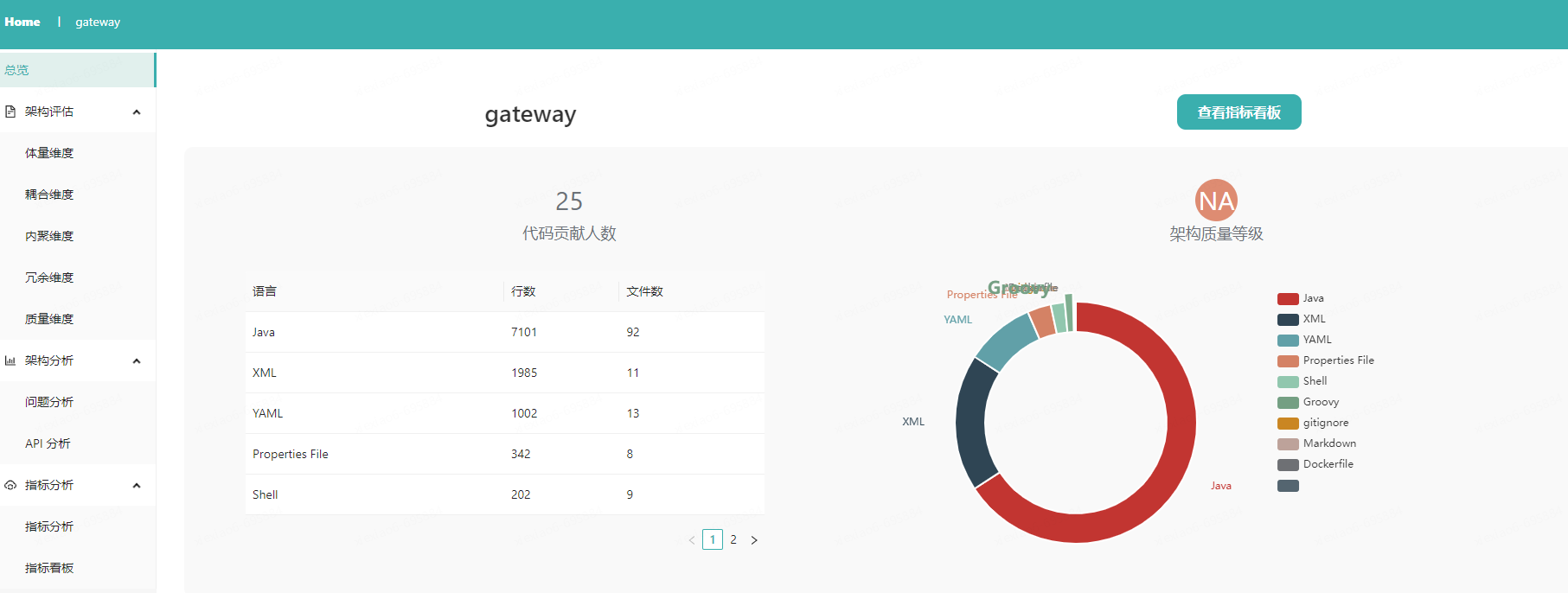
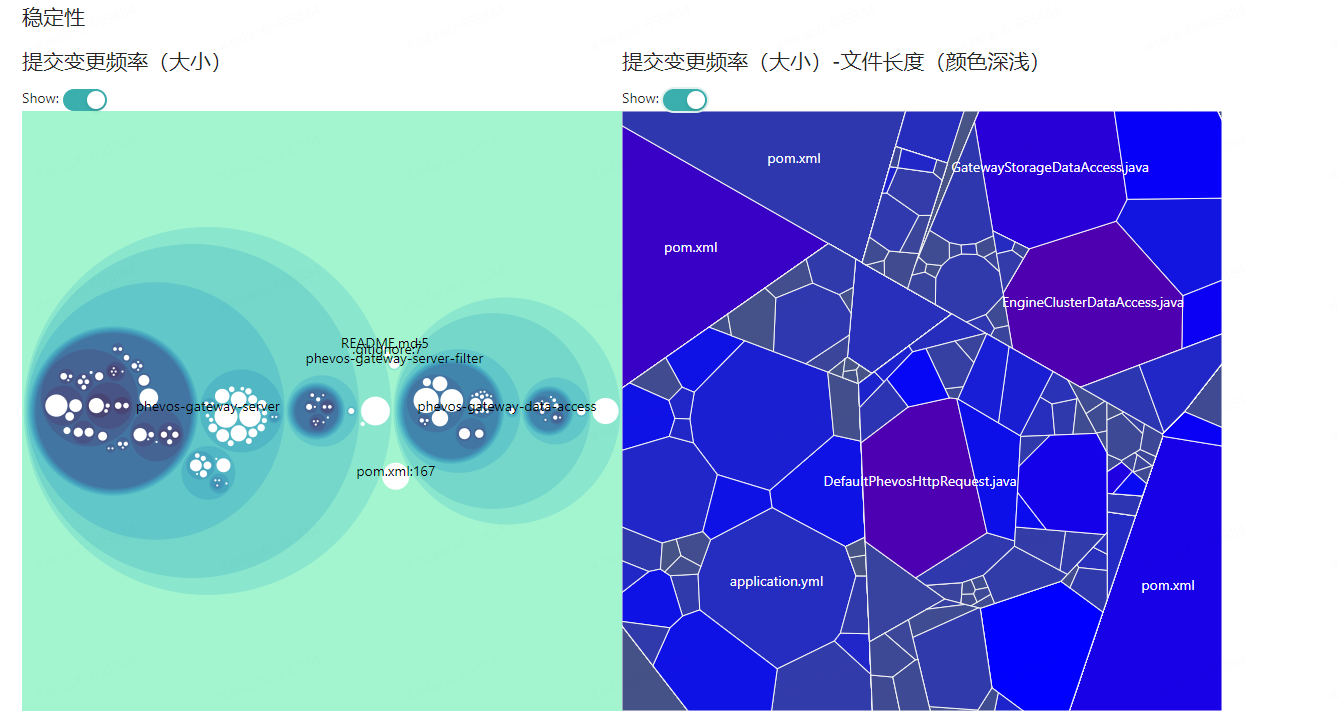
Cas : ArchGuard
Fournit une analyse visuelle basée sur le modèle C4 (contexte, conteneur, composant et code) et fournit des indicateurs de surveillance de l'état de l'architecture.
5. Prolongez la lecture
- Connaissance de base des principes de compilation
- Modèle C4 pour l'architecture logicielle
- Comment visualisez-vous le code ?
- Qu'est-ce qu'un graphique d'appel ? Et comment les générer automatiquement
- analyse de programme statique
(Avertissement : certaines photos proviennent d'Internet et ont été supprimées)
Lei Jun : La version officielle du nouveau système d'exploitation de Xiaomi, ThePaper OS, a été emballée. Une fenêtre contextuelle sur la page de loterie Gome App insulte son fondateur. Le gouvernement américain restreint l'exportation du GPU NVIDIA H800 vers la Chine. L'interface Xiaomi ThePaper OS est exposé. Un maître a utilisé Scratch pour frotter le simulateur RISC-V et il a fonctionné avec succès. Noyau Linux RustDesk Remote Desktop 1.2.3 publié, prise en charge améliorée de Wayland Après avoir débranché le récepteur USB Logitech, le noyau Linux a planté. DHH examen approfondi des "outils d'emballage" " : le front-end n'a pas du tout besoin d'être construit (No Build) JetBrains lance Writerside pour créer de la documentation technique Outils pour Node.js 21 officiellement publiéAuteur : Xie Xiao, technologie de Jingdong
Source : Communauté de développeurs JD Cloud Veuillez indiquer la source lors de la réimpression