Avant-propos : DDPM2020 est né. En seulement un an, le modèle a connu deux améliorations considérables. L'une d'elles est l'introduction de la condition. Les articles les plus récents sur le DDPM en discuteront.Certains articles l'appellent variable latente. Semblable au développement du GAN à l’époque, l’émergence du CGAN et du DCGAN a grandement favorisé le développement du GAN et revêt une grande importance.
1. Le début de la naissance : génération inconditionnelle et inconditionnelle
Guide papier : "Modèles probabilistes de diffusion de débruitage" DDPM
Selon le calcul de l'équation dynamique de Langevin , l'expression de la génération finale repose sur la prédiction du bruit du réseau neuronal pour générer des images, mais cette génération n'a aucune contrainte. C'est-à-dire qu'avec un bruit gaussien pur, nous pouvons générer des images . L'avantage est que notre entrée n'est sous aucun contrôle, tant qu'il s'agit d'un bruit gaussien. L'inconvénient est que nous ne pouvons pas superviser ce processus et que le résultat final n'est pas contrôlé. Par exemple, sur l’ensemble de données LSUN, nous pouvons générer arbitrairement diverses images :

2. Introduction de la condition pour la première fois : conseils pour le classificateur
Guide papier : « Les modèles de diffusion battent les GAN sur la synthèse d'images »
Quelques mois après la publication du dernier article, la première condition DDPM est née.Cet article forme un classificateur sur ImageNet et utilise ce classificateur pour contrôler les étiquettes.
Ce classificateur est une structure Unet avec un pool d'attention, et des cultures aléatoires sont ajoutées pour réduire le surapprentissage.
Soit y représente l'étiquette, p ϕ ( y ∣ xt , t ) p_{\phi}\left(y \mid x_{t}, t\right)pϕ( oui∣Xt,t ) représente le classificateur, en utilisant le gradient∇ xt log p ϕ ( y ∣ xt , t ) \nabla_{x_{t}} \log p_{\phi}\left(y \mid x_{t}, t\ à droite)∇Xtsalut gpϕ( oui∣Xt,t ) pour guider le processus de diffusion vers n’importe quelle étiquette de catégorie y. En bref, les informations de classe sont incorporées dans la couche de normalisation, en utilisant le classificateurp ( y ∣ x , t ) p(y|x,t)p ( y ∣ X ,t ) améliorer le générateur.
Pendant le processus d'échantillonnage inverse, à xt + 1 x_{t+1}Xt + 1Générer xt x_t sous la condition de et yXt, peut s'écrire sous la forme de la formule suivante, où la majuscule Z est une constante. L'article prouve en détail que cette formule est vraie. où p θ ( xt ∣ xt + 1 ) p_{\theta}\left(x_{t} \mid x_{t+1}\right)pje( xt∣Xt + 1) est identique à DDPM inconditionnel, doncSeulement plus p ϕ ( y ∣ xt ) p_{\phi}\left(y \mid x_{t}\right)pϕ( oui∣Xt) cet article :
p θ , ϕ ( xt ∣ xt + 1 , y ) = Z p θ ( xt ∣ xt + 1 ) p ϕ ( y ∣ xt ) p_{\theta, \phi}\left(x_{t} \mid x_{ t+1}, y\right)=Z p_{\theta}\left(x_{t} \mid x_{t+1}\right) p_{\phi}\left(y \mid x_{t}\ droite)pje , ϕ( xt∣Xt + 1,oui )=Zp _je( xt∣Xt + 1)pϕ( oui∣Xt)
Dans le même temps, cet article se concentre également sur l'exploration du rôle d'un facteur d'échelle s. Le facteur d'échelle met à l'échelle le gradient du classificateur Σ ∇ xt log p ϕ ( y ∣ xt ) \Sigma \nabla_{x_{t}} \log p_{ \phi}\left(y \mid x_{t}\right)∇ _Xtsalut gpϕ( oui∣Xt) , les expériences montrent que plus le facteur d'échelle est grand, plus le FID reconstruit est petit, c'est-à-dire plus la qualité de la reconstruction est élevée.
Profitez de ce petit morceau de code :
def cond_fn(x, t, y=None):
assert y is not None
with th.enable_grad():
x_in = x.detach().requires_grad_(True)
logits = classifier(x_in, t)
log_probs = F.log_softmax(logits, dim=-1)
selected = log_probs[range(len(logits)), y.view(-1)]
return th.autograd.grad(selected.sum(), x_in)[0] * args.classifier_scale
Conformément à l’analyse qui vient d’être faite, la logique est très claire.

3. Report : l'échantillon comprend des images de référence tout au long du processus
Guide papier : "ILVR : Méthode de conditionnement pour les modèles probabilistes de diffusion de débruitage"
Un an plus tard, un article oral sur l'ICCV s'est concentré sur une méthode conditionnelle, qui a ajouté une image de référence au processus d'échantillonnage pour guider l'image reconstruite afin qu'elle soit similaire à l'image de référence.
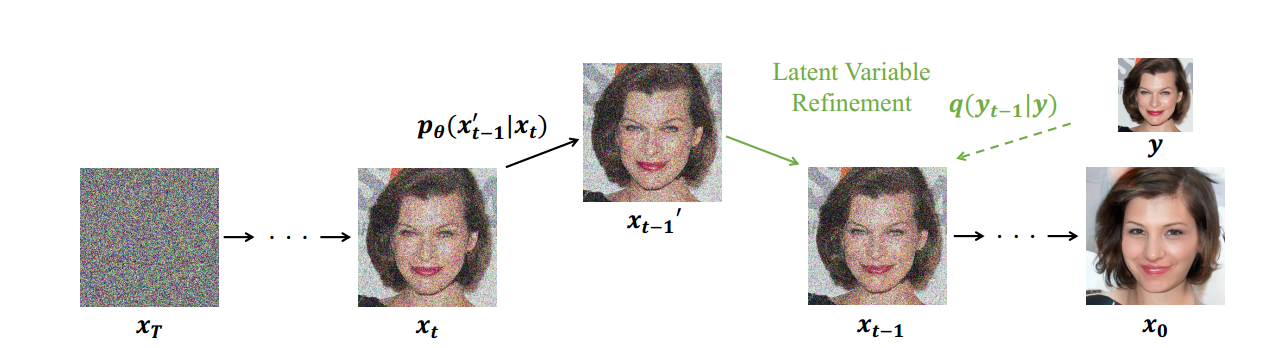
Il ne s'agit pas seulement d'un contrôle d'étiquette/catégorie. Dans un sens, nous pouvons contrôler le style généré, afin que DDPM puisse effectuer des tâches telles que la réparation d'image, l'image P, le transfert de style et même la multimodalité comme GAN !
L'image de référence est définie comme y. Nous devons maintenant conditionner c et xt x_tXtDérivation xt − 1 x_{t-1}Xt − 1, ϕ N \phi_{N}ϕNReprésente un filtre passe-bas. Ce filtre passe-bas peut être Bilinéaire, Lanczos3, Lanczos2, Bicubique, etc. La fonction de ce filtre passe-bas est de garantir que l'image générée et l'image de référence sont proches en dimension passe-bas. La condition c est utilisée pour utiliser Pour garantir que l'image générée ϕ N ( x 0 ) \phi_{N}\left(x_{0}\right)ϕN( x0) et l'image de référenceϕ N ( y ) \phi_{N}(y)ϕN( y ) sont égaux, donc l'équation peut s'écrire comme suit :
p θ ( xt − 1 ∣ xt , c ) ≈ p θ ( xt − 1 ∣ xt , ϕ N ( xt − 1 ) = ϕ N ( yt − 1 ) ) p_{\theta}\left(x_{t-1 } \mid x_{t}, c\right) \approx p_{\theta}\left(x_{t-1} \mid x_{t}, \phi_{N}\left(x_{t-1}\ droite)=\phi_{N}\left(y_{t-1}\right)\right)pje( xt − 1∣Xt,c )≈pje( xt − 1∣Xt,ϕN( xt − 1)=ϕN( ouit − 1) )
xt − 1 ′ ∼ p θ ( xt − 1 ′ ∣ xt ) xt − 1 = ϕ ( yt − 1 ) + ( I − ϕ ) ( xt − 1 ′ ) \begin{rassemblé} x_{t-1}^{ \prime} \sim p_{\theta}\left(x_{t-1}^{\prime} \mid x_{t}\right) \\ x_{t-1}=\phi\left(y_{t -1}\right)+(I-\phi)\left(x_{t-1}^{\prime}\right) \end{rassemblé}Xt − 1′∼pje( xt − 1′∣Xt)Xt − 1=ϕ( ouit − 1)+( je−) _( xt − 1′)
Encore une fois, nous séparons la partie conditionnelle de la partie inconditionnelle. Cet article se concentre sur l'exploration
de l'impact du sous-échantillonnage des facteurs N sur l'expérience. Soit u l'ensemble de génération DDPM inconditionnel. Caractéristiques de cette collection :
1) Exigences minimales pour la sélection d'images de référence ;
2) Possibilité de contrôle par l'utilisateur des sous-ensembles dirigés par référence, qui définit la similarité sémantique des images de référence.
À mesure que le facteur N augmente, un ensemble plus large d’images peut être échantillonné, et les images échantillonnées sont plus diverses et moins similaires sémantiquement aux images de référence. La similarité perceptuelle avec l'image de référence est contrôlée par le facteur de sous-échantillonnage. Les échantillons avec un facteur N élevé ont les caractéristiques grossières de l'échantillon de référence, tandis que les échantillons avec un facteur N faible ont également les caractéristiques de l'échantillon de référence.
Jetez un œil au code. Ce N est en fait un coefficient de redimensionnement :
down = Resizer(shape, 1 / args.down_N).to(next(model.parameters()).device)
up = Resizer(shape_d, args.down_N).to(next(model.parameters()).device)
Cette opération de redimensionnement provient de :
https://github.com/assafshocher/resizer
Je suis très curieux de savoir comment l'auteur s'est inspiré de ce redimensionnement. Il n'a fait une opération de redimensionnement que pour étudier les propriétés de l'échantillon. Peut-être existe-t-il des recherches similaires sur le GAN ou d'autres modèles génératifs ? ?
4. Innovation en matière de pipelines : contraintes variables potentielles
Guide papier : "Modèles probabilistes de diffusion pour la génération de nuages de points 3D"
Après m'être inspiré des idées de l'article précédent, de tels articles ont vu le jour en production de masse, et il existe de nombreux bons articles comme CVPR oral. Je choisirai un article sur la reconstruction 3D pour en parler. En fait, j'ai écrit une analyse de blog de cet article :
Utiliser DDPM pour réaliser une reconstruction de nuages de points en 3D_Le garçon accro au cyclisme - CSDN Blog
Ici, l'auteur vient de changer une référence, en utilisant un extracteur de fonctionnalités 3D mature pour extraire les fonctionnalités, et en utilisant cette fonctionnalité comme référence. Cette méthode est également utilisée dans les tâches de reconstruction de la parole, de reconstruction de séquences spatio-temporelles et de reconstruction texte-image. Voir moi pour plus de détails Dans le blog précédent, je n’entrerai pas dans les détails dans cet article.
Conclusion :
j'ai dit au début de l'article que l'introduction de la condition est une avancée majeure dans le DDPM, et qu'elle est désormais largement utilisée dans les articles DDPM. DDPM a un problème fatal, c'est-à-dire que la quantité de calcul est trop importante et le temps d'échantillonnage est trop long.Comment accélérer ce temps d'échantillonnage ? Le prochain article parlera de cette question clé, alors restez connectés !