Préface
Organisez certains paramètres de ligne de commande couramment utilisés à partir des documents officiels yolov8, des documents officiels YOLOv8 Docs
Le format d'exécution unifié de la ligne de commande yolov8 est :
yolo TASK MODE ARGS
Il y a trois parties principales du transfert de paramètres :
- TASK (facultatif) est l'un des [détecter, segmenter, classer]. S'il n'est pas transmis explicitement, YOLOv8 essaiera de deviner TASK à partir du type de modèle.
- MODE (obligatoire) est l'un des [train, val, prédire, exporter]
- ARGS (facultatif) est un nombre quelconque de paires arg=value personnalisées, telles que imgsz=320, remplaçant la valeur par défaut.
1. Paramètres de formation
Exemple de ligne de commande de formation :
# 从YAML中构建一个新模型,并从头开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
# 从预先训练的*.pt模型开始训练
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
# 从YAML中构建一个新的模型,将预训练的权重传递给它,并开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
Exemple de code python correspondant :
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # 从YAML中构建一个新模型
model = YOLO('yolov8n.pt') #加载预训练的模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并传递权重
# Train the model
model.train(data='coco128.yaml', epochs=100, imgsz=640)
Certains des paramètres les plus couramment utilisés :
| clé | expliquer |
|---|---|
| modèle | Le fichier model.yaml ou model.pt transmis est utilisé pour construire le réseau et l'initialiser. La différence est que si seul le fichier yaml est transmis, les paramètres seront initialisés de manière aléatoire. |
| données | Fichier yaml de configuration de l'ensemble de données d'entraînement |
| époques | Tours d'entraînement, par défaut 100 |
| patience | Le nombre de tours pour l'entraînement et l'observation à arrêt précoce est par défaut de 50. S'il n'y a pas d'amélioration de la précision en 50 tours, le modèle arrêtera directement l'entraînement. |
| lot | Lot de formation, par défaut 16 |
| images | Taille de l'image d'entraînement, 640 par défaut |
| sauvegarder | Enregistrez le processus d'entraînement et les poids d'entraînement, activés par défaut |
| période_de_sauvegarde | Pendant le processus de formation, le modèle de formation est enregistré tous les x tours, la valeur par défaut est -1 (non activé) |
| cache | S'il faut utiliser la RAM pour le chargement des données. La définition de True accélérera la formation, mais ce paramètre consomme beaucoup de mémoire et est généralement défini par les serveurs. |
| appareil | Le périphérique sur lequel s'exécuter, c'est-à-dire cuda device =0 ou Device =0,1,2,3 ou device=cpu |
| ouvriers | Le nombre de threads pour charger les données. Windows est généralement 4 et le serveur peut être plus grand. Ce paramètre sous Windows peut provoquer des erreurs de thread. Si vous constatez que des erreurs de thread sont signalées, vous pouvez essayer de réduire ce paramètre. Ce paramètre a la valeur par défaut 8, et la plupart d'entre elles doivent reduire. |
| projet | Le nom du dossier du projet, par défaut, exécute |
| nom | Utilisé pour enregistrer le nom du dossier de formation, exp par défaut, accumulé dans la séquence |
| existe_ok | S'il faut écraser le dossier de sauvegarde existant, la valeur par défaut est False |
| pré-entraîné | S'il faut charger des poids pré-entraînés, la valeur par défaut est Flase |
| optimiseur | Sélection de l'optimiseur, SGD par défaut, facultatif [SGD, Adam, AdamW, RMSProP] |
| verbeux | S'il faut imprimer une sortie détaillée |
| graine | Graine aléatoire, utilisée pour reproduire le modèle, par défaut 0 |
| déterministe | Définir sur True pour garantir la reproductibilité des expériences |
| single_cls | Entraînez les données multicatégories dans une seule catégorie et traitez toutes les données comme une seule catégorie pour l'entraînement. La valeur par défaut est Flase. |
| image_weights | Utiliser la sélection d'images pondérées pour l'entraînement, la valeur par défaut est Flase |
| rectifier | Utilisez l'apprentissage du rectangle, qui est identique à l'inférence du rectangle. La valeur par défaut est False. |
| cos_lr | Utiliser la planification du taux d'apprentissage du cosinus, la valeur par défaut est Flase |
| close_mosaïque | L'amélioration de la mosaïque est désactivée pour les x derniers tours, par défaut 10 |
| CV | Entraînement au point d'arrêt, la valeur par défaut est Flase |
| lr0 | Taux d'apprentissage d'initialisation, par défaut 0,01 |
| lrf | Taux d'apprentissage final, par défaut 0,01 |
| label_smoothing | Paramètre de lissage des étiquettes, par défaut 0,0 |
| abandonner | Utiliser la régularisation d'abandon (classification uniquement pour la formation), par défaut 0,0 |
Paramètres d'augmentation des données :
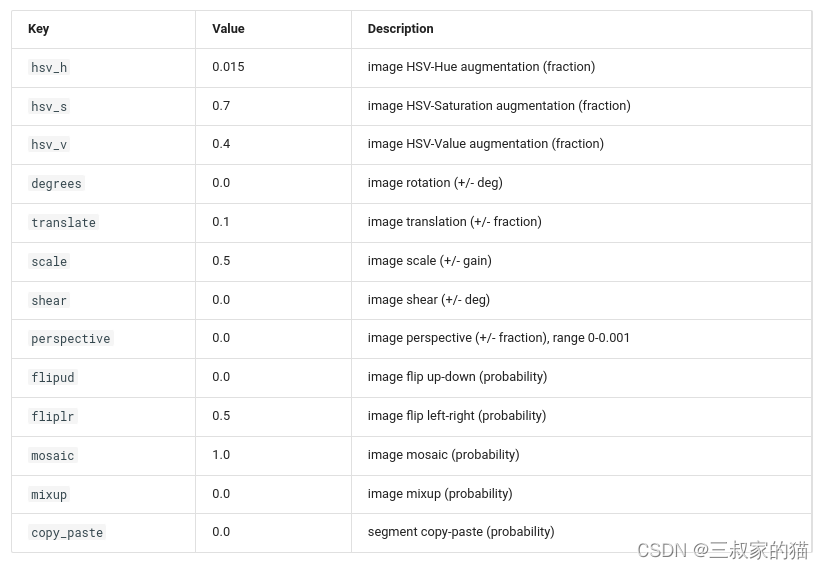
Pour plus de paramètres, se référer à : modes/train
2. Paramètres d'évaluation
Évaluez l’exemple de code de ligne de commande :
yolo detect val model=yolov8n.pt # val 官方模型
yolo detect val model=path/to/best.pt # val 自己训练的模型
Code python correspondant :
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') #加载官方模型
model = YOLO('path/to/best.pt') # 加载自己训练的模型
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
Certains des paramètres les plus couramment utilisés :
| clé | expliquer |
|---|---|
| modèle | Le chemin d'accès au fichier de modèle pt qui doit être évalué |
| données | Fichier yaml d'ensemble de données qui doit être évalué |
| images | Évaluer la taille de l'inférence d'image, par défaut 640 |
| lot | Évaluer les lots d'inférence, par défaut 16 |
| save_json | S'il faut enregistrer les résultats de l'évaluation en tant que sortie json, la valeur par défaut est False |
| save_hybride | S'il faut enregistrer des versions mixtes d'étiquettes (étiquettes + prédictions supplémentaires) |
| conf | Seuil de confiance de l'évaluation du modèle, par défaut 0,001 |
| je te | Seuil iou d'évaluation du modèle, par défaut 0,6 |
| max_it | Nombre maximum de cibles détectées dans une seule image, par défaut 300 |
| moitié | S'il faut utiliser l'inférence fp16, True par défaut |
| appareil | Le périphérique sur lequel s'exécuter, c'est-à-dire cuda device =0 ou Device =0,1,2,3 ou device=cpu |
| merde | 是否使用use OpenCV DNN for ONNX inference,默认Flase |
| rect | 是否使用矩形推理,默认False |
| split | 数据集分割用于验证,即val、 test、train,默认val |
三、推理参数
推理命令行示例:
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
对应python代码示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model
# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
# 目标检测后处理
boxes = results[0].boxes
boxes.xyxy # box with xyxy format, (N, 4)
boxes.xywh # box with xywh format, (N, 4)
boxes.xyxyn # box with xyxy format but normalized, (N, 4)
boxes.xywhn # box with xywh format but normalized, (N, 4)
boxes.conf # confidence score, (N, 1)
boxes.cls # cls, (N, 1)
boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
# 实例分割后处理
masks = results[0].masks # Masks object
masks.segments # bounding coordinates of masks, List[segment] * N
masks.data # raw masks tensor, (N, H, W) or masks.masks
# 目标分类后处理
results = model(inputs)
results[0].probs # cls prob, (num_class, )
一些常用传参解释:
| key | 解释 |
|---|---|
| source | 跟之前的yolov5一致,可以输入图片路径,图片文件夹路径,视频路径 |
| save | 保存检测后输出的图像,默认False |
| conf | 用于检测的对象置信阈值,默认0.25 |
| iou | 用于nms的IOU阈值,默认0.7 |
| half | FP16推理,默认False |
| device | 要运行的设备,即cuda设备=0/1/2/3或设备=cpu |
| show | 用于推理视频过程中展示推理结果,默认False |
| save_txt | 是否把识别结果保存为txt,默认False |
| save_conf | 保存带有置信度分数的结果 ,默认False |
| save_crop | 保存带有结果的裁剪图像,默认False |
| hide_label | 保存识别的图像时候是否隐藏label ,默认False |
| hide_conf | 保存识别的图像时候是否隐藏置信度,默认False |
| vid_stride | 视频检测中的跳帧帧数,默认1 |
| classes | 展示特定类别的,根据类过滤结果,即class=0,或class=[0,2,3] |
| line_thickness | 目标框中的线条粗细大小 ,默认3 |
| visualize | 可视化模型特征 ,默认False |
| augment | 是否使用数据增强,默认False |
| agnostic_nms | 是否采用class-agnostic NMS,默认False |
| retina_masks | 使用高分辨率分割掩码,默认False |
| max_det | 单张图最大检测目标,默认300 |
| box | 在分割人物中展示box信息,默认True |
yolov8支持各种输入源推理:
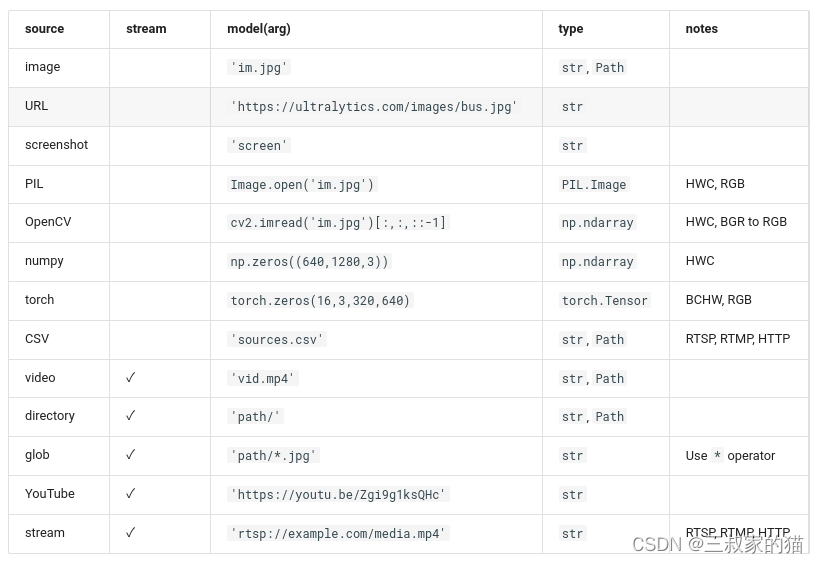
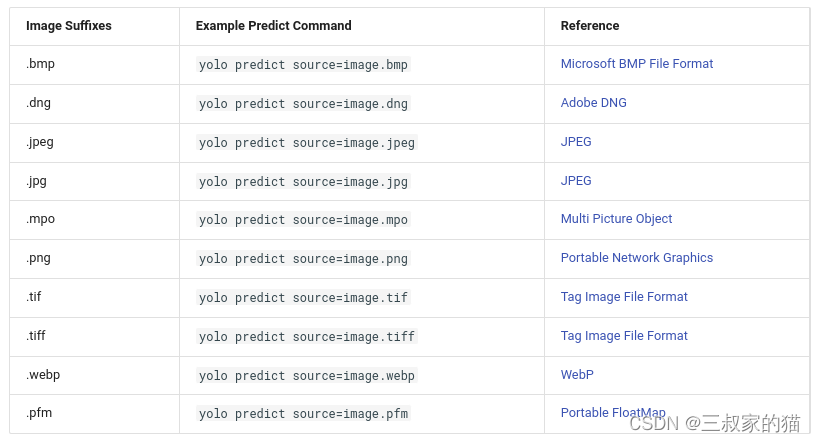
对于图片还支持以下保存格式的输入图片:
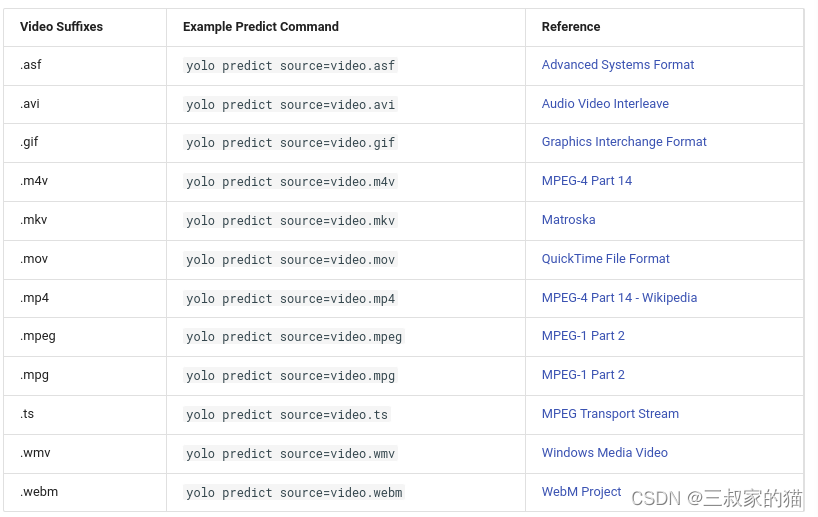
对于视频支持以下视频格式输入:
返回的result结果解析:
- Results.boxes: 目标检测返回的boxes信息
- Results.masks: 返回的分割mask坐标信息
- Results.probs: 分类输出的类概率
- Results.orig_img: 原始图像
- Results.path: 输入图像的路径
result可以使用如下方法在加载到cpu或者gpu设备中:
- results = results.cuda()
- results = results.cpu()
- results = results.to(“cpu”)
- results = results.numpy()
更多细节:modes/predict
四、模型导出
yolov8支持一键导出多种部署模型,支持如下格式的模型导出:
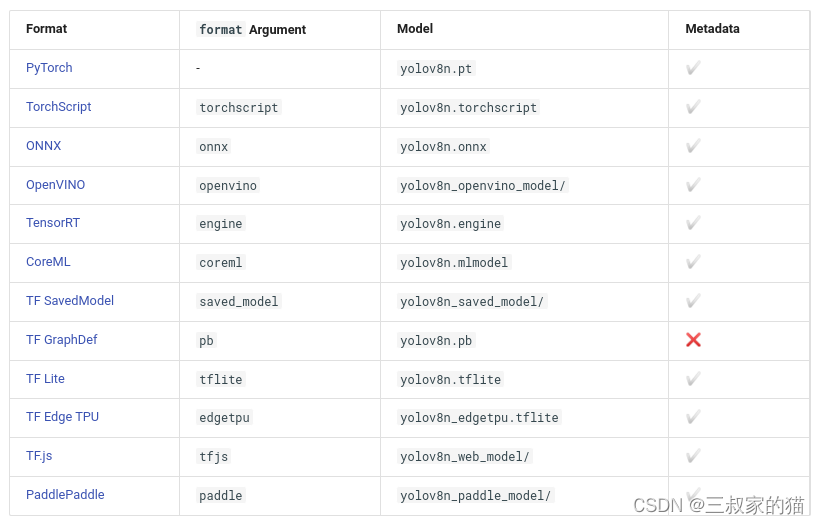
命令行运行示例:
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
python代码示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')
一些常用参数解释:
| key | 解释 |
|---|---|
| format | 导出的格式,默认’torchscript’,可选如上支持的格式 onnx、engine、openvino等 |
| imgsz | 导出时固定的图片推理大小,为标量或(h, w)列表,即(640,480) ,默认640 |
| keras | 使用Keras导出TF SavedModel ,用于部署tensorflow模型,默认False |
| optimize | 是否针对移动端对TorchScript进行优化 |
| half | fp16量化导出,默认False |
| int8 | int8量化导出,默认False |
| dynamic | 针对ONNX/TF/TensorRT:动态推理,默认False |
| simplify | onnx simplify简化,默认False |
| opset | onnx的Opset版本(可选,默认为最新) |
| workspace | TensorRT:工作空间大小(GB),默认4 |
| nms | 导出CoreML,添加NMS |
更多参考:modes/export
五、跟踪参数
yolov8目前支持:BoT-SORT、ByteTrack两种目标跟踪,默认使用BoT-SORT
命令行使用示例:
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
yolo track model=yolov8n-seg.pt source=... # official segmentation model
yolo track model=path/to/best.pt source=... # custom model
yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
python代码使用示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official detection model
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
model = YOLO('path/to/best.pt') # load a custom model
# Track with the model
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
Il prend en charge les modèles de détection et de segmentation, et il vous suffit de charger les poids correspondants.
Les paramètres transmis pour le suivi sont les mêmes que ceux utilisés pour l'inférence. Il existe trois paramètres principaux : conf, iou et show.
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
# or
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
Vous pouvez également personnaliser le fichier de configuration du suivi. Vous devez modifier le fichier yaml dans ultralytics/tracker/cfg et modifier la configuration dont vous avez besoin (sauf pour le type de tracker). La même méthode de fonctionnement :
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
# or
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
6. Paramètres de test de référence
Le mode Benchmark est utilisé pour analyser la vitesse et la précision des différents formats d'exportation de YOLOv8. Les benchmarks fournissent des informations sur la taille du format d'exportation, sa métrique mAP50-95 (pour la détection et la segmentation d'objets) ou sa métrique de précision top5 (pour la classification), ainsi que sur les performances de différents formats d'exportation (tels que ONNX, OpenVINO, TensorRT). , etc.), temps d'inférence par image en millisecondes. Ces informations aident les utilisateurs à choisir le meilleur format d'exportation pour leurs cas d'utilisation spécifiques, en fonction de leurs besoins de rapidité et de précision.
Exemple de code de ligne de commande :
yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
Exemple de code python :
from ultralytics.yolo.utils.benchmarks import benchmark
# Benchmark
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
Quelques paramètres courants pour les tests de référence :
| clé | expliquer |
|---|---|
| modèle | Chemin du fichier modèle, yoloV8v.pt, etc. |
| images | Taille de l'image de référence, par défaut 640 |
| moitié | S'il faut activer fp16 pour les tests de référence, False par défaut |
| appareil | Sur quels appareils sont testés cuda : device=0 ou device=0,1,2,3 ou device=cpu |
| échec_dur | Arrêtez de continuer en cas d'erreur (bool) ou de seuil inférieur de valeur (float), par défaut False |
Les benchmarks peuvent prendre en charge l'exécution de tests sur les formats exportés suivants :

Plus de référence : modes/benchmark
7. Autres tâches
Référence de segmentation : segment
Référence de classification : classer