Optimisation de l'index
1. Préparation des données
500 000 entrées sont insérées dans les listes d'étudiants et 10 000 entrées sont insérées dans les listes de classes.
Créer un tableau
CREATE TABLE `class` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`className` VARCHAR ( 30 ) DEFAULT NULL,
`address` VARCHAR ( 40 ) DEFAULT NULL,
`monitor` INT NULL,
PRIMARY KEY ( `id` )
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
CREATE TABLE `student` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL,
`name` VARCHAR ( 20 ) DEFAULT NULL,
`age` INT ( 3 ) DEFAULT NULL,
`classId` INT ( 11 ) DEFAULT NULL,
PRIMARY KEY ( `id` ) #CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
Paramètres de réglage
- Commande sur : Autoriser la création de paramètres de fonction :
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
Créer une fonction
Assurez-vous que chaque élément de données est différent.
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string ( n INT ) RETURNS VARCHAR ( 255 ) BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = CONCAT(
return_str,
SUBSTRING( chars_str, FLOOR( 1+RAND ()* 52 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;#假如要删除
#drop function rand_string;
Générer aléatoirement des numéros de classe
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num ( from_num INT, to_num INT ) RETURNS INT ( 11 ) BEGIN
DECLARE
i INT DEFAULT 0;
SET i = FLOOR(
from_num + RAND()*(
to_num - from_num + 1
));
RETURN i;
END //
DELIMITER;#假如要删除
#drop function rand_num;
Créer une procédure stockée
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu ( START INT, max_num INT ) BEGIN
DECLARE
i INT DEFAULT 0;
SET autocommit = 0;#设置手动提交事务
REPEAT#循环
SET i = i + 1;#赋值
INSERT INTO student ( stuno, NAME, age, classId )
VALUES
((
START + i
),
rand_string ( 6 ),
rand_num ( 1, 50 ),
rand_num ( 1, 1000 ));
UNTIL i = max_num
END REPEAT;
COMMIT;#提交事务
END //
DELIMITER;#假如要删除
#drop PROCEDURE insert_stu;
Créer une procédure stockée pour insérer des données dans la table de classe
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE `insert_class` ( max_num INT ) BEGIN
DECLARE
i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname, address, monitor )
VALUES
(
rand_string ( 8 ),
rand_string ( 10 ),
rand_num ( 1, 100000 ));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER;#假如要删除
#drop PROCEDURE insert_class;
Appeler une procédure stockée
classe
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
stu
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
Supprimer un index sur une table
Créer une procédure stockée
DELIMITER //
CREATE PROCEDURE `proc_drop_index` (
dbname VARCHAR ( 200 ),
tablename VARCHAR ( 200 )) BEGIN
DECLARE
done INT DEFAULT 0;
DECLARE
ct INT DEFAULT 0;
DECLARE
_index VARCHAR ( 200 ) DEFAULT '';
DECLARE
_cur CURSOR FOR SELECT
index_name
FROM
information_schema.STATISTICS
WHERE
table_schema = dbname
AND table_name = tablename
AND seq_in_index = 1
AND index_name <> 'PRIMARY';#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE
CONTINUE HANDLER FOR NOT FOUND
SET done = 2;#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE
_index <> '' DO
SET @str = CONCAT( "drop index ", _index, " on ", tablename );
PREPARE sql_str
FROM
@str;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index = '';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER;
Exécuter la procédure stockée
CALL proc_drop_index("dbname","tablename");
2. Cas d'échec de l'index
2.1 Valeur totale correspondant à mon favori
2.2 Règle du meilleur préfixe gauche
Extension : Le fichier d'index Alibaba "Java Development Manual" possède la fonction de correspondance de préfixe la plus à gauche de B-Tree. Si la valeur à gauche n'est pas déterminée, cet index ne peut pas être utilisé.
2.3 Ordre d'insertion de la clé primaire
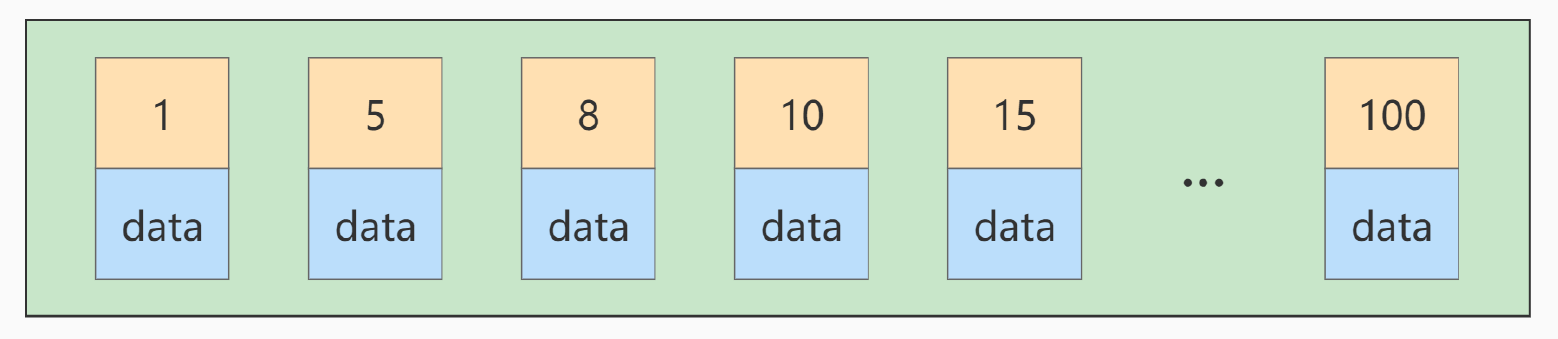
Si vous insérez un autre enregistrement avec une valeur de clé primaire de 9 à ce moment-là, sa position d'insertion sera comme indiqué ci-dessous :
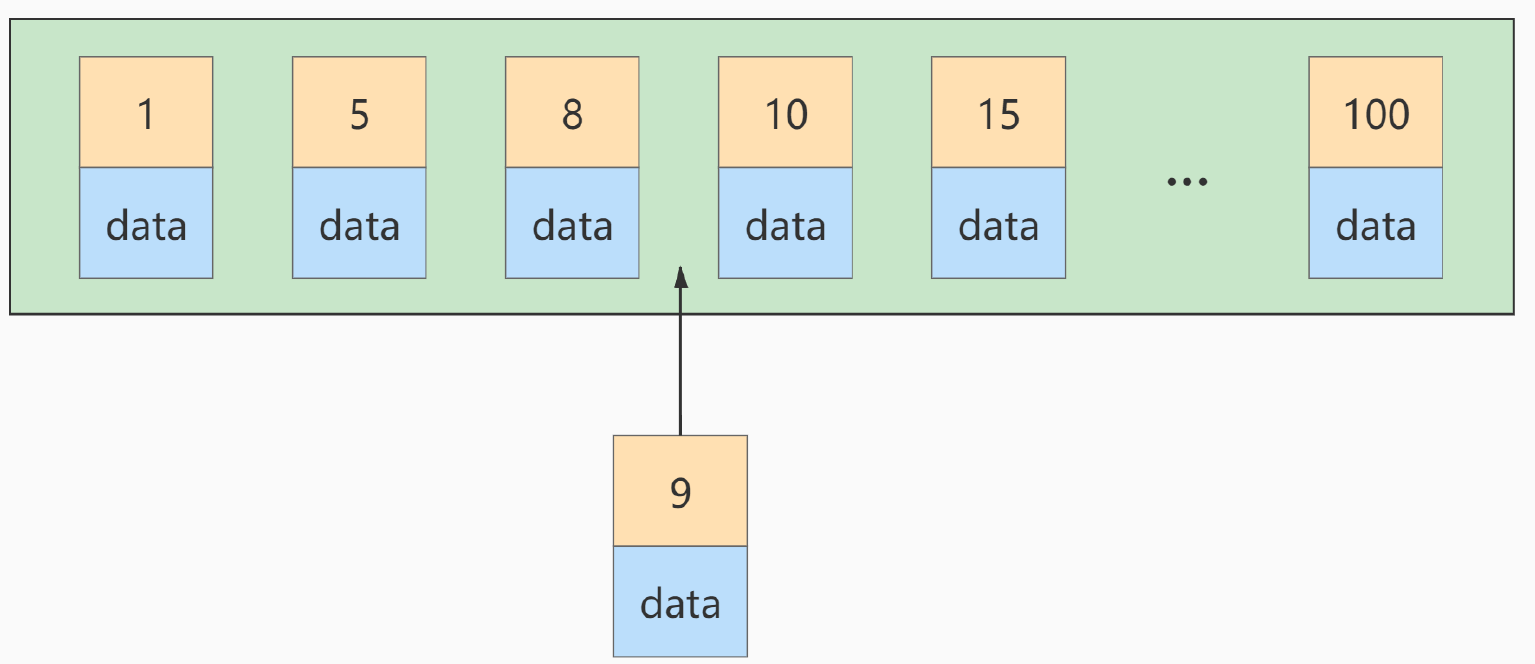
Mais cette page de données est déjà pleine, que dois-je faire si je l'insère à nouveau ? Nous devons diviser la page actuelle en deux pages et déplacer certains enregistrements de cette page vers la page nouvellement créée. Que signifient les fractionnements de pages et les décalages d’enregistrement ? Signification : Perte de performances ! Ainsi, si nous voulons éviter autant que possible une telle perte de performances inutile, il est préférable d'augmenter la valeur de la clé primaire de l'enregistrement inséré dans l'ordre, afin qu'une telle perte de performances ne se produise pas. Nous suggérons donc : laissez la clé primaire avoir AUTO_INCREMENT, et laissez le moteur de stockage générer lui-même la clé primaire de la table au lieu de l'insérer manuellement, par exemple : table person_info :
CREATE TABLE person_info (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
NAME VARCHAR ( 100 ) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR ( 11 ) NOT NULL,
country VARCHAR ( 100 ) NOT NULL,
PRIMARY KEY ( id ),
KEY idx_name_birthday_phone_number ( NAME ( 10 ), birthday, phone_number )
);
Notre ID de colonne de clé primaire personnalisé a AUTO_INCREMENT des attributs, et le moteur de stockage remplira automatiquement la valeur de clé primaire auto-incrémentée pour nous lors de l'insertion d'enregistrements. Ces clés primaires prennent peu de place, sont écrites de manière séquentielle et réduisent les fractionnements de pages.
2.4 Défaillance de l'index causée par un calcul, une fonction, une conversion de type (automatique ou manuelle)
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
Créer un index
CREATE INDEX idx_name ON student(NAME);
Type 1 : l'optimisation de l'index prend effet
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
Deuxième type : échec de l'optimisation de l'index
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 498917 | 100.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
mysql> SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
+--------+--------+--------+------+---------+
| id | stuno | name | age | classId |
+--------+--------+--------+------+---------+
| 399 | 100399 | ABcKtL | 24 | 198 |
| 16470 | 116470 | ABcJlg | 47 | 251 |
| 27952 | 127952 | ABcJmj | 10 | 397 |
| 54809 | 154809 | aBClvu | 37 | 495 |
| 61540 | 161540 | abclUS | 30 | 374 |
| 83160 | 183160 | aBCjpV | 34 | 593 |
| 89664 | 189664 | aBCjmJ | 34 | 350 |
| 240498 | 340498 | aBCksj | 41 | 491 |
| 245214 | 345214 | abciJU | 23 | 568 |
| 258459 | 358459 | aBClxC | 23 | 566 |
| 300169 | 400169 | aBClxC | 21 | 412 |
| 300328 | 400328 | ABcJnn | 27 | 870 |
| 324684 | 424684 | aBCkrg | 30 | 566 |
| 416907 | 516907 | ABcHgI | 46 | 607 |
| 424459 | 524459 | abclVU | 39 | 192 |
| 445547 | 545547 | ABcJpw | 16 | 180 |
| 454772 | 554772 | AbCHFf | 37 | 313 |
| 466466 | 566466 | abckRF | 26 | 725 |
| 475708 | 575708 | abclWY | 4 | 415 |
| 486611 | 586611 | ABcLwb | 41 | 948 |
| 490152 | 590152 | ABcHfC | 24 | 717 |
+--------+--------+--------+------+---------+
21 rows in set, 1 warning (0.12 sec)
le type est "ALL", indiquant qu'aucun index n'est utilisé
2.5 La conversion de type provoque un échec de l'index
Laquelle des instructions SQL suivantes peut utiliser des index. (Supposons qu'il existe un index défini sur le champ de nom)
# 未使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_name | NULL | NULL | NULL | 498917 | 10.00 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 4 warnings (0.00 sec)
# 使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | student | NULL | ref | idx_name | idx_name | 63 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 2 warnings (0.00 sec)
- La conversion de type se produit dans name=123 et l'index n'est pas valide.
2.6 L'index de colonne sur le côté droit de la condition de plage n'est pas valide
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
create index idx_age_name_classid on student(age,name,classid);
- Placez la condition de requête de plage à la fin de l'instruction :
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =
-> 'abc' AND student.classId>20 ;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | student | NULL | range | idx_age_name_classid | idx_age_name_classid | 73 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
1 row in set, 2 warnings (0.00 sec)
2.7 Différent de (!= ou <>) index invalide
2.8 L'index peut être utilisé pour est nul, mais l'index ne peut pas être utilisé pour n'est pas nul.
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
2.9 comme l'index commençant par le caractère générique % n'est pas valide
Expansion : Alibaba "Java Development Manual"
[Obligatoire] La recherche de pages floues à gauche ou entièrement floues est strictement interdite. Si nécessaire, veuillez utiliser un moteur de recherche pour le résoudre.
2.10 Il y a des colonnes non indexées avant et après OR, et l'index n'est pas valide.
# 未使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_age_name_classid | NULL | NULL | NULL | 498917 | 11.88 | Using where |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
# 使用到索引
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | student | NULL | ALL | idx_age_name_classid | NULL | NULL | NULL | 498917 | 11.88 | Using where |
+----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
1 row in set, 2 warnings (0.00 sec)
2.11 Les jeux de caractères des bases de données et des tables utilisent utf8mb4 de manière uniforme.
L'utilisation unifiée de utf8mb4 (prise en charge par la version 5.5.3 ou supérieure) offre une meilleure compatibilité et le jeu de caractères unifié peut éviter les caractères tronqués causés par la conversion du jeu de caractères. Différents jeux de caractères doivent être convertis avant la comparaison, ce qui entraînera un échec de l'index.
3. Optimisation des requêtes associées
3.1 Préparation des données
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#向分类表中添加20条记录
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO TYPE(card) VALUES(FLOOR(1 + (RAND() * 20)));
#向图书表中添加20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2 Utiliser la jointure externe gauche
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
Conclusion : le type a tout
Ajouter une optimisation d'index
ALTER TABLE book ADD INDEX Y ( card); #【被驱动表】,可以避免全表扫描
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
Vous pouvez voir que le type de la deuxième ligne a été changé en ref, et les lignes ont également changé pour une optimisation évidente. Ceci est déterminé par la propriété de jointure gauche. La condition LEFT JOIN
est utilisée pour déterminer comment rechercher les lignes de la table de droite. Il doit y avoir toutes les lignes sur le côté gauche, donc le côté droit est notre point clé et doit être indexé.
ALTER TABLE `type` ADD INDEX X (card); #【驱动表】,无法避免全表扫描
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | NULL | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
DROP INDEX Y ON book;
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | index | NULL | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
3.3 Utiliser les jointures internes
drop index X on type;
drop index Y on book;
Remplacer par une jointure interne (MySQL sélectionne automatiquement la table des pilotes)
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 2 warnings (0.00 sec)
Ajouter une optimisation d'index
ALTER TABLE book ADD INDEX Y ( card);
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
ALTER TABLE type ADD INDEX X (card);
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | X | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
alors:
DROP INDEX X ON `type`;
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | TYPE | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.TYPE.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
alors:
ALTER TABLE `type` ADD INDEX X (card);
mysql> EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
| 1 | SIMPLE | type | NULL | index | X | X | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | Y | Y | 4 | atguigudb2.type.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
3.4 Principe de l'instruction join
Jointure à boucle imbriquée d'index
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
Si vous utilisez directement l'instruction join, l'optimiseur MySQL peut sélectionner la table t1 ou t2 comme table pilote, ce qui affectera le processus d'exécution de notre analyse de l'instruction SQL. Par conséquent, afin de faciliter l'analyse des problèmes de performances lors de l'exécution, j'ai plutôt straight_join demandé à MySQL d'utiliser une méthode de connexion fixe pour exécuter la requête, afin que l'optimiseur ne rejoigne que de la manière spécifiée. Dans cette instruction, t1 est la table pilote et t2 est la table pilotée.
On peut voir que dans cette instruction, il y a un index sur le champ a de la table pilotée t2, et que le processus de jointure utilise cet index, donc le flux d'exécution de cette instruction est le suivant :
- Lire une ligne de données R du tableau t1 ;
- De la ligne de données R, retirez le champ a et recherchez-le dans le tableau t2 ;
- Supprimez les lignes qui remplissent les conditions du tableau t2 et formez une ligne avec R dans le cadre de l'ensemble de résultats ;
- Répétez les étapes 1 à 3 jusqu'à ce que la boucle se termine à la fin du tableau t1.
Ce processus consiste d'abord à parcourir la table t1, puis à accéder à la table t2 pour rechercher les enregistrements qui remplissent les conditions en fonction de la valeur a dans chaque ligne de données extraites de la table t1. Formellement, ce processus est similaire à la requête imbriquée lorsque nous écrivons un programme et peut utiliser l'index de la table pilotée. Nous l'appelons donc « Index Nested-Loop Join », ou NLJ en abrégé.
Son organigramme correspondant est le suivant :
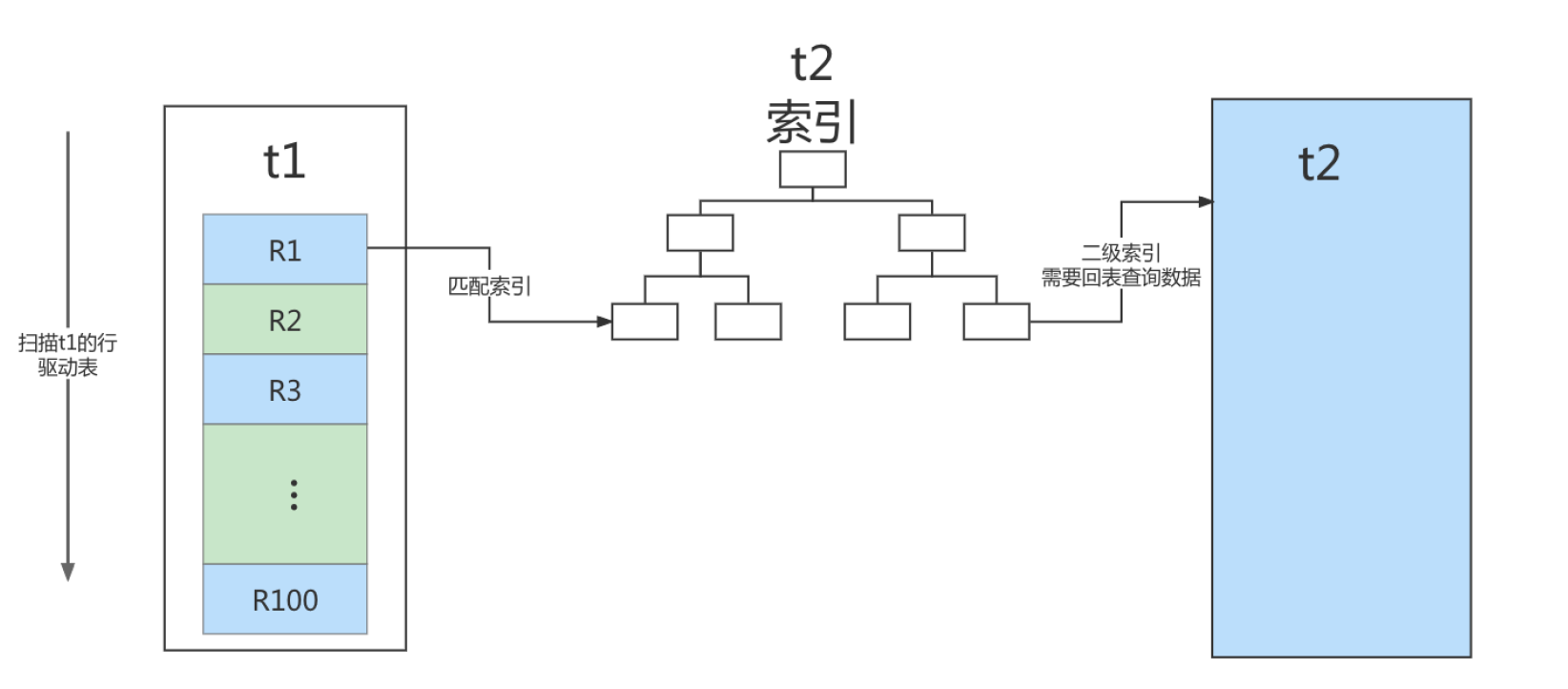
Dans ce processus:
- Une analyse complète de la table a été effectuée sur la table pilote t1. Ce processus a nécessité l'analyse de 100 lignes ;
- Pour chaque ligne de R, la table t2 est recherchée en fonction du champ a, en utilisant un processus de recherche arborescente. Étant donné que les données que nous construisons ont une correspondance biunivoque, une seule ligne est analysée dans chaque processus de recherche, et un total de 100 lignes sont analysées ;
- Par conséquent, le nombre total de lignes analysées dans l’ensemble du processus d’exécution est de 200.
Deux conclusions :
- En utilisant l'instruction join, les performances sont meilleures que si elle était divisée de force en plusieurs tables uniques pour exécuter des instructions SQL ;
- Si vous utilisez l'instruction join, vous devez faire de la petite table la table motrice.
Jointure à boucle imbriquée simple
Bloc de jointure à boucle imbriquée
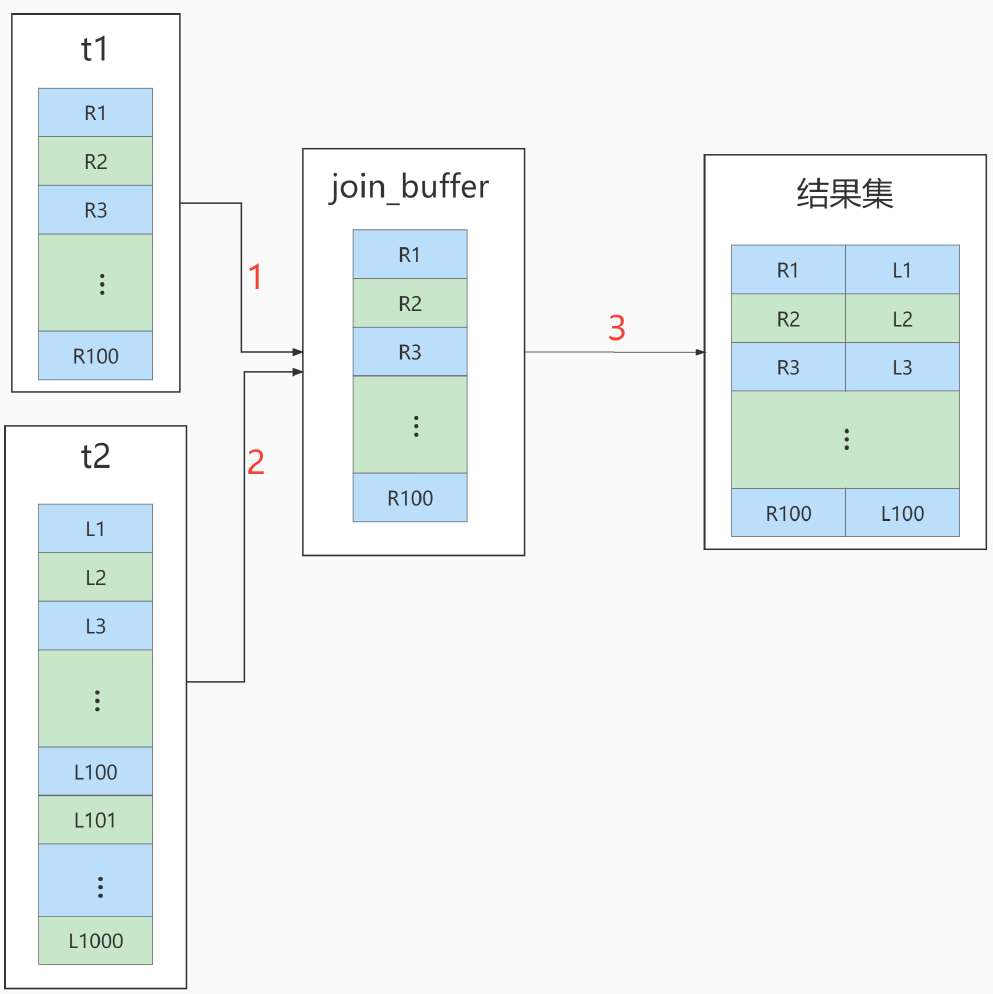
L’organigramme d’exécution ressemble à ceci :
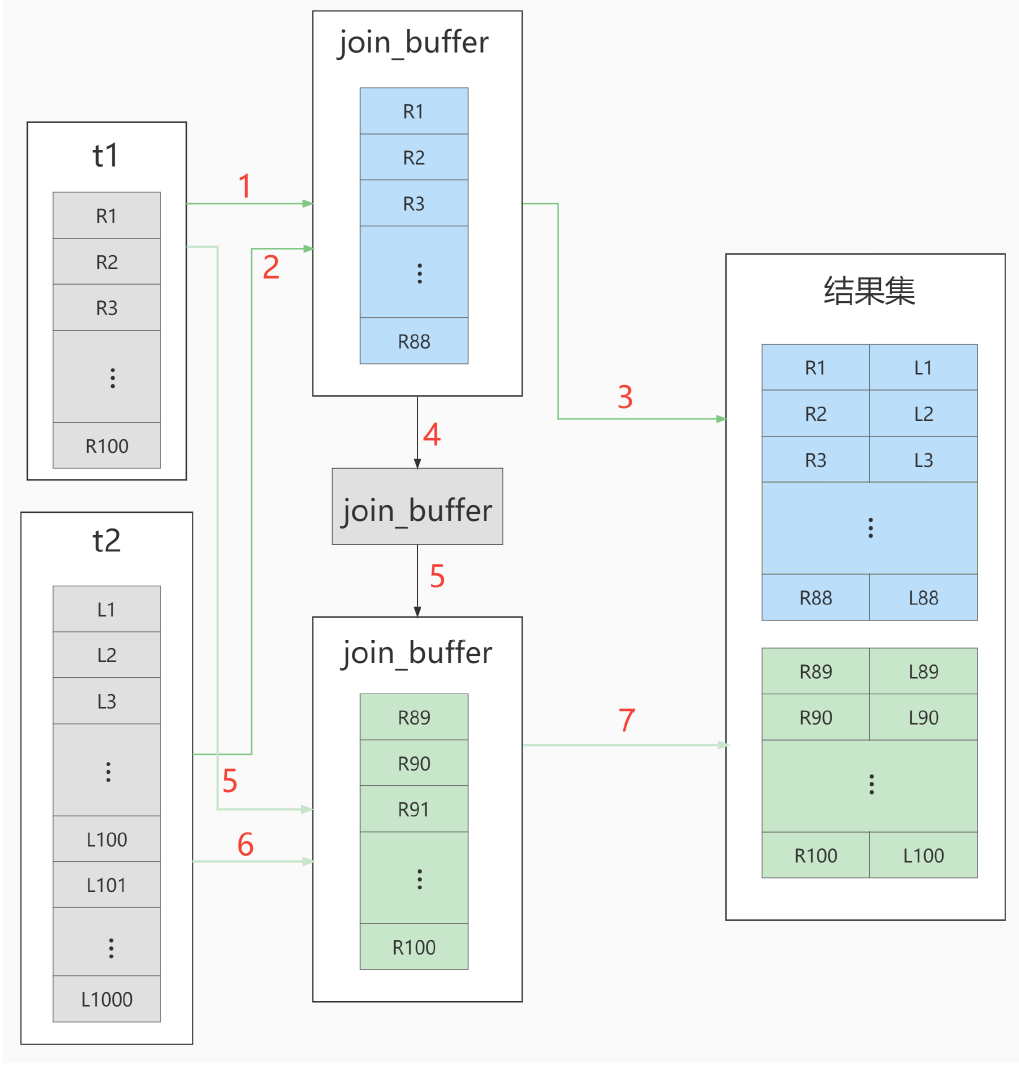
Au moment de décider quelle table doit être utilisée comme table de pilotage, les deux tables doivent être filtrées en fonction de leurs conditions respectives. Une fois le filtrage terminé, le volume total de données de chaque champ participant à la jointure est calculé. La table avec les données les plus petites le volume est la "petite table" comme table de pilotage.
Résumer
- Assurez-vous que le champ JOIN de la table pilotée a un index créé
- Pour les champs qui nécessitent JOIN, les types de données doivent rester absolument cohérents.
- Lorsque LEFT JOIN, sélectionnez la petite table comme table de conduite
大表作为被驱动表. Réduisez le nombre de boucles externes. - INNER JOIN, MySQL le fera automatiquement
小结果集的表选为驱动表. Choisissez de faire confiance aux stratégies d'optimisation MySQL. - Si vous pouvez associer directement plusieurs tables, essayez de les associer directement sans utiliser de sous-requêtes. (Réduire le nombre de requêtes)
- Il n'est pas recommandé d'utiliser des sous-requêtes. Il est recommandé de diviser la sous-requête SQL et de combiner le programme avec plusieurs requêtes, ou d'utiliser JOIN au lieu de sous-requêtes.
- La table dérivée ne peut pas créer d'index.
4. Optimisation des sous-requêtes
MySQL prend en charge les sous-requêtes à partir de la version 4.1. Vous pouvez utiliser des sous-requêtes pour effectuer des requêtes imbriquées d'instructions SELECT, c'est-à-dire que les résultats d'une requête SELECT servent de conditions pour une autre instruction SELECT. Les sous-requêtes peuvent effectuer de nombreuses opérations SQL qui nécessitent logiquement plusieurs étapes en une seule fois .
La sous-requête est une fonction importante de MySQL, qui peut nous aider à implémenter des requêtes plus complexes via une instruction SQL. Cependant, l'efficacité d'exécution des sous-requêtes n'est pas élevée
① Lors de l'exécution d'une sous-requête, MySQL doit créer une table temporaire pour les résultats de la requête de l'instruction de requête interne, puis l'instruction de requête externe interroge les enregistrements de la table temporaire. Une fois la requête terminée, ces tables temporaires sont révoquées. Cela consommera trop de ressources CPU et IO et générera un grand nombre de requêtes lentes.
② La table temporaire stockée dans le jeu de résultats de la sous-requête n'aura pas d'index, qu'il s'agisse d'une table temporaire en mémoire ou d'une table temporaire sur disque, les performances des requêtes seront donc affectées dans une certaine mesure.
③ Pour les sous-requêtes qui renvoient un ensemble de résultats plus important, l'impact sur les performances des requêtes sera plus important. Dans MySQL, vous pouvez utiliser des requêtes de jointure (JOIN) au lieu de sous-requêtes. Les requêtes de jointure n'ont pas besoin de créer de tables temporaires et sont plus rapides que les sous-requêtes. Si des index sont utilisés dans la requête, les performances seront meilleures.
Conclusion : essayez de ne pas utiliser NOT IN ou NOT EXISTS, utilisez plutôt LEFT JOIN xxx ON xx WHERE xx IS NULL.