1. Présentation de NoSQL
1. Pourquoi utiliser NoSQL ?
1. Le bon vieux temps de MySQL autonome
Dans les années 1990, le nombre de visites sur un site Web n’était généralement pas important, et une seule base de données pouvait facilement le gérer !
À cette époque, la plupart d’entre eux étaient des pages Web statiques et il n’existait pas beaucoup de sites Web interactifs dynamiques.
Dans le cadre de l’architecture ci-dessus, examinons quels sont les goulots d’étranglement du stockage de données ?
- La taille totale des données, lorsqu'elles ne peuvent pas tenir sur une seule machine
- L'index des données (B+ Tree) ne peut pas être stocké dans la mémoire d'une machine
- Le volume d'accès (lecture et écriture mixtes) ne peut être toléré par une seule instance
Si 1 ou 3 des conditions ci-dessus sont remplies, évoluez...
DAL : Database Access Layer

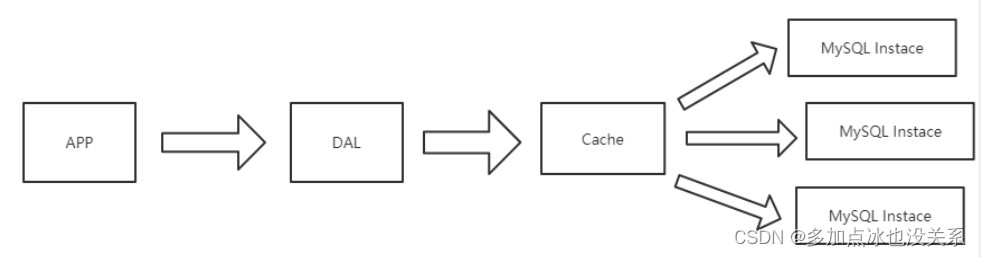
2. Memcached (cache) + MySQL + division verticale
Plus tard, à mesure que le nombre de visites augmentait, presque la plupart des sites Web utilisant l'architecture MySQL ont commencé à avoir des problèmes de performances au niveau de la base de données. Les programmes Web ne se concentraient plus uniquement sur les fonctions, mais recherchaient également les performances. Les programmeurs ont commencé à utiliser largement la technologie de mise en cache pour alléger la pression sur la base de données et optimiser la structure et l'index de la base de données. Il est devenu plus courant d'utiliser la mise en cache de fichiers pour alléger la pression sur la base de données. Cependant, lorsque le nombre de visites a continué d'augmenter , plusieurs machines Web ont commencé à utiliser la mise en cache de fichiers pour réduire la pression sur la base de données. Le cache ne peut pas être partagé et un grand nombre de petits caches de fichiers entraînent également une pression d'E/S relativement élevée. À cette époque, Memcached est naturellement devenu une technologie très à la mode produit.
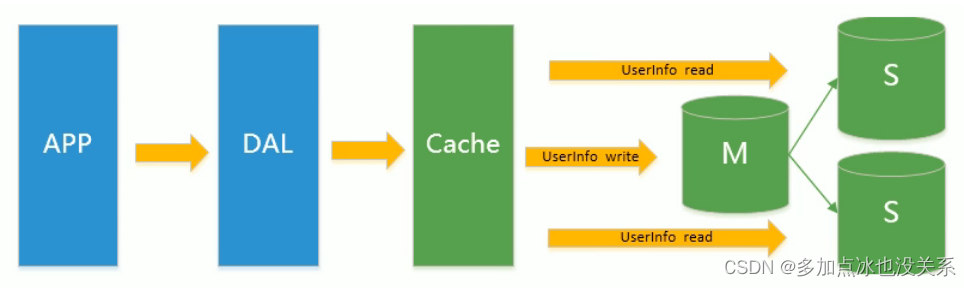
3. Séparation de lecture et d'écriture maître-esclave MySQL
À mesure que la pression d'écriture sur la base de données augmente, Memcached ne peut que soulager la pression de lecture sur la base de données. La concentration de la lecture et de l'écriture sur une seule base de données rend la base de données submergée. La plupart des sites Web ont commencé à utiliser la technologie de réplication maître-esclave pour séparer la lecture et l'écriture. pour améliorer les performances de lecture et d'écriture.Et l'évolutivité de la base de données de lecture, le mode maître-esclave de MySQL est devenu la norme pour les sites Web à l'heure actuelle.
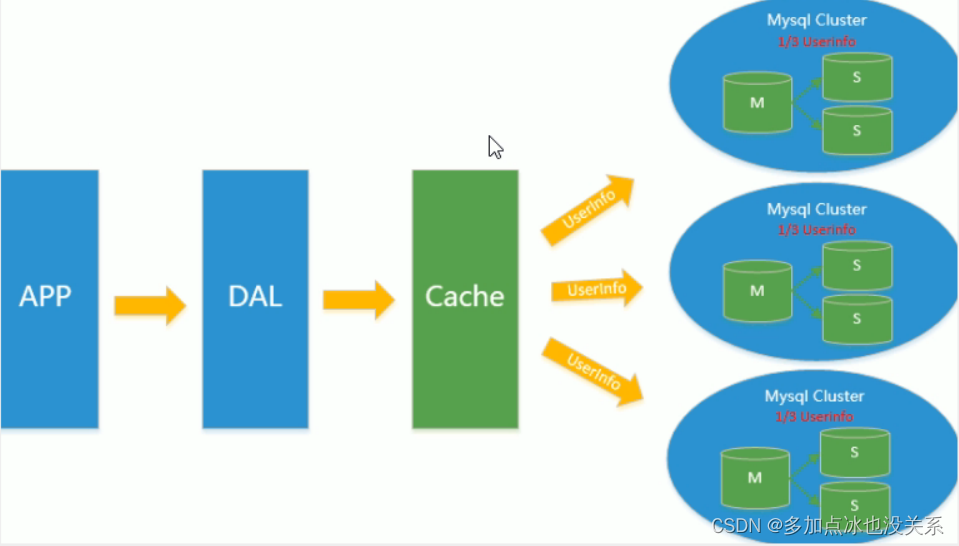
4. Sous-table et sous-base de données + division horizontale + cluster Mysql
Sur la base du cache de Memcached, de la réplication maître-esclave de MySQL et de la séparation lecture-écriture, la pression d'écriture de la base de données principale de MySQL a commencé à apparaître comme des goulots d'étranglement et la quantité de données a continué d'augmenter. Puisque MyISAM utilise des verrous de table, sous haute concurrence Verrouillage sérieux des problèmes surviendront et un grand nombre d'applications MySQL à haute concurrence commenceront à utiliser le moteur InnoDB au lieu de MyISAM.
Dans le même temps, il est devenu courant d'utiliser des sous-tableaux et des sous-bases de données pour atténuer la pression d'écriture et les problèmes d'expansion liés à la croissance des données. À cette époque, les sous-tableaux et les sous-bases de données sont devenus une technologie populaire, une question d'entrevue populaire et une question technique brûlante discutée dans l’industrie. C’est à cette époque que MySQL lance des partitions de tables pas encore stables, ce qui redonne également de l’espoir aux entreprises de force technique moyenne. Bien que MySQL ait lancé le cluster MySQL Cluster, ses performances ne peuvent pas très bien répondre aux besoins d'Internet, mais elles n'offrent qu'une très grande garantie en termes de haute fiabilité.
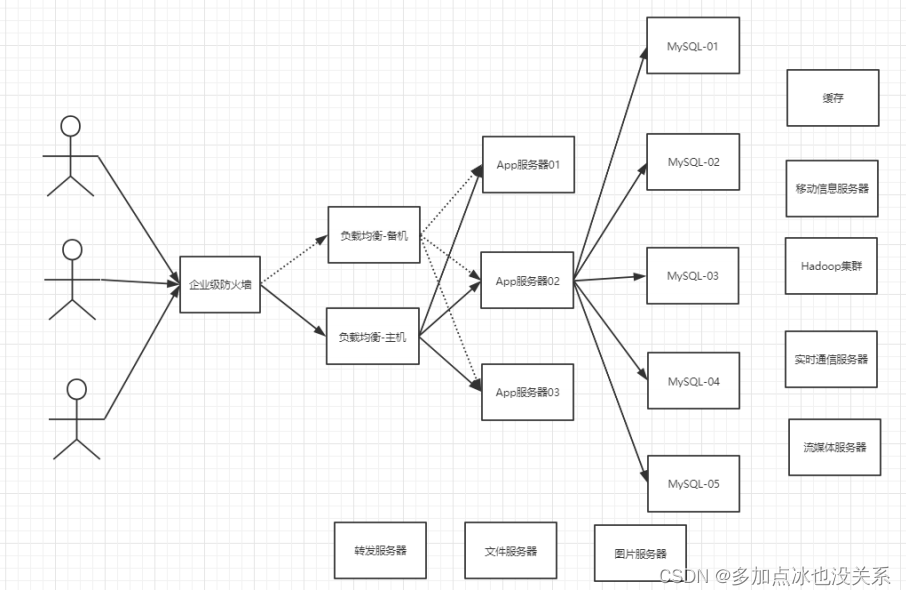
5. Goulot d'étranglement lié à l'évolutivité de MySQL
La base de données MySQL stocke également souvent des champs de texte volumineux, ce qui entraîne des tables de base de données très volumineuses, ce qui rend la récupération de la base de données très lente et difficile à restaurer rapidement. Par exemple, 10 millions de texte de 4 Ko correspondent à une taille proche de 40 Go. Si vous pouvez les éliminer données de MySQL, MySQL deviendra très petit. La base de données relationnelle est très puissante, mais elle ne peut pas bien gérer tous les scénarios d'application. MySQL a une faible évolutivité (nécessite une technologie complexe à mettre en œuvre) et le Big Data Pression d'E/S élevée et difficulté à changer le La structure des tables sont les problèmes rencontrés par les développeurs utilisant actuellement MySQL.
6. Comment est-ce aujourd’hui ? ?
7. Pourquoi utiliser NoSQL ?
Aujourd'hui, nous pouvons facilement accéder et capturer des données via des plateformes tierces (telles que Google, FaceBook, etc.). Les informations personnelles des utilisateurs, les réseaux sociaux, les localisations géographiques, les données générées par les utilisateurs et les journaux d'opérations des utilisateurs ont augmenté de façon exponentielle. Si l'on veut exploiter ces données utilisateur, les bases de données SQL ne sont plus adaptées à ces applications, et le développement de bases de données NoSQL Mais il peut très bien gérer ces données volumineuses !
2. Qu'est-ce que NoSQL ?
NoSQL
NoSQL = Not Only SQL, ce qui signifie : pas seulement SQL ;
Fait généralement référence aux bases de données non relationnelles. Avec l'essor des sites Web Internet Web2.0, les bases de données relationnelles traditionnelles sont devenues de plus en plus incapables de gérer les sites Web Web2.0, en particulier les sites Web purement dynamiques de type Web2.0 de services de réseaux sociaux ultra-larges et hautement concurrents. . Des capacités inadéquates ont exposé de nombreux problèmes insurmontables. Les bases de données non relationnelles se sont développées très rapidement en raison de leurs propres caractéristiques. Les bases de données NoSQL ont été créées pour résoudre les défis posés par les collectes de données à grande échelle et les multiples types de données, en particulier. Il s'agit d'une application Big Data. problème, notamment le stockage de données à très grande échelle.
(Google ou Facebook, par exemple, collectent chaque jour des milliards de données sur leurs utilisateurs). Ces types de magasins de données ne nécessitent pas de schéma fixe et peuvent évoluer sans opérations redondantes.
Caractéristiques de NoSQL
1. Facile à étendre
Il existe de nombreux types de bases de données NoSQL, mais une caractéristique commune est qu'elles suppriment les caractéristiques relationnelles des bases de données relationnelles.
Il n’y a aucune relation entre les données, elles sont donc très faciles à étendre et apportent également une évolutivité au niveau architectural.
2. Hautes performances pour les gros volumes de données
Les bases de données NoSQL ont des performances de lecture et d'écriture très élevées, en particulier lorsqu'elles traitent de grandes quantités de données. Cela est dû à sa nature non relationnelle et à la structure simple de la base de données.
Généralement, MySQL utilise le cache de requêtes, et le cache devient invalide à chaque fois que la table est mise à jour. C'est un cache très puissant. Dans les applications interactives fréquentes du Web2.0, les performances du cache ne sont pas élevées, tandis que le cache NoSQL est enregistrable. niveau, qui est une sorte de cache à granularité fine, donc NoSQL a des performances beaucoup plus élevées à ce niveau.
Record officiel : Redis peut écrire 80 000 fois et lire 110 000 fois par seconde !
3. Modèles de données diversifiés et flexibles
NoSQL n'a pas besoin de créer des champs pour les données à stocker à l'avance et peut stocker des formats de données personnalisés à tout moment. Dans les bases de données relationnelles, l'ajout et la suppression de champs sont une question très gênante. S’il s’agit d’une table contenant une très grande quantité de données, ajouter des champs est tout simplement un cauchemar.
4. SGBDR traditionnel VS NoSQL
传统的关系型数据库 RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性 和 可伸缩性
Expansion : 3V+3 haut
3V à l’ère du big data : principalement la description du problème
- Volume massif
- Variété
- Vitesse en temps réel
Top 3 des exigences Internet : principalement les exigences pour les programmes
- Haute concurrence
- La haute disponibilité
- haute performance
Les applications d'aujourd'hui utilisent SQL et NoSQL ensemble. Il n'y a pas de différence technologique, cela dépend simplement de la façon dont vous l'utilisez, n'est-ce pas ?
3. Analyse d'application classique
Parlons de la façon de stocker les informations sur les produits sur le site Web chinois d’Alibaba, en prenant comme exemple les vêtements et les sacs pour femmes :
Parlons de l'histoire du développement de l'architecture : Livre recommandé « Dix ans de technologie Taobao »
1. Processus d'évolution : Source des images suivantes : Pratique de conception d'architecture de site Web chinois d'Alibaba

2. Cinquième génération

3. Mission de l'architecture de 5ème génération

En rapport avec nous, problèmes de stockage de plusieurs sources de données et de plusieurs types de données
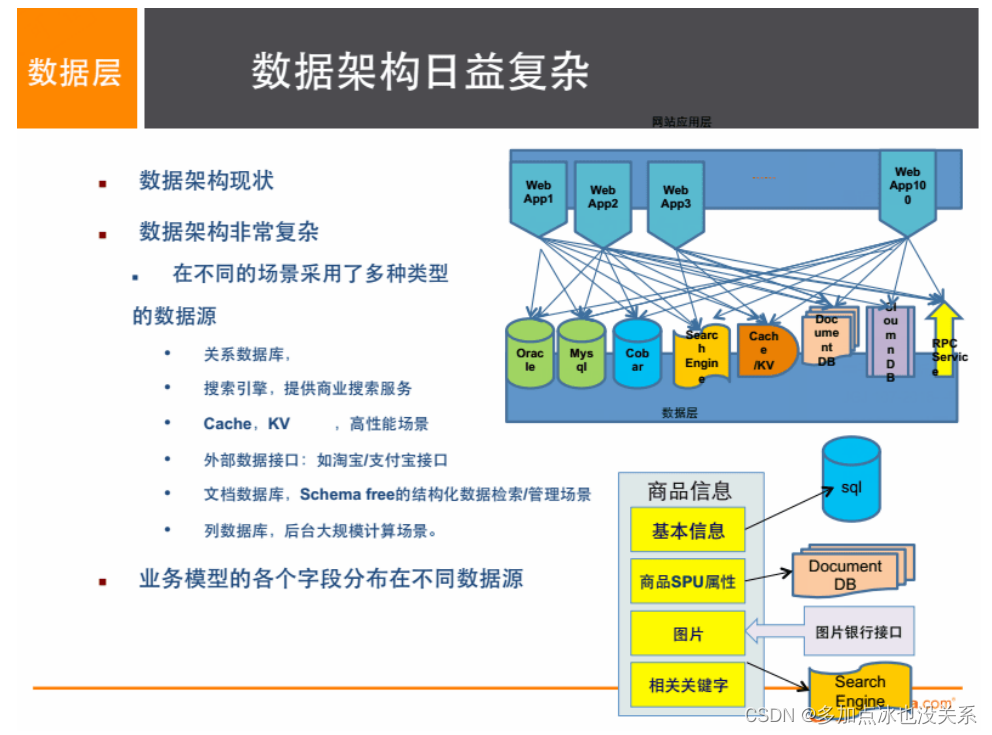
1. Informations de base du produit
名称、价格、出厂日期、生产厂商等
关系型数据库:mysql、oracle目前淘宝在去O化(也即,拿掉Oracle)
注意,淘宝内部用的MySQL是里面的大牛自己改造过的。
为什么去IOE:
2008年,王坚博士加入阿里巴巴,成为首席架构师。把云计算植入阿里IT基因。
2013年5月17日,阿里集团最后一台IBM小机在支付宝下线。这是自2009年“去IOE”战略透露以来,“去
IOE”非常重要的一个节点。“去 IOE”指的是摆脱掉IT部署中原有的IBM小型机、Oracle数据库以及EMC
存储的过度依赖。告别最后一台小机,意味着整个阿里集团尽管还有一些Oracle数据库和EMC存储,但是
IBM小型机已全部被替换。2013年7月10日,淘宝重中之重的广告系统使用的Oracle数据库下线,也是整
个淘宝最后一个 Oracle数据库。这两件事合在一起是阿里巴巴技术发展过程中的一个重要里程碑。
2. Description du produit, détails et informations d'évaluation (multitexte)
多文字信息描述类,IO读写性能变差
存在文档数据库MongDB中
3. Photos du produit
商品图片展现类
分布式文件系统中
- 淘宝自己的 TFS
- Google的 GFS
- Hadoop的 HDFS
4. Mots-clés du produit
搜索引擎,淘宝内用
ISearch:多隆一高兴一个人开发的
所有牛逼的人在牛逼之前,肯定有一段苦逼的岁月,但只要像傻逼一样的坚持,一定终将牛逼
5. Hotspot et informations à haute fréquence sur les matières premières
内存数据库
Tair、Redis、Memcache等
6. Transactions sur matières premières, calcul des prix et accumulation de points !
外部系统,外部第三方支付接口
支付宝
Difficultés et solutions pour les applications Internet à grande échelle (big data, haute concurrence, divers types de données)
difficulté:
- Diversité des types de données
- Diversité des sources de données et reconstruction des changements
- Les sources de données sont transformées et la plateforme de services de données ne nécessite pas de reconstruction approfondie.
Solution:

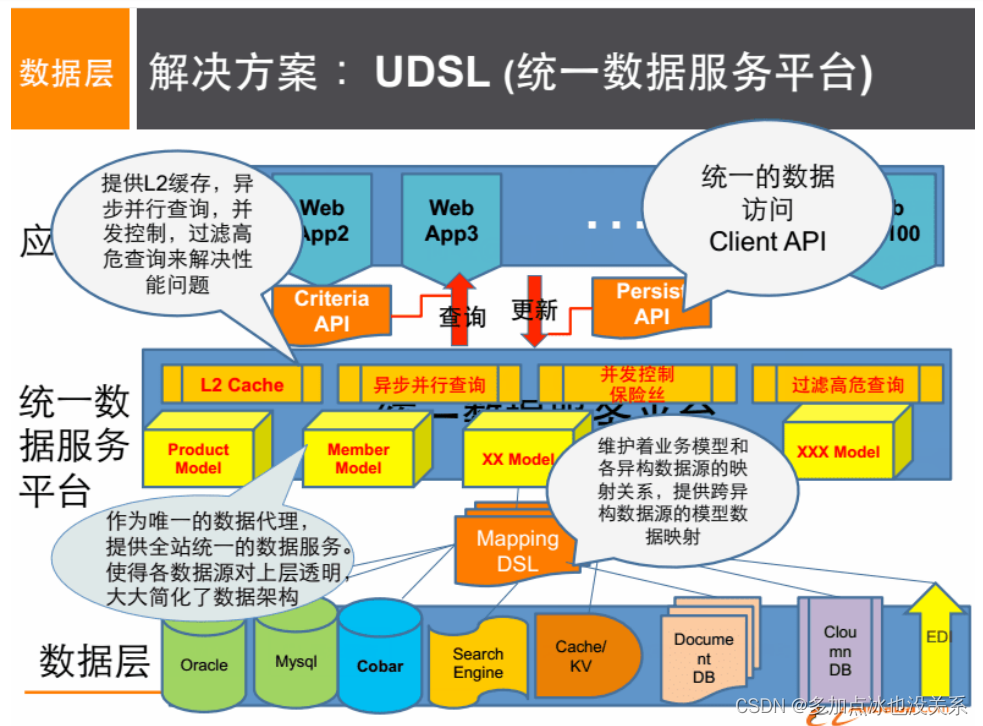


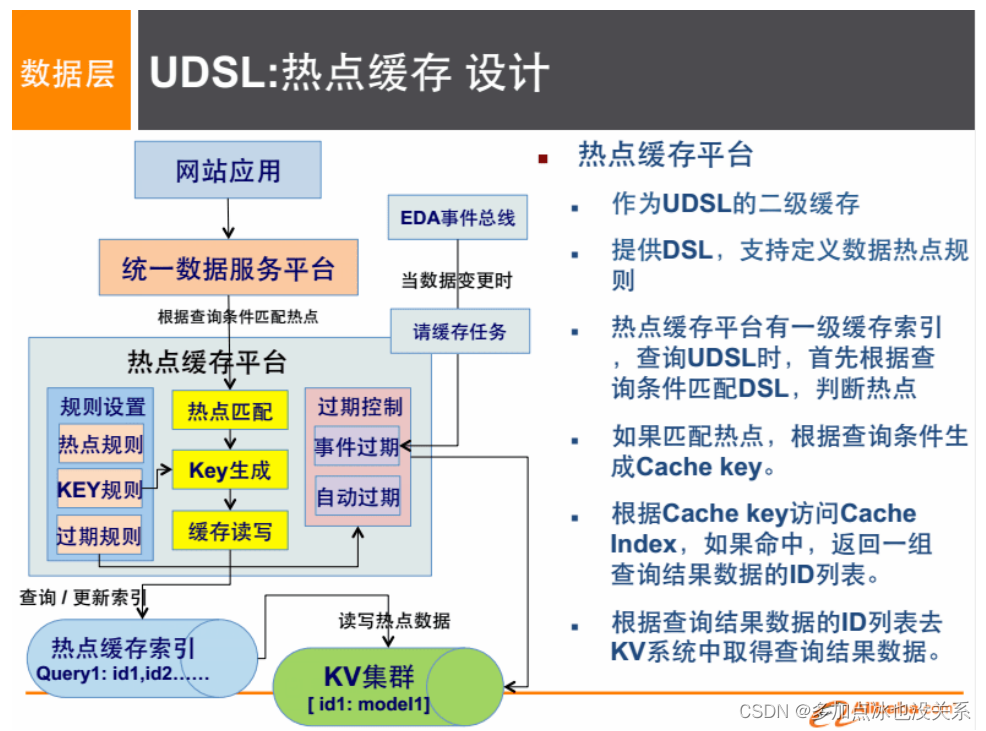
4. Introduction au modèle de données NoSQL
Conception du boîtier
Utiliser un modèle de client, de commande, de commande et d'adresse de commerce électronique pour comparer les bases de données relationnelles et les bases de données non relationnelles
Comment concevoir une base de données relationnelle traditionnelle ?
Diagramme ER (1:1/1:N/N:N, les clés primaires et étrangères, etc. sont communes)
- L'utilisateur correspond à plusieurs commandes et plusieurs adresses
- Chaque commande correspond à chaque produit, prix et adresse
- Produits correspondant à chaque article
Chat : analyse du portrait d'utilisateur, le cœur des femmes est difficile à comprendre. J'ai regardé les vêtements et les rasoirs pour hommes, et sur la base de ses informations, j'ai découvert que l'anniversaire de son petit ami était très récent. Le portrait d'arrière-plan a été analysé et prêt à diffuser des publicités. , mais elle a acheté, j'ai pris une collation et je suis parti~
Les programmeurs nés dans les années 1990 changent vraiment la vie petit à petit. Si vous avez la chance d'entrer dans une grande usine, vous constaterez que les amis autour de vous travaillent dur. Ce sont vraiment le genre de personnes qui peuvent manger là-bas. Haidilao. Les gens qui sortent soudainement leurs cahiers et écrivent du code en mangeant sont considérés comme fous par les autres, mais eux seuls comprennent. C'est l'obsession de la technologie
Comment concevoir NoSQL
Vous pouvez essayer d'utiliser BSON .
BSON est un format de stockage binaire similaire à JSON, appelé Binary JSON. Comme JSON, il prend en charge les objets de document intégrés et les objets de tableau.
Utilisez BSON pour dessiner le modèle de données construit
{
"customer":{
"id":1000,
"name":"Z3",
"billingAddress":[{
"city":"beijing"}],
"orders":[
{
"id":17,
"customerId":1000,
"orderItems":[{
"productId":27,"price":77.5,"productName":"thinking in
java"}],
"shippingAddress":[{
"city":"beijing"}]
"orderPayment":[{
"ccinfo":"111-222-
333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}],
}
]
}
}
Pensez à la base de données de modèles relationnels, comment la vérifiez-vous ? Si nous suivons notre nouveau BSON, il sera très simple à interroger.
- Les requêtes associées ne sont pas recommandées pour les opérations hautement concurrentes. Les sociétés Internet utilisent des données redondantes pour éviter les requêtes associées.
- Les transactions distribuées ne peuvent pas prendre en charge trop de concurrence.
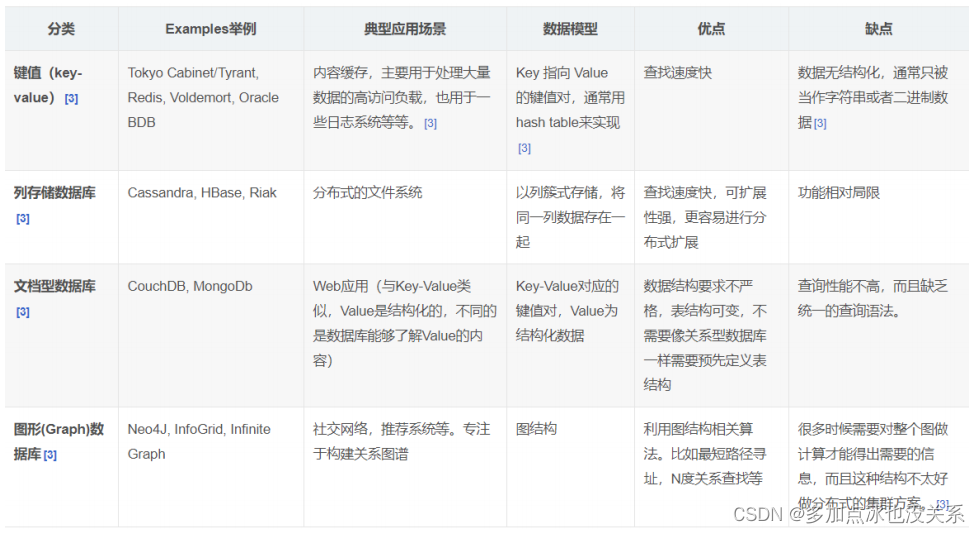
5. Quatre grandes catégories de NoSQL
Valeur clé KV :
- Sina : BerkeleyDB+redis
- Meituan : redis+tair
- Alibaba, Baidu : memcache+redis
Base de documents (plus de format bson) :
- CouchDB
- MongoDB
- MongoDB est une base de données basée sur le stockage de fichiers distribués. Écrit en langage C++. Conçu pour fournir des solutions de stockage de données évolutives et performantes pour les applications WEB.
- MongoDB est un produit entre une base de données relationnelle et une base de données non relationnelle. C'est la base de données non relationnelle la plus riche en fonctionnalités et ressemble le plus à une base de données relationnelle.
Base de données du magasin de colonnes :
- Cassandra, HBase
- Système de fichiers distribué
base de données relationnelle graphique
- Il ne s'agit pas de graphiques, mais de relations, telles que : cercle d'amis, réseau social, système de recommandation publicitaire.
- Réseaux sociaux, systèmes de recommandation, etc. Concentrez-vous sur la création de graphiques relationnels
- Neo4J, InfoGrille
Comparaison des quatre
6、CAP + BASE
Quels sont les ACID traditionnels ?
Les bases de données relationnelles suivent les règles ACID. Les transactions en anglais sont très similaires aux transactions du monde réel. Elles présentent les quatre caractéristiques suivantes :
- A (Atomicité) atomicité
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务
里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:
1)从A账户取100元;
2)存入100元至B账户。
这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100
元。
- C (Cohérence) Cohérence
事务前后数据的完整性必须保持一致。
- I (Isolement) isolement
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修
改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A
账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加
的100元的
- D (Durabilité) Durabilité
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
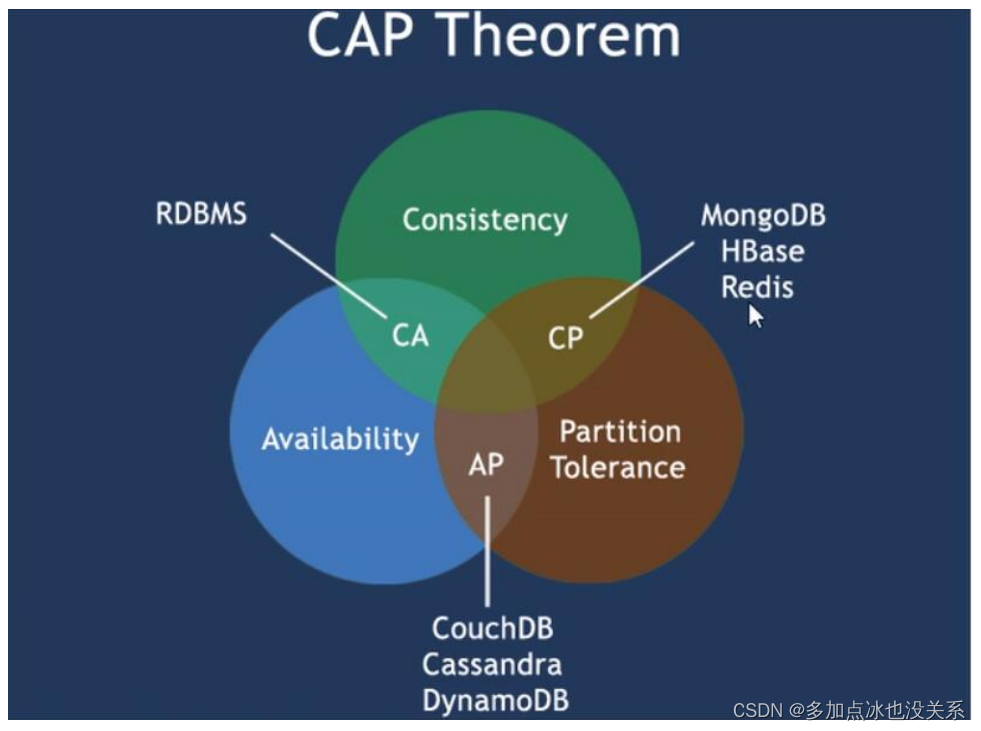
CAP (trois en deux)
- C : Cohérence (forte cohérence)
- R : Disponibilité
- P : tolérance de partition (tolérance aux pannes de partition)
La théorie CAP signifie que dans un système de stockage distribué, au maximum les deux points ci-dessus ne peuvent être atteints.
Étant donné que le matériel réseau actuel aura certainement des problèmes tels qu'une perte de paquets retardée, la tolérance aux pannes de partition est ce que nous devons atteindre .
On ne peut donc faire qu’un compromis entre cohérence et disponibilité : aucun système NoSQL ne peut garantir ces trois points à la fois.
Remarque : des compromis doivent être faits lors de la conception d'une architecture distribuée.
Trouvez un équilibre entre cohérence et disponibilité. La plupart des applications Web ne nécessitent pas réellement une forte cohérence.
Par conséquent, C est sacrifié au profit de P. C’est la direction actuelle des produits de bases de données distribuées.
Le choix entre cohérence et disponibilité
Pour les sites web web2.0, bon nombre des principales fonctionnalités des bases de données relationnelles sont souvent inutiles.
Exigences de cohérence des transactions de base de données
De nombreux systèmes Web en temps réel ne nécessitent pas de transactions de base de données strictes et ont des exigences très faibles en matière de cohérence en lecture. Dans certains cas, les exigences en matière de cohérence en écriture ne sont pas élevées. Permet une cohérence éventuelle.
Exigences d'écriture et de lecture en temps réel de la base de données
Pour les bases de données relationnelles, si vous interrogez une donnée immédiatement après l'avoir insérée, vous pouvez certainement lire les données. Cependant, pour de nombreuses applications Web, des performances en temps réel aussi élevées ne sont pas requises. Par exemple, après l'envoi d'un message, après un quelques secondes, il est tout à fait acceptable que mes abonnés voient cette mise à jour seulement dix secondes plus tard.
Demande de requêtes SQL complexes, en particulier les requêtes liées à plusieurs tables
Tout système Web contenant une grande quantité de données est très tabou en ce qui concerne les requêtes de corrélation de plusieurs grandes tables, ainsi que les requêtes de rapports complexes de type analyse de données, en particulier les sites Web de type SNS. Cette situation peut être évitée du point de vue des exigences et de la conception du produit. . Souvent, il n'y a que des requêtes de clé primaire d'une seule table et de simples requêtes de pagination conditionnelles d'une seule table. La fonction de SQL est considérablement affaiblie.
Le cœur de la théorie CAP est le suivant : un système distribué ne peut pas satisfaire simultanément aux trois exigences de cohérence, de disponibilité et de tolérance aux pannes de partition, il ne peut en satisfaire que deux à la fois. Ainsi, selon le principe CAP, les bases de données NoSQL sont divisées en trois catégories : satisfaisant le principe CA, satisfaisant le principe CP et satisfaisant le principe AP :
- CA - Cluster monopoint, système qui allie cohérence et disponibilité, généralement peu puissant en évolutivité.
- CP - Un système qui satisfait à la cohérence et doit tolérer les partitions, mais qui ne fonctionne généralement pas particulièrement bien.
- AP - Un système qui répond à la disponibilité, à la tolérance de partition et peut généralement avoir des exigences de cohérence inférieures.
Théorie BASE
La théorie BASE a été proposée par les architectes d'eBay. BASE est le résultat d'un compromis entre cohérence et disponibilité dans le CAP, il est issu de la synthèse de la pratique des systèmes distribués Internet à grande échelle et évolue progressivement sur la base de la loi CAP. L'idée centrale est que même si une forte cohérence ne peut être obtenue, chaque application peut adopter des méthodes appropriées en fonction de ses propres caractéristiques commerciales pour que le système atteigne la cohérence finale.
BASE est une solution proposée pour résoudre les problèmes causés par la forte cohérence des bases de données relationnelles et la disponibilité réduite.
BASE est en fait l'abréviation des trois termes suivants :
- Fondamentalement disponible : fondamentalement disponible signifie que le système distribué est autorisé à perdre une partie de sa disponibilité en cas de panne, c'est-à-dire que la disponibilité du cœur est garantie. Lors des promotions de commerce électronique, afin de faire face à l'augmentation du trafic, certains utilisateurs peuvent être dirigés vers la page de rétrogradation, et la couche de service ne peut fournir que des services de rétrogradation. Cela reflète la perte d’une certaine disponibilité.
- État souple : l'état souple fait référence au fait de permettre au système d'exister dans un état intermédiaire sans affecter la disponibilité globale du système. Dans le stockage distribué, une donnée comporte généralement au moins trois copies. Le délai qui permet la synchronisation des copies entre les différents nœuds est l'incarnation de l'état logiciel. La réplication asynchrone de MySQL Replication en est également une manifestation.
- Cohérence éventuelle : la cohérence finale signifie que toutes les copies de données dans le système peuvent éventuellement atteindre un état cohérent après une certaine période de temps. Une consistance faible est à l’opposé d’une consistance forte. La consistance finale est un cas particulier de consistance faible.
Son idée est d'améliorer l'évolutivité et les performances globales du système en permettant au système d'assouplir ses exigences en matière de cohérence des données à un moment donné. Pourquoi disons-nous cela ? La raison en est que les grands systèmes ne peuvent souvent pas utiliser des transactions distribuées pour compléter ces indicateurs en raison de la répartition géographique et des exigences de performance extrêmement élevées. Pour obtenir ces indicateurs, nous devons utiliser une autre façon de les compléter. Voici BASE C'est le solution à ce problème !
expliquer:
1. Distribué : Différents modules de services (projets) sont déployés sur plusieurs serveurs. Ils communiquent et appellent via Rpc pour fournir des services externes et collaborer au sein du groupe.
2. Cluster : le même module de service est déployé sur plusieurs serveurs différents et la planification unifiée est effectuée via un logiciel de planification distribué pour fournir
des services et un accès externes.
2. Démarrer avec Redis
1. Vue d'ensemble
Qu'est-ce que Redis
Redis : REmote DIctionary Server (serveur de dictionnaire distant)
Il est entièrement open source et gratuit. Il est écrit en langage C et est conforme au protocole BSD. Il s'agit d'une base de données à mémoire distribuée hautes performances (Clé/Valeur) qui s'exécute en fonction de la mémoire et prend en charge les bases de données NoSQL persistantes. C'est actuellement le base de données NoSQL la plus populaire. One, également connue sous le nom de serveur de structure de données
Redis et d'autres produits de mise en cache clé-valeur présentent les trois caractéristiques suivantes :
- Redis prend en charge la persistance des données, qui peut conserver les données en mémoire sur le disque et peut être rechargée pour être utilisée lors du redémarrage.
- Redis prend non seulement en charge les données de type clé-valeur simples, mais fournit également le stockage de structures de données telles que liste, ensemble, zset et hachage.
- Redis prend en charge la sauvegarde des données, c'est-à-dire la sauvegarde des données en mode maître-esclave.
Que peut faire Redis ?
Stockage mémoire et persistance : Redis prend en charge l'écriture asynchrone de données en mémoire sur le disque dur sans affecter la continuité du service.
L'opération de prise des N dernières données, par exemple : vous pouvez mettre les ID des 10 derniers commentaires dans la collection Redis List
Système de messages de publication et d'abonnement
Analyse des informations cartographiques
minuterie, compteur
…
caractéristique
Types de données, opérations de base et configuration
Persistance et réplication, RDB, AOF
contrôle des transactions
…
Sites Web fréquemment utilisés
https://redis.io/ site officiel
http://www.redis.cn Site chinois
2. Installation de Windows
Adresse de téléchargement : https://github.com/dmajkic/redis/downloads (matériel fourni)
Décompressez-le dans le répertoire d'environnement de votre ordinateur
Double-cliquez sur redis-server.exe pour démarrer
Accédez à redis-cli via le client
# 基本的set设值
127.0.0.1:6379> set key kuangshen
OK
# 取出存储的值
127.0.0.1:6379> get key
"kuangshen"
indice important
Étant donné que les entreprises développent Redis, 99 % d'entre elles utilisent et installent la version Linux, et la version Windows n'est presque jamais impliquée. L'explication précédente est uniquement pour l'exhaustivité des connaissances. La version Windows n'est pas au centre. Vous pouvez y jouer vous-même et pratiquez-le en entreprise. Reconnaissez simplement une version : la version Linux
http://www.redis.cn/topics/introduction

3. Installation Linux
Adresse de téléchargement http://download.redis.io/releases/redis-5.0.7.tar.gz
étapes d'installation
- Téléchargez redis-5.0.7.tar.gz et placez-le dans notre répertoire Linux/opt
- Dans le répertoire /opt, décompressez la commande : tar -zxvf redis-5.0.7.tar.gz
- Une fois la décompression terminée, le dossier apparaît : redis-5.0.7
- Entrez dans le répertoire : cd redis-5.0.7
- Exécutez la commande make dans le répertoire redis-5.0.7
运行make命令时故意出现的错误解析:
1、安装gcc (gcc是linux下的一个编译程序,是c程序的编译工具)
能上网: yum install gcc-c++
版本测试: gcc-v
2、二次make
3、Jemalloc/jemalloc.h: 没有那个文件或目录
运行 make distclean 之后再make
4、Redis Test(可以不用执行)
- Si vous continuez à exécuter make install une fois make terminé
- Vérifiez le répertoire d'installation par défaut : usr/local/bin
/usr 这是一个非常重要的目录,类似于windows下的Program Files,存放用户的程序
- Copier le fichier de configuration (sauvegarde)
cd /usr/local/bin
ls -l
# 在redis的解压目录下备份redis.conf
mkdir myredis
cp redis.conf myredis # 拷一个备份,养成良好的习惯,我们就修改这个文件
# 修改配置保证可以后台应用
vim redis.conf
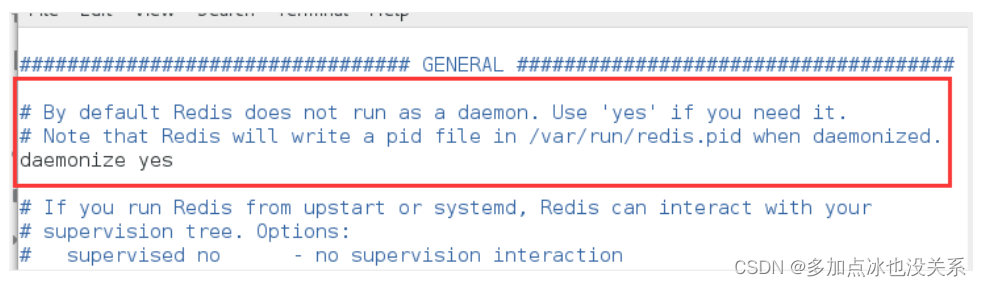
- A. Le thread démon de démonisation dans le fichier de configuration redis.conf est par défaut NON.
- B. daemonize est utilisé pour spécifier si Redis doit être démarré en tant que thread démon.
démoniser fait la différence entre oui ou non
-
démoniser: oui
- Redis utilise un mode multithread à processus unique. Lorsque l'option démoniser dans redis.conf est définie sur oui, cela signifie que le mode processus démon est activé. Dans ce mode, redis s'exécutera en arrière-plan et écrira le numéro pid du processus dans le fichier défini par l'option redis.conf pidfile. À ce stade, redis s'exécutera toujours à moins que le processus ne soit arrêté manuellement.
-
démoniser: non
- Lorsque l'option démoniser est définie sur non,l'interface actuelle entrera dans l'interface de ligne de commande redis.Une sortie forcée en quittant ou en fermant l'outil de connexion (putty, xshell, etc.) entraînera la fermeture du processus redis.
- Commencez le test !
# 【shell】启动redis服务
[root@192 bin]# cd /usr/local/bin
[root@192 bin]# redis-server /opt/redis-5.0.7/redis.conf
# redis客户端连接===> 观察地址的变化,如果连接ok,是直接连上的,redis默认端口号 6379
[root@192 bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set k1 helloworld
OK
127.0.0.1:6379> get k1
"helloworld"
# 【shell】ps显示系统当前进程信息
[root@192 myredis]# ps -ef|grep redis
root 16005 1 0 04:45 ? 00:00:00 redis-server
127.0.0.1:6379
root 16031 15692 0 04:47 pts/0 00:00:00 redis-cli -p 6379
root 16107 16076 0 04:51 pts/2 00:00:00 grep --color=auto redis
# 【redis】关闭连接
127.0.0.1:6379> shutdown
not connected> exit
# 【shell】ps显示系统当前进程信息
[root@192 myredis]# ps -ef|grep redis
root 16140 16076 0 04:53 pts/2 00:00:00 grep --color=auto redis
4. Description des connaissances de base
Préparation : démarrez le service Redis et connectez le client
outil de test de stress Redis -----Redis-benchmark
Redis-benchmark est l'outil officiel de test de performances Redis qui peut tester efficacement les performances des services Redis.
Les paramètres facultatifs de l'outil de test de performances Redis sont les suivants :
| numéro de série | Possibilités | décrire | valeur par défaut |
|---|---|---|---|
| 1 | -h | Spécifier le nom d'hôte du serveur | 127.0.0.1 |
| 2 | -p | Spécifier le port du serveur | 6379 |
| 3 | -s | Spécifier le socket du serveur | |
| 4 | -c | Spécifiez le nombre de connexions simultanées | 50 |
| 5 | -n | Précisez le nombre de demandes | 10000 |
| 6 | -d | Spécifie la taille des données de la valeur SET/GET en octets | 2 |
| 7 | -k | 1 = rester en vie 0 = se reconnecter | 1 |
| 8 | -r | SET/GET/INCR utilise des clés aléatoires, SADD utilise des valeurs aléatoires | |
| 9 | -P | Demandes de canal | 1 |
| dix | -q | Forcer à quitter Redis. Afficher uniquement les valeurs de requête/s | |
| 11 | –csv | Sortie au format CSV | |
| 12 | -l | Générez des boucles qui exécutent des tests pour toujours | |
| 13 | -t | Exécutez uniquement une liste de commandes de test séparées par des virgules. | |
| 14 | -JE | Mode inactif. Ouvrez uniquement N connexions inactives et attendez. |
# 测试一:100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
# 测试出来的所有命令只举例一个!
====== SET ======
100000 requests completed in 1.88 seconds # 对集合写入测试
100 parallel clients # 每次请求有100个并发客户端
3 bytes payload # 每次写入3个字节的数据,有效载荷
keep alive: 1 # 保持一个连接,一台服务器来处理这些请求
17.05% <= 1 milliseconds
97.35% <= 2 milliseconds
99.97% <= 3 milliseconds
100.00% <= 3 milliseconds # 所有请求在 3 毫秒内完成
53248.14 requests per second # 每秒处理 53248.14 次请求
Connaissance de base des bases de données
Il existe 16 bases de données par défaut. Semblable aux indices de tableau commençant à zéro, la valeur par défaut initiale est d'utiliser le numéro de bibliothèque zéro.
查看 redis.conf ,里面有默认的配置
databases 16
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
databases 16
Sélectionner la base de données des commutateurs de commande
127.0.0.1:6379> select 7
OK
127.0.0.1:6379[7]>
# 不同的库可以存不同的数据
Dbsize vérifie le nombre de clés dans la base de données actuelle
127.0.0.1:6379> select 7
OK
127.0.0.1:6379[7]> DBSIZE
(integer) 0
127.0.0.1:6379[7]> select 0
OK
127.0.0.1:6379> DBSIZE
(integer) 5
127.0.0.1:6379> keys * # 查看具体的key
1) "counter:__rand_int__"
2) "mylist"
3) "k1"
4) "myset:__rand_int__"
5) "key:__rand_int__"
Flushdb : effacer la bibliothèque actuelle
Flushall : effacer toutes les bibliothèques
127.0.0.1:6379> DBSIZE
(integer) 5
127.0.0.1:6379> FLUSHDB
OK
127.0.0.1:6379> DBSIZE
(integer) 0
Pourquoi le port par défaut est-il 6379 ? Effet éventail !
Pourquoi Redis est monothread
Il faut d’abord comprendre que Redis est rapide ! Le responsable a déclaré que Redis étant une opération basée sur la mémoire, le processeur n'est pas le goulot d'étranglement de Redis. Le goulot d'étranglement de Redis est probablement la taille de la mémoire de la machine ou la bande passante du réseau. Puisque le mono-threading est facile à mettre en œuvre et que le CPU ne deviendra pas un goulot d'étranglement, il est logique d'adopter la solution mono-thread !
Redis utilise une base de données KV basée sur la mémoire qui utilise un modèle à processus unique et à thread unique. Elle est écrite en langage C. Les données officiellement fournies peuvent atteindre plus de 100 000 QPS (nombre de requêtes par seconde). Ces données ne sont pas pires que Memcached, la même base de données KV basée sur la mémoire qui utilise un processus unique et multithread !
Pourquoi Redis est-il si rapide ?
1) Il y a toujours eu un malentendu dans le passé, penser que les serveurs hautes performances devaient être implémentés avec des multi-threads
La raison est très simple et est provoquée par le malentendu 2 : le multi-threading doit être plus efficace que le mono-threading, mais ce n'est pas le cas !
Avant d’en parler, j’espère que tout le monde comprend la vitesse du processeur, de la mémoire et du disque dur !
2) Le cœur de Redis est que si toutes mes données sont en mémoire, mon opération monothread sera la plus efficace. Pourquoi ? Parce que l'essence du multithreading est que le processeur simule plusieurs threads. Cette situation simulée est Il y a un prix, qui est le changement de contexte. Pour un système de mémoire, c'est le plus efficace sans changement de contexte. Redis utilise un seul processeur pour lier une partie des données de la mémoire, puis lors de la lecture et de l'écriture plusieurs fois dans les données de cette mémoire, tout est effectué sur un seul processeur, il gère donc cette question dans un seul thread. Dans le cas de la mémoire, cette solution est la meilleure.
Parce qu'un changement de contexte CPU prend environ 1 500 ns. La lecture de 1 Mo de données continues à partir de la mémoire prend environ 250 us. Supposons que 1 Mo de données soit lu 1 000 fois par plusieurs threads, puis il y a 1 000 changements de contexte temporel, puis 1 500 ns * 1 000 = 1 500 us. Il ne faut que 250 us pour lire 1 Mo de données dans un seul thread. Il faut 1 500 us juste pour changer le contexte temporel. Je n'inclus pas le temps qu'il vous faut pour lire un peu de données à chaque fois.
3. Cinq principaux types de données
Documentation officielle

Traduction complète :
Redis est un magasin de structures de données en mémoire open source (sous licence BSD) utilisé comme base de données, cache et courtier de messages. Il prend en charge les structures de données telles que les chaînes, les hachages, les listes, les ensembles, les collections triées avec des requêtes de plage, les bitmaps, les hyperlogs, les index géospatiaux avec les requêtes de rayon et les flux. Redis intègre une réplication, des scripts Lua, une expulsion LRU, des transactions et différents niveaux de durabilité du disque, et offre une haute disponibilité grâce au partitionnement automatique de Redis Sentinel et Redis Cluster.
Chaîne (type de chaîne)
String est le type de Redis le plus basique. Vous pouvez le comprendre comme le même type que Memcached. Une clé correspond à une valeur.
Le type String est binaire sûr, ce qui signifie que la chaîne redis peut contenir n'importe quelle donnée, telle que des images jpg ou des objets sérialisés.
Le type String est le type de données le plus basique de Redis. La valeur de chaîne dans un Redis peut aller jusqu'à 512 Mo.
Hash (Hash, similaire à Map en Java)
Le hachage Redis est une collection de paires clé-valeur.
Le hachage Redis est une table de mappage de champs et de valeurs de type String. Le hachage est particulièrement adapté au stockage d'objets.
Semblable à Map<String,Object> en Java
Liste
Les listes Redis sont de simples listes de chaînes, triées par ordre d'insertion. Vous pouvez ajouter un élément en tête (à gauche) ou en queue (à droite) de la liste.
Sa couche inférieure est en fait une liste chaînée !
Ensemble
Redis's Set est une collection non ordonnée de type String, qui est implémentée via HashTable !
Zset (ensemble trié : ensemble ordonné)
Redis zset, comme set, est également une collection d'éléments de type String et n'autorise pas les membres en double.
La différence est que chaque élément est associé à une partition de type double.
Redis utilise des scores pour trier les membres de l'ensemble de petit à grand. Les membres de zset sont uniques, mais les scores (Score) peuvent être répétés.
1. Clé Redis (clé)
# keys * 查看所有的key
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set name qinjiang
OK
127.0.0.1:6379> keys *
1) "name"
# exists key 的名字,判断某个key是否存在
127.0.0.1:6379> EXISTS name
(integer) 1
127.0.0.1:6379> EXISTS name1
(integer) 0
# move key db ---> 当前库就没有了,被移除了
127.0.0.1:6379> move name 1
(integer) 1
127.0.0.1:6379> keys *
(empty list or set)
# expire key 秒钟:为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删
除。
# ttl key 查看还有多少秒过期,-1 表示永不过期,-2 表示已过期
127.0.0.1:6379> set name qinjiang
OK
127.0.0.1:6379> EXPIRE name 10
(integer) 1
127.0.0.1:6379> ttl name
(integer) 4
127.0.0.1:6379> ttl name
(integer) 3
127.0.0.1:6379> ttl name
(integer) 2
127.0.0.1:6379> ttl name
(integer) 1
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> keys *
(empty list or set)
# type key 查看你的key是什么类型
127.0.0.1:6379> set name qinjiang
OK
127.0.0.1:6379> get name
"qinjiang"
127.0.0.1:6379> type name
string
2. Chaîne
Valeur unique Valeur unique
Descriptions de commandes courantes :
# ===================================================
# set、get、del、append、strlen
# ===================================================
127.0.0.1:6379> set key1 value1 # 设置值
OK
127.0.0.1:6379> get key1 # 获得key
"value1"
127.0.0.1:6379> del key1 # 删除key
(integer) 1
127.0.0.1:6379> keys * # 查看全部的key
(empty list or set)
127.0.0.1:6379> exists key1 # 确保 key1 不存在
(integer) 0
127.0.0.1:6379> append key1 "hello" # 对不存在的 key 进行 APPEND ,等同于 SET
key1 "hello"
(integer) 5 # 字符长度
127.0.0.1:6379> APPEND key1 "-2333" # 对已存在的字符串进行 APPEND
(integer) 10 # 长度从 5 个字符增加到 10 个字符
127.0.0.1:6379> get key1
"hello-2333"
127.0.0.1:6379> STRLEN key1 # # 获取字符串的长度
(integer) 10
# ===================================================
# incr、decr 一定要是数字才能进行加减,+1 和 -1。
# incrby、decrby 命令将 key 中储存的数字加上指定的增量值。
# ===================================================
127.0.0.1:6379> set views 0 # 设置浏览量为0
OK
127.0.0.1:6379> incr views # 浏览 + 1
(integer) 1
127.0.0.1:6379> incr views # 浏览 + 1
(integer) 2
127.0.0.1:6379> decr views # 浏览 - 1
(integer) 1
127.0.0.1:6379> incrby views 10 # +10
(integer) 11
127.0.0.1:6379> decrby views 10 # -10
(integer) 1
# ===================================================
# range [范围]
# getrange 获取指定区间范围内的值,类似between...and的关系,从零到负一表示全部
# ===================================================
127.0.0.1:6379> set key2 abcd123456 # 设置key2的值
OK
127.0.0.1:6379> getrange key2 0 -1 # 获得全部的值
"abcd123456"
127.0.0.1:6379> getrange key2 0 2 # 截取部分字符串
"abc"
# ===================================================
# setrange 设置指定区间范围内的值,格式是setrange key值 具体值
# ===================================================
127.0.0.1:6379> get key2
"abcd123456"
127.0.0.1:6379> SETRANGE key2 1 xx # 替换值
(integer) 10
127.0.0.1:6379> get key2
"axxd123456"
# ===================================================
# setex(set with expire)键秒值
# setnx(set if not exist)
# ===================================================
127.0.0.1:6379> setex key3 60 expire # 设置过期时间
OK
127.0.0.1:6379> ttl key3 # 查看剩余的时间
(integer) 55
127.0.0.1:6379> setnx mykey "redis" # 如果不存在就设置,成功返回1
(integer) 1
127.0.0.1:6379> setnx mykey "mongodb" # 如果存在就设置,失败返回0
(integer) 0
127.0.0.1:6379> get mykey
"redis"
# ===================================================
# mset Mset 命令用于同时设置一个或多个 key-value 对。
# mget Mget 命令返回所有(一个或多个)给定 key 的值。
# 如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。
# msetnx 当所有 key 都成功设置,返回 1 。
# 如果所有给定 key 都设置失败(至少有一个 key 已经存在),那么返回 0 。原子操
作
# ===================================================
127.0.0.1:6379> mset k10 v10 k11 v11 k12 v12
OK
127.0.0.1:6379> keys *
1) "k12"
2) "k11"
3) "k10"
127.0.0.1:6379> mget k10 k11 k12 k13
1) "v10"
2) "v11"
3) "v12"
4) (nil)
127.0.0.1:6379> msetnx k10 v10 k15 v15 # 原子性操作!
(integer) 0
127.0.0.1:6379> get key15
(nil)
# 传统对象缓存
set user:1 value(json数据)
# 可以用来缓存对象
mset user:1:name zhangsan user:1:age 2
mget user:1:name user:1:age
# ===================================================
# getset(先get再set)
# ===================================================
127.0.0.1:6379> getset db mongodb # 没有旧值,返回 nil
(nil)
127.0.0.1:6379> get db
"mongodb"
127.0.0.1:6379> getset db redis # 返回旧值 mongodb
"mongodb"
127.0.0.1:6379> get db
"redis"
La structure de données String est un simple type clé-valeur. En fait, la valeur peut être non seulement une chaîne, mais également un nombre.
Application générale de mise en cache clé-valeur :
Comptages conventionnels : nombre de publications sur Weibo, nombre de fans, etc.
3. Liste Liste
Valeur unique Valeur multiple
# ===================================================
# Lpush:将一个或多个值插入到列表头部。(左)
# rpush:将一个或多个值插入到列表尾部。(右)
# lrange:返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。
# 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。
# 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
# ===================================================
127.0.0.1:6379> LPUSH list "one"
(integer) 1
127.0.0.1:6379> LPUSH list "two"
(integer) 2
127.0.0.1:6379> RPUSH list "right"
(integer) 3
127.0.0.1:6379> Lrange list 0 -1
1) "two"
2) "one"
3) "right"
127.0.0.1:6379> Lrange list 0 1
1) "two"
2) "one"
# ===================================================
# lpop 命令用于移除并返回列表的第一个元素。当列表 key 不存在时,返回 nil 。
# rpop 移除列表的最后一个元素,返回值为移除的元素。
# ===================================================
127.0.0.1:6379> Lpop list
"two"
127.0.0.1:6379> Rpop list
"right"
127.0.0.1:6379> Lrange list 0 -1
1) "one"
# ===================================================
# Lindex,按照索引下标获得元素(-1代表最后一个,0代表是第一个)
# ===================================================
127.0.0.1:6379> Lindex list 1
(nil)
127.0.0.1:6379> Lindex list 0
"one"
127.0.0.1:6379> Lindex list -1
"one"
# ===================================================
# llen 用于返回列表的长度。
# ===================================================
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> Lpush list "one"
(integer) 1
127.0.0.1:6379> Lpush list "two"
(integer) 2
127.0.0.1:6379> Lpush list "three"
(integer) 3
127.0.0.1:6379> Llen list # 返回列表的长度
(integer) 3
# ===================================================
# lrem key 根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。
# ===================================================
127.0.0.1:6379> lrem list 1 "two"
(integer) 1
127.0.0.1:6379> Lrange list 0 -1
1) "three"
2) "one"
# ===================================================
# Ltrim key 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
# ===================================================
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 1
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 2
127.0.0.1:6379> RPUSH mylist "hello2"
(integer) 3
127.0.0.1:6379> RPUSH mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "hello2"
# ===================================================
# rpoplpush 移除列表的最后一个元素,并将该元素添加到另一个列表并返回。
# ===================================================
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "foo"
(integer) 2
127.0.0.1:6379> rpush mylist "bar"
(integer) 3
127.0.0.1:6379> rpoplpush mylist myotherlist
"bar"
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "foo"
127.0.0.1:6379> lrange myotherlist 0 -1
1) "bar"
# ===================================================
# lset key index value 将列表 key 下标为 index 的元素的值设置为 value 。
# ===================================================
127.0.0.1:6379> exists list # 对空列表(key 不存在)进行 LSET
(integer) 0
127.0.0.1:6379> lset list 0 item # 报错
(error) ERR no such key
127.0.0.1:6379> lpush list "value1" # 对非空列表进行 LSET
(integer) 1
127.0.0.1:6379> lrange list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 "new" # 更新值
OK
127.0.0.1:6379> lrange list 0 0
1) "new"
127.0.0.1:6379> lset list 1 "new" # index 超出范围报错
(error) ERR index out of range
# ===================================================
# linsert key before/after pivot value 用于在列表的元素前或者后插入元素。
# 将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。
# ===================================================
redis> RPUSH mylist "Hello"
(integer) 1
redis> RPUSH mylist "World"
(integer) 2
redis> LINSERT mylist BEFORE "World" "There"
(integer) 3
redis> LRANGE mylist 0 -1
1) "Hello"
2) "There"
3) "World"
Résumé des performances
- Il s'agit d'une liste chaînée de chaînes, gauche et droite peuvent être insérées et ajoutées
- Si la clé n'existe pas, créez une nouvelle liste chaînée
- Si la clé existe déjà, ajoutez le contenu
- Si toutes les valeurs sont supprimées, les clés correspondantes disparaîtront.
- Le fonctionnement de la liste chaînée est extrêmement efficace tant sur la tête que sur la queue, mais si l’opération est effectuée sur les éléments du milieu, l’efficacité est très lamentable.
Une liste est une liste chaînée, et toute personne ayant une certaine connaissance des structures de données devrait être capable de comprendre sa structure. Grâce à la structure des listes, nous pouvons facilement implémenter des fonctions telles que le classement des dernières actualités. Une autre application de List est la file d'attente de messages. Vous pouvez utiliser l'opération PUSH de List pour stocker des tâches dans la liste, puis le thread de travail utilise l'opération POP pour extraire les tâches à exécuter. Redis fournit également une API pour exploiter un certain segment dans la liste. Vous pouvez directement interroger et supprimer des éléments d'un certain segment dans la liste.
La liste de Redis est une liste doublement chaînée dans laquelle chaque sous-élément est de type String. Des éléments peuvent être ajoutés ou supprimés de la tête ou de la queue de la liste via des opérations push et pop, de sorte que la liste puisse être utilisée comme une pile ou un file d'attente.
4. Définir
valeur unique valeur multiple
# ===================================================
# sadd 将一个或多个成员元素加入到集合中,不能重复
# smembers 返回集合中的所有的成员。
# sismember 命令判断成员元素是否是集合的成员。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 0
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "hello"
127.0.0.1:6379> SISMEMBER myset "hello"
(integer) 1
127.0.0.1:6379> SISMEMBER myset "world"
(integer) 0
# ===================================================
# scard,获取集合里面的元素个数
# ===================================================
127.0.0.1:6379> scard myset
(integer) 2
# ===================================================
# srem key value 用于移除集合中的一个或多个成员元素
# ===================================================
127.0.0.1:6379> srem myset "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
# ===================================================
# srandmember key 命令用于返回集合中的一个随机元素。
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> SRANDMEMBER myset
"hello"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "world"
2) "kuangshen"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "kuangshen"
2) "hello"
# ===================================================
# spop key 用于移除集合中的指定 key 的一个或多个随机元素
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> spop myset
"world"
127.0.0.1:6379> spop myset
"kuangshen"
127.0.0.1:6379> spop myset
"hello"
# ===================================================
# smove SOURCE DESTINATION MEMBER
# 将指定成员 member 元素从 source 集合移动到 destination 集合。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset2 "set2"
(integer) 1
127.0.0.1:6379> smove myset myset2 "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "world"
2) "hello"
127.0.0.1:6379> SMEMBERS myset2
1) "kuangshen"
2) "set2"
# ===================================================
- 数字集合类
- 差集: sdiff
- 交集: sinter
- 并集: sunion
# ===================================================
127.0.0.1:6379> sadd key1 "a"
(integer) 1
127.0.0.1:6379> sadd key1 "b"
(integer) 1
127.0.0.1:6379> sadd key1 "c"
(integer) 1
127.0.0.1:6379> sadd key2 "c"
(integer) 1
127.0.0.1:6379> sadd key2 "d"
(integer) 1
127.0.0.1:6379> sadd key2 "e"
(integer) 1
127.0.0.1:6379> SDIFF key1 key2 # 差集
1) "a"
2) "b"
127.0.0.1:6379> SINTER key1 key2 # 交集
1) "c"
127.0.0.1:6379> SUNION key1 key2 # 并集
1) "a"
2) "b"
3) "c"
4) "e"
5) "d"
Dans l'application Weibo, tous les abonnés d'un utilisateur peuvent être stockés dans une collection, et tous les fans peuvent être stockés dans une collection. Redis fournit également des opérations telles que l'intersection, l'union et la différence pour les collections, ce qui peut être très pratique pour implémenter des fonctions telles que l'attention conjointe, les préférences communes et les amis du deuxième degré. Pour toutes les opérations de collecte ci-dessus, vous pouvez également utiliser différentes commandes Rendre les résultats au client ou les enregistrer dans une nouvelle collection.
5. Hachage
Le mode kv reste inchangé, mais V est une paire clé-valeur
# ===================================================
# hset、hget 命令用于为哈希表中的字段赋值 。
# hmset、hmget 同时将多个field-value对设置到哈希表中。会覆盖哈希表中已存在的字段。
# hgetall 用于返回哈希表中,所有的字段和值。
# hdel 用于删除哈希表 key 中的一个或多个指定字段
# ===================================================
127.0.0.1:6379> hset myhash field1 "kuangshen"
(integer) 1
127.0.0.1:6379> hget myhash field1
"kuangshen"
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> HGET myhash field1
"Hello"
127.0.0.1:6379> HGET myhash field2
"World"
127.0.0.1:6379> hgetall myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
127.0.0.1:6379> HDEL myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "World"
# ===================================================
# hlen 获取哈希表中字段的数量。
# ===================================================
127.0.0.1:6379> hlen myhash
(integer) 1
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> hlen myhash
(integer) 2
# ===================================================
# hexists 查看哈希表的指定字段是否存在。
# ===================================================
127.0.0.1:6379> hexists myhash field1
(integer) 1
127.0.0.1:6379> hexists myhash field3
(integer) 0
# ===================================================
# hkeys 获取哈希表中的所有域(field)。
# hvals 返回哈希表所有域(field)的值。
# ===================================================
127.0.0.1:6379> HKEYS myhash
1) "field2"
2) "field1"
127.0.0.1:6379> HVALS myhash
1) "World"
2) "Hello"
# ===================================================
# hincrby 为哈希表中的字段值加上指定增量值。
# ===================================================
127.0.0.1:6379> hset myhash field 5
(integer) 1
127.0.0.1:6379> HINCRBY myhash field 1
(integer) 6
127.0.0.1:6379> HINCRBY myhash field -1
(integer) 5
127.0.0.1:6379> HINCRBY myhash field -10
(integer) -5
# ===================================================
# hsetnx 为哈希表中不存在的的字段赋值 。
# ===================================================
127.0.0.1:6379> HSETNX myhash field1 "hello"
(integer) 1 # 设置成功,返回 1 。
127.0.0.1:6379> HSETNX myhash field1 "world"
(integer) 0 # 如果给定字段已经存在,返回 0 。
127.0.0.1:6379> HGET myhash field1
"hello"
Le hachage Redis est une table de mappage de champs et de valeurs de type chaîne. Le hachage est particulièrement adapté au stockage d'objets.
Stockez certaines données modifiées, telles que les informations utilisateur, etc.
6. Ensemble commandé Zset
En fonction de l'ensemble, ajoutez une valeur de score. Précédemment défini, c'était k1 v1 v2 v3, maintenant zset est k1 score1 v1 score2 v2
# ===================================================
# zadd 将一个或多个成员元素及其分数值加入到有序集当中。
# zrange 返回有序集中,指定区间内的成员
# ===================================================
127.0.0.1:6379> zadd myset 1 "one"
(integer) 1
127.0.0.1:6379> zadd myset 2 "two" 3 "three"
(integer) 2
127.0.0.1:6379> ZRANGE myset 0 -1
1) "one"
2) "two"
3) "three"
# ===================================================
# zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)次序排列。
# ===================================================
127.0.0.1:6379> zadd salary 2500 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 5000 xiaohong
(integer) 1
127.0.0.1:6379> zadd salary 500 kuangshen
(integer) 1
# Inf无穷大量+∞,同样地,-∞可以表示为-Inf。
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 显示整个有序集
1) "kuangshen"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # 递增排列
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
5) "xiaohong"
6) "5000"
127.0.0.1:6379> ZREVRANGE salary 0 -1 WITHSCORES # 递减排列
1) "xiaohong"
2) "5000"
3) "xiaoming"
4) "2500"
5) "kuangshen"
6) "500"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 WITHSCORES # 显示工资 <=2500
的所有成员
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
# ===================================================
# zrem 移除有序集中的一个或多个成员
# ===================================================
127.0.0.1:6379> ZRANGE salary 0 -1
1) "kuangshen"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> zrem salary kuangshen
(integer) 1
127.0.0.1:6379> ZRANGE salary 0 -1
1) "xiaoming"
2) "xiaohong"
# ===================================================
# zcard 命令用于计算集合中元素的数量。
# ===================================================
127.0.0.1:6379> zcard salary
(integer) 2
OK
# ===================================================
# zcount 计算有序集合中指定分数区间的成员数量。
# ===================================================
127.0.0.1:6379> zadd myset 1 "hello"
(integer) 1
127.0.0.1:6379> zadd myset 2 "world" 3 "kuangshen"
(integer) 2
127.0.0.1:6379> ZCOUNT myset 1 3
(integer) 3
127.0.0.1:6379> ZCOUNT myset 1 2
(integer) 2
# ===================================================
# zrank 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
# ===================================================
127.0.0.1:6379> zadd salary 2500 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 5000 xiaohong
(integer) 1
127.0.0.1:6379> zadd salary 500 kuangshen
(integer) 1
127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
5) "xiaohong"
6) "5000"
127.0.0.1:6379> zrank salary kuangshen # 显示 kuangshen 的薪水排名,最少
(integer) 0
127.0.0.1:6379> zrank salary xiaohong # 显示 xiaohong 的薪水排名,第三
(integer) 2
# ===================================================
# zrevrank 返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序。
# ===================================================
127.0.0.1:6379> ZREVRANK salary kuangshen # 狂神第三
(integer) 2
127.0.0.1:6379> ZREVRANK salary xiaohong # 小红第一
(integer) 0
Par rapport à l'ensemble, l'ensemble trié ajoute un score de paramètre de poids, de sorte que les éléments de l'ensemble puissent être disposés dans l'ordre en fonction du score. Par exemple, un ensemble trié qui stocke les notes de toute la classe, la valeur définie peut être l'élève. numéro du camarade de classe et score Il peut s'agir de son score au test, de sorte que lorsque les données sont insérées dans la collection, elles seront naturellement triées. Vous pouvez utiliser un ensemble trié pour créer une file d'attente pondérée. Par exemple, le score des messages ordinaires est de 1 et le score des messages importants est de 2. Le thread de travail peut ensuite choisir d'obtenir les tâches de travail dans l'ordre inverse des scores. Priorisez les tâches importantes.
Application de classement, prenez les opérations TOP N !
4. Trois types de données spéciaux
1. Localisation géographique GEO
Introduction
La fonctionnalité GEO de Redis a été lancée dans la version 3.2 de Redis. Cette fonctionnalité peut stocker les informations de localisation géographique fournies par l'utilisateur et exploiter ces informations. Pour mettre en œuvre des fonctions qui s'appuient sur des informations de localisation géographique telles que les emplacements à proximité et les secousses. Le type de données de géo est zset.
La structure de données de GEO comporte un total de six commandes communes :
- géoajouter
- géopos
- géodiste
- rayon géographique
- rayon géographiquepar membre
- gethash
Document officiel : https://www.redis.net.cn/order/3685.html
géoajouter
Analyse:
# 语法
geoadd key longitude latitude member ...
# 将给定的空间元素(纬度、经度、名字)添加到指定的键里面。
# 这些数据会以有序集合的形式被储存在键里面,从而使得georadius和georadiusbymember这样的命令可以在之后通过位置查询取得这些元素。
# geoadd命令以标准的x,y格式接受参数,所以用户必须先输入经度,然后再输入纬度。
# geoadd能够记录的坐标是有限的:非常接近两极的区域无法被索引。
# 有效的经度介于-180-180度之间,有效的纬度介于-85.05112878 度至 85.05112878 度之间。,当用户尝试输入一个超出范围的经度或者纬度时,geoadd命令将返回一个错误。
Test : requête de recherche de longitude et de latitude par Baidu, simulant des données réelles
127.0.0.1:6379> geoadd china:city 116.23 40.22 北京
(integer) 1
127.0.0.1:6379> geoadd china:city 121.48 31.40 上海 113.88 22.55 深圳 120.21
30.20 杭州
(integer) 3
127.0.0.1:6379> geoadd china:city 106.54 29.40 重庆 108.93 34.23 西安 114.02
30.58 武汉
(integer) 3
géopos
Analyse:
# 语法
geopos key member [member...]
#从key里返回所有给定位置元素的位置(经度和纬度)
test:
127.0.0.1:6379> geopos china:city 北京
1) 1) "116.23000055551528931"
2) "40.2200010338739844"
127.0.0.1:6379> geopos china:city 上海 重庆
1) 1) "121.48000091314315796"
2) "31.40000025319353938"
2) 1) "106.54000014066696167"
2) "29.39999880018641676"
127.0.0.1:6379> geopos china:city 新疆
1) (nil)
géodiste
Analyse:
# 语法
geodist key member1 member2 [unit]
# 返回两个给定位置之间的距离,如果两个位置之间的其中一个不存在,那么命令返回空值。
# 指定单位的参数unit必须是以下单位的其中一个:
# m表示单位为米
# km表示单位为千米
# mi表示单位为英里
# ft表示单位为英尺
# 如果用户没有显式地指定单位参数,那么geodist默认使用米作为单位。
#geodist命令在计算距离时会假设地球为完美的球形,在极限情况下,这一假设最大会造成0.5%的误
差。
test:
127.0.0.1:6379> geodist china:city 北京 上海
"1088785.4302"
127.0.0.1:6379> geodist china:city 北京 上海 km
"1088.7854"
127.0.0.1:6379> geodist china:city 重庆 北京 km
"1491.6716"
rayon géographique
Analyse:
# 语法
georadius key longitude latitude radius m|km|ft|mi [withcoord][withdist]
[withhash][asc|desc][count count]
# 以给定的经纬度为中心, 找出某一半径内的元素
Test : reconnectez redis-cli et ajoutez le paramètre --raw pour forcer la sortie chinoise, sinon elle sera tronquée.
[root@kuangshen bin]# redis-cli --raw -p 6379
# 在 china:city 中寻找坐标 100 30 半径为 1000km 的城市
127.0.0.1:6379> georadius china:city 100 30 1000 km
重庆
西安
# withdist 返回位置名称和中心距离
127.0.0.1:6379> georadius china:city 100 30 1000 km withdist
重庆
635.2850
西安
963.3171
# withcoord 返回位置名称和经纬度
127.0.0.1:6379> georadius china:city 100 30 1000 km withcoord
重庆
106.54000014066696167
29.39999880018641676
西安
108.92999857664108276
34.23000121926852302
# withdist withcoord 返回位置名称 距离 和经纬度 count 限定寻找个数
127.0.0.1:6379> georadius china:city 100 30 1000 km withcoord withdist count
1
重庆
635.2850
106.54000014066696167
29.39999880018641676
127.0.0.1:6379> georadius china:city 100 30 1000 km withcoord withdist count
2
重庆
635.2850
106.54000014066696167
29.39999880018641676
西安
963.3171
108.92999857664108276
34.23000121926852302
rayon géographiquepar membre
Analyse:
# 语法
georadiusbymember key member radius m|km|ft|mi [withcoord][withdist]
[withhash][asc|desc][count count]
# 找出位于指定范围内的元素,中心点是由给定的位置元素决定
test:
127.0.0.1:6379> GEORADIUSBYMEMBER china:city 北京 1000 km
北京
西安
127.0.0.1:6379> GEORADIUSBYMEMBER china:city 上海 400 km
杭州
上海
géohash
Analyse:
# 语法
geohash key member [member...]
# Redis使用geohash将二维经纬度转换为一维字符串,字符串越长表示位置更精确,两个字符串越相似
表示距离越近。
test:
127.0.0.1:6379> geohash china:city 北京 重庆
wx4sucu47r0
wm5z22h53v0
127.0.0.1:6379> geohash china:city 北京 上海
wx4sucu47r0
wtw6sk5n300
âge
GEO ne fournit pas de commande pour supprimer des membres, mais comme l'implémentation sous-jacente de GEO est zset, vous pouvez utiliser la commande zrem pour supprimer les informations de localisation géographique.
127.0.0.1:6379> geoadd china:city 116.23 40.22 beijin
1
127.0.0.1:6379> zrange china:city 0 -1 # 查看全部的元素
重庆
西安
深圳
武汉
杭州
上海
beijin
北京
127.0.0.1:6379> zrem china:city beijin # 移除元素
1
127.0.0.1:6379> zrem china:city 北京 # 移除元素
1
127.0.0.1:6379> zrange china:city 0 -1
重庆
西安
深圳
武汉
杭州
上海
2、HyperLogLog
Introduction
Redis a ajouté la structure HyperLogLog dans la version 2.8.9.
Redis HyperLogLog est un algorithme utilisé pour les statistiques de cardinalité. L'avantage de HyperLogLog est que lorsque le nombre ou le volume des éléments d'entrée est très grand, l'espace requis pour calculer la cardinalité est toujours fixe et très petit.
Dans Redis, chaque clé HyperLogLog ne coûte que 12 Ko de mémoire pour calculer la cardinalité de près de 2^64 éléments différents. Cela contraste fortement avec une collection qui consomme plus de mémoire lors du calcul de la cardinalité : plus il y a d'éléments, plus la mémoire est consommée.
HyperLogLog est un algorithme qui fournit une solution de comptage de déduplication inexacte.
Par exemple : Si je souhaite compter l'UV d'une page Web (le nombre d'utilisateurs naviguant, les visites multiples du même utilisateur dans une journée ne peuvent être comptées qu'une seule fois), la solution traditionnelle consiste à utiliser Set pour enregistrer l'ID utilisateur, puis comptez le nombre d'éléments dans le jeu. Obtenez la page UV. Cependant, cette solution ne peut héberger qu'un petit nombre d'utilisateurs. Une fois le nombre d'utilisateurs augmenté, elle consommera beaucoup d'espace pour stocker les identifiants des utilisateurs. Mon but est de compter le nombre d'utilisateurs plutôt que de les sauvegarder. C'est une solution ingrate ! HyperLogLog utilisant Redis nécessite jusqu'à 12 000 utilisateurs pour compter un grand nombre d'utilisateurs. Bien qu'il ait un taux d'erreur d'environ 0,81 %, il est négligeable pour compter des données UV qui ne nécessitent pas de données très précises.
Qu'est-ce que la cardinalité ?
Par exemple, si l'ensemble de données est {1, 3, 5, 7, 5, 7, 8}, alors l'ensemble de cardinalité de cet ensemble de données est {1, 3, 5,7, 8}, et la cardinalité (non -éléments répétitifs) est 5. L'estimation de la cardinalité consiste à calculer rapidement la cardinalité dans la plage d'erreur acceptable.
commandes de base
| Commande | décrire |
|---|---|
| [Élément clé PFADD [élément…] | Ajoute l'élément spécifié à HyperLogLog. |
| [Touche PFCOUNT [clé…] | Renvoie l'estimation de cardinalité pour l'HyperLogLog donné. |
| [PFMERGE destkey sourcekey [sourcekey…] | Fusionnez plusieurs HyperLogLogs en un seul HyperLogLog et calculez l'union |
test
127.0.0.1:6379> PFADD mykey a b c d e f g h i j
1
127.0.0.1:6379> PFCOUNT mykey
10
127.0.0.1:6379> PFADD mykey2 i j z x c v b n m
1
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2
OK
127.0.0.1:6379> PFCOUNT mykey3
15
3、BitMap
Introduction
Au cours du développement, vous pouvez rencontrer cette situation : vous devez compter certaines informations sur l'utilisateur, telles qu'actif ou inactif, connecté ou non ; ou vous devez enregistrer le statut d'enregistrement de l'utilisateur pendant un an. Si vous cochez dans, c'est 1, si vous ne vous êtes pas enregistré, c'est 1. 0. Si un stockage clé/valeur ordinaire est utilisé, 365 enregistrements seront enregistrés. Si le nombre d'utilisateurs est grand, l'espace requis sera également grand, Redis fournit donc la structure de données bitmap Bitmap. Bitmap fonctionne sur des bits binaires. Pour enregistrer, c'est 0 et 1 ; si vous souhaitez enregistrer le statut d'enregistrement pendant 365 jours, la représentation Bitmap est à peu près la suivante : 0101000111000111... Quels en sont les avantages ? Bien sûr, cela économise de la mémoire : 365 jours équivaut à 365 bits, et 1 octet = 8 bits, cela équivaut donc à utiliser 46 octets.
BitMap utilise un bit pour représenter la valeur ou l'état correspondant à un élément. La clé est l'élément correspondant lui-même. En fait, la couche inférieure est également implémentée via le fonctionnement de chaînes. Redis a ajouté plusieurs commandes liées aux bitmaps telles que setbit, getbit, bitcount, etc. depuis la version 2.2.
opération de définition de bits
Valeur de décalage de clé SETBIT : définit le bit de décalage de la clé sur la valeur (1 ou 0)
# 使用 bitmap 来记录上述事例中一周的打卡记录如下所示:
# 周一:1,周二:0,周三:0,周四:1,周五:1,周六:0,周天:0 (1 为打卡,0 为不打卡)
127.0.0.1:6379> setbit sign 0 1
0
127.0.0.1:6379> setbit sign 1 0
0
127.0.0.1:6379> setbit sign 2 0
0
127.0.0.1:6379> setbit sign 3 1
0
127.0.0.1:6379> setbit sign 4 1
0
127.0.0.1:6379> setbit sign 5 0
0
127.0.0.1:6379> setbit sign 6 0
0
getbitObtenir une opération
GETBIT key offset Obtient la valeur définie par offset. Si elle n'est pas définie, elle renvoie 0 par défaut.
127.0.0.1:6379> getbit sign 3 # 查看周四是否打卡
1
127.0.0.1:6379> getbit sign 6 # 查看周七是否打卡
0
opération statistique de comptage de bits
bitcount key [start, end] compte le nombre de clés avec le bit supérieur 1
# 统计这周打卡的记录,可以看到只有3天是打卡的状态:
127.0.0.1:6379> bitcount sign
3
5. Redis.conf
1. Familiarisé avec la configuration de base
Emplacement
Le fichier de configuration Redis se trouve dans le répertoire d'installation Redis et le nom du fichier est redis.conf
config get * # 获取全部的配置
Adresse du fichier de configuration :
Dans des circonstances normales, nous ferons une copie séparée pour l'exploitation. pour assurer la sécurité du fichier initial.
Unités Unités
1. Configurez les unités de taille. Certaines unités de mesure de base sont définies au début. Seuls les octets sont pris en charge, les bits ne sont pas pris en charge.
2. Insensible aux majuscules et aux minuscules
COMPREND contient
Semblable au fichier de configuration Spring, il peut être inclus via include. redis.conf peut être utilisé comme fichier total et peut inclure d'autres fichiers !
Configuration du réseau RÉSEAU
bind 127.0.0.1 # 绑定的ip
protected-mode yes # 保护模式
port 6379 # 默认端口
GÉNÉRAL Général
daemonize yes # 默认情况下,Redis不作为守护进程运行。需要开启的话,改为 yes
supervised no # 可通过upstart和systemd管理Redis守护进程
pidfile /var/run/redis_6379.pid # 以后台进程方式运行redis,则需要指定pid 文件
loglevel notice # 日志级别。可选项有:
# debug(记录大量日志信息,适用于开发、测试阶段);
# verbose(较多日志信息);
# notice(适量日志信息,使用于生产环境);
# warning(仅有部分重要、关键信息才会被记录)。
logfile "" # 日志文件的位置,当指定为空字符串时,为标准输出
databases 16 # 设置数据库的数目。默认的数据库是DB 0
always-show-logo yes # 是否总是显示logo
INSTANTANÉ INSTANTANÉ
# 900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化)
save 900 1
# 300秒(5分钟)内至少10个key值改变(则进行数据库保存--持久化)
save 300 10
# 60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化)
save 60 10000
stop-writes-on-bgsave-error yes # 持久化出现错误后,是否依然进行继续进行工作
rdbcompression yes # 使用压缩rdb文件 yes:压缩,但是需要一些cpu的消耗。no:不压缩,需要更多的磁盘空间
rdbchecksum yes # 是否校验rdb文件,更有利于文件的容错性,但是在保存rdb文件的时候,会有大概10%的性能损耗
dbfilename dump.rdb # dbfilenamerdb文件名称
dir ./ # dir 数据目录,数据库的写入会在这个目录。rdb、aof文件也会写在这个目录
RÉPLICATION Nous parlerons plus tard de la réplication maître-esclave et vous l'expliquerons ! Sautez ici d'abord !
SÉCURITÉSécurité
Afficher, définir et annuler les mots de passe d'accès
# 启动redis
# 连接客户端
# 获得和设置密码
config get requirepass
config set requirepass "123456"
#测试ping,发现需要验证
127.0.0.1:6379> ping
NOAUTH Authentication required.
# 验证
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> ping
PONG
limite
maxclients 10000 # 设置能连上redis的最大客户端连接数量
maxmemory <bytes> # redis配置的最大内存容量
maxmemory-policy noeviction # maxmemory-policy 内存达到上限的处理策略
#volatile-lru:利用LRU算法移除设置过过期时间的key。
#volatile-random:随机移除设置过过期时间的key。
#volatile-ttl:移除即将过期的key,根据最近过期时间来删除(辅以TTL)
#allkeys-lru:利用LRU算法移除任何key。
#allkeys-random:随机移除任何key。
#noeviction:不移除任何key,只是返回一个写错误。
mode ajouter uniquement
appendonly no # 是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这种方式在许多应用中已经足够用了
appendfilename "appendonly.aof" # appendfilename AOF 文件名称
appendfsync everysec # appendfsync aof持久化策略的配置
# no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
# always表示每次写入都执行fsync,以保证数据同步到磁盘。
# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
Nous expliquerons les détails plus tard lorsque nous expliquerons la configuration de persistance de Redis ! Comprenez d’abord, écoutez l’oreille !
2. Introduction aux configurations courantes
1. Redis ne s'exécute pas en tant que processus démon par défaut. Vous pouvez modifier cet élément de configuration et utiliser yes pour activer le processus démon.
démoniser non
2. Lorsque Redis s'exécute en mode démon, Redis écrira le pid par défaut dans le fichier /var/run/redis.pid, qui peut être spécifié via pidfile
fichier pid /var/run/redis.pid
3. Spécifiez le port d'écoute Redis. Le port par défaut est 6379. L'auteur a expliqué dans un de ses articles de blog pourquoi 6379 a été choisi comme port par défaut car 6379 est le numéro correspondant à MERZ sur le bouton du téléphone, et MERZ est extrait du nom de la chanteuse italienne Alessia Merz.
port 6379
4. L'adresse de l'hôte liée
lier 127.0.0.1
5. Lorsque le client est inactif pendant une longue période, la connexion est fermée. S'il est spécifié comme 0, cela signifie que cette fonction est désactivée.
délai d'attente 300
6. Spécifiez le niveau de journalisation. Redis prend en charge un total de quatre niveaux : débogage, détaillé, notification et avertissement. La valeur par défaut est détaillée.
niveau de journalisation verbeux
7. Mode de journalisation, la valeur par défaut est la sortie standard. Si Redis est configuré pour s'exécuter en mode démon et que le mode de journalisation est configuré comme sortie standard, le journal sera envoyé à /dev/null.
fichier journal, sortie standard
8. Définissez le nombre de bases de données. La base de données par défaut est 0. Vous pouvez utiliser la commande SELECT pour spécifier l'ID de la base de données sur la connexion.
bases de données 16
9. Spécifiez la période de temps et le nombre d'opérations de mise à jour pour synchroniser les données avec le fichier de données. Plusieurs conditions peuvent être remplies
Trois conditions sont fournies dans le fichier de configuration par défaut de save Redis :
save 900 1
save 300 10
save 60 10 000
signifie respectivement 1 changement en 900 secondes (15 minutes), 10 changements en 300 secondes (5 minutes) et 60 secondes. Il y a 10 000 changements .
10. Spécifiez s'il faut compresser les données lors de leur stockage dans la base de données locale. La valeur par défaut est oui. Redis utilise la compression LZF. Si vous souhaitez économiser du temps CPU, vous pouvez désactiver cette option, mais le fichier de base de données deviendra énorme.
rdbcompression oui
11. Spécifiez le nom du fichier de base de données locale. La valeur par défaut est dump.rdb.
nom de fichier db dump.rdb
12. Spécifiez le répertoire de stockage de la base de données locale
rép./
13. Définissez le moment où la machine locale dessert le service esclave, définissez l'adresse IP et le port du service maître. Lorsque Redis démarre, il synchronisera automatiquement les données du maître.
esclavede
14. Lorsque le service maître est protégé par mot de passe, le mot de passe permettant au service esclave de se connecter au maître
maîtreauth
15. Définissez le mot de passe de connexion Redis. Si le mot de passe de connexion est configuré, le client doit fournir le mot de passe via la commande AUTH lors de la connexion à Redis. Il est fermé par défaut.
exiger un laissez-passer foobaré
16. Définissez le nombre maximum de connexions client en même temps. La valeur par défaut est illimitée. Le nombre de connexions client que Redis peut ouvrir en même temps est le nombre maximum de descripteurs de fichiers que le processus Redis peut ouvrir. Si maxclients 0 est défini, cela signifie qu’il n’y a pas de limite. Lorsque le nombre de connexions client atteint la limite, Redis fermera la nouvelle connexion et renverra le message d'erreur du nombre maximum de clients atteint au client.
clients max 128
17. Spécifiez la limite de mémoire maximale de Redis. Redis chargera les données dans la mémoire au démarrage. Après avoir atteint la mémoire maximale, Redis tentera d'abord d'effacer les clés qui ont expiré ou sont sur le point d'expirer. Une fois cette méthode traitée, la mémoire maximale est encore atteinte, les réglages, les écritures ne seront plus possibles, mais les lectures seront toujours possibles. Le nouveau mécanisme vm de Redis stockera la clé en mémoire et la valeur dans la zone d'échange.
mémoire maximale
18. Spécifiez s'il faut effectuer la journalisation après chaque opération de mise à jour. Redis écrit les données sur le disque de manière asynchrone par défaut. S'il n'est pas activé, les données peuvent être perdues pendant un certain temps lors d'une panne de courant. Étant donné que les fichiers de données synchronisés de Redis sont synchronisés selon les conditions de sauvegarde ci-dessus, certaines données n'existeront en mémoire que pendant un certain temps. La valeur par défaut est non
en annexe seulement non
19. Spécifiez le nom du fichier journal de mise à jour, la valeur par défaut est appendonly.aof
appendfilename appendonly.aof
20. Spécifiez les conditions du journal de mise à jour. Il existe 3 valeurs facultatives :
non : signifie attendre que le système d'exploitation synchronise le cache de données sur le disque (rapide)
toujours : signifie appeler manuellement fsync() pour écrire les données sur le disque après chaque opération de mise à jour (lent, sûr)
toutes les secondes : signifie synchroniser une fois par seconde (compromis, valeur par défaut))
appendfsync chaque seconde
21. Spécifiez s'il faut activer le mécanisme de mémoire virtuelle. La valeur par défaut est non. Pour donner une brève introduction, le mécanisme de VM stocke les données dans des pages. Redis échange les pages avec moins d'accès, c'est-à-dire des données froides, au disque. les pages avec plus d'accès sont automatiquement transférées sur le disque. Échangez vers la mémoire (j'analyserai attentivement le mécanisme VM de Redis dans un article ultérieur)
compatible VM non
22. Chemin du fichier de mémoire virtuelle, la valeur par défaut est /tmp/redis.swap, qui ne peut pas être partagée par plusieurs instances Redis.
fichier-vm-swap /tmp/redis.swap
23. Stockez toutes les données supérieures à vm-max-memory dans la mémoire virtuelle. Peu importe la taille du paramètre vm-max-memory, toutes les données d'index sont stockées en mémoire (les données d'index de Redis sont des clés). En d'autres termes, quand vm Lorsque -max-memory est défini sur 0, toutes les valeurs existent réellement sur le disque. La valeur par défaut est 0
vm-max-mémoire 0
24. Le fichier d'échange Redis est divisé en plusieurs pages. Un objet peut être enregistré sur plusieurs pages, mais une page ne peut pas être partagée par plusieurs objets. La taille de la page vm est définie en fonction de la taille des données stockées. Il est recommandé que si vous stockez de nombreux petits objets, la taille de la page soit définie sur 32 ou 64 octets ; si vous stockez des objets très volumineux, vous pouvez utiliser une page plus grande. Si vous n'êtes pas sûr, utilisez la valeur par défaut.
vm-page-size 32
25. Définissez le nombre de pages dans le fichier d'échange. Étant donné que la table des pages (un bitmap indiquant qu'une page est libre ou utilisée) est placée en mémoire, toutes les 8 pages sur le disque consommeront 1 octet de mémoire.
pages vm 134217728
26. Définissez le nombre de threads pour accéder au fichier d'échange. Il est préférable de ne pas dépasser le nombre de cœurs de la machine. S'il est défini sur 0, alors toutes les opérations sur le fichier d'échange seront en série, ce qui peut entraîner une longue retard. La valeur par défaut est 4
vm-max-threads 4
27. Définissez s'il faut combiner des paquets plus petits en un seul paquet et l'envoyer lors de la réponse au client. La valeur par défaut est activée.
colleoutputbuf oui
28. Spécifiez qu'un algorithme de hachage spécial est utilisé lorsqu'un certain nombre est dépassé ou que l'élément le plus grand dépasse une certaine valeur critique.
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29. Spécifiez s'il faut activer le hachage de réinitialisation. La valeur par défaut est activée (les détails seront introduits plus tard lors de l'introduction de l'algorithme de hachage Redis)
activerehashing oui
30. En spécifiant d'autres fichiers de configuration, vous pouvez utiliser le même fichier de configuration entre plusieurs instances Redis sur le même hôte, et chaque instance possède son propre fichier de configuration spécifique.
inclure /chemin/vers/local.conf
6. Persistance Redis
Redis est une base de données en mémoire. Si l'état de la base de données en mémoire n'est pas enregistré sur le disque, une fois le processus serveur terminé, l'état de la base de données sur le serveur disparaîtra également. Redis fournit donc des fonctionnalités de persistance !
1、RDB(Redis DataBase)
Qu'est-ce que RDB
Écrivez un instantané de l'ensemble de données en mémoire sur le disque dans un intervalle de temps spécifié, également appelé instantané dans le jargon. Lorsqu'il est restauré, le fichier d'instantané est lu directement dans la mémoire.
Redis créera (fork) un sous-processus distinct pour la persistance. Il écrira d'abord les données dans un fichier temporaire. Une fois le processus de persistance terminé, ce fichier temporaire sera utilisé pour remplacer le dernier fichier persistant. Pendant tout le processus, le processus principal n'effectue aucune opération d'E/S. Cela garantit des performances extrêmement élevées. Si une récupération de données à grande échelle est requise et que l'intégrité de la récupération des données n'est pas très sensible, la méthode RDB est plus efficace que la méthode AOF. L'inconvénient de RDB est que les données après la dernière persistance peuvent être perdues.
Fourchette
La fonction de Fork est de copier un processus identique au processus actuel. Toutes les données (variables, variables d'environnement, compteur de programme, etc.) du nouveau processus ont les mêmes valeurs que le processus d'origine, mais il s'agit d'un processus complètement nouveau et sert de processus enfant du processus d'origine.
Rdb enregistre le fichier dump.rdb
Emplacement de la configuration et analyse SNAPSHOTTING
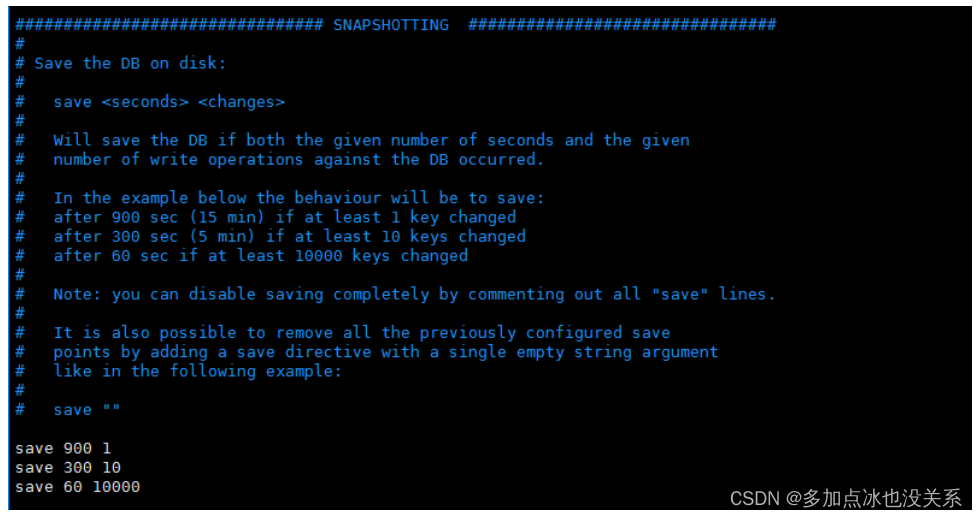
Nous pouvons modifier et tester le mécanisme des conditions de déclenchement ici :
save 120 10 # 120秒内修改10次则触发RDB
RDB est un instantané compressé qui intègre de la mémoire. La structure de données de RDB peut configurer des conditions de déclenchement d'instantané composées.
défaut:
- Changé 10 000 fois en 1 minute
- Changé 10 fois en 5 minutes
- Changé une fois toutes les 15 minutes
Si vous souhaitez désactiver la stratégie de persistance RDB, ne définissez simplement aucune instruction de sauvegarde ou ne transmettez pas un paramètre de chaîne vide à enregistrer.
Si la modification doit prendre effet immédiatement, vous pouvez utiliser manuellement la commande save ! En vigueur immédiatement!
Analyser le reste des commandes
Stop-writes-on-bgsave-error : si configuré sur non, cela signifie que vous ne vous souciez pas de l'incohérence des données ou que vous disposez d'autres moyens pour la détecter et la contrôler. La valeur par défaut est oui.
rbdcompression : pour les instantanés stockés sur le disque, vous pouvez définir s'il faut les compresser et les stocker. Si tel est le cas, Redis utilisera l'algorithme LZF pour la compression. Si vous ne souhaitez pas consommer de CPU pour la compression, vous pouvez désactiver cette fonctionnalité.
rdbchecksum : Après avoir stocké l'instantané, vous pouvez également laisser Redis utiliser l'algorithme CRC64 pour vérifier les données, mais cela augmentera la consommation de performances d'environ 10 %. Si vous souhaitez obtenir une amélioration maximale des performances, vous pouvez désactiver cette fonction. La valeur par défaut est oui.
Comment déclencher un instantané RDB
1. La configuration de l'instantané par défaut dans le fichier de configuration. Il est recommandé d'utiliser une machine supplémentaire comme sauvegarde et de copier dump.rdb.
2. Commande save ou bgsave
- Lors de la sauvegarde, enregistrez simplement, ignorez les autres éléments et bloquez tout.
- bgsave, Redis effectuera des opérations d'instantané de manière asynchrone en arrière-plan, et l'instantané peut également répondre aux demandes des clients. Vous pouvez utiliser la commande lastsave pour obtenir l'heure de la dernière exécution réussie de l'instantané.
3. L'exécution de la commande flushall générera également le fichier dump.rdb, mais il est vide et dénué de sens !
4. Le fichier dump.rdb sera également généré à la sortie !
Comment restaurer
1. Déplacez le fichier de sauvegarde (dump.rdb) vers le répertoire d'installation Redis et démarrez le service.
2. CONFIG GET dir pour obtenir le répertoire
127.0.0.1:6379> config get dir
dir
/usr/local/bin
avantages et inconvénients
Avantages :
1. Convient à la récupération de données à grande échelle
2. Faibles exigences en matière d’intégrité et de cohérence des données
Inconvénients :
1. Effectuez une sauvegarde à un certain intervalle, donc si Redis tombe accidentellement en panne, toutes les modifications après le dernier instantané seront perdues.
2. Lors de Fork, les données dans la mémoire sont clonées et environ 2 fois l'extension doit être prise en compte.
résumé
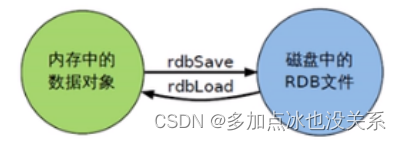

2、AOF(Ajouter uniquement le fichier)
qu'est-ce que
Chaque opération d'écriture est enregistrée sous la forme d'un journal, et toutes les instructions exécutées par Redis sont enregistrées (les opérations de lecture ne sont pas enregistrées). Seuls les fichiers peuvent être ajoutés mais pas réécrits. Au démarrage de Redis, le fichier sera lu pour reconstruire le En d'autres termes, lorsque Redis est redémarré, les instructions d'écriture seront exécutées d'avant en arrière en fonction du contenu du fichier journal pour terminer le travail de récupération de données.
Aof enregistre le fichier appendonly.aof
Configuration
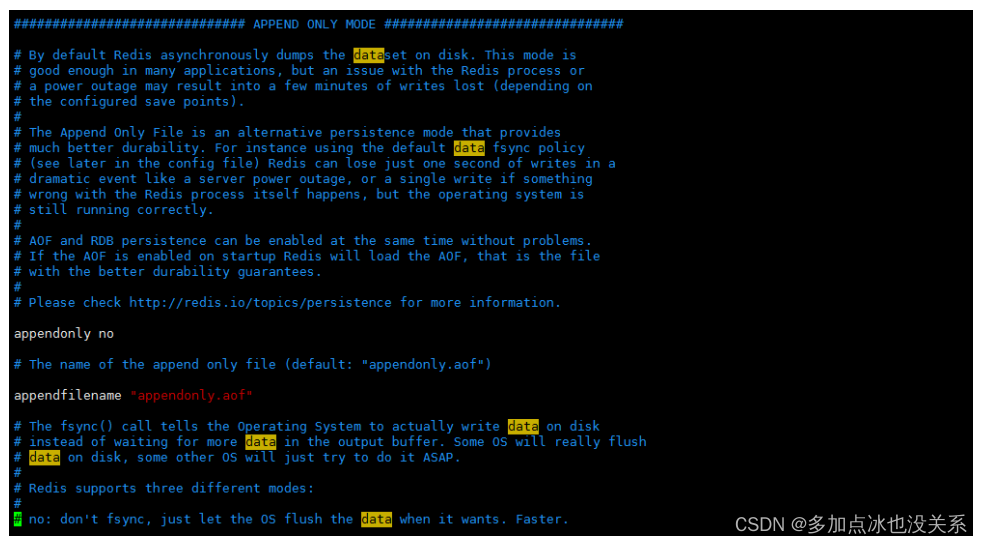
appendonly no # 是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这种方式在许多应用中已经足够用了
appendfilename "appendonly.aof" # appendfilename AOF 文件名称
appendfsync everysec # appendfsync aof持久化策略的配置
# no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
# always表示每次写入都执行fsync,以保证数据同步到磁盘。
# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
No-appendfsync-on-rewrite #重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性
Auto-aof-rewrite-min-size # 设置重写的基准值
Auto-aof-rewrite-percentage #设置重写的基准值
Démarrage/réparation/récupération AOF
Récupération normale :
- Démarrage : définissez Oui, modifiez le non en annexe par défaut et remplacez-le par oui.
- Copiez le fichier aof avec les données et enregistrez-le dans le répertoire correspondant (config get dir)
- Récupération : redémarrez Redis et rechargez
Récupération des exceptions :
- Démarrage : définir Oui
- Destruction volontaire du fichier appendonly.aof !
- Correctif : redis-check-aof --fix appendonly.aof pour corriger
- Récupération : redémarrez Redis et rechargez
Récrire
Qu'est-ce que:
AOF utilise l'ajout de fichiers, et le fichier deviendra de plus en plus grand. Pour éviter cette situation, un nouveau mécanisme de réécriture est ajouté. Lorsque la taille du fichier AOF dépasse le seuil défini, Redis démarre la compression du contenu du fichier AOF. Seulement conservez le jeu minimum d'instructions permettant de récupérer des données, vous pouvez utiliser la commande bgrewriteaof!
Principe de réécriture :
Lorsque le fichier AOF continue de croître et devient trop volumineux, un nouveau processus sera lancé pour réécrire le fichier (le fichier temporaire est d'abord écrit puis renommé
), et les données dans la mémoire du nouveau processus sont parcourues. une instruction Set. L'opération de réécriture du fichier AOF ne lit pas l'ancien fichier AOF, c'est un peu comme un instantané !
Mécanisme de déclenchement :
Redis enregistrera la taille AOF lors de sa dernière réécriture. La configuration par défaut est de se déclencher lorsque la taille du fichier AOF est la taille après la dernière réécriture et que le fichier est supérieur à 64 Mo.
Une fois qu'un expert fait un geste, il n'y aura aucun succès : les experts regarderont la porte, tandis que les profanes ne regarderont que le plaisir.
avantages et inconvénients
avantage:
1. Synchronisez chaque modification : appendfsync synchronise toujours la persistance. Chaque fois qu'un changement de données se produit, il sera immédiatement enregistré sur le disque. Les performances sont médiocres mais l'intégrité des données est meilleure.
2. Synchronisation toutes les secondes : opération asynchrone appendfsync eachsec, enregistrée chaque seconde. Si la machine tombe en panne dans la seconde, les données seront perdues.
3. Non synchronisé : appendfsync non ne se synchronise jamais
défaut:
1. Pour le même ensemble de données, les fichiers aof sont beaucoup plus volumineux que les fichiers rdb et la vitesse de récupération est plus lente que celle de rdb.
2. L'efficacité de fonctionnement d'Aof est plus lente que celle de RDB, la stratégie de synchronisation par seconde est plus efficace et l'efficacité de désynchronisation est la même que celle de RDB.
Résumé
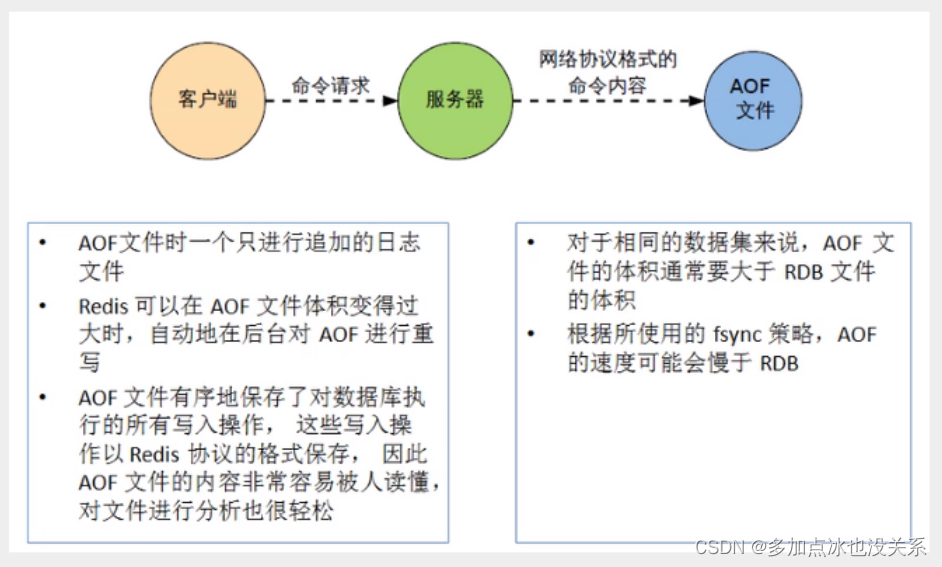
3. Résumé
1. La méthode de persistance RDB peut capturer et stocker vos données dans un intervalle de temps spécifié.
2. Le mode de persistance AOF enregistre chaque opération d'écriture sur le serveur. Lorsque le serveur redémarre, ces commandes seront réexécutées pour restaurer les données d'origine. La commande AOF utilise le protocole Redis pour ajouter et enregistrer chaque opération d'écriture à la fin du Redis peut également réécrire en arrière-plan les fichiers AOF pour éviter que la taille des fichiers AOF ne soit trop grande.
3. Cache uniquement. Si vous souhaitez que vos données n'existent que lorsque le serveur est en cours d'exécution, vous ne pouvez pas non plus utiliser de persistance.
4. Activez deux méthodes de persistance en même temps
- Dans ce cas, au redémarrage de Redis, le fichier AOF sera chargé en premier pour restaurer les données d'origine, car généralement l'ensemble de données enregistré par le fichier AOF est plus complet que l'ensemble de données enregistré par le fichier RDB.
- Les données dans RDB ne sont pas en temps réel. Lorsque le serveur est redémarré et que les deux sont utilisés en même temps, seuls les fichiers AOF seront trouvés. Alors faut-il utiliser uniquement AOF ? L'auteur ne le recommande pas, car RDB est plus adapté à la sauvegarde de la base de données (l'AOF change constamment et n'est pas facile à sauvegarder), redémarre rapidement et il n'y aura pas de bugs potentiels dans l'AOF, il est donc réservé en tant que mesure au cas où.
5. Suggestions de performances
- Étant donné que le fichier RDB n'est utilisé qu'à des fins de sauvegarde, il est recommandé de conserver le fichier RDB uniquement sur l'esclave et il ne doit être sauvegardé qu'une fois toutes les 15 minutes. Seule la règle de sauvegarde 900 1 est conservée.
- Si AOF est activé, l'avantage est que dans le pire des cas, les données ne seront perdues que pendant deux secondes maximum. Le script de démarrage est relativement simple, il suffit de charger votre propre fichier AOF. Le coût est qu'il apporte des E/S continues, et la seconde est la réécriture AOF. Enfin, le blocage provoqué par l'écriture des nouvelles données générées lors du processus de réécriture dans le nouveau fichier est presque inévitable. Tant que le disque dur le permet, la fréquence de réécriture AOF doit être minimisée. La taille de base par défaut de la réécriture AOF, 64 Mo, est trop petite. Elle peut être définie sur plus de 5 Go. La taille par défaut de réécriture 100 %, qui dépasse la taille originale, peut être modifiée à une valeur appropriée.
- Si AOF n'est pas activé, une haute disponibilité peut être obtenue en s'appuyant uniquement sur la réplication maître-esclave, ce qui peut économiser beaucoup d'E/S et réduire les fluctuations du système causées par la réécriture. Le coût est que si le maître/esclave est vidé en même temps, plus de dix minutes de données seront perdues. Le script de démarrage doit également comparer les fichiers RDB des deux maîtres/esclaves et charger le plus récent. Weibo a cette architecture.
7. Transactions Redis
1. Théorie
Le concept des transactions Redis :
L'essence d'une transaction Redis est un ensemble de commandes. Les transactions prennent en charge l'exécution de plusieurs commandes à la fois, et toutes les commandes d'une transaction seront sérialisées. Pendant le processus d'exécution de la transaction, les commandes dans la file d'attente seront exécutées en série dans l'ordre et les demandes de commandes soumises par d'autres clients ne seront pas insérées dans la séquence de commandes d'exécution de la transaction.
Pour résumer : une transaction Redis est une exécution unique, séquentielle et exclusive d'une série de commandes dans une file d'attente.
Les transactions Redis n'ont aucune notion de niveaux d'isolement :
L'opération par lots est placée dans le cache de file d'attente avant d'envoyer la commande EXEC et ne sera pas réellement exécutée !
Redis ne garantit pas l'atomicité :
Dans Redis, une seule commande est exécutée de manière atomique, mais il n'est pas garanti que les transactions soient atomiques et il n'y a pas de restauration. Si une commande de la transaction ne parvient pas à s'exécuter, les commandes restantes seront quand même exécutées.
Trois étapes de transactions Redis :
- commencer la transaction
- commande pour mettre en file d'attente
- Exécuter la transaction
Commandes liées aux transactions Redis :
watch key1 key2 ... #监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
multi # 标记一个事务块的开始( queued )
exec # 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
discard # 取消事务,放弃事务块中的所有命令
unwatch # 取消watch对所有key的监控
2. Pratique
Exécution normale
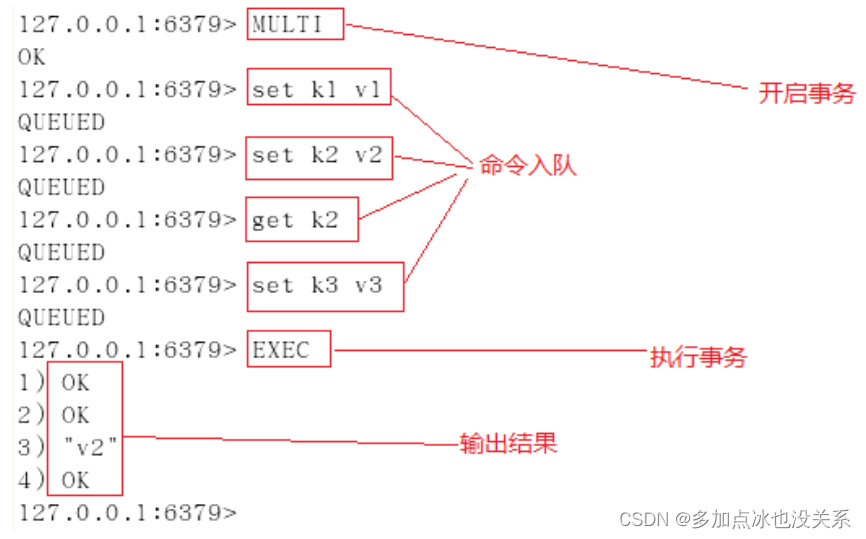
abandonner la transaction
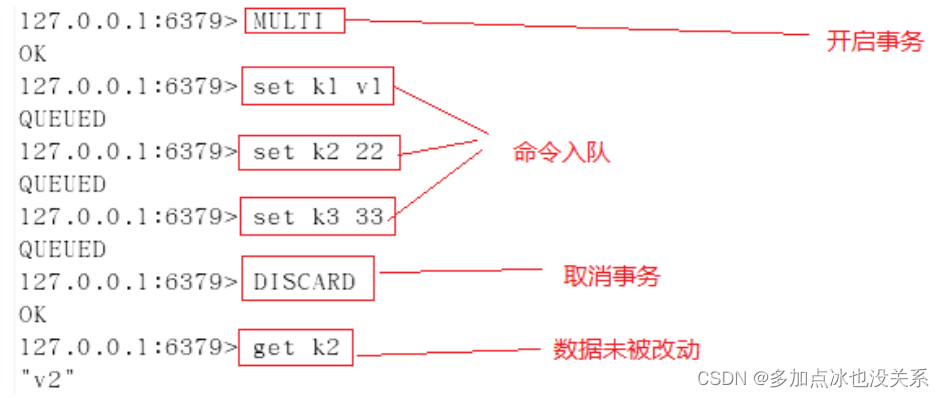
S'il y a une erreur de commande dans la file d'attente des transactions (similaire à une erreur de compilation Java), toutes les commandes ne seront pas exécutées lors de l'exécution de la commande EXEC.

S'il y a une erreur de syntaxe dans la file d'attente des transactions (similaire à l'exception d'exécution 1/0 de Java), lorsque la commande EXEC est exécutée, d'autres commandes correctes seront exécutées et la mauvaise commande lèvera une exception.

Surveillance de la montre
Verrouillage pessimiste :
Le verrouillage pessimiste, comme son nom l'indique, est très pessimiste. Chaque fois que vous allez récupérer les données, vous pensez que d'autres les modifieront, vous le verrouillerez donc à chaque fois que vous obtiendrez les données, de sorte que si d'autres le souhaitent récupérez les données, ils les bloqueront jusqu'à ce qu'ils obtiennent le verrou. De nombreux mécanismes de verrouillage de ce type sont utilisés dans les bases de données relationnelles traditionnelles, tels que les verrous de ligne, les verrous de table, les verrous de lecture, les verrous d'écriture, etc., qui sont tous verrouillés avant les opérations.
Verrouillage optimiste :
Optimistic Lock, comme son nom l'indique, est très optimiste. Chaque fois que vous allez récupérer les données, vous pensez que les autres ne les modifieront pas, vous ne les verrouillerez donc pas. Cependant, lors de la mise à jour, il sera jugé si d'autres ont mis à jour les données au cours de cette période. Vous pouvez utiliser des mécanismes tels que les numéros de version. Le verrouillage optimiste convient aux types d'applications à lectures multiples, ce qui peut améliorer le débit. Stratégie de verrouillage optimiste : la version doit être supérieure à La version actuelle doit être enregistrée afin d'effectuer les mises à jour.
test:
1. Initialisez le solde disponible et le solde impayé de la carte de crédit
127.0.0.1:6379> set balance 100
OK
127.0.0.1:6379> set debt 0
OK
2. Utilisez la montre pour détecter le solde. Les données du solde ne changent pas pendant la transaction et la transaction est exécutée avec succès.
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
3. Utilisez la montre pour détecter le solde. Les données du solde changent pendant la transaction et l'exécution de la transaction échoue !
# 窗口一
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI # 执行完毕后,执行窗口二代码测试
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec # 修改失败!
(nil)
# 窗口二
127.0.0.1:6379> get balance
"80"
127.0.0.1:6379> set balance 200
OK
# 窗口一:出现问题后放弃监视,然后重来!
127.0.0.1:6379> UNWATCH # 放弃监视
OK
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec # 成功!
1) (integer) 180
2) (integer) 40
illustrer:
Une fois EXEC exécuté pour démarrer l'exécution de la transaction, la surveillance des variables par WARCH sera annulée, que la transaction soit exécutée avec succès ou non.
Par conséquent, lorsque l'exécution de la transaction échoue, vous devez réexécuter la commande WATCH pour surveiller les variables et démarrer une nouvelle transaction pour l'opération.
3. Résumé
L'instruction de surveillance est similaire au verrouillage optimiste. Lorsque la transaction est validée, si la valeur d'une clé parmi les multiples clés surveillées par la surveillance a été modifiée par d'autres clients, lorsque EXEC est utilisé pour exécuter la transaction, la file d'attente des transactions ne sera pas être exécuté et Nullmulti- sera renvoyé. Réponse groupée pour informer l'appelant que l'exécution de la transaction a échoué.
8. Redis publier et s'abonner
qu'est-ce que
Redis publier et s'abonner (pub/sub) est un modèle de communication de messages : l'expéditeur (pub) envoie des messages et les abonnés (sub) reçoivent des messages.
Les clients Redis peuvent s'abonner à n'importe quel nombre de canaux.
Graphique des messages d'abonnement/publication :
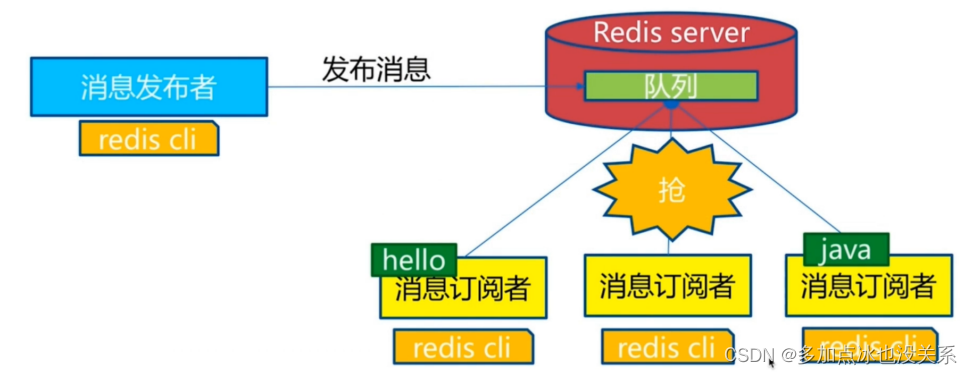
La figure suivante montre la relation entre le canal canal1 et les trois clients abonnés à ce canal : client2, client5 et client1 :
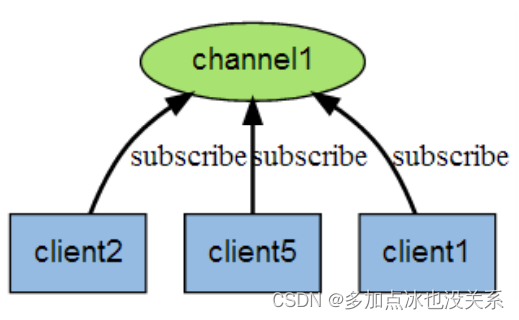
Lorsqu'un nouveau message est envoyé au canal canal1 via la commande PUBLISH, le message sera envoyé aux trois clients qui y sont abonnés :
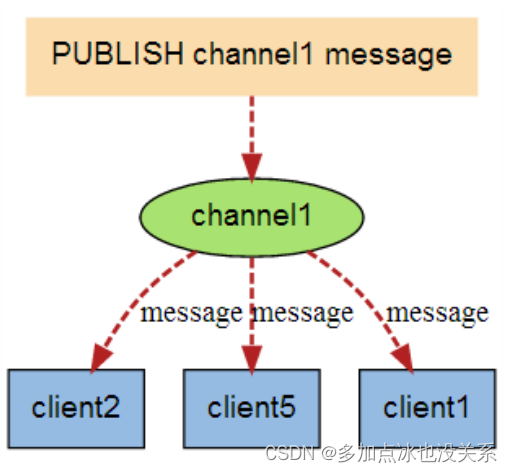
Commande
Ces commandes sont largement utilisées pour créer des applications de messagerie instantanée, telles que des salons de discussion en ligne, des diffusions en temps réel, des rappels en temps réel, etc.
test
L'exemple suivant montre le fonctionnement de la publication-abonnement. Dans notre exemple nous créons un canal d'abonnement nommé redisChat :
redis 127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
Maintenant, nous redémarrons d'abord un client Redis, puis publions le message deux fois sur le même canal redisChat, afin que les abonnés puissent recevoir le message.
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Redis"
(integer) 1
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Kuangshen"
(integer) 1
# 订阅者的客户端会显示如下消息
1) "message"
2) "redisChat"
3) "Hello,Redis"
1) "message"
2) "redisChat"
3) "Hello,Kuangshen"
principe
Redis est implémenté en C. En analysant le fichier pubsub.c dans le code source de Redis, nous pouvons comprendre l'implémentation sous-jacente du mécanisme de publication et d'abonnement, et ainsi approfondir notre compréhension de Redis.
Redis implémente des fonctions de publication et d'abonnement via des commandes telles que PUBLISH, SUBSCRIBE et PSUBSCRIBE.
Après vous être abonné à un canal via la commande SUBSCRIBE, un dictionnaire est conservé dans Redis-Server. La clé du dictionnaire est chaque canal et la valeur du dictionnaire est une liste chaînée. La liste chaînée stocke tous les clients qui s'abonnent à ce canal. . La clé de la commande SUBSCRIBE est d'ajouter le client à la liste d'abonnement d'un canal donné.
Pour envoyer des messages aux abonnés via la commande PUBLISH, redis-server utilisera le canal donné comme clé, recherchera la liste chaînée de tous les clients abonnés à ce canal dans le dictionnaire de canaux qu'il gère, parcourra cette liste chaînée et publiera le message. à tous les abonnés.
Pub/Sub signifie littéralement Publier et Abonnez-vous. Dans Redis, vous pouvez configurer la publication de messages et l'abonnement aux messages pour une certaine valeur de clé. Lorsqu'un message est publié sur une valeur de clé, tous les clients qui s'y abonnent recevront les messages correspondants. L'utilisation la plus évidente de cette fonction est celle d'un système de messagerie en temps réel, tel qu'un chat instantané ordinaire, un chat de groupe et d'autres fonctions.
scènes à utiliser
Pub/Sub crée un système de messagerie en temps réel
Le système Pub/Sub de Redis peut créer un système de messagerie en temps réel
, comme de nombreux exemples de systèmes de discussion en temps réel créés avec Pub/Sub.
9. Réplication maître-esclave Redis
1. Concept
La réplication maître-esclave fait référence à la copie de données d'un serveur Redis vers d'autres serveurs Redis. Le premier est appelé nœud maître (maître/leader) et le second est appelé nœud esclave (esclave/suiveur) ; la réplication des données est unidirectionnelle et ne peut s'effectuer que du nœud maître vers le nœud esclave. Le maître est principalement destiné à l'écriture et l'esclave est principalement destiné à la lecture.
Par défaut, chaque serveur Redis est un nœud maître ; et un nœud maître peut avoir plusieurs nœuds esclaves (ou aucun nœud esclave), mais un nœud esclave ne peut avoir qu'un seul nœud maître.
Les principales fonctions de la réplication maître-esclave comprennent :
1. Redondance des données : la réplication maître-esclave réalise une sauvegarde à chaud des données, qui est une méthode de redondance des données en plus de la persistance.
2. Récupération des pannes : lorsqu'un problème survient sur le nœud maître, le nœud esclave peut fournir des services pour obtenir une récupération rapide des pannes ; il s'agit en fait d'une sorte de redondance de service.
3. Équilibrage de charge : basé sur la réplication maître-esclave, combinée à une séparation lecture-écriture, le nœud maître peut fournir des services d'écriture et les nœuds esclaves peuvent fournir des services de lecture (c'est-à-dire que lors de l'écriture de données Redis, l'application se connecte au nœud maître , et lors de la lecture des données Redis, l'application se connecte au nœud esclave) pour partager la charge du serveur ; en particulier dans les scénarios où il y a moins d'écriture et plus de lecture, le partage de la charge de lecture via plusieurs nœuds esclaves peut augmenter considérablement la simultanéité du Serveur Redis.
4. La pierre angulaire de la haute disponibilité : En plus des fonctions ci-dessus, la réplication maître-esclave est également la base de la mise en œuvre de sentinelles et de clusters. Par conséquent, la réplication maître-esclave est la base de la haute disponibilité de Redis.
De manière générale, pour utiliser Redis dans des projets d'ingénierie, il est absolument impossible d'utiliser un seul Redis pour les raisons suivantes :
1. Structurellement, un seul serveur Redis aura un point de défaillance unique et un serveur doit gérer toutes les charges de requêtes, ce qui exerce une grande pression ;
2. En termes de capacité, un seul serveur Redis a une capacité de mémoire limitée. Même si un serveur Redis a une capacité de mémoire de 256 Go, toute la mémoire ne peut pas être utilisée comme mémoire de stockage Redis. De manière générale, la mémoire maximale utilisée par un seul Redis le serveur ne doit pas dépasser 20G.
Les produits sur les sites de commerce électronique sont généralement téléchargés une seule fois et consultés un nombre incalculable de fois, ce qui, en termes professionnels, signifie « lire plus et écrire moins ».
Pour ce scénario, nous pouvons utiliser l'architecture suivante :
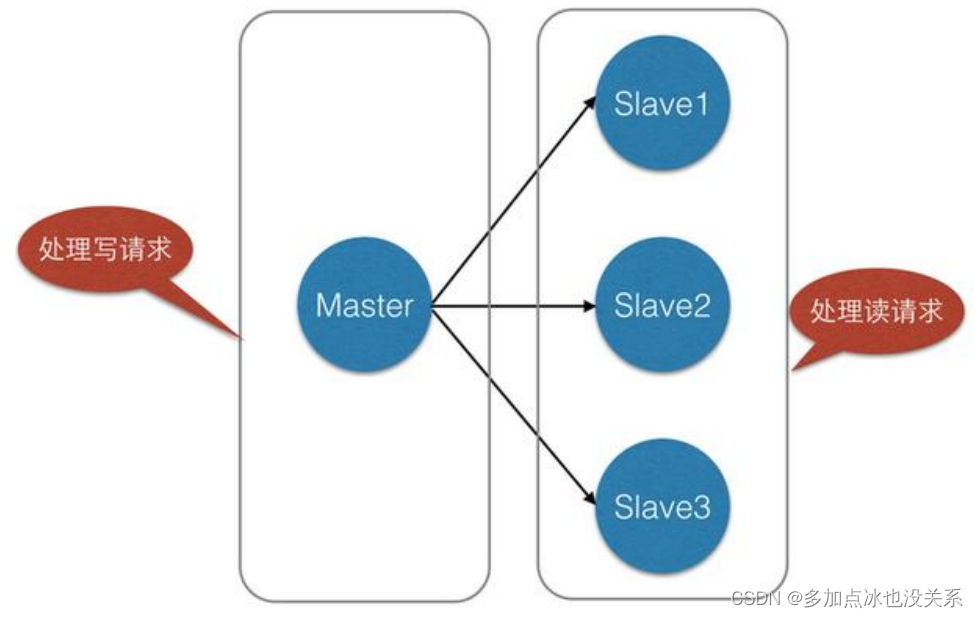
2. Configuration de l'environnement
configuration de base
Avec la bibliothèque esclave mais pas la bibliothèque maître, la configuration de la bibliothèque esclave :
slaveof 主库ip 主库端口 # 配置主从
Info replication # 查看信息
Chaque fois que vous vous déconnectez du maître, vous devez vous reconnecter, sauf si vous le configurez dans le fichier redis.conf !
Modifiez le fichier de configuration !
Travail de préparation : Nous configurons la réplication maître-esclave, il en faut au moins trois, un maître et deux esclaves ! Configurez trois clients !
1. Copiez plusieurs fichiers redis.conf
2. Spécifiez le port 6379, et ainsi de suite.
3. Activez la démonisation oui
4. Le nom du fichier Pid est pidfile /var/run/redis_6379.pid, et ainsi de suite.
5. Nom du fichier journal fichier journal « 6379.log », et ainsi de suite.
6. Nom Dump.rdb dbfilename dump6379.rdb, et ainsi de suite.

Une fois la configuration ci-dessus terminée et les trois services démarrés via trois fichiers de configuration différents, notre environnement de préparation est OK !

3. Un maître et deux esclaves
Un maître et deux serviteurs
1. Initialisation de l'environnement
Par défaut, tous les trois sont des nœuds maîtres.
2. Configurez comme un maître et deux esclaves
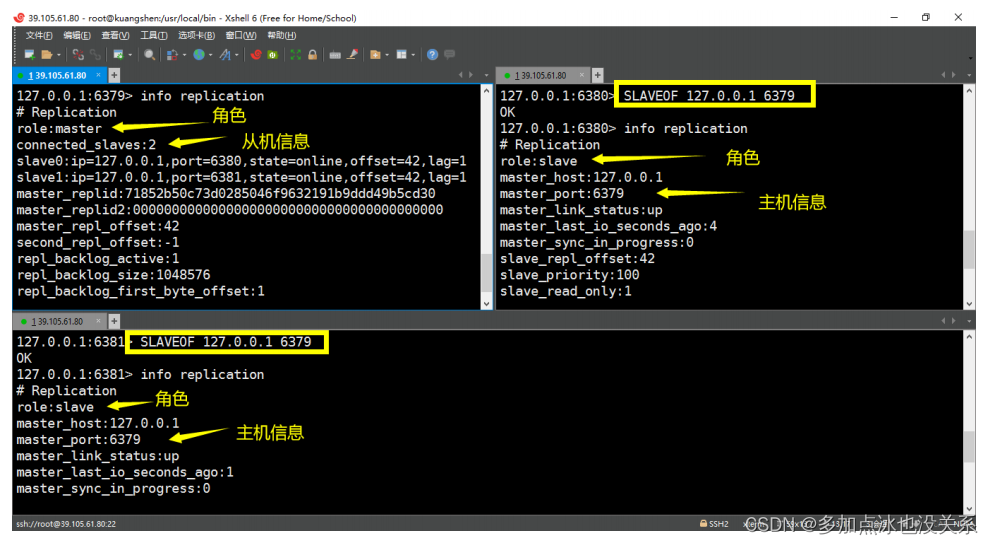
3. Les valeurs définies sur la machine hôte peuvent être obtenues sur la machine esclave ! L'esclave ne peut pas écrire de valeur !
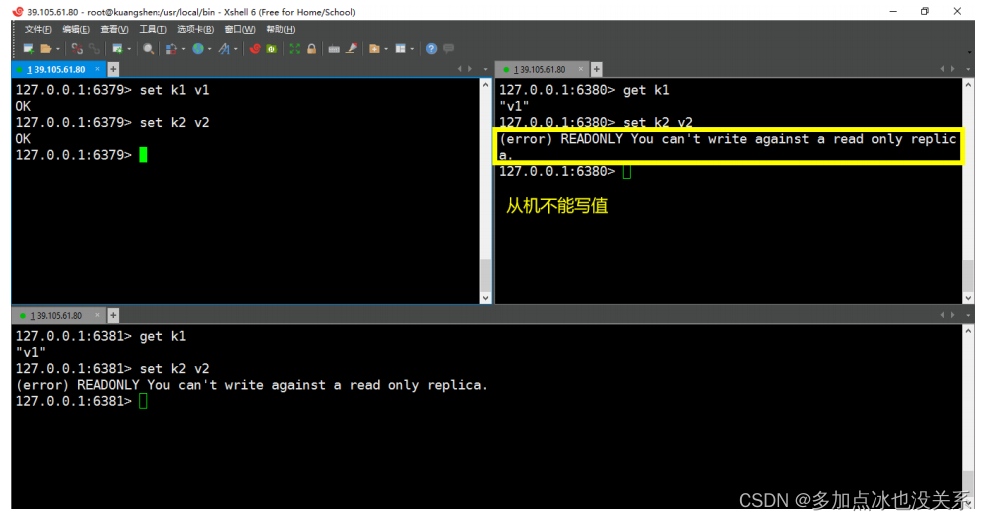
Test 1 : l'hôte raccroche, vérifie les informations sur l'esclave, l'hôte récupère et vérifie à nouveau les informations
Test 2 : la machine esclave raccroche, vérifiez les informations sur l'hôte, la machine esclave récupère et vérifiez les informations sur la machine esclave
liens couche par couche
L'esclave précédent peut être l'esclave et le maître suivant. L'esclave peut également recevoir des demandes de connexion et de synchronisation d'autres esclaves. L'esclave sert alors de prochain maître dans la chaîne, ce qui peut réduire efficacement la pression d'écriture du maître !
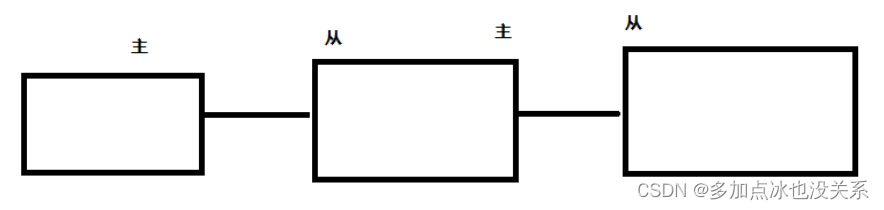
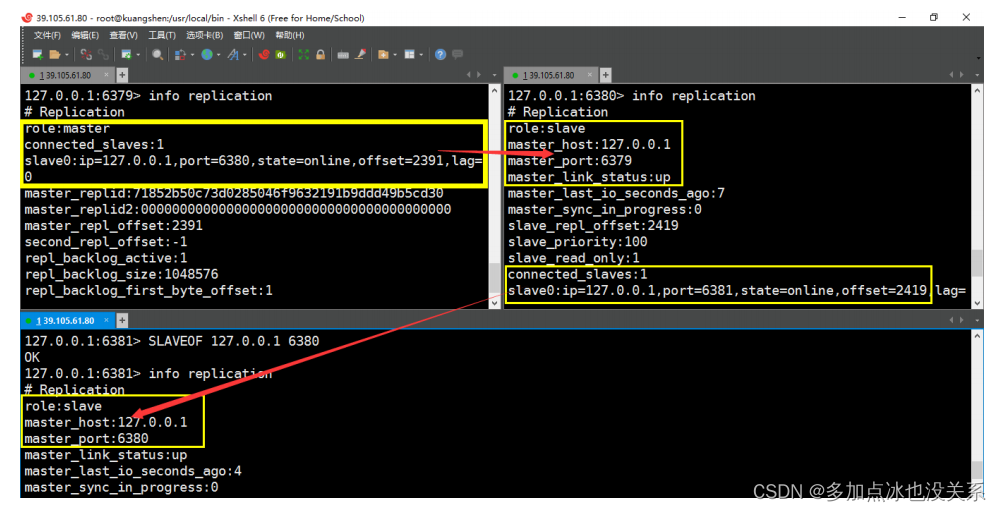
Test : Après avoir défini la valeur de 6379, 6380 et 6381 peuvent être obtenus ! D'ACCORD!
Complot pour usurper le trône
Dans le cas d'un maître et de deux esclaves, si le maître est déconnecté, l'esclave peut utiliser la commande SLAVEOF NO ONE pour se changer en maître ! A ce moment, les esclaves restants sont liés à ce nœud. L'exécution de la commande SLAVEOF NO ONE sur un serveur esclave entraînera la désactivation de la fonction de réplication du serveur esclave et la transition du serveur esclave vers le serveur maître. L'ensemble de données synchronisées d'origine ne sera pas supprimé.
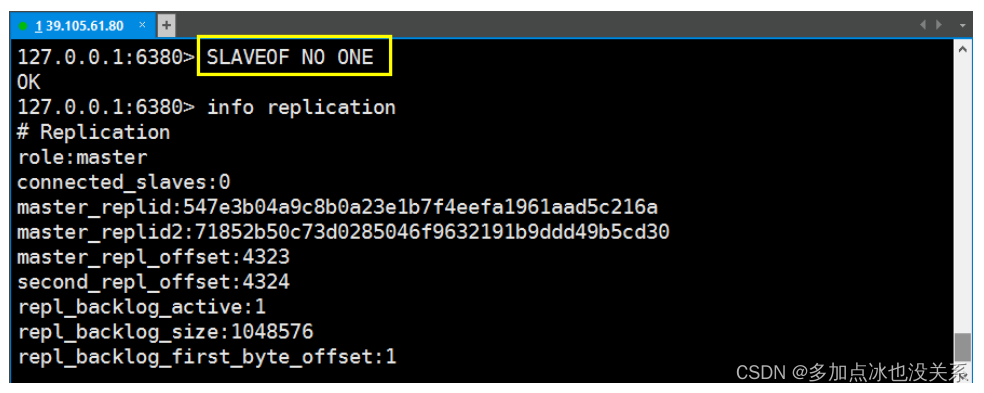
Lorsque la machine maître reviendra, ce ne sera qu'un commandant raffiné, et les machines esclaves fonctionneront vers la nouvelle machine maître pour une utilisation normale !
Principe de copie
Une fois que l'esclave démarre et se connecte avec succès au maître, il enverra une commande de synchronisation.
Après avoir reçu la commande, le maître démarre le processus de sauvegarde en arrière-plan et collecte toutes les commandes reçues pour modifier l'ensemble de données. Une fois le processus en arrière-plan terminé, le maître transférera l'intégralité du fichier de données à l'esclave et effectuera une synchronisation complète.
Copie complète : après avoir reçu les données du fichier de base de données, le service esclave les enregistre et les charge en mémoire.
Réplication incrémentielle : le maître continue de transmettre toutes les nouvelles commandes de modification collectées à l'esclave afin de terminer la synchronisation.
Mais tant que le maître est reconnecté, une synchronisation complète (réplication complète) sera automatiquement effectuée.
4. Mode sentinelle
Aperçu
La méthode de technologie de commutation maître-esclave est la suivante : lorsque le serveur maître tombe en panne, vous devez basculer manuellement un serveur esclave vers le serveur maître, ce qui nécessite une intervention manuelle, prend du temps et est laborieux, et entraînera également une interruption du service. indisponible pendant un certain temps. Ce n'est pas une approche recommandée, le plus souvent nous donnons la priorité au mode Sentinelle. Redis fournit officiellement l'architecture Sentinel depuis la version 2.8 pour résoudre ce problème.
La version automatique qui cherche à usurper le trône peut surveiller si l'hôte échoue en arrière-plan. En cas d'échec, il passera automatiquement de la base de données esclave à la base de données principale en fonction du nombre de votes.
Le mode Sentinel est un mode spécial. Premièrement, Redis fournit des commandes sentinelle. Sentinel est un processus indépendant. En tant que processus, il s'exécutera indépendamment. Le principe est que la sentinelle surveille plusieurs instances Redis en cours d'exécution en envoyant des commandes et en attendant la réponse du serveur Redis .
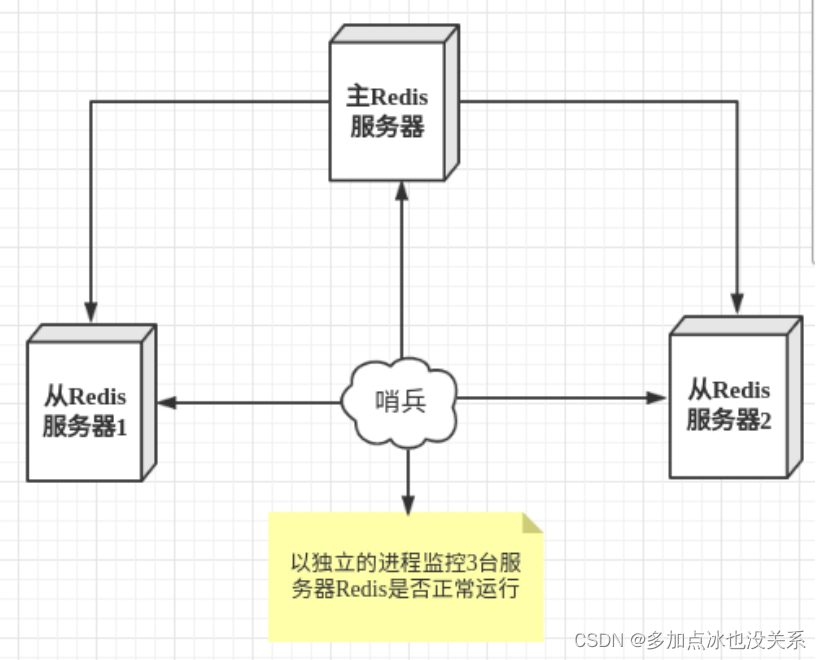
La sentinelle a ici deux fonctions
- En envoyant des commandes, le serveur Redis revient pour surveiller son état d'exécution, y compris le serveur maître et les serveurs esclaves.
- Lorsque Sentinel détecte que le maître est en panne, il bascule automatiquement l'esclave sur le maître, puis avertit les autres serveurs esclaves via le mode de publication et d'abonnement, modifie le fichier de configuration et les laisse changer d'hôte.
Cependant, des problèmes peuvent survenir lorsqu'un processus sentinelle surveille le serveur Redis. Pour cette raison, nous pouvons utiliser plusieurs sentinelles pour la surveillance. Chaque sentinelle sera également surveillée, formant ainsi un mode multi-sentinelle.
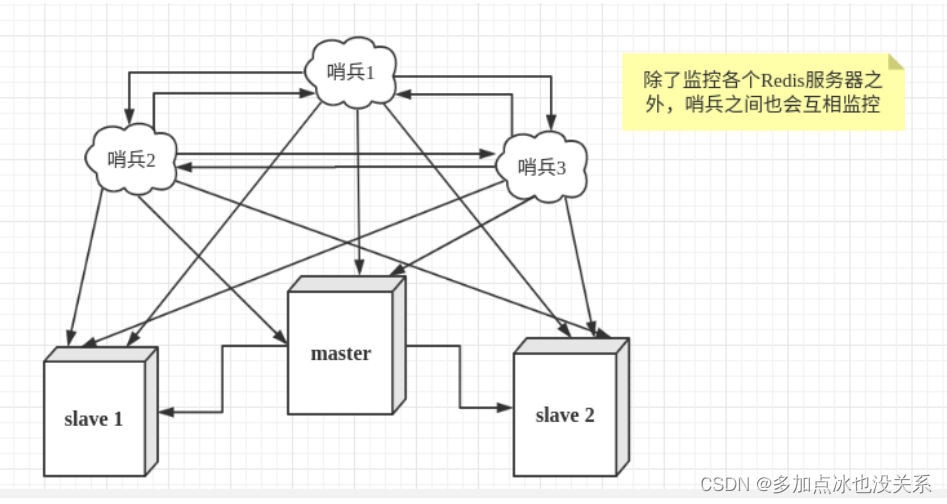
Supposons que le serveur principal est en panne et que Sentinel 1 détecte ce résultat en premier. Le système n'effectuera pas immédiatement le processus de basculement. C'est simplement que Sentinel 1 croit subjectivement que le serveur principal n'est pas disponible. Ce phénomène devient un phénomène subjectif hors ligne . Lorsque les sentinelles suivantes détectent également que le serveur principal est indisponible et que le nombre atteint une certaine valeur, un vote aura lieu entre les sentinelles. Le résultat du vote sera initié par une sentinelle pour effectuer une opération de basculement. Une fois le changement réussi, chaque sentinelle utilisera le mode publication-abonnement pour basculer le serveur esclave qu'elle surveille vers l'hôte. Ce processus est appelé objectif hors ligne .
Test de configuration
1. Ajustez la structure, 6379 apporte 80 et 81
2. Créez un nouveau fichier sentinel.conf dans le répertoire personnalisé /myredis. Assurez-vous que le nom est correct.
3. Configurez la sentinelle et remplissez le contenu
- nom d'hôte surveillé par le moniteur sentinelle 127.0.0.1 6379 1
- Le dernier chiffre 1 ci-dessus signifie qu'après que l'hôte ait raccroché, l'esclave votera pour voir qui prendra la relève en tant qu'hôte. Après avoir obtenu le nombre de voix, l'esclave deviendra l'hôte.
4. Démarrez Sentinelle
- Redis-sentinel /myredis/sentinel.conf
- Les répertoires ci-dessus sont configurés en fonction de leurs conditions réelles et les répertoires peuvent être différents.
5. Démonstration maître-esclave normale
6. Le Master d'origine est en panne.
7. Votez pour une nouvelle élection
8. Redémarrez l'opération maître-esclave et vérifiez la réplication des informations.
9. Question : Si le maître précédent est redémarré, y aura-t-il un conflit entre les deux maîtres ? Quand je suis revenu avant, je ne pouvais être que mon petit frère.
Avantages et inconvénients du mode sentinelle
avantage
- Le mode cluster Sentinel est basé sur le mode maître-esclave. Tous les avantages du mode maître-esclave sont également disponibles dans le mode Sentinel.
- Le maître et l'esclave peuvent être commutés, les défauts peuvent être transférés et la disponibilité du système est meilleure.
- Le mode Sentinel est une mise à niveau du mode maître-esclave. Le système est plus robuste et offre une plus grande disponibilité.
défaut
- Il est difficile pour Redis de prendre en charge l'expansion en ligne, et l'expansion en ligne deviendra très compliquée lorsque la capacité du cluster atteindra la limite supérieure.
- La configuration pour implémenter le mode sentinelle n’est pas simple, on peut même dire qu’elle est un peu lourde.
Instructions de configuration de Sentinelle
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都
要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同
步,这个数字越小,完成failover所需的时间就越长,
但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。
可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的
master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超
时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮
件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执
行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等
等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常
运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果
sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执
行的,否则sentinel无法正常启动成功。
#通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master
地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的
slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
10. Pénétration du cache et avalanche
L'utilisation du cache Redis améliore considérablement les performances et l'efficacité des applications, notamment dans les requêtes de données. Mais en même temps, cela pose également certains problèmes. Parmi eux, le problème le plus critique est celui de la cohérence des données. À proprement parler, ce problème n'a pas de solution. Si les exigences de cohérence des données sont très élevées, la mise en cache ne peut pas être utilisée.
D'autres problèmes typiques sont la pénétration du cache, l'avalanche de cache et la panne du cache. À l’heure actuelle, l’industrie dispose également de solutions relativement populaires.
1. Pénétration du cache
concept
Le concept de pénétration du cache est très simple : l'utilisateur souhaite interroger une donnée et constate que la base de données mémoire Redis ne l'a pas, c'est-à-dire que le cache n'atteint pas, il interroge donc la base de données de la couche de persistance. Il s’est avéré qu’il n’y en avait pas, cette requête a donc échoué. Lorsqu'il y a de nombreux utilisateurs, le cache ne fonctionne pas, ils demandent donc tous la base de données de la couche de persistance. Cela mettra beaucoup de pression sur la base de données de la couche de persistance, ce qui équivaut à une pénétration du cache.
solution
filtre de floraison
Le filtre Bloom est une structure de données qui stocke tous les paramètres de requête possibles sous forme de hachage. Il est d'abord vérifié au niveau de la couche de contrôle et rejeté s'ils ne correspondent pas, évitant ainsi la pression des requêtes sur le système de stockage sous-jacent ;
Mettre en cache les objets vides
Lorsque la couche de stockage manque, même l'objet vide renvoyé sera mis en cache et un délai d'expiration sera défini. L'accès ultérieur aux données sera obtenu à partir du cache, protégeant la source de données principale ;
Mais cette approche pose deux problèmes :
1. Si les valeurs nulles peuvent être mises en cache, cela signifie que le cache nécessite plus d'espace pour stocker plus de clés, car il peut y avoir de nombreuses clés de valeur nulle ;
2. Même si le délai d'expiration est défini sur la valeur nulle, les données de la couche de cache et de la couche de stockage resteront incohérentes pendant un certain temps, ce qui aura un impact sur les entreprises qui doivent maintenir la cohérence.
2. Panne du cache
Aperçu
Ici, vous devez faire attention à la différence avec la panne du cache. La panne du cache signifie qu'une clé est très chaude et transporte constamment une grande concurrence. La grande concurrence se concentre sur l'accès à ce point. Lorsque la clé échoue à ce moment-là, elle continue à faire face à une grande concurrence. traverse le cache et demande directement la base de données, ce qui revient à percer un trou dans une barrière.
Lorsqu'une clé expire, il y a un grand nombre de demandes d'accès simultanés. Ce type de données est généralement des données chaudes. Étant donné que le cache expire, la base de données sera accédée en même temps pour interroger les données les plus récentes, et le cache sera réécrit, ce qui entraînera une pression excessive sur la base de données en un instant.
solution
Définir les données du hotspot pour qu'elles n'expirent jamais
Du point de vue du cache, aucun délai d'expiration n'est défini, il n'y aura donc aucun problème causé par l'expiration de la clé du point d'accès.
Ajouter un verrou mutex
Verrouillage distribué : utilisez le verrouillage distribué pour garantir qu'un seul thread interroge le service back-end pour chaque clé en même temps. Les autres threads n'ont pas l'autorisation d'obtenir le verrou distribué, ils n'ont donc qu'à attendre. Cette méthode transfère la pression d’une concurrence élevée aux verrous distribués, ce qui pose un grand défi aux verrous distribués.
3. Avalanche de caches
concept
L'avalanche de cache fait référence à l'expiration centralisée des caches sur une certaine période de temps.
L'une des raisons de l'avalanche est que lorsque j'écris cet article, il est presque minuit sur Double 12, et il y aura bientôt une vague d'achats de panique.Cette vague de produits sera mise en cache dans un temps relativement concentré. Supposons que le cache dure une heure. . Puis à une heure du matin, le cache de ce lot de produits a expiré. Les requêtes d'accès à ce lot de produits tombent toutes sur la base de données, ce qui va générer des pics de pression périodiques pour la base de données. En conséquence, toutes les demandes atteindront la couche de stockage et le nombre d'appels vers la couche de stockage augmentera considérablement, provoquant également le blocage de la couche de stockage.
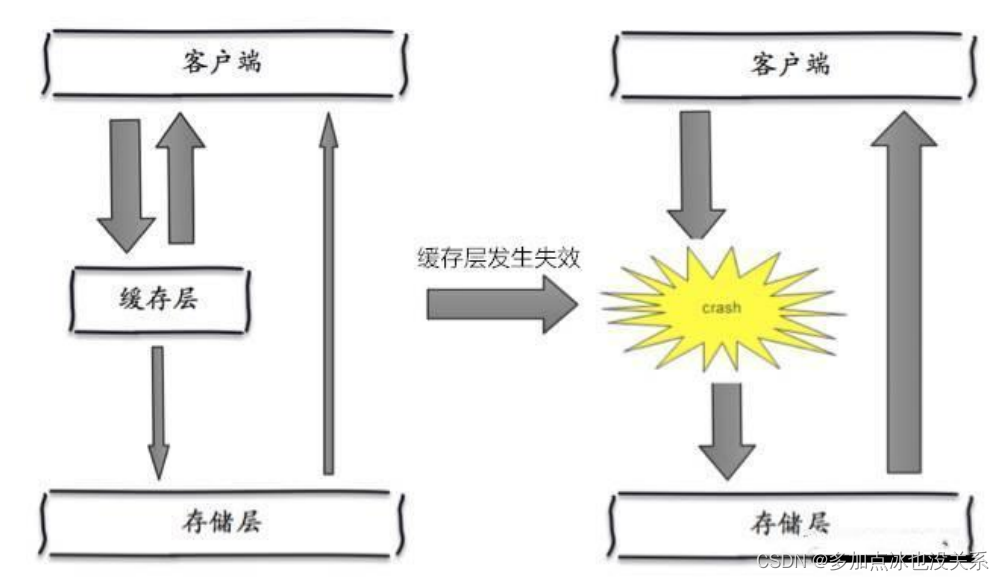
En fait, l'expiration centralisée n'est pas très fatale. Une avalanche de cache encore plus fatale se produit lorsqu'un nœud du serveur de cache tombe en panne ou est déconnecté du réseau. En raison de l'avalanche naturelle de caches, les caches doivent être créés de manière intensive pendant une certaine période de temps, pendant laquelle la base de données peut également résister à la pression. Ce n'est rien de plus qu'une pression périodique sur la base de données. Le temps d'arrêt du nœud de service de cache exercera une pression imprévisible sur le serveur de base de données et il est très probable que la base de données soit submergée en un instant.
solution
Redis haute disponibilité
Le sens de cette idée est que puisque Redis peut échouer, alors j'ajoute quelques Redis supplémentaires pour que les autres puissent continuer à fonctionner après l'échec de l'un d'entre eux. En fait, c'est un cluster.
Déclassement de limitation de courant
L'idée de cette solution est de contrôler le nombre de threads qui lisent la base de données et écrivent le cache via des verrous ou des files d'attente après l'expiration du cache. Par exemple, un seul thread est autorisé à interroger les données et à écrire dans le cache pour une certaine clé, tandis que les autres threads attendent.
Échauffement des données
La signification du chauffage des données est qu'avant le déploiement formel, j'accède d'abord aux données possibles à l'avance, afin que certaines données accessibles en grande quantité soient chargées dans le cache. Déclenchez manuellement le chargement de différentes clés dans le cache avant qu'un accès simultané important ne se produise et définissez différents délais d'expiration pour rendre les points temporels d'invalidation du cache aussi uniformes que possible.
11. Jedi
Jedis est l'outil de développement de connexion Java officiellement recommandé pour Redis. Pour bien utiliser le middleware Redis dans le développement Java, vous devez être familier avec Jedis pour écrire du beau code.
1. Testez China Unicom
1. Créez un nouveau projet Maven ordinaire
2. Importez les dépendances Redis !
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
3. Écrivez le code de test
package com.kuang.ping;
import redis.clients.jedis.Jedis;
public class Ping {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: "+jedis.ping());
}
}
4. Démarrez le service Redis
5. Démarrez le test et les résultats
连接成功
服务正在运行: PONG
2. API couramment utilisées
Opérations de base
public class TestPassword {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
//验证密码,如果没有设置密码这段代码省略
// jedis.auth("password");
jedis.connect(); //连接
jedis.disconnect(); //断开连接
jedis.flushAll(); //清空所有的key
}
}
Commandes pour les opérations clés
public class TestKey {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
System.out.println("清空数据:"+jedis.flushDB());
System.out.println("判断某个键是否存在:"+jedis.exists("username"));
System.out.println("新增<'username','kuangshen'>的键值对:"+jedis.set("username", "kuangshen"));
System.out.println("新增<'password','password'>的键值对:"+jedis.set("password", "password"));
System.out.print("系统中所有的键如下:");
Set<String> keys = jedis.keys("*");
System.out.println(keys);
System.out.println("删除键password:"+jedis.del("password"));
System.out.println("判断键password是否存在:"+jedis.exists("password"));
System.out.println("查看键username所存储的值的类型:"+jedis.type("username"));
System.out.println("随机返回key空间的一个:"+jedis.randomKey());
System.out.println("重命名key:"+jedis.rename("username","name"));
System.out.println("取出改后的name:"+jedis.get("name"));
System.out.println("按索引查询:"+jedis.select(0));
System.out.println("删除当前选择数据库中的所有key:"+jedis.flushDB());
System.out.println("返回当前数据库中key的数目:"+jedis.dbSize());
System.out.println("删除所有数据库中的所有key:"+jedis.flushAll());
}
}
Commandes pour les opérations sur les chaînes
public class TestString {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========增加数据===========");
System.out.println(jedis.set("key1","value1"));
System.out.println(jedis.set("key2","value2"));
System.out.println(jedis.set("key3", "value3"));
System.out.println("删除键key2:"+jedis.del("key2"));
System.out.println("获取键key2:"+jedis.get("key2"));
System.out.println("修改key1:"+jedis.set("key1", "value1Changed"));
System.out.println("获取key1的值:"+jedis.get("key1"));
System.out.println("在key3后面加入值:"+jedis.append("key3", "End"));
System.out.println("key3的值:"+jedis.get("key3"));
System.out.println("增加多个键值对:"+jedis.mset("key01","value01","key02","value02","key03","value03"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03","key04"));
System.out.println("删除多个键值对:"+jedis.del("key01","key02"));
System.out.println("获取多个键值对:"+jedis.mget("key01","key02","key03"));
jedis.flushDB();
System.out.println("===========新增键值对防止覆盖原先值==============");
System.out.println(jedis.setnx("key1", "value1"));
System.out.println(jedis.setnx("key2", "value2"));
System.out.println(jedis.setnx("key2", "value2-new"));
System.out.println(jedis.get("key1"));
System.out.println(jedis.get("key2"));
System.out.println("===========新增键值对并设置有效时间=============");
System.out.println(jedis.setex("key3", 2, "value3"));
System.out.println(jedis.get("key3"));
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(jedis.get("key3"));
System.out.println("===========获取原值,更新为新值==========");
System.out.println(jedis.getSet("key2", "key2GetSet"));
System.out.println(jedis.get("key2"));
System.out.println("获得key2的值的字串:"+jedis.getrange("key2", 2,4));
}
}
Liste des commandes d'opération
public class TestList {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("===========添加一个list===========");
jedis.lpush("collections", "ArrayList", "Vector", "Stack","HashMap", "WeakHashMap", "LinkedHashMap");
jedis.lpush("collections", "HashSet");
jedis.lpush("collections", "TreeSet");
jedis.lpush("collections", "TreeMap");
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));//-1代表倒数第一个元素,-2代表倒数第二个元素,end为-1表示查询全部
System.out.println("collections区间0-3的元素:"+jedis.lrange("collections",0,3));
System.out.println("===============================");
// 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈
System.out.println("删除指定元素个数:"+jedis.lrem("collections", 2,"HashMap"));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("删除下表0-3区间之外的元素:"+jedis.ltrim("collections", 0, 3));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("collections列表出栈(左端):"+jedis.lpop("collections"));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("collections添加元素,从列表右端,与lpush相对应:"+jedis.rpush("collections", "EnumMap"));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("collections列表出栈(右端):"+jedis.rpop("collections"));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("修改collections指定下标1的内容:"+jedis.lset("collections", 1, "LinkedArrayList"));
System.out.println("collections的内容:"+jedis.lrange("collections",0, -1));
System.out.println("===============================");
System.out.println("collections的长度:"+jedis.llen("collections"));
System.out.println("获取collections下标为2的元素:"+jedis.lindex("collections", 2));
System.out.println("===============================");
jedis.lpush("sortedList", "3","6","2","0","7","4");
System.out.println("sortedList排序前:"+jedis.lrange("sortedList", 0,-1));
System.out.println(jedis.sort("sortedList"));
System.out.println("sortedList排序后:"+jedis.lrange("sortedList", 0,-1));
}
}
Commandes d'opération pour Set
public class TestSet {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
System.out.println("============向集合中添加元素(不重复)============");
System.out.println(jedis.sadd("eleSet","e1","e2","e4","e3","e0","e8","e7","e5"));
System.out.println(jedis.sadd("eleSet", "e6"));
System.out.println(jedis.sadd("eleSet", "e6"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("删除一个元素e0:"+jedis.srem("eleSet", "e0"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("删除两个元素e7和e6:"+jedis.srem("eleSet","e7","e6"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("随机的移除集合中的一个元素:"+jedis.spop("eleSet"));
System.out.println("随机的移除集合中的一个元素:"+jedis.spop("eleSet"));
System.out.println("eleSet的所有元素为:"+jedis.smembers("eleSet"));
System.out.println("eleSet中包含元素的个数:"+jedis.scard("eleSet"));
System.out.println("e3是否在eleSet中:"+jedis.sismember("eleSet","e3"));
System.out.println("e1是否在eleSet中:"+jedis.sismember("eleSet","e1"));
System.out.println("e1是否在eleSet中:"+jedis.sismember("eleSet","e5"));
System.out.println("=================================");
System.out.println(jedis.sadd("eleSet1","e1","e2","e4","e3","e0","e8","e7","e5"));
System.out.println(jedis.sadd("eleSet2","e1","e2","e4","e3","e0","e8"));
System.out.println("将eleSet1中删除e1并存入eleSet3中:"+jedis.smove("eleSet1", "eleSet3", "e1"));//移到集合元素
System.out.println("将eleSet1中删除e2并存入eleSet3中:"+jedis.smove("eleSet1", "eleSet3", "e2"));
System.out.println("eleSet1中的元素:"+jedis.smembers("eleSet1"));
System.out.println("eleSet3中的元素:"+jedis.smembers("eleSet3"));
System.out.println("============集合运算=================");
System.out.println("eleSet1中的元素:"+jedis.smembers("eleSet1"));
System.out.println("eleSet2中的元素:"+jedis.smembers("eleSet2"));
System.out.println("eleSet1和eleSet2的交集:"+jedis.sinter("eleSet1","eleSet2"));
System.out.println("eleSet1和eleSet2的并集:"+jedis.sunion("eleSet1","eleSet2"));
System.out.println("eleSet1和eleSet2的差集:"+jedis.sdiff("eleSet1","eleSet2"));//eleSet1中有,eleSet2中没有
jedis.sinterstore("eleSet4","eleSet1","eleSet2");//求交集并将交集保存到dstkey的集合
System.out.println("eleSet4中的元素:"+jedis.smembers("eleSet4"));
}
}
Commandes d'opération pour le hachage
public class TestHash {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
Map<String,String> map = new HashMap<>();
map.put("key1","value1");
map.put("key2","value2");
map.put("key3","value3");
map.put("key4","value4");
//添加名称为hash(key)的hash元素
jedis.hmset("hash",map);
//向名称为hash的hash中添加key为key5,value为value5元素
jedis.hset("hash", "key5", "value5");
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));//return Map<String,String>
System.out.println("散列hash的所有键为:"+jedis.hkeys("hash"));//returnSet<String>
System.out.println("散列hash的所有值为:"+jedis.hvals("hash"));//returnList<String>
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:"+jedis.hincrBy("hash", "key6", 6));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:"+jedis.hincrBy("hash", "key6", 3));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("删除一个或者多个键值对:"+jedis.hdel("hash","key2"));
System.out.println("散列hash的所有键值对为:"+jedis.hgetAll("hash"));
System.out.println("散列hash中键值对的个数:"+jedis.hlen("hash"));
System.out.println("判断hash中是否存在key2:"+jedis.hexists("hash","key2"));
System.out.println("判断hash中是否存在key3:"+jedis.hexists("hash","key3"));
System.out.println("获取hash中的值:"+jedis.hmget("hash","key3"));
System.out.println("获取hash中的值:"+jedis.hmget("hash","key3","key4"));
}
}
3. Affaires
Opérations de base
package com.kuang.multi;
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class TestMulti {
public static void main(String[] args) {
//创建客户端连接服务端,redis服务端需要被开启
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello", "world");
jsonObject.put("name", "java");
//开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
try{
//向redis存入一条数据
multi.set("json", result);
//再存入一条数据
multi.set("json2", result);
//这里引发了异常,用0作为被除数
int i = 100/0;
//如果没有引发异常,执行进入队列的命令
multi.exec();
}catch(Exception e){
e.printStackTrace();
//如果出现异常,回滚
multi.discard();
}finally{
System.out.println(jedis.get("json"));
System.out.println(jedis.get("json2"));
//最终关闭客户端
jedis.close();
}
}
}
12. Intégration SpringBoot
1. Utilisation de base
Aperçu
Dans SpringBoot, les méthodes fournies par RedisTemplate sont généralement utilisées pour faire fonctionner Redis. Alors, quelles sont les étapes nécessaires pour intégrer Redis à l'aide de SpringBoot.
1. JedisPoolConfig (il s'agit de configurer le pool de connexions)
2. RedisConnectionFactory Ceci sert à configurer les informations de connexion. RedisConnectionFactory est ici une interface. Nous devons utiliser sa classe d'implémentation. Les quatre modèles d'usine suivants sont fournis dans la solution SpringD Data Redis :
- JredisConnectionFactory
- JedisConnectionFactory
- LettuceConnectionFactory
- SrpConnectionFactory
3. Opérations de base de RedisTemplate
Importer les dépendances
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
configuration yaml
spring:
redis:
host: 127.0.0.1
port: 6379
password: 123456
jedis:
pool:
max-active: 8
max-wait: -1ms
max-idle: 500
min-idle: 0
lettuce:
shutdown-timeout: 0ms
test
@SpringBootTest
class SpringbootRedisApplicationTests {
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("myKey","myValue");
System.out.println(redisTemplate.opsForValue().get("myKey"));
}
}
2. Outils d'emballage
1. Créez un nouveau projet SpringBoot
2. Importez le lanceur Redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3. Configurez Redis, vous pouvez afficher l'analyse RedisProperties
# Redis服务器地址
spring.redis.host=127.0.0.1
# Redis服务器连接端口
spring.redis.port=6379
4. Analyser la classe de configuration automatique RedisAutoConfiguration
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({
LettuceConnectionConfiguration.class,JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
Comme le montre le code source, SpringBoot génère automatiquement un RedisTemplate et un
StringRedisTemplate pour nous dans le conteneur.
Cependant, le type générique de ce RedisTemplate est <Object, Object>, ce qui n'est pas pratique pour écrire du code et nécessite d'écrire beaucoup de code de conversion de type ; nous avons besoin d'un RedisTemplate dont le type générique est sous la forme de <String, Object>.
De plus, ce RedisTemplate ne définit pas la méthode de sérialisation de la clé et de la valeur lorsque les données sont stockées dans Redis.
Après avoir vu cette annotation @ConditionalOnMissingBean, vous savez que s'il existe un objet RedisTemplate dans le conteneur Spring, ce RedisTemplate automatiquement configuré ne sera pas instancié. Par conséquent, nous pouvons directement écrire nous-mêmes une classe de configuration pour configurer RedisTemplate.
5. La configuration automatique n'étant pas facile à utiliser, reconfigurez un RedisTemplate.
package com.kuang.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import
org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings("all")