compression d'image traditionnelle
Brève description
Les premières méthodes de compression d'image utilisaient directement le codage entropique pour réduire la redondance de codage de l'image afin d'obtenir une compression, comme le codage de Huffman, le codage arithmétique et le codage arithmétique binaire adaptatif au contexte.
À la fin des années 1960, une méthode de compression basée sur la transformation d'image a été proposée. Cette méthode de compression convertit l'image du domaine spatial vers le domaine fréquentiel et l'encode dans le domaine fréquentiel. Les méthodes de transformation utilisées dans le codage par transformation comprennent principalement la transformée de Fourier, la transformée de Hadamard et la transformée en cosinus discret (Discrete Cosine Transform, DCT)
En plus de supprimer la redondance des données grâce à des techniques de codage et de transformation entropiques, des techniques de prédiction et de quantification ont ensuite été proposées pour réduire la redondance spatiale et la redondance psychovisuelle des images. La méthode de compression d'image la plus populaire, JPEG, est une méthode de compression d'image réussie. Ses avantages incluent que le taux de compression et la fidélité de l'image peuvent être ajustés dans une large plage, peuvent être sélectionnés en fonction de la situation d'application et de la complexité de mise en œuvre de la compression et la restauration sont modérées et le coût du matériel n'est pas élevé. Une autre méthode de compression d'image célèbre, JPEG 2000, est une amélioration de la méthode de compression JPEG. Dans des conditions de faible débit binaire, JPEG 2000 bénéficiera d'avantages évidents par rapport au JPEG, mais dans des conditions de débit binaire élevé, il ne peut atteindre que des performances comparables. Les codecs vidéo modernes, tels que HEVC et VVC, utilisent des filtres de prédiction intra et de boucle pour le codage intra, et ces deux composants sont également utilisés dans la méthode de compression d'image BPG pour réduire davantage la redondance spatiale et améliorer la qualité des images reconstruites.
Les premières méthodes de compression effectuaient directement la compression via le codage entropique ou le codage par transformation, et le codage entropique et le codage par transformation ont été considérés comme des liens indispensables dans la compression d'images. Les méthodes traditionnelles de compression d'images se composent de plusieurs modules de base, à savoir la transformation, la quantification et le codage entropique. Un codage de transformation bien conçu convertit le signal d'image en coefficients compacts et non corrélés, élimine la redondance psychovisuelle grâce à la quantification et facilite le codage entropique. Enfin, il est codé. dans le flux de code pour être transmis ou stocké via un codage entropique. Les méthodes traditionnelles classiques de compression d'images incluent principalement JPEG, JPEG2000 et BPG. Nous les trierons ensuite ainsi que leurs améliorations respectives.
JPEG
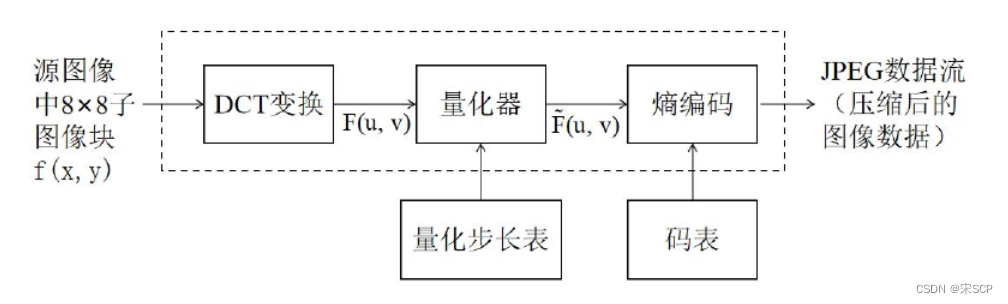
JPEG est le format d'image le plus courant. Le processus de compression de la norme de compression JPEG est illustré dans la figure. Il est divisé en quatre étapes. Tout d'abord, effectuez le prétraitement des données et changez l'image du mode couleur RVB au mode couleur YUV. Entre RVB et La conversion YUV entre codecs n'est pas incluse dans le codec, mais est effectuée par l'application avant l'encodage et après le décodage selon les besoins. Après la conversion, un échantillonnage des données doit être effectué. Généralement, le taux d'échantillonnage est de 2 : 1 : 1. Étant donné qu'une seule ligne de données sur deux est conservée après l'exécution de ce travail, la quantité de données d'image après l'échantillonnage sera compressée. à la moitié de la taille originale. La deuxième étape consiste à effectuer une transformée en cosinus discrète (DCT) bidimensionnelle sur le sous-bloc. La transformée DCT transforme le signal d'image dans le domaine fréquentiel, sépare les informations haute fréquence et basse fréquence, puis compresse les hautes fréquences. -Informations de fréquence pour atteindre l'objectif de compression d'image. Tout d'abord, l'image doit être divisée en plusieurs matrices, puis la transformation DCT est effectuée sur chaque matrice. La composante continue doit être utilisée avec la modulation différentielle par impulsions codées (DPCM) pour compresser la composante continue entre les blocs DCT adjacents. Au lieu de compresser directement l'image Valeur CC. Étant donné que les livres de codes utilisés dans le processus de codage entropique sont tous des nombres entiers, les coefficients du domaine fréquentiel après transformation DCT doivent être quantifiés. Il s'agit de la troisième étape de la compression. L'opération de quantification convertit les coefficients du domaine fréquentiel en nombres entiers.
La formule de l’opération de quantification est la suivante :
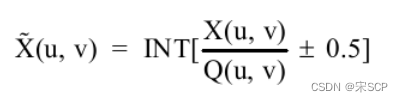
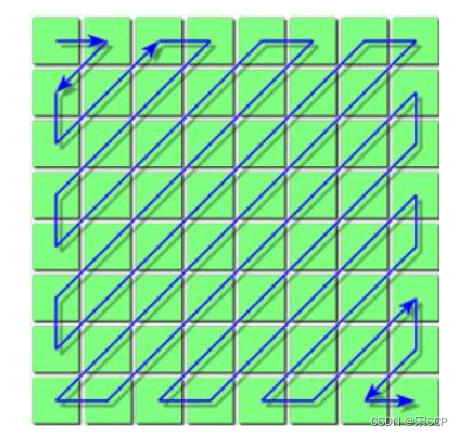
Parmi eux, X(u,v) représente la matrice d'image à quantifier, Q(u,v) est la matrice de coefficient de quantification et ±0,5 est pour l'arrondi. Afin de réduire la redondance visuelle, la norme de compression JPEG conçoit une matrice de coefficients de quantification spéciale pour bien conserver les informations à basse fréquence et éliminer davantage de détails à haute fréquence (semblables au bruit), car les gens sont moins sensibles à la perte d'informations dans les hautes fréquences. -partie fréquence. La norme de compression JPEG fournit deux matrices de coefficients de quantification standard pour traiter respectivement les données de luminance et les données de chrominance. Après quantification, la plupart des valeurs de la matrice des coefficients du domaine fréquentiel deviendront 0, ce qui est très propice au codage entropique ultérieur. Avant d'entrer dans l'étape suivante, il reste une dernière étape à effectuer dans la quantification de la matrice, qui consiste à convertir le bidimensionnel quantifié La matrice est convertie en un tableau unidimensionnel. Le coefficient DC est le premier coefficient dans le coin supérieur gauche de la matrice des coefficients du domaine fréquentiel. Il est prédit à l'aide du coefficient DC de la matrice de coefficients précédente. Pour le coefficient AC, JPEG utilise un ordre de balayage en zigzag, comme indiqué sur la figure. Cet ordre de balayage est utilisé pour permettre de rassembler davantage de valeurs 0 pour faciliter le codage ultérieur.Après cette transformation d'ordre, la matrice finale des coefficients du domaine fréquentiel devient un tableau d'entiers.
La quatrième étape est le codage entropique, y compris le codage de Huffman et le codage arithmétique binaire adaptatif. Les deux méthodes de codage ont leurs tables de codes correspondantes. Les tables de codes sont générées sur la base d'un grand nombre de résultats de tests d'images réels. Lors du codage, il suffit de consulter directement la table.
JPEG a également ses inconvénients. La compression JPEG introduira inévitablement divers artefacts, causés par la perte d'informations à haute fréquence pendant le processus de compression. En particulier à des taux de compression élevés, une distorsion se produira également, ce qui affectera grandement la qualité de l'expérience, de nombreux des méthodes ont été proposées pour ce problème, telles que les méthodes traditionnelles basées sur des filtres. D'autres appliquent un codage clairsemé pour récupérer des images compressées. Ces méthodes produisent souvent des images plus nettes avec une entrée compressée, mais elles sont souvent trop lentes et les résultats sont souvent accompagnés d'artefacts supplémentaires. Il existe donc de nombreuses méthodes basées sur l’apprentissage profond pour supprimer les artefacts de compression.
JPEG2000
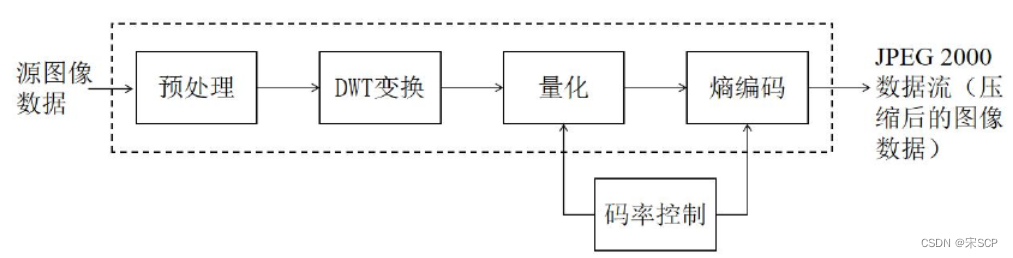
La norme de compression JPEG 2000 comporte également quatre étapes. Le prétraitement des données comprend le blocage de l'image, la normalisation du décalage des données et la transformation des couleurs. L'image est divisée en un certain nombre de blocs rectangulaires qui ne se chevauchent pas. La taille des blocs est arbitraire. Le décalage des données consiste à décaler la valeur du pixel symétriquement à 0, et la normalisation vise à faciliter la transformation en ondelettes discrète ultérieure (Transformation en ondelettes discrètes, DWT). Pour supprimer la corrélation entre les composants et améliorer l'efficacité de la compression, il est nécessaire d'effectuer la transformation des composants correspondants sur l'image. La transformation des couleurs convertit également l'image de la gamme de couleurs RVB en la gamme de couleurs YUV. JPEG 2000 utilise DWT. Une fois l'image transformée par DWT, la matrice de coefficients doit également être quantifiée pour faciliter le codage entropique, afin d'atteindre l'objectif de compression d'image. JPEG 2000 utilise une quantification scalaire uniforme et l'entropie est effectuée sur l'image quantifiée. matrice de coefficients. Codage, le codage entropique utilise un codage par bloc de code intégré tronqué optimal (codage par bloc intégré avec troncature optimisée, EBCOT)
JPEG 2000 présente des avantages évidents par rapport au JPEG. En tant qu'amélioration du JPEG, son taux de compression peut atteindre environ 30 % de plus que celui du JPEG, et JPEG 2000 peut prendre en charge la compression différentielle pour les zones d'intérêt, et peut également effectuer une transmission progressive, en transmettant d'abord le contour de l'image, puis les données sont progressivement transmises pour améliorer continuellement la qualité de l'image, permettant à l'image d'être affichée du flou au clair. Le codage basé sur les régions d’intérêt revêt une importance directrice importante dans le domaine de la compression d’images. Cependant, son inconvénient est qu'il entraînera un certain degré de distorsion du flou, car les hautes fréquences seront atténuées dans une certaine mesure pendant le processus de codage. De plus, JPEG 2000 prend en charge à la fois la compression avec perte et la compression sans perte. La compression sans perte de JPEG 2000 peut atteindre un taux de compression plus élevé que JPEG, mais les opérations de mise en œuvre de JPEG 2000 sont toutes dans le domaine des nombres réels, donc sa vitesse de décodage est plus lente que JPEG : il en existe beaucoup, ce qui fait qu'il n'est pas privilégié tant du côté client que du côté serveur, ce qui limite sa promotion vigoureuse.
Méthode de compression basée sur le deep learning
Le codage traditionnel par compression d'images s'est développé rapidement et est largement utilisé dans la pratique, mais il a également atteint une période de goulot d'étranglement en termes d'amélioration des performances. Dans le même temps, le codage de compression d'image traditionnel est composé de modules individuels connectés, tels qu'un module de transformation, un module de quantification et un module de codage entropique. Ces modules sont optimisés individuellement manuellement et conçus sans optimisation conjointe globale. Deuxièmement, l'évaluation traditionnelle de la qualité du codage cible généralement certains indicateurs de performance objectifs. Il est difficile de répondre aux exigences d'indicateurs de qualité plus subjectifs et d'indicateurs de qualité sémantique, et ne peut pas obtenir d'informations sémantiques approfondies sur l'image. À cet égard, le codage traditionnel par compression d'image est n'est plus en mesure de répondre aux exigences modernes.L'apprentissage profond et la vision par ordinateur se développent et progressent constamment et peuvent être utilisés comme une nouvelle façon de résoudre le problème de la compression et du codage des images. La compression d'images de bout en bout peut optimiser conjointement divers modules de codage d'images et laisser les données parler d'elles-mêmes.
Le développement historique et la situation actuelle de la compression d'images basée sur l'apprentissage profond peuvent être divisés en deux catégories : l'une est le développement de cadres de compression d'images basés sur différents réseaux neuronaux, et l'autre est le module de transformation d'image, le module de quantification, le module d'encodage, etc. .en compression d'images sous deep learning.Développement de modules de base.
Développement d'un framework de compression d'images basé sur différents réseaux de neurones
Selon les différents réseaux utilisés en deep learning, la compression d'images basée sur le deep learning peut être divisée en trois grandes catégories : la première est la compression d'images basée sur des réseaux de neurones convolutifs, la seconde est la compression d'images basée sur des réseaux de neurones récurrents et la dernière est Compression d'images basée sur des réseaux adverses génératifs. Ils sont présentés séparément ci-dessous.
CNN
Le premier est la compression d’images basée sur le réseau CNN. Le réseau CNN a été largement développé et appliqué dans le domaine du traitement d'images. Il présente les caractéristiques de perception partielle et de partage de poids, ce qui peut réduire la quantité de paramètres requis pour la formation du réseau. Dans la compression d'images traditionnelle, les chercheurs optimisent manuellement la transformation, la quantification, le codage et d'autres modules d'images grâce à l'expérience ou à des expériences, tandis que la compression d'images basée sur l'apprentissage en profondeur peut être optimisée conjointement. Mais la compression d'image de bout en bout est également difficile.Le premier problème à résoudre est le problème non différenciable de la quantification d'image. Dans la compression d'image traditionnelle, les données sont souvent quantifiées en dérivant directement la matrice de coefficients, puis en l'arrondissant.
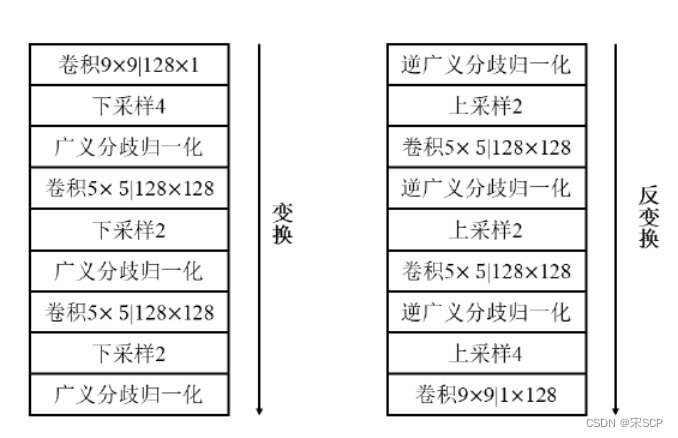
Des chercheurs tels que Ballé [1] ont résolu ce problème en ajoutant du bruit uniformément réparti. L'ajout de bruit rend les données continuellement différenciables sans modifier les résultats de quantification d'origine. Ils ont utilisé un réseau CNN pour traiter les images. Le réseau de codage du réseau comprenait trois grandes couches convolutives. Chaque couche était composée d'une couche convolutive, d'un sous-échantillonnage et d'une normalisation généralisée des bifurcations. Le réseau de décodage est similaire au réseau de codage. L'effet de codage obtenu par les recherches de Ballé et al. est proche de celui de JPEG 2000. Il s'agit d'un travail pionnier sur le réseau CNN et la compression d'images, qui a jeté les bases d'une compression d'images ultérieure basée sur le réseau CNN. Le cadre de codage d'images basé sur le réseau CNN proposé par Ballé est présenté dans la figure ci-dessous. Sur la base de ce cadre, Ballé [2] et al. ont ajouté un réseau super-prior pour faire des estimations raisonnables des données potentielles. Les informations contextuelles dans la compression d'images sont très importantes pour l'encodage et le décodage des images.
Afin de compenser le manque d'informations contextuelles, Minnen [3] a introduit le réseau contextuel pour estimer plus précisément les données potentielles, amélioré le réseau de super-codage et a été le premier à résoudre le problème du bruit de signal de crête d'image. Recherche sur un codage de compression d'apprentissage profond qui est meilleur que BPG en termes de rapport et de similarité structurelle de l'image.
Afin d'améliorer l'effet de reconstruction de la compression d'image, des chercheurs tels que Jiang [4] ont proposé un nouveau cadre de compression d'image basé sur CNN. Dans ce cadre, il existe deux réseaux de neurones convolutifs, connectés respectivement à l'encodeur et au décodeur, puis le deux réseaux sont optimisés de manière unifiée. Le réseau neuronal du côté codage extrait les informations efficaces des données d'image et le réseau neuronal du côté décodage reconstruit l'image. Cette étude atténue l'effet de blocage provoqué par la compression de l'image et est meilleure. que l’encodage JPEG.
Le framework de deep learning proposé par Toderici :
RNN
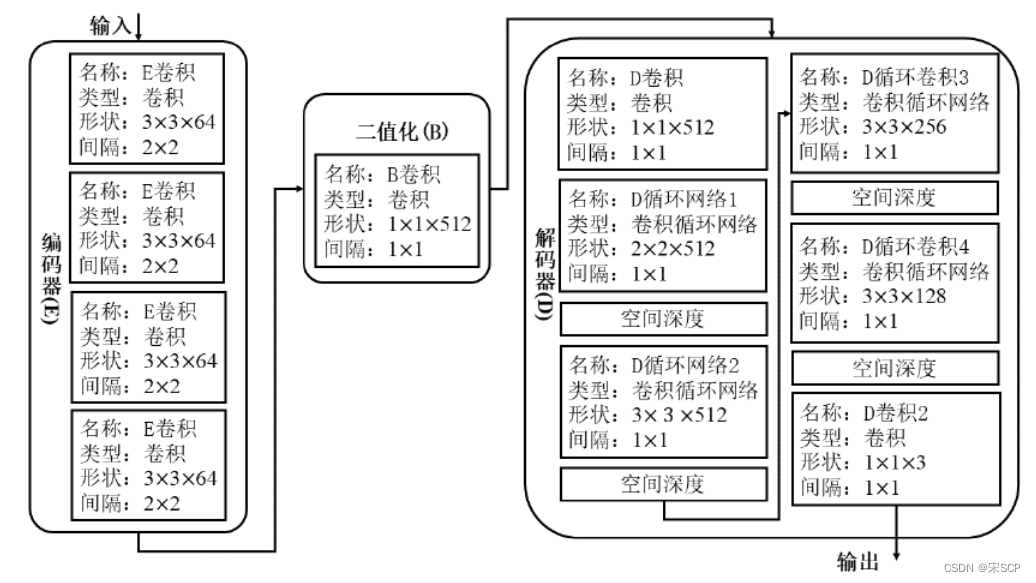
Codage de compression d'image de bout en bout avec des réseaux basés sur RNN. Le réseau RNN a une certaine fonction de mémoire et présente des avantages dans le traitement des signaux avec une forte dépendance au signal avant et après le traitement. Les neurones du réseau RNN sont non seulement connectés aux couches adjacentes, mais également connectés à eux-mêmes. Une méthode de compression d'image basée sur le réseau RNN proposée par Toderici[5] et al. Cette méthode utilise un réseau RNN itératif pour contrôler le débit de code et utilise un réseau résiduel pour améliorer la qualité de reconstruction de l'image. Plus précisément, elle comprend un réseau de codage, un réseau de binarisation et un réseau de décodage. L'effet de reconstruction est similaire à JPEG2000. Ces travaux ont ouvert la voie à une compression ultérieure d’images basée sur les réseaux RNN. Les chercheurs ultérieurs ont développé et étendu la compression d'images basée sur les réseaux RNN en introduisant des modules de codage entropique efficaces [6] et des modules d'allocation de débit de code [7]. L'effet de reconstruction d'image obtenu par certains réseaux a dépassé le BPG.
Le framework de deep learning proposé par Toderici :
CEPENDANT
L'essor du réseau GAN a également favorisé la recherche sur la compression d'images basée sur l'apprentissage profond. Le réseau GAN peut générer des images via le générateur et le discriminateur détermine si l'image générée est réelle. Rippel[8] a proposé une compression d'image basée sur le réseau GAN. La particularité de cette méthode est qu'elle utilise un réseau contradictoire génératif pour atteindre l'objectif de générer des réseaux de haute qualité à faible débit. Il s'agit du premier travail à utiliser un réseau contradictoire génératif pour la compression d'images. Ce framework obtient de bons résultats en termes de performances de compression d'image et de temps de compression.
Développement d'un module de base de compression d'images de bout en bout basé sur le deep learning
Le cadre de compression d'image de bout en bout traite le processus de compression d'image comme un réseau complet pour une optimisation conjointe. Ballé et Toderici et autres ont respectivement utilisé les réseaux CNN et RNN pour effectuer un travail de compression d'image de bout en bout, et le réseau GAN utilisé par Rippel est également un travail de compression d'image de bout en bout. Par conséquent, la compression d'images de bout en bout basée sur l'apprentissage profond est une solution plus couramment utilisée. Ce qui suit présentera en détail les travaux effectués par les chercheurs dans le domaine de la compression d'images de bout en bout.
Le processus de compression d'image traditionnel consiste à ce qu'une fois l'image prétraitée, elle passe ensuite par différents modules tels que le module de transformation, le module de quantification et le module d'encodage. Dans la compression d'image correspondante basée sur le deep learning, on trouve également des modules de transformation, des modules de quantification, des modules de codage, etc.
Développement de modules de transformation
L'étape de transformation dans la compression d'image traditionnelle transforme les données du domaine spatial de l'image en domaine fréquentiel ou dans d'autres domaines spatiaux pour obtenir l'effet de convergence énergétique des données d'image, éliminer les données sans importance et compresser le volume de données. Dans l'apprentissage profond, des couches convolutives en cascade sont utilisées pour transformer les images. Ballé [9] et al. ont proposé une transformation non linéaire basée sur le GDN, qui se compose de trois étapes : d'abord la convolution, puis le sous-échantillonnage et enfin effectuer la transformation GDN. Cette méthode réduit le nombre de mots de passe utilisés avec la même erreur de compression d'image que les méthodes de compression traditionnelles. Inspirés par l'idée de super-résolution d'image, Theis[10] et d'autres ont proposé un cadre d'encodeur automatique d'image avec perte. Ce cadre utilise des réseaux neuronaux convolutifs ordinaires pour réaliser la transformation d'image. Tout d'abord, les données de l'image sont prétraitées. L'image est ensuite convoluée. et sous-échantillonné, et finalement traité à l'aide de blocs résiduels. Afin d’extraire plus efficacement les informations sur les caractéristiques des images et de réduire la quantité de données, Zhao [11] et al. ont proposé un réseau FDNN pour extraire les caractéristiques des images. Le réseau FDNN utilise 8 couches convolutives pour traiter les données d'image. Afin d'augmenter le champ de réception, la taille du noyau de convolution utilisée dans la couche initiale et la dernière couche est de 9, et les couches ReLU sont intercalées au milieu pour augmenter la non-linéarité du réseau. En bref, la partie transformation de la compression d'image passe de la transformation d'opérations spatiales mathématiques traditionnelles à une convolution de réseau en cascade, atteignant finalement l'objectif d'extraire des informations de caractéristiques efficaces à partir de données dispersées.
Développement de modules quantitatifs
Dans le codage de compression d'image traditionnel, les données transformées sont ensuite quantifiées. Dans la compression d'images de bout en bout basée sur l'apprentissage profond, le problème de la non-différentiabilité de la quantification provoquée par la quantification est un problème clé qui doit être résolu. La solution proposée par Toderici[12] et d'autres est la quantification binaire. Cette méthode de quantification binaire génère d'abord une certaine quantité de sortie dans l'intervalle continu [−1,1], puis utilise l'expression à valeur réelle comme entrée pour obtenir -1. , 1 sortie discrète. La quantification binaire peut être directement sérialisée, ce qui est bénéfique pour la transmission des informations ; le taux de compression peut être contrôlé en limitant la tolérance sur les bits ; cela peut forcer le réseau à apprendre une représentation efficace de l'image. Afin de résoudre le problème du gradient zéro dans la quantification binaire, Rippel [8] et al. et Li [13] et al. ont introduit des fonctions de substitution dans la rétropropagation, et les fonctions de substitution sont différentiables. Ballé [9] et al. ont proposé d'ajouter un bruit uniforme additif pour remplacer la fonction d'arrondi originale afin de réaliser le processus de quantification et d'assurer une différentiabilité globale. Afin de résoudre le problème de la qualité de reconstruction d'image de la quantification entière, Agustsson [14] a proposé une méthode de quantification vectorielle pour quantifier au niveau de quantification requis en fonction d'une affectation douce scalaire ou vectorielle donnée. Des expériences ont prouvé que la quantification vectorielle offre de meilleures performances que la quantification scalaire traditionnelle.
Développement de modules de codage
Dans le codage de compression d'image traditionnel, le codage arithmétique ou le codage de Huffman est généralement utilisé pour supprimer la redondance des données quantifiées. Dans la compression d'images de bout en bout, Ballé [1] et al. ont proposé de construire un modèle d'entropie pour se rapprocher des bits requis pour les données d'expression potentielle quantifiées, jetant ainsi les bases du développement de modèles d'entropie ultérieurs. Dans le même temps, Theis[10] et d’autres ont utilisé le modèle gaussien comme estimation approximative, ce qui a effectivement amélioré les performances de la compression d’images de bout en bout basée sur l’apprentissage profond. Afin de réduire davantage la dépendance spatiale dans la représentation latente, Ballé [2] et al. ont continué à ajouter un réseau super-prior au modèle précédent, en utilisant des informations super-prior compressées comme auxiliaire, et en même temps en ajoutant quelques informations binaires au flux de code généré. Représente les informations auxiliaires, obtient un modèle plus précis et améliore le codage entropique. Sur cette base, des chercheurs tels que Minnen [3] ont étendu le modèle super-prior, amélioré le modèle gaussien de moyenne 0 en un modèle gaussien de moyenne non nulle et ajouté un module contextuel pour compenser le manque d'informations contextuelles dans le modèle super-prior.Combiné avec L'effet de compression d'image dans le cadre de réseau hyper-prior avec module de contexte est meilleur que BPG en termes de signal/bruit de pointe et de similarité structurelle multi-échelle. Lee [15] a proposé un réseau contextuel qui utilise deux types de réseaux contextuels, notamment un contexte consommateur de bits et un contexte sans bits, et choisit d'utiliser ou non des bits supplémentaires en fonction des besoins. Ce réseau est propice à l'estimation de représentations potentielles de problèmes plus larges. des modèles. Hu [16] et al. ont proposé un modèle super-prior multicouche pour résoudre le problème de dépendance à longue distance existant dans le réseau super-prior et le modèle de contexte, c'est-à-dire, ajouter un autre réseau au réseau super-prior original pour analyser Les données de la couche cachée. Effectuez une analyse et une transformation plus approfondies pour extraire pleinement la redondance spatiale de l'image. Qian [17] pensait que les recherches précédentes se concentraient sur la redondance des informations locales et accordaient trop peu d'attention à la redondance des informations globales. Il a ajouté un module de recherche globalement pertinent au modèle d'entropie et a progressivement combiné le modèle d'entropie avec le module contextuel. avec le module de recherche globale. Bai[18] et autres dans l'original Basé sur le cadre de compression d'image super-antérieur avec perte, un nouveau réseau d'apprentissage résiduel est construit pour apprendre à construire des images compressées presque sans perte, obtenant ainsi les meilleures performances sous compression sans perte. Dans le même temps, par rapport à la compression avec perte à des débits binaires élevés, ce n'est pas non plus inférieur. En plus d'utiliser des réseaux de neurones convolutifs, il existe également des modèles d'entropie basés sur Transformer. Qian [17] et d'autres ont proposé un mécanisme de filtrage Top-k et un module de position relative pour rendre le réseau plus précis dans la prédiction de la distribution de probabilité des caractéristiques. En résumé, la partie codage entropique du codage par compression d'image basée sur l'apprentissage profond est principalement complétée en utilisant la méthode d'estimation et de modélisation des représentations potentielles pour rendre l'estimation aussi précise que possible.
Développement d'un module d'allocation de débit de code adaptatif
En plus des trois modules ci-dessus, dans le cadre de compression d'image de bout en bout basé sur l'apprentissage profond, une allocation adaptative du débit de code est également effectuée pour l'image, en tenant compte de la structure complexe et des différences régionales de l'image. Li [19] et al. ont proposé un réseau de codage pondéré en fonction du contenu, appelé réseau de masques d'importance, à travers lequel un masque d'allocation de débit de code localement adaptatif peut être généré. Zhong [20] et d'autres pensent que la compression d'image précédente basée sur les réseaux de neurones convolutifs n'est pas rigoureuse dans la cartographie égale de tous les canaux de caractéristiques. Ils ont proposé un réseau de quantification variable, incluant l'apprentissage de l'importance des canaux et l'allocation de débits de code. chaînes. Liu [21] et al.utilisent des modules non locaux pour obtenir la corrélation globale des images, et combinent le mécanisme d'attention pour allouer plus de débits binaires aux informations importantes dans les caractéristiques de l'image. Liu [22] et al. ont conçu un module d'attention de canal léger, qui a effectivement réduit la quantité de calcul. Akutsu [23] et al. ont proposé un cadre de compression d'image basé sur une combinaison de codage automatique convolutif et de région d'intérêt (ROI). La fonction de perte dans ce cadre modifie les paramètres de qualité dans chaque région de l'image en fonction d'informations auxiliaires. La méthode réduit de 31 % par rapport au cadre d'origine et améliore la similarité structurelle de 0,97. Cai [24] et al. ont construit un réseau de codage ROI capable de générer des représentations multi-échelles et des masques ROI. Afin d'améliorer l'efficacité de la formation, un schéma de formation soft-to-hard a également été développé. Les chercheurs Xia [25] et d'autres ont conçu un réseau de segmentation cible pour décomposer les images en couches et ont utilisé différents schémas de codage pour le premier plan et l'arrière-plan de l'image. Cette méthode peut traiter efficacement des objets de n'importe quelle forme et est à faible débit. amélioration subjective des performances sous la compression d’images à haut débit.
les références
[1]BalléJ,Laparra V,Simoncelli E P.Compression d'image optimisée de bout en bout[J].arXiv e-prints, 2016,arXiv:1611.01704.
[2]BalléJ,Minnen D,Singh S,et al.Compression d'image variationnelle avec une échelle hyperprior[C].Conférence internationale sur les représentations d'apprentissage,Vancouver,2018,arXiv:1802.01436.
[3] Minnen D, Ballé J, Toderici G. Priors autorégressifs et hiérarchiques communs pour la compression d'images apprises [C]. Actes de la 32e Conférence internationale sur les systèmes de traitement de l'information neuronale, Red Hook, NY, États-Unis, 2018, 10794-10803 .
[4]Jiang F, Tao W, Liu S et al. Un cadre de compression de bout en bout basé sur des réseaux neuronaux convolutifs [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28 (10): 3007 -3018.
[5] Toderici G, Vincent D, Johnston N et al. Compression d'images pleine résolution avec réseaux neuronaux récurrents [C]. Conférence IEEE 2017 sur la vision par ordinateur et la reconnaissance de formes, Los Alamitos, CA, USA, 2017, 5435-5443.
[6] Minnen D, Toderici G, Covell M et al. Compression d'images spatialement adaptative à l'aide d'un réseau profond en mosaïque [C]. 2017 Conférence internationale IEEE sur le traitement d'images, 2017, 2796-2800.
[7] Johnston N, Vincent D, Minnen D et al. Compression d'images avec perte améliorée avec amorçage et débits binaires spatialement adaptatifs pour les réseaux récurrents [C]. Conférence IEEE/CVF 2018 sur la vision par ordinateur et la reconnaissance de formes, 2018, 4385-4393. .
[8] Rippel O, Bourdev L. Compression d'image adaptative en temps réel [C]. Actes de la 34e Conférence internationale sur l'apprentissage automatique, 2017, 2922-2930.
[9]Ballé J,Laparra V,Simoncelli E P.Optimisation de bout en bout des codes de transformation non linéaires pour la qualité perceptuelle[C].2016 Picture Coding Symposium,Nuremberg,Allemagne,2016,1-5.
[10]Theis L, Shi W, Cunningham A et al. Compression d'images avec perte avec des codeurs automatiques compressifs [J].arXiv e-prints,2017,arXiv:1703.00395.
[11]Zhao L,Bai H,Wang A et al.Apprentissage d'un vodec virtuel basé sur un réseau neuronal convolutif profond pour compresser l'image[J].arXiv e-prints,2017,arXiv:1712.05969.
[12] Toderici G, O'Malley SM, Hwang SJ, et al. Compression d'images à débit variable avec des réseaux neuronaux récurrents [J]. arXiv e-prints, 2015, arXiv : 1511.06085.
[13]Li M, Zuo W, Gu S, et al. Apprentissage des réseaux convolutifs pour la compression d'images pondérées par le contenu
[J].arXiv e-prints,2017,arXiv:1703.10553.
[14] Agustsson E, Mentzer F, Tschannen M, et al. Quantification vectorielle douce à dure pour l'apprentissage de bout en bout des représentations compressibles [C]. Actes de la 31e Conférence internationale sur les systèmes de traitement de l'information neuronale, Red Hook, NY, États-Unis, 2017, 1141-1151.
[15] Lee J, Cho S, Beack SK. Modèle d'entropie adaptatif au contexte pour une compression d'image optimisée de bout en bout
[J].
[16]Hu Y, Yang W, Liu J.Modélisation hyper-a priori grossière à fine pour la compression d'images apprise [J].
Actes de la conférence AAAI sur l'intelligence artificielle, 2020, 34(7):11013-11020.
[17]Qian Y, Tan Z, Sun X et al. Apprentissage d'un modèle d'entropie précis avec référence globale pour la
compression d'images [J].arXiv e-prints,2020,arXiv:2010.08321.
[18]Bai Y, Liu X, Zuo W, et al. Apprentissage de la compression d'image évolutiveℓ∞ avec contraintes quasi sans perte
via une image avec perte conjointe et une compression résiduelle [C]. Conférence IEEE/CVF 2021 sur la vision par ordinateur et la reconnaissance de formes, Nashville, TN, États-Unis, 2021, 11941-11950.
[19]Li M, Zuo W, Gu S, et al. Learning content-weighted deep image compression [J]. IEEE Transactions
on Pattern Analysis and Machine Intelligence, 2021, 43(10):3446-3461.
[20]Zhong Z,Akutsu H,Aizawa K.Réseau de quantification variable au niveau du canal pour
une compression d'image profonde[J].arXiv e-prints,2020.
[21] Liu H, Chen T, Guo P et al. Compression d'image profonde optimisée pour l'attention non locale [J]
.
[22] Liu J, Lu G, Hu Z et al. Un cadre unifié de bout en bout pour une compression efficace d'images profondes [J].
Tirages électroniques arXiv, 2020, arXiv : 2002.03370.
[23]Akutsu H, Naruko T.Compression d'images ROI profonde de bout en bout[J].IEICE Transactions on Information
and Systems,2020,E103.D(5):1031-1038.
[24]Cai C,Chen L,Zhang X et al.Compression d'image roi optimisée de bout en bout[J].IEEE Transactions
on Image Processing,2020,29:3442-3457.
[25]Xia Q, Liu H, Ma Z.Codage d'images basé sur des objets : une revisite axée sur l'apprentissage[C].2020 IEEE International
Conference on Multimedia and Expo,2020,1-6.