Quelles bases linguistiques devez-vous maîtriser pour apprendre le Big Data ?
1. Fondation Java
Plus de 90 % des frameworks Big Data utilisent le langage de développement Java, donc si vous souhaitez apprendre la technologie Big Data, vous devez d'abord maîtriser la grammaire Java de base et les connaissances pertinentes de la direction JavaEE.
2. Base de données MySQL
C'est l'une des connaissances qu'il faut maîtriser dans l'apprentissage du big data. Le langage de manipulation des données est SQL, l'objectif de développement de nombreux outils est donc de pouvoir utiliser SQL sur Hadoop.
3. Système Linux
Le framework Big Data est installé sur le système d'exploitation Linux, donc la maîtrise des connaissances liées à Linux est également la connaissance de base pour l'apprentissage du Big Data.
L'apprentissage du Big Data ne peut pas rester uniquement au niveau théorique. L'orientation du Big Data est globale et l'apprentissage du langage de base n'est qu'un petit aspect. Une fois la programmation mise en œuvre, c'est finalement l'idée de programmation. l'idéologie directrice, c'est facile à apprendre. Cela peut être beaucoup plus pratique.
À l'heure actuelle, les postes de Big Data proposés par les entreprises peuvent être divisés dans les catégories suivantes en fonction des exigences du contenu du poste :
① Catégorie d'analyse principale, comprenant les analystes de données commerciales, les analystes de données commerciales, etc.
② Algorithmes d'exploration de données, y compris les ingénieurs d'exploration de données, les ingénieurs en apprentissage automatique, les ingénieurs en apprentissage profond, les ingénieurs en algorithmes, les ingénieurs en IA, les scientifiques des données, etc.
③ Développement et maintenance, y compris les ingénieurs en développement Big Data, les ingénieurs en architecture Big Data, les ingénieurs d'exploitation et de maintenance Big Data, les ingénieurs en visualisation de données, les ingénieurs en acquisition de données, les administrateurs de bases de données, etc.
④ Catégorie d'opérations de produits, y compris le responsable des opérations de données, le chef de produit de données, le chef de projet de données, les ventes de Big Data, etc. Le nombre et la proportion des quatre types de postes sont indiqués dans la figure ci-dessous.
La demande de Big Data augmente et le pays ouvre également des emplois dans ce domaine, qui ont augmenté d'année en année depuis 2018.
A l'heure actuelle, les étudiants et les parents qui postulent à l'université sont également très intéressés par le big data et l'intelligence artificielle. Le big data est entré dans le top 5 pendant trois années consécutives, et un baccalauréat suffit.
Dans les années à venir, il s’agira vraiment d’une industrie en plein essor, et il y a maintenant un grand écart.
Les exigences techniques d'un ingénieur big data sont les suivantes :
1. Maîtriser au moins une technologie de développement de bases de données : Oracle, Teradata, DB2, Mysql, etc., et utiliser SQL de manière flexible pour réaliser le traitement ETL de données massives ;
2. Familiarisé avec les commandes de traitement shell régulières du système Linux et utiliser de manière flexible le traitement de texte et les opérations système effectuées par le shell ;
3. Une expérience dans le développement d'applications de stockage de données distribuées et de plates-formes informatiques, une familiarité avec les technologies écologiques Hadoop et une expérience pratique pertinente sont préférables, en se concentrant sur Hdfs, Mapreduce, Hive et Hbase ;
4. La maîtrise d'un ou plusieurs langages de programmation et une expérience dans la construction de projets à grande échelle sont préférables, en mettant l'accent sur Java, Python et Perl ;
5. Ceux qui connaissent les connaissances et les compétences dans le domaine de l'entrepôt de données sont préférés, y compris, mais sans s'y limiter : la gestion des métadonnées, les outils et méthodes de développement et de test des données, la qualité des données, la gestion des données de référence ;
6. Maîtriser la technologie informatique de flux en temps réel, une expérience dans le développement de tempêtes est préférable.
Les ingénieurs de données visent à avoir une vue d’ensemble et à se développer. Les ingénieurs de données construisent des systèmes automatisés et modélisent les structures de données afin que les données puissent être traitées efficacement. L'objectif d'un ingénieur de données est de créer et de développer des tables et des pipelines de données pour prendre en charge les tableaux de bord d'analyse et d'autres clients de données (tels que des scientifiques de données, des analystes et d'autres ingénieurs). Tout comme la plupart des ingénieurs, il existe de nombreuses conceptions, hypothèses, contraintes et développements pour pouvoir créer une sorte de système robuste ultime. Ce système peut être un entrepôt de données et un ETL ou un pipeline de streaming.
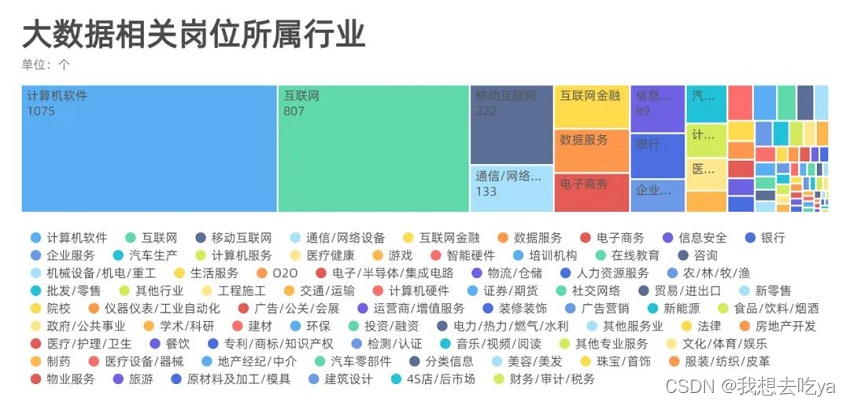
En analysant différents secteurs, nous avons constaté que la demande d'emplois dans le Big Data est répartie dans tous les domaines, principalement dans les logiciels informatiques et Internet, et qu'elle peut également être déterminée par ce logiciel de recrutement.Après tout, l'emploi direct des patrons est encore principalement dans l'industrie Internet.
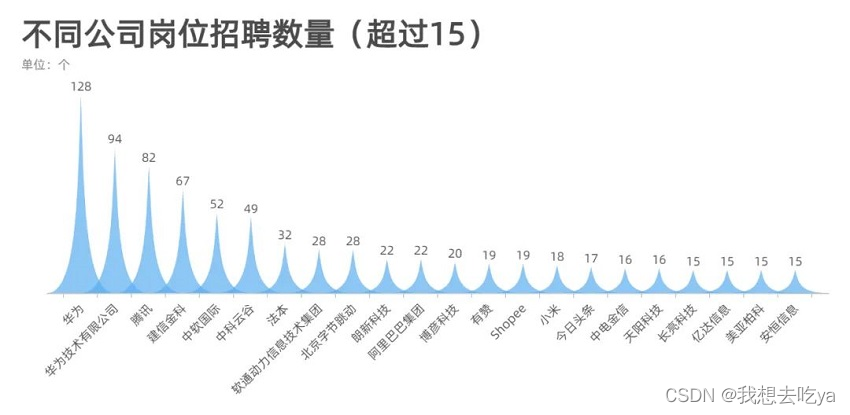
Jetons un coup d'œil aux entreprises qui recrutent pour des postes liés au big data : à en juger par le nombre de plus de 15, Huawei, Tencent, Ali, Byte, ces grandes entreprises ont encore une forte demande pour ce poste.
Alors, quelles compétences ces emplois nécessitent-ils ? Spark, Hadoop, Data Warehouse, Python, SQL, Mapreduce, Hbase, etc.

Selon la situation du développement national, les perspectives de développement futur du Big Data seront très bonnes. Depuis que les entreprises ont entamé leur transformation numérique en 2018, la demande de talents dans le domaine du Big Data dans les villes de premier et deuxième rangs est très forte. Au cours des prochaines années, la demande de talents dans les villes de troisième et quatrième rangs augmentera. augmentent également de manière significative.
Parcours et ressources d’apprentissage du Big Data :
Premiers pas : Premiers pas avec Linux → MySQL Database
Core Foundation :
Technologie Hadoop Data Warehouse : Projet Hive Data Warehouse
PB Memory Computing : Premiers pas avec Python → Advanced Python → pyspark Framework → Projet Hive+Spark
Avant de choisir un établissement de formation, vous pouvez d'abord apprendre les bases du big data pour voir si vous pouvez le maîtriser~
Cet ensemble de tutoriels couvre tout ce qui doit être appris en big data
Projets pratiques Hadoop, Hive et plateforme cloud
Permettez aux étudiants base zéro de commencer en un seul arrêt
Technologie de base du Big Data direct
Ce nouvel ensemble de didacticiels Big Data est basé sur Hadoop, Hive, la plate-forme cloud et d'autres technologies pour vous guider dans le domaine du Big Data, du superficiel au profond, et découvrir ensemble le charme du calcul de données à grande échelle.
Basé sur la conception du contenu de l'apprentissage base zéro, il fournit une multitude de points de connaissances supplémentaires permettant aux étudiants base zéro d'effectuer un pré-apprentissage.
En tant que nouveau cours d'introduction au Big Data en 2023, le contenu du cours adopte un nouveau système de pile technologique. Basé sur les plateformes cloud Hadoop3.3.4, Hive 3.1.3, Alibaba Cloud et UCloud, un cours d'introduction permettant aux étudiants de créer un écosystème Big Data Hadoop, mais pas seulement Hadoop.
caractéristiques du cours
• Combinaison parfaite de théorie + pratique : cet ensemble de tutoriels adopte la forme de « théorie + pratique » pour présenter de manière exhaustive les connaissances pertinentes du développement hors ligne du big data Hadoop et Hive ;
• À la fois contenu et profondeur : le cours adopte la conception de contenu « introduction + amélioration », les connaissances introductives et les connaissances avancées sont indépendantes les unes des autres, d'abord une introduction complète, puis une avancée complète, étape par étape pour que chacun puisse apprendre quelque chose ;
• Combiner les plates-formes cloud populaires actuelles (Aliyun, UCloud) pour vous proposer un « développement cloud natif du Big Data » : basé sur les plates-formes cloud Hadoop3.3.4, Hive 3.1.3, Alibaba Cloud et UCloud, en utilisant un nouveau système de pile technologique.
adapté à la foule
>Basic zéro : du niveau débutant au niveau avancé, puis au niveau maîtrise
>Avancé : des ingénieurs expérimentés consolident et développent
>Explorer : ceux qui souhaitent profiter du charme du big data
Premiers pas avec le développement Big Data en phase 1
Guide préalable à l'étude : commencez avec les bases de données relationnelles traditionnelles, les outils de migration de données de base, les outils de visualisation de données BI et SQL, et établissez une base solide pour l'apprentissage ultérieur.
1. Base de développement de données Big Data MySQL8.0 de l'entrée à la maîtrise
MySQL représente l'intégralité du cours de base en informatique, et SQL couvre toute la vie informatique. Comme le dit le proverbe, si SQL est bien écrit, vous pouvez facilement trouver un emploi. Ce cours explique entièrement MySQL8.0 du niveau zéro au niveau avancé. Après avoir étudié ce cours, vous pouvez avoir le niveau SQL requis pour le développement de base.
Le fondement du Big Data dans la deuxième étape
Guide de pré-étude : apprenez Linux, Hadoop, Hive et maîtrisez la technologie de base du big data.
Tutoriel d'introduction au Big Data Hadoop 2022
Hadoop hors ligne est le cœur et la pierre angulaire de l'écosystème du Big Data, une introduction à l'ensemble du développement du Big Data et un cours qui jette des bases solides pour les futurs Spark et Flink. Après avoir maîtrisé les trois parties du cours : Linux, Hadoop et Hive, vous pouvez réaliser de manière indépendante le développement de rapports visuels pour l'analyse de données hors ligne basée sur l'entrepôt de données.
La troisième étape de centaines de milliards de technologies d'entrepôt de données
Guide préalable à l'étude : Le cours à ce stade est animé par des projets réels, apprenant la technologie d'entrepôt de données hors ligne.
Entrepôt de données hors ligne, pratique de projet de formation en ligne au niveau de l'entreprise (processus complet du projet d'entrepôt de données Hive)
Ce cours établira un entrepôt de données de groupe, unifiera le centre de données de groupe et centralisera le stockage et le traitement des données commerciales dispersées ; le but est de la recherche de la demande, de la conception, du contrôle de version, de la R&D, des tests et du lancement, couvrant le processus complet du projet ; l'extraction et l'analyse de données massives sur le comportement des utilisateurs, la personnalisation d'ensembles de données multidimensionnels et la création d'un magasin de données à utiliser dans divers thèmes de scène. .
Le calcul de la mémoire PB de quatrième étape
Guide de pré-étude : Spark a officiellement adopté Python comme premier langage sur sa page d'accueil. Dans la mise à jour de la version 3.2, il met en évidence le contenu Pandas ; Spark intégré.
1. De l'entrée à la maîtrise de python (19 jours)
Cours d'apprentissage de base de Python, depuis la création de l'environnement. Énoncés de jugement, puis aux types de données de base, puis apprenez et maîtrisez les fonctions, familiarisez-vous avec les opérations sur les fichiers, construisez d'abord une idée de programmation orientée objet et enfin conduisez les étudiants dans le palais de la programmation python avec un cas.
2. Programmation Python avancée de zéro à la création de sites Web
Après avoir terminé ce cours, vous maîtriserez la syntaxe Python avancée, la programmation multitâche et la programmation réseau.
3.spark3.2 de base à compétent
Spark est le produit phare du système Big Data. Il s'agit d'un cadre informatique itératif à mémoire distribuée hautes performances capable de gérer d'énormes quantités de données. Ce cours est développé sur la base de l'apprentissage du langage Python Spark3.2. L'explication du cours se concentre sur l'intégration de la théorie à la pratique, qui est efficace, rapide et facile à comprendre, afin que les débutants puissent la maîtriser rapidement. Laissez les ingénieurs expérimentés y gagner également.
4. Projet industriel d'entrepôt de données hors ligne Big Data Hive+Spark Combat réel
Grâce à l'architecture technologique du Big Data, il résout les problèmes de stockage et d'analyse des données, de visualisation et de recommandation personnalisée dans l'industrie manufacturière de l'Internet des objets industriel. Le projet de fabrication à guichet unique est principalement basé sur la couche d'entrepôt de données Hive pour stocker les données de divers indicateurs commerciaux, et sur sparkSQL pour l'analyse des données. Le cœur de métier concerne les opérateurs, les centres d'appels, les bons de travail, les stations-service et le matériel d'entreposage.