Ce chapitre commencera par le problème de classification dans l'apprentissage automatique . Bien que le nom soit régression, c'est pour la classification. La façon la plus élémentaire de réfléchir aux problèmes de classification : par exemple, pour reconnaître les nombres manuscrits, le modèle prédira dix catégories d'images d'entrée et donnera 10 probabilités. Sélectionnez celui avec la probabilité la plus élevée comme résultat de prédiction, qui est multi-classification.
Nous utilisons ici un ensemble de données classique - minist, téléchargeable depuis pytorch, le code est le suivant :
import torchvision
train_set = torchvision.datasets.MNIST(root=’../dataset/mnist',train=FTrue,download=True)
test_set = torchvision.datasets.MNIST(root='../dataset/mnist',train=False,download=True)
L'ensemble de données CIFAR-10 est également fourni dans pytorch, qui est un ensemble de petites images 32 × 32, comprenant 50 000 ensembles d'entraînement et 10 000 ensembles de test, avec 10 catégories.
Puisque la prédiction y=wx+b, y∈R, mais que la probabilité de sortie doit être [0, 1], nous devons donc mapper le résultat de la prédiction sur [0, 1] . Ici, nous utiliserons la fonction logistique , l'image de la fonction est présentée dans la figure 1, située dans [0, 1].
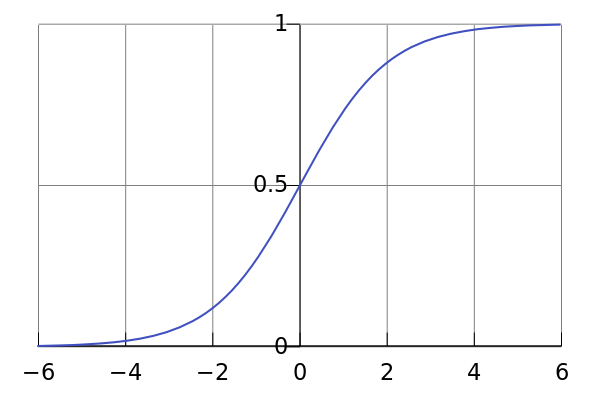
Utilisez cette fonction pour mapper y_hat à l'intervalle requis, et la logistique est également appelée sigmoïde, et la logistique est appelée sigmoïde dans la bibliothèque pytorch. Dans les articles sur l'apprentissage profond, si vous voyez σ(), vous activez avec la fonction sigmoïde. La seule différence entre celle-ci et la régression linéaire est l'ajout d'un biais σ . La différence de code est illustrée dans la figure 2 :

La formule nécessaire pour la fonction de perte dans le problème de classification binaire est :
Cette fonction s'appelle BCE Loss, et elle est utilisée dans le code comme :
criterion = torch.nn.BCELoss(size_average = False)
Il n'y a que deux changements dans l'ensemble du code, et une telle structure de framework peut écrire un grand nombre de modèles.

La section suivante traitera de la saisie de fonctionnalités multidimensionnelles.