1. Résumé

En tant que système de messagerie distribué de publication-abonnement à haut débit, Kafka est largement utilisé dans les applications de messagerie, en particulier dans les scénarios qui nécessitent un traitement de données en temps réel et un suivi de l'activité des applications. Kafka est devenu le service préféré ; avant Kafka2.8, Kafka était fort S'appuyer sur ZooKeeper pour gérer les métadonnées du cluster entraîne également une forte incidence sur les performances de Kafka lorsque les performances du cluster ZooKeeper fluctuent. Après la version 2.8, kafka3.x a commencé à fournir le mode KRaft (Kafka Raft, s'appuyant sur Java 8+) et a commencé à supprimer la dépendance à l'égard de zookeeper. Dans la dernière version 3.5, Kafka est toujours compatible avec zookeeper Controller, mais le mode métadonnées de Kafka Raft peut déjà démarrer Kafka indépendamment sans compter sur zookeeper.
Avantages du mode kraft :
1. Déploiement et gestion plus faciles – En installant et en gérant une seule application, Kafka a désormais une empreinte opérationnelle beaucoup plus réduite. Cela facilite également l'utilisation de Kafka dans les petits appareils en périphérie ;
2. Améliorer l'évolutivité : le temps de récupération de KRaft est un ordre de grandeur plus rapide que celui de ZooKeeper. Cela nous permet d'évoluer efficacement vers des millions de partitions dans un seul cluster. La limite effective de ZooKeeper est de plusieurs dizaines de milliers ;
3. Propagation plus efficace des métadonnées : la propagation des métadonnées basée sur les journaux et basée sur les événements peut améliorer les performances de nombreuses fonctions principales de Kafka. De plus, il prend en charge la capture instantanée de sujets de métadonnées.
Lien de données : site officiel kraft , kafka_jira
2. Topologie
2.1. Première topologie


Le principe de l'ancienne élection du contrôleur : un seul courtier peut être élu contrôleur. Lorsque le courtier où se trouve le contrôleur est en panne, d'autres courtiers peuvent rivaliser pour être élus contrôleur.

Kafka le fait en utilisant des numéros d'époque (numéros d'époque, également appelés jetons d'isolement). Le numéro d'époque est simplement un nombre croissant de façon monotone. Lorsque le contrôleur est sélectionné pour la première fois, la valeur du numéro d'époque est 1. Si un nouveau contrôleur est à nouveau sélectionné, le numéro d'époque sera 2, qui augmente de façon monotone.
Chaque contrôleur nouvellement sélectionné obtient un nouveau numéro d'époque plus grand grâce à l'opération d'incrémentation conditionnelle de Zookeeper. Une fois que les autres courtiers connaissent le numéro d'époque actuel, s'ils reçoivent des messages contenant des numéros d'époque plus anciens (plus petits) envoyés par le contrôleur, ils les ignoreront, c'est-à-dire que le courtier distingue le dernier contrôleur actuel en fonction du numéro d'époque le plus grand.
Il existe plusieurs états de réplication courants :
Nouveau : l'état du réplica lorsque le contrôleur vient de créer le réplica. Le réplica dans cet état ne peut
devenir qu'un réplica suiveur
. Une fois le courtier arrêté, l'état du réplica passe à Offline
ReplicaDeletionStarted : lorsque le cluster Kafa active le sujet suppression et reçoit une commande de suppression pour un sujet, la réplique sous le sujet entrera dans cet état. ReplicaDeletionSuccessful
: lorsque la réplique est supprimée avec succès, la réplique entrera dans cet état.
ReplicaDeletionIneligible : lorsqu'une réplique ne parvient pas à être supprimée, la réplique entrera cet état, en attendant que le contrôleur réessaye. NonExistant : lorsque la réplique est supprimée avec succès, la
réplique entrera dans cet état, ou lorsque la réplique qui vient d'être créée par le sujet n'a pas été établie, la réplique est dans cet état.
Lorsque le sujet Kafka vient d'être créé, la copie du sujet est dans l'état NonExistent . À ce moment, le contrôleur charge les informations de copie de chaque partition du sujet dans Zookeeper dans la mémoire et met en même temps à jour la copie vers l' état New , puis le contrôleur sélectionne la première copie de la partition. Agir en tant que réplique principale et définir toutes les répliques dans l'ISR, puis conserver la décision dans Kafka.
Après avoir déterminé la copie de partition et le leader, le contrôleur enverra les informations à chaque copie et synchronisera l'état de la copie à tous les courtiers en même temps. Une fois les opérations ci-dessus terminées, la copie entrera dans l'état En ligne .
Lorsque l'opération de suppression de sujet est activée, le contrôleur arrêtera toutes les répliques. S'il s'agit d'une réplique suiveuse, il cessera de récupérer les données de la réplique leader. S'il s'agit d'une réplique leader, le contrôleur définira le leader de la division sur NO_LEADER. , puis la réplique entrera dans l' état Hors ligne . Immédiatement après, le contrôleur modifiera l'état de la réplique en ReplicaDeletionStarted pour indiquer que la suppression du sujet a commencé. Le contrôleur enverra une demande de suppression à toutes les répliques, leur demandant de supprimer les données de la réplique locale. Lorsque toutes les répliques seront supprimées avec succès , il entrera dans l'état ReplicaDeletionSuccessful . En supposant que l'une des répliques ne parvient pas à être supprimée pendant le processus de suppression , elle entrera dans l'état ReplicaDeletionIneligible et attendra que le contrôleur réessaye. Dans le même temps, s'il est dans l'état ReplicaDeletionSuccessful, il passera automatiquement à l'état NonExistent et le cache contextuel du contrôleur effacera les informations de réplique.
Voici l'état de la partition :
NonExistent : Indique que la partition n'existe pas ou que la partition a été supprimée.
Nouveau : Une fois la partition créée, la partition est dans cet état. A l’heure actuelle, Kafka a déterminé la liste de partition, mais le leader et l’ISR n’ont pas encore été choisis.
En ligne : une fois le chef de partition sélectionné, il entrera dans cet état, indiquant que la partition peut fonctionner normalement.
Hors ligne : lorsque le courtier où se trouve le chef de partition est en panne, il entrera dans cet état, indiquant que la partition ne peut pas fonctionner normalement.
Lors de la création d'un sujet, le contrôleur est responsable de la création des objets de partition. Tout d'abord, il définit brièvement toutes les partitions sur l'état NonExistant , puis lit le plan d'allocation des répliques dans Zookeeper, puis fait entrer les partitions dans l'état Nouveau . Une partition à l'état Nouveau entrera dans l'état En ligne lorsqu'une copie Leader et un ISR sont sélectionnés .
Si l'utilisateur lance l'opération de suppression de sujet, la partition entrera dans l'état Non Existant et l'opération de suppression de réplica sous la partition sera également activée. Si l'opération du courtier est fermée ou si le système tombe en panne, le contrôleur déterminera si le courtier est le chef de partition. Si tel est le cas, il doit lancer un nouveau tour d'élection du chef de partition, puis remettre l'état de la partition à l'état En ligne.
2.2. Topologie du contrôleur kRaft



Cluster Kafka en mode kraft : doit comporter un nombre impair de nœuds, 3 nœuds ont une tolérance aux pannes maximale de 1 et 5 nœuds ont une tolérance aux pannes maximale de 2.


Dans un cluster KRaft, tous les agents de contrôleur maintiennent un cache de métadonnées en mémoire à jour afin que n'importe quel contrôleur puisse prendre le relais en tant que contrôleur actif si nécessaire. Tous les courtiers communiquent avec le contrôleur, où le contrôleur actif Le courtier gérera la communication. modifications des métadonnées avec d’autres courtiers. KRaft est basé sur le protocole de consensus Raft , qui a été introduit dans Kafka dans le cadre du KIP-500, avec plus de détails définis dans d'autres KIP associés. Le contrôleur actif est le leader d'une seule partition du sujet de métadonnées à l'intérieur du cluster kafka kraft, les autres contrôleurs sont des suiveurs de réplique et les courtiers sont des observateurs de réplique. Ainsi, au lieu que les contrôleurs diffusent les modifications des métadonnées à d’autres contrôleurs ou courtiers, chacun récupère activement les modifications. Cela rend très efficace la synchronisation de tous les contrôleurs et courtiers, et réduit également les temps de redémarrage des courtiers et des contrôleurs.
En mode KRaft, les métadonnées du cluster (reflétant l'état actuel de toutes les ressources gérées par le contrôleur) sont stockées dans une rubrique nommée __cluster_metadata. KRaft utilise cette rubrique pour synchroniser les changements d'état du cluster entre les nœuds du contrôleur et de l'agent. En mode KRaft, un cluster Kafka peut s'exécuter en mode dédié ou partagé. En mode dédié, certains nœuds ont leur configuration process.roles définie sur contrôleur, tandis que le reste des nœuds la définit sur courtier. Pour le mode partagé, ces nœuds auront process.roles défini sur contrôleur, courtier, c'est-à-dire que certains nœuds effectueront une double tâche. Le nœud spécial de ce mode appelé « contrôleur » est responsable de la gestion de l'enregistrement des agents dans le cluster, qui est généralement le premier nœud de contrôleur.quorum.voters. L'activité de courtier est soumise à deux conditions :
1. Les courtiers doivent maintenir une session active avec le contrôleur afin de recevoir des mises à jour régulières des métadonnées. La « session active » dépend de la configuration du cluster, une session active est maintenue en envoyant des battements de cœur périodiques au contrôleur . Si le contrôleur ne reçoit pas de pulsation avant l'expiration du délai d'attente configuré par broker.session.timeout.ms , le nœud est considéré comme hors ligne.
2. Les courtiers agissant en tant que suiveurs doivent reproduire les écrits du leader et ne pas prendre « trop de retard ».
En mode Kradt, les contrôleurs stockent les métadonnées du cluster dans le répertoire spécifié dans metadata.log.dir/le premier répertoire de journaux. En particulier, lors de l'ajout d'un nouveau nœud de contrôleur, vous devez attendre que le contrôleur existant soumette toutes les données : le nouveau nœud de contrôleur ne doit pas être formaté et démarré tant que la majorité des contrôleurs n'ont pas toutes les données validées. Vous pouvez vérifier et confirmez avec la commande suivante : kafka-metadata-quorum.sh --bootstrap-server broker_host:port describe --replication, il serait préférable que la valeur de Lag affichée soit 0, assurez-vous au moins que la valeur de Lag est suffisamment petite pour les contrôleurs, ou si le décalage de fin du leader n'augmente pas, vous pouvez attendre que le décalage soit 0 pour une majorité ; si ce n'est pas 0, vérifiez-le. Les deux valeurs de LastFetchTimestamp et LastCaughtUpTimestamp, les deux valeurs de tous les contrôleurs doivent être aussi proches que possible, c'est-à-dire que la lecture et la consommation doivent être cohérentes ; alors il peut être exécuté : formater le chemin de stockage des métadonnées du nouveau contrôleur ; noter que le bin/kafka-storage.sh format --cluster-id uuid --config server_propertiesmode mixte Dans ce cas, le format de stockage signalera une erreur : Le répertoire des journaux ... est déjà formaté, cette situation ne se produit qu'en mode mixte et le Le chemin d'origine du journal du contrôleur est perdu ou endommagé, vous pouvez exécuter : , et il n'est pas recommandé de l'utiliser dans d'autres cas bin/kafka-storage.sh format --cluster-id uuid --ignore-formatted --config server_properties. Les contrôleurs sont utilisés pour recevoir des demandes d’autres contrôleurs et agents. Par conséquent, même si le rôle de contrôleur n'est pas activé sur le serveur (c'est-à-dire qu'il s'agit simplement d'un courtier), il doit toujours définir l'écouteur du contrôleur et toutes les propriétés de sécurité nécessaires pour le configurer. Exemple de référence de configuration :
process.roles=broker
listeners=BROKER://localhost:9092 #broker does not expose the controller listener itself
inter.broker.listener.name=BROKER #区别于下面的controller.listener.names
controller.quorum.voters=0@localhost:9093
controller.listener.names=CONTROLLER #仅用于controller
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL
#混合模式
process.roles=broker,controller
listeners=BROKER://localhost:9092,CONTROLLER://localhost:9093 #listeners独立配置用户kafka 客户端访问
inter.broker.listener.name=BROKER #配合上面的与kafka client交互,隔离开controller
controller.quorum.voters=0@localhost:9093
controller.listener.names=CONTROLLER #The controller will accept requests on all listeners defined by controller.listener.names,多个controller时,the first one in the list will be used for outbound requests.
listener.security.protocol.map=BROKER:SASL_SSL,CONTROLLER:SASL_SSL

Voir le transfert principal KRaft pour en savoir plus . Remarque : Le mode mixte en mode kraft est principalement utilisé dans l'environnement de développement et il n'est pas recommandé pour l'environnement de production. Un problème évident en mode hybride est que le contrôleur sera moins isolé du reste du système, c'est-à-dire qu'il ne peut pas être isolé du courtier. Un scénario typique est que le contrôleur ne peut pas être étendu ou restauré de manière élastique et mis à niveau séparément. ; en mode KRaft, un Kafka spécifique Le serveur sera sélectionné comme contrôleur ; tous les contrôleurs candidats définis participeront à l'élection des métadonnées, et pour le contrôleur actif, d'autres contrôleurs agiront comme des rôles de secours ; par conséquent, notre pratique courante est pour configurer process.role en tant que courtier/contrôleur au lieu de Les deux sont disponibles (mode mixte) ; il est recommandé qu'un cluster Kafka utilise 3 contrôleurs, et plus de 3 contrôleurs ne sont pas recommandés. Le contrôleur Kafka stocke toutes les métadonnées du cluster dans la mémoire et le disque. La recommandation officielle est d'allouer 5G d'espace à la mémoire et au disque pour stocker ces journaux de métadonnées ; de plus, Kraft a également certaines limitations. Par exemple, les fonctions suivantes ne sont pas en mode KRaft. Entièrement implémenté dans :
1. Configurer les utilisateurs SCRAM via l'API de gestion
2. Prise en charge de la configuration JBOD avec plusieurs répertoires de stockage
3. Modifier certaines configurations dynamiques sur les contrôleurs KRaft autonomes
4. Déléguer des jetons
Processus de réplication des métadonnées KRaft :

les métadonnées du cluster sont stockées dans les sujets Kafka et le contrôleur actif est le leader d'une seule partition du sujet de métadonnées, qui recevra toutes les données et écrira. D'autres contrôleurs agissent en tant que suiveurs et prendront activement en compte ces changements. Par rapport à la réplication de réplicas traditionnelle, lorsqu'un nouveau leader doit être élu, cela se fait par arbitrage au lieu de synchroniser les jeux de réplicas. Par conséquent, la réplication des métadonnées n’implique pas d’ISR. Une autre différence est que les enregistrements de métadonnées sont immédiatement vidés sur le disque lorsqu'ils sont écrits dans le journal local de chaque nœud.
Configuration du mode Kraft et de l'authentification de sécurité :
SASL/GSSAPI : méthode d'authentification Kerberos, utilisant généralement la méthode d'authentification keytab avec mot de passe aléatoire, le mot de passe est crypté, et c'est également la méthode d'authentification la plus utilisée dans les entreprises ; SASL/PLAIN : cette méthode est en fait une méthode d'authentification compte/mot de passe, mais
Il existe de nombreux défauts, tels que le nom d'utilisateur et le mot de passe sont stockés dans le fichier, ne peuvent pas être ajoutés dynamiquement, le mot de passe est en clair, etc. ! L'avantage est que c'est assez simple ;
SASL/SCRAM : Une autre méthode d'authentification prévue pour pallier le manque de méthode SASL/PLAIN. Le nom d'utilisateur/mot de passe de cette manière est stocké dans zookeeper, afin qu'il puisse prendre en charge l'ajout dynamique d'utilisateurs. Cette méthode d'authentification utilise également sha256 ou sha512 pour crypter le mot de passe, qui est relativement plus sécurisé et a été introduit dans la version 0.10.2 ;
3. Configuration du déploiement
wget https://archive.apache.org/dist/kafka/3.4.0/kafka_2.13-3.4.0.tgz
tar -zxvf kafka_2.13-3.4.0.tgz -C /opt/
mv /opt/kafka_2.13-3.4.0. /opt/kafka
chown kafka:kafka -R /opt/kafka
cd /opt/kafka/
mkdir data
vim /opt/kafka/config/kraftserver.properties //如下所示
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller #the server acts as both a broker and a controller
# The node id associated with this instance's roles
node.id=2
# The connect string for the controller quorum 集群选举控制器配置,默认走 PLAINTEXT协议除非显示定义其他协议
controller.quorum.voters=1@172.18.1.176:9093,[email protected]:9093,[email protected]:9093
############################# Socket Server Settings #############################
# The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://172.31.7.237:9092,CONTROLLER://172.18.1.217:9093
# Name of listener used for communication between brokers. it is used exclusively仅用于 for requests between brokers
inter.broker.listener.name=PLAINTEXT #注意与controller.listener.names不要冲突
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://172.18.1.217:9092
#完成后,生成整个集群有一个唯一的ID标志,使用uuid。可使用官方提供的 kafka-storage 工具生成
/opt/kafka/bin/kafka-storage.sh random-uuid
或
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
#用上述ID格式化存储路径
/opt/kafka/bin/kafka-storage.sh format -t clust_ID -c /opt/kafka/config/kraft/server.properties
或
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
#完成后以kraft模式启动服务
bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
#创建topic
bin/kafka-topics.sh --create --topic First_Kafka_Topic --partitions 1 --replication-factor 3 --bootstrap-server 172.31.7.237:9092
#查看
bin/kafka-topics.sh --list --bootstrap-server 172.31.7.237:9092

2) script de démarrage de Kafka
#!/bin/bash
#kafka集群启动脚本
case $1 in
"start"){
for i in 172.18.1.176,172.18.1.217,@172.18.1.150
do
echo "--------启动 $i kafka with kraft-------"
ssh $i "/home/kafka/bin/kafka-server-start.sh -daemon /home/kafka/config/kraft/server.properties"
done
};;
"stop"){
for i in 172.18.1.176,172.18.1.217,@172.18.1.150
do
echo "------停止 $i kafka--------"
ssh $i "/home/kafka/bin/kafka-server-stop.sh"
done
};;
esac
3) configuration de l'authentification de sécurité kafka kRaft SASL/PLAIN :
Créez un nouveau fichier de configuration config/kafka_server_jaas.conf, comme suit :
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
serviceName="kafka"
username="admin"
password="admin"
user_admin="admin";
};
Copiez une copie de kafka-server-start.sh, modifiez le nom du script de démarrage kafka-server-start-sasl.sh, modifiez le nom et importez les fichiers cryptés :
……
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G -Djava.security.auth.login.config=/opt/kafka/kafka_2.13-3.4.0/config/kafka_server_jaas.conf"
fi
……
Copiez une copie de server_sasl.properties et modifiez le nom en server_sasl.properties pour le séparer de l'authentification non liée à la sécurité, modifiez :
node.id=1
controller.quorum.voters=1@kraft1:9093
listeners=SASL_PLAINTEXT://172.31.7.237:9092,CONTROLLER:///172.18.1.217:9093
inter.broker.listener.name=SASL_PLAINTEXT
advertised.listeners=SASL_PLAINTEXT://172.31.7.237:9092
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
Démarrez Kafka une fois terminé :sh ./bin/kafka-server-start-sasl.sh -daemon ./config/kraft/server_sasl.properties
4. Annexe : Bilan des connaissances
4.1, Comparaison des files d'attente de messages couramment utilisées
1)LapinMQ
RabbitMQ est une file d'attente de messages open source écrite en Erlang. Elle prend en charge de nombreux protocoles : AMQP, XMPP, SMTP, STOMP. De ce fait, elle est très lourde et plus adaptée au développement au niveau de l'entreprise. Parallèlement, l'architecture Broker est implémentée, ce qui signifie que les messages sont d'abord mis en file d'attente dans la file d'attente centrale lorsqu'ils sont envoyés au client. Il prend en charge le routage, l’équilibrage de charge ou la persistance des données.
2)Redis
Redis est une base de données NoSQL basée sur des paires clé-valeur, et son développement et sa maintenance sont très actifs. Bien qu'il s'agisse d'un système de stockage de base de données clé-valeur, il prend lui-même en charge la fonction MQ et peut donc être utilisé comme service de file d'attente léger. Pour les opérations de mise en file d'attente et de retrait de RabbitMQ et Redis, exécutez 1 million de fois chacune et enregistrez le temps d'exécution toutes les 100 000 fois. Les données de test sont divisées en quatre tailles de données différentes : 128 octets, 512 octets, 1 Ko et 10 Ko. Les expériences montrent que lors de l'entrée dans l'équipe, les performances de Redis sont supérieures à celles de RabbitMQ lorsque les données sont relativement petites, et si la taille des données dépasse 10 Ko, Redis est insupportablement lent ; lorsqu'il quitte l'équipe, quelle que soit la taille des données , Redis affiche de très bonnes performances , tandis que les performances de sortie de file d'attente de RabbitMQ sont bien inférieures à celles de Redis.
3) ZéroMQ
ZeroMQ est connu comme le système de file d'attente de messages le plus rapide, en particulier pour les scénarios de demande à haut débit. ZeroMQ peut implémenter des files d'attente avancées/complexes pour lesquelles RabbitMQ n'est pas doué, mais les développeurs doivent combiner eux-mêmes plusieurs cadres techniques. La complexité technique est un défi pour l'application réussie de ce MQ. ZeroMQ a un modèle unique sans middleware, vous n'avez pas besoin d'installer et d'exécuter un serveur de messages ou un middleware, car votre application jouera ce rôle de serveur. Il vous suffit de référencer la bibliothèque ZeroMQ, qui peut être installée à l'aide de NuGet, et vous pourrez ensuite envoyer des messages entre applications. Mais ZeroMQ ne fournit que des files d'attente non persistantes, ce qui signifie que si le système tombe en panne, les données seront perdues. Parmi eux, la version Storm de Twitter antérieure à 0.9.0 utilise ZeroMQ comme transmission du flux de données par défaut (Storm prend en charge ZeroMQ et Netty comme modules de transmission à partir de la version 0.9).
4)ActiveMQ
ActiveMQ est un sous-projet sous Apache. Semblable à ZeroMQ, il peut implémenter des files d’attente avec une technologie de courtier et peer-to-peer. Dans le même temps, à l’instar de RabbitMQ, il peut implémenter efficacement des scénarios d’application avancés avec une petite quantité de code.
5) Kafka/Jafka
Kafka est un sous-projet d'Apache. Il s'agit d'un système de file d'attente de messages de publication/abonnement distribué multilingue hautes performances, et Jafka est incubé au-dessus de Kafka, qui est une version améliorée de Kafka. Il présente les caractéristiques suivantes : persistance rapide, la persistance des messages peut être effectuée sous la surcharge du système O(1) ; débit élevé, qui peut atteindre un débit de 10 W/s sur un serveur ordinaire ; système distribué complet, courtier, producteur et consommateur. tous prennent en charge nativement et automatiquement l'équilibrage de charge distribué et automatique ; prennent en charge le chargement parallèle des données Hadoop, pour les données de journaux et les systèmes d'analyse hors ligne comme Hadoop, mais nécessitent des restrictions de traitement en temps réel, c'est une solution réalisable. Kafka unifie le traitement des messages en ligne et hors ligne grâce au mécanisme de chargement parallèle de Hadoop. Apache Kafka est un système de messagerie très léger par rapport à ActiveMQ. En plus de ses très bonnes performances, c'est également un système distribué qui fonctionne bien. Le déploiement léger à processus unique de Kafka3.0 peut non seulement remplacer les files d'attente de messages traditionnelles telles qu'ActiveMQ et RabbitMQ, mais convient également aux scénarios de périphérie et aux scénarios utilisant du matériel léger. Les données montrent que dans un cluster capable de gérer 2 millions de partitions, le processus de migration du Quorum Controller dans la nouvelle version de kafka3.0 peut être raccourci de quelques minutes à 30 secondes, éliminant ainsi le principal goulot d'étranglement de la gestion des métadonnées qui limite la portée du cluster Kafka, l'arrêt et le redémarrage sont plus de dix fois plus rapides que kafka2.8, et les performances sont complètement écrasées !
4.2. Le principe de Kafka
Un nouveau protocole de réplication pour Kafka, introduit dans Kafka 2.4. L'objectif du protocole Kraft est d'améliorer la fiabilité et la maintenabilité de Kafka et de répondre aux besoins de traitement de flux distribués ; il comprend principalement les aspects suivants :
1. Décentralisation : Le protocole Kraft décentralise les nœuds de contrôleur de Kafka et chaque copie peut devenir un contrôleur, améliorant ainsi la fiabilité et la tolérance aux pannes du système.
2. Atomicité : le protocole Kraft utilise le protocole de diffusion atomique pour garantir l'atomicité des messages, c'est-à-dire que toutes les répliques recevront le même message, garantissant ainsi la cohérence des données. 3.
Évolutivité : le protocole Kraft prend en charge l'ajout et la suppression dynamiques de répliques. améliorer l’évolutivité et la maintenabilité du système.
4. Fiabilité : Le protocole Kraft utilise l'algorithme Raft pour assurer la cohérence entre les répliques, améliorant ainsi la fiabilité et la tolérance aux pannes du système.
4.3. Outil de gestion DoctorKafka
Il s'agit d'un projet dérivé des produits Pinterest. Afin d'étendre l'échelle d'exploitation et de maintenance des services Kafka, Pinterest a construit DoctorKafka pour gérer l'auto-réparation du cluster Kafka et l'équilibrage de la charge de travail ; DoctorKafka peut détecter les échecs des courtiers Kafka et transférer automatiquement la charge des courtiers défaillants vers les courtiers sains. Désormais, Pinterest a rendu le projet open source sur GitHub. DoctorKafka se compose de trois parties, l'architecture est la suivante :

1. Le collecteur de métriques déployé sur chaque courtier collecte régulièrement les métriques du processus et de l'hôte Kafka et les publie dans un sujet Kafka. Ici, Kafka est utilisé comme stockage d'état du courtier. De cette façon, le processus de construction de DoctorKafka peut être simplifié et la dépendance à l'égard d'autres systèmes peut être réduite ; chaque courtier exécutera un collecteur d'indicateurs, qui collectera les entrées et les sorties. réseau de courtier Kafka Mesures de trafic et état de chaque réplica.
2. Le service centralisé DoctorKafka gérera plusieurs clusters, analysera les indicateurs d'état du courtier pour détecter les pannes du courtier et exécutera les commandes d'auto-réparation et d'équilibrage de charge du cluster. DoctorKafka enregistrera les commandes exécutées sur un autre sujet nommé « Journal des actions » ;
3. Page de l'interface utilisateur Web pour parcourir l'état du cluster Kafka et le processus d'exécution.
Une fois le service DoctorKafka démarré, il lira d'abord l'état du courtier au cours des dernières 24 à 48 heures. Sur cette base, DoctorKafka déduira les ressources requises par chaque charge de travail de réplica. Étant donné que les charges de travail Kafka sont principalement gourmandes en réseau, DoctorKafka se concentre principalement sur l'utilisation de la bande passante réseau des réplicas. Après le démarrage de DoctorKafka, il vérifiera périodiquement l'état de chaque cluster. Lorsqu'il détecte une panne de courtier, il transfère la charge de travail du courtier défaillant vers un courtier disposant d'une bande passante suffisante. Il avertit s'il n'y a pas suffisamment de ressources dans le cluster à réaffecter. De même, lorsque DoctorKafka effectue un équilibrage de la charge de travail, il identifie le courtier dont le trafic réseau dépasse la configuration et transfère la charge de travail vers le courtier avec moins de trafic, ou effectue un meilleur schéma d'élection du leader (élection du leader) pour détourner le trafic.
DoctorKafka est présent chez Pinterest depuis plusieurs mois et aide son personnel opérationnel à gérer plus de 1 000 clusters. Voir l'adresse du projet pour en savoir plus .
4.4、Kafka WebUI et Kowl
Kowl (Kafka Owl) : Kafka WebUI pour explorer les messages, les consommateurs, les configurations et bien plus encore en mettant l'accent sur une bonne interface utilisateur. Pour plus d'informations, voir : Adresse du projet .
En plus de ce qui précède, il existe 9 outils d'interface utilisateur kafka courants, en plus de LogiKM et kafka-console-ui, car Kafka-UI est entièrement fonctionnel et gratuit, il est recommandé.
1 AKHQ gratuit
2 Kowl Charge partielle
3 Kafdrop gratuit
4 UI pour Apache Kafka gratuit
5 Lenses gratuites
6 CMAK gratuit
7 Confluent CC Charge
8 Conduktor Charge
9 LogiKM gratuit
10 kafka-console-ui gratuit

Habituellement, le programme s'exécute via un conteneur Docker et le plus grand avantage de Kowl est son excellente interface utilisateur. Il est pratique, convivial et facile à utiliser ; l'interface après le lancement est la suivante :
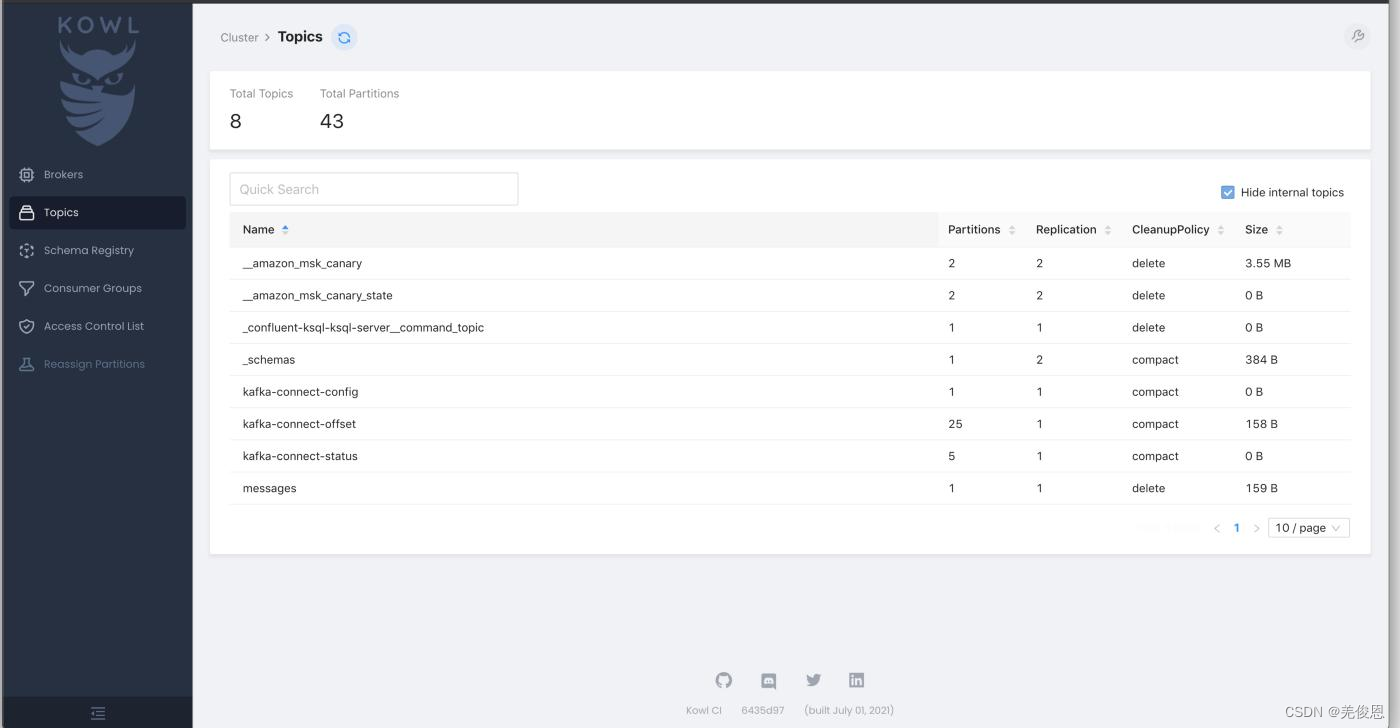
Kowl fournit la navigation dans les messages, le suivi en temps réel et la prise en charge de Protobuf, Avro et Amazon MSK IAM, mais les systèmes de connexion (Google, GitHub, Okta) et autorisations RBAC avec synchronisation de groupe Disponible uniquement pour les forfaits Kowl Business payants. Kowl manque également de fonctionnalités telles que la gestion multi-cluster, la configuration dynamique des sujets, l'ajout de partitions, les modifications de réplicas, la gestion de Kafka Connect, le registre de schémas, l'intégration KSQL, la topologie Kafka Streams, le mode lecture seule, ainsi que la visualisation et la représentation graphique des métriques JMX.