Als ich vor ein paar Tagen die Grundkenntnisse von Java überprüfte, fielen mir die beiden Methoden Equals und HashCode auf. Ich war völlig verwirrt über das Schreiben von HashCode und andere Probleme. Nach sorgfältiger Analyse und Code-Übungen habe ich es endlich gründlich herausgefunden. Falls ja Bei Fehlern und Mängeln korrigieren Sie mich bitte.
Artikelverzeichnis
- 1. Schauen wir uns zunächst die nativen Methoden equal und hashCode an.
- 2. Der Fall des Umschreibens von equal und hashCode
1. Schauen wir uns zunächst die nativen Methoden equal und hashCode an.
1.1、gleich
Die Methode equal in Object ist dieselbe wie „==“. Der folgende Code vergleicht Speicheradressen.
public boolean equals(Object obj) {
return (this == obj);
}
1.2、hashCode
Die native Methode hashCode gibt einen aus der Speicheradresse konvertierten Wert zurück. Es ist wie folgt definiert:
public native int hashCode();
Es ist ersichtlich, dass es sich hierbei um eine native Methode handelt, da die native Methode nicht von der Java-Sprache implementiert wird und daher in der Definition dieser Methode keine spezifische Implementierung enthalten ist. Gemäß der JDK-Dokumentation wird die Implementierung dieser Methode im Allgemeinen „durch Konvertierung der internen Adresse des Objekts in eine Ganzzahl realisiert“**, und dieser Rückgabewert wird als Hash-Codewert des Objekts zurückgegeben.
1.3. Zusammenfassung
Also, ohne Equals und HashCode zu überschreiben:
(1) Wenn die Gleichheit zweier Objekte gleich ist, muss der HashCode gleich sein. Da equal standardmäßig „==“ zum Vergleichen verwendet, wird die Speicheradresse verglichen und hashCode erhält den Hash-Wert basierend auf der Speicheradresse. Wenn die Speicheradresse gleich ist, muss der erhaltene Hash-Wert gleich sein.
(2) Wenn der HashCode zweier Objekte gleich ist, ist gleich nicht unbedingt gleich. Warum ist das so? Lassen Sie uns zunächst über die Hash-Tabelle sprechen. Die Hash-Tabelle kombiniert direkte Adressierung und Kettenadressierung. Vereinfacht ausgedrückt berechnet sie zunächst den Hash-Wert der einzufügenden Daten und fügt ihn dann in „Gehe zu“ ein die entsprechende Gruppierung, da die Hash-Funktion einen int-Typ zurückgibt, sodass es höchstens 2 hoch 32 Potenzen gibt, es zu viele Objekte gibt und es immer Zeiten gibt, in denen die Gruppierung nicht ausreicht. Zu diesem Zeitpunkt verschiedene Objekte Es wird derselbe Hash-Wert generiert, d. Da es sich um unterschiedliche Objekte handelt, sind die Speicheradressen unterschiedlich, daher müssen ihre Gleichen ungleich sein. Der HashCode entspricht hier dem Namen einer Person und equal entspricht einer ID-Nummer. Es gibt viele Personen mit demselben Namen, aber sie sind nicht dieselbe Person.
2. Der Fall des Umschreibens von equal und hashCode
2.1, nicht umschreiben
import java.util.*;
public class Test {
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "张三";
Person p2 = new Person();
p2.name = "李四";
Person p3 = new Person();
p3.name = "张三";
Set set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
for (Iterator iter=set.iterator(); iter.hasNext();) {
Person p = (Person)iter.next();
System.out.println("name=" + p.name );
}
System.out.println("p1.hashCode=" + p1.hashCode());
System.out.println("p2.hashCode=" + p2.hashCode());
System.out.println("p3.hashCode=" + p3.hashCode());
System.out.println();
System.out.println("p1 equals p2," + p1.equals(p2));
System.out.println("p1 equals p3," + p1.equals(p3));
}
}
class Person {
String name;
}
Ausgabe:

Unterschiedliche Gleichheit und unterschiedlicher HashCode
Es ist ersichtlich, dass doppelte Daten ohne Umschreiben eingefügt werden. Der Grund dafür ist, dass der Standardvergleich ohne Umschreiben auf dem von der Speicheradresse generierten Hash-Wert basiert. Unterschiedliche Speicheradressen erzeugen unterschiedliche Hash-Werte (ohne Berücksichtigung von Hash-Konflikten), sodass doppelte Daten eingefügt werden.
2.2, nur das Umschreiben ist gleich
import java.util.*;
public class Test {
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "张三";
Person p2 = new Person();
p2.name = "李四";
Person p3 = new Person();
p3.name = "张三";
Set set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
for (Iterator iter=set.iterator(); iter.hasNext();) {
Person p = (Person)iter.next();
System.out.println("name=" + p.name );
}
System.out.println("p1.hashCode=" + p1.hashCode());
System.out.println("p2.hashCode=" + p2.hashCode());
System.out.println("p3.hashCode=" + p3.hashCode());
System.out.println();
System.out.println("p1 equals p2," + p1.equals(p2));
System.out.println("p1 equals p3," + p1.equals(p3));
}
}
class Person {
String name;
//覆盖 equals
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Person) {
Person p = (Person)obj;
return this.name.equals(p.name);
}
return false;
}
}
Ausgabe:

gleich gleicher HashCode unterschiedlich
Obwohl der obige Code nach dem Umschreiben gleicher Werte dieselben Objekte vergleichen kann, werden dennoch doppelte Daten eingefügt, da der HashCode der beiden Objekte unterschiedlich ist. Daher muss der HashCode neu geschrieben werden, um das Einfügen doppelter Daten zu vermeiden.
2.3, nur hashCode neu schreiben
import java.util.*;
public class Test {
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "张三";
Person p2 = new Person();
p2.name = "李四";
Person p3 = new Person();
p3.name = "张三";
Set set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
for (Iterator iter=set.iterator(); iter.hasNext();) {
Person p = (Person)iter.next();
System.out.println("name=" + p.name );
}
System.out.println("p1.hashCode=" + p1.hashCode());
System.out.println("p2.hashCode=" + p2.hashCode());
System.out.println("p3.hashCode=" + p3.hashCode());
System.out.println();
System.out.println("p1 equals p2," + p1.equals(p2));
System.out.println("p1 equals p3," + p1.equals(p3));
}
}
class Person {
String name;
//覆盖 hashCode
public int hashCode() {
return (name==null) ? 0:name.hashCode();
}
}
Ausgabe:

gleich unterschiedlicher HashCode gleich
Es ist ersichtlich, dass der obige Code immer noch doppelte Daten einfügt, da beim Einfügen von Daten zuerst der Hash-Code verglichen wird, und wenn sie gleich sind, werden die Gleichen verglichen. Nur wenn die Gleichen gleich sind, wird dies der Fall sein wird als Duplikat betrachtet, da die Gleichen unterschiedlich sind, sodass es nicht als dasselbe Objekt betrachtet wird, ohne wiederholte Einfügungen zu vermeiden.
2.4. Schreiben Sie equal und hashCode gleichzeitig neu
import java.util.*;
public class Test {
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "张三";
Person p2 = new Person();
p2.name = "李四";
Person p3 = new Person();
p3.name = "张三";
Set set = new HashSet();
set.add(p1);
set.add(p2);
set.add(p3);
for (Iterator iter=set.iterator(); iter.hasNext();) {
Person p = (Person)iter.next();
System.out.println("name=" + p.name );
}
System.out.println("p1.hashCode=" + p1.hashCode());
System.out.println("p2.hashCode=" + p2.hashCode());
System.out.println("p3.hashCode=" + p3.hashCode());
System.out.println();
System.out.println("p1 equals p2," + p1.equals(p2));
System.out.println("p1 equals p3," + p1.equals(p3));
}
}
class Person {
String name;
//覆盖 hashCode
public int hashCode() {
return (name==null) ? 0:name.hashCode();
}
//覆盖 equals
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Person) {
Person p = (Person)obj;
return this.name.equals(p.name);
}
return false;
}
}
Ausgabe:

Unterschiedliche Gleichheit und unterschiedlicher HashCode
Du bist fertig. Es wurde nur ein Zhang San eingefügt.
2.5. Zusammenfassung
Wenn die Equals-Methode und die HashCode-Methode gleichzeitig überschrieben werden , muss der allgemeine Vertrag von HashCode erfüllt sein :
(1) Wenn während der Ausführung einer Java-Anwendung die Methode hashCode mehrmals für dasselbe Objekt aufgerufen wird, muss dieselbe Ganzzahl konsistent zurückgegeben werden, vorausgesetzt, die zum Vergleich der Objekte mit Gleichen verwendeten Informationen wurden nicht geändert. Diese Ganzzahl muss nicht von einer Ausführung einer Anwendung zur anderen Ausführung derselben Anwendung konsistent sein.
(2) Wenn zwei Objekte gemäß der Methode equal(Object) gleich sind, muss der Aufruf der Methode hashCode für jedes der beiden Objekte das gleiche ganzzahlige Ergebnis liefern.
(3) Wenn zwei Objekte gemäß der Methode equal(java.lang.Object) nicht gleich sind , ist der Aufruf der Methode hashCode für eines der beiden Objekte nicht erforderlich, um unterschiedliche ganzzahlige Ergebnisse zu erzeugen. Programmierer sollten sich jedoch darüber im Klaren sein, dass die Erzeugung eindeutiger ganzzahliger Ergebnisse für ungleiche Objekte die Leistung von Hash-Tabellen verbessern kann .
Daher werden beim Umschreiben der Methode folgende Schlussfolgerungen gezogen:
Wenn zwei
(4) Müssen Sie hashCode neu schreiben, wenn Sie equal umschreiben?
Die Antwort lautet nicht unbedingt: Wenn Sie „equals“ nur umschreiben, um zu vergleichen, ob zwei Objekte gleich sind, müssen Sie beide Methoden umschreiben, wenn Sie Container wie hashSet und hashMap verwenden, um das Hinzufügen doppelter Elemente zu vermeiden.
Im Lernprozess, insbesondere beim Lernen von Sammlungen, ist equalsdies hashCodeschon immer eine häufige Methode gewesen, und bei Interviewfragen gibt es oft Probleme wie den Unterschied zwischen gleich und ==. Jetzt werden wir von der unteren Ebene aus mehr equalsdarüber erfahren. hashCodeZwei Wege.
1. Übersicht
Zunächst müssen wir wissen, dass equalszur hashCodeMethode der Object-Basisklasse zwei Methoden gehören:
public boolean equals(Object obj) {
return (this == obj);
}
public native int hashCode();
Aus dem Quellcode können wir erkennen, dass equalsdie Methode standardmäßig vergleicht, ob die Referenzen zweier Objekte auf dieselbe Speicheradresse verweisen. Es hashCodehandelt sich um eine native lokale Methode (die sogenannte lokale Methode bezieht sich auf ein Programm, das nicht in der Java-Sprache, sondern in anderen Sprachen wie C/C++ geschrieben wurde, im Allgemeinen für eine schnellere Interaktion mit der Maschine), tatsächlich die Standardmethode hashCodeWas zurückgegeben wird, ist die Speicheradresse, die dem Objekt entspricht (beachten Sie, dass es sich um 默认) handelt. Wir können dies auch indirekt über die Methode verstehen . Wir alle wissen, dass toString „Klassenname@hexadezimale Speicheradresse“ zurückgibt. Aus dem Quellcode können wir erkennen, dass die Speicheradresse mit dem Rückgabewert toStringübereinstimmt.hashCode()
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
Interviewfrage:
hashCodeGibt die Methode die Speicheradresse des Objekts zurück? Antwort: Die Methode der Object-BasisklassehashCodegibt standardmäßig die Speicheradresse des Objekts zurück. In einigen Szenarien müssen wirhashCodedie Funktion jedoch neu schreiben, z. B. wenn wir sieMapzum Speichern des Objekts verwenden müssenhashCodeAdresse des Objekts.
2. Detaillierte Erklärung von Gleichgestellten
equalsDie Methode ist eine Methode der Basisklasse Object, daher verfügen alle von uns erstellten Objekte über diese Methode und haben das Recht, diese Methode zu überschreiben. Zum Beispiel:
String str1 = "abc";
String str2 = "abc";
str1.equals(str2);
//结果为:true
Offensichtlich Stringmuss die Klasse equalsdie Methode neu geschrieben haben, andernfalls Stringmüssen die Speicheradressen der beiden Objekte unterschiedlich sein. Schauen wir uns die Methode Stringder Klasse an equals:
public boolean equals(Object anObject) {
//首先判断两个对象的内存地址(引用)是否相同
if (this == anObject) {
return true;
}
// 判断两个对象是否属于同一类型。
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//长度相同的情况下逐一比较 char 数组中的每个元素是否相同
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
Wir können dem Quellcode auch entnehmen, dass equalsdie Methode nicht nur aufgerufen wird this==obj, um festzustellen, ob die Objekte gleich sind. Praktisch alle vorhandenen Referenzdatentypen von Java überschreiben diese Methode. Welchem Prinzip sollten wir folgen, wenn wir den Referenzdatentyp selbst definieren, um festzustellen, ob zwei Objekte gleich sind, was erfordert, dass wir ihn entsprechend den Geschäftsanforderungen erfassen? Aber wir alle müssen diese Regeln befolgen:
- reflexiv .
x.equals(x)Muss für jeden Referenzwert x wahr sein, der nicht null ist . - Symmetrie . gilt auch für alle Nicht-Null-Referenzwerte x und y genau dann, wenn
x.equals(y)true .y.equals(x) - transitiv . Wenn für alle Nicht-Null-Referenzwerte x, y und z
x.equals(y)wahr ist undy.equals(z)gleichzeitig wahr ist,x.equals(z)muss es wahr sein. - Konsequent . Für alle Nicht-Null-Referenzwerte x und y wird, wenn die für den Gleichheitsvergleich verwendeten Objektinformationen nicht geändert wurden, entweder
x.equals(y)konsistent true oder bei mehrmaligem Aufruf konsistent false zurückgegeben. - Gibt für jeden Referenzwert x, der nicht null ist,
x.equals(null)false zurück .
2.1 gleicht und ==
equal wird oft verwendet, um es von == zu unterscheiden.
Wir alle wissen, dass Java-Datentypen in Basisdatentypen und Referenzdatentypen unterteilt werden können. Es gibt acht grundlegende Datentypen byte, short, int , long , float , double , boolean ,char. Bei primitiven Datentypen vergleicht == deren Werte.
Bei Referenztypen vergleicht == die Speicheradressen der Objekte, auf die sie verweisen.
int a = 10;
int b = 10;
float c = 10.0f;
System.out.println("(a == b) = " + (a == b));//true
System.out.println("(b == c) = " + (b == c));//true
String s1 = "123";
String s2 = "123";
System.out.println(s1==s2);//true
Der Unterschied zwischen equal und dem ==-Operator lässt sich wie folgt zusammenfassen:
- Wenn beide Seiten von == grundlegende Datentypen sind, wird beurteilt, ob die Werte der Operationsdaten auf der linken und rechten Seite gleich sind
- Wenn beide Seiten von == Referenzdatentypen sind, wird beurteilt, ob die Speicheradressen des linken und des rechten Operanden gleich sind. Wenn zu diesem Zeitpunkt „true“ zurückgegeben wird, muss der Operator dasselbe Objekt bearbeiten.
- Die Equals der Object-Basisklasse vergleichen standardmäßig die Speicheradressen zweier Objekte. Wenn das konstruierte Objekt die Equals-Methode nicht überschreibt, ist das Ergebnis des Vergleichs mit dem ==-Operator dasselbe.
- equal wird verwendet, um Referenzdatentypen auf Gleichheit zu vergleichen. Im ersteren System, das die Beurteilungsregeln von Gleichen erfüllt, betrachten wir die beiden Objekte als gleich, solange die angegebenen Attribute zweier Objekte gleich sind.
Hier ist eine klassische Interviewfrage:
String s1 = "abc";
String s2 = "abc";
System.out.println(s1==s2);//true
System.out.println(s1.equals(s2));//true
String s3 = new String("100");
String s4 = new String("100");
System.out.println(s3==s4);//false
System.out.println(s3.equals(s4));//true
3. HashCode-Methode
hashCodeDie Methode wird nicht equalsso häufig verwendet wie die Methode. Die Methode hashCode muss mit dem Java Map-Container kombiniert werden. Ähnlich wie HashMapdieser Container, der den Hash-Algorithmus verwendet, bestimmt er hashCodezunächst die Position des Objekts im Container anhand der Rückgabe Wert des Objekts und dann intern. Zugriff auf Elemente gemäß einem bestimmten Hash-Algorithmus erreichen.
3.1 Einführung in den Hash-Algorithmus
Der Hash-Algorithmus wird auch als Hash-Algorithmus bezeichnet. Grundsätzlich besteht der Hash-Algorithmus darin, den Schlüsselwert des Objekts selbst durch bestimmte mathematische Funktionsoperationen oder andere Methoden in die entsprechende Datenspeicheradresse umzuwandeln. Die vom Hash-Algorithmus verwendete mathematische Funktion wird als „Hash-Funktion“ bezeichnet und kann auch als Hash-Funktion bezeichnet werden.
Lassen Sie uns dies anhand eines Beispiels veranschaulichen:
{0,3,6,10,48,5}Wenn wir den Index des Werts gleich 10 im Array finden möchten, in dem die Elemente gespeichert sind , müssen wir das Array durchlaufen, um den entsprechenden Index zu erhalten. Wenn das Array sehr groß ist, ist es daher relativ ineffizient, das Array zu durchlaufen, was sich stark auf die Effizienz der Programmausführung auswirkt.
Wenn wir beim Speichern des Arrays Elemente nach bestimmten Regeln platzieren können und wenn wir ein bestimmtes Element finden möchten, können wir gemäß den zuvor festgelegten Regeln schnell das gewünschte Ergebnis erhalten. Mit anderen Worten, die Reihenfolge, in der wir Elemente im Array speichern, kann mit der Reihenfolge der Hinzufügung übereinstimmen, aber wenn wir gemäß einer vorgegebenen mathematischen Funktion arbeiten, erhalten wir die Zuordnungsbeziehung zwischen dem Wert des zu platzierenden Elements und dem Index des Arrays. Wenn wir dann ein Element mit einem bestimmten Wert nehmen möchten, können wir die Zuordnungsbeziehung verwenden, um das entsprechende Element schnell zu finden.
Unter den gängigen Hash-Funktionen gibt es eine der einfachsten Methoden namens „Dividieren der Restmethode“. Die Operationsmethode besteht darin, die zu speichernden Daten durch eine Konstante zu dividieren und den Rest als Indexwert zu verwenden. Sehen wir uns ein Beispiel an:
Speichern Sie 323, 458, 25, 340, 28, 969 und 77 mithilfe der „Divisionsmethode“ in einem Array mit einer Länge von 11. Wir gehen davon aus, dass eine bestimmte oben erwähnte Konstante die Array-Länge 11 ist. Der Ort, an dem jede Zahl durch 11 geteilt wird, wird wie in der folgenden Abbildung gezeigt gespeichert:
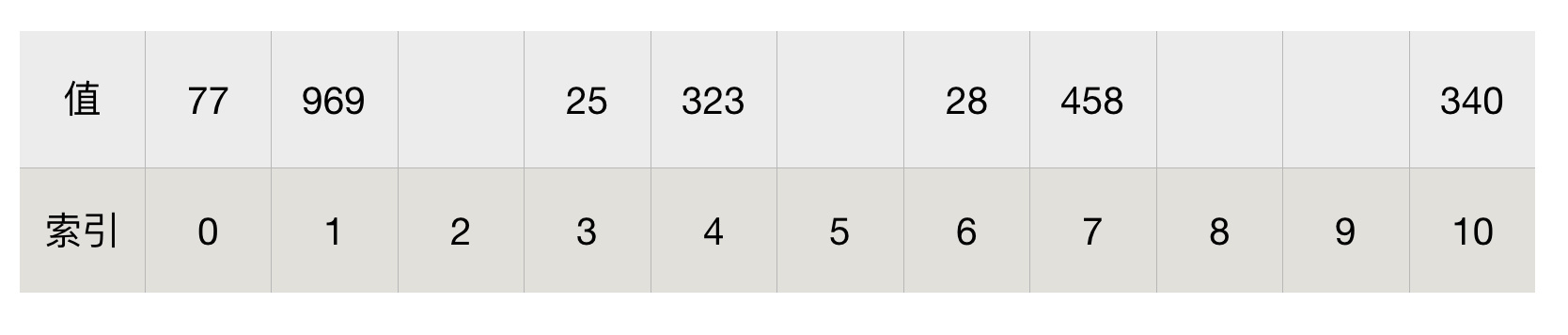
Stellen Sie sich vor, wir möchten jetzt die Position 77 im Array erhalten. Ist das alles, was wir brauchen arr[77%11] = 77?
Der oben erwähnte einfache Hash-Algorithmus hat jedoch offensichtliche Nachteile. Beispielsweise ist der Wert, der durch Berechnen des Rests von 11 aus 77 und 88 erhalten wird, 0, aber die Daten von 77 wurden im Index 0 gespeichert, sodass 88 nicht weiß, wo gehen. hoch. Das obige Phänomen hat im Hashing einen Begriff, der Kollision genannt wird:
Kollision: Wenn zwei verschiedene Daten nach der Verarbeitung durch dieselbe Hash-Funktion das gleiche Ergebnis erzielen, wird dieses Phänomen als Kollision bezeichnet.
Beim Entwerfen der Hash-Funktion sollten wir also so viel wie möglich tun:
- die Wahrscheinlichkeit einer Kollision verringern
- Versuchen Sie, die zu speichernden Elemente gleichmäßig im vorgesehenen Container (wir nennen sie Buckets) zu verteilen, nachdem die Hash-Funktionsoperation Ergebnisse liefert.
Kollisionen sind jedoch immer unvermeidbar. Wenn also hashCode verwendet wird, müssen andere Methoden verwendet werden, um das Kollisionsproblem zu lösen.
3.2 Die Beziehung zwischen der HashCode-Methode und dem Hash-Algorithmus
Eine Klasse mit einer HashCode-Methode in Java enthält einen Hash-Algorithmus. Wir können uns beispielsweise den HashCode-Algorithmus ansehen, der uns von String bereitgestellt wird:
public int hashCode() {
int h = hash;//默认是0
if (h == 0 && value.length > 0) {
char val[] = value;
// 字符串转化的 char 数组中每一个元素都参与运算
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Wie bereits erwähnt, ist die Methode hashCode eng mit der Sammlungsklasse verwandt, die Hash-Tabellen in Java verwendet. Nehmen wir Set als Beispiel. Wir alle wissen, dass doppelte Elemente nicht in Set gespeichert werden dürfen. Wie können wir also beurteilen, ob in der vorhandenen Set-Sammlung doppelte Elemente vorhanden sind? Manche Leute sagen vielleicht, dass wir anhand von Gleichen beurteilen können, ob zwei Elemente gleich sind. Dann stellt sich wieder die Frage: Wenn das Set bereits 10.000 Elemente enthält, wäre es dann nicht notwendig, die Methode equal nach dem Speichern eines Elements 10.000 Mal aufzurufen? Offensichtlich wird das nicht funktionieren, der Wirkungsgrad ist zu gering. Was können wir also tun, um sicherzustellen, dass es effizient ist und sich nicht wiederholt? Die Antwort liegt in der Funktion hashCode.
Nach der vorherigen Analyse wissen wir, dass der Hash-Algorithmus eine bestimmte Operation verwendet, um den Speicherort der Daten zu ermitteln, und dass die HashCode-Methode dann als diese bestimmte Funktionsoperation fungiert. Hier können wir einfach denken, dass der nach dem Aufruf der hashCode-Methode erhaltene Wert der Speicherort des Elements ist (tatsächlich wurden innerhalb der Sammlung weitere Berechnungen durchgeführt, um sicherzustellen, dass die Verteilung so gleichmäßig wie möglich ist, und es können unterschiedliche Hash-Algorithmen sein in verschiedenen Klassen verwendet).
Wenn das Set ein Element speichern muss, ruft es zunächst die Methode hashCode auf, um zu prüfen, ob an der entsprechenden Adresse ein Element gespeichert ist. Wenn nicht, bedeutet dies, dass das Set nicht dasselbe Element haben darf und es gut gespeichert werden kann es direkt an der entsprechenden Stelle. Aber wenn das Ergebnis von hashCode das gleiche ist, das heißt, es kommt zu einer Kollision, dann rufen wir weiter die Methode equal des Elements an dieser Stelle auf, um es mit dem zu speichernden Element zu vergleichen. Wenn sie das sind Sind sie gleich, werden sie nicht gespeichert. Wenn sie nicht gleich sind, müssen andere Adressen weiter gehasht werden. Auf diese Weise können wir die Methode ohne wiederholte Elemente so effizient wie möglich sicherstellen.
Interviewfrage: Die Funktion und Bedeutung der HashCode-Methode Antwort: Die Existenz von HashCode in Java wird hauptsächlich verwendet, um die Geschwindigkeit der Containersuche und -speicherung zu verbessern, z. B. HashSet, Hashtable, HashMap usw. HashCode wird zum Bestimmen von Objekten in verwendet Hash-Speicherstruktur der Speicheradresse.
3.3 Die Beziehung zwischen HashCode und der Methode equal
Es gibt einen solchen Kommentar zur Methode equal der Klasse Object:
Beachten Sie, dass beim Überschreiben dieser Methode normalerweise die Methode {@code hashCode} überschrieben werden muss, um den allgemeinen Vertrag der Methode {@code hashCode} aufrechtzuerhalten, der besagt, dass gleiche Objekte gleiche Hashcodes haben müssen.
Es ist ersichtlich, dass wir, wenn wir aus irgendeinem Grund die Methode „equals“ neu schreiben, die Methode hashCode gemäß der Vereinbarung neu schreiben und „equals“ verwenden müssen, um dieselben Objekte zu vergleichen, und dass wir gleiche Hash-Codes haben müssen.
Für das Objekt gelten außerdem mehrere Anforderungen an die Methode hashCode:
- Während der Ausführung einer Java-Anwendung müssen mehrere Aufrufe der hashCode-Methode für dasselbe Objekt stets dieselbe Ganzzahl zurückgeben, vorausgesetzt, die für die Gleichheit der Objekte verwendeten Informationen wurden nicht geändert. Diese Ganzzahl muss nicht von einer Ausführung einer Anwendung zur anderen Ausführung derselben Anwendung konsistent sein.
- Wenn zwei Objekte gemäß der Methode equal(Object) gleich sind, muss der Aufruf der Methode hashCode für jedes der beiden Objekte das gleiche ganzzahlige Ergebnis liefern.
- Wenn zwei Objekte gemäß der Methode equal(java.lang.Object) nicht gleich sind, ist der Aufruf der Methode hashCode für eines der beiden Objekte nicht erforderlich, um unterschiedliche ganzzahlige Ergebnisse zu erzeugen. Programmierer sollten sich jedoch darüber im Klaren sein, dass die Erzeugung eindeutiger ganzzahliger Ergebnisse für ungleiche Objekte die Leistung der Hash-Tabelle verbessern kann.
In Kombination mit der Methode „equals“ können wir die folgende Zusammenfassung erstellen:
- Zwei Objekte, für die ein Aufruf von equal „true“ zurückgibt, müssen gleiche Hashcodes haben.
- Wenn die HashCode-Rückgabewerte zweier Objekte gleich sind, gibt der Aufruf ihrer Methode „equals“ nicht unbedingt „true“ zurück.
Schauen wir uns die erste Schlussfolgerung an: Zwei Objekte, die „equals“ aufrufen, um „true“ zurückzugeben, müssen gleiche Hash-Codes haben. Warum so eine Anfrage? Nehmen wir als Beispiel die Set-Sammlung. Set ruft zunächst die hashCode-Methode des Objekts auf, um den Speicherort des Objekts zu ermitteln. Wenn zwei identische Objekte die hashCode-Methode aufrufen, um unterschiedliche Ergebnisse zu erhalten, ist das Ergebnis dasselbe Element wird im Set gespeichert. Und dieses Ergebnis ist definitiv falsch. Daher müssen zwei Objekte, die „equals“ aufrufen, um „true“ zurückzugeben, gleiche Hash-Codes haben .
Warum gibt das zweite Element hashCodedenselben Wert zurück, die beiden Objekte sind jedoch nicht unbedingt identisch? Dies liegt daran, dass es derzeit keinen perfekten Hash-Algorithmus gibt, der „Hash-Kollisionen“ vollständig vermeiden kann. Da Kollisionen nicht vollständig vermieden werden können, kann es sein, dass zwei verschiedene Objekte immer den gleichen Hash-Wert erhalten. Wir können also nur sicherstellen, dass verschiedene Objekte hashCodeso unterschiedlich wie möglich sind. Tatsächlich HashMapgeschieht dies beim Speichern von Schlüssel-Wert-Paaren. Vor JDK 1.7 HashMapbestand der Umgang mit Schlüssel-Hash-Wert-Kollisionen darin, die sogenannte „ Zipper-Methode “ zu verwenden. Die spezifische Implementierung wird HashMapspäter in der Analyse besprochen.