
1. Vue d'ensemble
Cet article analyse principalement le système de recommandation, présente principalement la définition du système de recommandation, le cadre de base du système de recommandation, et présente brièvement les méthodes et l'architecture associées de la recommandation de conception. Il convient à certains étudiants intéressés par le système de recommandation et à ceux qui ont des bases pertinentes. Mon niveau est limité et tout le monde est invité à me corriger.
2. Système de recommandation de produits
2.1 Définition du système de recommandation
Le système de recommandation résout essentiellement le problème de la surcharge d'informations, aide les utilisateurs à trouver les éléments qui les intéressent et exploite en profondeur les intérêts potentiels des utilisateurs.
2.2 Architecture recommandée
En fait, le processus central du système de recommandation est uniquement le rappel, le tri et le réarrangement.
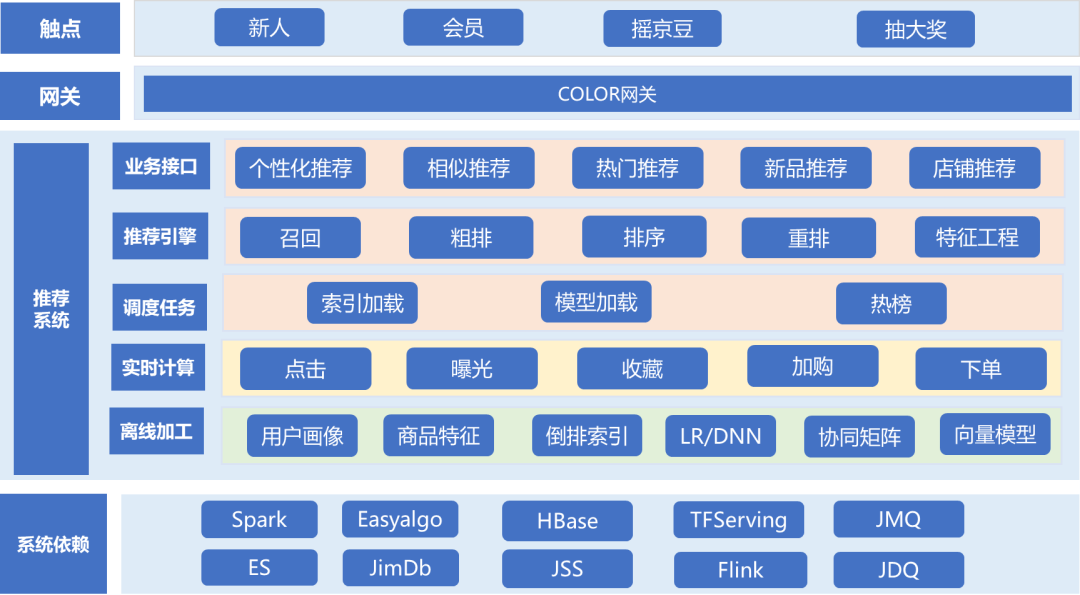
Processus de demande
Lorsqu'un utilisateur ouvre une page, le front-end portera les informations utilisateur (pin ou uuid, etc.) pour demander à l'interface back-end (appelée indirectement via la couleur), et lorsque le back-end recevra la demande, il le fera. généralement d'abord diviser et obtenir les configurations de politique pertinentes en fonction de l'ID utilisateur (stratégie ab), ces stratégies déterminent quelle interface du module de rappel, du module de tri et du module de réarrangement sera appelée ensuite. Le module de rappel général est divisé en plusieurs rappels, et chaque rappel est responsable du rappel de plusieurs produits, et le tri et la réorganisation sont responsables de l'ajustement de l'ordre de ces produits. Enfin, le produit approprié est sélectionné et les informations pertinentes telles que le prix et l'image sont complétées et affichées à l'utilisateur. Les utilisateurs choisiront de cliquer ou non selon qu'ils sont intéressés ou non. Ces comportements liés aux utilisateurs seront signalés à la plate-forme de données via des journaux, jetant ainsi les bases d'une analyse ultérieure des effets et d'une recommandation de produits utilisant le comportement des utilisateurs.
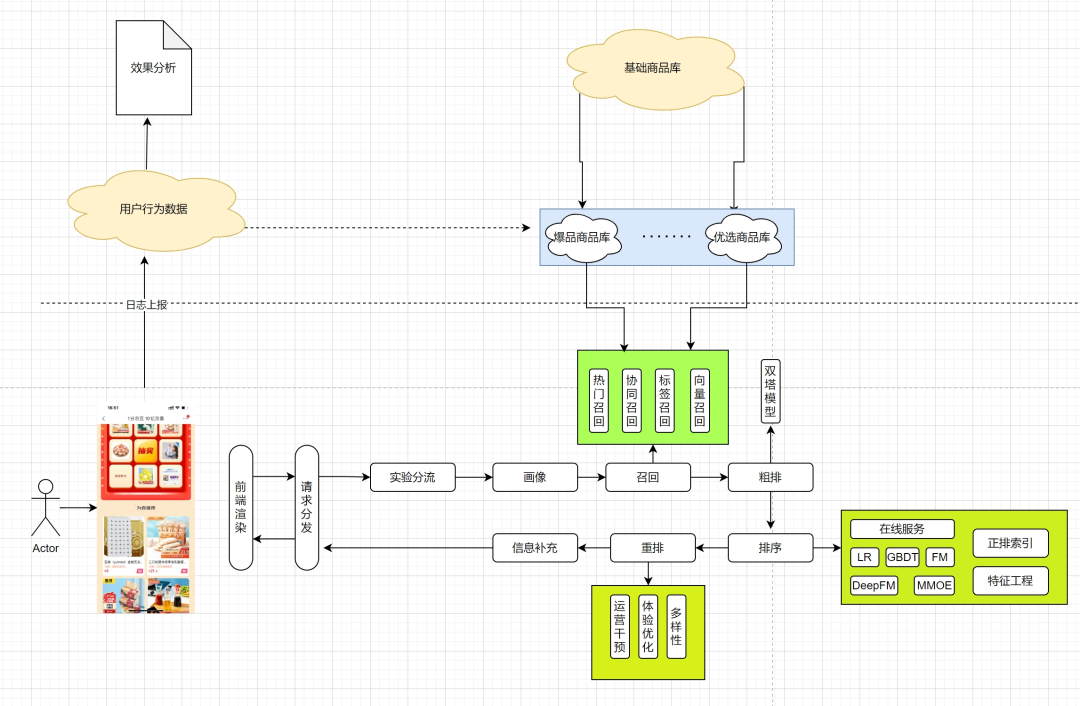
En fait, il y a quelques questions dont je veux parler :
Pourquoi adopter la hiérarchie en entonnoir de rappel, de tri et de réarrangement ?
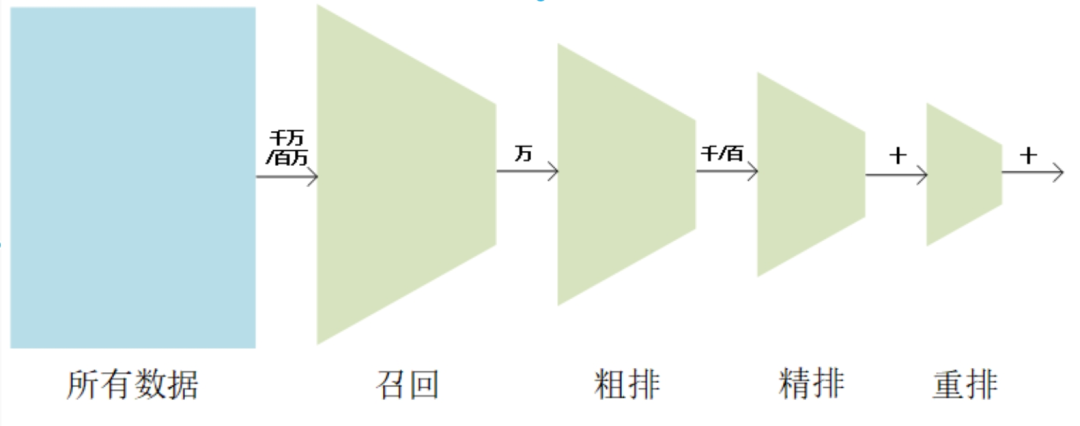
(1) En termes de performances
Niveau final : dans la bibliothèque de produits au niveau du million, sélectionnez les produits au niveau à un chiffre qui intéressent les utilisateurs.
L'inférence en ligne de modèles de tri complexes prend du temps et il est nécessaire de contrôler strictement le nombre de produits entrant dans le modèle de tri. il faut démonter
(2) Du point de vue de la cible
Module de rappel : La tâche du module de rappel est d'éliminer rapidement certains éléments candidats parmi un grand nombre d'éléments, dans le but de ne pas manquer d'éléments susceptibles d'intéresser les utilisateurs. Le module de rappel adopte généralement un rappel multidirectionnel, en utilisant des fonctionnalités ou des modèles simplifiés.
Module de tri : la tâche du module de tri est de trier avec précision et de trier les éléments candidats sélectionnés par le module de rappel en fonction du comportement historique, des intérêts, des préférences et d'autres informations de l'utilisateur. Les modules de tri utilisent généralement des modèles complexes.
Module de reclassement : La tâche du module de reclassement est de reclasser ou d'ajuster les résultats du module de classement pour améliorer encore la précision et la personnalisation des recommandations. Les modules de réarrangement utilisent généralement des algorithmes simples mais efficaces.
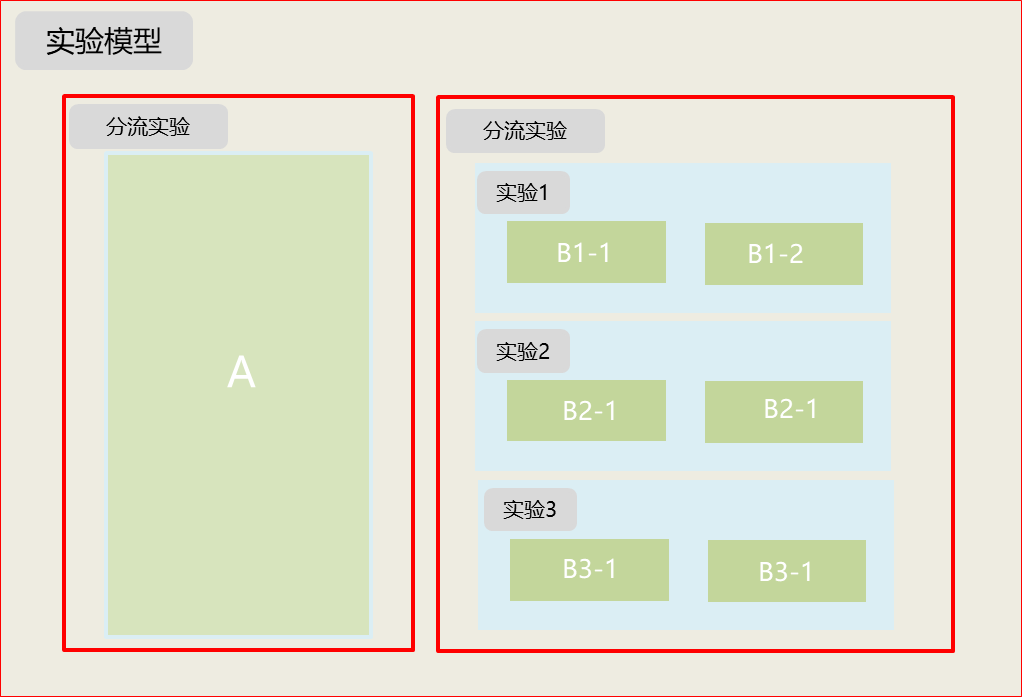
Qu'est-ce qu'une expérience abdominale ?
Référence : Infrastructure d'expérimentation superposée : expérimentations plus nombreuses, meilleures et plus rapides (google2010)
Seule l'expérience en ligne peut véritablement évaluer les avantages et les inconvénients du modèle, et l'expérience ab peut rapidement vérifier l'effet de l'expérience et itérer rapidement le modèle. Réduisez le risque de lancement de nouvelles fonctionnalités.
Algorithme ab : Hash (uuid+identifiant d'expérience+horodatage de création)%100
Caractéristiques : Shunt + Orthogonal

2.3 Rappel
L'existence de la couche de rappel permet uniquement aux utilisateurs de filtrer initialement un lot de bons produits provenant du vaste pool de produits. Afin d'équilibrer la contradiction entre la vitesse de calcul et le taux de rappel (la proportion d'échantillons positifs par rapport à tous les échantillons positifs), une stratégie de rappel multi-chemins est adoptée, et chaque stratégie de rappel ne considère qu'une seule fonctionnalité ou stratégie.
2.3.1 Avantages et inconvénients du rappel multicanal
Rappel multidirectionnel : utilisez différentes stratégies, fonctionnalités ou modèles simples pour rappeler une partie des ensembles candidats, puis mélangez les ensembles candidats pour le tri. Le taux de rappel est élevé, la vitesse est rapide et le rappel multidirectionnel se complète.
Dans le rappel multicanal, le nombre tronqué K de chaque rappel est un hyperparamètre, qui nécessite un réglage manuel des paramètres et un coût élevé ; il existe des problèmes de chevauchement et de redondance dans les canaux de rappel.
S'il existe une sorte de rappel pouvant remplacer le rappel multicanal, le rappel vectoriel a vu le jour, pour l'instant il reste basé sur le rappel vectoriel et d'autres rappels sont complétés.
2.3.2 Classification des rappels
Il est principalement divisé en deux catégories : le rappel non personnalisé et le rappel personnalisé. Les rappels non personnalisés concernent principalement des push push, et l'effet Matthew dans le domaine de la recommandation est sérieux, avec 20 % des produits contribuant à 80 % des clics. Le rappel personnalisé consiste principalement à découvrir les produits qui intéressent les utilisateurs, en se concentrant sur la gestion des différences de chaque utilisateur, en augmentant la diversité des produits et en maintenant la fidélité des utilisateurs.
rappel non personnalisé
(1) Rappels populaires : rappel de produits avec un nombre élevé de clics, de likes et de ventes élevées au cours des 7 derniers jours
(2) Rappel de nouveaux produits : Rappel des derniers produits en rayon
rappel personnalisé
(1) Rappel d'étiquette, rappel régional
Rappel d'étiquette : la catégorie, la marque, le rappel de magasin, etc. qui intéresse l'utilisateur
Rappel régional : Rappel de produits de qualité dans la région selon la région de l'utilisateur.
(2) cf rappel
L'algorithme de filtrage collaboratif est basé sur les données de comportement de l'utilisateur pour extraire les préférences comportementales de l'utilisateur, de manière à recommander des éléments en fonction des préférences comportementales de l'utilisateur, qui sont basées sur la matrice de comportement (matrice de cooccurrence) des utilisateurs et des éléments. Le comportement des utilisateurs inclut généralement la navigation, les likes, les achats supplémentaires, les clics, l'attention, le partage, etc.
Le filtrage collaboratif est divisé en trois catégories : le filtrage collaboratif basé sur l'utilisateur (UCF), le filtrage collaboratif basé sur les éléments (ICF) et le filtrage collaboratif basé sur un modèle (modèle sémantique caché). Que ce soit pour recommander un élément à un utilisateur, l'utilisateur et l'élément doivent d'abord être associés, et si le point associé est un autre élément ou un autre utilisateur détermine à quel type de filtrage collaboratif il appartient. Le modèle sémantique caché est basé sur les données de comportement de l'utilisateur pour regrouper et exploiter automatiquement les caractéristiques d'intérêt potentielles de l'utilisateur. Ainsi, les utilisateurs et les éléments sont associés via des fonctionnalités d’intérêt latent.
Filtrage collaboratif basé sur les éléments (ICF) : pour déterminer s'il convient de recommander un élément à un utilisateur, déduisez d'abord l'intérêt de l'utilisateur pour l'élément en fonction de la similitude entre l'élément enregistré dans le comportement historique de l'utilisateur et l'élément, afin de déterminer si nous recommandons l'article. L'ensemble du processus de filtrage collaboratif est principalement divisé en étapes suivantes : calcul de la similarité entre les éléments, calcul de l'intérêt de l'utilisateur pour les éléments, tri et interception des résultats.
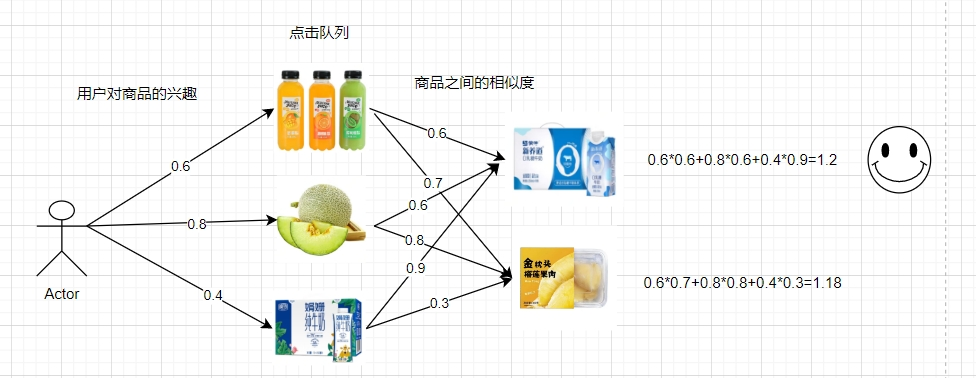
Calcul de similarité des matières premières :
Il existe principalement les méthodes suivantes pour mesurer la similarité : distance angle cosinus, formule de Jaccard. Du fait de la diversité des représentations des utilisateurs ou des objets, le calcul de ces similitudes est très souple. Nous pouvons utiliser la matrice de comportement des utilisateurs et des éléments pour calculer la similarité, et nous pouvons également construire des représentations vectorielles des utilisateurs et des éléments basées sur le comportement de l'utilisateur, les attributs des éléments et les relations contextuelles pour calculer la similarité.
Formule de distance angle cosinus :
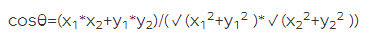
Formule de Jaccard J(A,B)=(|A⋂B|)/(|A⋃B|)
| Une marchandise |
Produit b | Produit c | Produit d | |
| Utilisateur A |
1 |
0 |
0 | 1 |
| Utilisateur B | 0 |
1 | 1 |
0 |
| Utilisateur C | 1 |
0 | 1 |
1 |
| Utilisateur D | 1 |
1 | 0 |
0 |
La formule de distance cosinusoïdale de l'angle inclus calcule la similarité entre les produits a et b :
Wab=(1*0+0*1+1*0+1*1)/(√(1^2+0^2+1^2+1^2 )*√(0^2+1^2+ 0^2+1^2 ))=1/√6
Spark implémente ICF : https://zhuanlan.zhihu.com/p/413159725
Problème : problème de démarrage à froid, effet longue traîne.
(3) Rappel de vecteur
Rappel vectorisé : en apprenant la représentation vectorisée de basse dimension des utilisateurs et des éléments, le rappel est modélisé comme un problème de recherche de voisin dans l'espace vectoriel, ce qui améliore efficacement la capacité de généralisation et la diversité du rappel, et constitue le canal de rappel principal du moteur de recommandation.
Vecteur : Tout peut être vectorisé. L'intégration consiste à utiliser un vecteur dense de faible dimension pour représenter un objet (un mot ou une marchandise). La fonction principale est de convertir un vecteur clairsemé en un vecteur dense (effet de réduction de dimensionnalité). La représentation contient ici une certaine signification profonde, de sorte qu'il peut exprimer une partie des caractéristiques de l'objet, et la distance entre les vecteurs reflète la similitude entre les objets.
Étape de rappel de vecteurs : formation hors ligne pour générer des vecteurs, récupération de vecteurs en ligne.
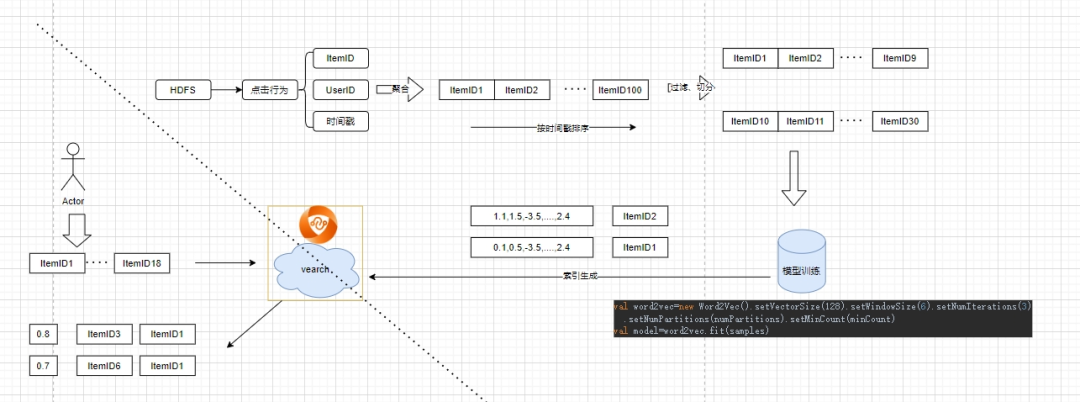
1. Formation hors ligne pour générer des vecteurs
word2vec : L'auteur du vecteur de mots se compose de trois couches de réseau neuronal : couche d'entrée, couche cachée, couche de sortie, la couche cachée n'a pas de fonction d'activation et la couche de sortie utilise softmax pour calculer la probabilité.
fonction objectif
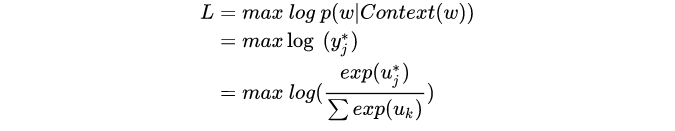
Structure du réseau :
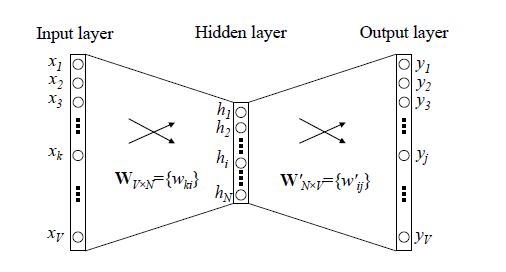
En général : l'entrée est une séquence de mots, et le vecteur correspondant à chaque mot peut être obtenu après entraînement du modèle. L'application dans le champ de recommandation consiste à saisir la séquence de clics de l'utilisateur et à obtenir le vecteur de chaque produit grâce à la formation de modèles.
Avantages et inconvénients : Simple et efficace, mais seules les séquences de comportement sont prises en compte et les autres fonctionnalités ne sont pas prises en compte.
Modèle de tours jumelles :
Structure du réseau : respectivement appelées User Tower et Item Tower ; User Tower reçoit des fonctionnalités côté utilisateur en entrée, telles que l'identifiant de l'utilisateur, le sexe, l'âge, les catégories d'intérêt de troisième niveau, la séquence de clics de l'utilisateur, l'adresse de l'utilisateur, etc. ; Item Tower accepte caractéristiques côté produit, telles que l'identifiant du produit, l'identifiant de la catégorie, le prix, le volume des commandes au cours des trois derniers jours, etc. Formation des données : (échantillon de données positif, 1) (échantillon négatif, 0) échantillon positif : le produit cliqué, échantillon négatif : échantillon de produit aléatoire global (ou autres échantillons de clics d'utilisateur dans le même lot)
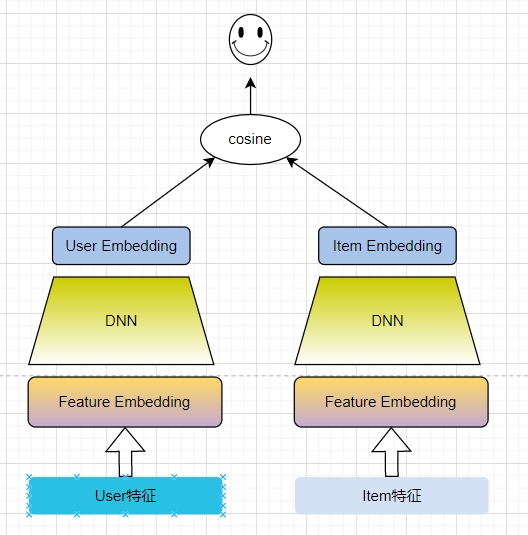
Avantages et inconvénients : Efficace, parfaitement adapté à la fonction de rappel, demande en ligne pour obtenir le vecteur utilisateur, récupérer et rappeler le vecteur article, généralisation élevée ; la tour utilisateur et la tour article sont séparées et n'interagissent qu'à la fin.
2. Récupération de vecteurs en ligne
Récupération de vecteurs : il s'agit d'une méthode de récupération d'informations basée sur le modèle spatial vectoriel, qui est utilisée pour trouver rapidement le vecteur de document le plus similaire au vecteur de requête dans une collection de textes à grande échelle. Il est largement utilisé dans la recherche d’informations, les systèmes de recommandation et la classification de textes.
Le processus de récupération de vecteurs consiste à calculer la similarité entre les vecteurs, et enfin à renvoyer le vecteur TopK avec une similarité plus élevée, et il existe de nombreuses façons de calculer la similarité des vecteurs. Les méthodes de calcul de la similarité vectorielle incluent la distance euclidienne, le produit scalaire et la distance cosinus. Après normalisation, le produit scalaire est équivalent à la formule de calcul de similarité cosinus.
L'essence de la récupération de vecteurs est la recherche de voisin approximatif (ANNS), qui réduit autant que possible la plage de recherche du vecteur de requête, améliorant ainsi la vitesse de requête.
Les algorithmes de récupération de vecteurs actuellement utilisés à grande échelle dans l’industrie peuvent être essentiellement divisés dans les trois catégories suivantes :
Hachage sensible à la localité (LSH)
Basé sur des graphiques (HNSW)
Quantification basée sur le produit
Une brève introduction à LSH
L'idée centrale de l'algorithme LSH est la suivante : après avoir transformé deux points de données adjacents dans l'espace de données d'origine via le même mappage ou projection, la probabilité que ces deux points de données soient toujours adjacents dans le nouvel espace de données est très élevée, et ils ne sont pas liés. La probabilité que des points de données adjacents soient mappés sur le même compartiment est très faible.
Par rapport à la recherche par force brute pour parcourir tous les points de l'ensemble de données, et en utilisant le hachage, nous trouvons d'abord dans quel compartiment l'échantillon de requête tombe. Si la division de l'espace est divisée selon la mesure de similarité souhaitée, l'échantillon de requête Le voisin le plus proche de tombera très probablement dans le compartiment de l'échantillon de requête, nous n'avons donc besoin de parcourir et de comparer que dans le compartiment actuel, au lieu de parcourir tous les ensembles de données. Lorsque le nombre de fonctions de hachage H est trop grand, la possibilité que l'échantillon de requête et son voisin le plus proche correspondant tombent dans le même compartiment deviendra très faible. Pour résoudre ce problème, nous pouvons répéter ce processus L fois (chaque fois est un hachage différent fonction), augmentant ainsi le taux de rappel du voisin le plus proche.
Cas : rappel de vecteur basé sur word2vec
2.4 Tri
La prunelle des yeux pour les systèmes de recommandation
L'étape de tri est divisée en tri grossier et tri fin. Le tri grossier se produit généralement lorsque l'ampleur des données des résultats de rappel est relativement importante.
Évolution
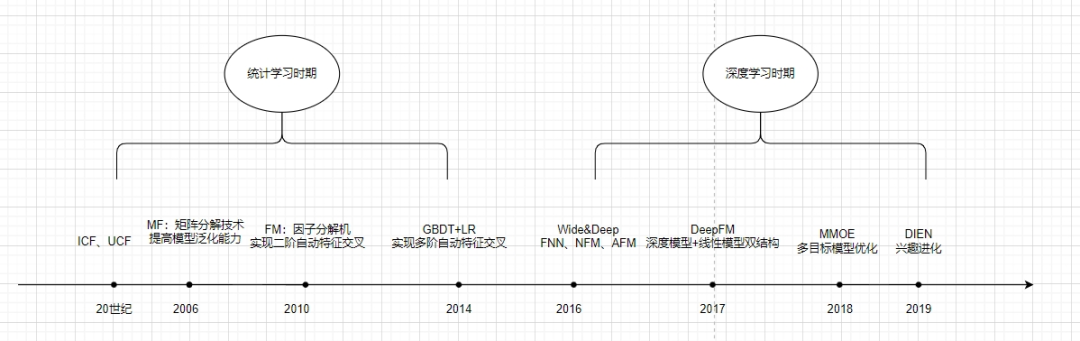
Une brève introduction à Wide&Deep
Contexte : La combinaison manuelle de fonctionnalités permet d'obtenir un bon effet de mémoire, mais l'ingénierie des fonctionnalités demande trop de main-d'œuvre et les combinaisons de fonctionnalités qui ne sont pas apparues auparavant ne peuvent pas être mémorisées et ne peuvent pas être généralisées.
Objectif : Faire en sorte que le modèle prenne en compte à la fois la généralisation et la capacité de mémoire (utilisation efficace des informations historiques et forte capacité d'expression)
(1) Le modèle de capacité de mémoire apprend et utilise directement la capacité de la fréquence de cooccurrence d'éléments ou de caractéristiques dans les données historiques pour mémoriser les caractéristiques de distribution des données historiques. Le modèle simple peut facilement trouver les caractéristiques ou les caractéristiques combinées dans les données qui avoir un plus grand impact sur les résultats et ajuster son poids pour obtenir une mémoire pour des fonctionnalités fortes
(2) La capacité de généralisation du modèle transfère la corrélation des caractéristiques et la capacité d'explorer la corrélation entre les caractéristiques clairsemées ou rares et l'étiquette finale.Même une entrée de vecteur de caractéristiques très clairsemée peut obtenir une probabilité de recommandation stable et fluide. Exemples de généralisation améliorée : factorisation matricielle, réseaux de neurones
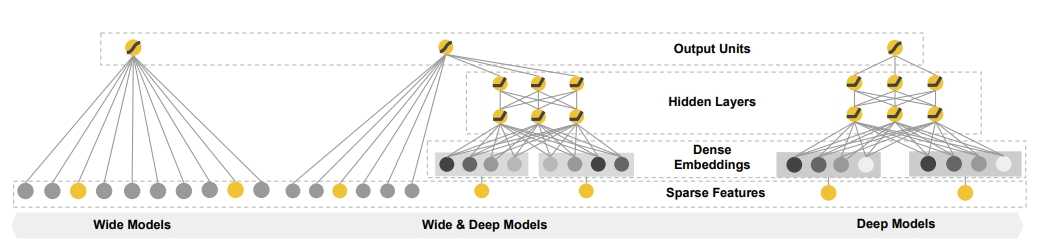
Basée à la fois sur les capacités de mémoire et de généralisation (précision des résultats et évolutivité), la partie large se concentre sur la mémoire du modèle, traitant rapidement un grand nombre de caractéristiques de comportement historiques, la partie profonde se concentre sur la généralisation du modèle, l'exploration de nouveaux mondes, la corrélation du transfert de modèle. caractéristiques et rareté de l'exploitation minière. La capacité de corréler des caractéristiques rares, même les plus éloignées, avec l'étiquette finale est puissamment expressive. Enfin, la partie large et la partie profonde sont combinées pour former un modèle unifié.
La partie large est le modèle linéaire de base, exprimé par y=W^T X+b. La partie caractéristique X comprend des fonctionnalités de base et des fonctionnalités croisées. La fonctionnalité croisée est très importante dans la partie large, qui peut capturer l'interaction entre les fonctionnalités et jouer le rôle d'ajout de non-linéarité.
La partie profonde est une couche d'intégration + un réseau neuronal à trois couches (relu), formule feed-forward
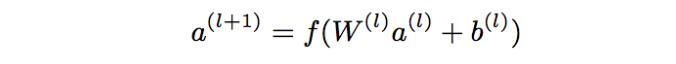
formation conjointe
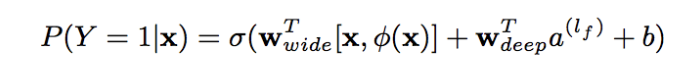
Avantages et inconvénients : il a jeté une base importante pour le développement d'algorithmes de recommandation/publicité/classement de recherche, et est passé des algorithmes traditionnels aux algorithmes d'apprentissage en profondeur, ce qui constitue une étape importante. En tenant compte à la fois des capacités de mémoire et de généralisation, mais le côté Wide doit encore combiner manuellement les fonctionnalités.
Document de référence : Apprentissage large et approfondi pour les systèmes de recommandation
2.5 Réarrangement
Définition : Affiner l'ordre des résultats après ajustement, d'une part pour parvenir à une optimisation globale, d'autre part pour répondre aux demandes métier et améliorer l'expérience utilisateur. Par exemple, stratégie de dispersion, stratégie d'insertion forte, augmentation de l'exposition, filtrage sensible
Algorithme MMR
Parvenir à la diversité des produits
Objectif : Assurer la diversité des résultats des recommandations tout en garantissant l’exactitude des résultats des recommandations, afin d’équilibrer la diversité et la pertinence des résultats des recommandations
Principes d'algorithme tels que les formules
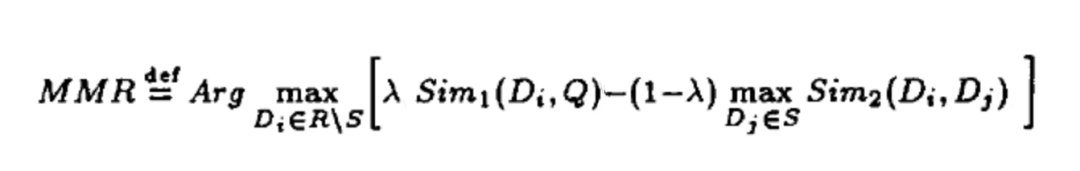
D : collection de produits, Q : utilisateur, S : collection de produits sélectionnés, R\S : collection de produits non sélectionnés dans R
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
#s 排序后列表 r 候选项
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
# 遍历所有剩余项
for i in r:
firstPart = itemScoreDict[i]
# 计算候选项与"已选项目"集合的最大相似度
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > second_part:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
# 添加新的候选项到结果集r,同时从s中删除
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]Le but est de sélectionner un élément qui est le plus pertinent pour l'utilisateur et le moins pertinent pour l'élément sélectionné. Complexité temporelle O(n2) peut réduire la complexité temporelle en limitant le nombre de choix
Implémentation technique : la corrélation entre les utilisateurs et les éléments et la similarité entre les éléments sont requises en entrée. La corrélation entre les utilisateurs et les éléments peut être remplacée par les résultats du modèle de tri, et la similarité entre les éléments peut être obtenue grâce à des algorithmes tels que le filtrage collaboratif. Vecteur de marchandise, pour calculer la distance cosinus. Cela peut aussi être aussi simple que de savoir s'il est représenté par la même catégorie de troisième niveau ou par le même magasin.
3. Résumé
C'est tout pour une brève discussion. Je veux que tout le monde comprenne le système de recommandation et présente l'ensemble de l'architecture de recommandation et les modules de l'ensemble de la recommandation. En raison de mon niveau limité, je n'ai pas expliqué chaque module en détail. J'espère pouvoir continuer à étudier ce domaine dans mon travail, approfondir les détails et produire de meilleures choses pour tout le monde.
-fin-