1. Descriptif
Dans cette série en 4 parties, nous allons parcourir la segmentation d'images à partir de zéro en utilisant des techniques d'apprentissage en profondeur dans PyTorch. Cette section se concentrera sur la façon de mettre en œuvre un modèle de segmentation d'image basé sur un transformateur visuel.

Figure 1 : Résultats de l'exécution de la segmentation d'images à l'aide de l'architecture du modèle Vision Transformer.
De haut en bas, l'image d'entrée, le masque de segmentation de vérité terrain et le masque de segmentation prédit. Source : Auteur
2. Aperçu de l'article
Dans cet article, nous allons faire le tour de l'architecture Transformer qui a pris d'assaut le monde de l'apprentissage en profondeur . Transformer est une architecture multimodale qui peut modéliser différentes modalités telles que la parole, la vision et l'audio.
Dans cet article, nous allons
- En savoir plus sur l'architecture du transformateur et les concepts clés impliqués
- Comprendre l'architecture du transformateur de vision
- Présentation d'un modèle Visual Converter écrit à partir de zéro afin que vous puissiez apprécier tous les blocs de construction et les pièces mobiles
- Gardez une trace du tenseur d'entrée fourni à ce modèle et vérifiez comment il change de forme
- Utilisez ce modèle pour effectuer une segmentation d'image sur l'ensemble de données Oxford IIIT Pets
- Observez le résultat de cette tâche de segmentation
- Une brève introduction à SegFormer, un transformateur visuel de pointe pour la segmentation sémantique
Dans cet article, nous nous référerons au code et aux résultats de ce notebook pour l'entraînement du modèle. Si vous souhaitez reproduire les résultats, vous aurez besoin d'un GPU pour vous assurer que le premier ordinateur portable fonctionne dans un délai raisonnable.
3. Cette série d'articles
Cette série s'adresse aux lecteurs de tous les niveaux d'expérience d'apprentissage en profondeur. Si vous souhaitez en savoir plus sur l'apprentissage en profondeur et l'IA visuelle en pratique avec une solide expérience théorique et pratique, vous êtes au bon endroit ! Ce sera une série en 4 parties avec les articles suivants :
- notions et idées
- Modèles basés sur CNN
- Convolution séparable en profondeur
- Modèles basés sur les transformateurs de vision (ce document)
Commençons notre visite guidée visuelle de Transformer par une introduction et une compréhension intuitive de l'architecture de Transformer.
4. Architecture du transformateur
Nous pouvons considérer l'architecture du transformateur comme une combinaison de couches de communication et de calcul entrelacées . La figure 2 illustre visuellement cette idée. Le transformateur a N unités de traitement (N dans la figure 3 est égal à 2), et chaque unité est responsable du traitement de 1/N parties de l'entrée. Pour que ces unités de traitement produisent des résultats significatifs, chaque unité de traitement doit avoir une vue globale de l'entrée . Ainsi, le système communique à plusieurs reprises des informations sur les données de chaque unité de traitement à toutes les autres unités de traitement ; cela est indiqué à l'aide de flèches rouges, vertes et bleues de chaque unité de traitement à toutes les autres unités de traitement. Voici quelques calculs basés sur ces informations. Après avoir suffisamment répété ce processus, le modèle a pu produire les résultats attendus.
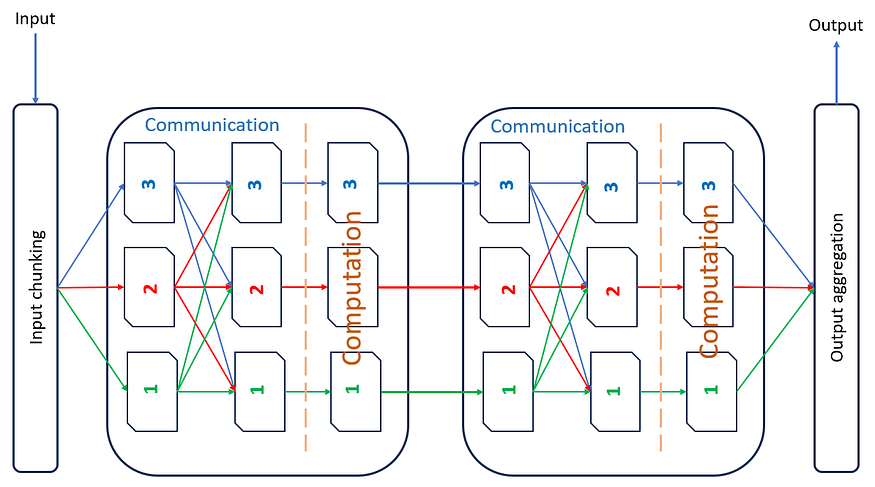
Figure 2 : Communication entrelacée et calcul dans un transformateur. L'image ne montre que 2 couches de communication et de calcul.
Il convient de noter que la plupart des ressources en ligne traitent généralement des encodeurs et des décodeurs de transformateur, comme décrit dans un article intitulé « L'attention est tout ce dont vous avez besoin » . Cependant, dans cet article, nous ne décrirons que la partie codeur du transformateur.
Examinons de plus près ce qui constitue la communication et le calcul dans Transformer.
4.1 Communication dans le transformateur : Remarque
Dans Transformer, la communication est implémentée par des couches appelées couches d'attention. Dans PyTorch, cela s'appelle MultiHeadAttention . Nous parlerons de la raison de ce nom plus tard.
Les docs disent :
"Permettre au modèle de se concentrer conjointement sur des informations provenant de différents sous-espaces de représentation, comme indiqué dans l'article : L'attention est tout ce dont vous avez besoin .
Le mécanisme d'attention prend un tenseur d'entrée x de forme (lot, longueur, caractéristiques) et produit un tenseur y de forme similaire , de sorte que les caractéristiques de chaque entrée sont mises à jour en fonction des autres entrées auxquelles le tenseur s'occupe dans la même instance. Ainsi, dans les instances de taille 'longueur', les caractéristiques de chaque tenseur de longueur 'caractéristiques' sont mises à jour par rapport à tous les autres tenseurs. C'est là qu'intervient le coût quadratique du mécanisme d'attention.
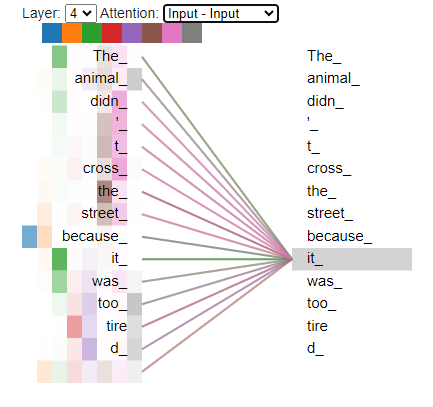
Figure 3 : Attention pour le mot "it" affiché par rapport aux autres mots de la phrase. On peut voir que "ça" fait attention aux mots "animal", "trop" et "tire(d)" dans la même phrase.
Dans le contexte des transformateurs de vision, l'entrée du transformateur est une image. Disons qu'il s'agit d'une image de 128 x 128 (largeur, hauteur). Nous l'avons divisé en plusieurs morceaux de plus petite taille (16 x 16). Pour une image 128 x 128, nous obtenons 64 patchs (longueur), 8 patchs par ligne et 8 patchs par ligne.
Chacun de ces 64 blocs de taille 16 x 16 pixels est considéré comme une entrée distincte du modèle de transformateur. Sans entrer dans les détails, il suffit de penser que ce processus est piloté par 64 unités de traitement différentes, chacune traitant un seul patch d'image 16x16.
À chaque tour, le mécanisme d'attention de chaque unité de traitement est chargé de regarder le patch d'image dont il est responsable et d'interroger chacune des 63 unités de traitement restantes pour toute information pertinente et utile pour l'aider à traiter efficacement sa propre image. patchs.
L'étape de communication par l'attention est suivie par le calcul, que nous examinerons ensuite.
4.2 Calcul dans les Transformateurs : Perceptrons Multicouches
Le calcul dans Transformer n'est rien de plus qu'une unité de perceptron multicouche (MLP). L'unité se compose de 2 couches linéaires avec une non-linéarité GeLU entre les deux. D'autres non-linéarités peuvent également être envisagées. L'unité projette d'abord l'entrée à 4x la taille, puis la reprojette à 1x, qui est la même taille que l'entrée.
Dans le code que nous verrons dans le cahier, cette classe s'appelle un perceptron multicouche. Le code est illustré ci-dessous.
class MultiLayerPerceptron(nn.Sequential):
def __init__(self, embed_size, dropout):
super().__init__(
nn.Linear(embed_size, embed_size * 4),
nn.GELU(),
nn.Linear(embed_size * 4, embed_size),
nn.Dropout(p=dropout),
)
# end def
# end classMaintenant que nous comprenons comment l'architecture Transformer fonctionne à un niveau élevé, concentrons-nous sur le Vision Transformer car nous allons effectuer une segmentation d'image.
5. Convertisseur de vision
Les transformateurs de vision ont été introduits à l'origine par un article intitulé "Images Worth 16x16 Words: Transformers for Large-Scale Image Recognition ". Cet article explique comment les auteurs ont appliqué l'architecture vanille Transformer au problème de la classification des images. Cela se fait en divisant l'image en patchs de taille 16x16 et en traitant chaque patch comme un jeton d'entrée pour le modèle. Le modèle Transformer-Encoder est alimenté par ces jetons d'entrée et invité à prédire la classe de l'image d'entrée.
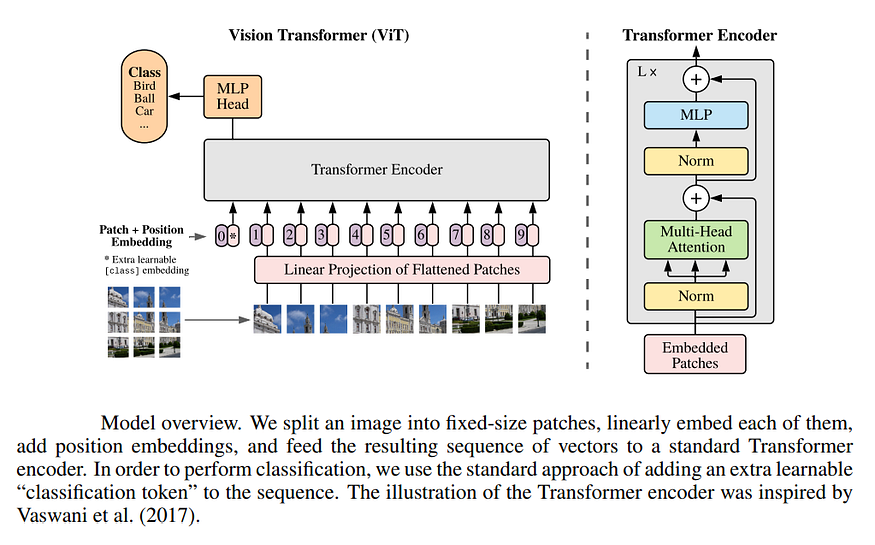
Figure 4 : Source : Transformateurs pour la reconnaissance d'images à grande échelle .
Dans notre cas, nous nous intéressons à la segmentation d'images. Nous pouvons considérer cela comme une tâche de classification au niveau des pixels, puisque nous avons l'intention de prédire la classe cible pour chaque pixel.
Nous avons apporté une modification mineure mais importante au convertisseur de vision vanille et remplacé l'en-tête MLP afin que la classification par pixel soit effectuée par l'en-tête MLP. Nous avons une couche linéaire en sortie, partagée par chaque patch, dont le masque de segmentation est prédit par le transformateur de vision. Cette couche linéaire partagée prédit un masque de segmentation pour chaque patch envoyé en entrée du modèle.
Dans le cas d'un transformateur visuel, un patch de taille 16x16 est considéré comme équivalent à un seul jeton d'entrée à un certain pas de temps.
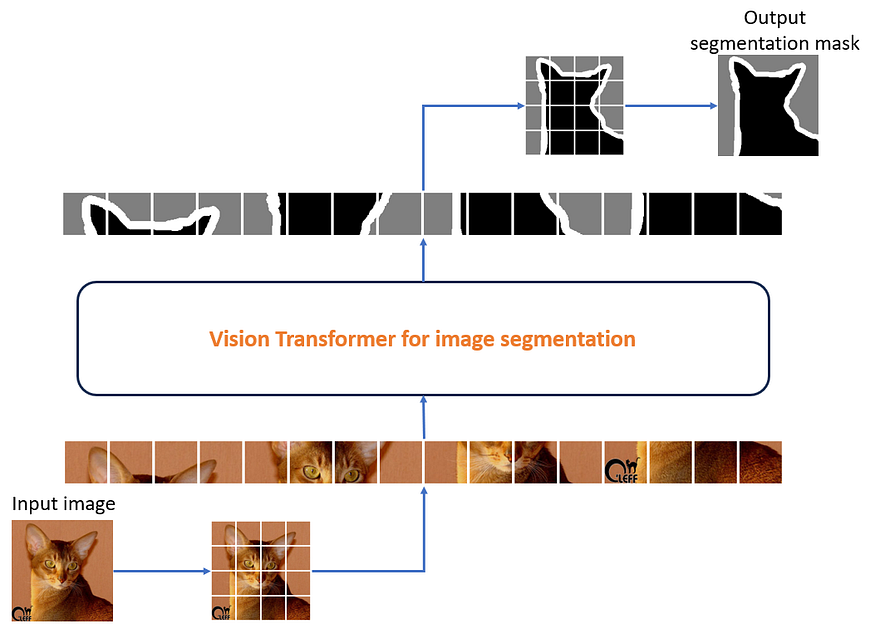
Figure 5 : Fonctionnement de bout en bout du Vision Transformer pour la segmentation d'images. Images générées à l'aide de ce bloc-notes .
5.1 Intuition pour construire des dimensions de tenseur dans un convertisseur visuel
Lorsque vous utilisez des CNN profonds, les dimensions du tenseur que nous utilisons principalement sont (N, CH, W), où les lettres signifient ce qui suit :
- N : taille du lot
- C : nombre de canaux
- H : Hauteur
- L : largeur
Vous pouvez voir ce format orienté vers le traitement d'image 2D, car il sent très spécifique aux caractéristiques de l'image.
D'autre part, avec les transformateurs, les choses deviennent plus génériques et indépendantes du domaine. Ce que nous verrons ci-dessous s'applique à la vision, au texte, à la PNL, à l'audio ou à d'autres problèmes où les données d'entrée peuvent être représentées sous forme de séquence. Remarquablement, il y a peu de biais spécifiques à la vision dans la représentation des tenseurs lorsqu'ils traversent notre convertisseur de vision.
En utilisant des transformateurs et en général, nous nous attendons à ce que les tenseurs aient la forme suivante : (B, T, C), où les lettres représentent ce qui suit :
- B : taille du lot (identique à CNN)
- T : dimension temporelle ou longueur de séquence. Cette dimension est aussi parfois appelée L. Dans le cas d'un transformateur visuel, chaque patch d'image correspond à cette dimension. Si nous avons 16 patchs d'image, la valeur de la dimension T sera de 16
- C : dimension de la taille du canal ou de l'encastrement. Cette dimension est aussi parfois appelée E. Lors du traitement d'une image, chaque patch de taille 3x16x16 (canaux, largeur, hauteur) est mappé sur un encastrement de taille C via une couche d'encastrement de patch. Nous verrons comment procéder plus tard.
Examinons en profondeur comment les tenseurs d'image d'entrée sont mutés et traités dans le processus de prédiction des masques de segmentation.
5.2 Le parcours des tenseurs dans Vision Converter
Dans un CNN profond, le parcours du tenseur ressemble à ceci (dans UNet, SegNet ou d'autres architectures basées sur CNN).
Le tenseur d'entrée est généralement de forme (1, 3, 128, 128). Ce tenseur passe par une série de convolutions et d'opérations de mise en commun maximale, où sa dimension spatiale est réduite et sa dimension de canal est augmentée, généralement d'un facteur 2 chacune. C'est ce qu'on appelle un encodeur de caractéristiques. Après cela, nous effectuons l'opération inverse, en augmentant la dimension spatiale et en diminuant la dimension du canal. C'est ce qu'on appelle un décodeur de fonctionnalités. Après le processus de décodage, nous obtenons un tenseur de forme (1, 64, 128, 128). Ceci est ensuite projeté dans notre nombre souhaité de canaux de sortie C, en utilisant une convolution ponctuelle non biaisée de 1x128 comme (128, C, 1, 1).
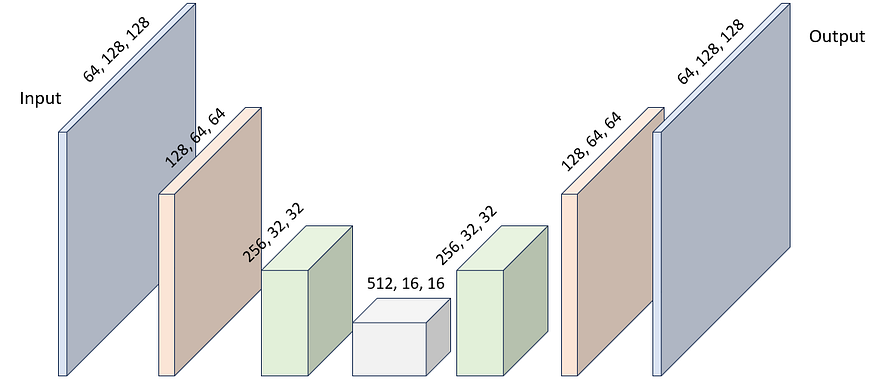
Figure 6 : Progression typique des formes de tenseur à travers un CNN profond pour la segmentation d'image.
Lors de l'utilisation d'un transformateur de vision, le processus est beaucoup plus compliqué. Examinons l'une des images ci-dessous et essayons de comprendre comment les tenseurs transforment la forme à chaque étape.
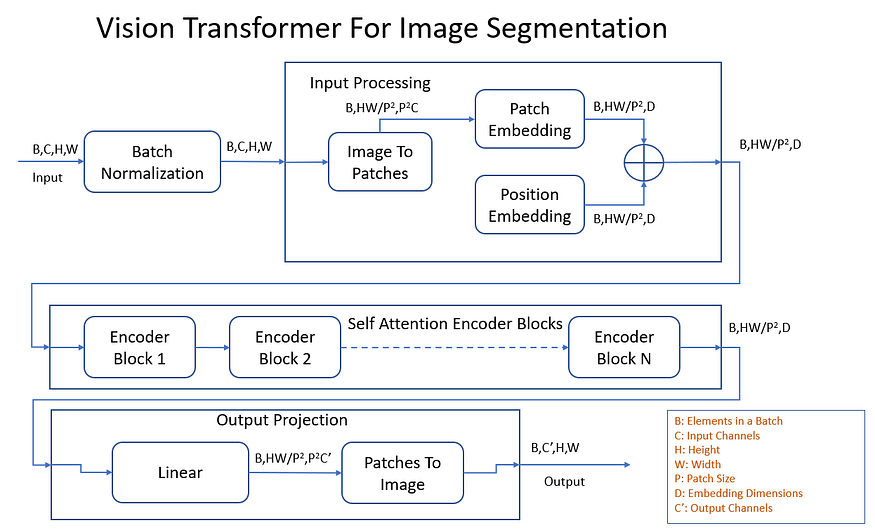
Figure 7 : Progression typique des formes de tenseur à travers un transformateur visuel pour la segmentation d'image.
Examinons chaque étape plus en détail et voyons comment elle met à jour la forme des tenseurs traversant le transformateur de vision. Pour mieux comprendre cela, prenons des valeurs concrètes pour les dimensions du tenseur.
- Normalisation par lots : les tenseurs d'entrée et de sortie ont la forme (1, 3, 128, 128). La forme reste la même, mais les valeurs sont normalisées à la moyenne nulle et à la variance unitaire.
- Image à patcher : un tenseur d'entrée de forme (1, 3, 128, 128) est converti en blocs empilés d'images 16x16. Le tenseur de sortie a la forme (1, 64, 768).
- Incorporation de patch : la couche d'intégration de patch mappe 768 canaux d'entrée sur 512 canaux d'intégration (dans cet exemple). La forme du tenseur de sortie est (1, 64, 512). La couche d'intégration de correctifs est essentiellement un NN. Couches linéaires dans PyTorch.
- Incorporation de position : la couche d'intégration de position ne prend aucun tenseur d'entrée, mais contribue efficacement à un paramètre apprenable (un tenseur entraînable dans PyTorch) avec la même forme que l'intégration de patch. C'est de forme (1, 64, 512).
- Ajouter : les patchs et les représentations incorporées de position sont additionnés par morceaux pour produire l'entrée de l'encodeur Vision Transformer. La forme de ce tenseur est (1, 64, 512). Vous remarquerez que le principal cheval de bataille du transformateur de vision, l'encodeur, maintient essentiellement cette forme de tenseur invariante.
- Encodeur de transformateur : un tenseur d'entrée de forme (1, 64, 512) traverse plusieurs blocs de transformateur-encodeur, chacun avec plusieurs têtes d'attention (communication), suivi d'une couche MLP (calcul). La forme du tenseur reste la même, comme (1, 64, 512).
- Projection de sortie linéaire : Si nous supposons que chaque image doit être divisée en 10 classes, nous avons besoin de 10 canaux par patch de taille 16x16. La couche nn.linear pour la projection de sortie convertira maintenant 512 canaux d'intégration en 16x16x10 = 2560 canaux de sortie, ce tenseur sera comme (1, 64, 2560). Dans le graphique ci-dessus, C' = 10. Idéalement, ce serait un perceptron multicouche puisque " les MLP sont des approximateurs de fonctions universels " , mais nous utilisons une seule couche linéaire car il s'agit d'un exercice pédagogique.
- Patch to Image : cette couche reconvertit 2560 patchs codés en tant que tenseurs (64, 1, 64) en quelque chose qui ressemble à un masque de segmentation. Il peut s'agir de 10 images monocanal, ou dans ce cas d'une seule image 10 canaux, où chaque canal est un masque de segmentation pour l'une des 10 classes. Le tenseur de sortie a la forme (1, 10, 128, 128).
C'est tout - nous avons réussi à segmenter l'image d'entrée à l'aide de Vision Transformer ! Ensuite, regardons une expérience et quelques résultats.
5.3 Applications pratiques des transformateurs de vision
Ce notebook contient tout le code de cette section.
En termes de structure de code et de classe, il imite étroitement le schéma fonctionnel ci-dessus. La plupart des concepts mentionnés ci-dessus correspondent 1:1 aux noms de classe dans ce cahier .
Il existe quelques concepts liés aux couches d'attention qui sont des hyperparamètres clés de notre modèle. Nous n'avons pas mentionné les détails de l'orientation des taureaux plus tôt, car le mentionner dépassait le cadre de cet article. Si vous n'avez pas une compréhension de base des mécanismes d'attention dans Transformers, nous vous recommandons fortement de lire les références ci-dessus avant de continuer.
Nous utilisons les paramètres de modèle suivants pour le transformateur de vision pour la segmentation.
- 768 dimensions d'intégration pour la couche d'intégration de patch
- 12 Bloc codeur transformateur
- 8 têtes d'attention dans chaque bloc d'encodeur de transformateur
- Attention multi-tête et 20% d'abandon en MLP
Cette configuration peut être vue dans la classe de données Python VisionTransformerArgs.
@dataclass
class VisionTransformerArgs:
"""Arguments to the VisionTransformerForSegmentation."""
image_size: int = 128
patch_size: int = 16
in_channels: int = 3
out_channels: int = 3
embed_size: int = 768
num_blocks: int = 12
num_heads: int = 8
dropout: float = 0.2
# end classUne configuration similaire à la précédente a été utilisée lors de la formation et de la validation du modèle . La configuration est spécifiée comme suit.
- Le retournement horizontal aléatoire et l'augmentation des données de gigue de couleur sont appliqués à l'ensemble d'apprentissage pour éviter le surajustement
- Redimensionner l'image à 128 x 128 pixels sans rapport d'aspect préservant l'opération de redimensionnement
- N'applique aucune normalisation d'entrée aux images, mais utilise à la place une couche de normalisation par lots comme première couche du modèle
- Le modèle est formé pour 12 époques à l'aide de l'optimiseur Adam avec un LR de 50,0 et du planificateur StepLR qui décroît le taux d'apprentissage d'un facteur de 0,8 toutes les 0004 époques
- La fonction de perte d'entropie croisée est utilisée pour classer les pixels comme appartenant à l'animal, à l'arrière-plan ou à la bordure de l'animal.
Le modèle a 86,28 M de paramètres et a une précision de validation de 89,50 % après 85 époques d'entraînement. Ceci est inférieur à la précision de 28,20% obtenue par le modèle CNN profond après 88 époques d'entraînement. Cela peut être dû à certains facteurs qui doivent être vérifiés expérimentalement.
- La dernière couche de projection de sortie est un seul NN. Perceptron linéaire au lieu de multicouche
- La taille du patch 16x16 est trop grande pour capturer des détails plus fins
- Période de formation insuffisante
- Pas assez de données d'entraînement - Les modèles Transformer sont connus pour nécessiter plus de données pour s'entraîner efficacement que les modèles CNN profonds
- Le taux d'apprentissage est trop faible
Nous dessinons un gif montrant comment le modèle apprend à prédire les masques de segmentation pour les 21 images de l'ensemble de validation.

Figure 8 : Un gif montrant la progression du masque de segmentation prédit par le transformateur visuel du modèle de segmentation d'image.
Nous avons remarqué quelque chose d'intéressant au début de la période de formation. Le masque de segmentation prédit a quelques artefacts de blocage étranges. La seule raison à laquelle nous pouvons penser est que nous décomposons l'image en patchs de taille 16x16 et après très peu d'époques d'entraînement, le modèle n'apprend rien d'utile sur ce patch 16x16 généralement caressé ou la superposition de pixels d'arrière-plan.

Figure 9 : Lors de l'utilisation d'un transformateur visuel pour la segmentation d'image, les artefacts d'occlusion vus dans la segmentation prédite sont masqués.
Maintenant que nous avons vu un transformateur visuel de base, tournons notre attention vers des transformateurs visuels de pointe pour les tâches de segmentation.
5.4 SegFormer : segmentation sémantique à l'aide de transformateurs
Cet article propose l'architecture SegFormer en 2021. Le convertisseur que nous avons vu ci-dessus est une version simplifiée de l'architecture SegFormer.
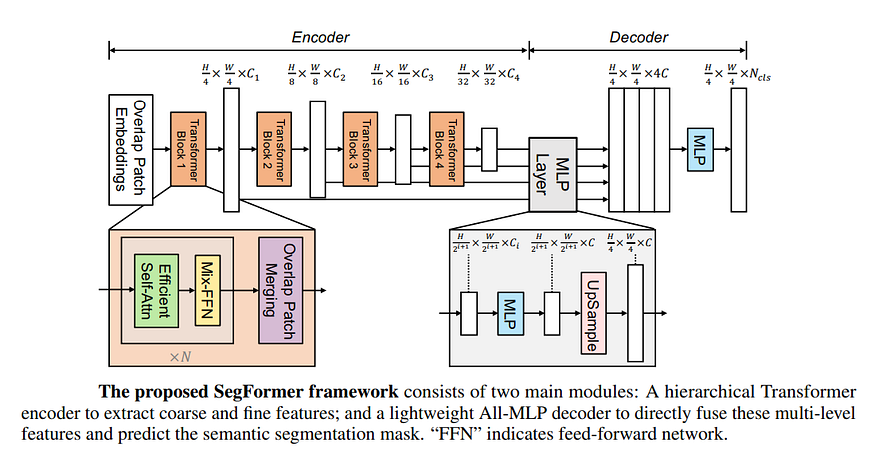
Figure 10 : Architecture SegFormer. source:
Plus particulièrement, SegFormer :
- Générez 4 ensembles d'images avec des patchs de taille 4x4, 8x8, 16x16 et 32x32 au lieu d'une seule image de patch avec des patchs de taille 16x16
- Utilisez 4 blocs d'encodeur de transformateur au lieu d'un seul. Cela ressemble à un ensemble modèle
- Utilisation des convolutions dans les phases pré et post-attention de soi
- Ne pas utiliser l'intégration de position
- Chaque module de transformateur traite les images à des résolutions spatiales H/4 x W/4, H/8 x W/8, H/16 x W/16 et H/32, W/32
- De même, les canaux augmentent à mesure que la dimension spatiale diminue. Cela ressemble à un CNN profond
- Suréchantillonnage des prédictions dans plusieurs dimensions spatiales, puis fusion de celles-ci dans le décodeur
- Le MLP combine toutes ces prévisions pour fournir la prévision finale
- La prédiction finale est en dimension spatiale H/4,W/4, pas en H,W.
6. Conclusion
Dans la partie 4 de cette série, nous avons couvert l'architecture des transformateurs et les transformateurs de vision en particulier. Nous acquérons une compréhension intuitive du fonctionnement des transformateurs de vision et des éléments de base impliqués dans les phases de communication et de calcul des transformateurs de vision. Nous avons vu une approche unique basée sur les patchs adoptée par les transformateurs visuels pour prédire les masques de segmentation, puis combiner les prédictions ensemble.
Nous passons en revue une expérience qui montre des transformateurs visuels en action et permet de comparer les résultats avec des approches CNN approfondies. Bien que notre convertisseur de vision ne soit pas à la pointe de la technologie, il est capable d'obtenir des résultats raisonnablement bons. Nous donnons un aperçu des méthodes de pointe telles que SegFormer.
Il devrait être clair maintenant que les transformateurs ont plus de pièces mobiles et sont plus complexes que les méthodes profondes basées sur CNN. D'un point de vue FLOP brut, le transformateur promet d'améliorer l'efficacité. Dans Transformer, la seule couche réelle qui est lourde en calcul est nn. linéaire. Ceci est implémenté à l'aide d'une multiplication matricielle optimisée sur la plupart des architectures. En raison de la simplicité de cette architecture, Transformer devrait être plus facile à optimiser et à accélérer par rapport aux méthodes profondes basées sur CNN.
Félicitations pour être arrivé aussi loin ! Nous sommes ravis que vous ayez apprécié la lecture de notre série sur la segmentation efficace des images dans PyTorch. Si vous avez des questions ou des commentaires, n'hésitez pas à les laisser dans la section des commentaires.
7. Lecture approfondie
Les détails du mécanisme d'attention dépassent le cadre de cet article. De plus, vous pouvez vous référer à de nombreuses ressources de haute qualité pour en savoir plus sur les mécanismes d'attention. En voici quelques-uns que nous recommandons vivement.
Nous fournirons ci-dessous des liens vers des articles qui fournissent plus de détails sur les convertisseurs visuels.
- Implémentation d'un transformateur de vision (ViT) dans PyTorch : cet article détaille l'implémentation d' un transformateur de vision pour la classification d'images dans PyTorch . Il convient de noter que leur implémentation utilise einops, que nous évitons car il s'agit d'un exercice axé sur l'éducation (nous recommandons d'apprendre et d'utiliser einops pour améliorer la lisibilité du code). Nous utilisons à la place des opérateurs PyTorch natifs pour permuter et réorganiser les dimensions du tenseur. De plus, les auteurs utilisent Conv2d au lieu de couches linéaires à certains endroits. Nous souhaitons construire une implémentation d'un transformateur de vision qui n'utilise pas du tout de couches convolutives.
- Convertisseur de vision : l'été de l'IA
- Implémentation de SegFormer dans PyTorch