Table des matières
Architecture fonctionnelle Flink
Architecture fonctionnelle Flink
Flink est un moteur de calcul distribué avec une architecture en couches. La mise en œuvre de chaque couche dépend des services fournis par la couche inférieure, tout en fournissant des interfaces et des services abstraits à utiliser par la couche supérieure.
L'architecture Flink peut être divisée en 4 couches, y compris la couche de déploiement Deploy, la couche Core Core, la couche API et la couche Library

- Couche de déploiement : implique principalement le mode de déploiement de Flink. Flink prend en charge plusieurs modes de déploiement, tels que local (local), cluster (Standalone/YARN), serveur cloud (GCE/EC2).
Vous pouvez démarrer une seule JVM, laisser Flink exécuter Flink en mode local ou s'exécuter en mode cluster autonome, et également prendre en charge Flink ON YARN. Les applications Flink peuvent être directement soumises à YARN pour s'exécuter. Flink peut également s'exécuter sur GCE (Google Cloud Service ) et EC2 (Amazon Cloud Services)
- Couche centrale : fournit toutes les implémentations principales qui prennent en charge l'informatique Flink, telles que la prise en charge du traitement de flux distribué, le mappage de JobGraph à ExecutionGraph, la planification, etc., et fournit des services de base pour les API de couche supérieure.
La couche Core (Runtime) fournit deux ensembles d'API principales en plus du Runtime, l'API DataStream (traitement de flux) et l'API DataSet (traitement par lots)
Couche de traitement de flux avec état : la couche inférieure d'abstraction ne fournit que des flux de données avec état, qui sont intégrés dans l'API de flux de données (API DataStream) via des fonctions de traitement. Les utilisateurs peuvent librement traiter un flux unique ou plusieurs flux via celui-ci, et maintenir la cohérence et la tolérance aux pannes. Dans le même temps, les utilisateurs peuvent enregistrer l'heure de l'événement et les rappels de temps de traitement pour mettre en œuvre une logique de calcul complexe
- Couche API : elle réalise principalement un traitement de flux orienté flux illimité et une API de traitement par lots orientée par lots, parmi lesquelles le traitement orienté flux correspond à l'API DataStream et le traitement orienté par lots correspond à l'API DataSet.
- Couche bibliothèque : cette couche peut également être appelée "couche de cadre d'application". Il s'agit d'un cadre d'implémentation informatique construit au-dessus de la couche API pour répondre à des applications spécifiques en fonction de la division de la couche API. Il correspond également au traitement de flux et au traitement par lots. respectivement Deux catégories. Le traitement orienté flux prend en charge le traitement d'événements complexes (Complex Event Processing, CEP), les opérations de type SQL (opérations relationnelles basées sur des tables) ; le traitement orienté batch prend en charge FlinkML (bibliothèque d'apprentissage automatique), Gelly (traitement de graphes).
SQL peut s'exécuter à la fois sur l'API DataStream et sur l'API DataSet.
Entrée et sortie Flink
Le scénario d'application le plus approprié pour Flink est le scénario de traitement des données à faible latence (traitement des données) : un pipeline à haute simultanéité traite les données avec une latence et une fiabilité de l'ordre de la milliseconde.
En tant que membre de l'écosystème Big Data, Flink peut être utilisé en combinaison avec d'autres composants de l'écosystème en plus de lui-même. En termes généraux, il existe des aspects d'entrée et de sortie.
Les schémas fonctionnels sur les côtés gauche et droit de la figure suivante montrent que le fond vert est la scène du traitement de flux et le fond bleu est la scène du traitement par lots.
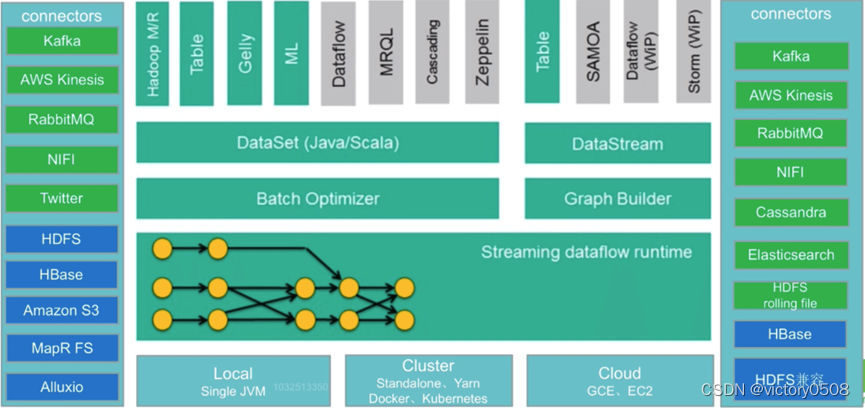
Entrez les connecteurs sur la gauche
Méthodes de traitement de flux : y compris Kafka (file d'attente de messages), AWS kinesis (service de flux de données en temps réel), RabbitMQ (file d'attente de messages), NIFI (pipeline de données), Twitter (API)
Méthode de traitement par lots : y compris HDFS (système de fichiers distribué), HBase (base de données en colonnes distribuée), Amazon S3 (système de fichiers), MapR FS (système de fichiers), ALLuxio (système de fichiers distribué basé sur la mémoire)
Connecteurs de sortie à droite
Méthodes de traitement de flux : y compris Kafka (file d'attente de messages), AWS kinesis (service de flux de données en temps réel), RabbitMQ (file d'attente de messages), NIFI (pipeline de données), Cassandra (base de données NOSQL), ElasticSearch (recherche en texte intégral), roulement HDFS fichier (fichier roulant)
Méthode de traitement par lots : y compris HBase (base de données en colonnes distribuée), HDFS (système de fichiers distribué)