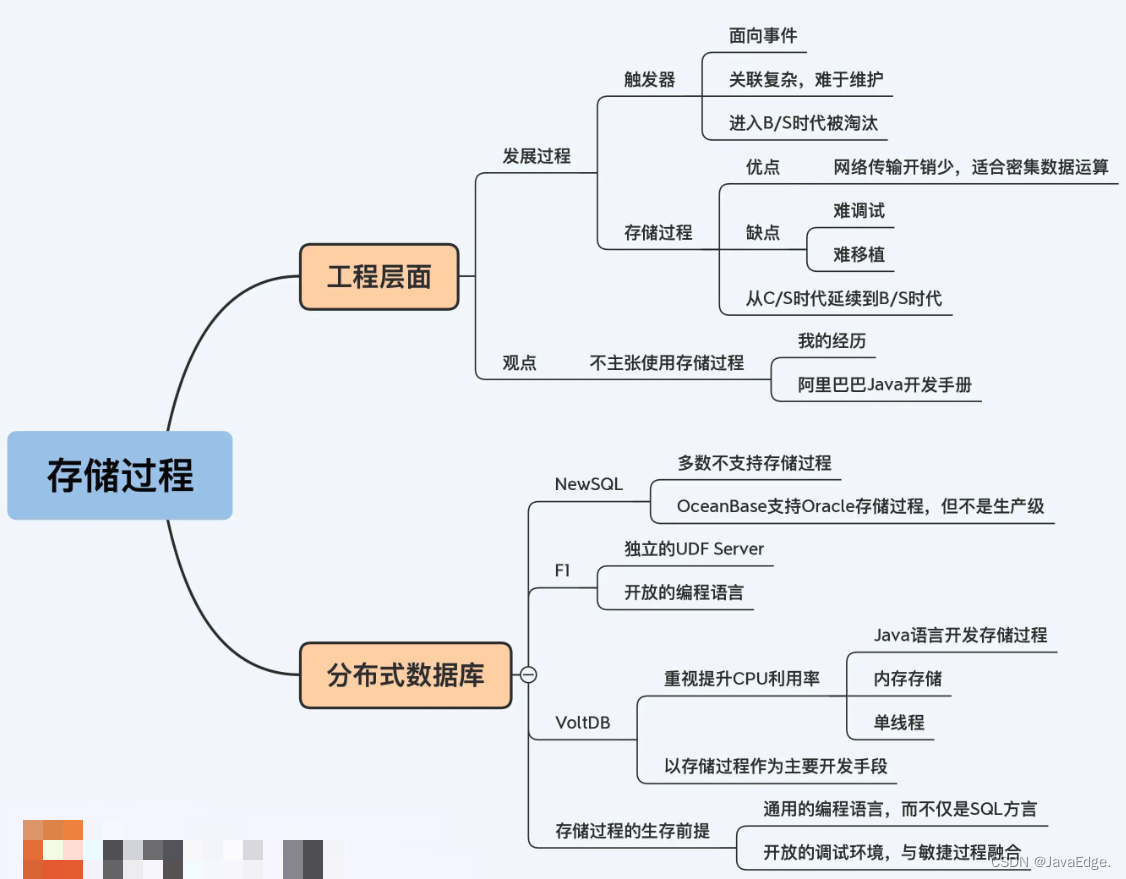
La procédure stockée est très bonne, ceux qui ne l'utilisent pas bien ont des compétences médiocres et n'acceptent pas les réfutations ! J'ai eu cette idée, mais pour les bases de données distribuées, je préfère utiliser moins ou pas de procédures stockées.
1 Je viens de l'ère C/S
Les kits de développement les plus populaires à la fin de l'ère de l'architecture C/S sont les bases de données PowerBuilder et Sybase :
- Outil de développement visuel PowerBuilder, comme VB, le programme développé s'exécute sur le terminal PC de l'utilisateur et se connecte à la base de données distante via le pilote
- Sybase était en concurrence avec Oracle pour la tête de la base de données à cette époque et avait une relation profonde avec SQL Server, et les deux étaient très similaires en architecture et en langage.
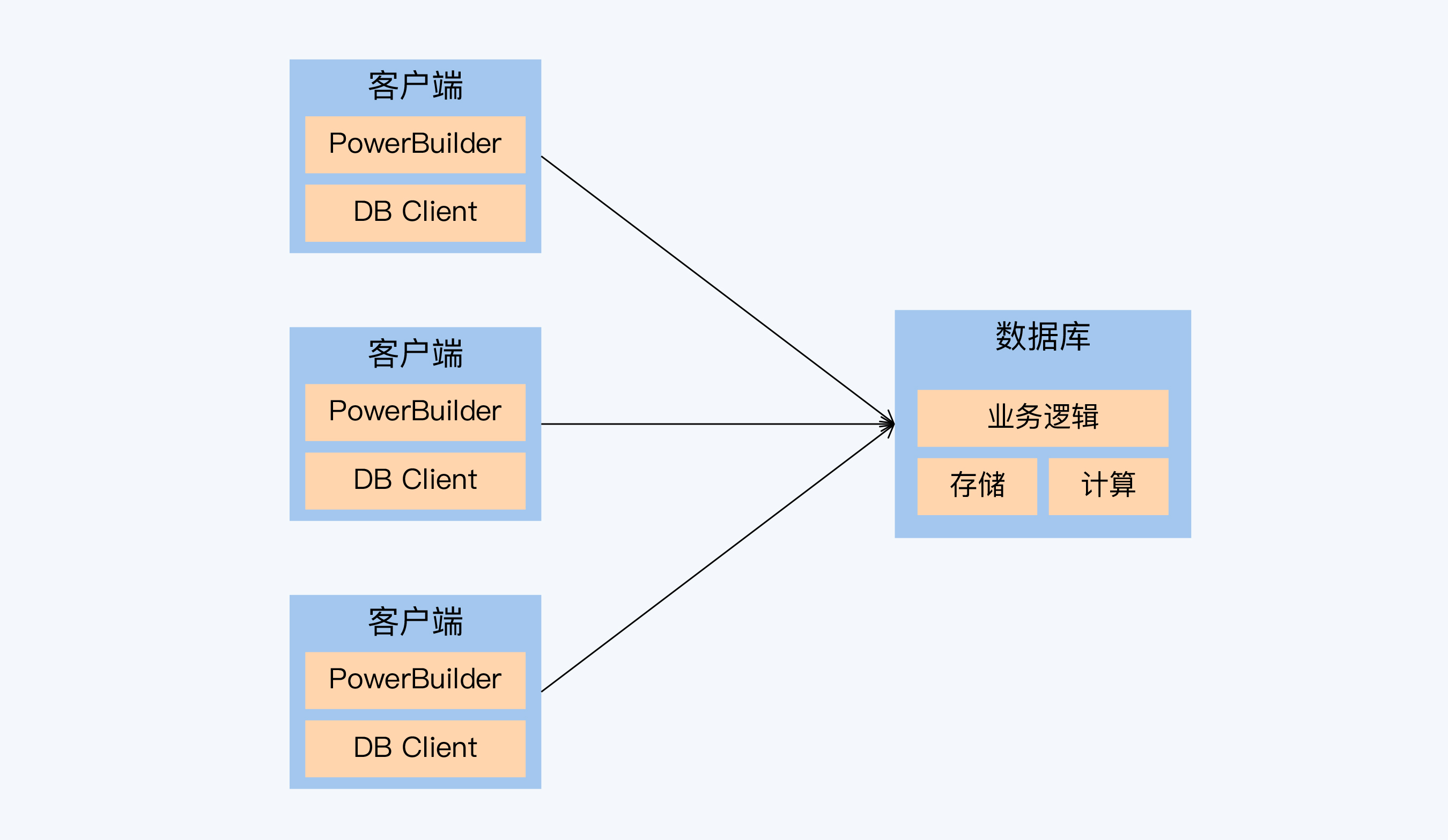
Dans cette architecture C/S, la base de données assure non seulement des fonctions de stockage de données et de calcul, mais exécute également une logique métier lourde, ce qui équivaut à ce que la base de données assume la plupart des fonctions du serveur d'application (Application Server). Le support technique de ces logiques métiers est la procédure stockée. Par conséquent, que ce soit Sybase ou Oracle, leurs procédures stockées sont très puissantes.
2 déclencheurs sont rejetés
En entrant dans B/S, la compréhension de la base de données par tout le monde a changé et le serveur d'applications porte la logique métier principale du serveur. Utilisez-vous toujours des procédures stockées ? Même problème qu'aujourd'hui. L'opinion dominante à l'époque était que les procédures stockées avaient toujours de la valeur, mais que leurs déclencheurs frères étaient complètement abandonnés.

Les déclencheurs sont des fonctions personnalisées comme les procédures stockées, mais :
- Il n'est pas appelé explicitement, mais déclenché passivement lorsque la table de données est exploitée, c'est-à-dire lorsque l'insertion, la mise à jour et la suppression sont exécutées
- Vous pouvez également choisir si le moment du déclenchement est avant ou après l'opération, c'est-à-dire la sémantique d'avant et d'après
Cela semble puissant, une programmation un peu orientée événement. Mais après avoir maintenu la logique de déclenchement, j'ai trouvé que c'était un gros gouffre. Au fur et à mesure que l'entreprise se développe et change, la logique du déclencheur devient de plus en plus complexe. Quelqu'un manipulera une autre table dans la logique du déclencheur, et il y a d'autres déclencheurs sur cette table qui impliquent d'autres tables, formant un skynet. Un petit faux pas, après une série de réactions en chaîne, devient une catastrophe. Par conséquent, le déclencheur s'est retiré de la scène de l'histoire. (J'ai toujours l'impression qu'il n'y a pas trop de restrictions, ce qui conduit à des abus)
3 Avantages des procédures stockées
L'appel est clair et il n'y a pas de problème de déclenchement. Les avantages sont évidents, la logique s'exécute dans la base de données et il n'y a pas de surcharge de données de transmission réseau, de sorte que l'avantage en termes de performances est exceptionnel lors de l'exécution d'opérations gourmandes en données.
À cette époque, il était nécessaire de développer des fonctions et de tracer la relation d'influence entre les entités commerciales. Par exemple, A affecte B et B affecte C. Cette fonction consiste à utiliser A comme entrée pour découvrir à la fois B et C. Bien sûr, la relation d'influence n'est pas limitée à trois couches et doit être retracée à toutes les entités affectées.
Les requêtes relationnelles typiques conviennent aux bases de données de graphes. Mais à cette époque, il n'y avait pas de base de données de graphes disponible, et ce problème devait être résolu dans Oracle. Un collègue plus jeune que moi a écrit un morceau de code Java pour réaliser cette fonction, je suppose qu'il n'a pas connu l'ère C/S. Après l'exécution du programme, le serveur d'application accède en permanence à cette table pour traiter la relation d'association de chaque enregistrement. On peut imaginer les performances : dans un environnement de test avec une petite quantité de données, le programme a duré 30 minutes. Ceci est bien au-delà de la tolérance de l'utilisateur et doit être optimisé.
Je suis passé à une procédure stockée pour obtenir la même logique, car aucune transmission réseau n'est requise et les performances sont grandement améliorées. Au final, la procédure stockée a mis une vingtaine de secondes pour obtenir le même résultat. Bien joué! .
4 Problèmes avec les procédures stockées
On a découvert plus tard que ce programme était mal transplantable. Les produits développés doivent être déployés dans l'environnement du client, sous réserve des contraintes du logiciel de base concerné.
Une fois, il est arrivé que le client n'utilise pas Oracle, alors d'autres collègues ont traduit la logique que j'ai écrite dans la base de données utilisée par le client. La procédure stockée qui peut être transplantée dans TDB ne parvient pas à se fermer sans aucun résultat. Après avoir suivi ce code, j'ai finalement trouvé que le problème n'était pas dans la logique elle-même, mais dans la base de données. J'ai utilisé un algorithme récursif dans cette logique, car Oracle prend en charge un niveau récursif profond, il n'y a donc aucun problème d'exécution ; alors que TDB ne prend en charge qu'un niveau récursif limité, et qu'il y avait de nombreuses associations de données à ce moment-là, le programme a donc signalé une erreur et quitté après une courte période de temps. .
Cette expérience a un peu ébranlé ma confiance dans les procédures stockées. Les procédures stockées dépendent fortement de l'environnement, et cet environnement n'est pas un environnement ouvert qui suit une norme unifiée et contient une grande quantité d'informations techniques telles que le système d'exploitation et la machine virtuelle Java, mais une boîte noire qui n'est pas si standard comme base de données.
Cependant, les problèmes avec les procédures stockées ne s'arrêtent pas là. Lorsque je développais sous l'architecture C/S, j'ai rencontré le problème que la procédure stockée était difficile à déboguer, mais à cette époque tout le monde pensait que c'était le prix à payer. Cependant, avec l'avènement de l'architecture B/S et le développement continu de la technologie de développement et de test de code Java, le problème du débogage difficile des procédures stockées est devenu plus important. Aujourd'hui, le développement agile devient de plus en plus populaire, la chaîne d'outils DevOps se développe rapidement et la procédure stockée est toujours "indépendante".
Cela dit, ce que j'espère que vous comprenez, c'est que les procédures stockées d'aujourd'hui et les déclencheurs de cette année-là sont essentiellement confrontés au même problème : une technologie doit correspondre au niveau d' ingénierie de l'époque et s'intégrer à l'ensemble de l'écologie technologique, sinon elle sortira la plupart des scénarios d'application .
Vous voyez, dans le "Alibaba Java Development Manual", il est également écrit de manière impressionnante que "l'utilisation de procédures stockées est interdite. Les procédures stockées sont difficiles à déboguer et à développer, et elles ne sont pas portables. " Je pense qu'ils ont probablement un similaire mentalité pour moi.
5 Prise en charge des bases de données distribuées
La plupart des bases de données distribuées NewSQL ne prennent toujours pas en charge les procédures stockées. L'exception est OceanBase, qui a ajouté la prise en charge des procédures stockées Oracle dans la version 2.2. Je pense que c'est un produit de sa compatibilité globale avec la stratégie d'Oracle. Cependant, la déclaration officielle d'OceanBase indique très clairement que la fonction de la procédure stockée ne répond pas aux exigences de production à l'heure actuelle.
La compatibilité avec les systèmes hérités peut être la plus grande importance des procédures stockées aujourd'hui. Pour les systèmes migrant de MySQL vers des bases de données distribuées, cet attrait peut ne pas être aussi fort, car ces systèmes ne reposent pas tellement sur des procédures stockées. Étant donné que MySQL ne fournit que des procédures stockées dans une version ultérieure et que les fonctions ne sont pas aussi puissantes qu'Oracle, la dépendance de l'utilisateur est beaucoup plus faible. Les procédures stockées ne sont pas largement supportées par NewSQL, mais aussi en raison de difficultés architecturales.
Voyez ce que l'industrie essaie.
Google a publié un nouvel article F1 « F1 Query : Declarative Querying at Scale » sur VLDB en 2018 . Il est proposé de prendre en charge les fonctions personnalisées, à savoir les procédures stockées, via un serveur UDF indépendant. Dans cette architecture, parce que F1 est complètement indépendant du stockage des données, UDF Server est naturellement extrait. À en juger par les données de test fournies dans l'article, cette conception maintient des performances élevées, mais je pense que cela a beaucoup à voir avec les puissantes installations de réseau de Google. Il est difficile de dire si cela peut être appliqué dans des conditions de réseau d'entreprise ordinaires.
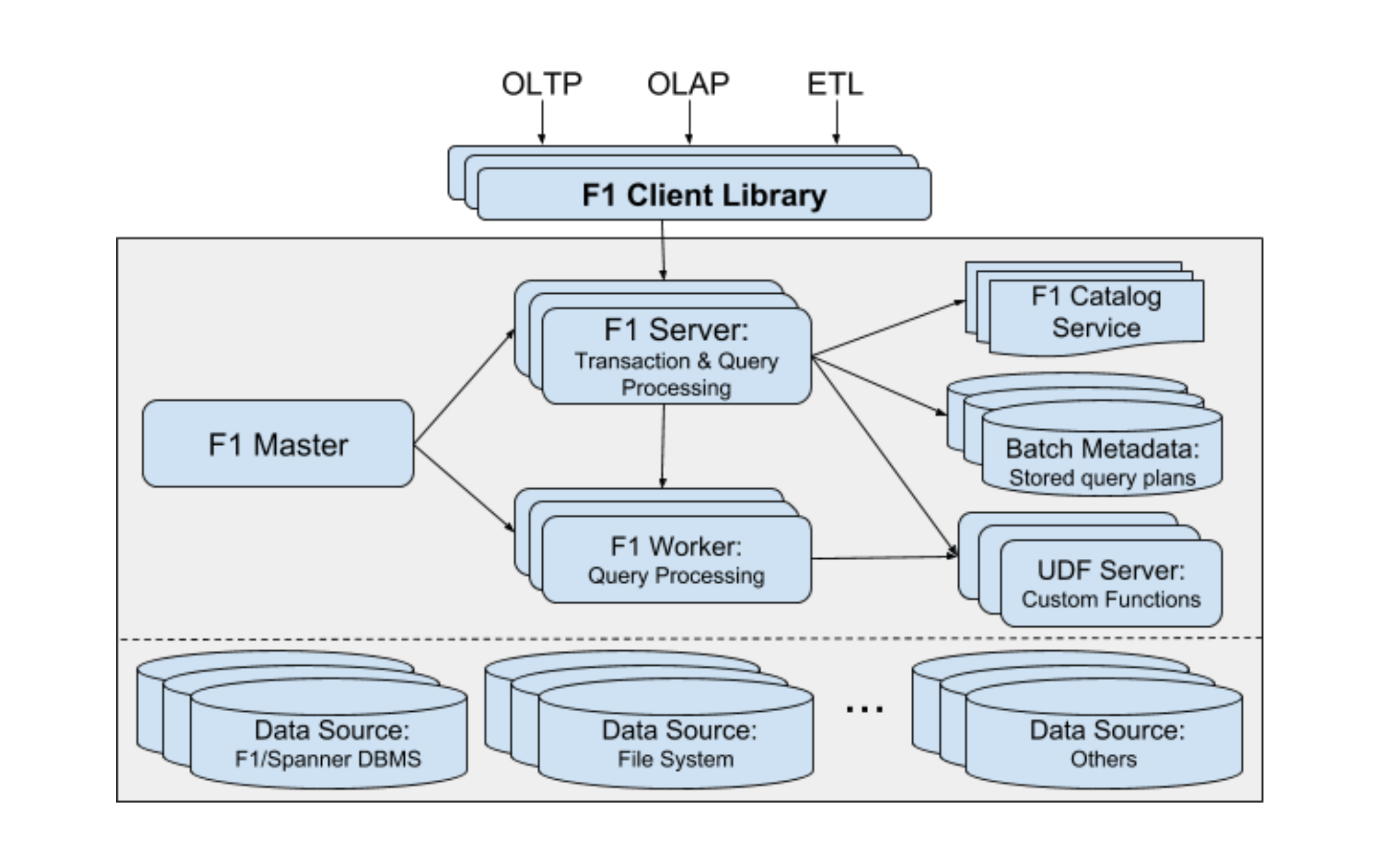
Conception du serveur UDF
- UDF réalise la prise en charge du langage général, en plus de SQL, il prend également en charge C++, Java, Go et d'autres implémentations de langage. De cette façon, cela ne dépend pas du dialecte SQL de la base de données, et la versatilité de l'expression logique est meilleure.
- Les UDF ne sont pas couplées à la couche de stockage. Cela signifie que son contexte peut être plus ouvert.
Cela signifie que le débogage des procédures stockées peut être considérablement amélioré, rendant possible l'interface avec le système DevOps.
Auparavant, VoltDB avait également réformé les procédures stockées. VoltDB est une base de données distribuée basée sur la mémoire développée par le légendaire Michael Stonebraker dans le domaine des bases de données. VoltDB utilise des procédures stockées comme principal mode de fonctionnement et prend en charge l'écriture dans le langage Java. Les développeurs peuvent hériter de la classe parent (VoltProcedure) fournie par le système pour développer leurs propres procédures stockées :
import org.voltdb.*;
public class LeastPopulated extends VoltProcedure {
//待执行的SQL语句
public final SQLStmt getLeast = new SQLStmt(
" SELECT TOP 1 county, abbreviation, population "
+ " FROM people, states WHERE people.state_num=?"
+ " AND people.state_num=states.state_num"
+ " ORDER BY population ASC;" );
//执行入口
public VoltTable[] run(int state_num)
throws VoltAbortException {
//赋输入参数
voltQueueSQL( getLeast, state_num );
//SQL执行函数
return voltExecuteSQL();
}
}
Définissez d'abord SQL, où "state_num=" est une position de paramètre réservée, puis affectez et exécutez les paramètres dans la fonction d'entrée run().
Le concept de conception de VoltDB est différent et attache une grande importance à l'efficacité de l'utilisation du processeur. Ils ont analysé les bases de données traditionnelles et ont estimé que seulement 12 % du temps CPU des bases de données ordinaires est utilisé pour des opérations de données significatives, de sorte que bon nombre de ses conceptions tournent autour de l'utilisation complète des ressources CPU.
La procédure stockée est essentiellement une transaction prédéfinie et il n'y a pas de processus d'interaction manuelle, ce qui évite l'attente du processeur. Dans le même temps, étant donné que le contenu de la procédure stockée est prévisible, les données peuvent être chargées dans la mémoire dès que possible, ce qui réduit encore l'attente du processeur causée par les E/S réseau et disque.
C'est grâce à l'utilisation de procédures stockées et de mémoire que VoltDB atteint de bonnes performances même sous le modèle monothread. À l'inverse, le thread unique lui-même simplifie le contrôle des transactions, évite la surcharge de la gestion traditionnelle des verrous et de l'attente du processeur, et améliore les performances de VoltDB.
Par rapport à d'autres bases de données, les procédures stockées ont des significations complètement différentes de VoltDB.
6 Résumé
- Le portage des procédures stockées est médiocre. Très dépendant de l'environnement de la base de données, et l'environnement de la base de données ne suit pas une norme unifiée comme le système d'exploitation ou la machine virtuelle. Pour la même raison, le débogage des procédures stockées est également très compliqué, n'a pas suivi le rythme du développement agile et ne correspond pas aux exigences d'ingénierie d'aujourd'hui. C'est précisément pour ces deux raisons techniques que les procédures stockées ne sont pas utilisées ou sont moins utilisées
- Du point de vue des bases de données distribuées, la plupart des NewSQL ne supportent pas encore les procédures stockées.OceanBase, comme seule exception, supporte déjà les procédures stockées Oracle, mais il n'a toujours pas atteint le niveau de production.
- L'article de F1 a proposé l'idée d'un serveur UDF indépendant, qui est un schéma d'implémentation pour les procédures stockées dans une architecture distribuée, mais il reste à voir s'il peut convenir aux environnements de réseau d'entreprise ordinaires. Cependant, dans cette solution, le langage d'implémentation de la procédure stockée ne se limite pas au dialecte SQL, mais est étendu à une variété de langages courants, compatibles avec les standards, et présente une meilleure ouverture. Cela soulève la possibilité de l'intégration de la technologie des procédures stockées avec DevOps.
- En tant que base de données distribuée en mémoire, VoltDB utilise des procédures stockées comme principale méthode de définition des opérations et prend en charge le développement du langage Java. On peut même dire que la base de VoltDB est la méthode transactionnelle prédéfinie des procédures stockées. Les procédures stockées, le stockage en mémoire et le thread unique interagissent les uns avec les autres, ce qui confère à VoltDB d'excellentes performances.
Pour tout programmeur, ce doit être une décision difficile d'abandonner une technologie qui a été maîtrisée et exécutée efficacement. Mais aujourd'hui, pour les grands systèmes logiciels, les exigences d'ingénierie sont bien plus importantes qu'une certaine technologie elle-même. Les technologies qui ne peuvent pas coopérer avec l'ensemble de l'écosystème technologique ne pourront finalement pas éviter le sort d'être marginalisées. Avant d'apprendre une nouvelle technologie, qu'il s'agisse d'une base de données distribuée ou d'un microservice, je vous suggère de faire attention à savoir si elle peut s'adapter à l'écologie environnante, car la technologie qui correspond à la tendance a la possibilité de s'améliorer, mais elle est trop créneau La technologie contient une plus grande incertitude.
référence
- Bart Samwel : Requête F1 : requête déclarative à grande échelle
7 FAQ
L'idée de conception de VoltDB est très particulière. En plus d'être monothread, d'utiliser une grande quantité de mémoire et de stocker des procédures pour prendre en charge le langage Java, sa conception en réplication de données est également ingénieuse. Ce n'est ni le protocole Paxos de NewSQL ni la réplication maître-esclave de PGXC. Vous pouvez imaginer Comment est-il conçu ? Il existe une certaine relation entre le mécanisme de réplication et la procédure stockée.
1. Le code métier et le code technique doivent être séparés Nous devons nous assurer que la traduction de la logique métier au code métier est simple et pure. Il s'agit non seulement de réduire le couplage à des technologies spécifiques dans la phase de mise en œuvre, mais aussi d'assurer la testabilité du code métier et la simplicité et la cohésion du code métier.
2. Les caractéristiques de technologies spécifiques (telles que les procédures stockées) permettent souvent d'atteindre des performances exceptionnelles. Mais cela augmente également la complexité de la phase de mise en œuvre, et la complexité signifie une maintenance difficile, ce qui signifie des coûts et des risques. Alors que la valeur comportementale du logiciel est réalisée, la santé de la qualité architecturale est compromise. Par conséquent, dans des scénarios avec des exigences de performances strictes, il est compréhensible d'utiliser certaines fonctionnalités de technologies spécifiques, mais nous devons rester vigilants et reconnaître qu'il s'agit d'une arme à double tranchant. N'agissez pas de manière imprudente sur la base de votre propre "compétence profonde".
3. N'ont pas connu l'ère du c/s. Cependant, à partir des livres pertinents sur la conception basée sur le modèle de données, nous pouvons voir comment la procédure stockée était si populaire au début. Mais maintenant, alors qu'une série de méthodes telles que les procédures stockées appartiennent au passé, la conception basée sur le modèle de données commence à devenir très "anémique". Fondamentalement, il ne reste que le modèle entité-relation et les éléments de données, ce qui est une faible capacité de transport d'informations, qui n'est plus adaptée pour piloter la conception de logiciels métiers complexes.
4. Mettez votre propre implémentation du pilote de modèle de données pour la communication : https://github.com/Jxin-Cai/mdd/tree/master/data-model/mini-faas
La réplication de fragments de VoltDB est similaire au serveur de noms de rocketMq. En effectuant des opérations sur toutes les répliques en parallèle, la complexité de parvenir à un consensus entre les répliques est évitée.
OceanBase n'a d'autre choix que de supporter les procédures stockées d'Oracle, car c'est lui qui détermine s'il peut "envahir" le camp client traditionnel d'Oracle - les grandes entreprises et le secteur financier, qui est purement commercial. Les produits ERP d'Oracle utilisent un grand nombre de procédures stockées pour implémenter la logique métier. Le code source de la logique métier la plus complexe est imprimé sur des dizaines de pages. Je pense que les outils d'OceanBase ne peuvent pas parfaitement gérer une procédure stockée aussi compliquée (transplantée en OB), mais pour les enchères et autres Si vous ne supportez pas de nombreuses fonctionnalités d'Oracle, vous n'avez pas du tout la possibilité de participer.
VoltDB utilise le mécanisme de sécurité K pour résoudre le problème de réplication des données. En fait, il s'agit d'un mécanisme de copie N + 1. Lorsque VoltDB écrit des données, il exécutera l'instruction dans chaque copie, afin de s'assurer que les données sont correctement inséré dans chaque exemplaire. . Toutes les copies N+1 peuvent fournir un accès en même temps, et en même temps, jusqu'à N copies peuvent être perdues (panne de partition). Lorsque les copies N+1 ne sont pas disponibles, VoltDB arrête le service pour réparation.
"Alibaba Java Development Manual" interdit l'utilisation de procédures stockées, qui sont difficiles à déboguer et à développer, et n'ont aucune portabilité. "Il est soupçonné d'être trompeur. La procédure stockée ici est destinée à MySQL, et elle est vraiment difficile à déboguer et difficile à répliquer. Dans les produits de la même époque, les procédures stockées écrites en PL/SQL d'oracle et T-SQL du serveur SQL sont toujours très avantageux. DB2 et Oracle prennent en charge PL/SQL, où PL/SQL est portable, et cette procédure stockée est appelée dans le standard SQL (SQL/PSM (SQL/Persistent Stored Modules) https://en.wikipedia. org/wiki/SQL/PSM).
Cette suggestion dans le manuel de développement d'Ali ne fait pas spécifiquement référence à MySQL. Elle peut être incluse dans le chapitre MySQL car MySQL est largement utilisé dans Ali et est une base de données représentative. Se pourrait-il qu'ils désactivent les procédures stockées MySQL tout en utilisant secrètement et joyeusement les procédures stockées Oracle ? Cela semble peu probable.
Tout au long du développement des normes SQL et du développement d'oracle, le support des procédures stockées a également un processus de développement.Les performances et l'efficacité de développement des procédures stockées sont encore assez élevées. À l'ère des mégadonnées, les gens parlent de la séparation du stockage, le stockage appartient au stockage et l'informatique appartient à l'informatique. Sur la base de l'équilibre entre le matériel et les coûts, la puissance de calcul est augmentée par l'expansion horizontale et la fonction de processus de stockage est temporairement non développé ou il est difficile à développer.Mais la ruche Apache est La procédure stockée prise en charge s'appelle hpsql.
De plus, la norme SQL n'est qu'une référence pour toutes les bases de données. Différentes bases de données ont des longueurs différentes dans les types de données, les variables globales, les fonctions et même les noms de procédures stockées. Aucune base de données n'est identique à moins d'être spécifiquement adaptée. C'est pourquoi on dit que la base de données de commutation de système est un gros problème.
Les représentants typiques des bases de données distribuées sont TiDB et CockroachDB. Ils sont quelque peu différents en termes de compatibilité de syntaxe et de prise en charge des procédures stockées. CockroachDB prend-il en charge les procédures stockées dans la syntaxe pg (pg est similaire à PL/SQL) ?
Après avoir compris ces différences, certains élèves peuvent encore penser que ce n'est pas un problème, c'est si facile. Pour les particuliers, que ce soit difficile ou facile est un jugement très subjectif, l'essentiel étant de savoir si votre équipe peut utiliser cette technologie pendant longtemps et à faible coût.
Étant donné que toutes les procédures stockées prennent en charge JAVA, la réplication de données devrait pouvoir apprendre de TCC, qui est directement implémenté dans la couche de code, ce qui équivaut à la "couche de service", et il est basé sur la mémoire, et le coût de la nouvelle tentative est bas, en utilisant directement le code pour écrire sur le nœud Compris ?
Ils sont tous basés sur la mémoire, mais contrairement à Redis, ils ne devraient pas nécessiter des performances aussi élevées et utiliser directement le pool de threads pour écrire des données sur les nœuds de données en même temps.
Les procédures stockées sont un produit irremplaçable de l'ère des bases de données autonomes.Quand j'étais programmeur, les procédures stockées étaient le meilleur outil pour résoudre la séparation des codes front-end et back-end. Une opération de revue par lots de 100 000 commandes peut être réalisée en quelques minutes en appelant la procédure stockée, et le code VB front-end est exécuté, et le résultat ne peut pas être obtenu avant une heure ?
Oui, les procédures stockées sont définitivement un outil puissant pour l'informatique gourmande en données.
La vue matérialisée de clickhouse est en fait un élément déclencheur, sous quel angle faut-il l'analyser ?
D'un point de vue mécanique, la vue matérialisée (MaterializedView) dans ClickHouse peut en effet être considérée comme un déclencheur.
- angle fonctionnel
La fonction de la vue matérialisée est de pré-calculer une table de base et de maintenir les résultats de la requête SELECT en temps réel, ce qui équivaut fonctionnellement à créer une vue en cache mise à jour en temps réel. Ceci est similaire à la façon dont les déclencheurs peuvent effectuer automatiquement des actions prédéfinies lorsque les données changent.
- Perspective du mécanisme de mise en œuvre
ClickHouse crée une vue matérialisée via le moteur, et lorsqu'il y a un changement de données dans la table sous-jacente, il déclenchera automatiquement la mise à jour de la vue matérialisée. Cela tire parti du mécanisme de déclenchement du moteur pour obtenir des vues matérialisées en temps réel.
- utiliser l'angle de la scène
Les vues matérialisées peuvent être utilisées dans l'analyse de données, le tableau de bord et d'autres scénarios nécessitant un accès rapide aux résultats agrégés, remplaçant les requêtes répétées, ce qui est similaire à l'utilisation de déclencheurs.
- point de vue des performances
Les vues matérialisées améliorent les performances de lecture grâce à la mise en cache, mais augmentent la charge d'écriture. Vous devez peser le ratio de lecture et d'écriture pour décider de l'utiliser. Cela reflète également les caractéristiques de compromis de performance des déclencheurs.
- angle limite
Les vues matérialisées ont diverses restrictions sur les requêtes, et ces restrictions sont également des facteurs que les déclencheurs doivent généralement prendre en compte.
Pour résumer, sous plusieurs angles, la vue matérialisée de ClickHouse peut en effet être considérée comme un déclencheur spécial, utile pour comprendre et utiliser les vues matérialisées. Cela m'a donné un nouvel angle pour analyser divers mécanismes d'automatisation dans la base de données.