Elasticsearch est un outil clé pour permettre une expérience de recherche transparente pour les utilisateurs. Il a révolutionné la façon dont les utilisateurs interagissent avec les applications en fournissant des résultats de recherche rapides, précis et pertinents. Cependant, pour garantir des performances optimales de votre déploiement Elasticsearch, vous devez prêter attention aux métriques clés et à l'optimisation de divers composants tels que l'indexation, la mise en cache, l'interrogation, la recherche et le stockage.
Dans cet article de blog, nous allons plonger dans les meilleures pratiques et conseils sur la façon d'ajuster Elasticsearch pour des performances optimales et un potentiel maximal, de l'optimisation de la santé du cluster, des performances de recherche et de l'indexation, à la maîtrise des stratégies de mise en cache et des options de stockage. Que vous soyez un expert Elasticsearch expérimenté ou nouveau dans le domaine, il est essentiel de suivre certaines bonnes pratiques pour garantir les performances, la fiabilité et l'évolutivité de votre déploiement.

1. Suggestions générales d'optimisation
1.1 Utiliser le bon matériel
Elasticsearch est une application gourmande en mémoire, il est donc important d'utiliser du matériel avec suffisamment de mémoire. En outre, les disques SSD sont recommandés comme périphériques de stockage, car ils peuvent améliorer considérablement les performances d'indexation et de recherche.
Bien que les performances d'E/S des SSD soient meilleures que celles des disques durs traditionnels, les performances d'E/S peuvent toujours devenir un goulot d'étranglement si le nombre de nœuds dans le cluster Elasticsearch est important. Afin de garantir les performances, certaines mesures d'optimisation peuvent être prises, telles que l'utilisation d'une configuration RAID, un partitionnement de disque raisonnable et un équilibrage de charge.
| Niveau RAID | avantage | défaut | Scène applicable |
|---|---|---|---|
| RAID 0 | Performances d'E/S élevées, réalisation de lecture et d'écriture parallèles | Pas de redondance, une panne de disque peut entraîner une perte de données | Applications sensibles aux performances avec des temps de récupération de données acceptables |
| RAID 1 | Redondance des données, les données ne seront pas perdues en cas de panne de disque | Les performances d'écriture ne sont pas aussi bonnes que RAID 0 | Applications avec une sécurité et une fiabilité des données élevées |
| RAID 5 | Redondance des données, un certain degré d'avantage en termes de performances d'E/S | Les performances d'écriture ne sont pas aussi bonnes que RAID 0 | Applications nécessitant un équilibre entre performances et sécurité des données |
| RAID 10 | Combinant les avantages de RAID 0 et RAID 1, hautes performances d'E/S et redondance des données | Nécessite plus de disques et coûte plus cher | Applications nécessitant à la fois performances et sécurité des données |
1.2 Stratégie d'indice de planification
Elasticsearch est conçu pour gérer de grandes quantités de données, mais doit réfléchir à la façon d'indexer ces données. Cela inclut le nombre de partitions et de répliques nécessaires, la manière dont les données seront indexées et la manière dont les mises à jour et les suppressions seront gérées.
Nombre de fragments
Choisissez un nombre approprié de partitions pour obtenir une mise à l'échelle horizontale et un équilibrage de charge.
Par défaut, chaque index a 1 fragment principal. Ajustez le nombre de partitions en fonction de la quantité de données et du nombre de nœuds. Essayez d'éviter d'utiliser trop de partitions, car chaque partition nécessite des ressources et des frais généraux supplémentaires.
nombre de copies
Augmentez le nombre de copies pour améliorer les performances de recherche et la tolérance aux pannes du système, mais cela doit être dialectique, ce qui sera expliqué en détail plus tard.
Par défaut, chaque partition a 1 réplique. Ajustez le nombre de répliques en fonction des besoins de charge et de disponibilité.
Stratégie d'indexation des données
Utilisez des stratégies de gestion du cycle de vie des index (ILM) basées sur le temps pour améliorer les performances des requêtes et réduire la consommation des ressources. Par exemple, créez un nouvel index pour les données quotidiennes, hebdomadaires ou mensuelles.
Choisissez le type de champ et l'analyseur appropriés. Optimisez les mappages pour réduire l'espace de stockage et améliorer les performances des requêtes.
Utilisez des modèles d'index pour appliquer automatiquement des mappages et des paramètres.
Gestion des mises à jour et des suppressions
Utilisez l'API de mise à jour pour mettre à jour des documents sans supprimer ni réindexer l'intégralité du document.
Faites un usage raisonnable des fonctionnalités de contrôle de version d'Elasticsearch.
Envisagez d'utiliser Index Lifecycle Management (ILM) pour gérer automatiquement le cycle de vie de vos index. En fonction des besoins et des scénarios spécifiques de l'entreprise, ajustez de manière flexible les suggestions ci-dessus pour optimiser les performances du cluster Elasticsearch.
1.3 Optimisation des requêtes
Elasticsearch est un moteur de recherche puissant, mais assurez-vous que les performances des requêtes sont optimisées. Cela inclut l'utilisation de filtres au lieu de requêtes lorsque cela est possible, et l'utilisation de la pagination pour limiter le nombre de résultats renvoyés.

Utilisez des filtres au lieu de requêtes :
Vitesse de requête améliorée : les filtres ne calculent pas les scores de pertinence.
Les résultats peuvent être mis en cache : obtenez les résultats directement avec les mêmes conditions de filtre.
Utilisez la pagination pour limiter le nombre de résultats renvoyés :
Réduisez la charge de calcul et de transfert : améliorez les performances des requêtes.
Notez que la pagination profonde peut entraîner des problèmes de performances : pensez à utiliser
search_afterle paramètre.
L'optimisation des performances des requêtes peut aider à réduire les temps de réponse, à augmenter le débit et à garantir la stabilité du cluster en cas de charge élevée.
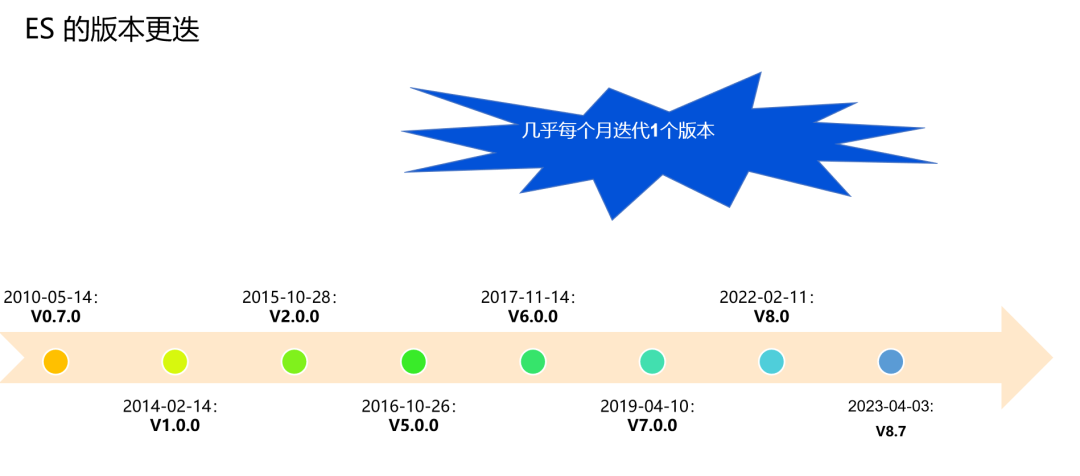
1.4 Maintenir la version d'Elasticsearch à jour
Elasticsearch est un projet actif et de nouvelles versions sont publiées régulièrement pour corriger les bogues et fournir de nouvelles fonctionnalités. Il est essentiel de maintenir la version à jour pour tirer parti de ces améliorations et éviter les problèmes connus.
1.5 Groupe de surveillance
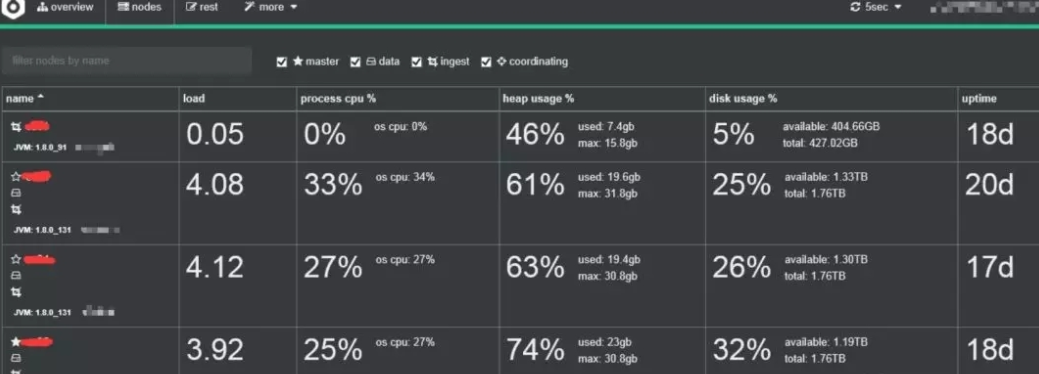
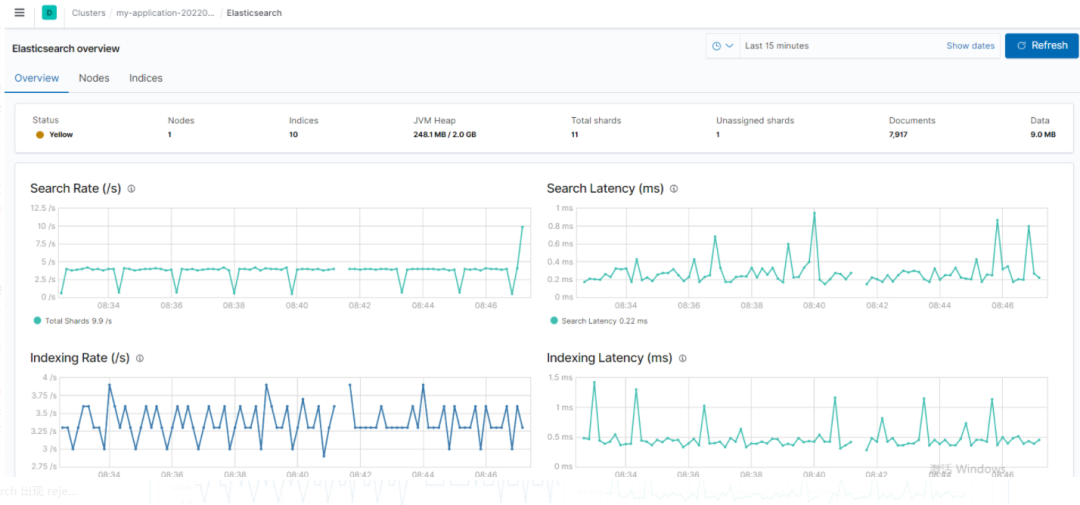
Elasticsearch fournit une variété d' outils de surveillance , tels que Elasticsearch Head, les plug-ins de surveillance Kibana (préférés), qui peuvent être utilisés pour surveiller la santé et les performances du cluster. Gardez un œil sur l'utilisation du disque, l'utilisation du processeur et de la mémoire, ainsi que le nombre de requêtes de recherche.
En nous appuyant sur les meilleures pratiques générales, nous nous pencherons sur des domaines spécifiques tels que l'indexation, l'interrogation et la recherche, la mise à l'échelle, les performances et la surveillance.
2. Rédaction (indexation) des suggestions d'optimisation
2.1 Utiliser les requêtes par lots
L'API de masse d'Elasticsearch permet d'effectuer plusieurs opérations d'indexation/suppression en un seul appel d'API. Cela améliore considérablement la vitesse d'indexation. Si l'une des demandes échoue, l'indicateur d'erreur de niveau supérieur sera défini sur vrai et les détails de l'erreur seront signalés sous la demande concernée.
Raisons d'utiliser l'API de masse d'Elasticsearch :
améliorer les performances
Réduisez la surcharge du réseau et le temps d'établissement de la connexion, améliorez la vitesse d'indexation.
Réduire la consommation de ressources
Réduisez la consommation des ressources du serveur et du client, améliorez l'efficacité et le débit du système.
la gestion des erreurs
Gestion des erreurs flexible et contrôlable, même si certaines opérations échouent, d'autres opérations peuvent continuer à s'exécuter.
L'utilisation de l'API en bloc permet des opérations efficaces d'indexation et de suppression des données tout en améliorant la stabilité et la fiabilité du système.
2.2 Indexer les données à l'aide d'un client multithread
L'envoi de requêtes par lots par un seul thread ne peut pas tirer pleinement parti des capacités d'indexation du cluster Elasticsearch.
L'envoi de données via plusieurs threads ou processus aidera à utiliser toutes les ressources du cluster, à réduire le coût de chaque fsync et à améliorer les performances.
2.3 Augmenter l'intervalle de rafraîchissement (index.refresh_interval)
L'intervalle d'actualisation par défaut dans Elasticsearch est de 1 seconde, mais si le trafic de recherche est faible, cette valeur peut être augmentée pour optimiser la vitesse d'indexation.
2.4 Utilisation d'identifiants générés automatiquement
Lors de l'indexation d'un document avec un ID explicite, Elasticsearch doit vérifier si un document avec le même ID existe déjà, ce qui est une opération coûteuse.
L'utilisation d'ID générés automatiquement peut ignorer cette vérification, ce qui accélère l'indexation.
2.5 index.translog.sync_interval
Ce paramètre contrôle le moment où le translog est validé sur le disque, quelles que soient les opérations d'écriture. La valeur par défaut est de 5 secondes, mais les valeurs inférieures à 100 millisecondes ne sont pas autorisées.
Adresse du document officiel :
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
2.6 Évitez les gros documents
Les documents volumineux peuvent exercer une pression sur le réseau, l'utilisation de la mémoire et le disque, provoquant une indexation lente et affectant les recherches de proximité et la mise en surbrillance.
Le traitement de surbrillance recommande la méthode de surbrillance fvh .
Lecture recommandée : Performances de récupération de fichiers volumineux d'Elasticsearch améliorées par 20 fois la pratique (marchandises sèches)
2.7 Définition explicite des mappages
Elasticsearch peut créer dynamiquement des mappages, mais il ne convient pas à tous les scénarios. La définition explicite du mappage (strict) contribuera à garantir des performances optimales.

Avantages de définir explicitement le mappage :
type de champ exact
Assurez-vous que les opérations de requête et d'agrégation sont correctes.
Optimiser le stockage et les performances
Réduisez l'espace de stockage et améliorez les performances des requêtes.
Évitez les mises à jour cartographiques inutiles
Réduisez les opérations de mise à jour de la carte et la surcharge de performances.
2.8 Éviter d'utiliser des types imbriqués imbriqués
Bien que les types imbriqués soient utiles dans certains scénarios, ils ont également un certain impact sur les performances :
La requête est plus lente
L'interrogation de champs imbriqués est plus lente que l'interrogation de champs normaux dans des documents non imbriqués.
En effet, les requêtes sur des champs imbriqués nécessitent des étapes de traitement supplémentaires telles que des filtres et des jointures. Cela peut entraîner une baisse des performances des requêtes, en particulier lorsqu'il s'agit de grandes quantités de données.
décélération supplémentaire
Lors de la récupération de documents correspondant à des champs imbriqués , Elasticsearch doit associer des documents imbriqués. Cela signifie qu'il doit faire correspondre les documents imbriqués avec leurs documents externes pour déterminer quels documents contiennent réellement des champs imbriqués correspondants. Ce processus peut entraîner une surcharge de performances supplémentaire, en particulier lorsque le jeu de résultats de la requête est volumineux.
Pour éviter l'impact des types imbriqués sur les performances, envisagez d'utiliser les méthodes suivantes :
Structure de données aplatie (communément appelée table large et large) : convertissez autant que possible les champs imbriqués en une structure de données aplatie, par exemple, utilisez plusieurs champs communs pour représenter les champs imbriqués d'origine.
Utiliser le type de mot-clé (type de mot-clé) : pour les champs avec des valeurs définies fixes, vous pouvez utiliser le type de mot-clé pour l'indexation afin d'améliorer la vitesse de la requête.
Utiliser le type de jointure (type d'association parent-enfant) : dans certains scénarios, vous pouvez utiliser le type de jointure au lieu du type imbriqué.
Notez toutefois que les types de jointure peuvent également entraîner des problèmes de performances, en particulier si les relations entre les documents doivent être modifiées fréquemment.
3. Suggestions d'optimisation des requêtes et de la recherche
3.1 Utilisez autant que possible le filtre au lieu de la requête
La clause de requête est utilisée pour répondre "Dans quelle mesure ce document correspond-il à cette clause ?
La clause de filtre est utilisée pour répondre "Est-ce que ce document correspond à cette clause ?" Elasticsearch n'a qu'à répondre "oui" ou "non". Il n'a pas besoin de calculer les scores de pertinence pour les clauses de filtre et les résultats du filtre peuvent être mis en cache.
3.2 Augmenter l'intervalle de rafraîchissement
L'augmentation de l'intervalle d'actualisation peut aider à réduire le nombre de segments et à réduire le coût d'E/S de la recherche.
De plus, une fois qu'une actualisation se produit et que les données changent, le cache est invalidé. L'augmentation de l'intervalle d'actualisation permet à Elasticsearch d'utiliser le cache plus efficacement.
3.3 Un regard dialectique sur l'impact de l'augmentation du nombre de copies sur les performances de récupération
Donnez directement la conclusion du test au niveau de l'entreprise - l'impact du nombre de copies sur les performances de récupération n'est pas positivement corrélé. C'est-à-dire : ce n'est pas que plus il y a de copies, plus les performances de récupération sont élevées.
Avantages d'augmenter le nombre de répliques :
l'équilibrage de charge
Distribuez la charge des demandes de requête pour obtenir un équilibrage de charge.
la haute disponibilité
Améliorez la disponibilité des clusters et la tolérance aux pannes.
traitement parallèle
Accélérez les requêtes et augmentez le débit.
Remarque : l'augmentation du nombre de répliques consomme de l'espace de stockage et des ressources informatiques supplémentaires. Le nombre de répliques doit être mis en balance avec la demande et les contraintes de ressources.
3.4 Récupérer uniquement les champs obligatoires
Si le document est volumineux et que seuls quelques champs sont nécessaires, utilisez les champs_stockés pour récupérer uniquement les champs obligatoires, pas tous les champs.
3.5 Éviter les requêtes génériques
Les requêtes génériques peuvent être lentes et gourmandes en ressources. Il vaut mieux les éviter au maximum.
Alternatives : segmentation des mots Ngram , définition du type de données générique .
Elasticsearch méfiez-vous des récupérations de caractères génériques ! Alors quoi?
3.6 Utilisation du cache de requête de nœud
Les résultats de la requête utilisés dans le contexte du filtre seront mis en cache dans le cache de requête du nœud pour des recherches rapides.
Avantages de la mise en cache des résultats de la requête de contexte de filtre :
taux de succès du cache
Les requêtes de filtrage ont un taux d'accès au cache élevé et sont souvent réutilisées dans plusieurs requêtes.
économiser les ressources informatiques
La mise en cache des résultats réduit les calculs répétés et économise les ressources.
Améliorer la vitesse des requêtes
La mise en cache accélère les requêtes, en particulier les requêtes de filtre complexes ou gourmandes en données.
La requête simultanée fonctionne mieux
Le cache de requête de nœud joue un rôle dans les scénarios de concurrence élevée pour améliorer les performances.
Remarque : Il existe un équilibre entre l'utilisation du cache et la consommation de mémoire. Pour les requêtes qui changent fréquemment ou qui ont de faibles taux d'accès au cache, la mise en cache peut être d'une efficacité limitée.
Explication détaillée du cache Elasticsearch
3.7 Utilisation du cache de requête partagé
La mise en cache des requêtes partagées peut être activée en définissant "index.requests.cache.enable" sur true.
La référence de réglage est la suivante :
PUT /my-index-000001
{
"settings": {
"index.requests.cache.enable": false
}
}Adresse du document officiel :
https://www.elastic.co/guide/en/elasticsearch/reference/current/shard-request-cache.html
3.8 Utilisation de modèles d'index
Les modèles d'index peuvent aider à appliquer automatiquement les paramètres et les mappages aux nouveaux index.
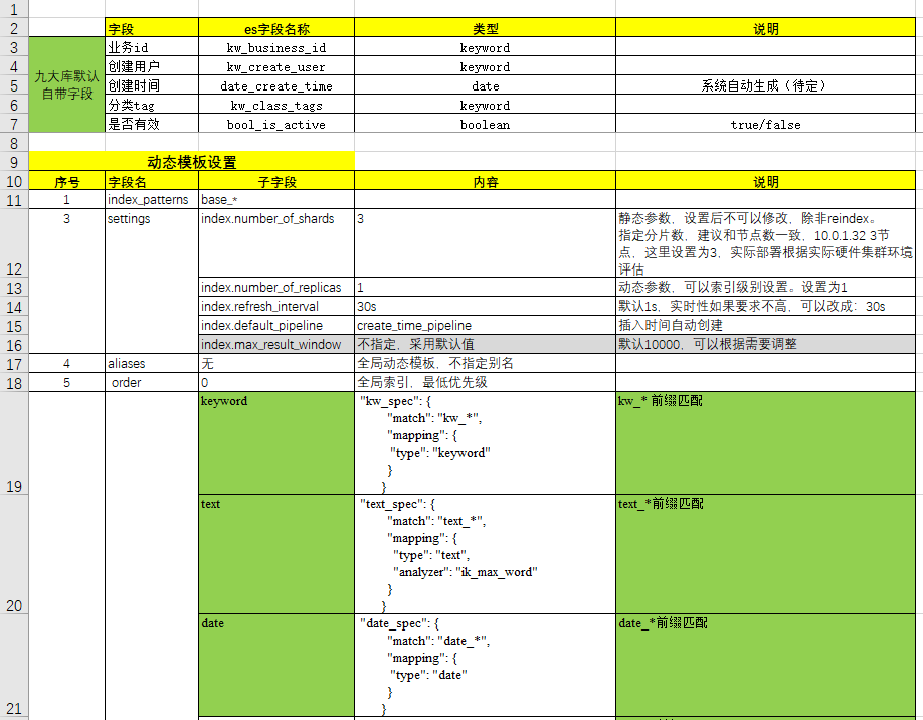
Avantages d'utiliser des modèles d'index :
cohérence
Assurez-vous que le nouvel index a les mêmes paramètres et mappages pour la cohérence du cluster.
Simplifiez le fonctionnement
Appliquez automatiquement des paramètres et des mappages prédéfinis, réduisant ainsi la configuration manuelle.
facile à étendre
Créez rapidement de nouveaux index avec la même configuration pour faciliter la mise à l'échelle du cluster.
Contrôle de version et mises à jour
Implémentez la gestion des versions de modèle pour vous assurer que les nouveaux index utilisent la dernière configuration.
4. Suggestions d'optimisation des performances
4.1 Le partitionnement actif doit être proportionnel au CPU
Fragments actifs = somme des fragments primaires + fragments de réplique.
Raisons des fragments actifs proportionnels au CPU :
traitement parallèle
Des partitions plus actives augmentent le traitement parallèle, accélérant les requêtes et les requêtes d'indexation. Proportionnel au nombre de cœurs de processeur pour garantir une utilisation complète des ressources du processeur.
éviter la concurrence des ressources
Proportionnez les fragments actifs au nombre de cœurs de processeur pour éviter que plusieurs fragments ne se disputent le même cœur de processeur et améliorer les performances.
l'équilibrage de charge
Un nombre proportionnel de partitions actives permet de répartir les demandes sur plusieurs nœuds, en évitant les goulots d'étranglement des ressources sur un seul nœud.
optimisation des performances
Le nombre de fragments proportionnel au nombre de cœurs de processeur alloue la puissance de traitement aux fragments en fonction des ressources informatiques disponibles, optimisant ainsi les opérations de requête et d'indexation.
Remarque : Le déploiement réel doit tenir compte d'autres facteurs, tels que la mémoire, le disque et les ressources réseau.
Comme mentionné précédemment, pour améliorer les performances pour les cas d'utilisation intensive en écriture, l'intervalle d'actualisation doit être augmenté à une valeur élevée (par exemple, 30 secondes), et les fragments primaires doivent être augmentés pour distribuer les demandes d'écriture à différents nœuds. Pour les cas d'utilisation à lecture intensive, l'augmentation du nombre de fragments de réplica pour équilibrer les demandes de requête/recherche entre les réplicas peut aider.
4.2 Si la requête comporte un filtre de plage de dates, organisez les données par date.
Pour les scénarios de journalisation ou de surveillance, l'organisation des index par jour, semaine ou mois et l'obtention d'une liste d'index selon une plage de dates spécifiée peuvent améliorer les performances.

Elasticsearch n'a besoin d'interroger que des ensembles de données plus petits, pas l'ensemble de données complet, et il serait facile de réduire/supprimer les anciens index lorsque les données expirent.
Cas négatif : Auparavant, il y avait un problème selon lequel les données du client de plus de 100 To n'avaient pas de champ de format de date ou le format de champ n'était pas normalisé.
4.3 Si la requête comporte un champ de filtre et que sa valeur est énumérable, divisez les données en plusieurs index.
Si notre requête inclut un champ de filtre énumérable (par exemple, région), les performances de la requête peuvent être améliorées en divisant les données en plusieurs index.
Par exemple, si les données contiennent des enregistrements des États-Unis, d'Europe et d'autres régions, et que les requêtes sont souvent filtrées à l'aide de "région", les données peuvent être divisées en trois index, chacun contenant des données pour un ensemble de régions.
Ainsi, lors de l'exécution d'une requête avec la clause de filtre "région", Elasticsearch n'a besoin de rechercher que dans l'index contenant les données de cette région, ce qui améliore les performances de la requête.
5. Suggestions d'extension
5.1 Gestion de l'état de l'index
Définissez des politiques de gestion personnalisées pour automatiser les tâches courantes et appliquez-les aux index et aux schémas d'index. Par exemple, vous pouvez définir une politique qui rend un index en lecture seule après 30 jours et le supprime après 90 jours.
ILM (Index Lifecycle Management) est une fonctionnalité d'Elasticsearch qui automatise la gestion et la maintenance des index, avec les avantages suivants :
Gestion simplifiée des index : automatisez la gestion du cycle de vie des index, y compris la création, la mise à jour, la suppression et l'archivage des index, ce qui réduit la charge de travail des administrateurs.
Améliorer les performances : optimisez automatiquement les paramètres d'index, notamment en ajustant la taille des fragments, en réduisant les index et en supprimant les données expirées, etc., pour améliorer les performances des requêtes et réduire l'utilisation de l'espace de stockage.
Réduisez les coûts : archivez et supprimez automatiquement les données expirées, réduisez les coûts de stockage et réduisez la charge de travail des administrateurs et les coûts de temps.
Meilleure évolutivité : ajustez automatiquement les paramètres d'index et les politiques de stockage selon les besoins, ce qui rend les index plus adaptables à la croissance et à l'évolution des données.
L'utilisation d'ILM peut rendre la gestion des index plus simple et plus fiable.
5.2 Gestion du cycle de vie des instantanés
SLM ( Snapshot Lifecycle Management ) est une fonctionnalité d'Elasticsearch qui automatise la gestion et la maintenance des snapshots, avec les avantages suivants :
Gestion simplifiée des instantanés : automatisez la gestion du cycle de vie des instantanés, y compris la création, la gestion, la suppression et le nettoyage des instantanés, ce qui réduit la charge de travail des administrateurs.
Améliorez l'efficacité : créez, gérez, supprimez et nettoyez automatiquement des instantanés pour améliorer l'efficacité de la gestion.
Réduisez les coûts de stockage : supprimez automatiquement les instantanés inutiles pour réduire les coûts de stockage.
Meilleure évolutivité : Ajustez automatiquement les paramètres d'instantané et les politiques de stockage selon les besoins, ce qui rend les instantanés plus adaptables à la croissance et à l'évolution des données.
L'utilisation de SLM peut rendre la gestion des instantanés plus facile et plus fiable, améliorer l'efficacité de la gestion et réduire les coûts de stockage.
Un guide pratique de la gestion du cycle de vie des instantanés Elasticsearch (SLM)
5.3 Faire bon usage du suivi
Afin de surveiller les performances de votre cluster Elasticsearch et de détecter tout problème potentiel, les métriques suivantes doivent être suivies régulièrement :
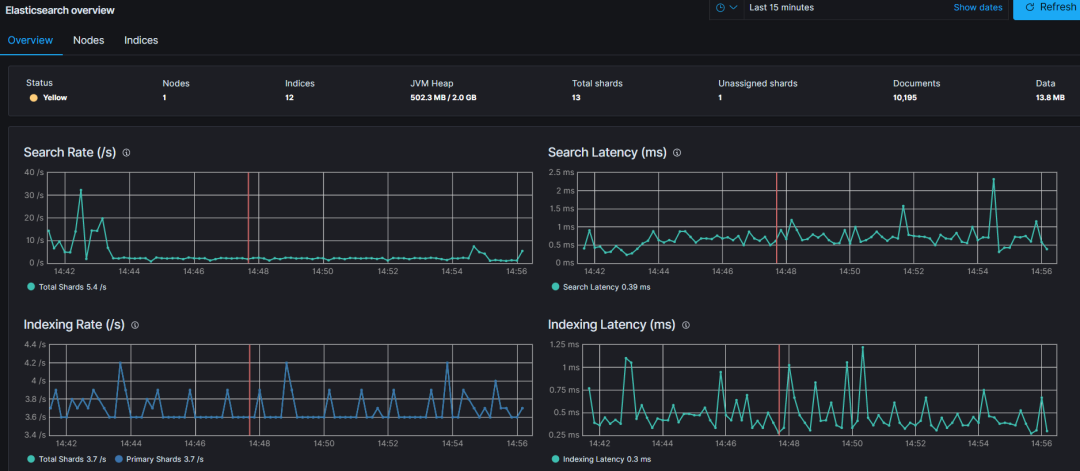
Nœuds et fragments de santé du cluster : surveille le nombre de nœuds dans le cluster ainsi que les fragments et leur distribution.
Performances de recherche : Latence et taux de requête - Suit la latence des requêtes de recherche et le nombre de requêtes de recherche par seconde.
Performances de l'index : temps d'actualisation et temps de fusion - Surveillez le temps nécessaire pour actualiser l'index et le temps nécessaire pour fusionner les segments.
Utilisation des nœuds : pools de threads : surveille l'utilisation des pools de threads sur chaque nœud, tels que le pool d'index.
6. Résumé
Le respect de ces bonnes pratiques peut garantir un déploiement Elasticsearch performant, fiable et évolutif.
N'oubliez pas qu'Elasticsearch est un puissant moteur de recherche et d'analyse qui peut traiter de grandes quantités de données rapidement et en temps quasi réel, mais pour en tirer le meilleur parti, il faut planifier, optimiser et surveiller votre déploiement.
Les suggestions ci-dessus sont fournies à titre indicatif uniquement. Le fonctionnement réel est basé sur la documentation officielle d'Elasticsearch et sur les conclusions des tests de performances de votre propre cluster. Il n'y a pas de suggestion d'optimisation universelle, seule l'optimisation qui vous convient est la meilleure optimisation.
lecture recommandée
Première diffusion sur tout le réseau ! De 0 à 1 vidéo de dédouanement Elasticsearch 8.X
Liste de cognition de la méthodologie Dead Elasticsearch 8.X
Comment JMeter implémente-t-il les tests de performances Elasticsearch 8.X ?
Guide pratique d'optimisation des performances de récupération d'Elasticsearch
Laissez Elasticsearch s'envoler ! - Pratique d'optimisation des performances
Guide pratique d'optimisation des performances d'Elasticsearch
Six astuces pour l'optimisation des performances d'agrégation Elasticsearch
Comment esrally effectue-t-il des tests de performances personnalisés simples ?

Acquérir plus de produits secs plus rapidement en moins de temps !
Améliorez-vous avec près de 2000+ passionnés d'Elastic dans le monde entier !

Apprenez les produits secs avancés avec une longueur d'avance sur vos collègues !