Passez du langage de l'entrée au combat réel - articles simultanés
coroutine
Fil vs groutine

En revanche, la taille de la pile de la coroutine est beaucoup plus petite, et elle sera créée plus rapidement et économisera les ressources système.
La pile d'une goroutine, comme un thread du système d'exploitation, stockera les variables locales de ses appels de fonction actifs ou suspendus, mais contrairement à un thread du système d'exploitation, la taille de la pile d'une goroutine n'est pas fixe ; la taille de la pile sera basée sur Elle doit être dynamique mis à l'échelle, et la taille initiale est 2KB. La valeur maximale de la pile de goroutines 1GBest beaucoup plus grande que la pile de threads de taille fixe traditionnelle, bien qu'en général, la plupart des goroutines n'aient pas besoin d'une pile aussi grande.

Alors, que signifie cette correspondance plusieurs-à-plusieurs pour notre programme ?
Si c'est 1: 1, alors notre thread (Thread) est directement planifié par notre entité noyau. De cette façon, son efficacité de planification est très élevée, mais il y a un problème ici. Si un changement de contexte se produit entre les threads, cela impliquera la commutation mutuelle des objets du noyau, cela coûtera très cher.
Relativement parlant, si plusieurs coroutines sont planifiées par la même entité du noyau, alors la commutation entre les coroutines n'implique pas la commutation entre les objets du noyau et peut être effectuée en interne, et la commutation entre elles sera beaucoup plus petite. .
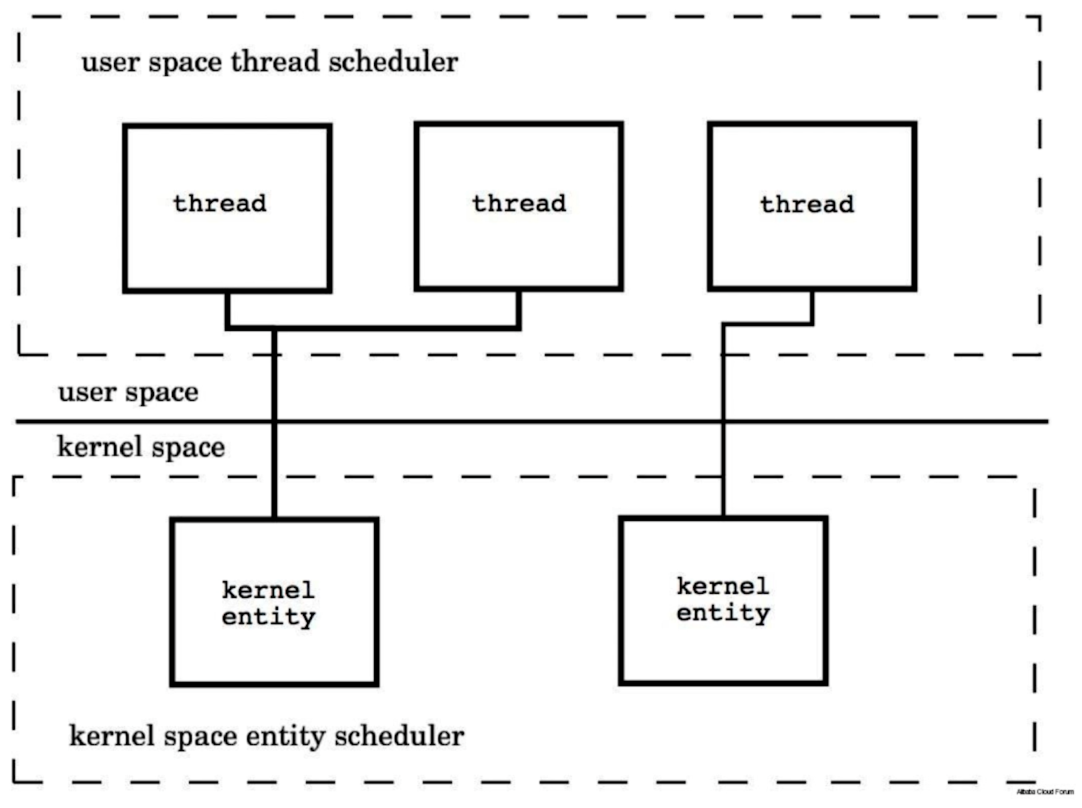
Mécanisme de planification en Go
Le processeur de coroutine P (processeur) de Go est suspendu sous le thread système M (thread système), et il existe une file d'attente de coroutine (Goroutine) prête à s'exécuter sous le processeur de coroutine P. Chaque fois dans chaque file d'attente de coroutine, il y a une coroutine G qui est en cours d'exécution.
Si le temps d'exécution de la coroutine en cours d'exécution est particulièrement long, bloquera-t-il la file d'attente de la coroutine ?
Le mécanisme de traitement de Go est le suivant. Lorsque Go exécute une coroutine, il lance un 守护线程compteur pour compter le nombre de coroutines exécutées par chaque processeur. Lorsqu'il constate que le nombre de coroutines exécutées par un processeur n'a pas changé après une période de temps, il insère une marque spéciale dans la pile de tâches de la coroutine.Lorsque la coroutine s'exécute et rencontre une fonction non en ligne, elle lit cette marque, s'interrompt et l'insère à la fin de la file d'attente de la coroutine.Puis passez à la coroutine suivante pour continuer à courir.
Un autre mécanisme de concurrence est celui-ci. Lorsqu'une coroutine est interrompue par le système, par exemple, lorsque les E/S doivent attendre, afin d'améliorer la concurrence globale, le processeur se déplace vers un autre thread système disponible et continue l'exécution D'autres coroutines dans la file d'attente de coroutine à laquelle il se bloque. Lorsque la coroutine qui a été interrompue la dernière fois est à nouveau réveillée, elle s'ajoute à l'une des files d'attente du processeur ou à la file d'attente globale. Pendant l'interruption de la coroutine, son état d'exécution dans le registre sera enregistré dans l'objet coroutine. Lorsque la coroutine aura une chance de s'exécuter à nouveau, les données seront à nouveau écrites dans le registre, puis continueront à s'exécuter.
En général, nous pouvons connaître la relation entre ce mécanisme de coroutine et les threads système 多对多, et comment il utilise efficacement les threads système pour exécuter autant de tâches de coroutine simultanées que possible.
Le premier : ordonnancement en cas de blocage de canal ou d'E/S réseau
Si G est bloqué sur une opération de canal ou une opération d'E/S réseau, G sera placé dans une file d'attente (attente) et M essaiera d'exécuter le prochain G exécutable de P. Si P n'a pas de G exécutable pour que M s'exécute à ce moment, alors M déliera P et M entrera dans l'état suspendu. Lorsque l'opération d'E / S est terminée ou que l'opération de canal est terminée, le G dans la file d'attente sera réveillé, marqué comme exécutable et mis dans la file d'attente d'un certain P, lié à un M pour continuer l'exécution.
Le deuxième type : la planification en cas de blocage des appels système
Si G est bloqué sur un appel système (appel système), alors non seulement G sera bloqué, mais M qui exécute ce G déliera également P, et M et G entreront ensemble dans l'état suspendu. S'il y a un M inactif à ce moment, alors P se liera à lui et continuera à exécuter d'autres G ; s'il n'y a pas de M inactif, mais qu'il y a encore d'autres G à exécuter, alors le runtime Go créera un nouveau M (thread ).
Au retour de l'appel système, G bloqué sur cet appel système tentera d'obtenir un P disponible, s'il n'y a pas de P disponible, alors G sera marqué comme exécutable (s'il n'y a pas de P disponible, après un certain nombre de tours, G sera mis dans le P global), le M suspendu précédent entrera à nouveau dans l'état suspendu (M entrera dans la liste libre après un certain temps et obtiendra à nouveau le P disponible).
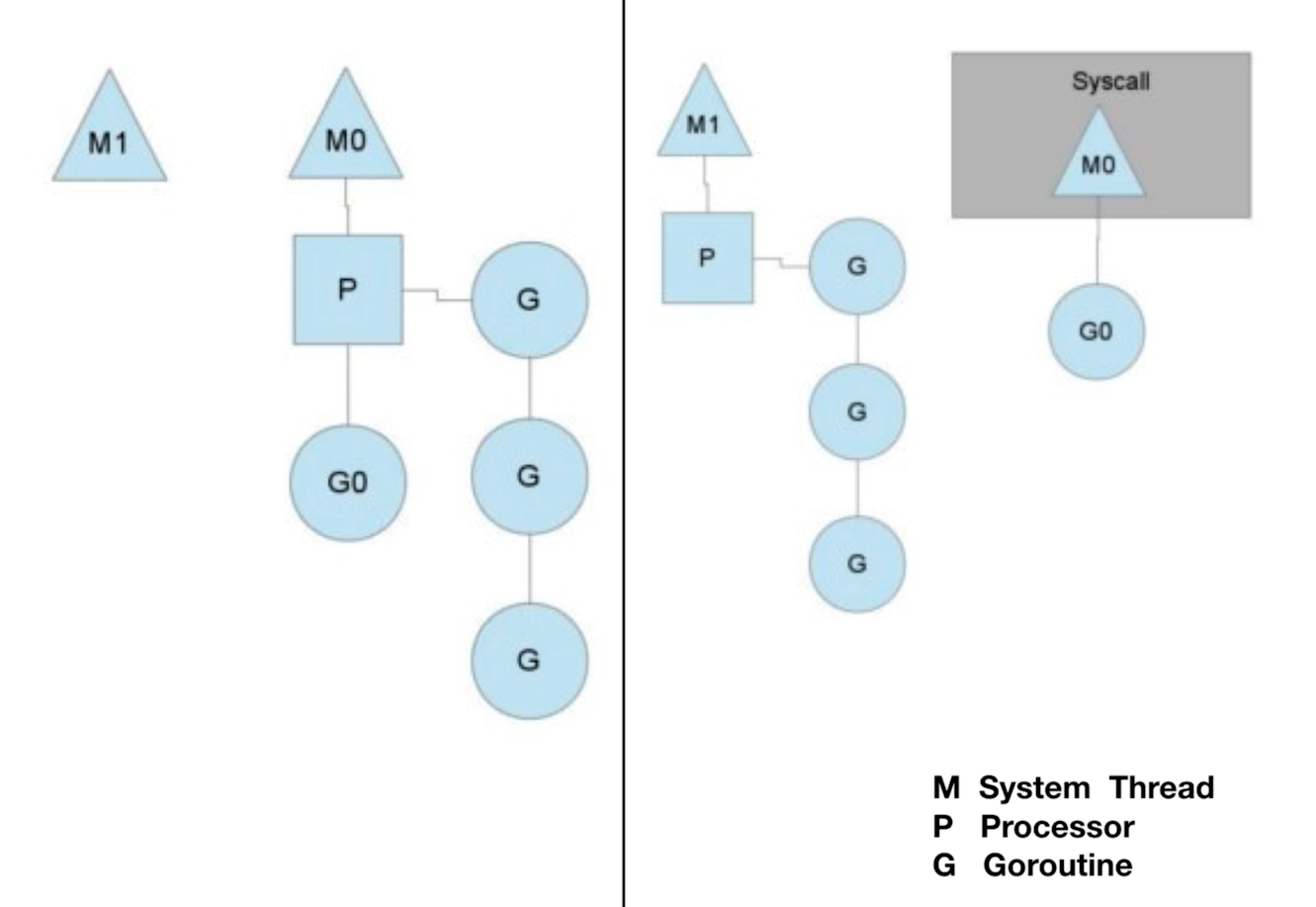
Pour une analyse détaillée, veuillez vous référer à cet article : Principe d'ordonnancement Go coroutine (goroutine)
Utilisation des coroutines Go
L'utilisation des coroutines Go est très simple, il suffit d'ajouter un gomot-clé devant la méthode.
// Go 协程的使用
func TestGoroutine(t *testing.T) {
for i := 0; i < 5; i++ {
// 加到匿名函数前
go func(i int) {
fmt.Println(i)
}(i)
}
time.Sleep(time.Millisecond * 50) // 让上面的程序先全部执行完
}

Le résultat de l'exécution est similaire à Java créant plusieurs threads, l'ordre dans lequel les coroutines sont appelées n'est pas planifié en fonction de l'ordre des méthodes.
simultanéité de la mémoire partagée
Serrure
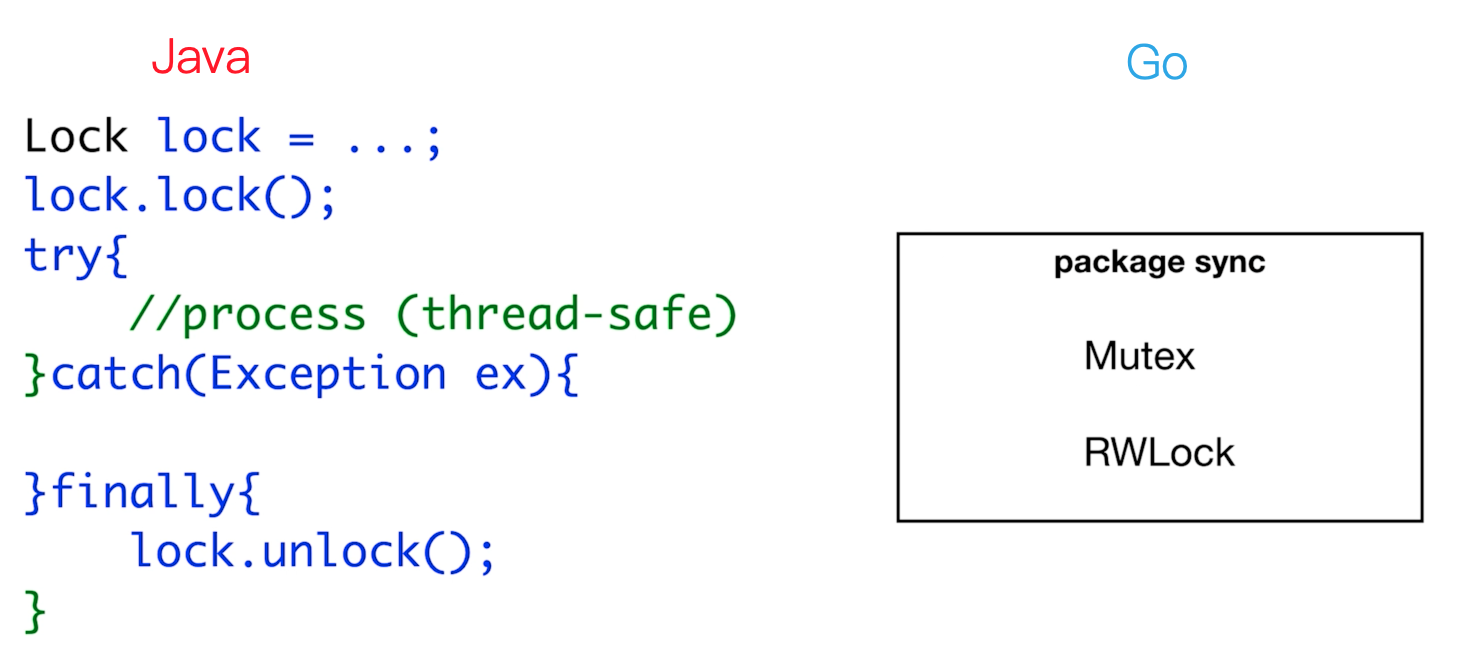
Non thread-safe
func TestCounter(t *testing.T) {
counter := 0
for i := 0; i < 5000; i++ {
go func() {
counter++ // 创建5000个协程,对counter自增了5000次 预期值为5000
}()
}
time.Sleep(1 * time.Second) // 使上面的程序先执行完
t.Logf("counter = %d", counter)
}
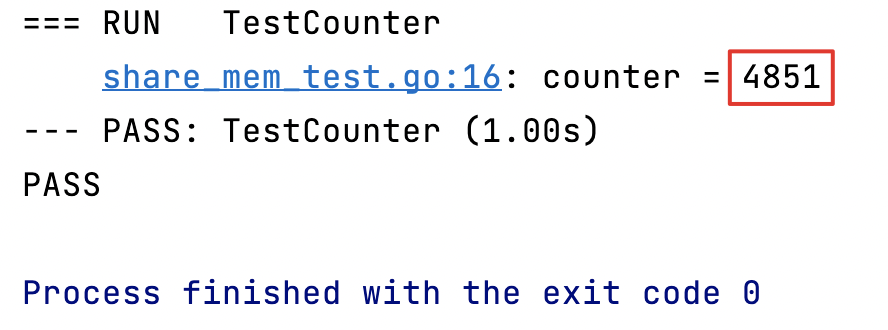
Il n'a pas répondu à nos attentes de 5000. En effet, le compteur que nous utilisons est en concurrence entre différentes coroutines, ce qui entraîne une concurrence simultanée, c'est-à-dire des programmes non sécurisés pour les threads et des opérations d'écriture non valides. Si nous voulons garantir la sécurité des threads, vous besoin de verrouiller cette mémoire partagée.
Synchronisation thread-safe.Mutex
func TestCounterSafe(t *testing.T) {
var mut sync.Mutex
counter := 0
for i := 0; i < 5000; i++ {
go func() {
// 锁的释放我们一般要写在defer中,类似java的finally。
defer func() {
mut.Unlock() // 在这个协程执行完的最后释放锁
}()
mut.Lock() // 加锁
counter++
}()
}
time.Sleep(1 * time.Second) // 使上面的程序先执行完
t.Logf("counter = %d", counter)
}

Répondez à nos 5000 attentes.
Groupe d'attente
joinLa méthode de synchronisation de chaque thread est équivalente à , en java CountDownLatch.
Ce n'est qu'après que tout le contenu de mon attente est terminé, que le programme peut continuer à s'exécuter vers le bas.
func TestCounterWaitGroup(t *testing.T) {
var mut sync.Mutex
var wg sync.WaitGroup
counter := 0
for i := 0; i < 5000; i++ {
wg.Add(1) // 每启动1个协程,WaitGroup的数量就+1
go func() {
// 锁的释放我们一般要写在defer中,类似java的finally。
defer func() {
mut.Unlock() // 在这个协程执行完的最后释放锁
}()
mut.Lock() // 加锁
counter++
wg.Done() // 每执行完1个协程,WaitGroup的数量就-1
}()
}
wg.Wait() // 如果WaitGroup中的数量不为0则一直等待
t.Logf("counter = %d", counter)
}

Alors pourquoi WaitGroup est-il meilleur ? Vous pouvez regarder le temps d'exécution final. Si vous utilisez time.Sleep(), car nous ne savons pas combien de temps il faudra pour exécuter 5000 coroutines. Ce temps n'est pas facile à contrôler. Dans l'ordre pour obtenir le résultat correct, nous avons estimé artificiellement 1 seconde, mais en fait, il ne faut que 0,00 seconde pour terminer l'exécution, donc l'utilisation de WaitGroup peut empêcher une mauvaise estimation du temps d'exécution de la coroutine et assurer la sécurité des threads, qui est le meilleur choix.
Verrouillage en lecture-écriture RWLock
Il sépare les verrous en lecture et les verrous en écriture. Les lectures ne sont pas mutuellement exclusives et les écritures sont mutuellement exclusives. Il est plus efficace que Mutex pour une exclusion mutuelle complète. Il est recommandé d'utiliser des verrous en lecture-écriture.
Mécanisme de concurrence CSP
Le processus de séquence de communication CSP (Communicating Sequential Processes) est un modèle de transmission de messages qui transmet les données entre les Goroutines via des canaux pour transmettre les messages, au lieu de verrouiller les données pour obtenir un accès synchrone aux données.
CSP VS Acteur
Modèle d'acteur

- Le mécanisme d'Actor consiste à communiquer directement, tandis que le mode CSP communique via des canaux , qui sont couplés de manière plus lâche.
- Les acteurs et Erlang utilisent des boîtes aux lettres pour stocker les messages. La capacité des boîtes aux lettres est illimitée, tandis que la capacité des canaux Go est limitée.
- Le processus de réception d'Actor et d'Erlang traite toujours les messages de manière passive, tandis que les coroutines de Go traitent activement les messages transmis depuis le canal.

Canaliser
Mécanisme de messagerie typique
L'expéditeur et le destinataire de la communication doivent être sur le canal en même temps pour terminer cette interaction, et l'absence de l'une des parties entraînera le blocage et l'attente de l'autre partie.
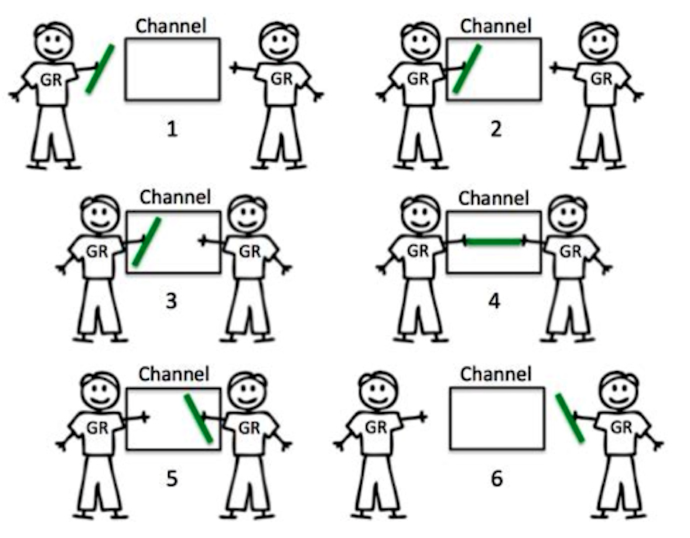
mécanisme de canal tampon
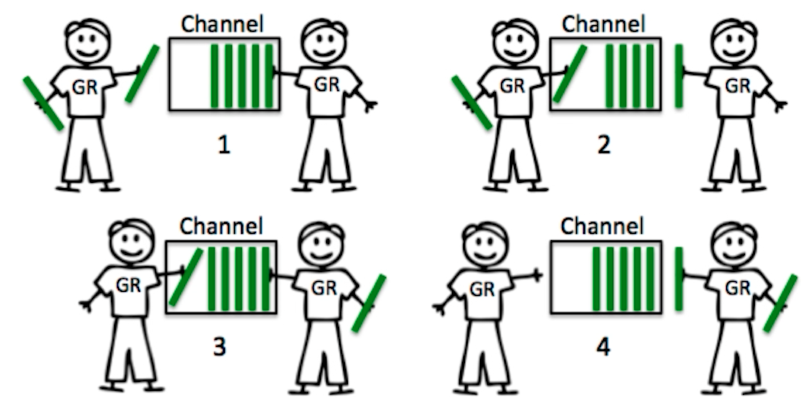
Dans ce mécanisme, l'expéditeur et le destinataire du message sont un mécanisme plus lâchement couplé. Nous pouvons définir une capacité pour le canal. Tant que la capacité n'est pas pleine, la personne qui met le message peut envoyer le message Put in, si la capacité est pleine, vous devez bloquer et attendre que la personne qui reçoit le message prenne un message, et la personne qui a mis le message peut continuer à le mettre. De la même manière, pour ceux qui reçoivent des messages, tant qu'il y a des messages dans ce canal, ils peuvent continuer à les recevoir jusqu'à ce qu'il n'y ait plus de messages dans le canal, et ils bloqueront et attendront que de nouveaux messages arrivent.
retour asynchrone
Lorsque nous appelons une tâche, nous n'avons pas besoin d'obtenir immédiatement son résultat de retour, nous pouvons d'abord exécuter une autre logique, jusqu'à ce que nous ayons besoin du résultat, puis obtenir le résultat. Cela réduira considérablement le temps d'exécution global du programme et améliorera l'efficacité du programme . Si nous obtenons le résultat de cette tâche, mais que le résultat de la tâche n'est pas sorti, il y sera bloqué jusqu'à ce que nous obtenions le résultat.
code java

synchrone (exécution en série)
func service() string {
time.Sleep(time.Millisecond * 50)
return "service执行完成"
}
func otherTask() {
fmt.Println("otherTask的各种执行逻辑代码")
time.Sleep(time.Millisecond * 100)
fmt.Println("otherTask执行完成")
}
// 测试同步执行效果, 先调用 service() 方法,在调用 otherTask() 方法,
// 理论上最后程序的执行时间为二者相加。
func TestService(t *testing.T) {
fmt.Println(service())
otherTask()
}
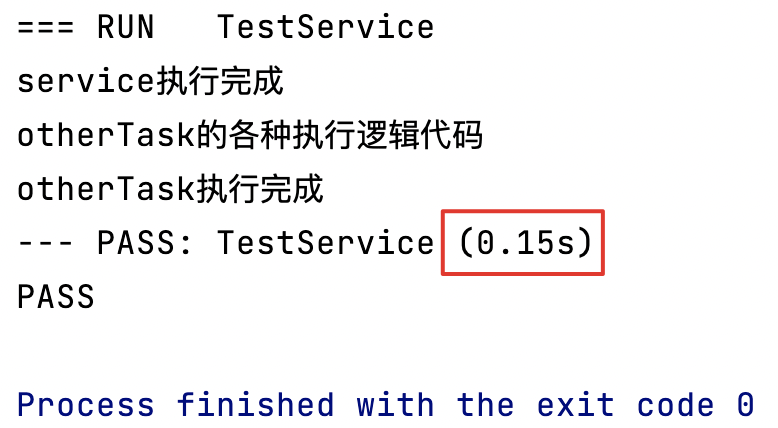
0.15s, Conforme aux attentes.
Le canal typique revient de manière asynchrone
func service() string {
time.Sleep(time.Millisecond * 50)
return "service执行完成"
}
func otherTask() {
fmt.Println("otherTask的各种执行逻辑代码")
time.Sleep(time.Millisecond * 100)
fmt.Println("otherTask执行完成")
}
func syncService() chan string {
// 声明一个channel,数据只能存放 string 类型
resCh := make(chan string)
// 创建一个协程去执行service任务
go func() {
ret := service()
fmt.Println("service 结果已返回")
// 因为不是用的 buffer channel,所以,协程会被阻塞在这一步的消息传递过程中,
// 只有接受者拿到了 channel 中的消息,channel 放完消息后面的逻辑才会被执行。
resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号
fmt.Println("channel 放完消息后面的逻辑")
}()
return resCh
}
// 异步返回执行结果,先调用 SyncService(),把它放入channel,用协程去执行,
// 然后主程序继续执行 otherTask(),最后把 SyncService() 的返回结果从 channel 里面取出来。
func TestSyncService(t *testing.T) {
resCh := syncService()
otherTask()
fmt.Println(<-resCh) // 取数据,从 channel 里面存放数据都用这个 “<-” 符号
}

Il est optimisé pour 0.1smontrer que otherTask()le temps d'exécution est de 0,1 seconde, service()car cela ne prend que 0,05 seconde, donc l'exécution est terminée à l'avance, et il n'est nécessaire de récupérer les résultats que si nécessaire, ce qui réduit considérablement le temps d'exécution global du programme.
“<-”Utilisez ce symbole pour stocker les données du canal- Déclarez le canal :
make(chan string)
le canal tampon revient de manière asynchrone
Nous constaterons qu'il y a encore un petit problème dans le mécanisme ci-dessus, c'est-à-dire qu'après l'exécution de service(), mettez des données dans le canal, et la coroutine sera bloquée ici à ce moment, et la coroutine attendra jusqu'à ce que le le récepteur reçoit le message. À l'avenir, pouvons-nous faire en sorte que la coroutine ne bloque pas ? Lorsque service() a fini de s'exécuter, nous plaçons le message dans le canal, puis continuons à exécuter une autre logique. La réponse est oui, à ce stade, notre canal tampon est utile.
func service() string {
time.Sleep(time.Millisecond * 50)
return "service执行完成"
}
func otherTask() {
fmt.Println("otherTask的各种执行逻辑代码")
time.Sleep(time.Millisecond * 100)
fmt.Println("otherTask执行完成")
}
// 异步执行 service(), 并将结果放入 buffer channel
func syncServiceBufferChannel() chan string {
// 声明一个 channel,数据只能存放 string 类型
// 后面的数字表示 buffer 的容量
resCh := make(chan string, 1)
go func() {
ret := service()
fmt.Println("service 结果已返回")
// 此时使用的是 buffer channel,所以只要 service() 结果返回了,buffer容量未满
// channel放完消息后面的逻辑就会被执行,不会被阻塞。
resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号
fmt.Println("channel 放完消息后面的逻辑")
}()
return resCh
}
// 异步返回执行结果,先调用 SyncService(),把它放入 buffer channel,用协程去执行,
// 此时协程不会被阻塞,然后主程序继续执行 otherTask(),
// 最后把 TestSyncServiceBufferChannel() 的返回结果从 channel 里面取出来。
func TestSyncServiceBufferChannel(t *testing.T) {
resCh := syncServiceBufferChannel()
otherTask()
fmt.Println(<-resCh) // 取数据,从 channel 里面存放数据都用这个 “<-” 符号
}

Nous constaterons qu'après l'adoption du canal tampon, lorsque le résultat de retour de service() est mis dans le canal tampon, la coroutine ne se bloque pas, mais continue à exécuter "la logique derrière le canal après avoir mis le message", et d'autres les résultats sont cohérents avec le canal typique.
Bien que le temps soit également le même 0.1s, il faut savoir que s'il y a beaucoup de tâches et que le temps d'exécution est long, l'optimisation doit être très évidente.
Contrôle du multiplexage et du timeout
sélectionner le mécanisme multiplex
La syntaxe de select est très similaire à la syntaxe de switch, son ordre d'exécution n'est pas nécessairement déterminé par le contexte de notre code, mais le résultat de quel cas est exécuté lorsque le cas est satisfait . Si tous les canaux sont bloqués, passez à la valeur par défaut.
select {
// 从 channel 上等待一个消息
case ret := <-retCh1:
t.Logf("result:%s", ret)
// 从另一个 channel 上等待一个消息
case ret := <-retCh2:
t.Logf("result:%s", ret)
// 如果所有的 channel 都处于阻塞中,则走 default
default:
t.Error("No more returned")
}
contrôle du délai d'attente
En utilisant le mécanisme de multiplexage de select, nous pouvons implémenter un mécanisme de timeout. Par exemple, lorsqu'un canal n'a pas renvoyé de message depuis longtemps, nous renverrons un timeout.
select {
case ret := <-retCh1:
t.Logf("result:%s", ret)
case ret := <-time.After(time.Second * 5):
t.Error("time out")
}
time.After()Après un certain temps, son canal spécifique renverra un message. Lorsque l'heure définie n'est pas atteinte, ce cas sera bloqué ici. Lorsque la durée que nous avons définie est dépassée, ce cas peut être obtenu à partir du canal. Un message, donc il peut être utilisé pour le contrôle du délai d'attente.
func service() string {
time.Sleep(time.Millisecond * 50)
return "service执行完成"
}
func otherTask() {
fmt.Println("otherTask的各种执行逻辑代码")
time.Sleep(time.Millisecond * 100)
fmt.Println("otherTask执行完成")
}
func syncService() chan string {
// 声明一个channel,数据只能存放 string 类型
resCh := make(chan string)
// 创建一个协程去执行service任务
go func() {
ret := service()
fmt.Println("service 结果已返回")
// 因为不是用的 buffer channel,所以,协程会被阻塞在这一步的消息传递过程中,
// 只有接受者拿到了 channel 中的消息,channel 放完消息后面的逻辑才会被执行。
resCh <- ret // 存数据,从 channel 里面存放数据都用这个 “<-” 符号
fmt.Println("channel 放完消息后面的逻辑")
}()
return resCh
}
// 异步返回执行结果,先调用 SyncService(), 把它放入channel,用协程去执行,
// 然后主程序继续执行 otherTask(),最后把 SyncService() 的返回结果 从 channel 里面取出来。
func TestSyncService(t *testing.T) {
select {
case ret := <-syncService():
otherTask()
t.Logf("result:%s", ret)
case <-time.After(time.Millisecond * 10):
t.Error("time out")
}
}

Étant donné que service() doit s'exécuter pendant 0,05 seconde, nous avons défini un délai d'attente de 0,01 seconde, donc le délai d'attente a disparu.
Fermeture de chaîne et diffusion
Que se passe-t-il si le canal n'est pas fermé
Écrivez un programme pour un producteur de données et un consommateur de données. Le producteur de données produit en continu des données, et le consommateur consomme en continu les données produites par le producteur et interagit via le canal.
// 数据生产者
func dataProducer(ch chan int, wg *sync.WaitGroup) chan int {
wg.Add(1)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
wg.Done()
}()
return ch
}
// 数据消费者
func dataConsumer(ch chan int, wg *sync.WaitGroup) {
wg.Add(1)
go func() {
for i := 0; i < 10; i++ {
data := <-ch
fmt.Println(data)
}
wg.Done()
}()
}
// 数据消费者
func dataConsumer2(ch chan int, wg *sync.WaitGroup) {
wg.Add(1)
go func() {
for i := 0; i < 10; i++ {
data := <-ch
fmt.Println(data)
}
wg.Done()
}()
}
// channel还未关闭的场景
func TestChannelNotClosed(t *testing.T) {
ch := make(chan int)
var wg sync.WaitGroup
dataProducer(ch, &wg)
dataConsumer(ch, &wg)
wg.Wait()
}
Une fois que les données que nous produisons sont incohérentes avec les données que nous consommons, par exemple, le producteur peut générer 11 numéros et le consommateur ne consomme toujours que 10 numéros, ou lorsque le producteur génère 10 numéros et le consommateur consomme 11 numéros, il signalera le erreur suivante :

Afin de résoudre ce problème, Go a besoin de toute urgence que la chaîne ait une fonction de fermeture, et tous les abonnés seront diffusés après la fermeture.
fermeture de canal

format grammatical
// 关闭 channel
close(channelName)
// ok=true表示正常接收,false表示通道关闭
if val, ok := <-ch; ok {
// other code
}
Lorsque le canal est normalement fermé et que le récepteur de données continue de recevoir des données, les données reçues sont la valeur par défaut des données correspondantes du canal.
// 数据生产者
func dataProducer(ch chan int, wg *sync.WaitGroup) chan int {
wg.Add(1)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
// 关闭 channel
close(ch)
//ch <- 11 // 向关闭的 channel 发送消息,会报 panic: send on closed channel
wg.Done()
}()
return ch
}
// 数据消费者
func dataReceiver(ch chan int, wg *sync.WaitGroup) {
wg.Add(1)
go func() {
// 我们这里多接收一个数据,看看拿到的值是什么
for i := 0; i < 11; i++ {
data := <-ch
fmt.Print(data, " ")
}
wg.Done()
}()
}
// 关闭channel
func TestCloseChannel(t *testing.T) {
ch := make(chan int)
var wg sync.WaitGroup
dataProducer(ch, &wg)
dataReceiver(ch, &wg)
wg.Wait()
}
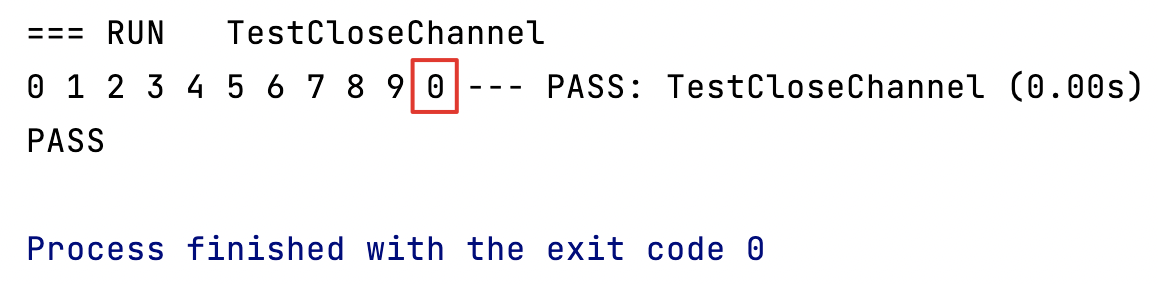
Nous constaterons que lorsque le canal est fermé, nous recevons une valeur supplémentaire. Puisque le type de données défini par notre canal est int, le type de données que nous obtenons sera la valeur par défaut de int type 0.
Généralement, une de nos chaînes peut correspondre à plusieurs consommateurs, ainsi lorsque la chaîne est fermée, le mécanisme de diffusion sera souvent utilisé pour informer tous les consommateurs que la chaîne a été fermée.
annulation de tâche
La solution traditionnelle est, en supposant qu'une tâche est en cours d'exécution, nous jugeons en définissant la valeur d'une variable dans la mémoire partagée truesur ou . falseNous allons maintenant utiliser CSP, sélectionner le mécanisme de multiplexage et la fermeture et la diffusion des canaux pour implémenter la fonction d'annulation de tâche.
Principe de réalisation
- Diffusez un message sur le canal via CSP pour dire à toutes les coroutines que tout le monde peut arrêter maintenant.
comment juger
- Grâce au mécanisme de multiplexage de sélection, si un message est reçu du canal, cela signifie que la fonction d'annulation de tâche doit être exécutée, sinon elle ne sera pas exécutée.
exemple de code
// 任务是否已被取消
// 实现原理:
// 检查是否从 channel 收到一个消息,如果收到一个消息,我们就返回 true,代表任务已经被取消了
// 当没有收到消息,channel 会被阻塞,多路选择机制就会走到 default 分支上去。
func isCanceled(cancelChan chan struct{
}) bool {
select {
case <-cancelChan:
return true
default:
return false
}
}
// 执行任务取消
// 因为 close() 是一个广播机制,所以所有的协程都会收到消息
func execCancel(cancelChan chan struct{
}) {
// close(cancelChan)会使所有处于处于阻塞等待状态的消息接收者(<-cancelChan)收到消息
close(cancelChan)
}
// 利用 CSP,多路选择机制和 channel 的关闭与广播实现任务取消功能
func TestCancel(t *testing.T) {
var wg sync.WaitGroup
cancelChan := make(chan struct{
}, 0)
// 启动 5 个协程
for i := 0; i < 5; i++ {
wg.Add(1)
go func(i int, cancelChan chan struct{
}, wg *sync.WaitGroup) {
// 做一个 while(true) 的循环,一直检查任务是否有被取消
for {
if isCanceled(cancelChan) {
fmt.Println(i, "is Canceled")
wg.Done()
break
} else {
// 其它正常业务逻辑
time.Sleep(time.Millisecond * 5)
}
}
}(i, cancelChan, &wg)
}
// 执行任务取消
execCancel(cancelChan)
wg.Wait()
}

Toutes les coroutines sont annulées.
close()Il s'agit d'un mécanisme de diffusion qui fera en sorte que tous les récepteurs de messages dans l'état d'attente bloquant reçoivent le message.
Contexte et annulation de tâche
Annulation des tâches associées
Scénario : Lorsque l'on lance plusieurs sous-tâches, sous-tâches et sous-tâches sont associées :
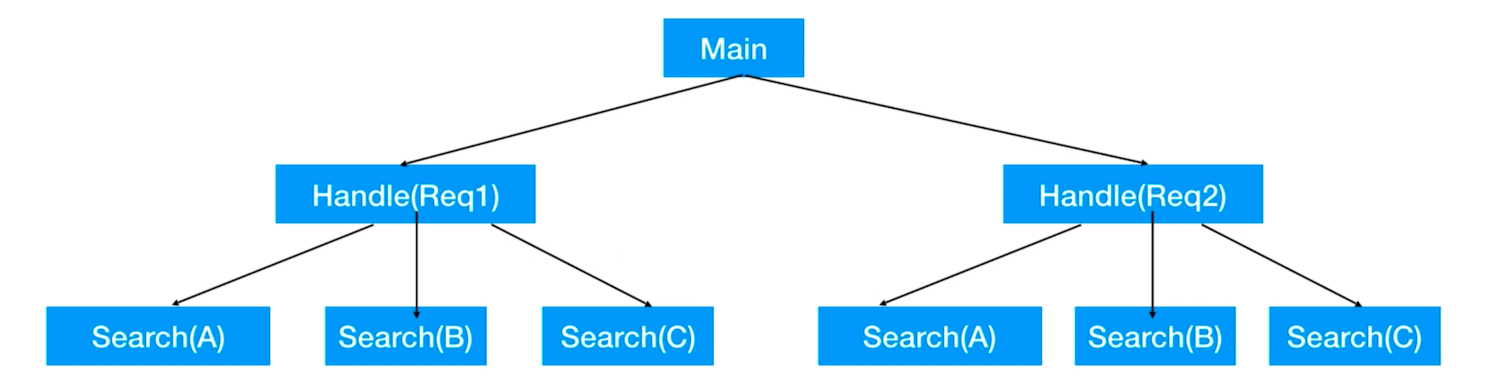
Si nous voulons simplement annuler la tâche d'un nœud feuille, cela peut être réalisé en utilisant CSP, en sélectionnant le mécanisme de multiplexage et la fermeture et la diffusion du canal.
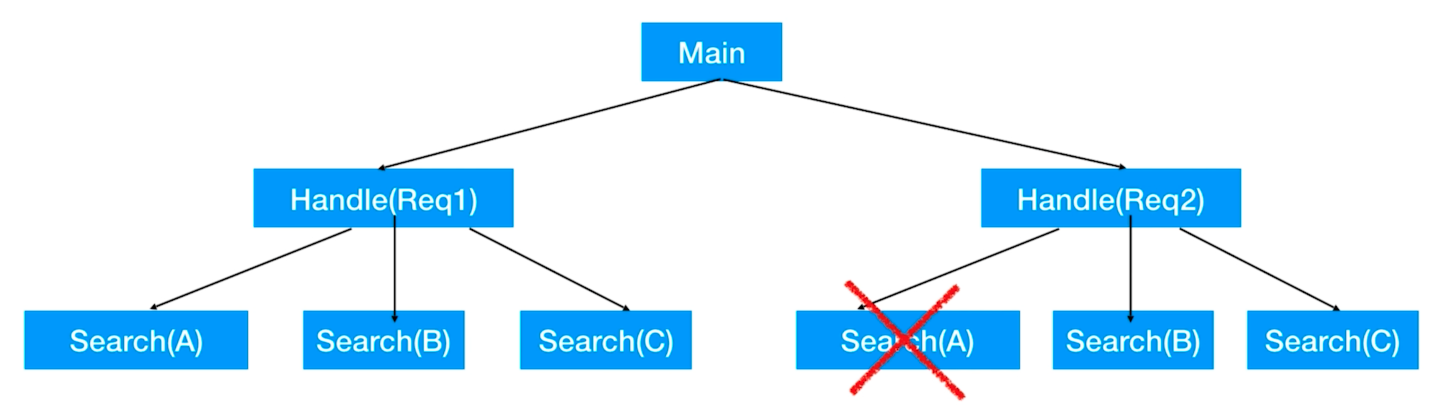
Mais notre scénario actuel est que lorsque nous annulons la tâche du nœud parent, nous voulons annuler toutes les tâches du nœud enfant, comment y parvenir ?
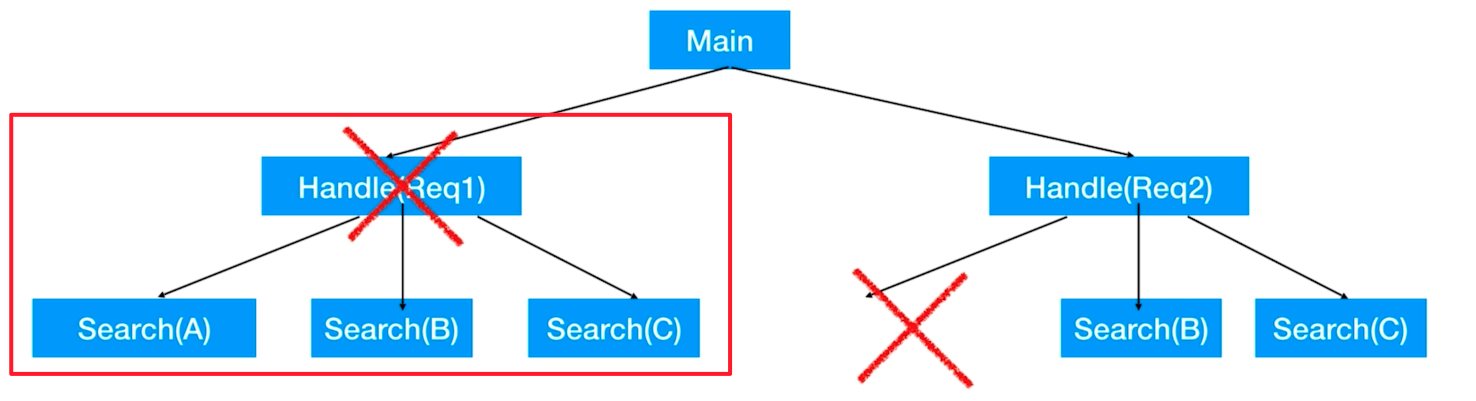
Bien sûr, nous pouvons l'implémenter nous-mêmes, mais depuis Golang 1.9, il a été Contextofficiellement intégré au package intégré de Go, et il est spécialement conçu pour le faire.
Contexte

ctx, cancel := context.WithCancel(context.Background())
context.WithCancel(), context.Background()une fois le nœud racine transmis, l'un des retours est ctx et l'autre est la méthode d'annulation, l'appel de la méthode d'annulation exécutera la fonction d'annulation. Et ctx peut être passé à la sous-tâche pour annuler la sous-tâche, de sorte que le nœud parent et la sous-tâche soient annulés. Le formulaire de notification d'annulation consiste à ctx.Done()faire passer le message pour juger de la réception de la notification. Ce ctx.Done() est analogue au close() du canal, tous les canaux recevront une notification.
Code
// 任务是否已被取消
// 实现原理:
// 通过 ctx.Done() 接收context的消息,如果收到消息,我们就返回 true,代表任务已经被取消了
// 当没有收到消息,多路选择机制就会走到 default 分支上去。
func isCanceled(ctx context.Context) bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}
// 通过context实现任务取消功能
func TestCancel(t *testing.T) {
var wg sync.WaitGroup
// ctx传到子节点中去,可以取消子节点,调用cancel()方法则执行取消功能
ctx, cancel := context.WithCancel(context.Background())
// 启动 5 个协程
for i := 0; i < 5; i++ {
wg.Add(1)
go func(i int, ctx context.Context, wg *sync.WaitGroup) {
// 做一个 while(true) 的循环,一直检查任务是否有被取消
for {
if isCanceled(ctx) {
fmt.Println(i, "is Canceled")
wg.Done()
break
} else {
// 其它正常业务逻辑
time.Sleep(time.Millisecond * 5)
}
}
}(i, ctx, &wg)
}
// 执行任务取消
cancel()
wg.Wait()
}
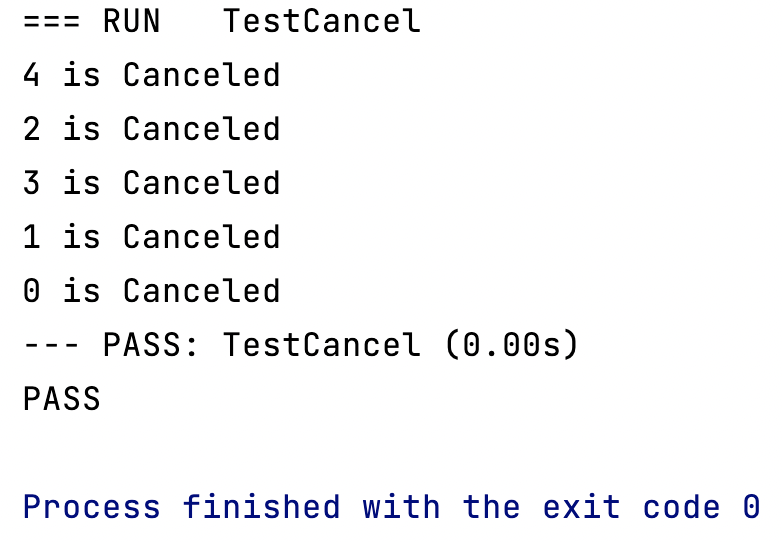
Les coroutines sont toutes annulées, comme prévu.
tâches simultanées
Exécuter une seule fois - modèle singleton
- Code Java - mode singleton - style paresseux - sécurité des threads (double vérification)

-
Aller coder
sync.Once()Il peut garantir que la méthode à l'intérieurDo()ne sera exécutée qu'une seule fois dans le cas d'un multi-threading.type Singleton struct { } var singleInstance *Singleton var once sync.Once // 获取一个单例对象 func GetSingletonObj() *Singleton { once.Do(func() { fmt.Println("Create a singleton Obj") singleInstance = new(Singleton) }) return singleInstance } // 启动多个协程,测试我们单例对象是否只创建了一次 func TestGetSingletonObj(t *testing.T) { var wg sync.WaitGroup for i := 0; i < 5; i++ { wg.Add(1) go func() { obj := GetSingletonObj() fmt.Printf("%x\n", unsafe.Pointer(obj)) wg.Done() }() } wg.Wait() }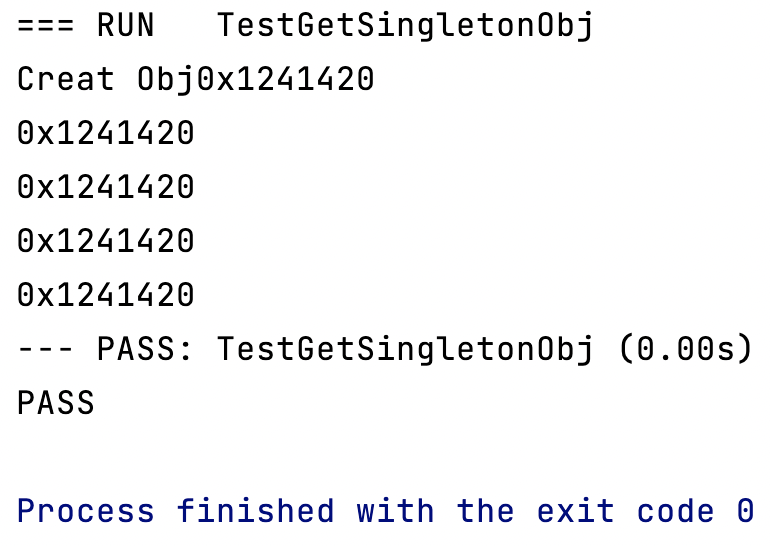
On peut voir que
Do()le contenu de sortie dans la méthode n'est imprimé qu'une seule fois et que les valeurs d'adresse obtenues par plusieurs coroutines sont les mêmes, réalisant le mode singleton.
N'importe quelle tâche à accomplir
Lorsque nous devons effectuer de nombreuses tâches simultanées, mais tant qu'une tâche est terminée, le résultat peut être renvoyé à l'utilisateur. Par exemple, si nous recherchons un certain terme de recherche sur Baidu et Google en même temps, si un moteur de recherche revient en premier, nous pouvons renvoyer le résultat à l'utilisateur, et il n'est pas nécessaire de renvoyer tous les scénarios.
- Ici nous utilisons le mécanisme de CSP pour réaliser ce mode
// 从网站上执行搜索功能
func searchFromWebSite(webSite string) string {
time.Sleep(10 * time.Millisecond)
return fmt.Sprintf("search from %s", webSite)
}
// 收到第一个结果后立刻返回
func FirstResponse() string {
var arr = [2]string{
"baidu", "google"}
// 防止协程泄露,这里用 buffer channel 很重要,否则可能导致剩下的协程会被阻塞在那里,
// 当阻塞的协程达到一定量后,最终可能导致服务器资源耗尽而出现重大故障
ch := make(chan string, len(arr))
for _, val := range arr {
go func(v string) {
// 拿到所有结果放入 channel
ch <- searchFromWebSite(v)
}(val)
}
// 这里没有使用 WaitGroup,因为我们的需求是当 channel 收到第一个消息后就立刻返回
return <-ch
}
func TestFirstResponse(t *testing.T) {
t.Log("Before:", runtime.NumGoroutine()) // 输出当前系统中的协程数
t.Log(FirstResponse())
t.Log("After:", runtime.NumGoroutine()) // 输出当前系统中的协程数
}
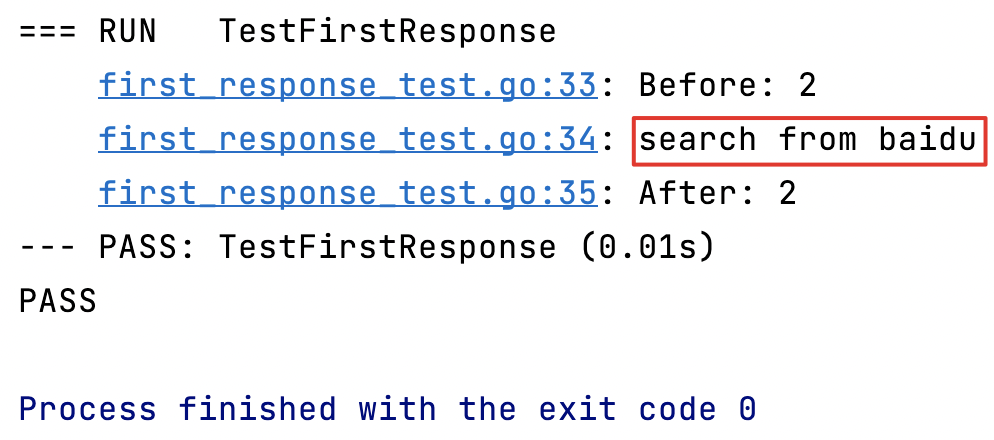
toutes les tâches terminées
Parfois, nous devons terminer toutes les tâches avant de passer au lien suivant. Lorsque nous passons une commande avec succès, ce n'est que lorsque les points et les coupons sont donnés que toutes les remises ont été accordées avec succès.
Ce mode peut bien sûr être implémenté avec WaitGroup, mais nous utiliserons ici le mécanisme CSP pour l'implémenter.
// 送豪礼方法
func sendGift(gift string) string {
time.Sleep(10 * time.Millisecond)
return fmt.Sprintf("送%s", gift)
}
// 使用 CSP 拿到所有的结果才返回
func CspAllResponse() []string {
var arr = [2]string{
"优惠券", "积分"}
// 防止协程泄露,这里用 buffer channel 很重要,否则可能导致剩下的协程会被阻塞在那里,
// 当阻塞的协程达到一定量后,最终可能导致服务器资源耗尽而出现重大故障
ch := make(chan string, len(arr))
for _, val := range arr {
go func(v string) {
// 拿到所有结果放入 channel
ch <- sendGift(v)
}(val)
}
var finalRes = make([]string, len(arr), len(arr))
// 等到所有的的协程都执行完毕,把结果一起返回
for i := 0; i < len(arr); i++ {
finalRes[i] = <-ch
}
return finalRes
}
func TestAllResponse(t *testing.T) {
t.Log("Before:", runtime.NumGoroutine())
t.Log(CspAllResponse())
t.Log("After:", runtime.NumGoroutine())
}

pool d'objets
Dans notre développement quotidien, il y a souvent des connexions à la base de données, des connexions réseau, etc., et nous avons souvent besoin de les mutualiser pour éviter que des objets soient créés à plusieurs reprises. En langage Go, nous pouvons utiliser un canal tamponné pour implémenter le pool d'objets. En définissant la taille du tampon pour définir la taille du pool, nous pouvons obtenir un objet de ce pool de tampons et le renvoyer au canal lorsqu'il est épuisé.
// 可重用对象,比如连接等
type Reusable struct {
}
// 对象池
type ObjPool struct {
bufChan chan *Reusable // 用于缓存可重用对象
}
// 创建一个包含多个可重用对象的对象池
func NewObjPool(numOfObj int) *ObjPool {
// 声明对象池
objPool := ObjPool{
}
// 初始化 objPool.bufChan 为一个 channel
objPool.bufChan = make(chan *Reusable, numOfObj)
// 往 objPool 对象池里面放多个可重用对象
for i := 0; i < numOfObj; i++ {
objPool.bufChan <- &Reusable{
}
}
return &objPool
}
// 从对象池拿到一个对象
func (objPool *ObjPool) GetObj(timeout time.Duration) (*Reusable, error) {
select {
case ret := <-objPool.bufChan:
return ret, nil
case <-time.After(timeout): // 超时控制
return nil, errors.New("time out")
}
}
// 将可重用对象还回对象池
func (objPool *ObjPool) ReleaseObj(ReusableObj *Reusable) error {
select {
case objPool.bufChan <- ReusableObj:
return nil
default:
return errors.New("overflow") // 超出可重用对象池容量
}
}
// 从对象池里面拿出对象,用完了再放回去
func TestObjPool(t *testing.T) {
pool := NewObjPool(3)
for i := 0; i < 3; i++ {
if obj, err := pool.GetObj(time.Second * 1); err != nil {
t.Error(err)
} else {
fmt.Printf("%T\n", obj)
if err := pool.ReleaseObj(obj); err != nil {
t.Error(err)
}
}
}
t.Log("Done")
}
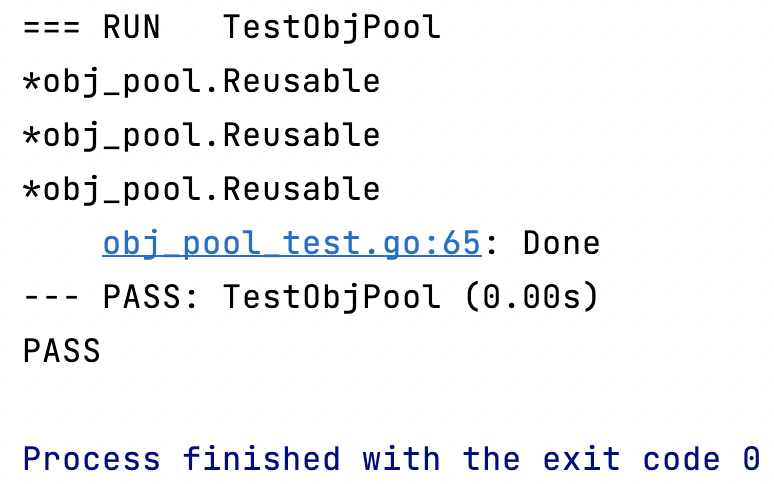
cache d'objets sync.Pool
En fait, sync.Pool n'est pas une classe de pool d'objets, mais un cache d'objets, appelé sync.Cache, est plus approprié.
sync.Pool a deux concepts importants, objet privé et pool partagé :
- Objet privé : Coffre-fort Coroutine, aucun cadenas requis lors de l'écriture.
- Piscine partagée : Les coroutines ne sont pas sécurisées, et des cadenas sont nécessaires lors de l'écriture.
Les deux sont stockés dans le dont nous avons parlé plus tôt Processor.
acquisition d'objets sync.Pool
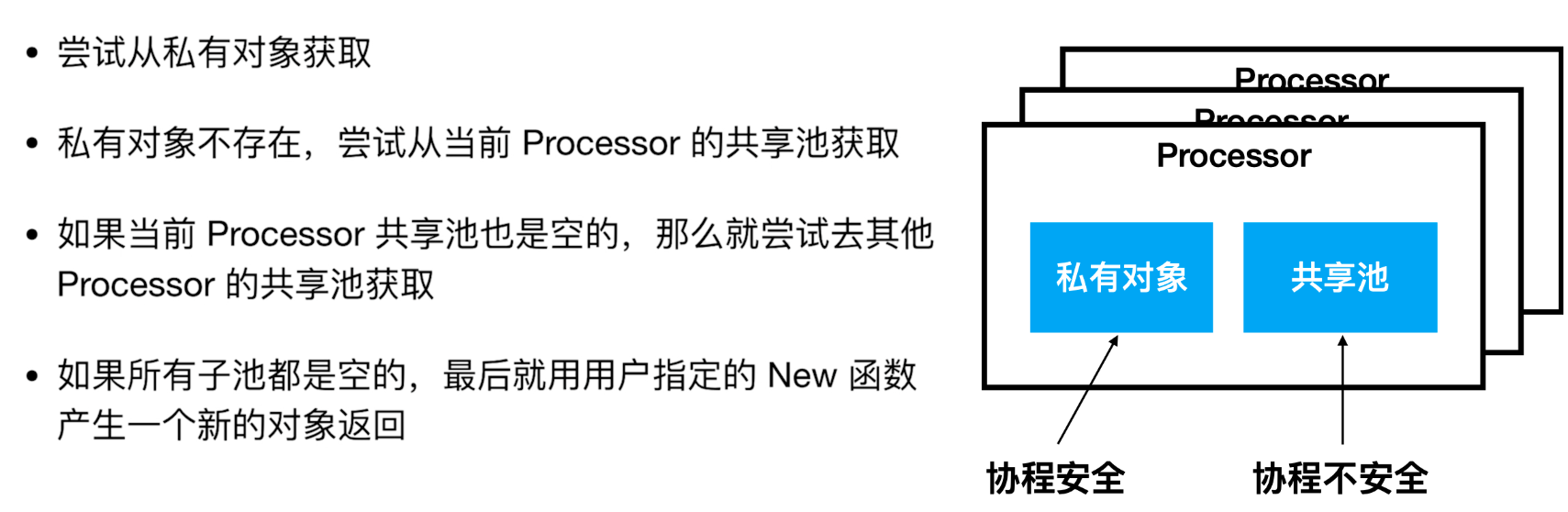
objet sync.Pool remis en place

Cycle de vie sync.Pool

C'est pourquoi il ne peut pas être utilisé comme pool d'objets.
Utiliser sync.Pool
伪代码
// 使用 New 关键字创建新对象
pool := &sync.Pool{
New: func() interface{
} {
return 0
},
}
// 从 pool 中获取一个对象,因为返回的是空接口interface{},所以要自己做断言
array := pool.Get().(int)
// 往 pool 中放入一个对象
pool.Put(10)
utilisation de base
// 调试 sync.Pool 对象
func TestSyncPool(t *testing.T) {
pool := &sync.Pool{
New: func() interface{
} {
fmt.Println("Create a new object")
return 1
},
}
// 第一次从池中获取对象,我们知道它一定是空的,所有肯定会调用 New 方法去创建一个新对象
v := pool.Get().(int)
fmt.Println(v) // 1
// 放一个不存在的对象,它会优先放入私有对象
pool.Put(2)
// 此时私有对象已经存在了,所以会优先拿到私有对象的值
v1 := pool.Get().(int)
fmt.Println(v1) // 2
// 模拟系统调用GC, GC会清除 sync.pool中缓存的对象
//runtime.GC()
}

Un GC se produit pendant le processus :
// 调试 sync.Pool 对象
func TestSyncPool2(t *testing.T) {
pool := &sync.Pool{
New: func() interface{
} {
fmt.Println("Create a new object")
return 1
},
}
// 第一次从池中获取对象,我们知道它一定是空的,所有肯定会调用 New 方法去创建一个新对象
v := pool.Get().(int)
fmt.Println(v) // 1
// 放一个不存在的对象,它会优先放入私有对象
pool.Put(2)
// 模拟系统调用GC, GC会清除 sync.pool中缓存的对象
runtime.GC()
// 此时私有对象已经被GC掉了,所以这里又新建了一次对象
v1 := pool.Get().(int)
fmt.Println(v1) // 1
}

Le nouvel objet est créé 2 fois, comme prévu.
Remarque : L'objet nouvellement créé à l'aide
Get()de la méthode ne sera pas placé dans l'objet privé, seulePut()la méthode sera placée dans l'objet privé.
Application en multi-coroutine
// 调试 sync.Pool 在多个协程中的应用场景
func TestSyncPoolInMultiGoroutine(t *testing.T) {
pool := sync.Pool{
New: func() interface{
} {
fmt.Println("Create a new object")
return 0
},
}
pool.Put(1)
pool.Put(2)
pool.Put(3)
var wg sync.WaitGroup
for i := 0; i < 5; i++ {
wg.Add(1)
go func() {
v, _ := pool.Get().(int)
fmt.Println(v)
wg.Done()
}()
}
wg.Wait()
}

sync.Résumé du pool

Test de l'unité
Cadre de test unitaire intégré

func TestErrorInCode(t *testing.T) {
fmt.Println("Start")
t.Error("Error")
fmt.Println("End")
}
func TestFailInCode(t *testing.T) {
fmt.Println("Start")
t.Fatal("Error")
fmt.Println("End")
}
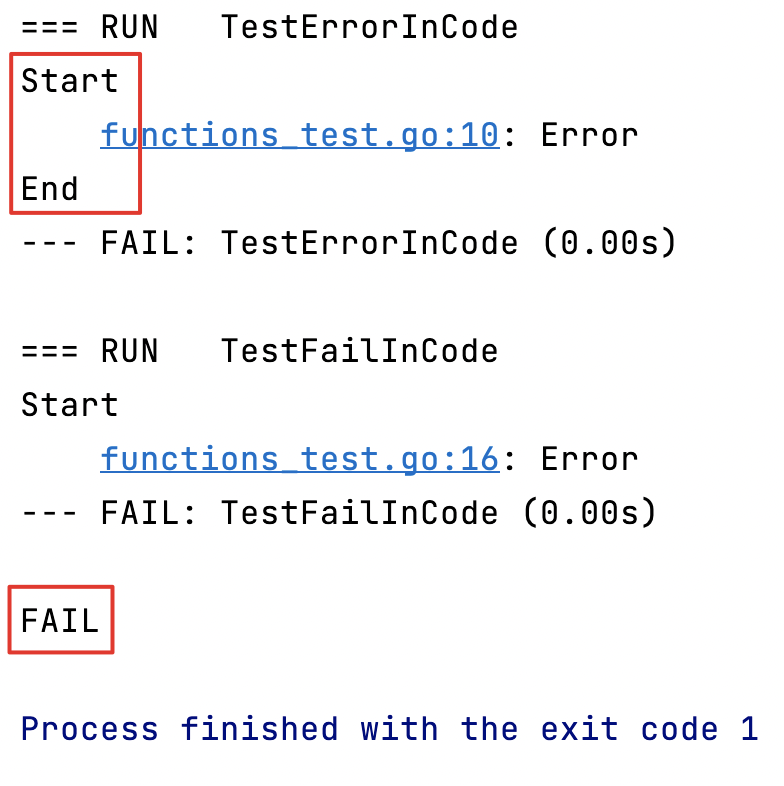
Avec Errorla méthode de test, le test continue son exécution, avec Fatalla méthode de test, le test est interrompu.
afficher la couverture du code
go test -v -cover
Affirmation
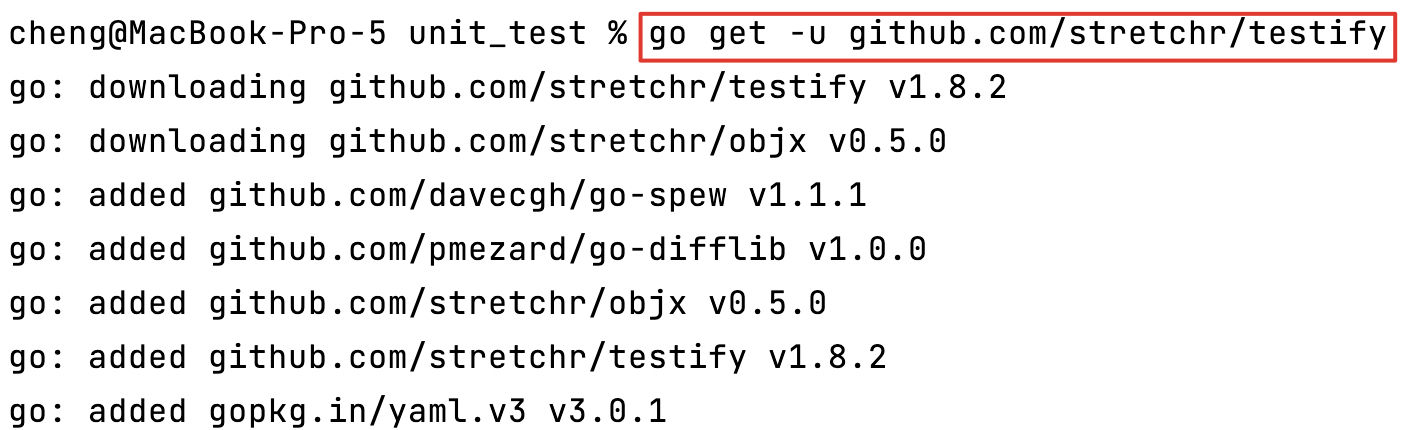
installer assert:
go get -u github.com/stretchr/testify
// 平方 故意+1计算错误,使断言生效
func square(num int) int {
return num * num + 1
}
// 表格测试法
func TestSquare(t *testing.T) {
// 输入值
inputs := [...]int{
1, 2, 3}
// 期望值
expected := [...]int{
2, 4, 9}
for i := 0; i< len(inputs); i++ {
ret := square(inputs[i])
// 调用 assert 断言包
assert.Equal(t, expected[i], ret)
}
}

Référence
utiliser
- Effectuez une évaluation des performances de certains fragments de code dans le programme et comparez quelle méthode d'écriture est la meilleure.
- Effectuez une évaluation de la bibliothèque tierce pour voir quelle bibliothèque est la plus performante.
Exemple d'utilisation
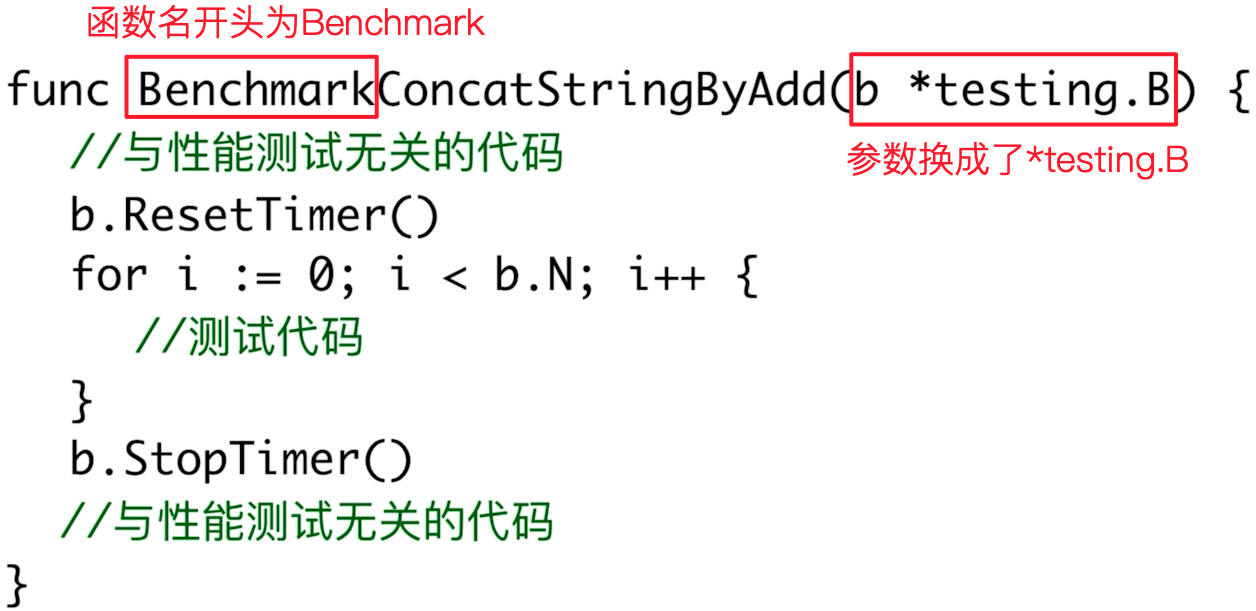
Utilisez b.ResetTimer()et b.StopTimer()pour isoler le code non pertinent pour les tests de performances.
Test de code : comparaison des performances de la concaténation de chaînes
// 通过“+=”的方式拼接字符串
func ConcatStringByLink() string {
elements := [...]string{
"1", "2", "3", "4", "5", "6", "7", "8", "9", "10",
"11", "12", "13", "14", "15", "16", "17", "18", "19", "20"}
str := ""
for _, elem := range elements {
str += elem
}
return str
}
// 通过字节数组 bytes.buffer 拼接字符串
func ConcatStringByBytesBuffer() string {
elements := [...]string{
"1", "2", "3", "4", "5", "6", "7", "8", "9", "10",
"11", "12", "13", "14", "15", "16", "17", "18", "19", "20"}
var buf bytes.Buffer
for _, elem := range elements {
buf.WriteString(elem)
}
return buf.String()
}
// 用benchmark测试字符串拼接方法的性能
func BenchmarkConcatStringWithLink(b *testing.B) {
// 与性能测试无关的代码的开始位置
b.ResetTimer()
for i := 0; i < b.N; i++ {
ConcatStringByLink()
}
// 与性能测试无关代码的结束为止
b.StopTimer()
}
// 用 benchmark 测试 bytes.buffer 连接字符串的性能
func BenchmarkConcatStringWithByteBuffer(b *testing.B) {
// 与性能测试无关的代码的开始位置
b.ResetTimer()
for i := 0; i < b.N; i++ {
ConcatStringByBytesBuffer()
}
// 与性能测试无关代码的结束为止
b.StopTimer()
}
| Chemin | le code s'exécute | temps d'exécution unique |
|---|---|---|
utiliser +=la couture |
1813815 | 649,9 ns/opération |
utiliser bytes.Bufferla couture |
6804018 | 172,6 ns/opération |
Il ne s'agit que de 20 chaînes concaténées, l'écart serait plus visible si plus de chaînes étaient concaténées.
commande native
// -bench= 后面跟方法名,如果是所有方法就写"."
go test -bench=.
// 注意:windows下使用 go test 命令时, -bench=.应该写成 -bench="."
// 如果想知道 代码每一次的内存分配情况,这种方案为什么快,那种方案为什么慢,可以加一个-benchmem参数
go test -bench=. -benchmem

Grâce +=à la façon dont nous utilisons pour allocsallouer de l'espace 19 fois au total, mais byte.Bufferune seule fois par la méthode, l'amélioration des performances est là.
BDD
BDD (Behavior Driven Development), développement piloté par le comportement.
Afin de rendre la communication entre nous et nos clients plus fluide, nous utiliserons le même "langage" pour décrire un système pour éviter le problème des incohérences dans l'expression, et quand il y a un comportement, que se passera-t-il.


BDD en Go
site web du projet goconvey :
Installer
go get -u github.com/smartystreets/goconvey/convey
exemple de code
package bdd
import (
"testing"
// 前面这个"."点,表示将import进来的package的方法是在当前名字空间的,可以直接使用里面的方法
// 例如使用 So()方法,就可以直接用,不用写成 convey.So()
. "github.com/smartystreets/goconvey/convey"
)
// BDD框架 convey的使用
func TestSpec(t *testing.T) {
Convey("Given 2 even numbers", t, func() {
a := 3
b := 4
Convey("When add the two numbers", func() {
c := a + b
Convey("Then the result is still even", func() {
So(c%2, ShouldEqual, 0) // 判断c % 2是否为 0
})
})
})
}

Démarrer l'interface utilisateur WEB
~/go/bin/goconvey

L'interface web est très conviviale :
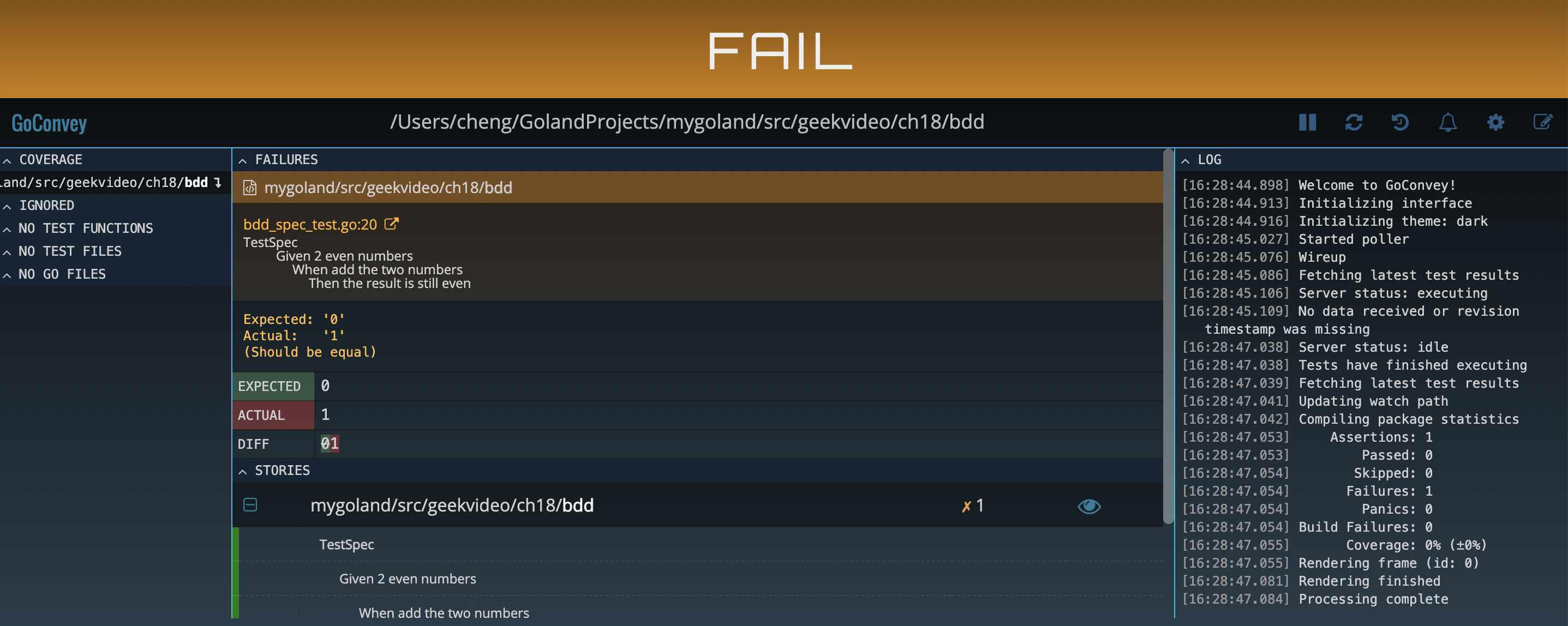
S'il y a un conflit de port, vous pouvez le résoudre comme ceci
~/go/bin/goconvey -port 8081
Les notes sont organisées à partir du didacticiel vidéo Geek Time : Go language from entry to real combat