Flink est utilisé pour traiter l'informatique en continu avec état. Il doit traiter les données du côté source, puis les écrire du côté du récepteur. La figure suivante montre le traitement des données dans Flink. Aujourd'hui, je vais le partager avec vous en fonction de ceci image.
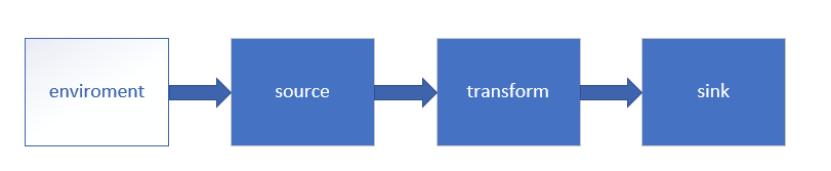
Démarrez rapidement
1. Ajouter des dépendances
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.2</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.3</version>
</dependency>
<!-- This dependency is provided, because it should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.12.7</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency>2. Lire les données kafka
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> transactions = env
.addSource(new FlinkKafkaConsumer<>(topicName, new SimpleStringSchema(), properties));
transactions.print();
env.execute();01 Environnement
Tous les programmes Flink démarrent à partir de cette étape, ce n'est que lorsque l'environnement d'exécution est créé que l'étape suivante peut être écrite. Vous pouvez utiliser les méthodes suivantes pour obtenir l'environnement d'exploitation :
(1)getExecutionEnvironment
Créer un environnement d'exécution, qui représente le contexte du programme en cours d'exécution
Si le programme a été appelé indépendamment, cette méthode renvoie l'environnement d'exécution local
Si le programme a été appelé à partir d'un client en ligne de commande pour être soumis à un cluster, cette méthode renvoie l'environnement d'exécution de ce cluster
Il déterminera le type d'environnement d'exécution à renvoyer en fonction de la manière dont la requête est exécutée.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();02 Source et puits
Source est la source de données dans Flink et Sink est le terminal de sortie de données. Flink est connecté au système de stockage externe via le connecteur de streaming Flink. Flink effectue principalement l'échange de données de quatre manières :
Flink prédéfini Source et Sink
Connecteurs bornés fournis à l'intérieur de Flink
Connecteurs dans des projets Apache Bahir tiers
Mode E/S asynchrone
Ce qui suit présente principalement le contenu prédéfini et les connecteurs liés. Pour plus de contenu, reportez-vous à
(1) Source et puits prédéfinis
Examinons d'abord le Source intégré fourni par Flink.Ces méthodes sont situées dans la classe StreamExecutionEnvironment.

Le récepteur intégré dans Flink est illustré dans la figure ci-dessous, tous situés dans la classe DataStream.
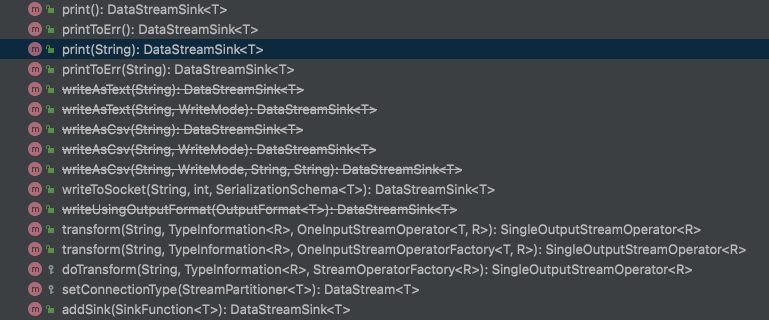
Source et récepteur basés sur des fichiers
lire les données d'un fichier texte
env.readTextFile(path)Écrire les résultats au format texte ou csv dans un fichier
dataStream.writeAsText(path) ;
dataStream.writeAsCsv(path);(2) Connecteur intégré
Sur le site officiel, les connecteurs suivants sont donnés :
Apache Kafka (source/puits)
JDBC (récepteur)
Apache Cassandra (sink)
Amazon Kinesis Streams (source/sink)
Elasticsearch (sink)
FileSystem (sink)
RabbitMQ (source/sink)
Google PubSub (source/sink)
Hybrid Source (source)
Apache NiFi (source/sink)
Apache Pulsar (source)
Twitter Streaming API (source)
在使用过程中,提交 Job 的时候需要注意, job 代码 jar 包中一定要将相应的 connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常
(3) 自定义Source&Sink
除了上述的Source与Sink外,Flink还支持自定义Source与Sink。
自定义Source
实现SourceFunction类
重写run方法和cancel方法
在主函数中通过addSource调用
public class MySource implements SourceFunction<String> {
// 定义一个运行标志位,表示数据源是否运行
Boolean flag = true;
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (flag){
sourceContext.collect("当前时间为:" + System.currentTimeMillis());
Thread.sleep(100);
}
}
@Override
public void cancel() {
flag = false;
}
}
自定义Sink
继承SinkFunction
重写invoke方法
下面给出了自定义JDBC Sink的案例,可以参考
public class MyJdbcSink extends RichSinkFunction<String> {
// 定义连接
Connection conn;
// 创建连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","root");
}
// 关闭连接
@Override
public void close() throws Exception {
super.close();
conn.close();
}
// 调用连接执行SQL
@Override
public void invoke(String value, Context context) throws Exception {
PreparedStatement preparedStatement = conn.prepareStatement(value);
preparedStatement.execute();
preparedStatement.close();
}
}
env.addSink(newMyJdbcSink()); rongHeStream.addSink(JdbcSink.sink(
"INSERT INTO ronghe_log VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
(preparedStatement, rongHeLog) -> {
preparedStatement.setObject(1, rongHeLog.getId());
preparedStatement.setObject(2, rongHeLog.getDeviceNum());
preparedStatement.setObject(3, rongHeLog.getSrcIp());
preparedStatement.setObject(4, rongHeLog.getSrcPort());
preparedStatement.setObject(5, rongHeLog.getDstIp());
preparedStatement.setObject(6, rongHeLog.getDstPort());
preparedStatement.setObject(7, rongHeLog.getProtocol());
preparedStatement.setObject(8, new Timestamp(rongHeLog.getLastOccurTime()));
//SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//Date date = new Date(rongHeLog.getLastOccurTime());
//String dateStr = simpleDateFormat.format(date);
preparedStatement.setObject(9, rongHeLog.getCount());
try {
String idListJson = objectMapper.writeValueAsString(rongHeLog.getSourceLogIds());
preparedStatement.setObject(10, idListJson);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
},
JdbcExecutionOptions.builder()
.withBatchSize(10)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://81.70.199.213:3306/flink21?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false")
.withUsername("root")
.withPassword("lJPWRbm06NbToDL03Ecj")
.build()
));