Optimisation du déchargement des calculs pour l'informatique de périphérie mobile assistée par UAV : une approche de gradient de politique déterministe profonde
Documents de référence :
[1] Wang Y, Fang W, Ding Y et al. Optimisation du déchargement des calculs pour l'informatique de périphérie mobile assistée par UAV : une approche déterministe profonde du gradient de politique [J]. Réseaux sans fil, 2021 : 1-16.doi: https://doi.org/10.1007/s11276-021-02632-zCode
:
fangvv/UAV-DDPG
Combinant papiers et codes open source pour expliquer en détail l'algorithme DDPG, voici le code pour bien tourner (le code ici est aussi modifié en fonction d'Internet, l'algorithme DDPG est déjà fixé et l'innovation ne peut se faire qu'en termes de modélisation. La classe d'environnement doit être écrite par vous-même et l'algorithme DDPG peut être directement appliqué. Utilisez tensorboard pour exporter le tenseur graphique de flux C'est un très bon outil de visualisation qui aide à clarifier le code, le diagramme tensorboard du code est le suivant, et ce qui suit sera expliqué en détail sur la base de ce diagramme. (Nécessite des connaissances théoriques sur l'apprentissage par renforcement et une certaine compréhension de tensorflow et de python. Le blog précédent propose un itinéraire d'apprentissage gratuit du système d'apprentissage par renforcement. Il sera plus convivial de lire ce blog après avoir appris)
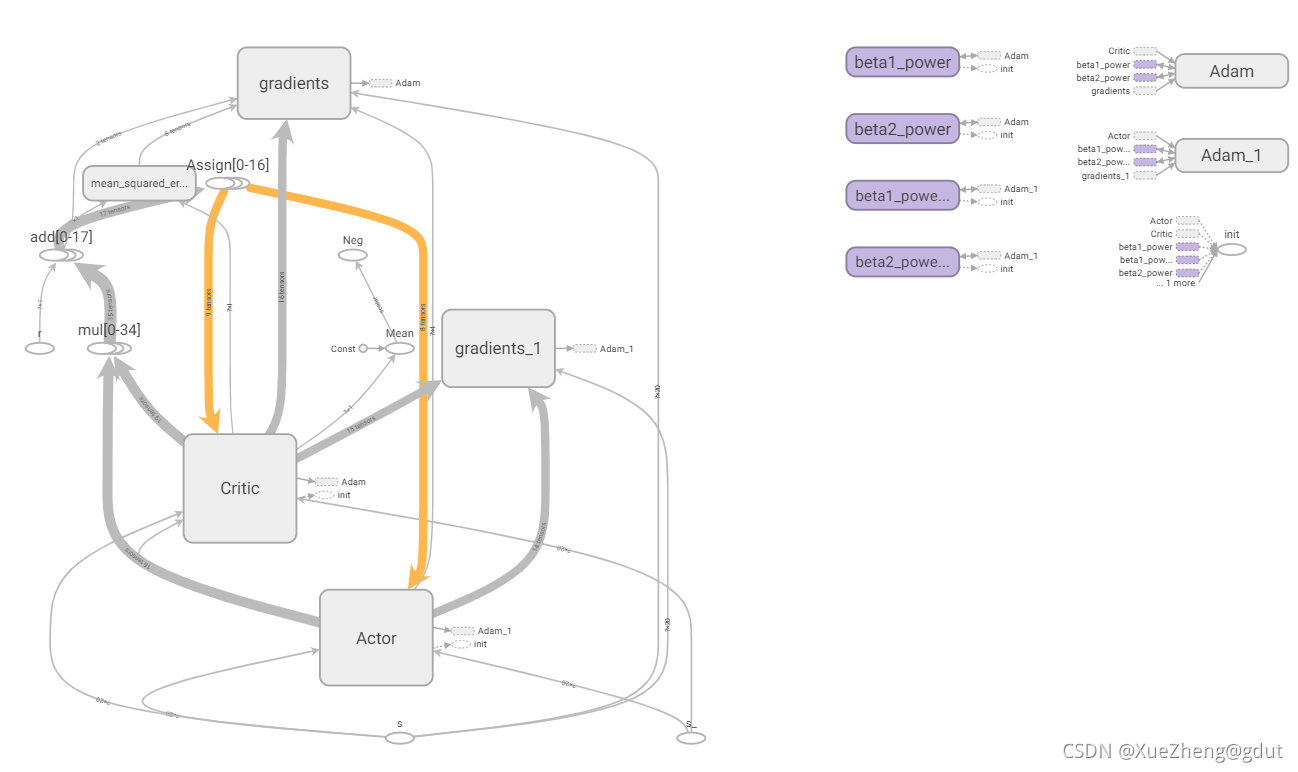
contribuer
Compte tenu de l'état du canal variable dans le temps dans le système MEC assisté par UAV à créneaux temporels, optimiser conjointement la planification des utilisateurs, le mouvement des UAV et l'allocation des ressources, formuler le problème de déchargement informatique non convexe comme un problème de processus de décision de Markov (MDP), et minimiser le temporisation initiale.
Compte tenu du modèle MDP, la complexité de l'état du système est très élevée et la prise de décision du déchargement informatique doit prendre en charge un espace d'action continu. L'algorithme DDPG est utilisé pour résoudre ce problème, le réseau Actor est utilisé pour effectuer des actions et le réseau Critic est utilisé pour approximer la fonction de valeur d'action Q pour marquer les actions et la meilleure stratégie optimale.
Cadre DDPG

Code détaillé
Définissez la classe DDPG, initialisez-la et la session est une instruction permettant à Tensorflow de contrôler et d'exécuter le fichier de sortie. Exécutez session.run() pour obtenir le résultat du calcul que vous souhaitez connaître ou la partie que vous souhaitez calculer. Vous utilisez session.run later () pour initialiser la variable. placeholder est un espace réservé dans Tensorflow. Il stocke temporairement des variables. Il peut être compris comme une coquille vide et la valeur est transmise pour le calcul. Si elle n'est pas transmise, la coquille vide n'effectue aucun calcul.
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
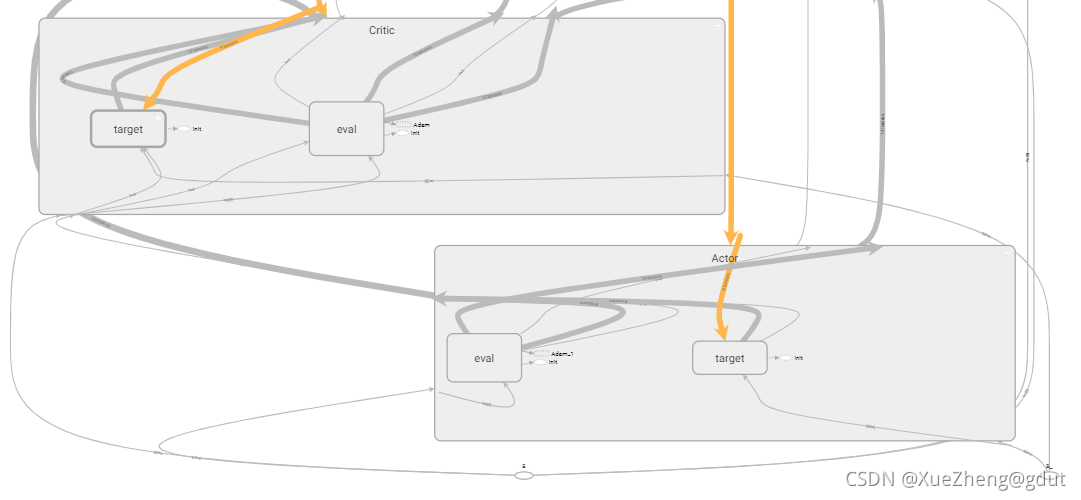
tf.variable_scope Compréhension personnelle, principalement pour le partage de variables, différents noms peuvent partager la même variable, DDPG a un total de quatre réseaux de neurones, la structure des deux réseaux de neurones dans Actor est la même, et les deux réseaux de neurones dans Critic La structure du réseau de neurones est la même, mais les paramètres sont différents. Après avoir écrit la structure d'un réseau de neurones, ces variables peuvent être partagées en les nommant différemment. Comme on peut le voir dans le code suivant, Actor a deux réseaux, l'un est l'évaluation du réseau principal et l'autre est la cible du réseau cible, le réseau d'évaluation produit directement l'action a et le réseau cible produit l'action a_, les deux étant construits à l'aide de la fonction _build_a, et sont nommés différemment Implémenter le partage de variables. Il en va de même pour le réseau Critic, qui sont respectivement les réseaux eval et cible, et la sortie est de deux valeurs Q, q, q_. À partir du tensorboard, vous pouvez voir qu'il existe deux réseaux sous l'acteur et le critique. Regardons de plus près comment construire un réseau d'acteurs et un réseau de critiques. trainable=True ou False est principalement utilisé pour spécifier s'il faut ajouter les variables du réseau de neurones à l'atlas du tensorboard.
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
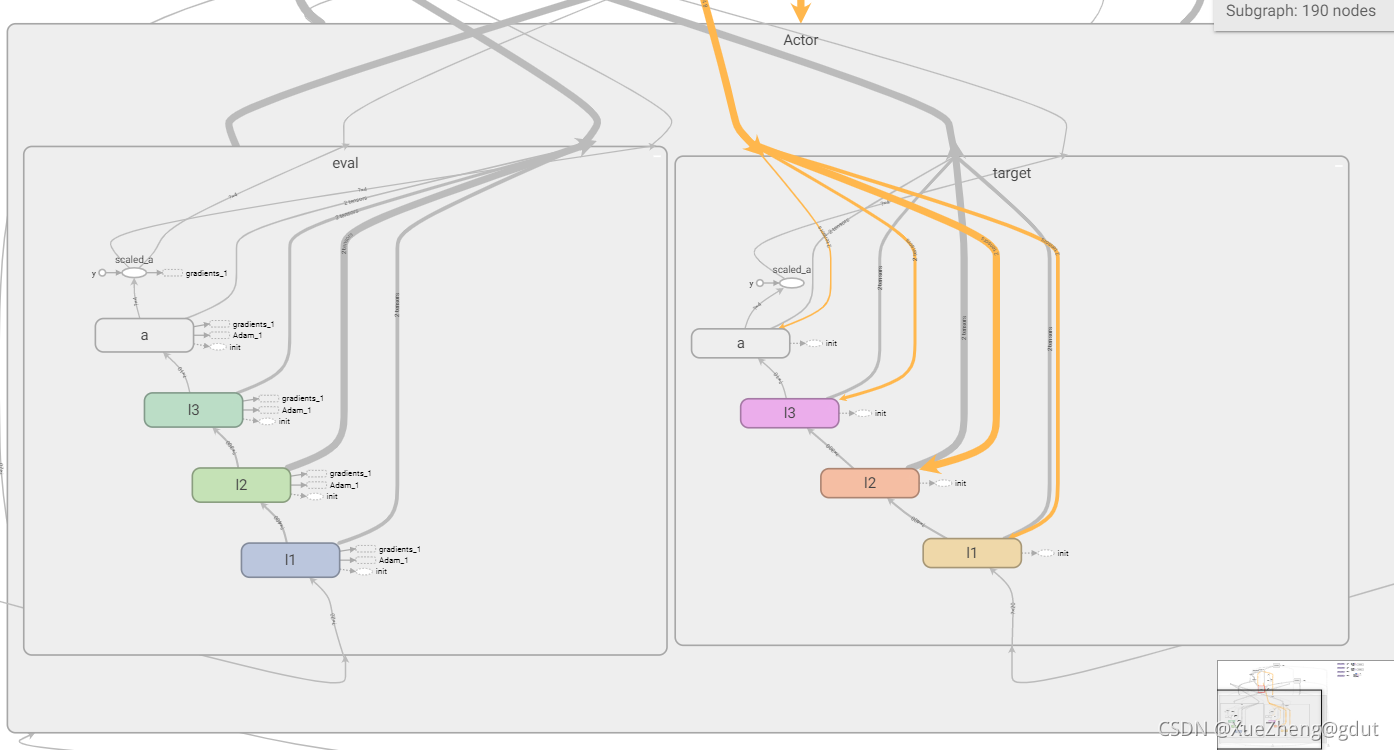
Acteur
Une fois que le réseau d'acteurs a principalement saisi l'état s, il produit directement l'action a. tf.layers.dense( input, units=k ) générera automatiquement un noyau de matrice de pondération et compensera le biais de l'élément en interne. Les dimensions spécifiques de chaque variable sont les suivantes : pour une entrée de tenseur bidimensionnelle d'une taille de [m, n ], tf.layers.dense() générera : un noyau de matrice de poids de taille [n, k] et un décalage d'élément de taille [m, k]. Le processus de calcul interne est y = entrée * noyau + biais, et la dimension de la valeur de sortie y est [m, k].
En utilisant la fonction de couche entièrement connectée encapsulée par tensorflow, l'état d'entrée, la première couche de neurones 400 (nommée l1), la deuxième couche 300 (nommée l2), la troisième couche 10 (nommée l3), la couche de sortie 4 (a_dim= 4 nommé a ). Deux réseaux avec la même structure de l'acteur sont construits, et le tensorboard est montré sur la figure.
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
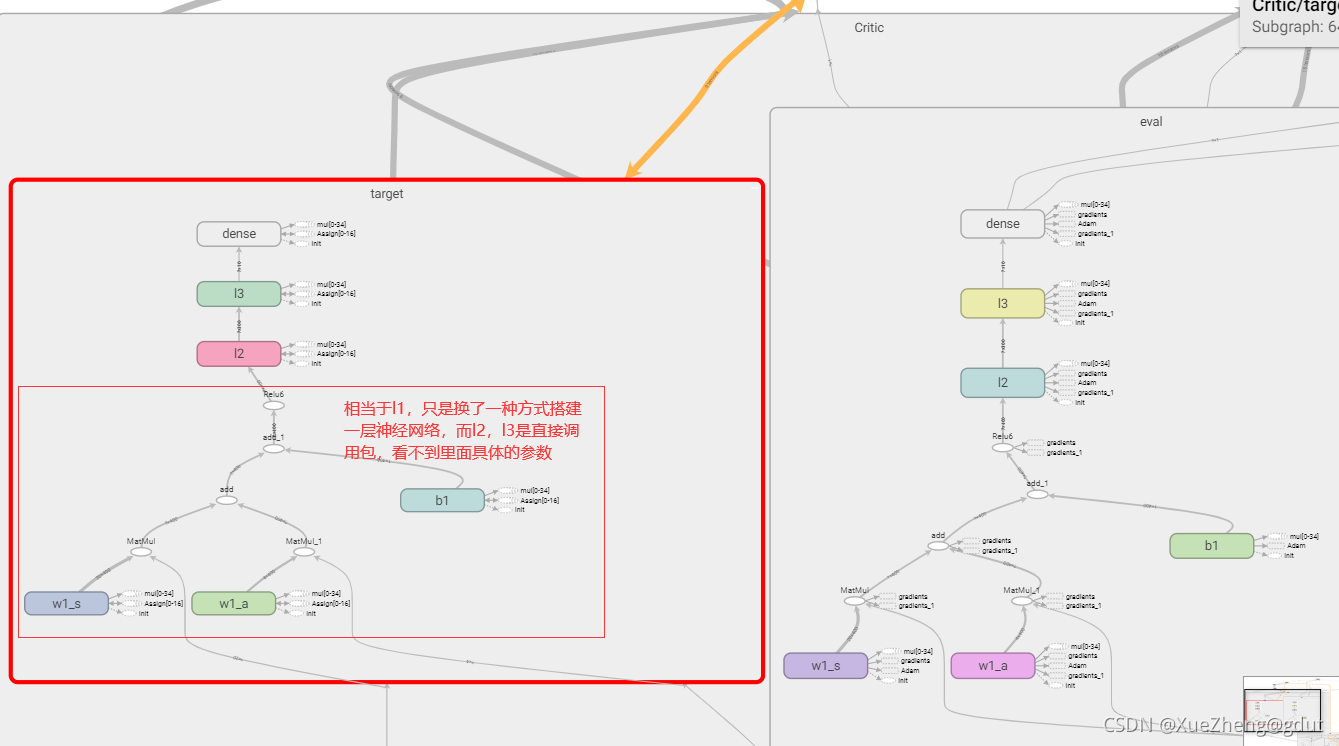
Critique
Voici le réseau Critic, qui note l'action a et génère la valeur Q. Ceci est un peu différent de la méthode ci-dessus de construction d'un réseau de neurones, car la fonction Q doit entrer l'état s et l'action a, donc s correspond à un poids, a correspond à un poids et il y a un biais dans son ensemble, puis passer par une fonction d'activation équivaut à une couche de réseau de neurones, w1_s, w1_a et b1 sont les paramètres du réseau de neurones, qui doivent être enregistrés et mis à jour, ils sont donc définis sur formable, de sorte que l'entrée à la première couche de neurones est de 400 et la deuxième couche est de 300 (nommée l2 ), la troisième couche est de 10 (nommée l3) et la sortie est le score de l'action, scalaire. Le principe du réseau de neurones, à travers la fonction d'activation (fonction non linéaire) après sommation linéaire. Les deux réseaux de Critic avec la même structure sont construits, et le tensorboard est montré dans la figure.
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
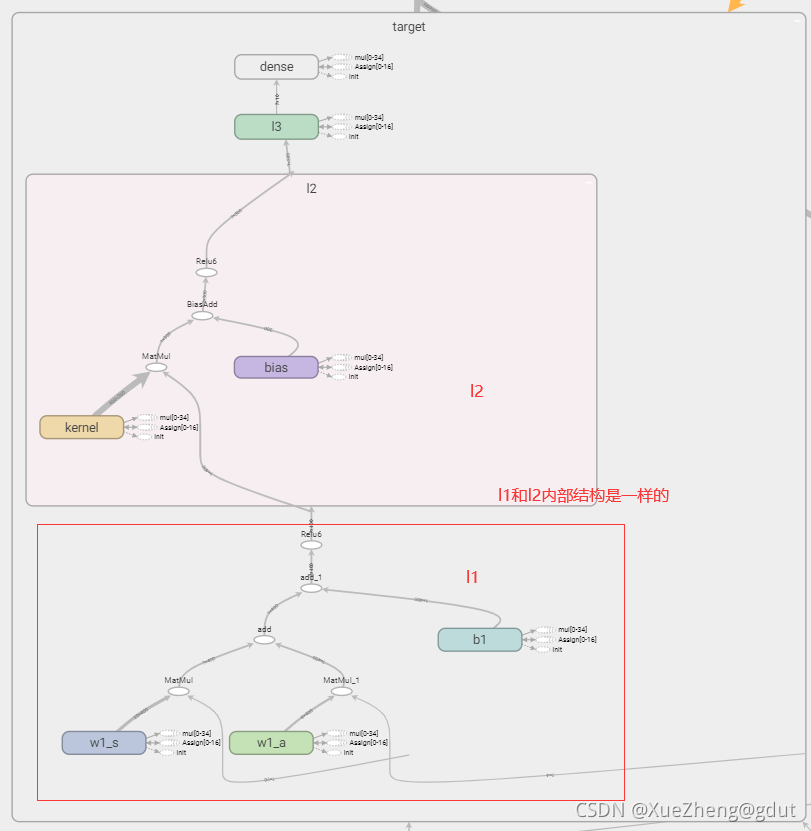

Jusqu'à présent, les quatre structures de réseau de neurones ont été construites.
Les paramètres importants du réseau de neurones sont le poids et le biais de chaque couche. Nous n'avons pas construit le réseau de neurones de manière très primitive, mais directement appelé tf.layers.dense pour le construire. Les paramètres spécifiques de chaque couche ne sont pas clairs , mais tensorflow fournit un très Le pratique tf.get_collection extrait toutes les variables d'une collection. C'est une liste. Il y a quatre réseaux au total. De cette façon, tous les paramètres des quatre réseaux peuvent être extraits pour la mise à jour.
# networks parameters
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
Piscine de relecture de l'expérience
Étant donné que l'entrée du réseau de neurones n'est souvent pas entrée une par une, mais sous la forme de petits lots, il est nécessaire de collecter une certaine quantité d'expérience et de la mettre dans le pool de lecture d'expérience.Chaque petit lot est retiré pour former le neurone réseau et l'entraînement atteint un certain nombre de fois. Arrêtez l'entraînement. Appelez s, a, r, s_ une expérience et stockez-la dans le pool d'expériences jusqu'à ce que la capacité maximale soit atteinte.
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
Mise à jour des paramètres du réseau neuronal
Les deux principaux réseaux Actor_eval et Critic_eval dans Actor et Critic sont mis à jour via TError et policy gradient respectivement.

Calculez TError pour mettre à jour les paramètres réseau de Critic_eval, et les paramètres réseau de Actor_eval sont dérivés des paramètres actor_eval via la fonction Q. Ici, Q dérive en fait a puis dérive mu. {\theta^Q}
est le ce_params ici, et {\theta^\mu} est le ae_params. q_cible correspond à y_i.
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
Il y a un total de quatre réseaux neuronaux. Les paramètres du réseau principal sont mis à jour à partir de ce qui précède, et les deux réseaux cibles doivent également être mis à jour. La méthode de mise à jour douce (moyenne glissante) est adoptée, et chaque mise à jour est un peu bit. Pourquoi utiliser deux réseaux de neurones respectivement dans Actor et Critic ? Un réseau de neurones sert principalement à éviter le problème de la surestimation, de sorte que les paramètres doivent être définis différemment. La méthode de mise à jour matérielle consiste à retarder les paramètres du réseau principal et à les copier au réseau cible, tandis que la mise à jour logicielle équivaut à mettre à jour un peu à chaque fois. Sa formule et le code correspondant sont les suivants.
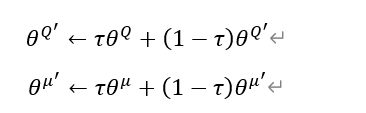
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
La formule ici peut mettre à jour les paramètres des deux réseaux cibles à la fois ? Pourquoi voici self.at_params + self.ct_params voici + ? Pour être honnête, je ne le comprends pas très bien, de sorte que at_params et ct_params puissent être mis à jour ? Quelqu'un qui sait peut expliquer en détail? Mais après avoir cherché cela, il semble que ce soit la bonne façon d'écrire. C'est aussi un code ennuyeux à utiliser directement.
économiser de l'expérience
À ce stade, l'ensemble du cadre de DDPG est essentiellement construit, et le reste consiste à stocker des données dans le pool d'expérience. Une fois le stockage plein, vous pouvez commencer à former le réseau de neurones construit. Accéder à l'expérience (s, a, r, s_), sélectionner au hasard un état s, à ce moment besoin de produire une action via le réseau de neurones, de sorte que la fonction choose_action est définie, ici le réseau de neurones est appelé pour produire l'action a, cette action est souvent représentée par le bruit Explore, puis l'environnement récompense r en fonction de l'action a et met à jour l'état suivant s_, de sorte qu'une expérience est obtenue. Lors de l'enregistrement, il jugera si le stockage est plein ou s'il a certaines exigences pour les actions de sortie, etc., voir le code ci-dessous. À ce stade, le réseau de neurones ne peut pas être formé.
def choose_action(self, s):
temp = self.sess.run(self.a, {
self.S: s[np.newaxis, :]})
return temp[0]
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
former
Après avoir jugé que le pool d'expériences est plein, commencez à entraîner le réseau de neurones et mettez à jour les paramètres. Ici, vous pouvez appeler directement la fonction d'apprentissage pour démarrer le processus d'entraînement et mettre à jour les paramètres.
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
Après avoir créé le graphique de flux, utilisez sess.run pour exécuter, effectuez d'abord une mise à jour logicielle (mise à jour des paramètres du réseau cible), retirez au hasard l'expérience BATCH_SIZE du pool d'expériences et utilisez sess.run pour mettre à jour les principaux paramètres du réseau (atrain, ctrain) .
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {
self.S: bs})
self.sess.run(self.ctrain, {
self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
Le code de la classe DDPG est expliqué ici, et le code de la classe DDPG est publié ici.
############################### DDPG ####################################
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound):
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) # memory里存放当前和下一个state,动作和奖励
self.pointer = 0
self.sess = tf.Session()
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.S = tf.placeholder(tf.float32, [None, s_dim], 's') # 输入
self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_')
self.R = tf.placeholder(tf.float32, [None, 1], 'r')
with tf.variable_scope('Actor'):
self.a = self._build_a(self.S, scope='eval', trainable=True)
a_ = self._build_a(self.S_, scope='target', trainable=False)
with tf.variable_scope('Critic'):
# assign self.a = a in memory when calculating q for td_error,
# otherwise the self.a is from Actor when updating Actor
q = self._build_c(self.S, self.a, scope='eval', trainable=True)
q_ = self._build_c(self.S_, a_, scope='target', trainable=False)
self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval')
self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target')
self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval')
self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target')
# target net replacement
self.soft_replace = [tf.assign(t, (1 - TAU) * t + TAU * e)
for t, e in zip(self.at_params + self.ct_params, self.ae_params + self.ce_params)]
q_target = self.R + GAMMA * q_
# in the feed_dic for the td_error, the self.a should change to actions in memory
td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q)
self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params)
a_loss = - tf.reduce_mean(q) # maximize the q
self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params)
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
def choose_action(self, s):
temp = self.sess.run(self.a, {
self.S: s[np.newaxis, :]})
return temp[0]
def learn(self):
self.sess.run(self.soft_replace)
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = bt[:, :self.s_dim]
ba = bt[:, self.s_dim: self.s_dim + self.a_dim]
br = bt[:, -self.s_dim - 1: -self.s_dim]
bs_ = bt[:, -self.s_dim:]
self.sess.run(self.atrain, {
self.S: bs})
self.sess.run(self.ctrain, {
self.S: bs, self.a: ba, self.R: br, self.S_: bs_})
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
# transition = np.hstack((s, [a], [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
def _build_a(self, s, scope, trainable):
with tf.variable_scope(scope):
net = tf.layers.dense(s, 400, activation=tf.nn.relu6, name='l1', trainable=trainable)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable)
return tf.multiply(a, self.a_bound[1], name='scaled_a')
def _build_c(self, s, a, scope, trainable):
with tf.variable_scope(scope):
n_l1 = 400
w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable)
w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable)
b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable)
net = tf.nn.relu6(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1)
net = tf.layers.dense(net, 300, activation=tf.nn.relu6, name='l2', trainable=trainable)
net = tf.layers.dense(net, 10, activation=tf.nn.relu, name='l3', trainable=trainable)
return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a)
À l'exception des quelques phrases suivantes, initialisez toutes les variables et affichez le graphe tensorboard.
self.sess.run(tf.global_variables_initializer())
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", self.sess.graph)
Code de formation :
############################### training ####################################
np.random.seed(1)
tf.set_random_seed(1)
env = UAVEnv()
MAX_EP_STEPS = env.slot_num
s_dim = env.state_dim
a_dim = env.action_dim
a_bound = env.action_bound # [-1,1]
ddpg = DDPG(a_dim, s_dim, a_bound)
# var = 1 # control exploration
var = 0.01 # control exploration
t1 = time.time()
ep_reward_list = []
s_normal = StateNormalization()
for i in range(MAX_EPISODES):
s = env.reset()
ep_reward = 0
j = 0
while j < MAX_EP_STEPS:
# Add exploration noise
a = ddpg.choose_action(s_normal.state_normal(s))
a = np.clip(np.random.normal(a, var), *a_bound) # 高斯噪声add randomness to action selection for exploration
s_, r, is_terminal, step_redo, offloading_ratio_change, reset_dist = env.step(a)
if step_redo:
continue
if reset_dist:
a[2] = -1
if offloading_ratio_change:
a[3] = -1
ddpg.store_transition(s_normal.state_normal(s), a, r, s_normal.state_normal(s_)) # 训练奖励缩小10倍
if ddpg.pointer > MEMORY_CAPACITY:
# var = max([var * 0.9997, VAR_MIN]) # decay the action randomness
ddpg.learn()
s = s_
ep_reward += r
if j == MAX_EP_STEPS - 1 or is_terminal:
print('Episode:', i, ' Steps: %2d' % j, ' Reward: %7.2f' % ep_reward, 'Explore: %.3f' % var)
ep_reward_list = np.append(ep_reward_list, ep_reward)
# file_name = 'output_ddpg_' + str(self.bandwidth_nums) + 'MHz.txt'
file_name = 'output.txt'
with open(file_name, 'a') as file_obj:
file_obj.write("\n======== This episode is done ========") # 本episode结束
break
j = j + 1
# # Evaluate episode
# if (i + 1) % 50 == 0:
# eval_policy(ddpg, env)
print('Running time: ', time.time() - t1)
plt.plot(ep_reward_list)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()