Informations papier
nombre d'en-têtes : auto, premier niveau 2, max 4, _.1.1
name_en : parler, lire et demander : synthèse vocale haute fidélité avec supervision minimale
name_ch : parler, lire et demander : une petite quantité de supervision à réaliser texte haute fidélité vers Voice
paper_addr : http://arxiv.org/abs/2302.03540
date_read : 2023-04-25
date_publish : 2023-02-07
tags : ['Deep Learning','TTS']
auteur : Eugene Kharitonov, Code de recherche Google
: https://google-research.github.io/seanet/speartts/examples/
1 Commentaires
Il s'agit d'un système TTS complet, qui peut être considéré comme une extension d'AudioLM.
2 Résumé
Un système de synthèse vocale multilingue, utilisant une grande quantité de données non supervisées et une petite quantité de données supervisées, combine deux types de représentations vocales discrètes, découplant : générer des balises sémantiques (lecture) à partir de texte, et régénérer des balises sonores à partir de balises sémantiques (Speaking ) deux parties, utilisant une grande quantité de données audio pures pour former le "module de parole", réduisant la demande de données parallèles du "module de lecture" (les données parallèles font référence à : des paires de données texte-parole).
Pour le contrôle du locuteur, en utilisant une méthode de repérage, seulement 3 secondes d'audio sont nécessaires pour synthétiser le discours d'un locuteur non vu dans l'ensemble d'apprentissage.
Les expériences montrent que SPEAR-TTS est comparable aux méthodes de pointe en termes de taux d'erreur de caractère en utilisant seulement 15 minutes de données parallèles, et des tests subjectifs démontrent qu'il est comparable à la parole réelle en termes de naturel et de qualité acoustique.
3 représentations discrètes de la parole
Voir AudioLM pour plus de détails
3.1 Jeton sémantique
Le rôle du balisage sémantique est de fournir une condition approximative de haut niveau pour générer le balisage acoustique ultérieur. Par conséquent, une représentation doit être fournie où le contenu linguistique (de la phonétique à la sémantique) est saillant tout en ignorant les informations paralinguistiques telles que l'identité du locuteur et les détails acoustiques.
Pour obtenir une telle représentation, un modèle de représentation de la parole auto-supervisé basé sur w2v-BERT est formé. Le modèle combine la modélisation du langage de masque et l'apprentissage contrastif pour obtenir des représentations de la parole. Après l'entraînement, exécutez le clustering k-means sur la sortie normalisée moyenne-variance d'une couche particulière . Utilisez des indices centroïdes comme marqueurs discrets .
3.2 Jeton acoustique
Les marqueurs acoustiques sont des représentations audio discrètes qui fournissent des reconstructions haute fidélité des détails acoustiques. Un codec neuronal SoundStream est formé pour reconstruire la parole tout en la comprimant en un certain nombre d'unités discrètes . SoundStream y parvient en ajoutant un quantificateur résiduel dans le goulot d'étranglement de l'auto-encodeur convolutif .
4 Présentation de SPEAR-TTS
SPEAR-TTS étend AudioLM en prenant le texte comme condition de génération . Comme le montre la figure 1, il est principalement divisé en deux scénarios : S1 convertit le texte en balises sémantiques discrètes et S2 convertit les balises sémantiques en balises acoustiques, puis les convertit en audio à l'aide de SoundStream .
Une conversion en deux étapes est nécessaire car : les informations sémantiques se situent logiquement entre le texte et les informations acoustiques ; et la transacoustique sémantique ne nécessite qu'un apprentissage des données audio non étiquetées . De plus, un troisième scénario similaire à AudioLM peut être ajouté pour améliorer la qualité de la parole synthétisée en prédisant la signature acoustique correspondant au niveau de quantification vectorielle résiduel fin.
5 S1 : Améliorer l'efficacité de la supervision
En apprenant supervisé le mappage du texte aux balises sémantiques, en utilisant l'ensemble de données de synthèse vocale pour extraire les balises sémantiques, le S1 est transformé en une tâche seq2seq séquence à séquence, en utilisant spécifiquement la structure Transformer.

L'apprentissage supervisé nécessite une grande quantité de données étiquetées, ce qui est difficile pour les petits langages Deux stratégies d'amélioration sont utilisées dans cet article :
5.1 Pré-formation
Pré-former le transformateur de l'encodeur-décodeur sur une tâche de pré-formation de débruitage. Le modèle reçoit une version corrompue de la séquence de jetons sémantiques d'origine , et l'objectif est de produire la séquence de jetons non corrompue correspondante.
Les méthodes de corruption typiques incluent le remplacement aléatoire, la suppression et l'occultation de jetons individuels ou de plages de jetons entières. Les méthodes qui suppriment indépendamment des jetons individuels avec une probabilité constante sont observées dans des études préliminaires comme étant plus efficaces que d'autres alternatives.
Une fois que le modèle est pré-formé sur la tâche de débruitage, il est affiné sur la tâche S1. Gelez les couches supérieures de l'encodeur et les paramètres du décodeur lors du réglage fin.
5.2 Contre-traduction : contre-traduction
La même séquence de texte peut correspondre à plusieurs types d'audio, tels que des voix, des accents, une prosodie, un contenu émotionnel et des conditions d'enregistrement différents. Cela rend le texte et l'audio très asymétriques. L'approche de rétrotraduction consiste à entraîner un modèle de synthèse vocale à l'aide de la paire de données parallèles disponible, et à l'utiliser, ainsi que le corpus de l'audio uniquement, pour générer des données parallèles , en augmentant les données d'entraînement du modèle.

Regardez la figure 2 en bas à gauche. Tout d'abord, utilisez la méthode d'endommagement limité des données (bruit puis débruitage) pour pré-entraîner le modèle P afin de générer des jetons sémantiques pour représenter les données audio ; puis entraînez le module de rétro-traduction et utilisez un petite quantité de données parallèles pour affiner le décodeur, former le modèle B ; utiliser la méthode de rétrotraduction du modèle B et une grande quantité de données non étiquetées pour générer une grande quantité de données parallèles pouvant être utilisées pour la formation (en haut à droite) ; enfin utiliser toutes les données parallèles pour affiner le modèle (en bas à droite) et affiner uniquement les couches inférieures de l'encodeur.
6 S2 : Contrôler le processus de génération
Le deuxième scénario consiste à mapper des balises sémantiques sur des balises acoustiques. Ici, les balises acoustiques sémantiques peuvent être extraites de phrases dans des ensembles de données uniquement audio , puis le modèle Transformer peut être formé pour implémenter la fonction de traduction de seq2seq. La deuxième étape génère des énoncés avec des variations aléatoires dans la parole, le tempo et les conditions d'enregistrement , reproduisant la distribution des caractéristiques observée dans les données d'apprentissage.
Étant donné que la formation de S1 et S2 est découplée , S2 préserve la diversité de la parole générée tandis que S1 est formé sur un ensemble de données à locuteur unique .
Afin de contrôler les caractéristiques de la voix du locuteur, les deux cas avec et sans invites audio sont pris en compte lors de la formation . Comme le montre la figure 3 :
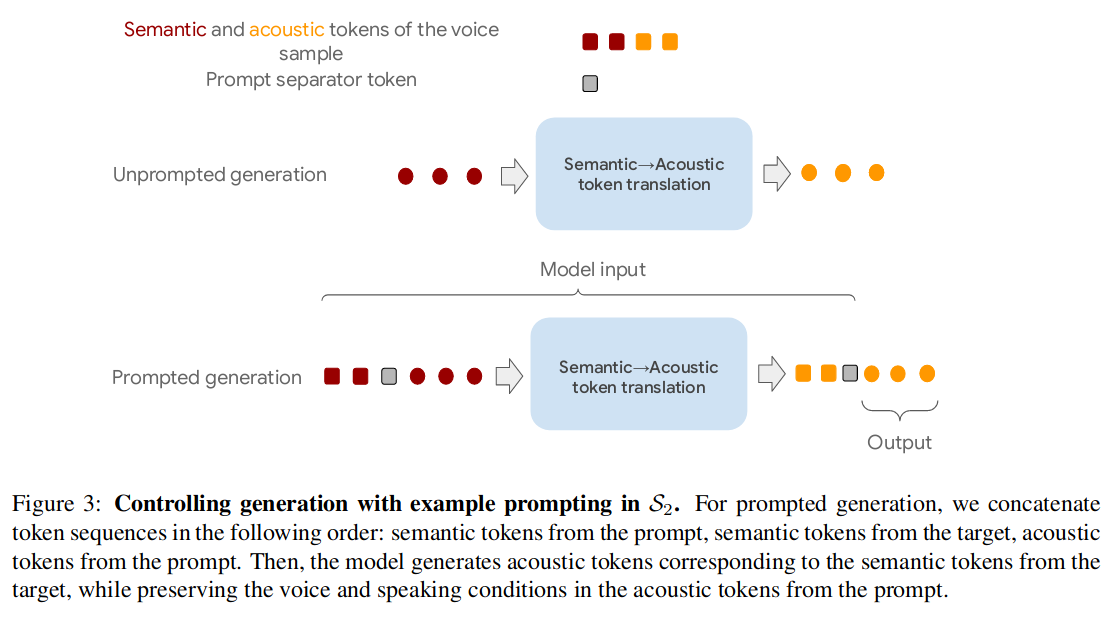
Les blocs rouges sont ici des jetons sémantiques, les blocs jaunes sont des jetons acoustiques et les blocs gris sont des séparateurs d'invite. Dans le scénario de génération de parole à partir de signaux audio (ci-dessous), les séquences concaténées suivantes sont formées : jetons sémantiques à partir de signaux, jetons sémantiques à partir de cibles et jetons acoustiques à partir de signaux. Le modèle génère des jetons acoustiques (Sortie) correspondant aux jetons sémantiques de la cible, tout en préservant la parole et les conditions de parole dans les jetons acoustiques des repères.
Au moment de l'apprentissage, deux fenêtres vocales qui ne se chevauchent pas sont sélectionnées au hasard dans chaque ensemble d'apprentissage, à partir desquelles des séquences d'étiquettes sémantiques et acoustiques sont calculées. Considérez l'une des fenêtres comme une invite et l'autre comme une sortie cible .
Lors de l'inférence, l'entrée est également constituée des trois premiers blocs et la sortie est générée à l'aide de la méthode autorégressive.