
Galaxy Zoo (Galaxy Zoo) est un projet scientifique bénévole organisé par des institutions de recherche telles que l'Université d'Oxford et invitant le public à participer, dans le but de cataloguer plus d'un million d'images de galaxies. Il s'agit d'une enquête publique à grande échelle sur le ciel étoilé en astronomie. L'enthousiasme du public est grand. Avec la participation active de près de 100 000 bénévoles, la première phase du projet de zoo galactique a été achevée en seulement 175 jours : 950 000 Les galaxies ont été classées, et chaque galaxie a été classée 38 fois en moyenne.
Selon les résultats de recherche du Galaxy Zoo, les images de galaxies peuvent être divisées en quatre catégories : les galaxies circulaires, les galaxies intermédiaires, les galaxies latérales et les galaxies spirales. La figure 1 montre des images de 4 classes de galaxies sélectionnées au hasard. La première rangée est une galaxie circulaire, c'est-à-dire que la forme de la galaxie est un cercle aux bords lisses. La deuxième rangée est la galaxie intermédiaire, c'est-à-dire que la forme de la galaxie est une ellipse. La raison pour laquelle on l'appelle une galaxie intermédiaire signifie que sa forme se situe entre la galaxie circulaire de la première rangée et la galaxie latérale de la troisième rangée. . La galaxie latérale montrée dans la rangée 3 est une galaxie à disque latérale avec un renflement central. La quatrième rangée est une galaxie spirale. Comme son nom l'indique, ce type de galaxie est en forme de spirale, avec un renflement nucléaire au milieu et des bras spiraux autour d'elle. La Voie lactée est une galaxie spirale typique.

■ Figure 1 Exemple d'image d'une galaxie
Parce que l'ensemble de données d'origine du zoo de la galaxie est relativement important, ce chapitre n'utilise qu'une partie des données : 500 images sont sélectionnées dans chacun des quatre types d'échantillons de galaxies, donc l'échantillon de données dans ce chapitre est de 4 × 500 = 2000 images . Chaque image est une image RVB avec une étiquette de classification et la taille de l'image est de 424 × 424 × 3 pixels. Les étiquettes de classe sont 0, 1, 2, 3, représentant respectivement les galaxies circulaires, intermédiaires, latérales et spirales.
La tâche de ce cas est d'utiliser le réseau neuronal convolutif pour classer 2000 images de galaxies et d'évaluer l'effet de classification du modèle de réseau.
01. Réalisation de cas
Cette section utilise le modèle ResNet50 de la bibliothèque Keras pour implémenter le cas ci-dessus, c'est-à-dire utiliser le modèle ResNet50 pour classer les images de galaxies. Le processus de mise en œuvre est le suivant.
1. Description du jeu de données
Dans ce cas, l'ensemble de données est stocké dans le dossier image_anli. Il existe quatre types de galaxies : les galaxies circulaires, les galaxies intermédiaires, les galaxies latérales et les galaxies spirales. Chaque type de galaxie a 500 images et la taille de l'image est de 424 x 424. ×3 . Selon la catégorie des images de galaxies, les images de galaxies sont placées dans 4 dossiers et les étiquettes de catégorie sont 0, 1, 2 et 3, qui représentent respectivement les galaxies circulaires, les galaxies intermédiaires, les galaxies latérales et les galaxies spirales. Le nom du dossier est l'étiquette de catégorie pour cette galaxie. Le diagramme de structure de répertoire où se trouve l'ensemble de données est illustré à la figure 2.
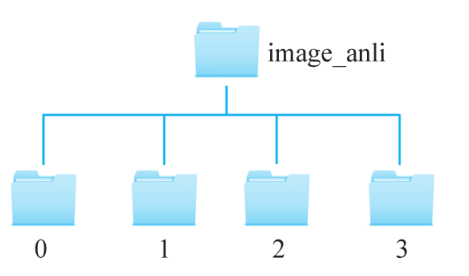
■ Figure 2 Diagramme de structure de répertoire où se trouve l'ensemble de données
2. Division du jeu de données
Avant d'entraîner et de tester les images de galaxies, il faut d'abord diviser le jeu de données : diviser 2000 images de galaxies en un ensemble d'apprentissage (train), un ensemble de vérification (validation) et un ensemble de test (test) selon le rapport de 7 : 2:1, respectivement pour la formation, la validation et les tests du modèle. L'idée de réalisation est la suivante : divisez d'abord le dossier image_anli en un dossier temporaire et un dossier de test selon le ratio de 9:1, et le dossier de test est un jeu de test, qui stocke 4 sous-dossiers, dont un total de 4 × 50 = 200 images de galaxie ; Il y a 4 sous-dossiers stockés dans le dossier temporaire, y compris un total de 4 × 450 = 1800 images de galaxie, puis le dossier temporaire est divisé en un ensemble d'apprentissage et un ensemble de vérification selon un ratio de 7:2.
Créez un nouveau programme .py nommé split_dataset.py, qui est utilisé pour terminer la tâche de division de l'ensemble de données. Le processus de mise en œuvre spécifique est le suivant.
(1) Bibliothèque d'importation. Importez la bibliothèque os et la bibliothèque shutdown pour effectuer des opérations connexes sur des dossiers et des fichiers, et la bibliothèque aléatoire réalise une division aléatoire des données. code affiché comme ci-dessous.
import os
import random
import shutil(2) Définissez la fonction split() pour diviser l'ensemble de données d'origine en deux ensembles de données selon le rapport spécifié, et copiez l'image dans le dossier correspondant. code affiché comme ci-dessous.
def split(initial path, save dir, split rate):
'''
划分数据集
:param initial path:字符串类型,未划分数据之前的文件路径
:param save dir:列表类型,划分数据之后的文件路径
:param split rate:浮点数,划分比例
'''
# 获取数据集数量及类别
file number list=os.listdir(initial path)
total num classes=len(file number list)
#置入随机种子,使每次划分的数据集相同
random.seed(1)
for i in range(total num classes):
class name=file number list [i]
image dir=os.path.join(initial path,class name)
# 调用函数将图像从一个文件夹复制到另一个文件夹
file copy(image dir,save list dir,class name, split rate)
print(' s 已成功划分 class name)Parmi eux, la fonction de la fonction file_copy() copie l'image de file_dir vers save_dir en proportion. code affiché comme ci-dessous.
def file copy(file dir, save dir,class name,split rate):
'''
将图像从源文件夹复制到目标文件夹
:param file dir:字符串类型,未划分数据之前的文件路径
:param save dir:列表类型,划分数据之后的文件路径
:param class name:字符串类型,星系类别的名称
:param split rate:浮点数,划分比例
'''
image list=os.listdir(file dir) #获取图片的原始路径
image number=len(image list)
train number=int(image number * split rate)
#从 image list 中随机选取图像
train_sample=random.sample(image_list,train_number)
test_sample=list(set(image_list) - set(train_sample))
data_sample=[train_sample,test_sample]
# 复制图像到目标文件夹
for i in range(len(save dir)) :
if os.path.isdir(save dir i + class name) :
for data in data sample [i] :
shutil.copy(os.path.join(file dir,data),os.path.join(save)
dir [i] + class_name+'/',data))
else:
os.makedirs(save dir[i] + class_name)
for data in data sample [i] :
shutil.copy(os.path.join(file_dir,data), os.path.join(save)
dir [i] + class_name+'/', data))(3) Fonction principale. Dans la fonction principale, la fonction split() est appelée pour la première fois, et l'ensemble de données d'origine est divisé en dossier temporaire et dossier de test selon le rapport de 9:1, et la fonction split() est appelée pour la seconde temps, et le dossier temporaire est divisé en 7:2 Le rapport est divisé en ensemble de formation et ensemble de validation. code affiché comme ci-dessous.
if_name_== ' _main_'
# 原始数据集路径
initial path=r'./image anli'
#保存路径
save_list dir=[r'./temp/',r'./test/]
# 原始数据集按 9:1被划分为 temp 文件夹和 test 文件夹
split rate=0.9
split(initial path, save list dir, split rate)
# 继续将 temp 划分成训练集和验证集
initial path=r'./temp
#保存路径
save list dir=[r'./train/',r'./val/!]
# temp 数据集按 7:2 被划分成训练集和验证集
split rate=7/9
split(initial path,save list dir,split rate)
3. Classer les images à l'aide du modèle ResNet50
Après avoir divisé l'ensemble de données, créez un programme classify_resnet50.py pour réaliser des fonctions telles que la lecture et le traitement d'images, la formation et l'évaluation de modèles. Le processus de mise en œuvre spécifique est le suivant.
(1) Bibliothèque d'importation. Importez le modèle ResNet50 emballé de Keras, classez l'image et importez les méthodes associées du module sklearn.metrics pour évaluer la précision de la classification, le taux de rappel, le taux de précision et la mesure F1 du modèle. code affiché comme ci-dessous.
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
from sklearn.metrics import accuracy score
from sklearn.metrics import precision score
from sklearn.metricsimport recall score
from sklearn.metrics import f score(2) Lire l'image du jeu de données. Lisez les images de l'ensemble d'apprentissage, de l'ensemble de vérification et de l'ensemble de test à partir du local, et placez-les respectivement dans les objets train, val et test. code affiché comme ci-dessous.
# 从训练集、验证集和测试集所在文件夹里读取图像
train dir=r'. train'
test dir=r'. test!
val dir=r'. val
height=224width=224
# resnet 50 的处理的图像大小
# resnet 50 的处理的图像大小
batch size=24
train=tf.keras.preprocessing.image dataset from directory(
train dir
seed=123
image size=(height, width),
batch size=batch size)
test=tf.keras.preprocessing.image dataset from directory(test dir,
shuffle=False
image size=(height,width)batch size=batch size)
val=tf.keras.preprocessing.image dataset from directory(val dir,
seed=123
image size=(height, width)
batch size=batch size)Lors de la lecture des images de jeu de test, définissez la valeur du paramètre shuffle sur False. Le but de ceci n'est pas de perturber l'ordre des images de jeu de test de lecture, ce qui est pratique pour l'évaluation ultérieure de l'effet de classification du modèle.
(3) Amélioration de l'image. Les grands ensembles de données sont une condition préalable au succès des réseaux de neurones profonds. Si l'ensemble de données d'apprentissage est petit, l'augmentation d'image peut être utilisée pour augmenter la diversité de l'ensemble d'apprentissage. L'amélioration de l'image consiste à générer des échantillons d'apprentissage similaires mais différents après une série de modifications aléatoires des images d'apprentissage. Les images utilisées par le réseau de neurones à chaque cycle d'apprentissage itératif ne sont pas exactement les mêmes pour améliorer la robustesse du modèle. De plus, la modification aléatoire des échantillons d'apprentissage peut réduire la dépendance du modèle à certaines propriétés, améliorant ainsi la capacité de généralisation du modèle. Par exemple, zoomez ou déplacez l'image de manière aléatoire afin que l'objet cible apparaisse dans différentes positions, réduisant ainsi la dépendance du modèle à la position de l'objet. Dans ce cas, le nombre d'images de galaxies dans l'ensemble d'apprentissage est limité, utilisez donc la couche de prétraitement de tensorflow.keras pour effectuer les opérations d'amélioration d'image suivantes sur l'ensemble d'apprentissage.
① Retournement aléatoire tf.keras.layers.experimental.preprocessing.RandomFlip (mode) : retourner de manière aléatoire l'image d'entrée. Généralement, mode="horizontal" signifie retourner horizontalement, et mode="vertical" signifie retourner de haut en bas.
② Rotation aléatoire tf.keras.layers.experimental.preprocessing.RandomRotation (facteur) : Faites pivoter de manière aléatoire l'image d'entrée en fonction de l'angle de rotation (facteur × 2π). Le paramètre factor peut être un tuple de 2 éléments, ou un seul nombre à virgule flottante : une valeur positive indique une rotation dans le sens antihoraire et une valeur négative indique une rotation dans le sens horaire. Par exemple, factor=(-0.2, 0.3) signifie que la plage de rotation est une quantité aléatoire dans [-20%×2π, 30%×2π]. facteur=0,1 signifie que la plage de rotation est une quantité aléatoire comprise entre [-10 % × 2π, 10 % × 2π]. En raison de l'invariance de rotation des images de galaxies, la catégorie des images de galaxies ne changera pas après la rotation, ce qui peut augmenter la quantité de données dans une certaine mesure.
③ Couches de mise à l'échelle aléatoires.experimental.preprocessing.RandomZoom(factor) : rétrécir ou agrandir de manière aléatoire l'image de la galaxie. Le paramètre factor représente le facteur d'échelle et la valeur peut être un tuple de 2 éléments ou un seul nombre à virgule flottante. factor=(0.2, 0.3) indique que la plage de réduction de sortie est [+20%, +30%] quantité aléatoire, factor=(-0.3, -0.2) indique que la plage d'amplification de sortie est [+20%, +30% ] quantité aléatoire.
④ Couches de hauteur aléatoires.experimental.preprocessing.RandomHeight (facteur) : modifier de manière aléatoire la hauteur de l'image. Le paramètre factor représente le rapport et sa valeur est similaire au paramètre factor de la mise à l'échelle aléatoire.
⑤ Layers.experimental.preprocessing.RandomWidth (facteur) de largeur aléatoire : déplacez l'image de manière aléatoire sur une certaine largeur.
⑥ Couches normalisées. expérimental. prétraitement. Redimensionnement (échelle) : normaliser les données. scale=1./255 indique que l'entrée dont la plage de valeur est [0, 255] est normalisée à la plage [0, 1].
Le code spécifique pour l'amélioration de l'image dans ce cas est le suivant.
# 图像增强,包括随机水平翻转,随机旋转,随机缩放
data augmentation=keras.Seguential(
[
layers.experimental.preprocessing.RandomFlip("horizontal",
input shape=(height, width,3)),
layers.experimental.preprocessing.RandomRotation(0.1),
layers.experimental.preprocessing.RandomZoom(0.1),
layers.experimental.preprocessing.Randomwidth(0.1),
layers.experimental.preprocessing.RandomHeight(0.1),
layers.experimental.preprocessing.Rescaling(1./255)
]
)Afin de montrer l'effet de l'amélioration de l'image, une image sélectionnée au hasard dans l'ensemble de données est retournée horizontalement et tournée au hasard, l'effet est illustré à la figure 3.
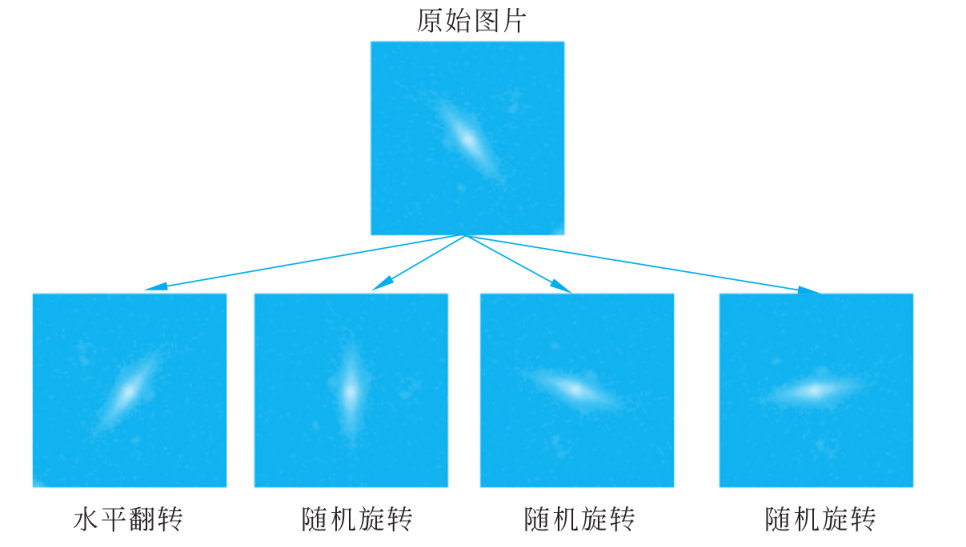
■ Figure 3 Exemple d'amélioration d'image
(4) Construction de modèles et formation. Le modèle de réseau sélectionné dans ce cas est le modèle ResNet50 fourni avec Keras. L'optimiseur (optimiseur) utilisé est Adam, la perte sélectionnée est sparse_categorical_crossentropy et la norme de mesure (métrique) utilise la précision. La valeur des époques définies est 100, et la valeur de batch_size est La valeur est 32. Bien sûr, le choix des hyperparamètres n'est pas unique, vous pouvez essayer d'autres hyperparamètres par vous-même et observer leurs effets d'entraînement. code affiché comme ci-dessous.
#构建模型
model=Sequential(Ldata augmentation,
ResNet50(weights=None,classes= 4)])
#配置模型参数
model.compile(optimizer="Adam"loss='sparse categorical crossentropy'rmetrics='accuracy' )
#训练模型
epochs=100
history=model.fit(train,epochs=epochs,batch size=32
validation data=val)
# 保存模型
model.save("resnet img.h5")Une fois le programme exécuté, un fichier nommé resnet_img.h5 est généré dans le répertoire où se trouve le programme, qui est le modèle formé.
(5) Modèle d'essai. Une fois la formation du modèle terminée, utilisez le jeu de test pour tester le modèle afin de vérifier l'effet de classification du modèle. Lors de l'évaluation du modèle, utilisez le taux de précision, le taux de rappel, le taux de précision et les indicateurs d'évaluation de mesure F1 dans la bibliothèque Scikit-learn. Dans ce cas, les indicateurs ci-dessus sont écrits dans une fonction personnalisée test_score(), puis la catégorie prédite par le modèle et la valeur réelle de l'étiquette sont envoyées à la fonction, et l'efficacité de classification du modèle est supérieure à 85 %. code affiché comme ci-dessous.
deftest score(x,y):
'''
自定义函数对分类效果进行评估
:param x:预测类别
:param y:真实标签
'''
print("准确率:.4f" accuracy score(x,y))
print("精确率:4f" precision score(x,Y,average='macro'))
print("召回率:.4f"号recall score(x,y,average='macro'))
print("F1度量:.4f" fl score(x,y,average='macro'))
#加载模型
model=tf.keras .models.load model("resnet img.h5")
# 使用模型对测试集进行预测
predict y=model.predict(test)
predict class=np.argmax(predict y, axis=1) #选出最大概率对应的下标#生成标签值
labels=[07 * 50+[1 * 50+27 * 50+/3 * 50 # 评估预测结果
test score(predict class,labels)La sortie est :
准确率:0.8550
精确率:0.8550
召回率:0.8791
E1度量:0.8571On peut voir d'après ce qui précède que le test de l'ensemble de test contient 200 images de galaxies, qui sont divisées en 4 catégories, et chaque catégorie a 50 images. L'ensemble de test est prédit par model.predict(test) et les valeurs dans les données renvoyées sont des tableaux de tableaux 200. Chaque tableau de tableaux stocke 4 valeurs de probabilité et l'image de galaxie correspondante est divisée en 0, 1, Les valeurs de probabilité de 2 et 3 classes. Ensuite, l'indice correspondant à la valeur maximale dans chaque tableau est obtenu via np.argmax(), et la valeur de l'indice est la catégorie de cette image.
Lors de la lecture des images de l'ensemble de test, l'ordre des images de l'ensemble de test n'a pas été perturbé, de sorte que les étiquettes de l'ensemble de test n'ont pas été perturbées. L'ordre des étiquettes correspondant aux 200 images de galaxies de l'ensemble de test est de 50 valeurs d'étiquettes 0, 50 valeurs d'étiquettes 1, 50 valeurs d'étiquettes 2, 50 valeurs d'étiquettes 3, et la variable étiquettes est une variable contenant 50 0 , une liste de 50 1, 50 2 et 50 3, utilisez donc la variable labels pour représenter la véritable catégorie des 200 images de l'ensemble de test.