Auteur de cet article : Byte, scientifique en chef de Guanyuan Data. Diriger l'application de plusieurs projets d'IA dans les 500 plus grandes entreprises mondiales et remporter à plusieurs reprises le championnat Hackathon dans le domaine de la vente au détail intelligente. Il a déjà travaillé chez MicroStrategy et Alibaba Cloud et possède plus de dix ans d'expérience dans l'industrie.
Dans l'article précédent, nous avons présenté la composition et la construction de la plateforme d'apprentissage automatique cloud-native [1]. Dans les applications d'entreprise réelles, la plate-forme d'apprentissage automatique est très dépendante de la plate-forme de données sous-jacente de l'entreprise.Bien que la recrudescence de l'IA ait été vague après vague au cours des deux dernières années, elle est très dépendante de l'infrastructure de la plate-forme de données à mettre en œuvre. bien l'application de l'algorithme. Il ressort également de certains rapports d'analyse [2] d'a16z que les sociétés de plateformes de données ont attiré beaucoup d'attention du marché et des capitaux, et des concepts tels que la pile de données moderne [3] ont émergé au fil des temps . Dans cet article, parlons de ce qu'est la plate-forme de données native cloud.
1. Historique du développement
La première plate-forme de données est issue de la technologie des bases de données relationnelles (RDBMS). Depuis le début, elle a commencé avec le système OLTP qui enregistrait les données d'exploitation commerciale, et a progressivement développé les exigences connexes pour l'analyse des données des conditions commerciales et la prise de décision ultérieure, qui est le système dit OLAP., qui contient de nombreuses théories classiques et méthodes techniques.
Dans les années 1980, il existait une méthode de conception consistant à établir un système d'entrepôt de données ( Data Warehouse ) pour les besoins d'analyse de données, qui est devenu la première génération de système de «plate-forme de données». En 1992, le célèbre "père de l'entrepôt de données" Bill Inmon a publié le livre "Building the Data Warehouse", qui formait un ensemble de méthodologies descendantes et centralisées pour la construction d'entrepôts de données au niveau de l'entreprise. Un autre magnat, Ralph Kimball, a publié le livre "The Datawarehouse Toolkit" en 1996 et a proposé l'idée de construire un entrepôt de données au niveau de l'entreprise basé sur le concept de Data Mart de bas en haut. Dans les années 1990, les livres de ces deux maîtres sont presque devenus les ouvrages faisant autorité incontournables pour les praticiens, et le concept d'entrepôts de données au niveau de l'entreprise est progressivement devenu populaire, et a été largement adopté et déployé par les grandes entreprises avec des applications d'analyse BI. À cette époque, les systèmes logiciels courants provenaient tous des principaux logiciels commerciaux à source fermée, tels que IBM DB2, SQL Server, Teradata, Oracle, etc.
Au début du 21e siècle, le concept d'Internet a commencé à prendre de l'ampleur, et en termes de traitement et d'analyse de données, le défi du "big data" a également émergé au fur et à mesure que l'époque l'exige. La technologie traditionnelle d'entrepôt de données a été difficile à gérer avec les données massives de l'ère Internet, les structures de données en évolution rapide et diverses exigences de stockage et de traitement de données semi-structurées et non structurées. À partir des trois articles classiques (MapReduce, GFS, BigTable) publiés par Google, une pile technologique de système de données distribuée différente de la technologie de base de données relationnelle traditionnelle a émergé. Cette tendance a ensuite été poursuivie par l'écosystème open source Hadoop, qui a eu un impact profond sur l'industrie pendant plus de dix ans. Je me souviens d'avoir assisté à diverses conférences techniques à cette époque, et tout le monde parlait de technologies et de concepts tels que "data lake", NoSQL, SQL sur Hadoop, etc. La plupart des plateformes de données adoptées par les sociétés Internet étaient basées sur l'écosystème open source de Hadoop ( HDFS, Fil, HBase, Hive, etc.). Les célèbres Hadoop Troika, Cloudera, Hortonworks et MapR ont également fait leur apparition sur le marché.
Avec l'essor de la vague de cloud computing menée par AWS, tout le monde est de plus en plus conscient des divers problèmes de l'architecture du système Hadoop, notamment la liaison des ressources de stockage et de calcul, la difficulté et le coût d'exploitation et de maintenance très élevés, et ne peut pas bien prendre en charge les données en continu. traitement, requêtes interactives, etc. Un très grand changement dans l'ère du cloud natif est que tout le monde a tendance à réduire le coût de possession, d'exploitation et de maintenance de divers systèmes, et les fournisseurs de cloud fournissent des services professionnels. Une autre tendance majeure est la recherche de capacités d'"élasticité" extrêmes. Par exemple, certains entrepôts de données cloud peuvent même facturer la quantité de calcul consommée par une seule requête. Ces exigences sont relativement difficiles à atteindre dans l'écosystème Hadoop, c'est pourquoi le concept d'une nouvelle génération de plates-formes de données cloud-native a progressivement émergé, ce qui est également le sujet principal de cet article.
2. Architecture de la plateforme de données
2.1 Architecture d'entrepôt de données classique
D'un point de vue traditionnel, une plate-forme de données est approximativement équivalente à une plate-forme d'entrepôt de données. Par conséquent, seuls les outils ETL sont nécessaires pour charger des données provenant de diverses sources de données dans l'entrepôt de données, puis utiliser SQL pour effectuer divers traitements, conversions et créer un système d'entrepôt de données hiérarchique, puis fournir des services externes via l'interface SQL :
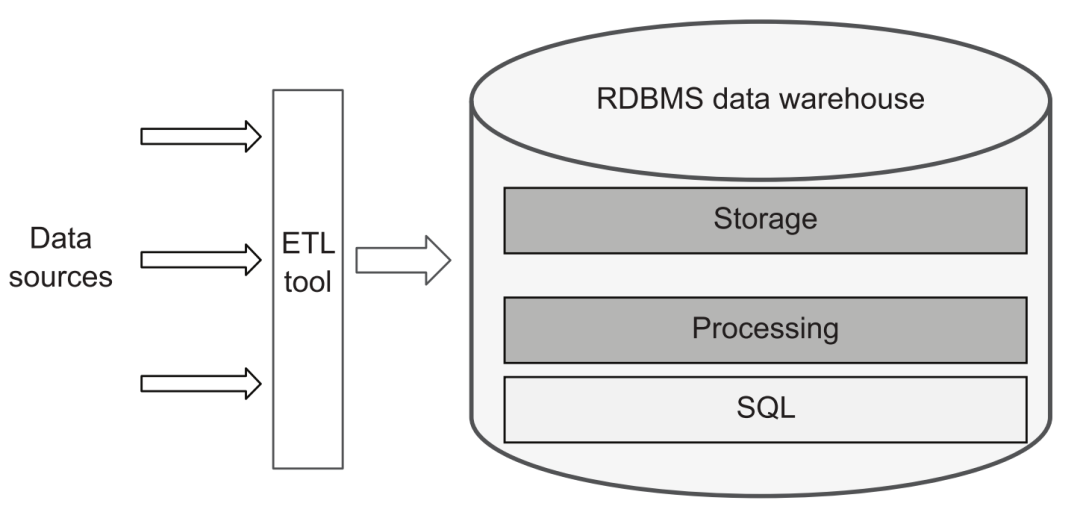
plate-forme de données traditionnelle
2.2 Architecture du lac de données
Cependant, avec le développement des affaires, tout le monde a progressivement plus d'exigences pour les capacités de la plate-forme de données, y compris certains des quatre V classiques :
-
Variété, la diversité des données. Par exemple, il est nécessaire de stocker et de traiter diverses données Json, Avro et ProtoBuf semi-structurées, ou du texte, des images, de l'audio et de la vidéo non structurés. Le traitement de ces contenus est souvent difficile à gérer pour SQL. De plus, les exigences se sont diversifiées : en plus de l'analyse BI, les exigences d'analyse et de modélisation de l'IA et la consommation des résultats d'analyse par les systèmes d'entreprise sont devenues de plus en plus courantes.
-
Volume, l'ampleur des données. Avec la transformation des affaires en ligne et la numérisation, la pensée axée sur les données devient de plus en plus populaire, et la quantité de données que les entreprises modernes doivent stocker et traiter devient également de plus en plus importante. Bien que les logiciels d'entrepôt de données commerciaux traditionnels puissent prendre en charge l'expansion horizontale, leur architecture est souvent liée au stockage et à l'informatique, ce qui entraîne d'énormes frais généraux. C'est également un point de différence très important dans les plates-formes de données modernes.
-
Vélocité, la vitesse de changement des données. Dans certains scénarios d'application de données, le besoin d'une prise de décision automatisée en temps réel a progressivement commencé à émerger. Par exemple, après qu'un utilisateur a parcouru certains produits, le système peut obtenir de nouvelles données comportementales et mettre à jour le contenu recommandé par l'utilisateur en temps réel ; ou prendre une décision de révision automatique du contrôle des risques en fonction du comportement de l'utilisateur au cours des dernières minutes, etc. Dans ce cas, le fonctionnement traditionnel de l'entrepôt de données T+1 ne peut évidemment pas répondre à la demande.
Poussée par ces exigences, l'architecture de la plate-forme de données a évolué vers une structure plus complexe, et de nombreux composants de système de Big Data bien connus tels que Hadoop et Spark ont également commencé à être introduits. Parmi eux, la célèbre Lambda Architecture proposée par l'auteur de Storm, Nathan Marz :
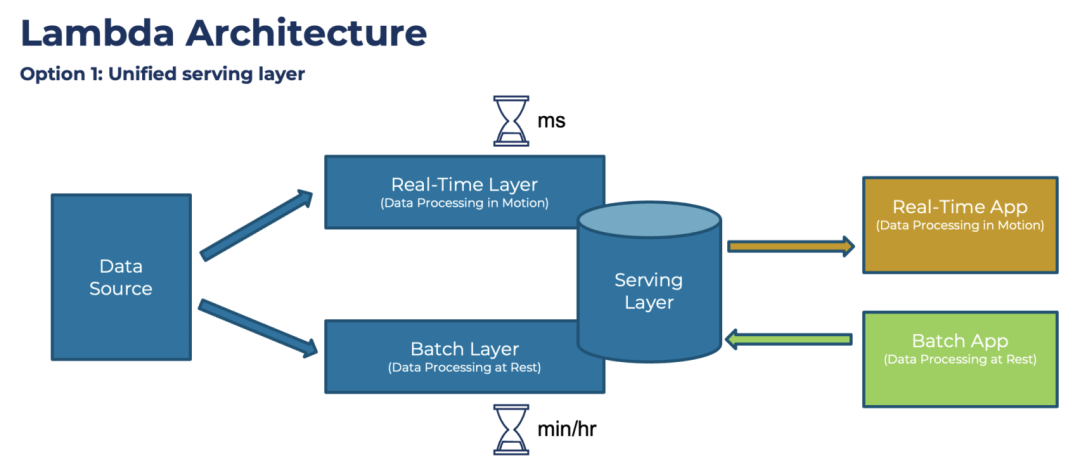
Architecture lambda
La conception de cette architecture a fait l'objet de nombreuses réflexions et résumés d'expérience. Le cœur est le traitement par lots (couche par lots) de la quantité totale de données chaque jour. Par rapport à la conversion de données traditionnelle basée sur SQL, elle peut prendre en charge des types de données plus riches. et les méthodes de traitement.En même temps, avec l'aide de l'architecture Hadoop, il peut également prendre en charge une plus grande quantité de données. Dans le même temps, afin de supporter les exigences "temps réel", une couche de traitement de flux (Real-Time Layer) est ajoutée. Enfin, lorsque les données sont consommées, les deux données peuvent être combinées (Serving Layer) pour former le résultat final. Cependant, cette architecture a également été critiquée, notamment la nécessité de maintenir deux ensembles de frameworks de calcul, traitement par lots et temps réel, et de mettre en œuvre deux fois la même logique de traitement, ce qui est insuffisant en termes de complexité architecturale et de coûts de développement et de maintenance. Plus tard, Jay Kreps, l'auteur de Kafka, a proposé l'architecture Kappa, il voulait unifier le traitement par lots et le traitement en temps réel, ce qui signifiait « intégration flux-batch ».
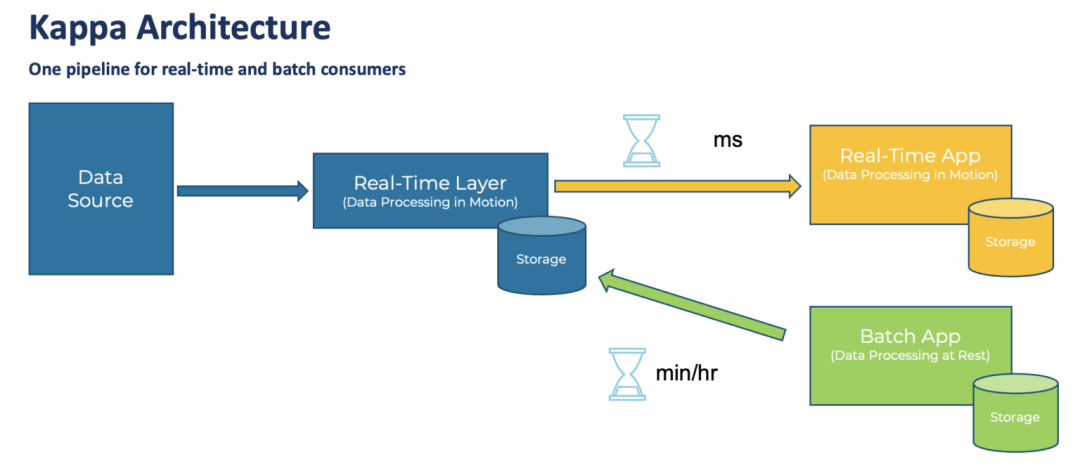
Architecture Kappa
Mais je pense personnellement que l'architecture Kappa est trop idéaliste.Même d'ici 2022, le streaming de données est loin de devenir le courant dominant de l'industrie. La duplication des données du flux de messages, la séquence des messages, la prise en charge de calculs complexes (tels que la jointure en temps réel), la prise en charge de divers systèmes de données sources, la gestion du schéma de données, le contrôle des coûts de stockage des données, etc. n'ont pas encore atteint un niveau très stable. Etat utile et efficace. Par conséquent, il n'est pas réaliste de laisser les données d'une entreprise fonctionner entièrement sur la base d'un système de données en continu. Par conséquent, l'architecture de la plate-forme de données principale à ce stade combine en fait le système de traitement par lots avec le système de traitement en temps réel en fonction des besoins de l'entreprise et de la maturité de l'ensemble du système de processus.
2.3 Architecture cloud native
Pour les besoins de combinaison de divers composants, avec l'avènement de l'ère du cloud natif, de plus en plus de produits de données SaaS plus faciles à "assembler et à utiliser" ont vu le jour. Par rapport à la complexité du déploiement et de la maintenance des clusters Hadoop et Kafka dans le passé, la nouvelle génération de produits natifs du cloud peut généralement utiliser directement les services d'hébergement, payer au fur et à mesure et les utiliser prêts à l'emploi, ce qui est très convivial pour les non -Sociétés Internet. Par conséquent, des architectures de plates-formes de données communes ont commencé à se développer dans le sens de l'introduction de divers composants de produits , et de nombreuses nouvelles idées intéressantes ont émergé :
-
Au niveau du traitement des données, différents moteurs de calcul sont utilisés pour effectuer des tâches de traitement par lots ou de traitement de flux, mais pour l'interface utilisateur, on espère qu'elle sera la plus cohérente possible, il existe donc ce que l'on appelle "l'intégration flux-batch".
-
En termes de stockage et de services de données, le « lac de données » et le « entrepôt de données » étaient autrefois en lice, mais après plusieurs années de développement, ils ont constaté qu'ils ne pouvaient pas complètement se remplacer. Par conséquent, le camp du lac de données a ajouté beaucoup de support pour des fonctions telles que SQL, Schema et la gestion des données, et est devenu une nouvelle espèce de Lakehouse. Et les entrepôts de données deviennent également natifs du cloud, et de nombreux entrepôts de données cloud prennent également en charge l'utilisation de leurs moteurs informatiques pour calculer et traiter directement les fichiers sur le lac de données. "L'intégration Hucang" est également devenue un terme populaire.
-
En outre, il existe des exigences pour les fonctionnalités de requête par lots et à point unique dans le magasin de fonctionnalités, "HSAP" né de la combinaison d'exigences d'application d'analyse en temps réel et de consommation de données, etc.
La vue d'ensemble de l'architecture de données unifiée donnée par l'institution d'investissement bien connue a16z est très représentative :
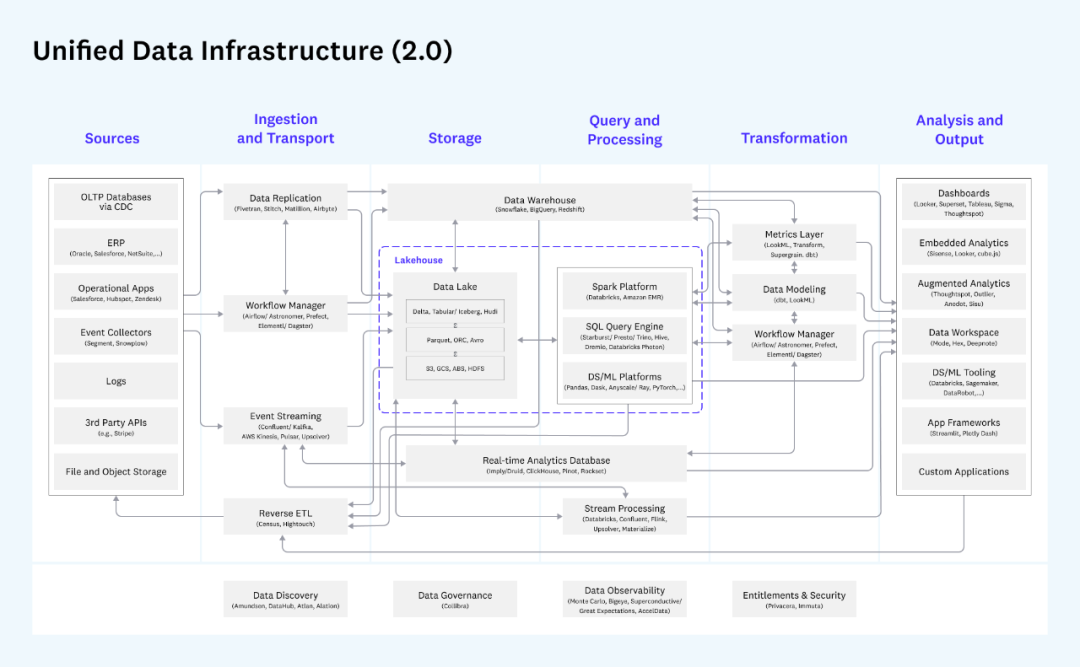
Architecture de données unifiée d'a16z
Cette image est très détaillée. Elle divise l'ensemble du processus de transfert de données en sources de données (généralement non incluses dans la plate-forme de données), acquisition et transmission de données, stockage, traitement des requêtes, conversion de données et sortie d'analyse. Chaque bloc Chaque module et les produits associés sont marqué en détail. En règle générale, les entreprises sélectionnent certains des composants à déployer en fonction de leurs besoins. Par exemple, s'il n'y a pas de demande de données en continu, la partie suivante de l'accès et du traitement des données en continu n'est pas nécessaire. Contrairement à l'architecture Lambda, pour un même scénario métier, il n'est généralement pas nécessaire de faire passer la même donnée par le lien de traitement temps réel et le lien de traitement batch deux fois à T+1, mais de choisir celui qui convient. peut être utilisé pour un traitement ultérieur.
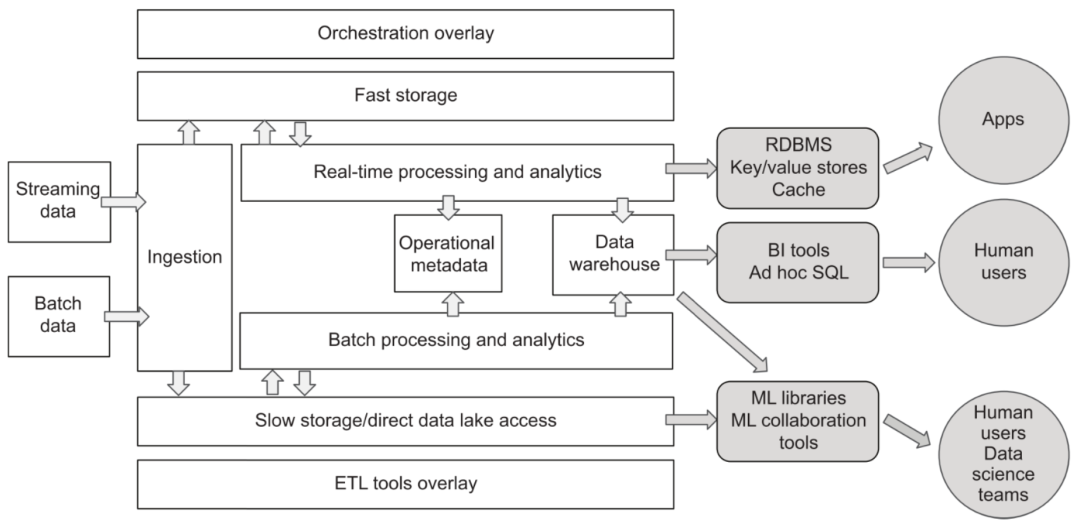
Cependant, le schéma d'architecture mentionné ci-dessus est un peu trop compliqué car il prend en compte les besoins de différentes entreprises dans différents scénarios et à différentes étapes. Personnellement, je préfère un aperçu de l'architecture relativement simplifié donné par l'auteur dans le livre "Designing Cloud Data Plateforme":
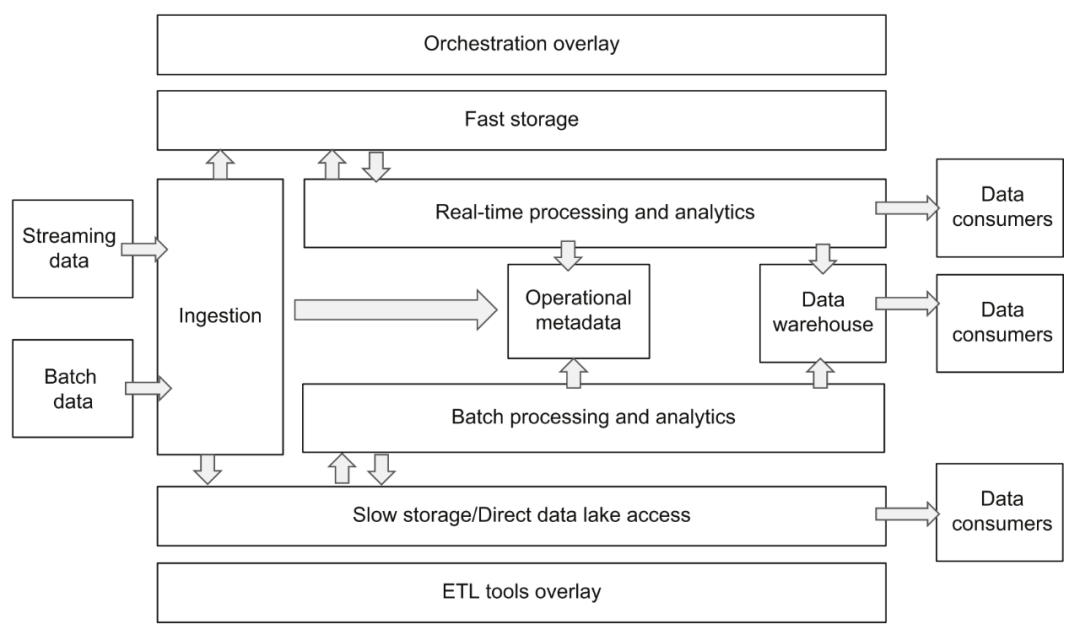
Architecture de plate-forme de données cloud
Le cœur de cette architecture est fondamentalement le même que la référence d'architecture donnée par a16z, mais la conception divisée de chaque couche est plus claire, ce qui nous aide à comprendre et à planifier l'ensemble de la plate-forme de données. Si les responsabilités et les interfaces entre chaque couche peuvent être clairement définies, cela sera très bénéfique pour la normalisation du flux de données et le remplacement et la mise à niveau flexibles de la mise en œuvre des composants. Plus tard, nous développerons et décrirons les différents composants de la plate-forme de données cloud sur la base de ces deux schémas.
D'une manière générale, la tendance à l'évolution de l'architecture de la plate-forme de données au cours des dernières années a principalement deux aspects. L'un est de répondre aux divers besoins de l'entreprise. Les composants système globaux de la plate-forme sont de plus en plus nombreux, ce qui est à un stade très différencié. L'utilisateur reste transparent ; le second est que la sélection des composants tend à choisir des produits de différents éditeurs de cloud public ou de plateformes de données SaaS. Dans le cas d'une architecture complexe, le coût de maintenance n'est pas trop augmenté, mais les responsabilités entre les composants sont claires (couplage lâche) et la standardisation des interfaces restent un défi.
3. Acquisition de données
En termes d'acquisition de données, la plate-forme doit être en mesure de prendre en charge à la fois les données par lots et l'accès aux données en continu.
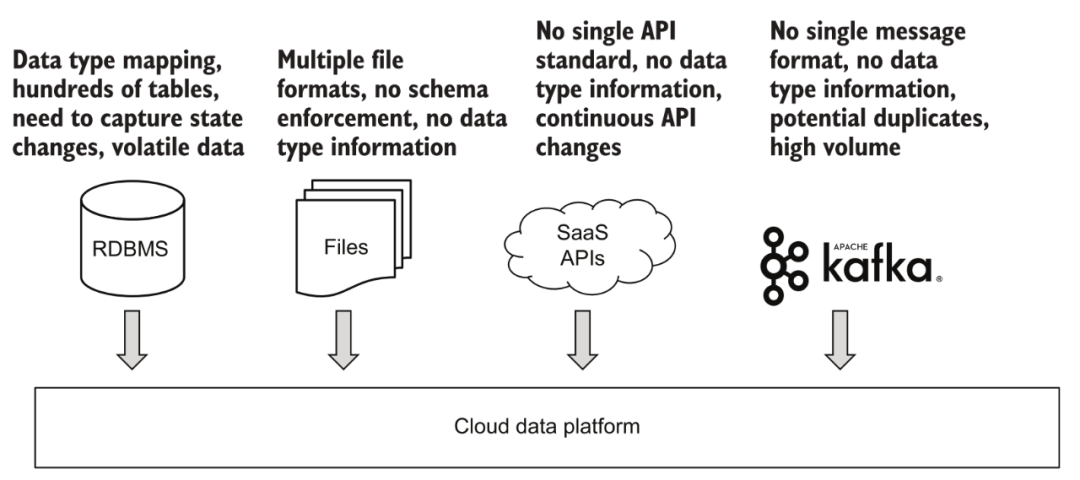
Divers accès aux données
3.1 Acquisition par lots
Pour les données par lots, telles que divers fichiers téléchargés, ftp ou d'autres sources de données d'API tierces qui ne peuvent pas prendre en charge la consommation en temps réel. En fait, les différentes sources de données actuellement connectées par la plupart des entreprises et la structure de base des données au sein de l'entreprise se présentent essentiellement sous la forme d'un traitement par lots. La grande majorité des plates-formes prennent assez bien en charge ce domaine. Une approche typique consiste à déclencher des tâches à intervalles réguliers, à obtenir un contenu de données complet ou mis à jour de manière incrémentielle à partir de sources de données via des composants, et à les stocker dans la plate-forme de données. Si le paramètre de déclenchement de cette tâche est défini plus fréquemment, nous pouvons également obtenir un contenu de données mis à jour "quasi-temps réel" grâce au traitement par lots pour une analyse et une utilisation ultérieures.
3.2 Acquisition en continu
Les données en streaming sont une tendance très populaire ces dernières années, mais elles ont relativement peu d'applications en dehors des sociétés Internet. La compréhension du "temps réel" par chacun est également différente. Par exemple, pour les scénarios d'analyse, il est généralement reconnu que la mise à jour des données de T+1 (le lendemain voit la situation jusqu'au jour précédent) appartient au traitement par lots, tant qu'il y a plusieurs mises à jour des données dans une journée, il appartient aux Analyses "temps réel". Ce type de demande peut être entièrement réalisé grâce à la petite mise à jour par lots mentionnée ci-dessus. Pour certains scénarios de prise de décision automatique, tels que les systèmes de recommandation et le contrôle des risques de transaction, même si des mises à jour "en petits lots" au niveau de la minute sont réalisées, la rapidité ne répond pas aux exigences et un système de données en continu doit être connecté.
Un scénario plus intéressant consiste à se connecter aux données de la base de données du système métier en amont. Si l'accès par lots est utilisé, l'approche générale consiste à interroger régulièrement les tables de données associées via un horodatage de mise à jour, puis à enregistrer les données incrémentielles sur la plate-forme de données. Cette méthode ne semble pas poser de problème, mais en fait, si l'entrée de données d'origine a été modifiée plusieurs fois au cours de la fenêtre de temps de mise à jour, par exemple, l'utilisateur a d'abord ouvert l'adhésion dans les 5 minutes, puis l'a annulée, via une requête par lots, elle peut être possible Après les deux requêtes, l'utilisateur est dans le statut de non-membre, et les informations de changement de statut intermédiaire sont perdues. C'est pourquoi de plus en plus de scénarios utilisent désormais la technologie CDC pour capturer les modifications en temps réel des données d'entreprise et se connecter à la plate-forme de données via des données en continu pour éviter toute perte d'informations.
La voie de construction suggérée pour ce bloc consiste à créer d'abord une capacité d'accès aux données par lots stable, puis à obtenir des données en continu, et enfin à envisager le traitement et l'analyse des données en continu (introduction de Flink, etc.) en fonction des besoins réels.
3.3 Demande et produits
Pour les composants d'acquisition de données, les exigences suivantes doivent être remplies :
-
L'architecture du plug-in prend en charge l'accès aux données à partir de plusieurs sources de données, telles que différentes bases de données, fichiers, API, sources de données en continu, etc., et prend en charge des configurations personnalisées flexibles.
-
L'opérabilité, car elle doit traiter avec divers systèmes tiers, l'enregistrement de diverses informations et la commodité du dépannage en cas d'erreurs sont très importantes.
-
Performance et stabilité, afin de faire face à la grande quantité de données et au fonctionnement stable d'importants processus d'analyse et de prise de décision, une assurance qualité de la plate-forme au niveau de l'entreprise est requise.
De nombreux produits peuvent également être envisagés pour l'acquisition de données :
-
Services associés des trois principaux clouds, tels qu'AWS Glue, Google Cloud Data Fusion, Azure Data Factory pour le traitement par lots ; AWS Kinesis, Google Cloud Pub/Sub, Azure Event Hubs pour le streaming de données, etc.
-
Services SaaS tiers, tels que Fivetran, Stitch, Matillion, Airbyte, etc. mentionnés par a16z.
-
Frameworks open source comme Apache NiFi, Kafka, Pulsar, Debezium (outil CDC), etc.
-
Basée sur le service Serverless, la fonction d'acquisition de données est développée par elle-même.
Notez qu'en ce qui concerne les services cloud, les services SaaS tiers, la sélection d'outils open source ou auto-développés, vous pouvez vous référer à la figure suivante pour l'évaluation des compromis. Plus on se rapproche des produits finaux tels que les fournisseurs de cloud, moins il faut investir dans l'exploitation, la maintenance et le développement, mais la contrôlabilité et la portabilité sont relativement faibles (à moins qu'elles ne soient compatibles avec l'API standard du framework open source) ; plus à gauche c'est l'inverse, utiliser les produits Open source ont une personnalisation très souple (mais il faut faire attention au contrôle de la modification magique des branches privées) et une souplesse de déploiement, mais le coût de R&D et d'exploitation et de maintenance sera beaucoup plus élevé.
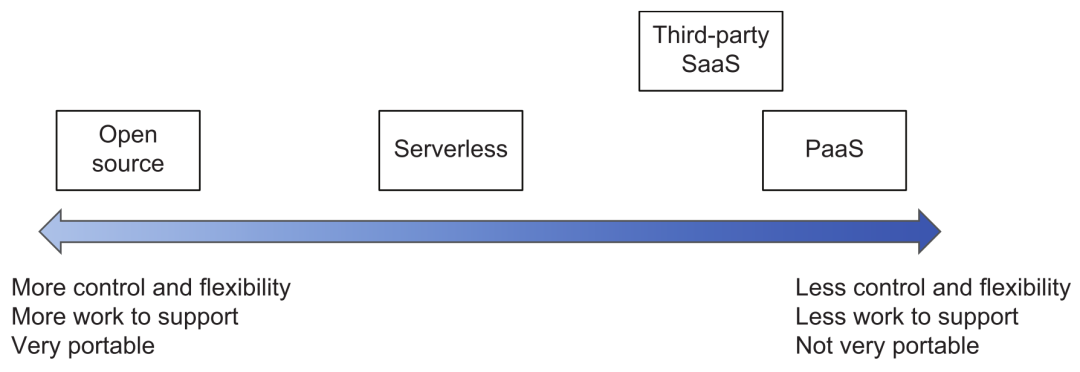
Compromis de sélection de produits
4. Stockage des données
Après l'acquisition des données, les données doivent être enregistrées sur le stockage de la plate-forme. Dans le diagramme d'architecture de la plate-forme de données précédente, nous voyons que l'auteur divise le stockage en deux parties : rapide et lent :
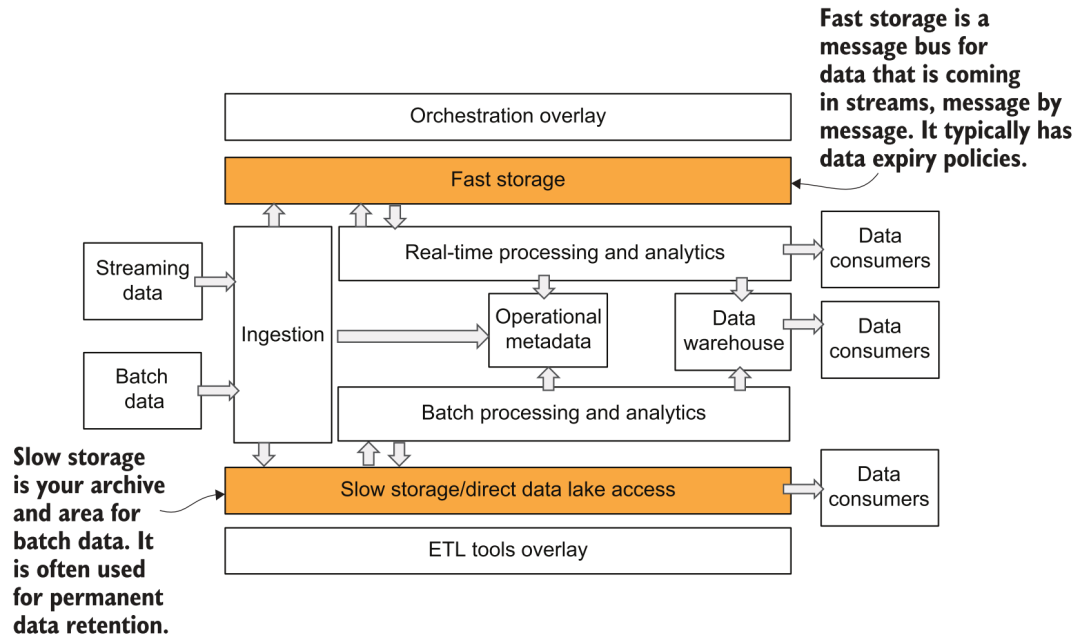
Stockage rapide et lent
4.1 Stockage lent
Ce stockage lent est relativement facile à comprendre. À l'ère des entrepôts de données, c'est la partie stockage du système d'entrepôt. À l'ère des mégadonnées, c'est ce que l'on appelle le lac de données. Les systèmes de fichiers distribués tels que HDFS étaient plus populaire avant, et maintenant de plus en plus de stockage et de calcul sont utilisés.En se développant dans le sens de la séparation, les méthodes de stockage courantes choisissent essentiellement divers stockages d'objets, tels que S3, GCS, ABS, etc. La forme de stockage du lac de données est relativement libre et il est souvent difficile de garantir la qualité des données ainsi que la gestion et le contrôle de l'entreprise.Par conséquent, au cours des deux dernières années, Databricks a proposé le concept de Lakehouse, dans lequel les métadonnées et le stockage correspondants sont Le protocole de stockage peut prendre en charge la gestion des schémas, la version des données, la prise en charge des transactions et d'autres fonctionnalités, que nous avons également présentées dans l'article Data Lake System in the Algorithm Platform [4].
4.2 Stockage rapide
Ce stockage rapide peut être plus facile à mal comprendre. Dans l'architecture Lambda et le diagramme d'architecture a16z, le stockage rapide fait généralement référence à un système de stockage qui fournit des services de requête ad hoc et d'analyse en temps réel pour les consommateurs de données. Par exemple, nous pouvons utiliser certaines bases de données analytiques à hautes performances en temps réel (Presto, ClickHouse), ou pour des services de stockage spécifiques tels que le système KV, RDBMS, etc. Dans l'image fournie par l'auteur, le stockage rapide représente en fait une signification plus simple, qui est le stockage intégré du système de données en continu, tel que Kafka et la partie du système Pulsar qui stocke les messages d'événement. Cela vous donne-t-il l'impression de revenir à l'ancienne méthode de calcul et de liaison de stockage ? Alors maintenant, Kafka et Pulsar ont commencé à prendre en charge le stockage hiérarchisé [5], améliorant l'évolutivité globale et réduisant les coûts.
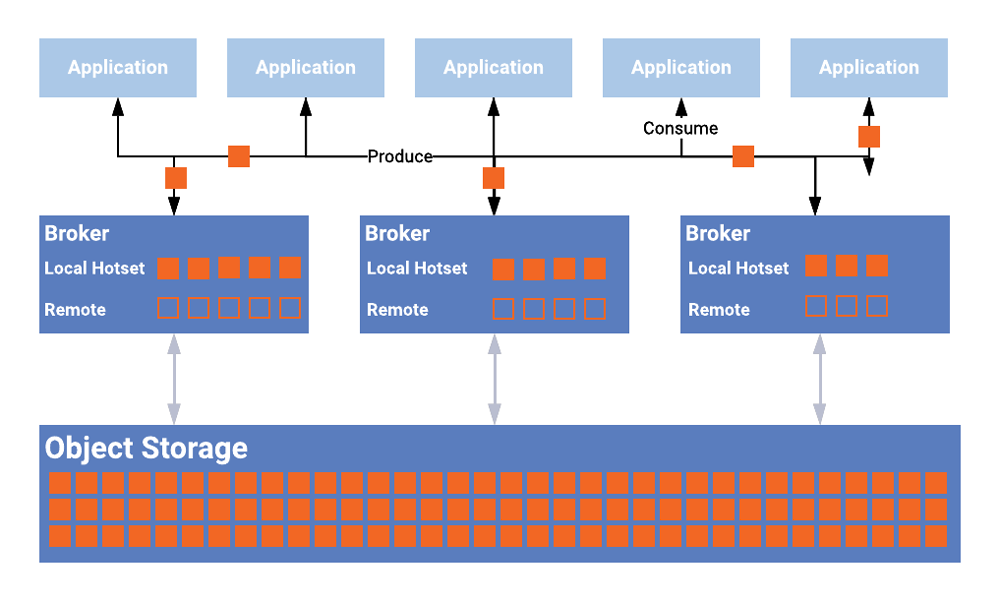
Stockage hiérarchisé
4.3 Processus d'accès aux données
Les données saisies à partir de la couche d'accès aux données sont généralement stockées directement dans le stockage lent sous la forme de données brutes, puis converties sous la forme qui doit être utilisée ultérieurement via d'autres traitements et planifications, tels que la table dans le Lakehouse ou le entrepôt de données qui fournit des services externes au milieu. Une fois que les données en continu sont entrées dans le stockage rapide, le composant de traitement et d'analyse en temps réel acquiert et consomme les données, et finalement déclenche la mise à jour des données en aval. Dans le même temps, les données en continu enregistrent généralement une copie des données d'origine pour ralentir le stockage de manière synchrone via un flux de traitement en temps réel, de sorte que des opérations de traitement flexibles ultérieures peuvent être effectuées pour d'autres exigences d'utilisation. Les messages dans le stockage rapide fourni avec le système en temps réel ne sont généralement conservés que pendant un certain temps pour éviter des coûts de stockage élevés. On peut voir ici que le stockage lent a essentiellement besoin de stocker la totalité de la quantité de données, et sa surcharge sera très élevée, c'est pourquoi le grand public choisit généralement des systèmes de stockage d'objets bon marché et faciles à étendre.
4.4 Demande et produits
Pour les composants de stockage, certaines exigences de fonctionnalités importantes incluent :
-
Haute fiabilité, la perte de données est certainement la plus inacceptable.Généralement, seul C dans CAP est une fonctionnalité qui ne peut pas être compromise.
-
L'évolutivité nécessite la capacité d'étendre et de réduire facilement l'espace de stockage.
-
Pour des raisons de performances, le stockage lent doit avoir un débit relativement bon pour prendre en charge l'acquisition simultanée de grandes quantités de données par les consommateurs. Et le stockage rapide doit avoir une très bonne vitesse de réponse en lecture et en écriture pour les petits volumes de données.
En termes de produits de stockage, les services des fournisseurs de cloud devraient être le choix dominant car après tout, il est trop compliqué de construire et de maintenir des clusters de stockage par vous-même. Il existe également des projets open source basés sur le stockage d'objets de ces fournisseurs de cloud qui ont ajouté des fonctions supplémentaires (telles que la prise en charge de POSIX) et une optimisation, telles que lakeFS [6], JuiceFS [7] et SeaseedFS [8], etc. (les deux derniers sont des projets chinois) .
5. Traitement des données
Le traitement des données est plus complexe dans l'ensemble de la plate-forme, et c'est aussi une partie où divers genres se concurrencent férocement. L'approche la plus typique consiste à utiliser deux ensembles de moteurs de calcul pour prendre en charge respectivement le traitement par lots et le traitement par flux, ce qui est cohérent avec la partie acquisition de données. L'avantage de ceci est que la technologie la plus appropriée peut être sélectionnée pour le scénario commercial, et les points forts du cadre lui-même peuvent être mieux utilisés. La plupart des entreprises sont principalement basées sur les exigences de traitement par lots, il n'est donc pas nécessaire d'introduire un moteur de traitement de flux au début.
5.1 Traitement par lots
Le framework le plus populaire pour le traitement par lots est Apache Spark. En tant que projet open source à l'ancienne, la communauté est active, la phase de développement est relativement mature et les fonctions sont très complètes et puissantes. En plus du traitement de données structuré typique, il peut également prendre en charge des données non structurées, des données graphiques, etc. S'il est basé sur des données structurées, alors l'ancien Hive, et les nouveaux venus comme Presto et Dremio sont également de très bons choix pour les moteurs de calcul SQL. Lors du traitement par lots de données massives, de nombreuses méthodes d'optimisation sont également impliquées, telles que la sélection de diverses méthodes de jointure, l'ajustement du parallélisme des tâches, le traitement du biais des données, etc., qui ne seront pas détaillées ici.
5.2 Traitement de flux
En termes de traitement de flux, le plus entendu en Chine doit être Apache Flink. De plus, comme Spark Streaming, Kafka Streams fournit également des capacités de traitement de flux correspondantes. Pour certaines logiques de calcul complexes, le seuil de développement pour le calcul de flux est encore assez élevé, et de nombreuses exigences peuvent être réalisées sans calculs complexes dans le traitement de flux. Par exemple, nous pouvons simplement traiter les données et les écrire dans des bases de données analytiques en temps réel, telles que ClickHouse, Pinot, Rockset ou des systèmes comme ElasticSearch, le stockage KV et la base de données en mémoire, qui peuvent également fournir un grand partie de l'informatique en continu Les exigences sont remplies, et nous présenterons les exemples correspondants plus tard. Le traitement de flux, comme le traitement par lots, nécessite diverses optimisations de performances et d'évolutivité, telles que la spécification de la logique de partition, la résolution de l'asymétrie des données et le réglage des points de contrôle.
5.3 Intégration du lot de flux
Ces dernières années, le concept d'intégration flux-lot est devenu populaire, en particulier dans la communauté Flink, qui estime que le traitement par lots n'est qu'une forme particulière de traitement de flux, qui peut être complété à l'aide d'un cadre unifié. C'est presque la même chose que l'architecture Kappa mentionnée précédemment. Bien sûr, il existe également des tentatives d'unification au niveau logiciel, comme Apache Beam, qui peut utiliser le même DSL pour le développement, puis basculer vers Spark ou Flink pour le traitement par lots et le traitement par flux lorsque l'exécution sous-jacente est exécutée.
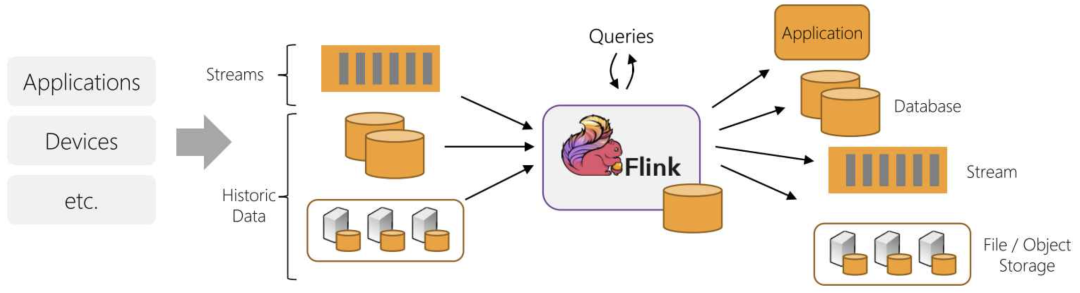
Streaming et intégration par lots de Flink
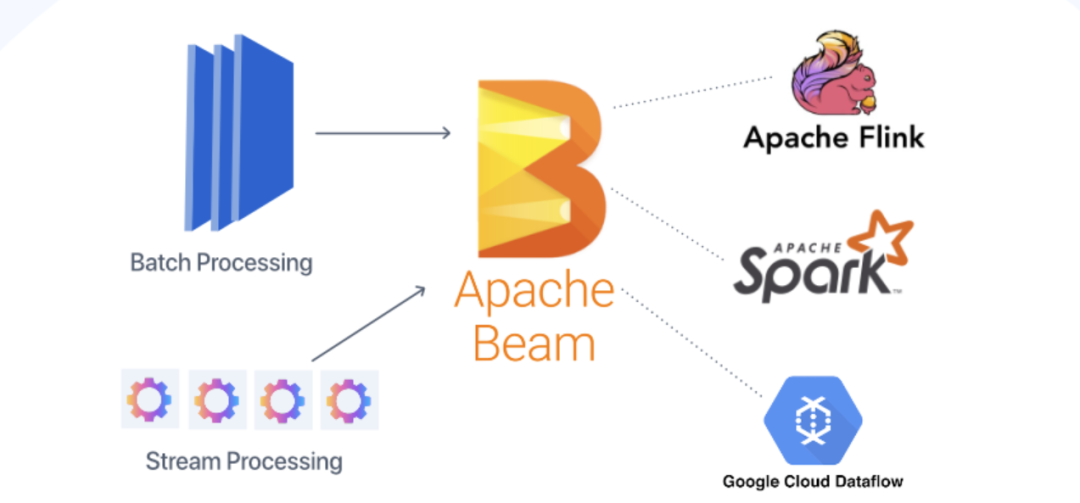
Streaming et intégration par lots de Beam
5.4 Demande et produits
Pour les composants de traitement de données, les exigences à respecter sont :
-
La capacité d'expansion horizontale de l'informatique peut utiliser plusieurs nœuds pour calculer de grandes quantités de données.
-
Stabilité et disponibilité, capacités de basculement/récupération multi-nœuds.
-
Prise en charge flexible et ouverte des API/SDK/DSL, tels que SQL, ou de divers langages de programmation courants pour développer la logique de traitement.
Produits de traitement par lots En plus des divers frameworks open source mentionnés ci-dessus, les fournisseurs de cloud fournissent également divers services gérés, notamment le bien connu AWS EMR, Google Dataproc ou Cloud Dataflow (basé sur Beam), Azure Databricks, etc.
Les produits de traitement de flux incluent AWS Kinesis Data Analytics, Google Cloud Dataflow et Azure Stream Analytics fournis par les fournisseurs de cloud. En outre, il existe des fournisseurs SaaS bien connus, notamment la société "officielle" de Kafka, Confluent [9], Upsolver [10], Materialise [11], etc.
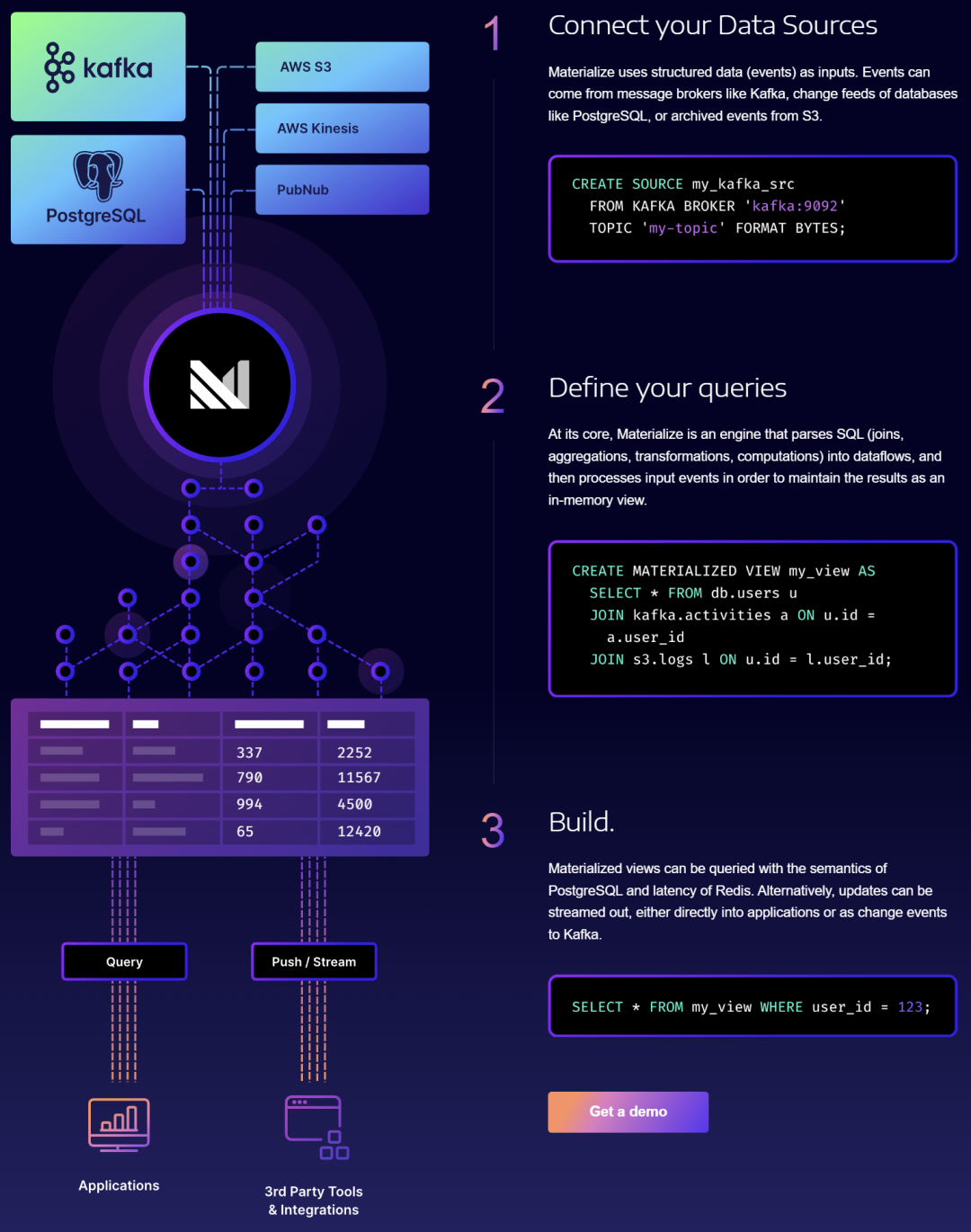
Société de traitement de données de streaming Materialise
6. Métadonnées
Après des années d'application dans l'industrie et de perfectionnement des produits, le SGBDR traditionnel est relativement complet en termes de métadonnées. Cependant, la plate-forme de données cloud n'étant pas encore vulgarisée, elle est souvent facilement ignorée dans le processus de construction interne de chaque entreprise. Cette partie de la capacité est en fait un élément crucial d'un produit mature au niveau de l'entreprise.
6.1 Métadonnées de la plateforme
Pendant le fonctionnement de la plate-forme, diverses informations seront générées, telles que diverses sources de données configurées, l'exécution de l'acquisition de données, l'exécution du traitement des données, le schéma, les informations statistiques, la relation sanguine des ensembles de données, l'utilisation des ressources du système, diverses informations de journal et plus. Grâce à ces informations, nous pouvons surveiller et alerter diverses tâches de la plate-forme, et lorsque des problèmes surviennent, nous pouvons également les dépanner et les traiter facilement en affichant ces informations, au lieu de nous connecter à la console de gestion de chaque module pour les vérifier un par un.
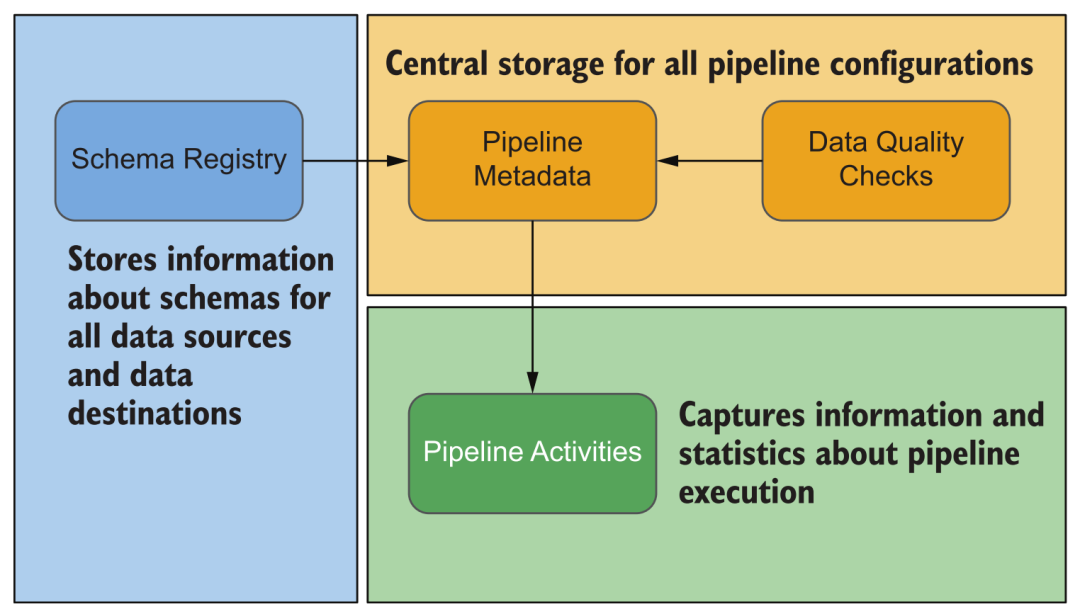
Type de métadonnées de plate-forme
Le schéma est un vaste sujet. Par rapport au système d'entrepôt de données basé sur la technologie des bases de données relationnelles, la plate-forme de données cloud présente certains avantages dans la gestion flexible des modifications du schéma de l'ensemble de données. Lorsque la plupart des entrepôts de données cloud traitent des modifications de schéma, leurs services seront affectés dans une certaine mesure (par exemple, des verrous de table sont nécessaires). Et de nombreux Lakehouses peuvent mieux prendre en charge l'évolution du schéma, comme l'option mergeSchema dans Delta. Bien entendu, cette fonction n'est pas omnipotente : dans l'ensemble de la plateforme de données, elle implique le traitement et la transformation de diverses données, l'interaction de divers liens, les systèmes en aval tels que les entrepôts de données, l'analyse en temps réel de l'écriture de la base de données et la consommation d'autres ressources externes. Le schéma doit être strictement documenté et géré.
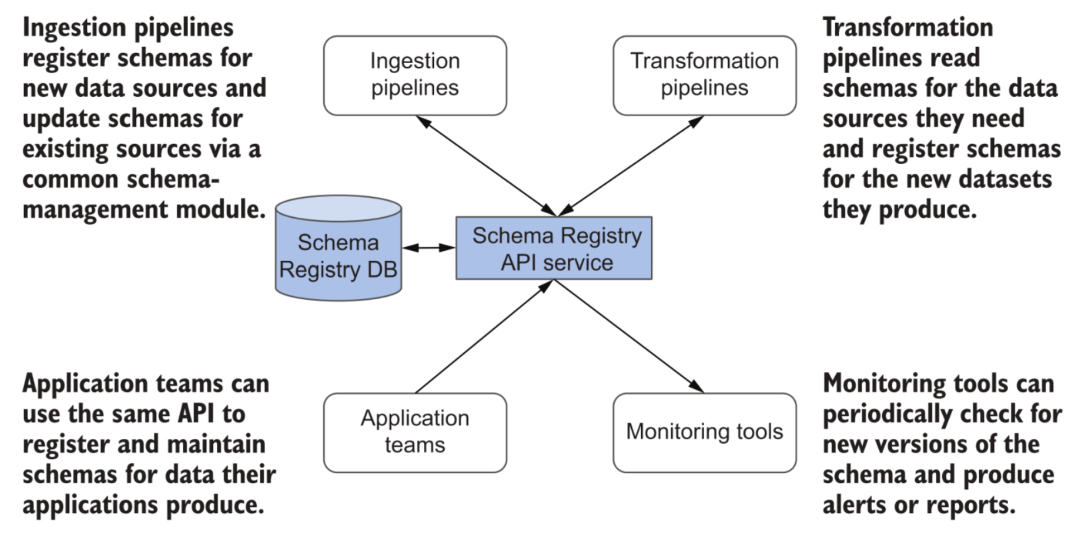
Schema Registry dans les métadonnées
Une autre catégorie de métadonnées très importante est la qualité des données. Avec l'avancement de la numérisation des entreprises, de plus en plus de sources de données sont impliquées, et divers traitements et transformations de données internes deviennent de plus en plus complexes, et diverses décisions d'entreprise dépendent de plus en plus du contenu des données et des résultats d'analyse correspondants. peut encore garantir la qualité des "produits de données" et l'efficacité globale de l'exploitation et de la maintenance itératives pendant tout le processus de complexité croissante est devenue un problème très critique. Ces demandes ont favorisé l'émergence du soi-disant mouvement DataOps, s'appuyant sur l'expérience de la manière de maintenir le développement, la livraison, l'exploitation et la maintenance d'entreprise de logiciels complexes dans DevOps, et de l'appliquer au domaine des produits de données.
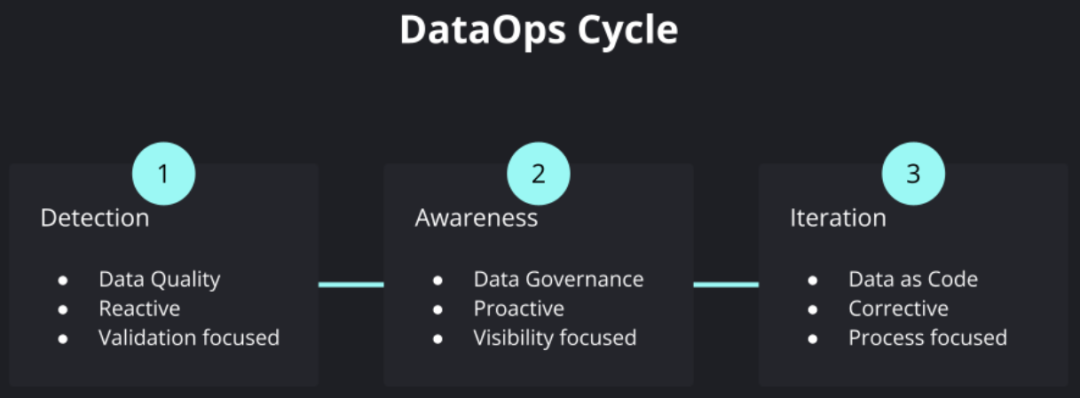
Cycle des opérations de données
Une partie très importante de cela est la surveillance et le test continus de l'inspection de la qualité des données, qui est appliquée au flux de données CI/CD, ainsi que le contrôle des données, la découverte des données et d'autres liens. Cela a également donné naissance à une nouvelle classe de produits appelée "Data Observability", qui exprime très clairement l'objectif d'avoir un aperçu de l'état de santé global des données dans la plate-forme de données.
6.2 Métadonnées commerciales
Outre les métadonnées au niveau technique, il existe également des exigences connexes en matière de gestion et d'utilisation des métadonnées dans les entreprises. Par exemple, lorsqu'il y a plus d'ensembles de données sur la plate-forme, la gestion et la recherche seront plus compliquées et la structure de base des dossiers peut ne pas répondre aux besoins. Par conséquent, nous devons prendre en charge des fonctions telles que la description, le balisage et la recherche d'ensembles de données. pour aider les utilisateurs professionnels à les trouver plus rapidement. Informations appropriées sur les données commerciales. Les produits dits Data Discovery et Data Catalog sont généralement conçus pour répondre à de tels besoins.
De plus, selon l'activité de l'entreprise, il est également nécessaire de suivre les exigences de conformité des données correspondantes, telles que la protection de la vie privée des informations personnelles, la prise en charge des divers droits et libertés des utilisateurs en matière de données, etc. Les capacités dans ce domaine nécessitent également une gestion dédiée des métadonnées et une prise en charge de la gouvernance des données. Les entreprises typiques sont Collibra et ainsi de suite.
6.3 Demande et produits
Pour les composants de métadonnées, les exigences conventionnelles doivent encore garantir une disponibilité et une évolutivité élevées.Lorsque l'échelle de la plate-forme est grande, l'échelle des métadonnées sera également très considérable. Une autre chose importante est la flexibilité et l'évolutivité, telles que la prise en charge du contenu de métadonnées défini par l'utilisateur et la fourniture de services externes via des API ouvertes. Dans des modules tels que le traitement des données, l'orchestration et l'exécution des processus, et la consommation de données qui en découle, toutes sortes de métadonnées doivent être traitées. Par conséquent, un service de métadonnées bien conçu attire de plus en plus l'attention.
Ce domaine est relativement nouveau et les produits fournis par les fournisseurs de cloud peuvent ne pas répondre à tous les besoins, tels que AWS Glue Data Catalog, Google Data Catalog et Azure Data Catalog.
Il existe également des fournisseurs open source qui fournissent des services connexes, et il existe relativement peu de métadonnées de plate-forme, le plus représentatif étant Marquez [12]. Au niveau des métadonnées métiers ou plus complètes, on trouve Apache Atlas [13], Amundsen [14], DataHub [15], Atlan [16], Alation [17] etc.
Présentation de la fonction Atlan
Pour l'observabilité des données, il existe également de nombreux outils et produits open source que nous connaissons, tels que Deequ [18], "Pengci" Dickens' Great Expectations [19], Monte Carlo [20], BigEye [21] attendez.
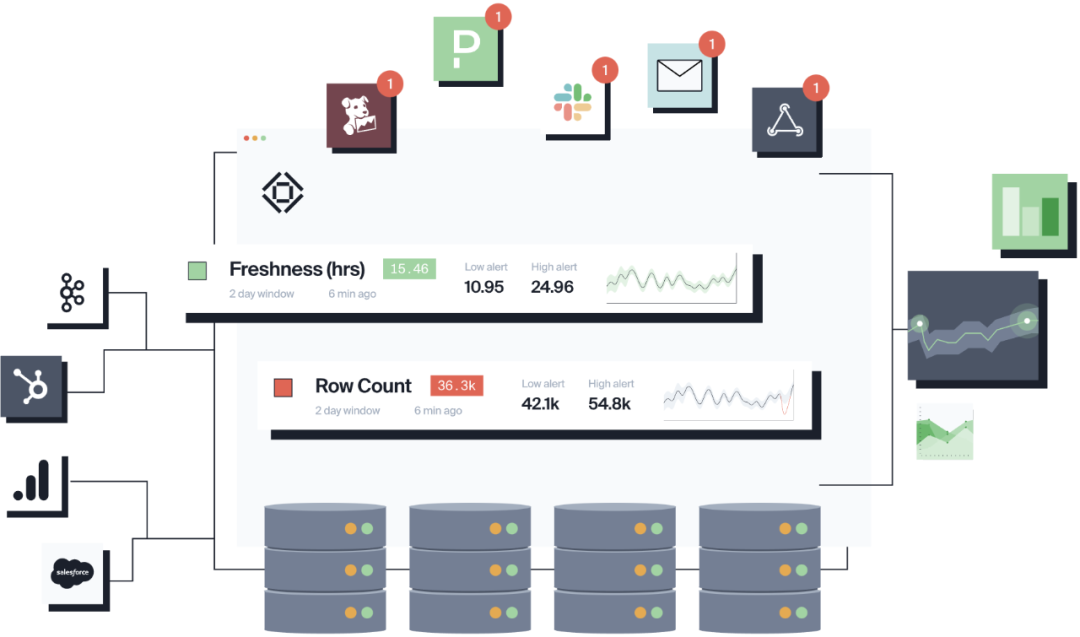
grand œil
7. Consommation de données
Par rapport à l'ère des entrepôts de données, les services externes fournis par la plate-forme de données sont également beaucoup plus riches.En plus des applications typiques d'analyse de données, des applications de consommation de données en continu, de science des données et d'apprentissage automatique ont également commencé à émerger. Afin de répondre à différents besoins, la plate-forme de données cloud peut introduire ou connecter divers systèmes de données spéciaux sous l'idée de conception de couplage lâche et de composantisation, et étendre de manière flexible ses capacités de service.
Divers besoins de consommation de données
7.1 Requête d'analyse
Pour les exigences d'analyse de données BI, la plupart des applications utilisent SQL pour interroger et obtenir des données. En raison de l'augmentation des besoins d'analyse de données en libre-service, de la flexibilité des requêtes, de la rapidité des interactions (nécessitant généralement des réponses de sous-seconde à deuxième niveau) et des exigences croissantes pour le traitement de grandes quantités de données, les requêtes Hive, Spark traditionnelles En raison du problème de temps de réponse, il est souvent incapable de répondre à la demande. Dans ce contexte, il existe de nombreuses solutions correspondantes :
-
Entrepôts de données cloud, tels que BigQuery, Redshift, Azure Synapse des trois principaux fournisseurs ou Snowflake du tiers. Dans le cas d'exigences de traitement de données structurées, il est même possible d'utiliser directement ces systèmes comme noyau pour remplacer les entrepôts de données traditionnels pour construire l'ensemble de la plate-forme de données.
-
Lakehouse, comme le moteur de calcul commercial Photon de Spark, ou des technologies telles que Presto et Dremio, effectuent un traitement efficace des requêtes basé sur des formats ouverts (Delta, Hudi, Iceberg) sur certains lacs de données.
-
Des bases de données d'analyse en temps réel open source, telles que ClickHouse mentionnée à plusieurs reprises ci-dessus, et divers projets émergents tels qu'Apache Doris [22], Databend [23], etc.
7.2 Sciences des données
Dans le domaine de la science des données et de l'apprentissage automatique, l'écologie la plus importante est construite sur la base de Python.Son mode de fonctionnement typique obtiendra directement une grande quantité de données de la couche de stockage de données via des cahiers, des scripts Python, etc., pour un traitement et une utilisation unifiés. La formation ultérieure du modèle, etc., nécessite rarement d'exécuter des requêtes complexes via SQL. Dans ce cas, si vous pouvez accéder directement aux fichiers d'origine dans un stockage lent, le surcoût est naturellement le plus bas. Bien sûr, cela présente également des inconvénients, tels que le contrôle des données, les autorisations, etc. seront difficiles à garantir.
De plus, si vous considérez l'ensemble du processus de développement, de déploiement et de surveillance de l'apprentissage automatique, un autre ensemble important d'exigences liées à MLOps sera introduit. Parmi eux, les exigences en matière de données impliquent le Feature Store, et la différence entre le lot et modes de demande de fonctionnalités en temps réel. , qui correspond également aux exigences de l'acquisition par lots et de la requête en un seul point dans la plate-forme de données dont nous avons discuté, et si les composants de déploiement peuvent être réutilisés peuvent être pris en compte lors de la construction.
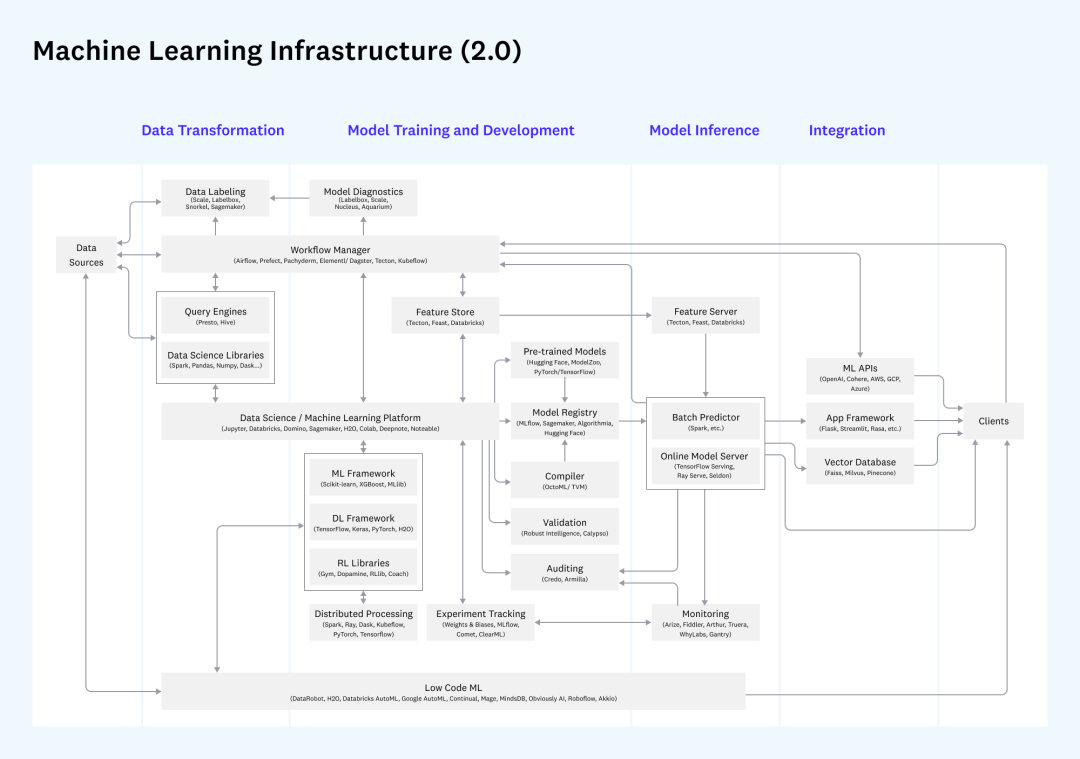
Infra liées à l'apprentissage automatique
Pour les discussions liées à MLOps, vous pouvez également vous référer à ma précédente introduction à MLOps [24].
7.3 Consommation en temps réel
Enfin, pour les résultats de traitement et d'analyse de flux, il y aura également des applications correspondantes pour la consommation en temps réel. Il peut fournir des services externes via une poussée de résultats en temps réel, l'écriture dans une base de données relationnelle, un stockage KV, un système de cache (tel que Redis) et un système de recherche (tel qu'ElasticSearch). De nombreux systèmes de traitement de flux tels que Flink prennent également en charge les requêtes en temps réel, et des API spécifiques peuvent être développées pour fournir des résultats de données directement à partir du système de flux.
7.4 Autorisations et sécurité
Dans les applications au niveau de l'entreprise, le contrôle des autorisations des utilisateurs, l'audit et la surveillance de divers enregistrements d'opérations, y compris la désensibilisation des données, le cryptage, etc., sont très importants. En plus de la prise en charge de la plate-forme elle-même, nous pouvons également envisager d'utiliser divers services cloud connexes, tels qu'Azure Active Directory, des services d'authentification d'identité tels que Auth0
7.5 Produits de la couche de service
Outre l'entrepôt de données cloud mentionné ci-dessus, Lakehouse et la base de données d'analyse en temps réel, il existe également des produits tels que Metric Store, qui s'appuient sur diverses sources de données et fournissent des services unifiés au monde extérieur. Comme LookML [26], Transform [27], Metlo [28], etc.
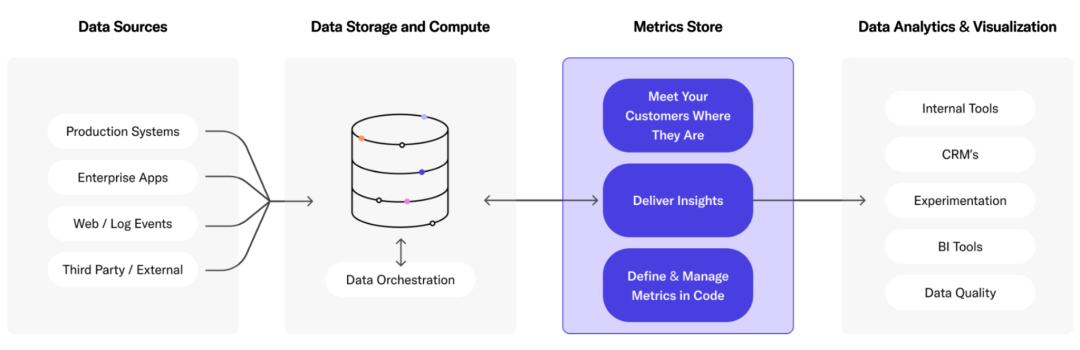
Magasin métrique
8 Orchestration des processus et ETL
8.1 Orchestration des processus
Dans l'architecture d'entrepôt de données traditionnelle, les outils d'orchestration jouent également un rôle extrêmement important. Dans la plate-forme de données cloud, la planification de l'exécution des processus de pipeline associés sera plus compliquée. Par exemple, nous devons déclencher le processus d'acquisition de données via la synchronisation ou l'API, puis déclencher et planifier diverses tâches en cascade. En cas de problème ou d'échec dans l'exécution d'une tâche, il peut automatiquement réessayer et récupérer, ou inviter l'utilisateur à intervenir.
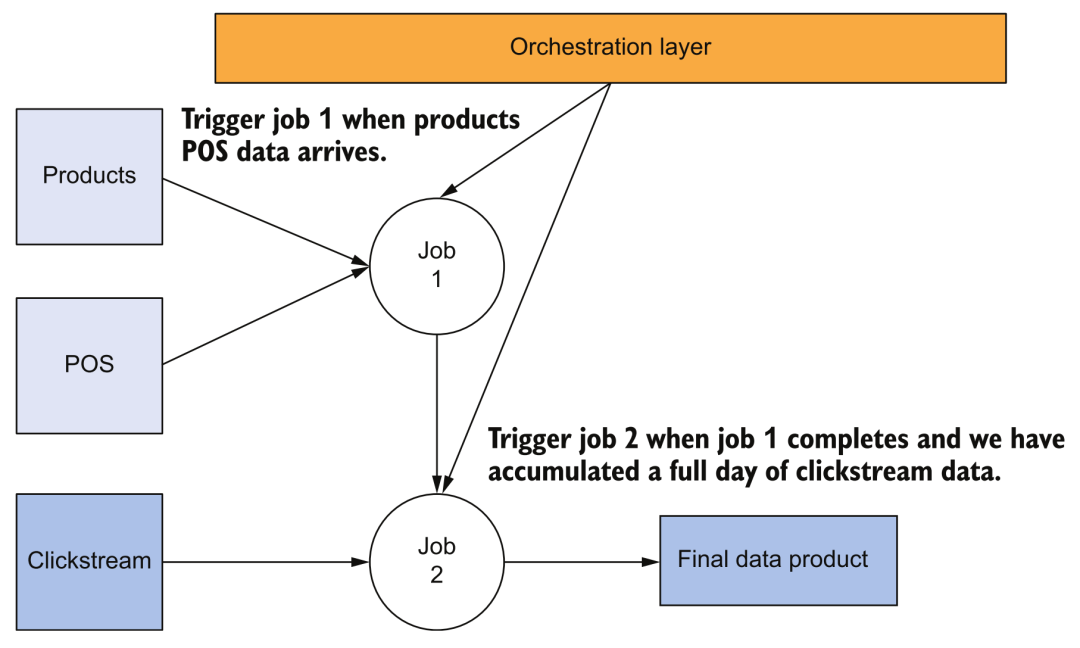
Organigramme
Par exemple, la figure ci-dessus montre la dépendance de tâche la plus simple. Le déclenchement de la tâche 2 dépend de la réussite de la tâche par lots de la tâche 1. À l'heure actuelle, nous avons besoin d'outils d'orchestration pour prendre en charge ce type de travail.
8.2 ETL
Les tâches spécifiques effectuées dans le processus d'orchestration sont généralement diverses opérations d'accès aux données et de conversion de données, ce que nous appelons communément ETL. En plus de développer une logique métier via SQL ou des SDK de moteur de calcul (tels que PySpark), il existe également de nombreux produits sur le marché qui prennent en charge le développement sans code/à faible code, ce qui réduit considérablement le seuil pour les utilisateurs. Par exemple, notre Guanyuan SmartETL est un bon produit à cet égard et a été apprécié par de nombreux employés d'entreprise.
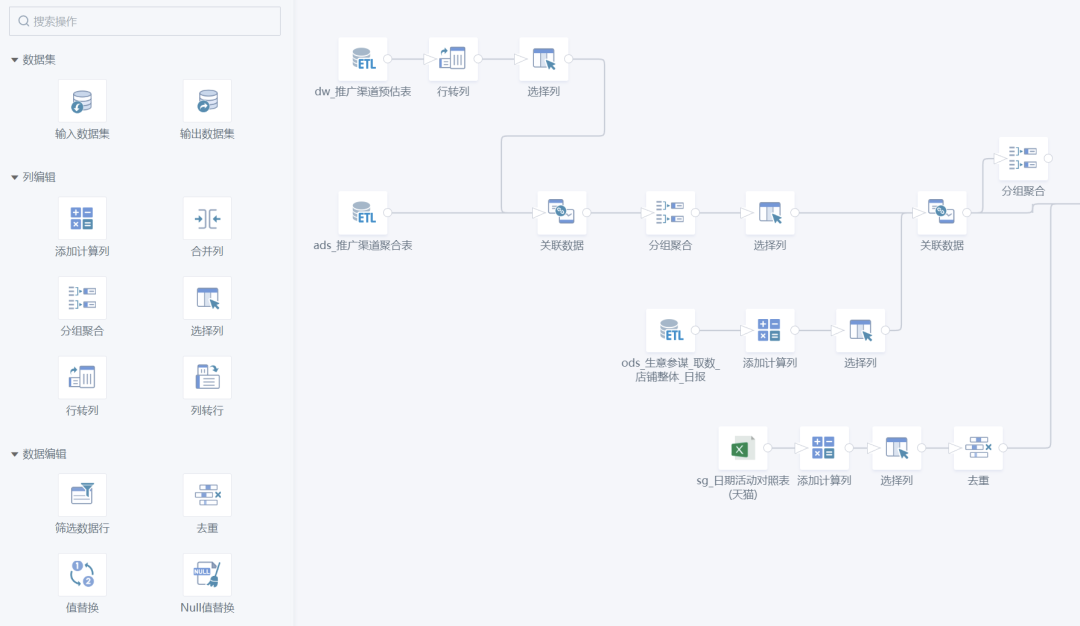
Guanyuan SmartETL
8.3 Demande et produits
Pour les outils liés à l'orchestration des processus, les principales exigences système sont :
-
Évolutivité, prise en charge de la planification et de la surveillance de pipelines massifs.
-
La stabilité doit garantir la stabilité et la haute disponibilité.Une fois que la capacité d'orchestration des processus est paralysée, cela signifie que les capacités de traitement de données de base de l'ensemble de la plate-forme se sont arrêtées.
-
Observable, utilisable et maintenable, l'état d'exécution de diverses tâches, les journaux, la surcharge des ressources système, etc. doivent être enregistrés et facilement visualisés, ce qui est pratique pour l'exploitation, la maintenance et le dépannage.
-
L'ouverture facilite le développement de diverses logiques de traitement personnalisées dans l'outil pour exécuter différents types de tâches.
-
Prise en charge de DataOps, même si un développement sans code par glisser-déposer est fourni, la couche inférieure doit toujours être en mesure de bien prendre en charge les besoins de DataOps, tels que la gestion des versions de la logique du pipeline, les tests et la publication (CI/CD), et prendre en charge les appels API pour réaliser l'automatisation des processus, etc.
On peut remarquer qu'en fait, beaucoup d'outils d'acquisition et de traitement de données ont également des capacités d'ETL ou d'orchestration. Les produits des fournisseurs de cloud sont essentiellement des outils d'acquisition de données, notamment AWS Glue, Google Cloud Composer (version hébergée d'Airflow), Google Cloud Data Fusion et Azure Data Factory.
En termes d'outils open source, parmi les outils d'orchestration, Airflow devrait être le plus connu.Avec l'énorme demande d'orchestration de workflow dans le domaine du machine learning, de nombreuses étoiles montantes ont émergé, telles que Dagster, Prefect, Flyte, Cadence, Argo (Pipeline KubeFlow) attendez. De plus, la popularité de DolphinScheduler [29] est assez bonne. Il n'y a pas beaucoup d'outils open source pour ETL, et talend n'est pas complètement open source, les plus connus sont Apache NiFi [30] et OpenRefine [31], deux projets open source avec une longue histoire.
Les fournisseurs SaaS peuvent faire référence à des fournisseurs d'acquisition de données, tels que Airbyte, Fivetran, Stitch, Rivery, etc. De nombreux projets open source d'outils d'orchestration mentionnés ci-dessus ont également des sociétés commerciales correspondantes qui fournissent des services d'hébergement. Je dois également mentionner le très populaire dbt [32], un outil de conversion de données utilisé par presque toutes les entreprises. Il a emprunté beaucoup de bonnes pratiques dans le domaine du génie logiciel. On peut dire qu'il répond aux besoins du DataOps. A très bon produit à l'appui.
9. Meilleures pratiques
9.1 Superposition des données
Lorsque nous construisons un système d'entrepôt de données d'entreprise, nous suivons généralement certaines bonnes pratiques classiques. Par exemple, en ce qui concerne le modèle de table de données, il existe des méthodes de conception telles que le schéma en étoile et le modèle en flocon de neige ; du point de vue du processus de transfert de données, il existe des méthodes très classiques entrepôts de données Mode hiérarchique :
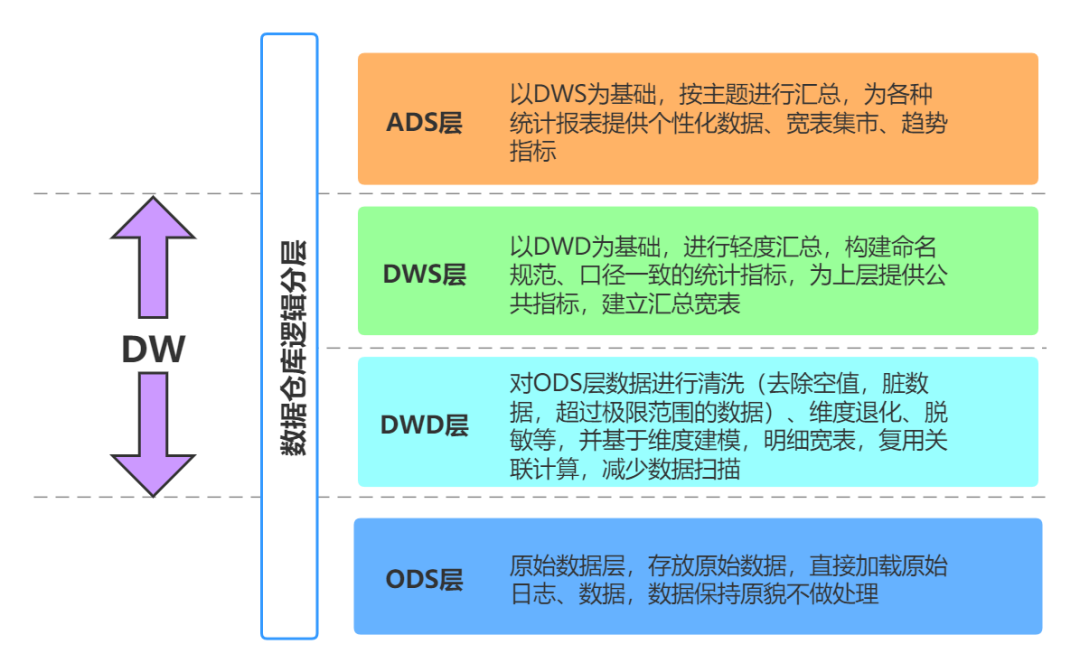
Hiérarchie de l'entrepôt de données
Dans la plate-forme de données cloud, nous pouvons également apprendre de cette idée. Par exemple, le flux de données dans le Lakehouse conçu par Databricks est très similaire à la couche d'entrepôt de données ci-dessus :
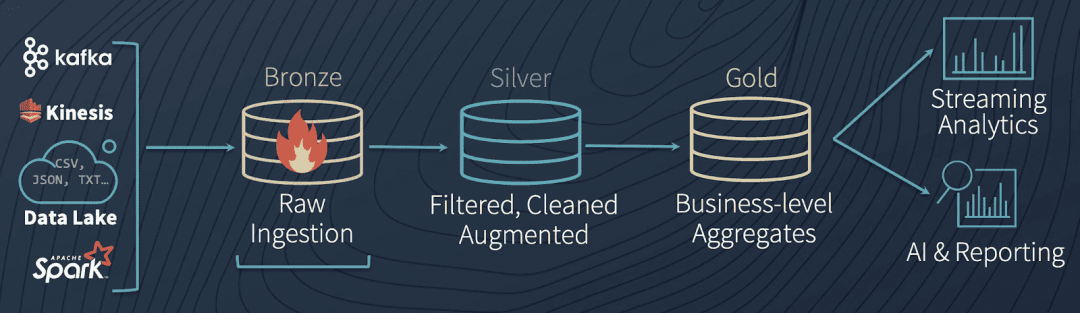
Architecture de données Lakehouse
Les étapes spécifiques du processus sont les suivantes :
-
Généralement, lors de l'entrée dans la plate-forme de données cloud via l'acquisition de données, l'état des données d'origine (qui peuvent être au format d'origine ou au format Avro) sera conservé autant que possible et stocké dans la zone d'atterrissage (bronze). l'architecture globale, seuls les outils de la couche d'acquisition de données peuvent écrire dans cette zone.
-
Les données d'origine subiront ensuite des contrôles de qualité généraux, une déduplication, un nettoyage et une conversion, et entreront dans la zone de staging (argent). A partir de maintenant, il est recommandé d'utiliser un format de rangement en colonne similaire au parquet.
-
Dans le même temps, les données d'origine seront copiées dans la zone d'archivage, puis utilisées pour le retraitement, le débogage de processus ou le test de nouveaux pipelines.
-
L'outil de couche de traitement des données lira les données de la zone de transfert, effectuera divers traitements de logique métier, agrégation, etc., et enfin formera des données de production (or) et fournira des services de données.
-
Les données de la zone de préparation peuvent également être laissées non traitées, contournées vers la zone de production et finalement transmises à l'entrepôt de données.Cette partie est équivalente aux données brutes, ce qui peut aider les consommateurs de données à comparer et à localiser les problèmes connexes dans certains cas.
-
Différentes logiques de traitement de données formeront des "produits de données" pour différents thèmes commerciaux et scénarios d'application, fourniront des services de consommation par lots (en particulier des scénarios d'algorithmes) dans la zone de production ou chargeront des entrepôts de données pour fournir des services de requête SQL.
-
Pendant le processus de transfert entre la mise en scène et la production, si la couche de traitement des données rencontre des erreurs, elle peut enregistrer les données dans la zone défaillante et, une fois le dépannage résolu, remettre les données dans la zone d'atterrissage pour déclencher à nouveau l'ensemble du processus.
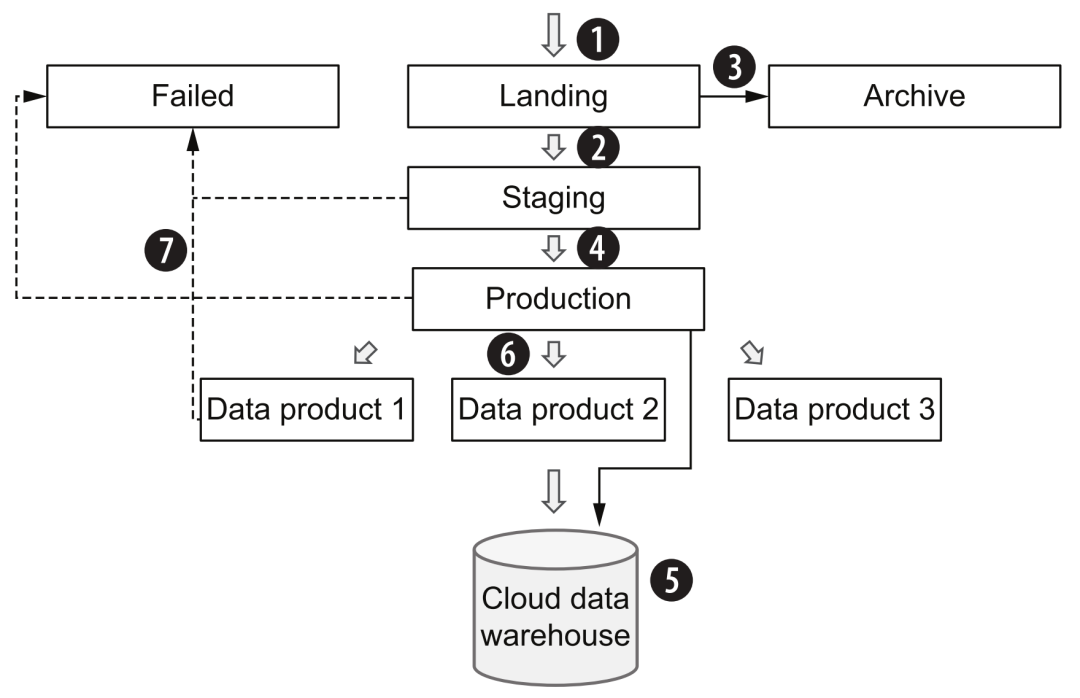
Meilleures pratiques de traitement des données
Ces zones peuvent être divisées par des concepts de stockage d'objets typiques, tels que "bucket" ou "dossier". Le contrôle d'accès de chaque zone aux différents modules de couche peut également être déterminé en fonction de différents modèles de lecture et d'écriture, ainsi que de la conception du stockage à froid et à chaud pour réduire les coûts. De plus, le flux de traitement des données en continu peut également apprendre d'une logique similaire, mais il y aura plus de défis dans la déduplication des données, l'inspection de la qualité, l'amélioration des données et la gestion des schémas.
9.2 Distinguer les exigences d'acquisition de flux et d'analyse de flux
Nous entendons souvent dire que les clients de l'analyse BI ont besoin d'une "analyse de données en temps réel". Cependant, après une analyse minutieuse, les utilisateurs ne regardent pas tout le temps le tableau d'analyse BI pour faire une "analyse en temps réel".En général, il y a un certain intervalle de temps pour ouvrir le tableau. Nous devons seulement nous assurer que les données que les clients voient à chaque fois qu'ils ouvrent le tableau de bord d'analyse sont à jour, de sorte que l'architecture suivante peut être utilisée pour répondre aux exigences :
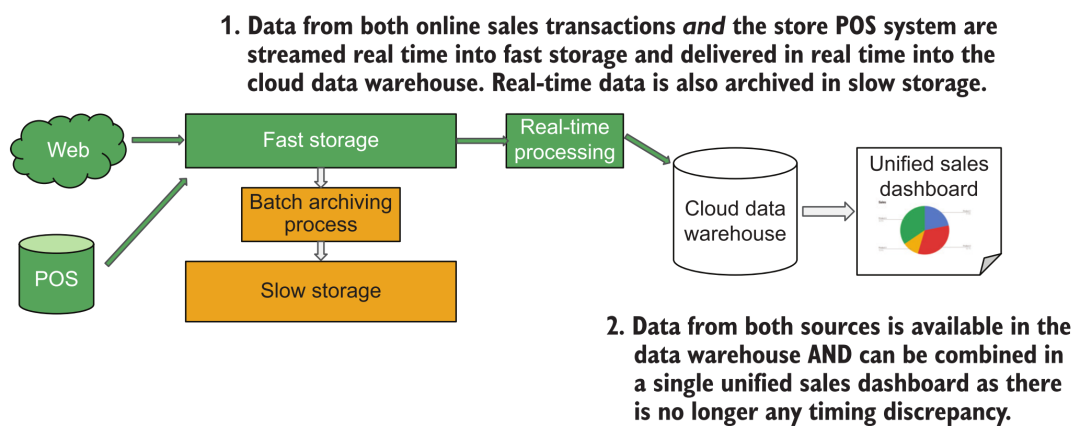
Architecture d'acquisition de données en continu
Ici, nous n'avons qu'à écrire les données de commande dans l'entrepôt de données cloud en temps réel via le système d'acquisition de données en continu.Lorsque l'utilisateur ouvre le rapport de temps en temps, déclenchez la requête SQL de l'entrepôt de données pour afficher les derniers résultats.
Mais considérons un autre scénario : dans un certain jeu, nous voulons afficher des données d'action en temps réel des utilisateurs, telles que des informations statistiques telles que les points d'expérience gagnés depuis le lancement. À l'heure actuelle, il n'est peut-être pas approprié d'utiliser encore l'architecture "d'acquisition en continu" mentionnée ci-dessus. Parce qu'à ce moment-là, chaque joueur regarde vraiment ses statistiques en "temps réel", il faut donc prendre en charge les requêtes à haute fréquence et à grande simultanéité. Le temps de réponse et les capacités de service simultanées des entrepôts de données cloud généraux sont difficiles à respecter, et c'est la véritable exigence pour "l'analyse en temps réel". Nous devons effectuer des opérations d'analyse statistique en streaming après avoir diffusé de nouvelles données des utilisateurs, et stocker les résultats dans certains systèmes de base de données/cache qui peuvent prendre en charge les requêtes à haute simultanéité et à faible latence afin de répondre aux besoins de consommation de données des joueurs en ligne massifs.
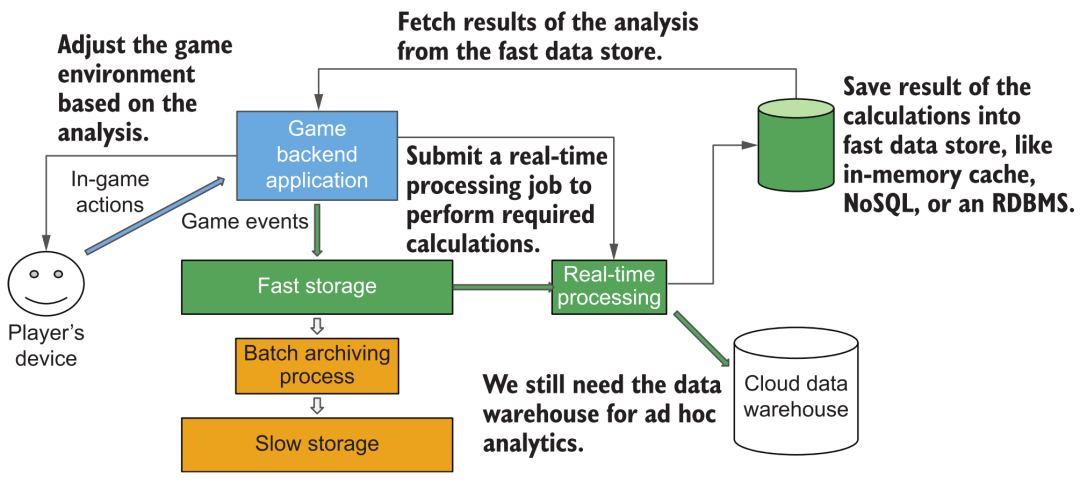
Architecture d'analyse de données en continu
9.3 Contrôler les dépenses de cloud computing
À l'ère du cloud natif, les barrières à l'entrée pour nous d'utiliser divers composants sont beaucoup plus faibles. Prêt à l'emploi, la mise à l'échelle élastique et l'absence d'O&M ont apporté beaucoup de commodité aux développeurs et changent tranquillement notre pensée. À l'ère des systèmes auto-construits, nous avons une compréhension plus fine et une optimisation en profondeur de la surcharge de ressources de chaque composant et du taux d'utilisation de l'ensemble du cluster. Mais maintenant, le compromis de diverses conceptions de systèmes est passé de l'allocation de pools de ressources limités au compromis entre coût et performance, ce qui a réduit la prise de conscience de l'optimisation du coût des ressources pour chaque composant. Y compris les fournisseurs de cloud eux-mêmes parfois "mauvais" intentionnellement ou non. Récemment, il y a un article The Non-Expert Tax [33] dédié à discuter de l'économie de l'auto-scaling des fournisseurs de cloud.
Par conséquent, en tant que développeur d'une plate-forme de données cloud, il est toujours nécessaire d'avoir une compréhension approfondie des divers composants du cloud computing, des principes d'architecture des produits, des modèles de facturation et de pratiquer les méthodes de surveillance et d'optimisation des ressources correspondantes. Les exemples typiques incluent le contrôle de la surcharge du réseau (réduction de la transmission entre les nuages), la conception du stockage à chaud et à froid, le partitionnement des données et d'autres méthodes d'optimisation pour améliorer l'efficacité du calcul et du traitement des données, etc.
9.4 Éviter les couplages serrés
Comme le montre le schéma d'architecture complexe ci-dessus, une plate-forme de données cloud se compose généralement d'un grand nombre de composants, et toute l'écologie technologique change chaque jour qui passe. Généralement, pour ce type de système complexe, nous adopterons une méthode de construction étape par étape. Au cours du processus, nous continuerons d'augmenter, de remplacer ou d'éliminer certains produits composants. Par conséquent, nous devons apprendre du principe de couplage lâche dans l'ingénierie logicielle pour éviter que des produits/interfaces spécifiques aient des dépendances étroites. Bien que parfois l'accès direct au stockage sous-jacent semble réduire les étapes intermédiaires et être plus efficace, mais cela nous fera également rencontrer beaucoup de problèmes lorsque nous voulons nous développer et changer plus tard. Idéalement, nous devrions clarifier autant que possible les frontières et les interfaces entre les composants et encapsuler différents produits pour fournir des interfaces relativement standard pour l'interaction et les services.
10. Construction de la plateforme de données
10.1 Valeur commerciale
Enfin, il convient de mentionner que la construction d'une plate-forme de données cloud complexe ne peut être promue uniquement d'un point de vue technique. L'ensemble du projet doit être initié et planifié à partir d'objectifs commerciaux (commerciaux). Les valeurs typiques d'une plateforme de données incluent :
-
Réduisez les dépenses, améliorez l'efficacité des opérations commerciales, économisez l'investissement en actifs et divers coûts d'exploitation et de maintenance.
-
Open source, prend en charge l'optimisation du marketing, l'optimisation de l'expérience client et d'autres scénarios, et favorise la croissance des revenus de l'entreprise.
-
L'innovation, grâce à d'excellentes capacités de produits, pour soutenir l'analyse des données en libre-service et la prise de décision de l'entreprise, pour explorer rapidement de nouveaux points de croissance.
-
Conformité, grâce à la construction d'une plate-forme unifiée pour répondre aux diverses réglementations, politiques et besoins réglementaires en matière de données.
Nous devons clarifier les exigences commerciales de l'entreprise et concevoir des stratégies et des plans de données pour la construction de plateformes de données de manière ciblée. Pour savoir comment les stratégies techniques servent les objectifs commerciaux, vous pouvez également vous référer à cet article The Road to Senior Engineers: Technical Strategy [34], qui ne sera pas développé ici.
10.2 Chemin de construction
Comme on peut le voir sur le schéma d'architecture précédent, la composition de l'ensemble de la plateforme est assez compliquée, et il faut généralement plusieurs années pour la construire et l'améliorer progressivement. Cela est cohérent avec l'évolution en ligne, numérique et intelligente de l'entreprise elle-même, au lieu d'ignorer le statu quo des données d'entreprise et de développer et déployer des plates-formes de données en continu, des plates-formes d'apprentissage automatique et d'autres technologies apparemment à la mode.
Au début de sa création, Guanyuan a profondément réfléchi et a proposé une méthodologie de chemin de mise en œuvre 5A pour l'analyse des données et la prise de décision intelligente dans les entreprises [35], y compris l'analyse en libre-service, basée sur la scène, l'automatisation, l'amélioration et enfin la prise de décision. -faire l'automatisation étape. Correspondant à la construction de la plateforme de données, vous pouvez également vous référer à des cadres politiques similaires, par exemple :
-
L'agilité peut être obtenue grâce à la construction du système d'entrepôt de données de base et à l'application de produits d'analyse BI en libre-service pour atteindre l'objectif de "voir les données".
-
Basé sur des scénarios, à travers la couche métrique et le marché des applications dans les produits BI, forment les meilleures pratiques de divers scénarios commerciaux, afin que davantage d'utilisateurs puissent savoir "comment regarder les données".
-
L'automatisation nécessite que la plate-forme ait certaines capacités d'orchestration, connecte divers résultats d'analyse aux systèmes de l'entreprise, pousse automatiquement les résultats (ETL inversé), l'alerte précoce des données, etc., pour obtenir l'effet de "données chassant les gens".
-
L'amélioration, sur la base de l'analyse, en ajoutant davantage de capacités de modélisation et de prévision de l'IA, nécessite que la plate-forme prenne en charge le traitement et la consommation de données algorithmiques (telles que les données non structurées, les ordinateurs portables) pour obtenir un "aperçu de l'avenir".
-
La mobilité, au final on espère aller plus loin sur la base de la prévision, s'étendant de l'IA analytique à l'IA d'action, ce qui nécessite que la plateforme fournisse des capacités de services externes plus complètes (API, données en temps réel, AB Test, etc.), combiné à certains outils low-code La création d'applications métier basées sur les données devrait permettre une "prise de décision automatique".
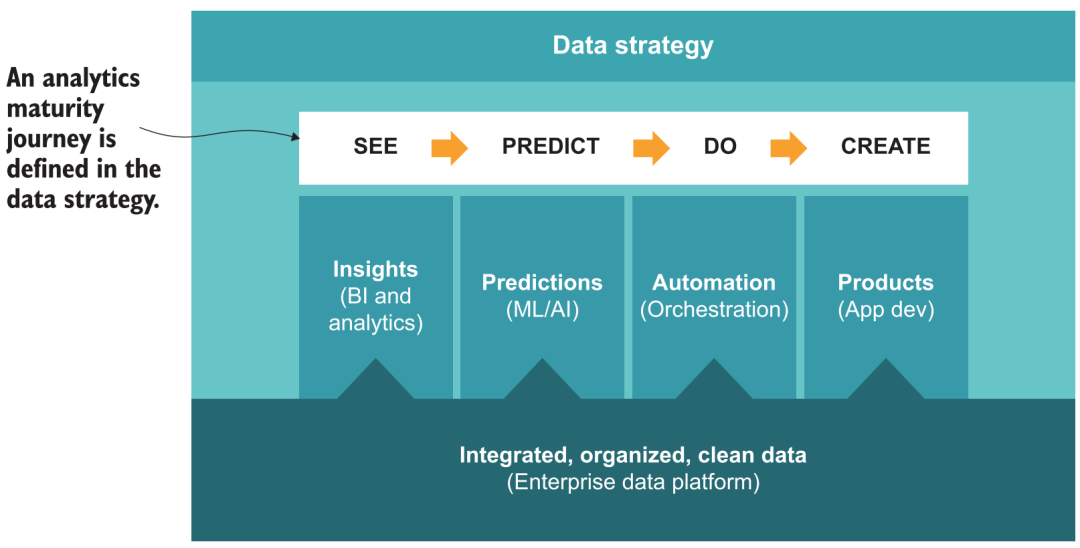
Parcours de maturité de l'analyse des données
10.3 Promotion des utilisateurs
Outre la méthodologie d'évolution au niveau de l'architecture technique, comment faire connaître et promouvoir la plateforme au niveau métier est également un enjeu important. Il y a trop de projets de plateformes de données qui manquent de communication et de compréhension métier approfondies. En l'absence d'un consensus entre les deux parties, des projets complexes sont promus, et la période de construction est extrêmement longue, ce qui finit par aboutir à un échec à mi-parcours. Nous devrions rapidement refléter la valeur de la plate-forme à travers quelques petits projets, renforcer le consensus entre les deux parties, gagner la confiance des utilisateurs et la promouvoir progressivement auprès de départements plus organisationnels ; après avoir obtenu plus d'applications, elle animera également la scène et enrichira la demande, qui à son tour augmentera également Elle peut guider et favoriser la construction et le développement de la plate-forme elle-même, et entrer dans un cercle vertueux. C'est aussi la voie et la méthode de "faire usage commercial" que nous explorons et pratiquons constamment.
À la fin, nous avons mis en place une petite publicité. Chez Guanyuan Data, nous avons une très riche expérience dans le niveau de technologie des produits mentionné ci-dessus, les services aux entreprises et la promotion des entreprises. Grâce aux gammes de produits Universe, Galaxy et Atlas, il peut prendre en charge les plates-formes de données d'entreprise à différents stades de maturité de l'analyse des données, de l'analyse BI + AI et des besoins décisionnels. Pour certains clients leaders de l'industrie, nos produits ont également atteint avec succès le cap des plus de 20 000 analystes actifs et utilisateurs décisionnels de données.Il est concevable qu'une telle entreprise puisse incarner les énormes avantages de l'efficacité et de la qualité de la prise de décision dans le concurrence féroce sur le marché. Les amis intéressés sont les bienvenus pour discuter et échanger ensemble, et rechercher des opportunités de coopération et de co-construction :)
Les références
[1] Composition et construction d'une plateforme d'apprentissage automatique cloud native : https://zhuanlan.zhihu.com/p/383528646
[2] Quelques rapports d'analyse d'a16z : https://future.com/data50/
[3] pile de données moderne : https://www.moderndatastack.xyz/
[4] Système de lac de données dans la plate-forme d'algorithme : https://zhuanlan.zhihu.com/p/400012723
[5] stockage hiérarchisé : https://www.confluent.io/blog/infinite-kafka-storage-in-confluent-platform/
[6] lacFS : https://github.com/treeverse/lakeFS
[7] JuiceFS : https://github.com/juicedata/juicefs
[8] SeaseedFS : https://github.com/chrislusf/seaweedfs
[9] Confluent : https://www.confluent.io/
[10] Upsolver : https://www.upsolver.com/
[11] Matérialiser : https://materialize.com/
[12] Marquez : https://github.com/MarquezProject/marquez
[13] Atlas apache : https://atlas.apache.org/
[14] Amundsen : https://www.amundsen.io/
[15] DataHub : https://datahubproject.io/
[16] Atlan: https://atlan.com/
[17] Alation : https://www.alation.com/
[18] Deequ : https://github.com/awslabs/deequ
[19] Grandes attentes : https://github.com/great-expectations/great_expectations
[20] Monte-Carlo : https://www.montecarlodata.com/
[21] BigEye : https://www.bigeye.com/
[22] Apache Doris : https://doris.apache.org/
[23] Databend : https://databend.rs/
[24] Introduction aux MLOps : https://zhuanlan.zhihu.com/p/357897337
[25] Auth0 : https://auth0.com/
[26] LookML : https://www.looker.com/platform/data-modeling/
[27] Transformer : https://transform.co/
[28] Metlo : https://blog.metlo.com/
[29] DolphinScheduler : https://github.com/apache/dolphinscheduler
[30] Apache NiFi : https://github.com/apache/nifi
[31] OpenRefine : https://github.com/OpenRefine/OpenRefine
[32] dbt : https://www.getdbt.com/
[33] La taxe des non-experts : https://dl.acm.org/doi/10.1145/3530050.3532925
[34] Le chemin vers l'ingénieur principal : stratégie technique : https://zhuanlan.zhihu.com/p/498475916
[35] Méthodologie de la trajectoire d'atterrissage 5A : https://zhuanlan.zhihu.com/p/43515719