Code de référence
ImageBind:GitHub - facebookresearch/ImageBind : ImageBind One Embedding Space pour les lier tous
ImageBind + stable-diffusion-2-1-unclip:GitHub - Zeqiang-Lai/Anything2Image : Générer une image à partir de n'importe quoi avec ImageBind et Stable Diffusion
ImageBind, récemment populaire, apprend un seul espace de représentation partagé en utilisant des données d'appariement d'images de plusieurs types (profondeur, texte, carte thermique, audio, IMU). ImageBind ne nécessite pas de jeux de données où toutes les modalités apparaissent en même temps. Il utilise les propriétés de liaison des images. Tant que l'incorporation de chaque modal est alignée sur l'incorporation de l'image, toutes les modalités peuvent être rapidement alignées.
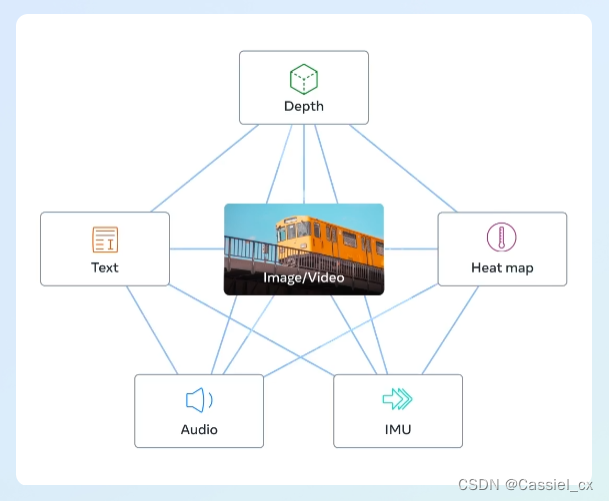
Mais à en juger par le code open source d'ImageBind, l'auteur n'a ouvert que la partie d'encodage (mappage des données de différentes modalités dans l'espace d'intégration aligné) et n'a pas pu implémenter directement des fonctions telles que text2img et audio2img. Afin de réaliser les fonctions ci-dessus, les gros bonnets ont combiné "l' espace latent unifié " fourni par ImageBind avec le décodeur en diffusion stable. Si vous êtes intéressé, vous pouvez rechercher Anything2Image ou BindDiffusion sur Github . Ici, je me réfère au code de ImageBind et Anything2Image, et je reproduis l'audio+img en img, le texte en img et d'autres fonctions. La bibliothèque dépendante de l'opération de code peut faire référence à ImageBind (pip install -r requirements.txt), plus des diffuseurs (pip install diffuseurs).
exemple de code
import torch
from diffusers import StableUnCLIPImg2ImgPipeline
import sys
sys.path.append("..")
from models import data
from models import imagebind_model
from models.imagebind_model import ModalityType
model = imagebind_model.imagebind_huge(pretrained=True).to("cuda").eval()
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16).to("cuda")
with torch.no_grad():
## image
image_path = ["/kaxier01/projects/GPT/ImageBind/assets/image/bird.png"]
embeddings = model.forward({ModalityType.VISION: data.load_and_transform_vision_data(image_path, "cuda")}, normalize=False)
img_embeddings = embeddings[ModalityType.VISION]
## audio
audio_path = ["/kaxier01/projects/GPT/ImageBind/assets/wav/wave.wav"]
embeddings = model.forward({ModalityType.AUDIO: data.load_and_transform_audio_data(audio_path, "cuda")}, normalize=True)
audio_embeddings = embeddings[ModalityType.AUDIO]
embeddings = (img_embeddings + audio_embeddings) / 2
images = pipe(image_embeds=embeddings.half()).images
images[0].save("/kaxier01/projects/GPT/ImageBind/results/bird_wave_audioimg2img.png")Problèmes rencontrés et solutions
Le problème rencontré dans ce domaine est principalement le problème du délai de téléchargement du modèle, la solution est la suivante :
première méthode :
Rendez-vous sur le site officiel ( Hugging Face – The AI community building the future. ) pour rechercher le modèle et le télécharger (il est préférable de télécharger tous les fichiers), comme par exemple



Après le téléchargement, spécifiez simplement le chemin du modèle dans le code, tel que
# 模型路径: "/kaxier01/projects/GPT/ImageBind/checkpoints/stable-diffusion-2-1-unclip"
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained("/kaxier01/projects/GPT/ImageBind/checkpoints/stable-diffusion-2-1-unclip", torch_dtype=torch.float16).to("cuda")Deuxième méthode :
télécharger git-lfs
apt-get update
apt-get install git-lfs
git lfs installAprès le téléchargement et l'installation, vous pouvez utiliser cette commande pour télécharger le modèle, tel que
git lfs clone https://huggingface.co/stabilityai/stable-diffusion-2-1-unclipAffichage des résultats
thermique2img
saisir

sortir

audio+img2img
saisir
Voix (wave.wav) + image

sortir

text2img
saisir
'a photo of an astronaut riding a horse on mars'sortir
