Papier : https://arxiv.org/abs/2303.13508
Page d'accueil : https://dreambooth3d.github.io/
Annuaire d'articles
Aperçu
3. Approche
Configuration du problème.
Invite textuelle T et image du sujet :

Notre objectif est de générer un élément 3D qui capture l'identité (géométrie et apparence) du sujet donné tout en étant fidèle à l'invite de texte.
Nous optimisons les actifs 3D sous la forme de Neural Radiance Fields (NeRF) [28], qui consiste en un réseau MLP M qui encode les champs de radiance dans un volume 3D.
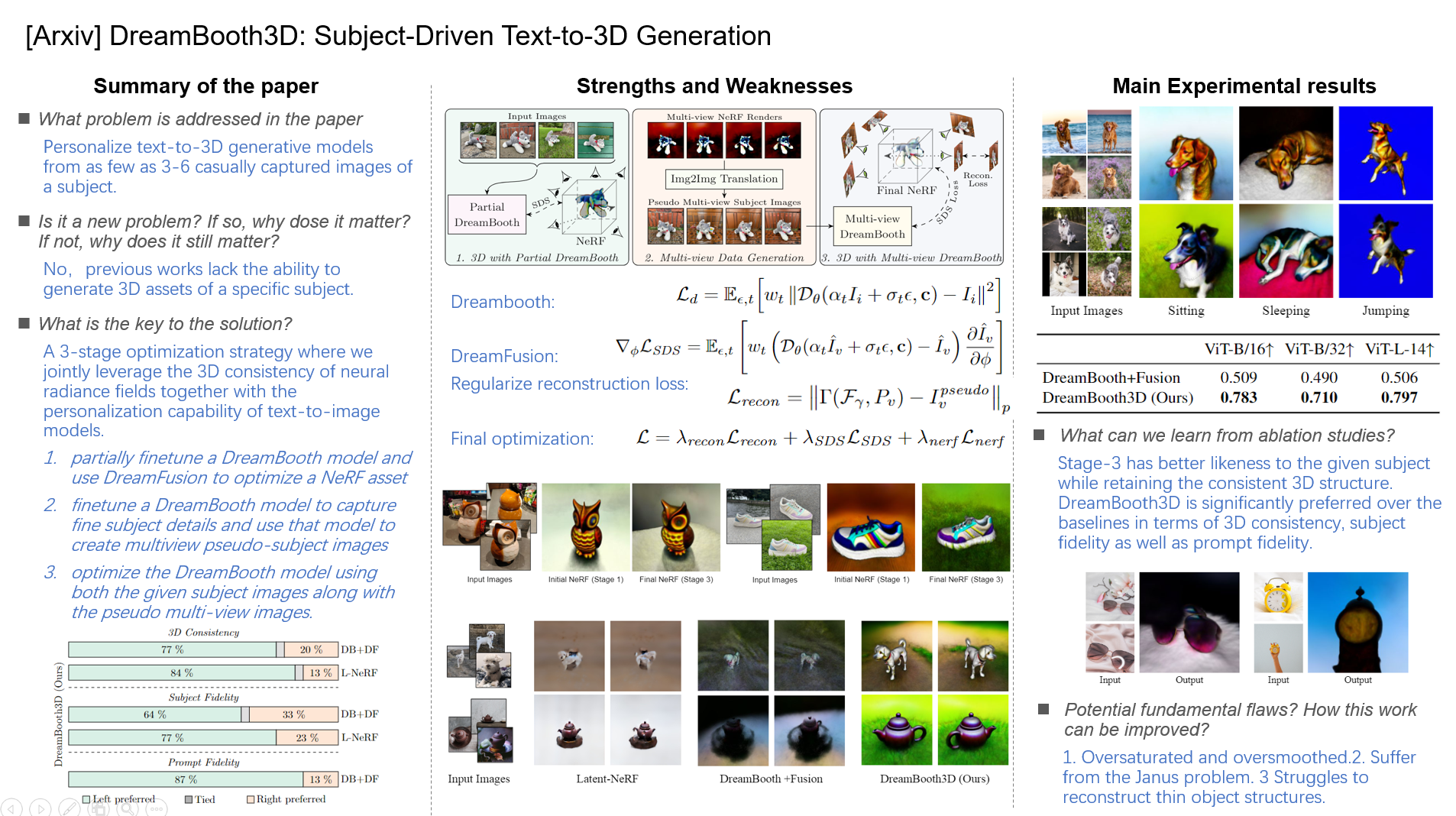
nous utilisons DreamFusion [33] l'optimisation text-to-3D et la personnalisation DreamBooth [38] dans notre framework.
3.1. Préliminaires
Personnalisation DreamBooth T2I.
En bref, DreamBooth utilise la fonction de perte de diffusion suivante pour affiner le modèle T2I :

où t ∼ U[0, 1] désigne le pas de temps dans le processus de diffusion et wt, αt et σt sont les paramètres de programmation correspondants.
DreamFusion
DreamFusion a introduit l'échantillonnage par distillation par score (SDS) qui pousse les versions bruyantes des images rendues vers des états d'énergie plus faibles du modèle de diffusion T2I :

3.2. Échec de Naive Dreambooth + Fusion
Une approche simple pour la génération de texte en 3D axée sur le sujet consiste à personnaliser d'abord un modèle T2I, puis à utiliser le modèle résultant pour l'optimisation du texte en 3D. Par exemple, faire l'optimisation DreamBooth suivie de DreamFusion. que nous appelons DreamBooth+Fusion.
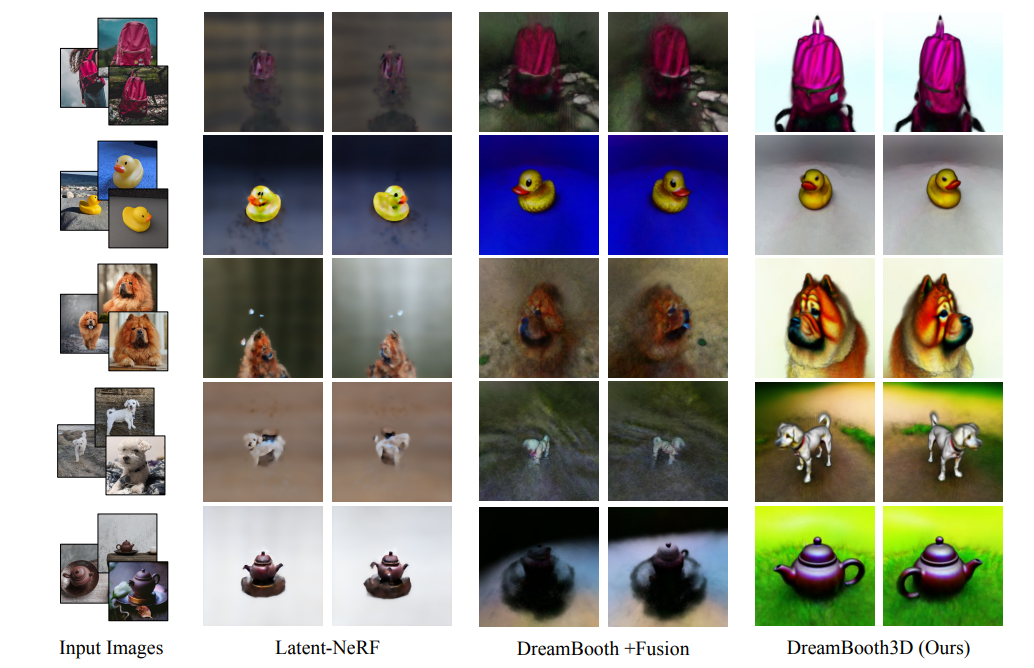
Figure 3 : Résultats visuels sur 5 sujets différents avec deux techniques de base de Latent-NeRF et DreamBooth+Fusion ainsi que celles de notre technique (DreamBooth3D). Les résultats indiquent clairement de meilleurs résultats cohérents en 3D avec notre approche par rapport à l'une ou l'autre des techniques de base. Voir le supplément pour des visualisations et des vidéos supplémentaires.
Un problème clé que nous constatons est que DreamBooth a tendance à suradapter les vues du sujet qui sont présentes dans les vues d'entraînement, ce qui réduit la diversité des points de vue dans les générations d'images.
3.3. Optimisation Dreambooth3D
La figure 2 illustre les 3 étapes de notre approche, que nous décrivons en détail par la suite.

Figure 2 : Présentation de DreamBooth3D. Dans l'étape 1 (à gauche), nous formons d'abord partiellement un DreamBooth et utilisons le modèle résultant pour optimiser le NeRF initial. À l'étape 2 (au milieu), nous rendons des images multi-vues le long de points de vue aléatoires à partir du NeRF initial, puis les traduisons en images de sujet pseudo-multi-vues à l'aide d'un modèle DreamBooth entièrement formé. Dans la dernière étape 3 (à droite), nous affinons davantage le DreamBooth partiel à l'aide d'images multi-vues, puis utilisons le DreamBooth multi-vues résultant pour optimiser l'actif NeRF 3D final en utilisant la perte SDS avec la reconstruction multi-vues perte.
Étape 1 : 3D avec DreamBooth partiel
Nous formons d'abord un modèle DreamBooth personnalisé ˆDθ sur les images de sujet d'entrée telles que celles illustrées à la Fig. 2 (à gauche).
- DreamFusion sur de tels modèles DreamBooth partiellement ajustés peut produire un NeRF 3D plus cohérent.
- utilisez la perte SDS (Eq. 2) pour optimiser un actif NeRF initial pour une invite de texte donnée, comme illustré à la Fig. 2 (à gauche).
- Cependant, le modèle partiel DreamBooth ainsi que l'actif NeRF manquent de ressemblance complète avec le sujet d'entrée.
Étape 2 : Génération de données multi-vues.
nous rendons d'abord plusieurs images le long de points de vue aléatoires {v} à partir de l'actif NeRF initial, ce qui donne les rendus multi-vues, comme illustré à la Fig. 2 (au milieu).
- Nous ajoutons ensuite une quantité fixe de bruit en exécutant le processus de diffusion directe de chaque rendu vers tpseudo , puis exécutons le processus de diffusion inverse pour générer des échantillons à l'aide du modèle DreamBooth entièrement formé ˆDθ comme dans [25].( SDEdit : Image Synthesis and Édition avec des équations différentielles stochastiques )
- Cependant, ces images ne sont pas cohérentes avec plusieurs vues car le processus de diffusion inverse peut ajouter différents détails à différentes vues, nous appelons donc cette collection d'images pseudo images multi-vues.
Étape 3 : NeRF final avec DreamBooth multi-vues.
Les points de vue ainsi que la ressemblance au sujet ne sont qu'approximativement précis en raison de la nature stochastique de la traduction DreamBooth et Img2Img.
Nous utilisons ensuite des images multi-vues générées et des images de sujet d'entrée pour optimiser notre modèle DreamBooth final suivi d'un actif NeRF 3D final.
Nous utilisons ensuite le modèle Dreambooth multi-vues pour optimiser l'actif NeRF 3D à l'aide de la perte DreamFusion SDS (Eq.2).
En particulier, puisque nous connaissons les paramètres de la caméra {Pv } à partir desquels ces images ont été générées, nous régularisons en outre l'entraînement du deuxième NeRF MLP Fγ , avec des paramètres γ avec la perte de reconstruction : le premier terme à droite est la fonction de rendu

qui restitue une image du NeRF Fγ le long du point de vue de la caméra Pv .
La figure 2 (à droite) illustre l'optimisation du NeRF final avec les pertes de reconstruction SDS et multi-vues. L'objectif final d'optimisation de NeRF est donné par :

4. Expériences
4.1. Résultats
Résultats visuels.
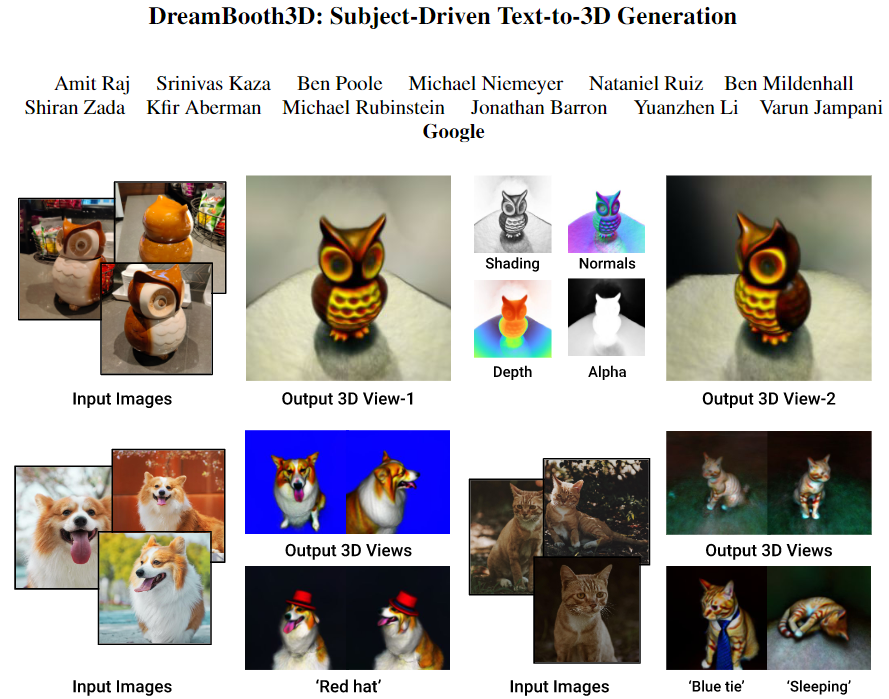
La figure 1 montre des exemples de résultats visuels de notre approche ainsi que différentes variations sémantiques et contextualisations.

Figure 1 : DreamBooth3D est un modèle génératif texte-3D personnalisé qui crée des ressources 3D plausibles d'un sujet spécifique à partir de seulement 3 à 6 images. En haut : sortie 3D et géométrie estimée pour un objet hibou. En bas : notre approche peut générer des variations du sujet 3D dans différents contextes (dormir) ou avec différents accessoires (chapeau ou cravate) en fonction d'une invite textuelle.
Comparaisons quantitatives.
Le tableau 1. démontre clairement des scores significativement plus élevés pour les résultats de DreamBooth3D indiquant une meilleure cohérence 3D et un meilleur alignement des invites de texte de nos résultats.

Tableau 1 : Les comparaisons quantitatives à l'aide de CLIP Rprecision sur les générations DreamBooth+Fusion (ligne de base) et DreamBooth3D indiquent que les rendus de nos sorties de modèle 3D ressemblent plus précisément aux invites textuelles.
NeRF initial vs final.

Figure 4 : Estimations NeRF initiales et finales. Les résultats d'échantillons multi-vues montrent que le NeRF initial obtenu après l'étape 1 n'a qu'une ressemblance partielle avec le sujet donné, tandis que le NeRF final de l'étape 3 de notre pipeline a une meilleure identité de sujet.
Étude d'utilisateur.
Nous menons des études d'utilisateurs par paires comparant DreamBooth3D à des lignes de base afin d'évaluer notre méthode selon trois axes : (1) Fidélité au sujet (2) Cohérence et plausibilité 3D (3) Fidélité à l'invite

Figure 5 : Étude des utilisateurs. Les utilisateurs montrent une préférence significative pour notre DreamBooth3D par rapport à DB+DF et L-NeRF pour la cohérence 3D, la fidélité du sujet et la fidélité des invites.
4.2. Exemples d'applications
Recontextualisation.

Figure 6 : Recontextualisations 3D avec DreamBooth3D. Avec de simples modifications dans l'invite de texte, nous pouvons générer des articulations et des déformations 3D non rigides qui correspondent à la sémantique du texte d'entrée. Les visuels montrent une contextualisation cohérente de différents chiens dans différents contextes d'assise, de sommeil et de saut. Voir le supplément pour les vidéos.
Édition couleur/matière.

Figure 7 : Exemples d'applications. La préservation du sujet de DreamBooth3D et la fidélité à l'invite de texte permettent plusieurs applications telles que l'édition de couleurs/matériaux, l'accessoirisation, la stylisation, etc. DreamBooth3D peut même produire des modèles 3D plausibles à partir d'images de dessins animés irréalistes. Voir le matériel supplémentaire pour les vidéos.
Accessoirisation
La figure 7 montre des exemples de résultats d'accessoirisation sur un sujet de chat, où nous mettons une cravate ou un costume dans la sortie du modèle de chat 3D. De même, on peut penser à d'autres accessoirisations comme mettre un chapeau ou des lunettes de soleil etc.
Stylisation
La figure 7 montre également des exemples de résultats de stylisation, où une chaussure de couleur crème est stylisée en fonction de la couleur et de l'ajout de volants.
Du dessin animé à la 3D.
La figure 7 montre un exemple de résultat où le modèle 3D résultant pour le personnage de dessin animé rouge est plausible, même si toutes les images montrent le dessin animé uniquement de face. Reportez-vous au matériel supplémentaire pour des résultats plus qualitatifs sur différentes applications.
4.3. Limites
- Premièrement, les représentations 3D optimisées sont parfois sursaturées et trop lissées
- les représentations 3D optimisées peuvent parfois souffrir du problème de Janus consistant à apparaître face à face à partir de plusieurs points de vue incohérents si les images d'entrée ne contiennent aucune variation de point de vue.
- notre modèle a parfois du mal à reconstruire des structures d'objets minces comme des lunettes de soleil

Figure 8 : Exemples de cas d'échec. Nous observons que DreamBooth3D échoue souvent à reconstruire des structures d'objets minces comme des lunettes de soleil, et échoue parfois à reconstruire des objets avec une variation de vue insuffisante dans les images d'entrée.
5. Conclusion
Dans cet article, nous avons proposé DreamBooth3D , une méthode de génération de texte en 3D axée sur le sujet. Étant donné quelques (3-6) captures d'images occasionnelles d'un sujet (sans aucune information supplémentaire telle que la pose de la caméra), nous générons des ressources 3D spécifiques au sujet qui adhèrent également à la contextualisation fournie dans les invites de texte d'entrée (par exemple, dormir, saut, rouge, etc.). Nos expériences approfondies sur l'ensemble de données DreamBooth [38] ont montré que notre méthode peut générer des actifs 3D réalistes avec une grande ressemblance avec un sujet donné tout en respectant les contextes présents dans les invites de texte d'entrée. Notre méthode surpasse plusieurs lignes de base dans les évaluations quantitatives et qualitatives. À l'avenir, nous prévoyons de continuer à améliorer le photoréalisme et la contrôlabilité de la génération 3D axée sur le sujet.