Ceci est une revue de l'extraction de règles d'association, et j'enregistre également mes propres notes d'expérience
Annuaire d'articles
Résumé
L'exploration de règles d'association consiste à rechercher la relation entre les attributs dans la base de données d'objets. L'ensemble du processus de découverte de règles est très complexe, y compris les techniques de prétraitement, les étapes d'exploration de règles et le post-traitement, où la visualisation est effectuée. La visualisation des règles d'association découvertes est une étape importante dans l'ensemble du pipeline d'exploration de règles d'association pour améliorer la compréhension des utilisateurs des résultats d'exploration de règles.
Au cours des dernières décennies, plusieurs méthodes d'extraction et de visualisation de règles d'association ont été développées. Cet article vise à construire une revue de la littérature qui recense les principales techniques publiées dans la littérature à comité de lecture, examine les principales caractéristiques de chaque méthode, et présente les principales applications dans ce domaine. L'identification des étapes futures dans ce domaine de recherche est un autre objectif de cet article de synthèse.
1. Introduction
L'arrière-plan est relativement éloigné et l'algorithme bien connu est Apriori, qui est comme une pierre angulaire. Généralement, il est divisé en trois étapes : le prétraitement, l'exploration des règles d'association et le post-traitement. Cet article met en évidence les avantages de la visualisation. (ARM signifie association rule mining, Association Rule Mining)
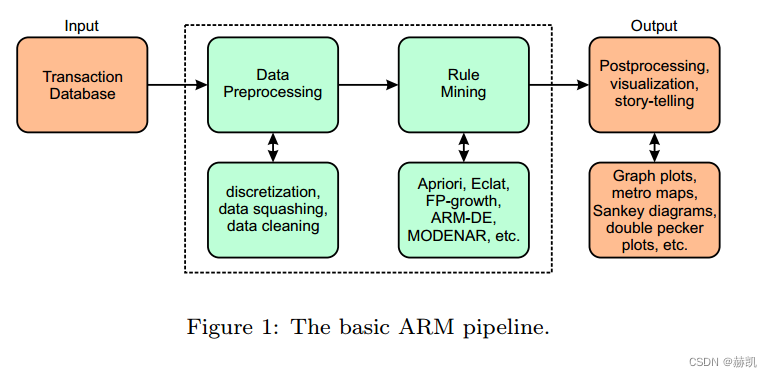
- L'évolution des méthodes de visualisation ARM est présentée.
- Les caractéristiques de chaque méthode sont définies.
- Les avantages/inconvénients de chaque méthode sont décrits.
- Un exemple est présenté pour chaque méthode étudiée.
- Résume les modèles interprétés visualisés à l'aide d'ARM.
2. L'extraction de règles d'association est une petite chose
Pour définir certaines formules mathématiques pour l'exploration d'associations de règles, il existe une base de données de choses, la colonne est l'index des choses et la ligne horizontale est l'accumulation de différentes choses, qui est notre base de données commune. L'exploration de règles consiste à examiner la relation entre différents indicateurs de choses.
X ⇒ Y, c'est la règle d'association, l'ensemble d'indicateurs X peut être dérivé de l'ensemble d'indicateurs Y, il n'y a pas d'intersection entre eux, et ils appartiennent tous aux indicateurs de la base de données.
n représente le nombre d'occurrences des indicateurs suivants, et N représente le nombre total d'éléments, c'est-à-dire le nombre de lignes dans la base de données.
| officiel | nom | interprétation des probabilités |
|---|---|---|
| supp ( X ⇒ Y ) = n ( X ⋂ Y ) N supp(X⇒Y)=\frac{n(X\bigcap Y)}{N}s u pp ( X⇒Y )=Nn ( X⋂Y ) | Soutien | La probabilité que cette règle se produise |
| conf ( X ⇒ Y ) = n ( X ⋂ Y ) n ( X ) conf(X⇒Y)=\frac{n(X\bigcap Y)}{n(X)}con f ( X _⇒Y )=n ( X )n ( X⋂Y ) | Confiance | Dans le cas où la règle X apparaît, la probabilité que l'ensemble de règles Y apparaisse. c'est-à-dire la probabilité conditionnelle |
| lift ( X ⇒ Y ) = supp ( X ⋂ Y ) supp ( X ) × supp ( Y ) lift(X⇒Y)=\frac{supp(X\bigcap Y)}{supp(X)\times supp(Y )}l je f t ( X⇒Y )=s u pp ( X ) × s u pp ( Y )s u pp ( X⋂Y ) | ascenseur | La mesure dans laquelle l'occurrence de la règle X augmente la probabilité d'occurrence de la règle Y |
| conv ( X ⇒ Y ) = 1 − supp ( Y ) 1 − conf ( X ⇒ Y ) conv(X⇒Y)=\frac{1-supp(Y)}{1-conf(X⇒Y)}co n v ( X⇒Y )=1 − co n f ( X ⇒ Y )1 − s u pp ( Y ) | Degré d'erreur | Déterminer la probabilité que cette règle soit fausse, |
On définit généralement que supp ( X ⇒ Y ) ≥ S min supp(X ⇒ Y ) ≥ Smins u pp ( X⇒Y )≥S min ,conf ( X ⇒ Y ) ≥ C min conf (X ⇒ Y ) ≥ C mincon f ( X _⇒Y )≥C min oùS min SminS min ,C min C minC min est le seuil que nous avons fixé artificiellement, et les règles d'association dépassant ce seuil seront considérées à l'étape suivante.
Le degré de portance indique le rapport de la probabilité de contenir Y sous la condition de contenir X à la probabilité de ne regarder que Y. L'ascenseur reflète la corrélation entre X et Y dans les règles d'association. L'ascenseur > 1 et plus indique une corrélation positive plus élevée, l'ascenseur < 1 et moins indique une corrélation négative plus élevée et l'ascenseur = 1 indique l'absence de corrélation. Généralement, lorsque le degré de promotion est supérieur à 3 en data mining, on admet que les règles d'association minées sont précieuses.
PS Après avoir lu d'autres informations, les méthodes de jugement couramment utilisées incluent la mesure KULC et le rapport de déséquilibre.
KULC est la moyenne de deux niveaux de confiance : 0,5 ∗ ( conf ( X ⇒ Y ) + conf ( Y ⇒ X ) ) 0,5*(conf(X⇒Y)+conf(Y⇒X))0,5∗( co n f ( X⇒Y )+co n f ( O⇒X ))
IR不平衡比例 :IR ( X , Y ) = ∣ supp ( X ) − supp ( Y ) ∣ supp ( X ) + supp ( Y ) − supp ( X ⇒ Y ) IR(X, Y) =\ frac{|supp(X)-supp(Y)|}{supp(X)+supp(Y)-supp(X⇒Y) }Je R ( X ,Y )=s u pp ( X ) + s u pp ( Y ) - s u pp ( X ⇒ Y )∣ s u pp ( X ) − s u pp ( Y ) ∣
Plus la métrique KULC est grande, mieux c'est, et plus le rapport de déséquilibre IR est petit, mieux c'est. La combinaison des deux peut trouver des règles d'association fortes mieux que d'utiliser Lift seul.
2.1 Extraction de règles d'association numériques
On peut également voir à partir du résumé ci-dessus que cela ne peut que discrétiser les données, avec ou sans elles. Mais dans la vraie vie, il y a des nombres continus, et un indicateur peut aller de 0 à 100. Sortez avec une exploration de règles d'association numérique étendue (NARM, Numerical Association Rule Mining).
Dans NARM, chaque attribut numérique est délimité par un intervalle de valeurs possibles, déterminé par les limites supérieure et inférieure de l'attribut. Plus l'intervalle est large, plus les règles d'association sont minées. Inversement, plus l'intervalle est étroit, plus les relations spécifiques entre les attributs peuvent être découvertes. L'introduction d'un intervalle de valeurs réalisables a deux effets principaux : il transforme un espace de recherche discret existant en un espace continu, et il correspond mieux au problème d'intérêt. Les règles d'association minées peuvent être évaluées selon plusieurs critères, tels que le soutien et la confiance. Cependant, pour NARM, des mesures supplémentaires doivent être envisagées afin d'évaluer correctement l'ensemble miné de règles d'association.
2.2 Exploration de règles d'association de séries temporelles
TS-ARM est un nouveau paradigme qui traite les bases de données transactionnelles comme des données de séries chronologiques. La définition formelle du problème NARM doit être redéfinie à la lumière de cela. Dans TS-ARM, une règle d'association est définie comme une formule :
X ( ∆ t ) ⇒ Y ( ∆ t ) X(∆t)⇒ Y(∆t)X ( ∆t ) _⇒Y ( ∆ t )
∆ t = [ t 1 , t 2 ] ∆ t=[t_1, t_2]∆t _=[ t1,t2] , oùt 1 t_1t1est l'heure de début, t 2 t_2t2Est le temps de fin, je peux le comprendre comme X ( ∆ t ), Y ( ∆ t ) X(∆t), Y(∆t)X ( ∆ t ) , Y ( ∆ t ) sont la séquence de choses représentées dans la période de temps.
conft ( X ( ∆ t ) ⇒ Y ( ∆ t ) ) = n ( X ( ∆ t ) ∩ Y ( ∆ t ) ) n ( X ( ∆ t ) ) conft(X(∆t) ⇒ Y (∆t) ) = \frac{n(X(∆t) ∩ Y (∆t))}{n(X(∆t))}co n f t ( X ( ∆ t )⇒Y ( ∆ t ))=n ( X ( ∆ t ))n ( X ( ∆ t ) ∩ Y ( ∆ t ) )Confiance
suppt ( X ( ∆ t ) ⇒ Y ( ∆ t ) ) = n ( X ( ∆ t ) ∩ Y ( ∆ t ) ) N ( ∆ t ) suppt(X(∆t) ⇒ Y (∆t)) =\ frac{ n(X(∆t) ∩ Y (∆t))}{N(∆t)}s u ppt ( X ( ∆ t )⇒Y ( ∆ t ))=N ( ∆ t )n ( X ( ∆ t ) ∩ Y ( ∆ t ) )Soutien
Les deux tableaux de formules ci-dessus montrent la confiance et le soutien dans la même période, c'est-à-dire que les données qu'ils contiennent ont été modifiées.
3. Visualisation de l'extraction de règles d'association
...
La prochaine chose est que cet article est d'étudier quelle visualisation est la plus appropriée pour différents problèmes, omis

référence
https://cs.nyu.edu/~jcf/classes/g22.3033-002/slides/session6/MiningFrequentPatternsAssociationAndCorrelations.pdf