écrit devant
Enregistrez les points principaux dans "Modern C++ Tutorial".
Le C++ moderne fait référence aux fonctionnalités grammaticales après C++11. Sauf indication contraire, les fonctionnalités grammaticales suivantes ne peuvent être utilisées qu'après C++11.
1. Amélioration de la convivialité de la langue
1. Constantes
1.1 nullptr
-
effet:
- Au lieu d'attribuer
NULLun pointeur nul ;
- Au lieu d'attribuer
-
utiliser:
char *a = nullptr;
- raison:
- Les compilateurs définissent généralement
NULL = (void*)0soitNULL = 0; - Mais puisque C++ n'autorise pas
void *la conversion implicite vers d'autres types de pointeurs, il doit être explicitement converti ; - Par conséquent, lorsque la fonction reçoit des paramètres, la fonction entrante
NULLne sait pas s'il s'agit d'un appelintouxxx *d'une fonction surchargée du type ; nullptrUtilisé pour faire la distinction entre les pointeurs nuls et 0, et obsolèteNULL;nullptroccupe levoid*même espace que- Avis:
NULLLes valeurs de et\0sont toutes les deux 0, leur inversion peut donc être convertie entruevaleurs booléennes ;- Mais
nullptrla valeur de n'est pas 0, donc son inversion ne peut pas être convertie entrue, et elle doit êtreptr == nullptrutilisée pour juger si le pointeur est vide ;
- Les compilateurs définissent généralement
1.2 constexpr
-
effet:
- Laisser la fonction explicitement déclarée par l'utilisateur ou le constructeur d'objet devenir une expression constante au moment de la compilation ;
- C'est-à-dire que la valeur de retour de la fonction peut être utilisée comme constante ;
-
utiliser:
constexprObjet déclaré :- doit être initialisé avec une expression constante (
constexprune expression consistant en une constante ou);
- doit être initialisé avec une expression constante (
constexprFonction déclarée :- Si vous souhaitez passer un paramètre, il doit s'agir d'une expression constante ;
- La valeur de retour doit être une expression constante ;
- Les déclarations autres que
usingles directives,typedefles déclarations,static_assertles affirmations etreturnles déclarations ne doivent pas apparaître ; - À partir de C++14 , les variables locales, les boucles et les branches sont disponibles ;
// 对象构造函数
constexpr int a = 1 + 2 + 3;
// 函数
constexpr int fibonacci(const int n) {
return n==1 || n==2 ? 1 : fibonacci(n-1) + fibonacci(n-2);
}
int arr_1[a];
int arr_2[fibonacci(5)];
2. Les variables et leur initialisation
2.1 Les variables temporaires peuvent être déclarées dans l'instruction conditionnelle de if/switch
- utiliser:
- Après C++17, les variables temporaires peuvent être déclarées dans l'instruction conditionnelle de if/switch ;
if(
const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end()
)
{
*itr = 4;
}
[2.2] Les listes d'initialisation peuvent être utilisées dans les fonctions membres
-
effet:
class object = {}Autoriser l'initialisation des classes personnalisées dans le formulaire qui peut également être utilisé ;
-
utiliser:
- Utilisé dans les paramètres formels des fonctions membres
std::initializer_list<参数类型> list; - Peut être utilisé dans les constructeurs ou dans les fonctions membres générales ;
- Utilisé dans les paramètres formels des fonctions membres
class MagicFoo {
public:
std::vector<int> vec;
// 构造函数中使用
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
// 一般的成员函数中使用
void foo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
};
MagicFoo magicFoo = {
1, 2, 3, 4, 5};
magicFoo.foo({
6,7,8,9});
2.3 Peut se lier automatiquement à la structure de type std :: tuple
-
effet:
- Décompressez et liez automatiquement le type std::tuple à plusieurs variables sans connaître le type de chaque variable du package ;
-
utiliser:
- Après C++17 , il peut être automatiquement décompressé et affecté à plusieurs variables ;
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, "456");
}
// 自动将int、double和string的值绑定到x、y和z上
auto [x, y, z] = f();
[3] Déduction de type
3.1 automatique
-
effet:
- Détermine automatiquement le type de la valeur de gauche de l'égalité en fonction de la valeur de droite de l'égalité ;
-
utiliser:
- Après C++20 , il peut être utilisé comme paramètre formel d'une fonction ;
- Les types de tableau ne peuvent pas être déduits ;
- ne peut pas être utilisé comme argument de paramètre de modèle ;
- Le type de valeur de retour peut
decltypeêtre déduit avec collocation, et peut être utilisé sans collocation après C++14 ;decltype
auto i = 5; // i被推导为int
auto arr = new auto(10); // arr被推导为int *
auto it = vec.begin(); // it被推导为容器对应的迭代器类型
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
// C++14之后
template<typename T, typename U>
auto add2(T x, U y){
return x + y;
}
3.2 decltype
-
effet:
- obtenir le type d'une expression ;
-
utiliser:
decltype(表达式);- Peut être utilisé
decltype(auto)comme type de retour d'une fonction, il peut déduire automatiquement le type de retour de la fonction de renvoi ou de la fonction d'encapsulation, c'est-à-dire le cas d'appel d'autres fonctions comme type de retour ;
auto x = 1;
auto y = 2;
// 用x+y表达式的类型定义z
decltype(x+y) z;
// 比较x和int类型是否相同
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
// 用decltype(auto)自动推导封装的返回类型
std::string look_up_a_string_1() {
return lookup1();
}
decltype(auto) look_up_a_string_1() {
return lookup1();
}
3.3 std :: is_same
-
effet:
- Détermine si deux types sont égaux ;
- renvoie le type booléen ;
-
utiliser:
// 比较x和int类型是否相同
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
4. Flux de contrôle
4.1 si constexpr
-
effet:
- La valeur booléenne de la condition if est calculée lors de la compilation ;
- Cela peut accélérer la vitesse du jugement conditionnel;
-
utiliser:
// 注意泛型的实例化在编译过程中就已经实现了
template<typename T>
auto print_type_info(const T& t) {
if constexpr (std::is_integral<T>::value) {
return t + 1;
} else {
return t + 0.001;
}
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
/* 编译时的代码为:
int print_type_info(const int& t) {
return t + 1;
}
double print_type_info(const double& t) {
return t + 0.001;
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
*/
[4.2] Intervalle d'itération
-
effet:
- L'objet de classe qui implémente l'itérateur peut être complètement parcouru sans donner explicitement la position de début et la position de fin de la boucle for ;
-
utiliser:
for(auto element: 实现了迭代器的对象), alors dans la boucle vous pouvezelementlire chaque élément de l'objet avec ;for(auto &element: 实现了迭代器的对象), puis chaque élément de l'objet peut êtreelementlu et écrit dans la boucle ;- Généralement utilisé pour les conteneurs de base autres que les adaptateurs , car ces conteneurs implémentent des itérateurs ;
for (auto element : vec) {
std::cout << element << std::endl; // read only
}
for (auto &element : vec) {
element += 1; // read and write
}
5. Modèle
5.1 Modèles externes
-
effet:
- Évitez l'instanciation implicite automatique par le compilateur chaque fois qu'il rencontre un objet instancié du modèle, car cela entraînera l'instanciation répétée du modèle sur le même type ;
- L'instanciation explicite peut spécifier explicitement où le modèle du type est instancié ;
- La raison pour laquelle on l'appelle un modèle externe est qu'il est très similaire à l'utilisation de variables externes. L'ajouter
externsignifie qu'il est instancié ailleurs, et il est utilisé dans ce fichier mais pas instancié à plusieurs reprises ;
-
utiliser:
- (1) Instanciez dans le fichier de sortie compilé correspondant à ce code source :
- Les modèles de classe sont
template class 模板类名<实例化类型>instanciés explicitement avec ; - Les modèles de fonction sont
template 函数返回值类型 模板函数名<实例化类型>(参数类型)instanciés explicitement avec ;
- Les modèles de classe sont
- (2) Instanciez dans le fichier de sortie compilé correspondant aux autres codes sources, et utilisez dans ce fichier :
- Les modèles de classe sont
extern template class 模板类名<实例化类型>instanciés explicitement avec ; - Les modèles de fonction sont
extern template 函数返回值类型 模板函数名<实例化类型>(参数类型)instanciés explicitement avec ;
- Les modèles de classe sont
- (1) Instanciez dans le fichier de sortie compilé correspondant à ce code source :
// 在本编译文件中实例化模板
template class std::vector<bool>;
template int add<int>(int t1, int t2);
// 不在该当前编译文件中实例化模板
extern template class std::vector<double>;
extern template int add<int>(int t1, int t2);
5.2 Instanciation de modèles imbriqués
-
effet:
- Possibilité d' instancier des modèles avec des modèles instanciés en tant que types ;
-
utiliser:
std::vector<std::vector<int>> matrix;
- raison:
- Dans les compilateurs C++ traditionnels, deux crochets droits consécutifs
>>sont considérés comme un opérateur de décalage vers la droite ; - Par conséquent, il ne peut pas être compilé avec succès ;
- Dans les compilateurs C++ traditionnels, deux crochets droits consécutifs
5.3 l'utilisation définit les alias de type de modèle
-
effet:
- En usage traditionnel, ajoutez la fonction de définition d'alias pour les types et les templates, qui peuvent être remplacés
typedef;
- En usage traditionnel, ajoutez la fonction de définition d'alias pour les types et les templates, qui peuvent être remplacés
-
utiliser:
- (1) Utilisez
using namespace 命名空间名称l'espace de noms d'importation (C++ traditionnel) ; - (2) Utilisé
using 基类::基类成员dans les sous-classes pour modifier les autorisations des membres de la classe de base référencés ; - (3) Utiliser
using 别名 = 类型或者模板un alias désigné ;
- (1) Utilisez
// 命名空间
using namespace std;
using namespace std::vector;
// 在子类中改变基类成员的权限
class Base{
protected:
int member;
};
class Derived: private Base {
// 虽然是私有继承
public:
using Base::member; // 但用using后member成为了子类的public成员
}
// 指定普通类型别名
using ULL = unsigned long long; //typedef unsigned long long ULL;
// 指定函数类型别名
using func = void(*)(int, int); //typedef void(*func)(int, int);
// 指定类成员函数类型别名
using handler_t = void(ProcessPool::*)(int);
// 指定模板别名
template <typename T>
using mapInt = std::map<int, T>;
mapInt<bool> bmap;
- raison:
typedefLes alias ne peuvent pas être définis pour les modèles, car les modèles ne sont pas des types, mais sont utilisés pour générer des types ;- De plus,
typedefla méthode d'écriture lors de la définition de l'alias du pointeur de fonction est très unique et la forme n'est pas régulière ; usingpeut être complètementtypedefremplacé par
[5.4] Gabarits variadiques
-
effet:
- Pas besoin de donner explicitement tous les paramètres du modèle ;
-
utiliser:
sizeof()Il peut être utilisé avec la récursivité et des fonctions pour réaliser le déballage des paramètres de modèle ;- référence:
template <typename... TS>
void magic(Ts... args) {
// 输出参数的个数
std::cout << sizeof...(args) << std::endl;
}
// 1. 用递归实现模板参数的拆包,终止函数是一个参数的函数
// 这样传入的可变参数最少是1个
template<typename T0>
void printf1(T0 value) {
// 仅一个参数
std::cout << value << std::endl;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
// 函数重载,多个参数
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// 2. 用递归实现模板参数的拆包,终止函数是无模板且无参数的函数
// 这样传入的可变参数可以是0个
void printf1() {
// 无参数
return;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
// 函数重载,多个参数
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// 3. 用逗号表达式实现模板参数的拆包
// 但这种方式只适用于各个参数的处理方式相同的情况,使用的范围比较局限
template<typename T>
void printf1(T value) {
std::cout << value << std::endl;
}
template<typename... Ts>
void printf1(Ts... args) {
// 使用std::initializer_list
int arr[] = {
(printf1(args), 0)... };
// 等价于用下面的方式
// std::initializer_list<int> {(printf1(args), 0)...};
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// C++17后可以这样实现拆包
template<typename T0, typename... T>
void printf2(T0 t0, T... t) {
// 一个或者多个参数
std::cout << t0 << std::endl;
if constexpr (sizeof...(t) > 0) printf2(t...);
}
5.5 Utilisation de littéraux comme paramètres de modèle
-
effet:
- En plus d'utiliser des types comme paramètres de modèle, vous pouvez également utiliser des littéraux comme paramètres de modèle ;
- Les littéraux peuvent être considérés comme des constantes définies sans symboles de variables, telles que des constantes, des chaînes, etc. ;
-
utiliser:
template <typename T, int BufSize>
class buffer_t {
public:
T& alloc();
void free(T& item);
private:
T data[BufSize];
}
buffer_t<int, 100> buf; // 100 作为模板参数
5.6 Modèles communs
-
(1)
std::is_same:- Comparez si les deux types sont identiques;
- Référence du principe d'implémentation : c++11 std::is_same analyse du code source ;
-
(2)
std::decay:- Pour dégénérer des types en types primitifs, vous pouvez :
- supprimer
constet les références de valeur gauche et droite, - dégénérer le nom de la fonction ou le nom du tableau en pointeur de fonction ;
- supprimer
- Référence du principe d'implémentation : c++11 std::decay analyse du code source ;
- Pour dégénérer des types en types primitifs, vous pouvez :
-
(3)
std::enable_if:- Cela équivaut à l'utilisation de if, qui est utilisé pour vérifier si le type peut être utilisé ;
- Référence du principe d'implémentation : Plusieurs utilisations de std::enable_if ;
// 比较类型1是否和类型2相同,如果是,value=true,反之,value=false
std::is_same<类型1, 类型2>::value
// 获得类型的退化类型(基本类型)
std::decay<类型>::type
// 如果布尔值=true,则type=类型,否则编译出错(类型默认为void)
std::enable_if<布尔值, 类型>::type
6. Orienté objet
6.1 Déléguer les constructeurs
-
effet:
- Vous pouvez appeler un autre constructeur dans un constructeur de la classe actuelle ;
-
utiliser:
- L'utilisation est similaire à l'appel du constructeur de la classe parente ;
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() {
// 委托Base() 构造函数
value2 = value;
}
};
6.2 Construction d'héritage
-
effet:
- Hériter directement du constructeur de la classe parent dans la sous-classe, de sorte qu'il n'est pas nécessaire de réécrire le constructeur de la sous-classe ;
-
utiliser:
usingImplémenté par mots-clés ;
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() {
// 委托Base() 构造函数
value2 = value;
}
};
class Subclass : public Base {
public:
using Base::Base; // 继承构造
};
6.3 Remplacer et finaliser la surcharge de fonctions virtuelles explicites
-
effet:
- La fonction pour éviter la surcharge n'est pas une fonction virtuelle de la classe de base ;
- Empêcher les sous-classes de remplacer les fonctions virtuelles surchargées par la classe actuelle ;
-
utiliser:
- Utilisez
overridepour vous assurer que la surcharge actuelle est la fonction virtuelle de la classe de base ; - Utilisez
finalpour vous assurer que la sous-classe n'écrasera pas la fonction virtuelle surchargée par la classe actuelle, ou assurez-vous que la sous-classe ne sera pas dérivée à nouveau ;
- Utilisez
struct Base {
virtual void foo(int);
};
struct SubClass: Base {
virtual void foo(int) override; // 合法
//virtual void foo(float) override; // 非法, 父类没有此虚函数
};
struct Base {
virtual void foo() final;
};
struct SubClass1 final: Base {
}; // 合法
struct SubClass2 : SubClass1 {
}; // 非法, SubClass1 已final
struct SubClass3: Base {
void foo(); // 非法, foo 已final
};
6.4 Utilisation explicite ou désactivation des fonctions par défaut
-
effet:
- Utiliser ou désactiver explicitement les fonctions par défaut ;
-
utiliser:
函数定义 = defaultpuis utilisez explicitement la fonction par défaut ;函数定义 = deletepuis désactivez explicitement la fonction par défaut ;
class Magic {
public:
Magic() = default; // 显式声明使用编译器生成的构造
Magic& operator=(const Magic&) = delete; // 显式声明拒绝编译器生成构造
Magic(int magic_number);
}
- raison:
- C++ génère un constructeur par défaut, un constructeur de copie, un opérateur d'affectation surchargé, un destructeur, un nouvel opérateur et un opérateur de suppression par défaut ;
- Mais parfois, il est nécessaire d'utiliser explicitement ou d'interdire l'utilisation de ces fonctions générées par défaut au lieu de donner le contrôle au compilateur ;
6.5 Énumérations fortement typées
-
effet:
- Laissez les types d'énumération être plus que de simples
inttypes ;
- Laissez les types d'énumération être plus que de simples
-
utiliser:
- En
enum class 枚举类名: 类型 {};définissant une classe d'énumération, vous pouvez spécifier le type de la classe d'énumération ; - Pour l'utilisation des types d'énumération traditionnels, veuillez vous référer à : Explication détaillée du type d'énumération C++ ;
- En
// 传统C++枚举类型
enum color_set {
red, blue, green};
color_set color1;
color1 = red;
color_set color2 = color1;
int i = color1; // 相当于int i = 0;
//color1 = 1; // 不允许将int赋值给enum
cout << color1; // 相当于cout << int(0);
//cin >> color1; // 不允许输入
// 强类型枚举
enum class color_set1: unsigned int {
red, blue, green};
enum class color_set2: int {
red, blue, green};
color_set1 color1 = red;
color_set2 color2 = red;
//color1 == color2 // 非法
//int i = color1; // 非法
//color1 == 0 // 非法
- raison:
- Les énumérations C++ traditionnelles sont en fait
intdes types ; - Mais
intà la différence de la variable d'énumération, la valeur de la variable d'énumération est limitée, déterminée par le nombre d'identifiants lorsqu'elle est définie ; - Étant donné que la comparaison de valeurs de différents types d'énumération est en fait convertie en une comparaison d'entiers, elle n'est pas sécurisée ;
- Les énumérations C++ traditionnelles sont en fait
2. Renforcement du runtime du langage
[1] Expression lambda
-
effet:
- Fournit la fonctionnalité des fonctions anonymes ;
- Autrement dit, une fonction est définie, mais elle n'a pas besoin d'être nommée en tant que fonction externe, elle peut être considérée comme un objet fonction ;
- Renvoie un objet fonction plutôt qu'un pointeur de fonction ;
-
principe de fonctionnement:
- Générer un objet anonyme d'une classe anonyme ;
- Puis surchargez
operator()l'opérateur ;
-
utiliser:
- Les expressions sont
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 { // 函数体 }, y compris :- Liste de capture : capturez des variables en dehors de la fonction dans la fonction, ce qui équivaut à passer des paramètres ;
- Capture de valeur :
[外部变量名], copie une copie d'une variable externe dans la fonction ; - Capture de référence :
[&外部变量名], passez la référence de la variable externe dans la fonction ; - Capture implicite :
[&]alternativement , laisser le compilateur déduire automatiquement la capture[=]requise par référence ou par valeur ; - Après C++14, il est permis de capturer des rvalues, c'est-à-dire des valeurs d'expression, des valeurs de retour de fonction, etc. ;
- Capture de valeur :
- Liste de paramètres : les variables de paramètre que l'appelant doit transmettre ;
- mutable : la variable de capture de valeur entrante peut être modifiée à l'intérieur de la fonction, mais n'a aucun effet sur la valeur en dehors de la fonction ;
- type de retour : le type de valeur de retour de la fonction ;
- Liste de capture : capturez des variables en dehors de la fonction dans la fonction, ce qui équivaut à passer des paramètres ;
- scènes à utiliser :
- Passez la fonction d'algorithme dans STL en tant que paramètre de pointeur de fonction ;
- En tant que fonction qui implémente une fonction simple ;
- Vous pouvez vous référer au blog : Notes "Compréhension approfondie du C++11" - fonction lambda ;
- Les expressions sont
// 和STL算法库中的函数搭配使用
sort(testdata.begin(), testdata.end(), [](int a, int b){
return a > b; });
for_each(a, a+4, [=](int x) {
cout << x << " "; });
auto pos = find_if(coll.cbegin(), coll.cend(), [=](int i) {
return i > x && i < y; });
vec_data.erase(std::remove_if(vec.date.begin(), vec_data.end(), [](int i) {
return n < x;}), vec_data.end());
// C++14后,可以在参数列表中使用auto
auto add = [](auto x, auto y) {
return x + y;
};
cout << add(1, 4) << endl;
[2]. Enveloppe d'objet de fonction
2.1 std :: fonction
-
effet:
- Équivalent à un conteneur de fonctions, les fonctions et les pointeurs de fonction peuvent être traités comme des objets ;
- est de type sûr ;
-
utiliser:
#include <functional>;std::function<函数返回类型(函数参数类型)> 容器名 = 函数名或者lambda表达式;
#include <functional>
int foo(int para) {
return para;
}
// 封装函数foo
std::function<int(int)> func = foo;
int important = 10;
// 封装lambda表达式
std::function<int(int)> func2 = [&](int value) -> int {
return 1+value+important;
};
std::cout << func(10) << std::endl;
std::cout << func2(10) << std::endl;
2.2 std :: lier
-
effet:
- Utilisé pour lier des paramètres fixes à des fonctions existantes afin de générer de nouvelles fonctions avec moins de paramètres ;
- Cela revient à modifier la liste des paramètres d'une fonction existante ;
-
utiliser:
#include <functional>;- Le paramètre passant de la fonction générée par std::bind est la valeur passant par défaut ;
- Vous pouvez vous référer au billet de blog : std::bind of c++11 is simple to use ;
#include <functional>
// 1. 绑定普通函数
void print(int a, int b, int c)
{
std::cout << "a = " << a << ", b=" << b << ", c=" << c << "\n\n";
}
...
// 将占位符2绑定到a,将2绑定到b,将占位符1绑定到c,生成新函数func(_1, _2)
auto func1 = std::bind(print, std::placeholders::_2, 2, std::placeholders::_1);
func1(3, 4); // 相当于是print(4, 2, 3)
...
// 2. 绑定类成员函数
class A {
public:
void print(int x, int y) {
std::cout << "x + y = " << x + y << std::endl;
}
};
...
A a;
// 将a对象的成员函数绑定到f2上
auto func2 = std::bind(&A::print, &a, 1, std::placeholders::_1);
func2(2); // 相当于是a.print(1,2)
...
[3]. Référence Rvalue
3.1 Le concept de valeurs gauche et droite
- Lvalue : la valeur à gauche du signe égal, l'objet persistant qui existe toujours après l'équation, et l'adresse qui peut prendre la valeur ;
- Rvalue : la valeur à droite du signe égal, un objet temporaire qui n'existe plus après l'égalité ;
- A prvalue (pas de nom, ne peut pas prendre d'adresse) :
- Variables temporaires retournées par non-référence ;
- Variables temporaires générées par des expressions d'opération ;
- les littéraux autres que les chaînes (les littéraux de chaîne sont des lvalues) ;
- Expression lambda ;
- Xvalue (a un nom et peut prendre une adresse) : une variable temporaire qui est sur le point d'être détruite mais qui est référencée par une rvalue pour la maintenir en vie ;
- Une lvalue est une rvalue d' une référence rvalue ;
- Une lvalue est une rvalue référencée par une constante lvalue ;
- A prvalue (pas de nom, ne peut pas prendre d'adresse) :
- Vous pouvez vous référer au blog : C++ Scenery in the Fog 10 : Talk about lvalues, prvalues and Dying Values ;
3.2 références de valeurs gauche et droite
- référence lvalue :
T &;
std::string & str
- référence rvalue :
T &&;- L'objet utilisé comme référence (équivalent à prendre une adresse) est une valeur mourante ;
- Si l'objet référencé n'est pas une xvalue, vous devez
std::move(左值变量)convertir la lvalue en une rvalue.Notez que cela rendra la variable lvalue d'origine inaccessible ; - Une variable de référence rvalue est elle-même une lvalue ;
std::string && str
- Quelques exemples d'utilisation :
std::string lv1 = "string,"; // lv1 是一个左值
// std::string&& r1 = lv1; // 非法, 右值引用不能引用左值
std::string&& rv1 = std::move(lv1); // 合法, std::move 可以将左值转移为右值
std::cout << rv1 << std::endl; // string,
const std::string& lv2 = lv1 + lv1; // 合法, 常量左值引用能够延长临时变量的生命周期
// lv2 += "Test"; // 非法, 常量引用无法被修改
std::cout << lv2 << std::endl; // string,string,
std::string&& rv2 = lv1 + lv2; // 合法, 右值引用延长临时对象生命周期
rv2 += "Test"; // 合法, 非常量引用能够修改临时变量
std::cout << rv2 << std::endl; // string,string,string,Test
3.3 Déplacer la sémantique
-
Copier la sémantique :
- Copiez complètement les ressources d'un objet vers un autre objet, c'est-à-dire en copie profonde ;
-
Déplacer la sémantique :
- Déplacer les ressources d'un objet vers un autre objet sans copier les données ;
- Seules les ressources du tas
newl'espace demandé :- Étant donné que les ressources appliquées sur le tas sont généralement relativement importantes, le coût d'utilisation de la sémantique de copie est très élevé ;
- L'utilisation de la sémantique de déplacement peut éviter les créations et les suppressions fréquentes, évitant ainsi la surcharge de copie ;
nullptrMéthode de mise en œuvre : déplacement complet des ressources en copiant de nouveaux pointeurs et en définissant d'anciens pointeurs ;
- Les ressources sur la pile ne peuvent pas être déplacées , c'est-à-dire non
new-space, y compris les pointeurs et les types de POD, etc. ;- Étant donné que les ressources appliquées sur la pile ne peuvent être détruites que lorsque la portée se termine, et ne peuvent pas être libérées et transférées manuellement, la sémantique de déplacement réel ne peut donc pas être réalisée ;
- Cependant, ces ressources peuvent également être définies sur des valeurs initiales par défaut pour obtenir une sémantique de pseudo-déplacement (c'est-à-dire indisponible après le déplacement, mais pas vraiment inaccessible) ;
-
Fonctions connexes impliquées :
-
std::move():- Fonction : convertir une lvalue en une xvalue, et obtenir une référence rvalue de la lvalue ;
- Mais en fait, la lvalue d'origine n'est pas publiée, mais une référence à sa rvalue est ajoutée ;
- En utilisant cette référence rvalue comme paramètre réel de la fonction, vous pouvez appeler des fonctions surchargées qui implémentent la sémantique de déplacement , telles que les constructeurs de déplacement et les fonctions surchargées d'opérateur d'affectation de déplacement ;
- est le seul moyen de convertir une lvalue en une rvalue ;
- référence:
- Fonction : convertir une lvalue en une xvalue, et obtenir une référence rvalue de la lvalue ;
-
Déplacer le constructeur
A(A&& _a):- Rôle : implémenter le constructeur de sémantique mobile ;
- Le paramètre formel est une référence rvalue ;
- Déplacez la ressource sur le tas du paramètre formel vers l'objet actuel, c'est-à-dire que le pointeur de l'objet actuel pointe vers la ressource sur le tas du paramètre formel, puis rendez le pointeur du paramètre formel vide ;
- Remarque : Il existe un constructeur de déplacement par défaut, mais il n'implémente pas la sémantique de déplacement, mais implémente uniquement la sémantique de copie superficielle comme le constructeur par défaut ;
- Rôle : implémenter le constructeur de sémantique mobile ;
-
Déplacer l'opérateur d'affectation des fonctions surchargées
A& operator=(A&& _a):- Fonction : la fonction de surcharge de l'opérateur d'affectation qui réalise la sémantique de déplacement ;
- Déplacez la ressource sur le tas du paramètre formel vers l'objet actuel, c'est-à-dire que le pointeur de l'objet actuel pointe vers la ressource sur le tas du paramètre formel, puis rendez le pointeur du paramètre formel vide ;
- Remarque : Il existe une fonction de surcharge d'opérateur d'affectation de déplacement par défaut, mais elle n'implémente pas la sémantique de déplacement, mais implémente uniquement la sémantique de copie superficielle comme la fonction de surcharge d'opérateur d'affectation par défaut ;
- Fonction : la fonction de surcharge de l'opérateur d'affectation qui réalise la sémantique de déplacement ;
-
-
Implémenter la sémantique de déplacement :
- Vous devez implémenter manuellement les fonctions de surcharge du constructeur de déplacement et de l'opérateur d'affectation de déplacement de la classe ;
- Ensuite,
std::move()la sémantique de déplacement est réalisée en appelant le constructeur de déplacement ou la fonction surchargée de l'opérateur d'affectation de déplacement ; - Les méthodes d'appel incluent :
- (1) Appelez explicitement le constructeur de déplacement ou la fonction surchargée de l'opérateur d'affectation de déplacement ;
- (2) Passez un argument rvalue dans un paramètre formel de passage de valeur d'un objet de classe ;
- À ce stade, le constructeur de déplacement est appelé implicitement , ce qui correspond à la sémantique de déplacement ;
- Si une lvalue est passée, le constructeur de copie est appelé, ce qui correspond à la sémantique de copie ;
- Si le constructeur de déplacement n'est pas implémenté, le constructeur de copie est appelé automatiquement, car
const A &les références lvalue constantes peuvent également être suivies de références rvalue ; - S'il est passé à un paramètre formel de référence rvalue d'un objet de classe, ce n'est ni la sémantique de déplacement ni la sémantique de copie, car à ce moment la ressource du paramètre réel n'a pas été déplacée ou copiée, seule la méthode d'accès au sein de la fonction a été ajouté ( Il équivaut à un pointeur pointant), et sa fonction est la même que celle d'une référence lvalue utilisée (la différence est qu'elle équivaut à une surcharge d'une référence lvalue, qui peut distinguer les fonctions surchargées) ;
- (3) assigner l'objet de retour temporaire (rvalue) à un objet de classe ;
- À ce stade, la fonction surchargée de l'opérateur d'affectation de déplacement est implicitement appelée , ce qui correspond à la sémantique de déplacement ;
- Si la fonction de surcharge de l'opérateur d'affectation de déplacement n'est pas implémentée, la fonction de surcharge de l'opérateur d'affectation est appelée automatiquement, car la
const A &référence lvalue constante peut également être connectée à la référence rvalue ; - Si l'objet renvoyé par la fonction est affecté d'une référence rvalue , il ne s'agit ni d'une sémantique de déplacement ni d'une sémantique de copie, car à ce moment les ressources de l'objet temporaire n'ont pas été déplacées et copiées, et seule la voie d'accès en dehors de la fonction (équivalent au pointeur pointant) a été ajouté. , l'objet temporaire est la valeur mourante à ce moment ;
-
Un exemple de code est le suivant :
class A{
public:
char* ptr;
int val;
std::string s;
A() :ptr("hello"), val(5), s("world") {
};
A(const A& _a) {
// 拷贝语义
printf("copy constructor\n");
int _cnt = 0;
while (*(_a.ptr + _cnt) != '\0') {
_cnt++;
}
ptr = new char[_cnt + 1];
memcpy(ptr, _a.ptr, sizeof(char) * (_cnt + 1));
val = _a.val;
s = _a.s;
}
A(A&& _a) {
// 移动语义
printf("move constructor\n");
val = std::move(_a.val);
ptr = std::move(_a.ptr);
s = std::move(_a.s);
_a.val = 0;
_a.ptr = nullptr;
}
A& operator=(const A& _a) {
// 拷贝语义
printf("copy operator =\n");
int _cnt = 0;
while (*(_a.ptr + _cnt) != '\0') {
_cnt++;
}
ptr = new char[_cnt + 1];
memcpy(ptr, _a.ptr, sizeof(char) * (_cnt + 1));
val = _a.val;
s = _a.s;
}
A& operator=(A&& _a) {
// 移动语义
printf("move operator =\n");
val = std::move(_a.val);
ptr = std::move(_a.ptr);
s = std::move(_a.s);
_a.val = 0;
_a.ptr = nullptr;
}
};
A a;
printf("c: %s %s\n", a.ptr, a.s.c_str());
printf("a: %d\n", &a.ptr);
// 拷贝语义
A b(a);
printf("c: %s %s\n", b.ptr, b.s.c_str());
printf("b: %d\n", &b.ptr);
// 移动语义
A c(std::move(a));
printf("c: %s %s\n", c.ptr, c.s.c_str());
printf("c: %d\n", &c.ptr);
auto func = []() {
A tmp;
tmp.ptr = "hello again";
tmp.val = 10;
tmp.s = "new world";
return tmp;
};
A d;
// 移动语义
d = func();
printf("d: %s\n", d.ptr);
printf("d: %s\n", d.s.c_str());
A e;
// 移动语义
e = std::move(d);
printf("e: %s\n", e.ptr);
printf("e: %s\n", e.s.c_str());
3.4 Règles de réduction des citations
- Utilisé pour passer à nouveau les paramètres de référence ;
- Les règles de réduction de référence (également appelées règles de réduction de référence) sont les suivantes :
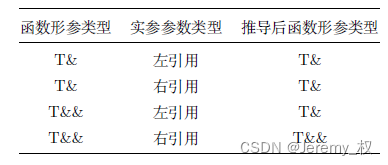
- Lorsque seulement lorsque le paramètre réel est un type référence droite (la valeur x) et que le paramètre formel est un type référence droite , le type passé à la fonction est un type référence droite et le reste sont des types référence gauche, c'est-à-dire , la forme du paramètre formel ne peut pas déterminer le type de référence ;
- Notez qu'une variable de type référence droite elle-même est une lvalue, donc si elle continue à passer, elle doit être considérée comme un type référence gauche ;
- Les règles de réduction de référence ne s'appliquent qu'en cas de déduction de type automatique , comme suit :
- fonction de modèle
T&&; autoDéduction de type variable ;decltypedéduction de type d'expression ;typedefouusingdérivation d'alias ;- référence:
- fonction de modèle
// 模板函数
template<typename T>
void f(T&& param);
// auto自动推导
auto&& var2 = var1;
// typedef自动推导
template<typename T>
typedef T&& RRef;
// using自动推导
template<typename T>
using RRef = T&&;
// decltype自动推导
decltype(w1)&& v2 = w2;
- Si le type n'est pas automatiquement déduit, les références de valeur gauche et droite sont en fait deux types différents, à savoir :
- impossible de passer un argument de référence lvalue à un paramètre de référence rvalue ;
- Mais vous pouvez passer un argument de référence rvalue à un paramètre de référence constant lvalue ;
3.5 Transmission parfaite
-
effet:
- Évitez de transmettre le bon type de référence en tant que lvalue lorsqu'il est transmis en tant que référence ;
- De cette manière, le paramètre quelque peu compliqué selon lequel la variable de type référence droite elle-même est une lvalue peut être ignoré ;
-
utiliser:
- Une transmission parfaite peut être effectuée en utilisant
std::forward<右值或左值引用类型>(右值或左值引用变量);
- Une transmission parfaite peut être effectuée en utilisant
void pass(T&& v) {
// 总作为左值转发
std::cout << " 普通传参: ";
reference(v);
// 强制转为右值转发
std::cout << " std::move 传参: ";
reference(std::move(v));
// 使用std::forward转发
std::cout << " std::forward 传参: ";
reference(std::forward<T>(v));
// static_cast<T&&>转换也符合引用坍缩规则
std::cout << "static_cast<T&&> 传参: ";
reference(static_cast<T&&>(v));
}
3. Conteneur
1. std :: tableau
- effet:
- en remplacement des baies traditionnelles ;
- Convient aux objets de tableau avec une taille d'objet fixe ;
2. std :: forward_list
- effet:
- Comme alternative à la liste liée à sens unique traditionnelle ;
3. std :: unordered_map
- effet:
- La couche inférieure utilise une table de hachage ;
- La complexité temporelle est inférieure à std::map, qui est une complexité temporelle constante ;
- Le parcours ordonné ne peut pas être effectué automatiquement ;
4. std :: unordered_set
- effet:
- La couche inférieure utilise une table de hachage ;
- La complexité temporelle est inférieure à std::set, qui est une complexité temporelle constante ;
- Le parcours ordonné ne peut pas être effectué automatiquement ;
5. std :: tuple
-
effet:
- Dépassez la limitation selon laquelle std::pair ne peut stocker que deux éléments, et std::tuple peut stocker n'importe quel nombre d'éléments ;
-
utiliser:
#include <tuple>;std::make_tuple(参数1,参数2...)Utilisé pour retourner un tuple de type std::tuple composé de paramètres ;std::get<元组下标>(元组变量)Il permet d'obtenir l'élément de l'indice correspondant à la variable tuple, qui peut être lu et écrit ;std::tie(变量名1, 变量名2...) = 元组变量Il est utilisé pour décompresser la variable tuple, puis l'affecter au nom de variable correspondant, qui peutstd::ignoreêtre utilisé comme espace réservé pour le nom de variable ;std::tuple_cat(元组变量1, 元组变量2)pour fusionner deux tuples ;std::tuple_len(元组变量)Utilisé pour renvoyer le nombre d'éléments de tuple (longueur de tuple) ;- Après C++14, il peut
std::get<元素类型>(元组变量)être utilisé pour obtenir ce type d'élément dans le tuple, mais si l'élément de ce type n'est pas unique, il y aura une erreur de compilation ; - Après C++17, vous pouvez utiliser pour
std::tuple_index(元组变量, 元组下标)obtenir l'élément correspondant à l'indice du tuple ; - référence:
auto student = std::make_tuple(3.8, ’A’, " 张三");
std::get<0>(student) = 3.6; // 修改元组的元素
cout << std::get<0>(student) << endl; // 读取元组的元素
std::get<double>(student) = 3.6 // C++14后
std::tie(gpa, std::ignore, name) = student;
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));
for(int i = 0; i != tuple_len(new_tuple); ++i)
// 运行期索引,C++17后
std::cout << tuple_index(new_tuple, i) << std::endl;
4. Pointeurs intelligents et gestion de la mémoire
[1]. std ::shared_ptr
-
effet:
- Enregistrez le nombre de points shared_ptr vers le même objet ;
- Lorsque le compteur de références est 0, l'objet est automatiquement supprimé ;
-
utiliser:
#include <memory>;- Use
std::make_shared<对象类型>(对象值)peut générer un objet et retourner son pointeur shared_ptr, ce qui est recommandé ; - L'utilisation
get()peut obtenir des pointeurs bruts sans augmenter le nombre de références ; - Utilisez
reset()pour effacer le pointeur et le nombre de références du point partagé partagé actuel, et diminuer le nombre de références des autres points partagés pointant vers le même objet d'une unité ; - peut être affecté comme
nullptr;
std::make_shared<int> pointer0(new int); // 不推荐这样使用
auto pointer = std::make_shared<int>(10);
auto pointer2 = pointer; // 引用计数+1
auto pointer3 = pointer; // 引用计数+1
int *p = pointer.get(); // 这样不会增加引用计数
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 3
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 3
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 3
pointer2.reset();
std::cout << "reset pointer2:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 2
std::cout << "pointer2.use_count() = "
<< pointer2.use_count() << std::endl; // pointer2 已reset; 0
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 2
pointer3.reset();
std::cout << "reset pointer3:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 1
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 0
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // pointer3 已reset; 0
[2]. std :: unique_ptr
-
effet:
- Pointer exclusivement vers un objet et interdire aux autres pointeurs intelligents de partager un objet avec lui ;
-
utiliser:
#include <memory>;std::unique_ptr<对象类型> 智能指针名(指向对象的指针)Un objet peut être généré avec ;- Après C++14, vous pouvez l'utiliser pour
std::make_unique<对象类型>(对象值)générer un objet et renvoyer son pointeur unique_ptr, ce qui est recommandé ; - Bien que std::unique_ptr soit exclusif, il peut être utilisé
std::move(unique_ptr)pour transférer l'objet vers lequel il pointe vers un autre std::unique_ptr ; - peut être affecté comme
nullptr;
std::unique_ptr<Foo> p1(std::make_unique<Foo>());
// p1 不空, 输出
if (p1) p1->foo();
{
std::unique_ptr<Foo> p2(std::move(p1));
// p2 不空, 输出
f(*p2);
// p2 不空, 输出
if(p2) p2->foo();
// p1 为空, 无输出
if(p1) p1->foo();
p1 = std::move(p2);
// p2 为空, 无输出
if(p2) p2->foo();
std::cout << "p2 被销毁" << std::endl;
}
// p1 不空, 输出
if (p1) p1->foo();
// Foo 的实例会在离开作用域时被销毁
[3]. std ::weak_ptr
-
effet:
- Des références faibles n'augmenteront pas le nombre de références ;
- ne peut pas prendre de valeurs (pas d'opérateur *) et prendre des pointeurs (pas d'opérateur ->);
- Il n'est utilisé que pour vérifier si l'objet pointé par shared_ptr existe toujours, ou pour obtenir un nouveau shared_ptr pointant sur l'objet ;
-
utiliser:
#include <memory>;- Weak_ptr ne peut être construit que via shared_ptr ;
- Vous
expired()pouvez vérifier si l'objet actuellement pointé existe toujours et renvoyer un type booléen ; - Utilisez
use_count()pour vérifier le nombre de références de l'objet actuellement pointé ; - Utilisez
lock()un pointeur shared_ptr qui peut renvoyer l'objet pointant actuel ; - Vous pouvez vous référer au blog : utilisation de base de faiblesse_ptr et comment résoudre les références circulaires ;
shared_ptr<int> sp(new int(10));
weak_ptr<int> wp(sp);
auto new_sp = wp.lock();
if(wp.expired()) {
cout << "weak_ptr无效,资源已释放";
}
else {
cout << "weak_ptr有效, *new_sp = " << *new_sp << endl;
}
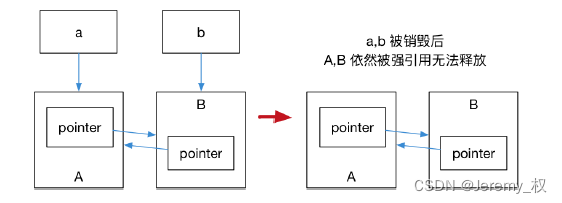
- raison:
- S'il y a un shared_ptr à l'intérieur de l'objet pointé par shared_ptr, cela peut faire en sorte que le nombre de références du shared_ptr actuel ne soit pas 1, ce qui entraîne un blocage de libération (problème de référence circulaire) ;
- Parce que si vous voulez libérer la mémoire pointée par shared_ptr, vous avez besoin que son compteur de références soit 0 ;
- Mais si le nombre de références de shared_ptr est 0, il peut être nécessaire de libérer l'espace mémoire vers lequel il pointe en premier, car il y a un pointeur intelligent à l'intérieur qui peut occuper le nombre de références de l'objet actuel ;
- Par conséquent, l'espace mémoire ne peut pas être libéré et provoque une fuite, comme illustré dans la figure suivante :
4. Résumé
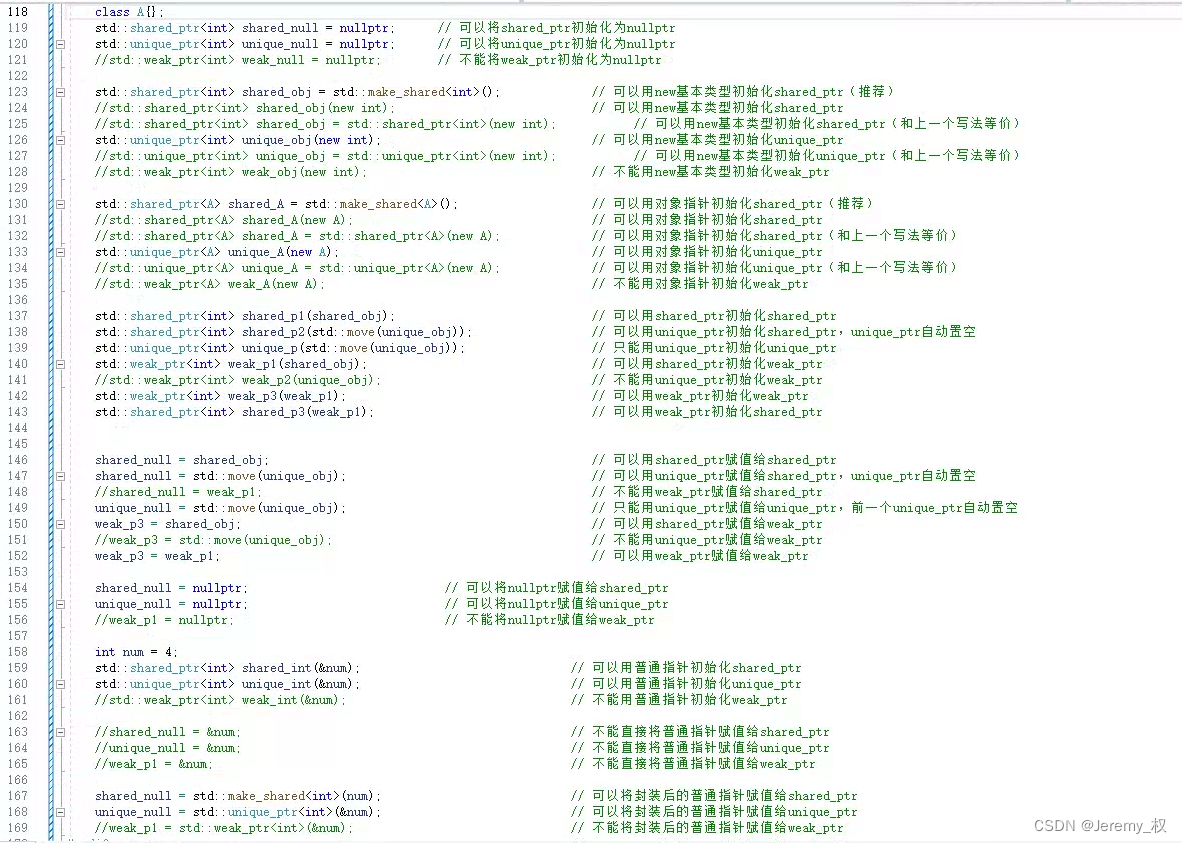
- L'utilisation des trois pointeurs intelligents est résumée comme suit :
weak_ptr:- ne peut être initialisé que par
shared_ptrouweak_ptr; - ne peut être affecté que par
shared_ptrouweak_ptr;
- ne peut être initialisé que par
unique_ptr:- Ne peut être initialisé que par un pointeur d'objet ou
std::move(unique_ptr); - ne peut être affecté que par
nullptr,std::move(unique_ptr)ouunique_ptr<对象类型>(对象指针);
- Ne peut être initialisé que par un pointeur d'objet ou
shared_ptr:- Peut être initialisé par un pointeur d'objet,
shared_ptr,std::move(unique_ptr)ouweak_ptr; - Peut être affecté par
nullptr,shared_ptr,std::move(unique_ptr)oushared_ptr<对象类型>(对象指针);
- Peut être initialisé par un pointeur d'objet,
5. Parallélisme et concurrence
- Ici présente principalement la programmation multithread ;
[1]. std :: fil
-
effet:
- Créez une instance d'exécution de thread ;
-
utiliser:
#include <thread>;- Créez
std::thread 线程实例名(线程执行的函数名, 函数参数1, 函数参数2...)un thread pour exécuter la fonction avec ;- Le nom de la fonction exécutée par le thread doit être une fonction globale ou une fonction membre statique ;
- Notez que les paramètres de la fonction ici sont
std::bind()les mêmes que, si elle est passée par valeur ou par pointeur, c'est la même chose qu'une fonction normale, mais si elle est passée par référence, elle doit être utilisée au lieu d'êtrestd::ref(对象名)directement utilisée对象名comme un réel paramètre;- S'il n'est pas utilisé
std::ref(对象名), le passage de référence lvalue ordinaire est toujours l'implémentation du passage de valeur, et le passage de référence rvalue (usestd::move()) est la véritable implémentation du passage de référence ; - Ceci est principalement pour rappeler aux utilisateurs de faire attention à la situation où le cycle de vie de l'objet référencé peut expirer lorsqu'il est utilisé à l'intérieur de la fonction , mais en fait, la mémoire pointée par le pointeur passé risque également d'être libérée ;
- S'il n'est pas utilisé
- Blogue de référence :
- Les threads peuvent être créés avec des expressions Lambda comme paramètres de fonction ;
- Fonctions membres d'une instance de thread :
join()Utilisé pour bloquer le thread qui crée l'instance de thread jusqu'à ce que l'exécution de l'instance de thread soit terminée ;- Si le thread n'est pas détaché et que d'autres threads sont toujours actifs lorsque le thread principal détruit d'autres threads,
terminate called without an active exceptionune erreur se produit ; - Par conséquent, lorsqu'il ne quitte pas le thread, il doit être utilisé
join()pour que le thread principal attende que chaque thread se termine avant de se terminer ;
- Si le thread n'est pas détaché et que d'autres threads sont toujours actifs lorsque le thread principal détruit d'autres threads,
detach()Il est utilisé pour détacher l'instance de thread du thread qui a créé l'instance de thread et devenir un thread démon, donc :- Le contrôle de l'instance de thread ne peut plus être obtenu via le nom de l'instance de thread ;
- Cependant, il est toujours possible
std::futured'obtenir le résultat d'exécution de l'instance de thread dans le thread qui a créé l'instance de thread ; - Une fois les exécutions respectives terminées, le système libère leurs ressources sans s'affecter mutuellement, ce qui peut empêcher les sous-threads inachevés de se terminer après la fin du thread du processus principal;
#include <iostream>
#include <thread>
int main() {
std::thread t([](){
std::cout << "hello world." << std::endl;
});
// 阻塞main()直至t线程执行完毕
t.join();
return 0;
}
[2]. std :: mutex
-
effet:
- Fournissez un mutex pour le thread ;
- Quelques notions :
- Section critique : une zone de code qui n'autorise qu'un seul thread à accéder, mais un seul processus peut obtenir un accès d'exclusion mutuelle ;
- Mutex : objet du noyau, qui peut effectuer une opération de verrouillage dans le noyau et peut obtenir un accès d'exclusion mutuelle sur plusieurs processus ;
- Quatre conditions pour qu'un blocage se produise :
- Exclusion mutuelle : les ressources demandées s'excluent mutuellement ;
- Demander et conserver : lorsque la demande est bloquée, les ressources existantes continuent d'être conservées et non libérées ;
- Pas de privation : les ressources occupées par d'autres threads ne peuvent pas être privées et ne peuvent être libérées que par elles-mêmes ;
- Boucle en attente : une boucle d'attente de ressources doit apparaître ;
- La surcharge de mise en œuvre des verrous mutex est très élevée, ce qui convient à l'exclusion mutuelle de codes de section critique plus importants ;
-
utiliser:
#include <mutex>;- Fonction membre :
lock(): Le thread en cours essaie de verrouiller le mutex,- En cas de succès, le thread actuel possède le mutex jusqu'à
unlock(); - En cas d'échec, attendez que les autres threads libèrent le verrou mutex jusqu'à ce qu'ils réussissent et que le thread actuel soit bloqué ;
- En cas de succès, le thread actuel possède le mutex jusqu'à
unlock(): Le thread courant libère le mutex ;try_lock(): essayez de verrouiller le mutex,- En cas de succès, le thread actuel possède le mutex jusqu'à
unlock(); - En cas d'échec, renvoie false et le thread actuel ne sera pas bloqué ;
- En cas de succès, le thread actuel possède le mutex jusqu'à
std::lock_guard<互斥量类型> 名称(互斥量变量): syntaxe RAII pour les mutex, pour :- Au lieu de cela
mutex对象.lock(), essayez de verrouiller l'objet mutex lorsque l'objet est construit ; - Libérer automatiquement le mutex à la fin de la portée (y compris les conditions de fin anormales telles qu'une sortie anormale), sans appeler manuellement
unlock()la libération ; - Avis:
release()Cela doit être fait avant l'opération manuelleunlock(), sinon le mutex ne peut pas libérer le verrou, ce qui entraînera la chute d'autres endroits dans une impasse de verrouillage concurrentiel ;- Essayez donc de ne pas l'utiliser
release(), surtout de ne pas en abuserrelease();
- Au lieu de cela
std::unique_lock<互斥量类型> 名称(互斥量变量): Syntaxe RAII de mutex, plus souple que lock_guard, permettant :- Libérez manuellement le mutex dans la section critique ;
- Libère automatiquement le mutex à la fin de la section critique ;
- Il est même possible de transférer le verrou du mutex à l'objet unique_lock en dehors de la portée sous la forme d'une valeur de retour pour prolonger le temps de maintien du verrou ;
- Recommandé sur lock_guard et les sémaphores natifs ;
- Vous pouvez consulter le blog :
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex
// 调用mutex成员函数
volatile int counter(0); // non-atomic counter
std::mutex mtx; // locks access to counter
void attempt_10k_increases() {
for (int i=0; i<10000; ++i) {
if (mtx.try_lock()) {
// only increase if currently not locked:
++counter;
mtx.unlock();
}
}
}
// 使用lock_guard
void critical_section(int change_v) {
static std::mutex mtx;
std::lock_guard<std::mutex> lock(mtx); // 相当于mtx.lock()
// 执行竞争操作
v = change_v;
// 离开此作用域后mtx 会被释放
}
// 使用unique_lock
void critical_section(int change_v) {
static std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx); // 相当于mtx.lock()
// 执行竞争操作
v = change_v;
std::cout << v << std::endl;
// 将锁进行释放
lock.unlock(); // 相当于mtx.unlock()
// 在此期间,任何人都可以抢夺v 的持有权
// 开始另一组竞争操作,再次加锁
lock.lock(); // 相当于mtx.lock()
v += 1;
std::cout << v << std::endl;
}
[3]. std::packaged_task和std::future
-
effet:
- std::packaged_task et std::future sont généralement utilisés ensemble ;
- std::packaged_task : cela équivaut à encapsuler une fonction afin qu'elle puisse être appelée dans un environnement multi-thread, et le résultat d'exécution de la fonction d'encapsulation peut être obtenu via std::future;
- std::future : bloque le processus en cours jusqu'à ce que le résultat asynchrone de la fonction std::packaged_task exécutée par d'autres threads soit obtenu ;
- std::packaged_task est similaire à std::function, mais fournit une encapsulation de fonction et un retour de résultat dans un environnement multithread ;
- std::future équivaut à une méthode de synchronisation pour appeler les threads de manière asynchrone, à savoir barrière ;
- Quelques notions :
- Synchronisation : après avoir émis un appel, vous devez attendre qu'il soit terminé avant de poursuivre l'exécution, par exemple en appelant
future.get()outhread.join(); - Asynchrone : après l'envoi d'un appel, il peut continuer à s'exécuter sans attendre qu'il se termine, par exemple en créant une
threadfonction d'exécution ;
- Synchronisation : après avoir émis un appel, vous devez attendre qu'il soit terminé avant de poursuivre l'exécution, par exemple en appelant
- std::packaged_task et std::future sont généralement utilisés ensemble ;
-
utiliser:
- les deux
#include <future>; std::packaged_task<函数返回类型(函数参数类型)> 容器名(函数名或者lambda表达式)Créez un objet std::packaged_task avec ;- Utilisez
std::futrue<函数返回类型> 容器名 = std::packaged_task对象.get_future()pour créer un futur objet qui obtient le résultat d'exécution de std::packaged_task ; - Utilisez std::future
get()pour obtenir le résultat d'exécution de std::packaged_task ; - Blog de référence : C++11 Concurrency Guide 4 (Détaillé 2 std::packaged_task introduction) et C++11 Concurrency Guide 4 (Détaillé 3 std::future & std::shared_future) ;
- les deux
#include <iostream> // std::cout
#include <future> // std::packaged_task, std::future
#include <chrono> // std::chrono::seconds
#include <thread> // std::thread, std::this_thread::sleep_for
// count down taking a second for each value:
int countdown (int from, int to) {
for (int i=from; i!=to; --i) {
std::cout << i << '\n';
std::this_thread::sleep_for(std::chrono::seconds(1));
}
std::cout << "Finished!\n";
return from - to;
}
int main ()
{
std::packaged_task<int(int,int)> task(countdown); // 设置 packaged_task
std::future<int> ret = task.get_future(); // 获得与 packaged_task 共享状态相关联的 future 对象.
std::thread th(std::move(task), 10, 0); //创建一个新线程完成计数任务.
int value = ret.get(); // 等待任务完成并获取结果.
std::cout << "The countdown lasted for " << value << " seconds.\n";
th.join();
return 0;
}
[4]. std :: condition_variable
-
effet:
- Fournir un mécanisme de sémaphore pour un groupe de threads en compétition pour le même mutex, permettant de bloquer le thread courant ou de réveiller d'autres threads bloqués ;
- C'est-à-dire que sur la base des verrous mutex, un mécanisme de synchronisation est ajouté pour permettre le contrôle de la séquence des verrous mutex concurrents , en évitant une concurrence inutile et en consommant des ressources ;
-
utiliser:
#include <condition_variable>;std::condition_variable 条件变量名;Définir les variables de condition ;- Dans un groupe de threads se disputant le même mutex, appelez :
条件变量对象.wait(unique_lock对象), le thread actuel est bloqué et libère en même temps le verrou de l'objet mutex possédé ;条件变量对象.wait(unique_lock对象, bool类型返回值函数), uniquement lorsque la fonction renvoie une valeurfalse, le thread actuel sera bloqué et le verrou d'objet mutex détenu sera libéré en même temps ;条件变量对象.notify_all(), libère le verrou de l'objet mutex possédé, réveille touswait()les threads et les laisse entrer en compétition pour le sémaphore mutex ;条件变量对象.notify_one(), libérez le verrou d'objet mutex possédé, réveillez un certainwait()thread et laissez-les concourir pour le sémaphore mutex, mais il n'y a aucun moyen d'obtenir une concurrence simultanée de cette manière, l'efficacité est faible et il n'est pas recommandé de l'utiliser dans un environnement concurrent ;
- L'objet de l'attention
wait()est l'objet tenumutex,unique_locknonmutexl'objet lui-même ; - Blogue de référence :
#include <queue>
#include <chrono>
#include <mutex>
#include <thread>
#include <iostream>
#include <condition_variable>
int main() {
std::queue<int> produced_nums;
std::mutex mtx;
std::condition_variable cv;
bool notified = false; // 通知信号
// 生产者
auto producer = [&]() {
for (int i = 0; ; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(900));
std::unique_lock<std::mutex> lock(mtx);
std::cout << "producing " << i << std::endl;
produced_nums.push(i);
notified = true;
// 释放mtx,唤醒所有wait(mtx)的线程
cv.notify_all();
}
};
// 消费者
auto consumer = [&]() {
while (true) {
std::unique_lock<std::mutex> lock(mtx);
while (!notified) {
// 避免虚假唤醒
// 释放mtx,等待别的线程唤醒自己
cv.wait(lock);
// 虚假唤醒:可能是由于别的原因而非notify()让自己获得了互斥量锁
}
// 消费者慢于生产者,则短暂取消锁,使得生产者有机会在消费者消费前继续生产
lock.unlock();
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
// 加锁消费
lock.lock();
while (!produced_nums.empty()) {
std::cout << "consuming " << produced_nums.front() << std::endl;
produced_nums.pop();
}
notified = false;
}
};
// 分别在不同的线程中运行
std::thread p(producer);
std::thread cs[2];
for (int i = 0; i < 2; ++i) {
cs[i] = std::thread(consumer);
}
p.join();
for (int i = 0; i < 2; ++i) {
cs[i].join();
}
return 0;
}
[5]. std :: atomique
-
effet:
- Fournir des opérations atomiques au niveau des instructions du processeur pour que les threads réalisent des opérations variables mutuellement exclusives ;
- La surcharge est inférieure à std::mutex, qui est utilisé pour l'exclusion mutuelle des variables ;
-
utiliser:
#include <atomic>;- Tous les types ne peuvent pas implémenter des opérations atomiques, mais les types entiers et à virgule flottante le peuvent, et d'autres types peuvent utiliser
std::atomic<T>::is_lock_free()des fonctions pour vérifier si le type atomique correspondant de type T prend en charge les opérations atomiques réelles ; - Fonction membre :
fetch_add(): Opération d'addition, a également une surcharge d'opérateur "+" ;fetch_sub(): Opération de soustraction, a également une surcharge de l'opérateur "-" ;load(): renvoie la valeur de la variable atomique ;store(): mettre à jour la valeur de la variable atomique ;exchange(): définit une variable atomique sur une nouvelle valeur et renvoie l'ancienne valeur ;
- Concernant
atomicl'atomicité des fonctions variables surchargées et des fonctions membres :- Toutes les opérations d'affectation ne sont pas atomiques ;
- En général, les fonctions membres qui l'appellent sont fondamentalement atomiques, mais la surcharge de l'opérateur peut rendre invisibles plusieurs opérations atomiques ;
- Les opérations d'auto-incrémentation et d'auto-décrémentation sont atomiques, mais une attention particulière est que
x = x + ycette opération n'est pas atomique ; - La recommandation est d'utiliser au maximum ses fonctions membres au lieu de surcharger ses opérateurs, afin que l'atomicité de l'opération soit plus intuitive ;
- Blogue de référence :
#include <atomic>
#include <thread>
#include <iostream>
//std::atomic<int> count = {0};
int main() {
std::atomic<int> count;
std::atomic_init(&count, 0);
std::thread t1([](){
count.fetch_add(1);
});
std::thread t2([](){
count++; // 等价于fetch_add
count += 1; // 等价于fetch_add
});
t1.join();
t2.join();
std::cout << count << std::endl;
return 0;
}
[6] Modèle de mémoire d'opération atomique
6.1 Modèle de cohérence
- (1) Cohérence linéaire/cohérence forte/cohérence atomique :
- A chaque fois, vous pouvez lire les dernières données écrites par la variable ;
- L'ordre des opérations vu par tous les threads est cohérent avec l'ordre sous l'horloge globale ;
- L'ordre de l'horloge globale est l'ordre temporel dans lequel les événements se produisent réellement, mais en raison des retards de communication, l'ordre des opérations vu par chaque thread n'est pas nécessairement l'ordre de l'horloge globale ;
- Comme le montre la figure ci-dessous, l'ordre vu par chaque thread doit être write
x = 1, writex = 2, readx = 2;
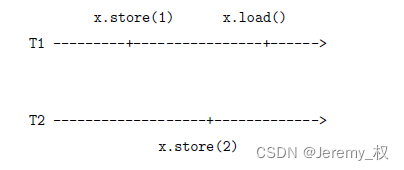
- (2) Cohérence séquentielle :
- A chaque fois, vous pouvez lire les dernières données écrites par la variable ;
- Cependant, il n'est pas nécessaire que l'ordre des opérations vu par tous les threads soit cohérent avec l'ordre sous l'horloge globale. Il est seulement nécessaire de pouvoir trouver un ordre raisonnable des opérations globales aux yeux de tous les threads , qui soit conforme à l'ordre de lecture et d'écriture du programme ;
- Zookeeper utilise la cohérence séquentielle ;
- Vous pouvez vous référer au blog : Qu'est-ce que la cohérence séquentielle ? ;
- Comme le montre la figure ci-dessous, chaque thread est garanti capable de lire
x = 3, mais il n'est pas garanti que l'xécriture vue 1 doit être exécutée avant l'écriture 2 ;

- (3) Cohérence causale :
- Il est seulement garanti que l'ordre des opérations causales vu par chaque thread est conforme à l'ordre causal ;
- L'enchaînement des opérations sans causalité n'est pas garanti ;
- WeChat Moments utilise la cohérence causale ;
- Comme le montre la figure ci-dessous, il est uniquement garanti que chaque thread s'exécute après
cavoir vuaet écrit ;b

- cohérence finale :
- S'il n'y a pas d'opération d'écriture, les résultats lus par tous les threads sont finalement cohérents ;
- Il ne garantit pas que les résultats actuellement lus doivent être les plus récents, mais seulement que les résultats finaux lus doivent être les plus récents ;
- Comme le montre la figure ci-dessous, il est seulement garanti que chaque thread pourra éventuellement le lire
x = 4, mais pas nécessairement pour le moment ;

- Quelques références :
6.2 std::memory_order
- Il est possible de contrôler la cohérence des opérations atomiques pour les objets atomiques
load()et d'augmenter les paramètres , réduisant ainsi lastore()surcharge de synchronisation ;fetch_add()std::memory_order_xxx - (1) Modèle de cohérence séquentielle :
std::memory_order_seq_cst;- Les opérations atomiques de chaque thread satisfont à la cohérence séquentielle ;
- comme:
counter.fetch_add(1, std::memory_order_seq_cst);
-
(2) libérer/acquérir le modèle :
std::memory_order_release;- pour
store(); - Assurez-vous que les opérations de lecture et d'écriture de toutes les variables par le code avant le thread actuel ne se produiront pas après l'opération de libération ;
- Équivalent à une barrière pour les opérations d'écriture ;
- Après la fin de la release de ce thread, toutes les écritures sont visibles pour les autres threads qui imposent une sémantique d'acquisition, car release synchronisera toutes les opérations d'écriture de ce thread en mémoire ;
- Équivalent à l'opération de déverrouillage du mutex, relâchez le verrou après lecture et écriture ;
- pour
std::memory_order_acquire;- pour
load(); - Assurez-vous que les opérations de lecture et d'écriture de toutes les variables par le code après le thread en cours ne se produiront pas avant l'opération d'acquisition ;
- Équivalent à une barrière pour les opérations de lecture ;
- On peut voir que d'autres threads écrivent dans cette variable atomique et dans toutes les variables atomiques précédentes avec une sémantique de libération, car l'acquisition lira la dernière valeur de mémoire dans ce thread ;
- Équivalent à l'opération de verrouillage de mutex, obtenez le verrou puis lisez et écrivez ;
- pour
std::memory_order_acq_rel;- En même temps, il a acquis une sémantique pour la lecture et libéré une sémantique pour l'écriture ;
- Vous pouvez voir toutes les écritures que d'autres threads imposent une sémantique de publication, et en même temps toutes les écritures sont visibles pour les autres threads qui imposent une sémantique d'acquisition après la fin de leur propre publication ;
- Blog de référence : Memory Order (Memory Order) ;
-
Un exemple est le suivant :
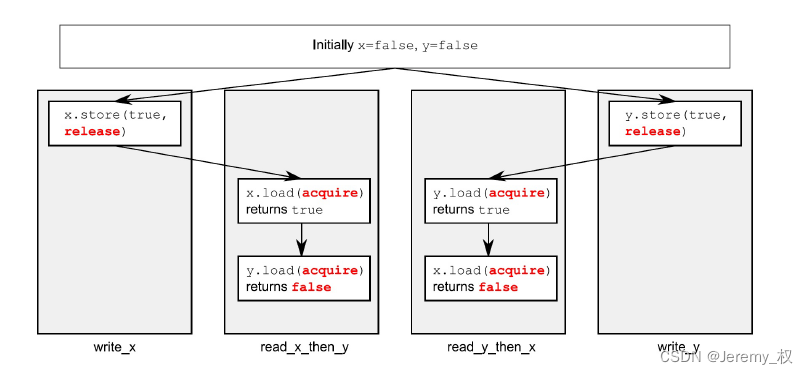
-
Un exemple de code est le suivant :
a = 0;
b = 0;
c = 0;
thread 1:
{
a = 1;
b.store(2, memory_order_relaxed);
c.store(3, memory_order_release);
}
thread 2:
{
while (c.load(memory_order_acquire) != 3)
;
// 以下 assert 永远不会失败
assert(a == 1 && b == 2);
assert(b.load(memory_order_relaxed) == 2);
}
- (3) Modèle rejet/consommation :
std::memory_order_consume;- pour
load(); - Vous pouvez voir toutes les écritures de sémantique de release imposées par d'autres threads sur la variable atomique et les variables atomiques qui ont des dépendances sur la variable atomique ;
- est une version légèrement plus faible de la sémantique d'acquisition pour la lecture ;
- Ce modèle n'est généralement pas recommandé ;
- pour
a = 0;
c = 0;
thread 1:
{
a = 1;
c.store(3, memory_order_release);
}
thread 2:
{
while (c.load(memory_order_consume) != 3)
;
assert(a == 1); // assert 可能失败也可能不失败
}
-
(4) Modèle lâche :
std::memory_order_relaxed;- Les opérations atomiques dans ce thread sont exécutées séquentiellement, mais l'ordre des opérations atomiques dans différents threads est arbitraire ;
-
Certains résumés sont les suivants :



6.3 Blocages tournants
- Il permet d'implémenter des opérations atomiques sur des ressources partagées dans un environnement multi-thread en mode utilisateur Le principe d'implémentation est d'utiliser en même temps des boucles et des fonctions CAS (Compare And Set) ;
- Les verrous tournants n'ont pas besoin d'utiliser réellement des mutex pour verrouiller, et ne sont pas non plus une opération atomique, mais ils peuvent obtenir l'effet d'opérations atomiques;
std::atomicIl y a deux fonctions CAS dans原子变量.compare_exchange_weak(期望值, 设置值):- Comparez la variable atomique avec la valeur attendue, si elles sont égales, rendez la variable atomique égale à la valeur définie et renvoyez vrai ; sinon, mettez à jour la valeur attendue avec la valeur de la variable atomique et renvoyez faux ;
- Il est permis de retourner false lorsque la variable atomique est égale à la valeur attendue car la compétition échoue , car il peut y avoir d'autres threads qui ont également la variable atomique égale à la valeur attendue mais la compétition réussit et modifie la valeur ;
- Faibles exigences de concurrence et plus grande efficacité ;
原子变量.compare_exchange_strong(期望值, 设置值):- Comparez la variable atomique avec la valeur attendue, si elles sont égales, rendez la variable atomique égale à la valeur définie et renvoyez vrai ; sinon, mettez à jour la valeur attendue avec la valeur de la variable atomique et renvoyez faux ;
- Il ne retournera pas faux parce que la compétition échoue, s'il retourne faux, ce doit être parce que la valeur de la variable atomique et la valeur attendue ne sont pas égales ;
- Peut bien résoudre les problèmes de concurrence, mais moins efficacement ;
- Voici quelques explications de leurs différences :

- Un exemple de compteur implémenté avec un spin lock est le suivant :
#include <atomic>
#include <thread>
#include <iostream>
int main() {
std::atomic<int> count(0);
std::thread t1([&]() {
for (int i = 0; i < 1000000; ++i) {
/*以下是计数器自旋锁实现*/
int expected = count.load();
// 尝试将count设置为expected+1
// 如果count == expected则设置成功,返回true
// 否则,将expected设置为为count.load(),返回false
while (!count.compare_exchange_weak(expected, expected + 1)) {
}
}
});
std::thread t2([&]() {
for (int i = 0; i < 1000000; ++i) {
/*以下是计数器自旋锁实现*/
int expected = count.load();
while (!count.compare_exchange_weak(expected, expected + 1)) {
}
}
});
t1.join();
t2.join();
std::cout << "count = " << count.load() << '\n';
return 0;
}
6. Autres
1. long long int
- Type int d'au moins 64 bits ;
[2]. non sauf
-
effet:
- Déclarez que la fonction actuelle ne peut pas lever d'exception ;
- Si la fonction déclarée lève une exception, le programme se termine immédiatement ;
- Capable de prévenir la propagation des anomalies ;
-
utiliser:
函数返回值类型 函数名(函数参数类型) noexcept;Utilisé pour déclarer qu'une fonction ne lèvera pas d'exceptions ;noexcept(表达式)Utilisé pour juger si l'expression est anormale;
// 可能抛出异常的函数
void may_throw() {
throw true;
}
auto non_block_throw = []{
may_throw();
};
// 不抛出异常的函数
void no_throw() noexcept {
return;
}
auto block_throw = []() noexcept {
no_throw();
};
3. Littéraux de chaîne personnalisés
-
effet:
- Évitez d'ajouter beaucoup de caractères d'échappement dans la chaîne, etc. ;
-
utiliser:
R"(字符串)"Définit une chaîne comme un littéral de chaîne ;- La surcharge de l'opérateur de suffixe de guillemet double
""peut personnaliser les littéraux entiers, les littéraux à virgule flottante, les littéraux de chaîne et les littéraux de caractère en tant que littéraux de chaîne ;
// 字符串字面量自定义必须设置如下的参数列表
std::string operator"" _wow1(const char *wow1, size_t len) {
return std::string(wow1)+"woooooooooow, amazing";
}
std::string operator"" _wow2 (unsigned long long i) {
return std::to_string(i)+"woooooooooow, amazing";
}
int main() {
auto str = "abc"_wow1;
auto num = 1_wow2;
std::cout << str << std::endl;
std::cout << num << std::endl;
return 0;
}

4. Contrôler l'alignement de la mémoire
-
effet:
- Interroger ou re-modifier l'alignement de la structure ;
-
utiliser:
alignof(结构体): renvoie la valeur d'alignement effective de la structure ;struct alignas(有效对齐值) 结构体名{};: Modifier la valeur d'alignement effective de la structure, en s'alignant uniquement vers le plus grand ;- Blog de référence : alignof et alignas de C++11 ;
struct alignas(4) stTestAlign // 修改有效对齐值为4字节
{
char a;
char b;
stTestAlign()
{
cout << "sizeof(stTestAlign) =" << sizeof(stTestAlign) << endl; //4
cout << "alignof(stTestAlign) =" << alignof(stTestAlign) << endl; //4
}
};
struct stTestAlign
{
char a;
alignas(4) char b; // char原本是1字节,强制作为4字节对齐
stTestAlign()
{
cout << "sizeof(stTestAlign) =" << sizeof(stTestAlign) << endl; //8
cout << "alignof(stTestAlign) =" << alignof(stTestAlign) << endl; //4
}
};
Supplément : alignement par défaut des classes ou des structures
- Blog de référence : Alignement mémoire C++ ;
- concept:
- Facteur d'alignement du compilateur :
#pragma pack(n), déterminé par le nombre de bits du système et du compilateur, généralement la valeur par défaut est8; - Valeur d'alignement valide : la valeur minimale entre le coefficient d'alignement et la longueur du type de données le plus long de la structure ;
- Si la structure contient un membre du type structure, seule la longueur du type de données le plus long à l'intérieur du membre est prise, c'est-à-dire que la longueur du type de données le plus long de la structure est déterminée par la longueur des données de base les plus longues tapez à l'intérieur ;
- Facteur d'alignement du compilateur :
- Règles d'alignement :
- Le décalage de chaque membre de la structure par rapport à la première adresse de la structure = un multiple entier de min{ valeur d'alignement effective , la longueur du type de données du membre } et l'écart entre les membres augmentera les octets de remplissage ;
- La taille totale de la structure est un multiple entier de la valeur d'alignement effective et l'écart entre les membres augmentera le nombre d'octets de remplissage ;
Sept, fonctionnalités C++20
1. Coroutines
-
définition:
- Les coroutines sont des fonctions qui peuvent être suspendues et reprises plus tard ;
- Il s'agit entièrement d'une opération en mode utilisateur, et le commutateur n'a pas besoin de tomber dans le noyau ;
-
effet:
- Peut éviter l'enfer du rappel, c'est-à-dire que la logique de la fonction de rappel est trop profonde et peu claire ;
- Fonction de rappel : une fonction passée en paramètre à d'autres fonctions pour que d'autres fonctions l'appellent, il peut s'agir d'une fonction ordinaire ou d'une fonction anonyme ;
-
utiliser:
- Les trois mots clés suivants peuvent être utilisés dans la fonction coroutine :
co_await Awaitable结构体: appelez un objet Awaitable, et sa définition interne détermine s'il est suspendu ou poursuivi et le comportement lorsqu'il est suspendu et repris :await_ready(): Demander si la structure Awaitable est prête sans attendre ;await_suspend(): Passez uncoroutine_handletype de paramètre pour suspendre la structure Awaitable ;await_resume(): Appelez cette fonction lorsque la coroutine est en cours de réexécution et renvoyez la valeur en même temps, la promesse de la valeur de retour ;
co_yield: Pause de l'exécution et renvoi d'une valeur ;co_return: termine l'exécution et renvoie une valeur ;
// 用回调函数实现init + 100
using call_back = std::function<void(int)>;
void Add100ByCallback(int init, call_back f) //init是传入的初始值,add之后的结果由回调函数f通知
{
std::thread t([init, f]() {
std::this_thread::sleep_for(std::chrono::seconds(5)); // sleep一下,假装很耗时
f(init + 100); // 耗时的计算完成了,调用回调函数
});
t.detach();
}
// 将回调函数封装成协程结构
struct Add100AWaitable
{
Add100AWaitable(int init):init_(init) {
}
bool await_ready() const {
return false; }
int await_resume() {
return result_; }
void await_suspend(std::experimental::coroutine_handle<> handle)
{
// 定义一个回调函数,在此函数中恢复协程
auto f = [handle, this](int value) mutable {
result_ = value;
handle.resume(); // 这句是关键
};
Add100ByCallback(init_, f);
}
int init_; // 将参数存在这里
int result_; // 将返回值存在这里
};
// 调用协程计算init + 100,可以多次调用
Task Add100ByCoroutine(int init, call_back f)
{
int ret = co_await Add100AWaitable(init);
ret = co_await Add100AWaitable(ret);
ret = co_await Add100AWaitable(ret);
f(ret);
}
- référence:
2. Concepts et contraintes
-
effet:
- Permet au compilateur de juger des paramètres de modèle lors de la compilation, vérifiant et restreignant ainsi l'utilisation des paramètres de modèle ;
-
utiliser:
- utiliser
conceptsdes mots-clés ;
- utiliser
3. module
-
effet:
- Divisez le code en modules individuels ;
-
utiliser:
- Utilisez des mots clés tels que
export,moduleetimport;
- Utilisez des mots clés tels que