Détails du plug-in TensorRT
J'ai encore revu TensorRT-Plugin cette semaine, et cette fois je me suis concentré sur les détails du code. Voici les notes que j'ai prises en intégrant plusieurs bons matériaux et en les partageant.
Une brève introduction à TensorRT :
1) La partie source fermée est la bibliothèque officielle, qui est la partie centrale de TRT ;
2) La partie open source est sur github, incluant Parser (caffe, onnx), Sample et quelques plugins.

Besoin d'écrire 2 classes:
1) MyCustomPlugin, qui hérite de IPluginV2Ext/IPluginV2IOExt/IPluginV2DynamicExt, est une classe de plug-in et est utilisée pour écrire l'implémentation spécifique des plug-ins ;
2) MyCustomPluginCreator, hérité de BaseCreator, est une classe d'usine de plug-in utilisée pour créer le plug-in en fonction des besoins.
class MyCustomPlugin final : public nvinfer1::IPluginV2DynamicExt
class MyCustomPluginCreator : public BaseCreator
Avis:
1) Pour écrire un plugin, vous devez hériter de la classe de base de TRT (la figure ci-dessous est la fonctionnalité de la classe de base) ;
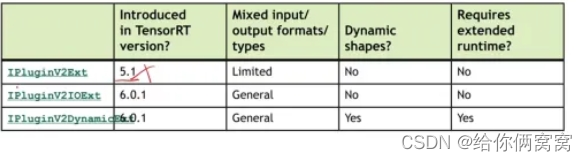
2) Pour la forme statique, utilisez IPluginV2IOExt ; pour la forme dynamique, utilisez IPluginV2DynamicExt.
API de plug-in de forme statique
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias); // 构造函数,用于网络定义阶段
MyCustomPlugin(void const* serialData, size_t serialLength); // 构造函数,用于反序列化阶段
int getNbOutputs() const; // 获得layer的输出个数
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims); // 获得layer的输出维度
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const; // 获得输出数据类型
size_t getSerializationSize() const; //返回序列化时需要写多少字节到buffer中
void serialize(void* buffer) const; //序列化函数,将plugin的参数权值写入到buffer中
const char* getPluginType() const; // 获得plugin的type,用于反序列化使用
const char* getPluginVersion() const; //获得plugin的version,用于反序列化使用
int initialize(); // 初始化函数,在这个插件准备开始run之前执行。一般申请权值显存空间并copy权值
void terminate(); // terminate函数就是释放initialize开辟的一些显存空间
void destroy(); // 释放整个plugin占用的资源
void configurePlugin(const nvinfer1::PluginTensorDesc* in, int nbInput, const nvinfer1::PluginTensorDesc* out, int nbOutput); // 判断输入是否符合标准
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const; // 判断输入、输出的格式
size_t getworkspaceSize(int maxBatchSize) const; // 获得plugin所需要的显存大小
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* * workspace, cudaStream_t stream); // 推理函数
const char* setPluginNamespace() const; // 为这个插件设置namespace名字,每个plugin定义1个专属的Namespace,如果不设置则默认是"",需要注意的是同一个namespace下的plugin如果名字相同会产生冲突
const char* getPluginNamespace() const; // 获取plugin的命名空间
const PluginFieldCollection *GridAnchorBasePluginCreator::getFieldNames(); // PluginFieldCollection的主要作用是传递插件op所需要的权重和参数
void attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator); // 将plugin附加到执行上下文,并授予plugin对某些上下文资源的访问权限
void detachFromContext(); // 将插件对象从其执行上下文中分离出来
constructeur et destructeur
Constructeur
Le constructeur peut écrire 1~3, généralement le premier correspond à def, le second correspond à clone et le troisième correspond à la sérialisation.
1. Pour l'étape de définition du réseau, le constructeur appelé par PluginCreator lors de la création du plugin doit transmettre des informations de poids et des paramètres. Il peut également être utilisé dans la phase de clonage ou écrire un constructeur de clone.
MyCustomPlugin(int in_channel, nvinfer1::Weights const& weight, nvinfer1::Weights const& bias);
2. Clone : Comme son nom l'indique, il s'agit de cloner et cloner cet objet plugin vers le constructeur, le réseau ou le moteur de TensorRT. Cette fonction membre appelle le constructeur suivant :
MyCustomPlugin(float in_channel, const std::vector<float>& weight, const std::vector<float>& bias);
Passez les poids et les paramètres du plugin à cloner à ce constructeur.
IPluginV2DynamicExt* MyCustomPlugin::clone() const
{
auto plugin = new MyCustomPlugin{_in_channel, _weight, _bias};
plugin->setPluginNamespace(mPluginNamespace);
return plugin;
}
La fonction de membre clone est principalement utilisée pour transmettre des poids et des paramètres constants, et pour copier le plugin n copies afin qu'il puisse être utilisé par différents moteurs, constructeurs et réseaux.
3. Il est utilisé dans l'étape de désérialisation pour transmettre les poids et les paramètres sérialisés au plug-in et le créer.
MyCustomPlugin(void const* serialData, size_t serialLength);
Notez que le constructeur par défaut doit être supprimé ;
MyCustomPlugin() = delete;
destructeur
Le destructeur doit exécuter terminate, et la fonction terminate est de libérer de l'espace mémoire ouvert avant cette opération ;
MyCustomPlugin::~MyCustomPlugin(){
terminate();
}
Fonctions liées aux sorties
1. Obtenir le numéro de sortie de la couche
int getNbOutputs() const;
2. Selon le nombre d'entrées et les dimensions d'entrée, obtenez la dimension de la sortie d'index
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims);
3. Selon le numéro d'entrée et le type d'entrée, obtenez le type de sortie d'index
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const;
Fonctions liées à la sérialisation et à la désérialisation
1. Combien d'octets doivent être écrits dans le tampon lors du retour de la sérialisation
size_t MyCustomPlugin::getSerializationSize() const
{
return (serialized_size(_in_channel) + serialized_size(_weight) + serialized_size(_bias));
};
2. La fonction de sérialisation écrit le poids du paramètre du plugin dans le tampon
void MyCustomPlugin::serialize(void* buffer) const
{
serialize_value(&buffer, _in_channel);
serialize_value(&buffer, _weight);
serialize_value(&buffer, _bias);
};
3. Si cette opération utilise d'autres éléments, tels que le handle cublas, vous pouvez directement utiliser le handle cublas fourni par TensorRT :
void MyCustomPlugin::attachToContext(cudnnContext* cudnnContext, cublasContext* cublasContext, IGpuAllocator* gpuAllocator)
{
mCublas = cublasContext;
}
4. Obtenir le type et la version du plugin pour la désérialisation
const char* getPluginType() const;
const char* getPluginVersion() const;
Fonctions d'initialisation, de configuration, de destruction
Fonction d'initialisation, exécutée avant que ce plugin ne soit prêt à fonctionner. S'applique généralement à l'espace mémoire de poids et au poids de copie
int initialize();
La fonction terminate consiste à libérer de l'espace mémoire vidéo ouvert par initialize
void terminate();
Libérer les ressources occupées par l'ensemble du plugin
void destroy();
Configurez le plug-in op de configurePlugin pour déterminer si le nombre de types d'entrée et de sortie est correct. Le responsable a également mentionné que grâce à ces informations de configuration, TensorRT peut être informé pour sélectionner l'algorithme approprié (algorithme) pour régler le modèle. Cependant, le réglage automatique n'a pas encore été essayé. Généralement, le code d'exécution du plugin écrit par soi-même est fixe. Les soi-disant étapes de réglage peuvent être plus destinées à l'op officiel.
void MyCustomPluginDynamic::configurePlugin(const nvinfer1::DynamicPluginTensorDesc* inputs, int nbInputs, const nvinfer1::DynamicPluginTensorDesc* outputs, int nbOutputs)
{
assert(nbOutputs == 1);
assert(nbInputs == 2);
assert(mType == inputs[0].desc.type);
};
TensorRT appelle cette méthode pour déterminer si l'entrée/sortie de l'index pos prend en charge le format/type de données spécifié par inOut[pos].format et inOut[pos].type. Si le plugin prend en charge le format/type de données à inOut[pos], le plugin peut faire dépendre son résultat du format/type de données dans inOut[0...pos-1], qui sera défini sur une valeur prise en charge par le plugin. Cette fonction n'a pas besoin de vérifier inOut[pos + 1...nbInputs + nbOutputs - 1], la décision de pos doit être basée uniquement sur inOut[0...pos].
bool MyCustomPlugin::supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs)
{
// 假设有一个输入和一个输出
assert(0 <= pos && pos < 2);
const auto *in = inOut;
const auto *out = inOut + nbInputs;
switch(pos){
case 0:
return in[0].type == DataType::kFLOAT && in[0].format == nvinfer1::TensorFormat::kLINEAR;
case 1:
return out[0].type == in[0].type && out[0].format == nvinfer1::TensorFormat::kLINEAR;
}
};
Exécuter les fonctions associées
1. Obtenez la taille de mémoire vidéo requise par le plug-in. Il est préférable de ne pas utiliser cudaMalloc pour demander de la mémoire vidéo dans le plugin enqueue .
size_t getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs, int nbInputs, const nvinfer1::PluginTensorDesc* outputs, int nbOutputs) const{
// 计算这个op前向过程中需要的中间显存数量
size_t need_num;
return need_num * sizeof(float);
};
2. Fonction d'inférence
int enqueue(int batchSize, const void* const* inputs, void** outputs, void *workspace, cudaStream_t stream){
// 假设这个fun是需要的中间变量,可以直接使用TensorRT开辟的显存空间
fun = static_cast<float*>(workspace);
};
Il est à noter que si certaines variables intermédiaires distribuées dans la mémoire vidéo sont nécessaires lors de l'opération, elles peuvent être obtenues via l'espace de travail du paramètre de pointeur passé. Le .cu écrit par défaut est fp32. TensorRT passe automatiquement en mode fp32 lorsqu'il s'exécute sur un plug-in qui ne prend pas en charge fp16 en mode d'exécution fp16, puis revient une fois le plug-in en cours d'exécution.
Vous pouvez définir un espace de travail maximal pour éviter la suppression de la mémoire vidéo et pouvez réutiliser la mémoire vidéo. Si cudaMalloc est utilisé pour demander de la mémoire vidéo dans la couche précédente, la couche suivante ne peut pas être utilisée (la raison spécifique doit être clarifiée) . De plus, la valeur de poids n'est généralement pas réutilisée, donc la valeur de poids ne sera pas placée dans l'espace de travail et sera appliquée pour l'utilisation de cudaMalloc.
La dimension N dans la forme statique est variable et inférieure à la taille de lot maximale.
Prenons l'un des exemples officiels, la fonction de mise en file d'attente dans lReluPlugin.cpp comme exemple :
La formule de leakyRelu est la suivante :

int LReLU::enqueue(int batchSize, const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept
{
const void* inputData = inputs[0];
void* outputData = outputs[0];
pluginStatus_t status = lReLUInference(stream, mBatchDim * batchSize, mNegSlope, inputData, outputData);
return status;
}
La fonction correspondante du noyau CUDA se trouve dans lReLU.cu, et j'y ai ajouté des commentaires pour votre compréhension :
template <unsigned nthdsPerCTA>
__launch_bounds__(nthdsPerCTA) __global__ void pReLUKernel(const int n, const float negativeSlope, const float* input, float* output)
{
// blockIdx.x表示当前线程块在线程格里x维度上的索引;nthdsPerCTA即blockDim.x,表示当前线程块中x维度上所有线程的个数;
// threadIdx.x表示当前线程在线程块里x维度上的索引;gridDim.x表示当前线程格中x维度上所有线程块的个数;
// i += gridDim.x * nthdsPerCTA,代表步长为gridDim.x * nthdsPerCTA,即1个线程格里的所有线程数。
for(int i = blockIdx.x * nthdsPerCTA + threadIdx.x; i < n; i += gridDim.x * nthdsPerCTA)
{
//negativeSlope就是系数阿尔法
output[i] = input[i] > 0 ? input[i] : input[i] * negativeSlope;
}
}
pluginStatus_t lReLUGPU(cudaStream_t stream, const int n, const float negativeSlope, const void* input, void* output)
{
// 这个n就是控制leakyRelu输出个数的变量
const int BS = 512;
const int GS = (n + BS - 1) / BS;
// <BS>是模板参数,表示使用的线程块大小,可以传给内核函数pReLUKernel()
pReLUKernel<BS><<<GS, BS, 0, stream>>>(n, negativeSlope, (const float*) input, (float*) output);
return STATUS_SUCCESS;
}
pluginStatus_t lReLUInference(cudaStream_t stream, const int n, const float negativeSlope, const void* input, void* output)
{
return lReLUGPU(stream, n, negativeSlope, (const float*) input, (float *) output);
}
Fonctions liées à IPluginCreator
Aperçu:
class MyCustomPluginCreator : public BaseCreator
{
public:
MyCustomPluginCreator();
~MyCustomPluginCreator() override = default;
const char* getPluginName() const override;
const char* getPluginVersion() const override;
const PluginFieldCollection* getFieldNames() override;
IPluginV2DynamicExt* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) override;
IPluginV2DynamicExt* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
}
Obtenir le nom et la version du plugin pour identifier le créateur
const char* getPluginName() const;
const char* getPluginVersion() const;
Créer un plugin via PluginFieldCollection
Sortez les poids et les paramètres requis par l'op un par un, puis appelez le premier constructeur mentionné ci-dessus :
const nvinfer1::PluginFieldCollection* getFieldNames();
IPluginV2DynamicExt* MyCustomPlugin::createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc)
{
int in_channel;
std::vector<float> weight;
std::vector<float> bias;
const PluginField* fields = fc ->fields;
for (int i = 0; i < fc ->nbFields; ++i)
{
const char* attrName = fields[i].name;
if (!strcmp(attrName, "in_channel"))
{
ASSERT(fields[i].type == PluginFieldType::kINT32);
in_channel = *(static_cast<const int32_t*>(fields[i].data));
}
else if (!strcmp(attrName, "weight"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_weight.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
h_weight.push_back(*w);
w++;
}
}
else if(!strcmp(attrName, "bias"))
{
ASSERT(fields[i].type == PluginFieldType::kFLOAT32);
int size = fields[i].length;
h_bias.reserve(size);
const auto* w = static_cast<const float*>(fields[i].data);
for (int j = 0; j < size; j++)
{
h_bias.push_back(*w);
w++;
}
}
}
Weights weightWeights{DataType::kFLOAT, weights.data(), (int64_t) weight.size()};
Weights biasWeights{DataType::kFLOAT, bias.data(), (int64_t) _bias.size()};
MyCustomPlugin* obj = new MyCustomPlugin(in_channel, weightWeights, biasWeights);
obj -> setPluginNamespace(mNamespace.c_str());
return obj;
}
PluginFieldCollection est une variable membre et sera également utilisée comme type de retour de la fonction membre getFieldNames. La fonction principale de PluginFieldCollection est de transmettre les pondérations et les paramètres requis par le plug-in op, qui ne sont pas utilisés dans le processus de raisonnement réel du moteur, mais seront utilisés dans l'analyse (comme caffe2trt, onnx2trt).
Lors de l'utilisation de ces analyses pour analyser cette opération, les poids et les paramètres de cette opération passeront par le processus Modèles -> Moteur TensorRT -> Exécution TensorRT.
Par exemple, dans onnx-tensorrt, utilisez DEFINE_BUILTIN_OP_IMPORTER pour enregistrer l'op, puis analysez le modèle onnx via l'analyse, puis analysez et construisez le modèle un par un en fonction de l'op enregistré. En supposant que l'op défini est my_custom_op, il ressemblera comme ceci dans DEFINE_BUILTIN_OP_IMPORTER(my_custom_op) accomplir :
DEFINE_BUILTIN_OP_IMPORTER(my_custom_op)
{
ASSERT(inputs.at(0).is_tensor(), ErrorCode::kUNSUPPORTED_NODE);
...
const std::string pluginName = "CUSTOM-OP";
const std::string pluginVersion = "001";
// f保存这个op需要的权重和参数,从onnx模型中获取
std::vector<nvinfer1::PluginField>f;
f.emplace_back("in_channel", &in_channel, nvinfer1::PluginFieldType::kINT32, 1);
f.emplace_back("weight", kernel_weights.values, nvinfer1::PluginFieldType::kFLOAT32, kernel_weights.count());
f.emplace_back("bias", bias_weights.values, nvinfer1::PluginFieldType::kFLOAT32, bias_weights.count);
// 从plugin工厂中获取该插件,并且将权重和参数传递进去
nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name(), f);
RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(tensors.data(), tensors.size(), *plugin));
}
En entrant dans la fonction importPluginFromRegistry, vous pouvez constater que les paramètres sont transmis au plugin via la variable fc via createPlugin :
nvinfer1::IPluginV2* importPluginFromRegistry(IImporterContext* ctx, const std::string& pluginName, const std::string& pluginVersion, const std::string& nodeName, const std::vector<nvinfer1::PluginField>& pluginFields)
{
const auto mPluginRegistry = getPluginRegistry();
const auto pluginCreator = mPluginRegistry->getPluginCreator(pluginName.c_str(), pluginVersion.c_str(),"ONNXTRT_NAMESPACE");
if(!pluginCreator)
{
return nullptr;
}
// 接受传进来的权重和参数信息,传递给plugin
nvinfer1::PluginFieldCollection fc;
fc.nbFields = pluginFields.size();
fc.fields = pluginFields.data();
return pluginCreator->createPlugin(nodeName.c_str(), &fc);
}
Dans les étapes ci-dessus, le pluginName et pluginVersion seront fournis pour initialiser MyCustomPluginCreator, et la fonction membre createPlugin est ce que nous devons écrire.
Créez un mPluginAttributes vide pour initialiser mFC :
MyCustomPluginCreator::MyCustomPluginCreator()
{
mPluginAttributes.emplace_back(PluginField("in_channel", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("weights", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("bias", nullptr, PluginFieldType::kFLOAT32, 1));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
Désérialisation, appeler le constructeur de désérialisation, générer le plugin
nvinfer1::IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength);
Cette fonction sera appelée par une opération de conversion appelée TRT_IPluginV2 de onnx-tensorrt. Cette opération lira les données du modèle onnx et les désérialisera dans le réseau.
Le nom ici est le même que le type précédent ; le createPlugin ici doit écrire le contenu de la création par lui-même, puis l'appeler par lui-même. La fonction Create peut être utilisée pour encapsuler l'interface et fournir une bibliothèque au monde extérieur sans exposer la conception du plugin au monde extérieur. L'essentiel est d'appeler le constructeur en passant les paramètres de structure.
API de plug-in de forme dynamique
Fonctions différentes de la forme statique
lot statique implicite (implicite) vs lot dynamique explicite (explicite)
1. Selon le nombre d'entrées et la dimension d'entrée dynamique, obtenir la dimension dynamique de la sortie index-th
statique
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* inputs, int nbInputDims);
dynamique
nvinfer1::DimsExprs getOutputDimensions(int outputIndex, const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder);
2. enqueue et getWorkspaceSize ont plus d'informations d'entrée et de sortie, de types de dimension, etc.
statique
int enqueue(int batchSize, const void* const* inputs, void** outputs, void *workspace, cudaStream_t stream);
dynamique
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc, const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream);
L'implicite et l'explicite ne se rencontrent que dans les plugins.
Le lot implicite de forme statique signifie que la valeur de ce lot est transmise par mise en file d'attente, que les dimensions restantes sont déterminées et que le lot est dynamique. Dans la forme statique, dans le raisonnement de TRT, le lot ne peut pas être obtenu, et le paramètre d'entrées de getOutputDimensions n'aura que CHW, qui est un tableau avec des valeurs et des dimensions claires. Pour la fonction enqueue, ce sont toutes des valeurs explicites.
Le lot explicite de la forme dynamique se trouve dans la fonction getOutputDimensions et le paramètre d'entrée est NCHW, qui a des valeurs de ces dimensions. La valeur de la dimension d'entrée de la forme dynamique est incertaine et la relation entre l'entrée et la sortie est déterminée par exprBuilder, ce qui équivaut à un opérateur arithmétique à quatre pour l'inférence de forme. Pour la fonction de mise en file d'attente, comme ce sont toutes des valeurs incertaines, une description de l'entrée et de la sortie est requise .
Statique signifie que les informations de forme peuvent être obtenues à l'avance, tandis que la dynamique ne peut être obtenue qu'au moment de l'exécution.
PluginCreatorRegistration
Lors du chargement du fichier d'en-tête NvInferRuntimeCommon.h, vous obtiendrez un getPluginRegistry, qui contient tous les IPluginCreators enregistrés, et obtiendrez l'IPluginCreator correspondant via la fonction getPluginCreator lors de son utilisation.
Il existe deux manières de s'inscrire :
1. Appelez l'API pour vous inscrire
extern "C" {
bool initLibNvInferPlugins(void* logger, const char* libNamespace)
{
initializePlugin<nvinfer1::plugin::GridAnchorPluginCreator>(logger, libNamespace);
initializePlugin<nvinfer1::plugin::NMSPluginCreator>(logger, libNamespace);
initializePlugin<nvinfer1::plugin::ReorgPluginCreator>(logger, libNamespace);
...
return true;
}
}
La fonction initializePlugin exécute la fonction addPluginCreator :
template <typename CreatorType>
void initializePlugin(void* logger, const char* libNamespace)
{
PluginCreatorRegistry::getInstance().addPluginCreator<CreatorType>(logger, libNamespace);
}
La fonction addPluginCreator exécute getPluginRegistry() -> registerCreator pour enregistrer pluginCreator, complétant ainsi la tâche d'enregistrement :
void addPluginCreator(void* logger, const char* libNamespace)
{
...
if(mRegistryList.find(pluginType) == mRegistryList.end())
{
bool status = getPluginRegistry()->registerCreator(*pluginCreator, libNamespace);
if (status)
{
mRegistry.push(std::move(pluginCreator));
mRegistryList.insert(pluginType);
verboseMsg = "Plugin creator registration succeeded - " + pluginType;
}
else
{
errorMsg = "Could not register plugin creator: " + pluginType;
}
}
else
{
verboseMsg = "Plugin creator already registered - " + pluginType;
}
...
}
2. Enregistrez-vous directement via REGISTER_TENSORRT_PLUGIN :
// 在加载'NvinferRuntimeCommon.h'头文件的时候会得到一个'getPluginRegistry'
extern "C" TENSORRTAPI nvinfer1::IPluginRegistry* getPluginRegistry();
namespace nvinfer1
{
template <typename T>
class PluginRegistrar{
public:
PluginRegistrar() {getPluginRegistry()->registerCreator(instance, "");}
private:
T instance{};
};
#define REGISTER_TENSORRT_PLUGIN(name) \
static nvinfer1::PluginRegistrar<name> pluginRegistrar##name {}
}
C'est-à-dire que si nous avons implémenté REGISTER_TENSORRT_PLUGIN(BatchedNMSPluginCreator) dans le fichier .h du plugin, il n'est pas nécessaire de créer une fonction similaire à l'officiel initLibNvInferPlugins() pour s'enregistrer un par un.
Lorsque la bibliothèque TRT est chargée, une variable globale sera obtenue, et lorsque le programme démarrera, elle sera enregistrée dans la variable globale.
Comment utiliser le PluginCreator enregistré ?
class IPluginRegistry{
public:
virtual bool registerCreator(IPluginCreator& creator, const char* pluginNamespace) noexcept = 0;
virtual IPluginCreator* const* getPluginCreatorList(int* numCreators) const noexcept = 0;
virtual IPluginCreator* getPluginCreator(const char* pluginType, const char* pluginVersion, const char* pluginNamespace = "") noexcept = 0;
}
Lorsque TRT C'est la raison de l'enregistrement.Ce n'est qu'après l'enregistrement que le plugin peut être automatiquement désérialisé en ligne pour exécuter le plugin, sinon il ne sera pas trouvé.
Comment appeler le plugin écrit par moi-même ?
Utilisez la fonction addPluginV2, par exemple :
IPluginV2Layer* embLayer = network->addPluginV2(inputs, 3, embPlugin);
Plugin TensorRT de débogage-débogage ?
TRT est un logiciel à source fermée et son API est relativement compliquée.
Dans quelles circonstances dois-je déboguer le plugin TensorRT ?
1) Que le réseau soit construit à l'aide d'une API ou d'un analyseur, une fois le modèle converti, l'erreur de résultat est très importante ;
2) Ajout d'un plugin personnalisé pour implémenter la fusion des opérateurs, mais les résultats ne sont pas corrects ;
3) Après avoir utilisé la stratégie d'optimisation FP16 ou INT8, la précision de l'algorithme chute beaucoup.
Les réseaux réguliers et les réseaux bien formés conviennent à l'optimisation int8, et le reste peut perdre beaucoup de précision.
Plusieurs méthodes de débogage sont recommandées :
1. Utilisez l'analyseur pour convertir le réseau et utilisez l'interface API de vidage pour vérifier si la structure du réseau est correcte ;
2. Si vous utilisez le plugin, vous devez écrire des tests unitaires ;
3. Méthode générale, sortie d'impression :
1) Suggestion officielle : régler la sortie de la couche suspecte sur la sortie réseau (relativement fatiguant) ;
2) La méthode de l'auteur : ajouter un plugin de débogage. Lien : https://github.com/LitLeo/TensorRT_Tutorial/tree/master/resource_for_billibilli/debug_plugin
Plugin TensorRT converti en FP16 :
S'il n'y a pas de Plugin dans le réseau, la conversion de FP32 à FP16 peut être réalisée en appelant directement le code suivant :
config->setFlag(BuilderFlag::kFP16);
builder->platformHasFastFp16(); // 判断平台是否支持FP16
builder->platformHasFastInt8(); // 判断平台是否支持Int8
S'il y a des plugins dans le réseau, vous devez faire attention à ce qui suit :
1) Choses à faire attention lors de l'écriture de plugin :
(1) La fonction Enqueue doit ajouter une demi-version ;
(2) Faites attention à la fonction supportsFormatCombination. Assurez-vous que les types d'entrée et de sortie sont cohérents et exigez que les types d'entrée et de sortie soient cohérents avec mType.
2) Pour le modèle fp16, l'entrée est-elle définie sur type flottant ou demi-type ?
Tout fonctionne, mais la suggestion est de définir l'entrée sur flottante.
3) Le modèle doit être formé avec une précision mitigée, sinon des problèmes de débordement peuvent survenir.
Exemple de code : https://github.com/NVIDIA/TensorRT/blob/7.2.1/plugin/skipLayerNormPlugin/skipLayerNormPlugin.cpp
Lien de référence :
https://zhuanlan.zhihu.com/p/567244140
https://www.bilibili.com/video/BV19Y411g7YY/?spm_id_from=333.999.0.0&vd_source=8002c1ea19b925cd4fa92e8ddf798043
https://zhuanlan.zhihu.com/p/297002406
https://github.com/nvidia/TensorRT