Table des matières
Collecte de déchets JVM
Pourquoi le ramasse-miettes : Java n'est pas comme les instructions C, vous devez ouvrir de l'espace à travers le code lorsque vous l'utilisez, et le détruire manuellement après utilisation. Java fournit une machine virtuelle pour notre programme, afin que nous accordions plus d'attention à la logique métier lors de l'écriture du code. Quant au développement de l'espace mémoire, libérez-le sur la JVM. Le code s'exécute sur la JVM, et la JVM identifiera laquelle est une poubelle via l'algorithme, puis libérera automatiquement l'espace inutilisé dans le programme via l'algorithme de récupération de place. Langage C, C++ est comme la transmission manuelle, Java est comme la transmission automatique.
GC: Garbage Collection 垃圾收集, le ramasse-miettes de la jeune génération est aussi appelé GC, et le ramasse-miettes de l'ancienne génération est appelé Full GC.
Qu'est-ce que les ordures
Lorsqu'un programme est en cours d'exécution, il a besoin d'ouvrir de l'espace en mémoire pour stocker des données. Mais après que cet espace est utilisé une fois, il ne peut plus jamais être utilisé.Sans adresse pointant vers lui, le programme ne peut pas utiliser le contenu de stockage de cet espace d'adressage, comme un fantôme dans la mémoire. Mais ces données existent vraiment en mémoire, ce qui est des ordures. Lorsqu'un programme Java est écrit, il n'ouvrira que de l'espace mais ne le libérera pas, ce qui entraînera trop d'espace mémoire occupé par des données inutiles dans la mémoire, ce qui réduira un peu la mémoire disponible réelle du programme, et éventuellement entraîner un débordement de mémoire.
Ci-dessous, prenez une liste chaînée pour supprimer un nœud à titre d'exemple, le nœud supprimé est une poubelle
public class Application {
public static void main(String[] args) {
// 创建三个节点
Node n1 = new Node("张三");
Node n2 = new Node("李四");
Node n3 = new Node("王五");
// 将3个节点连接起来,形成 n1->n2->n3
n1.next=n2;
n2.next=n3;
// 遍历链表
Node node=n1;
while (node!=null){
System.out.println(node.data);
node=node.next;
}
// 删除一个节点 将中间的节点删除
n1.next=n3;
n3.pre=n1;
n2=null;
// 遍历链表
node=n1;
while (node!=null){
System.out.println(node.data);
node=node.next;
}
}
}
@Data
class Node{
Node pre;
Node next;
Object data;
public Node(Object data){
this.data=data;
}
}
Réflexion : le nœud n2 est-il inutile ? Alors qu'est-ce qui prend encore de la place ?
Liste chaînée d'origine :
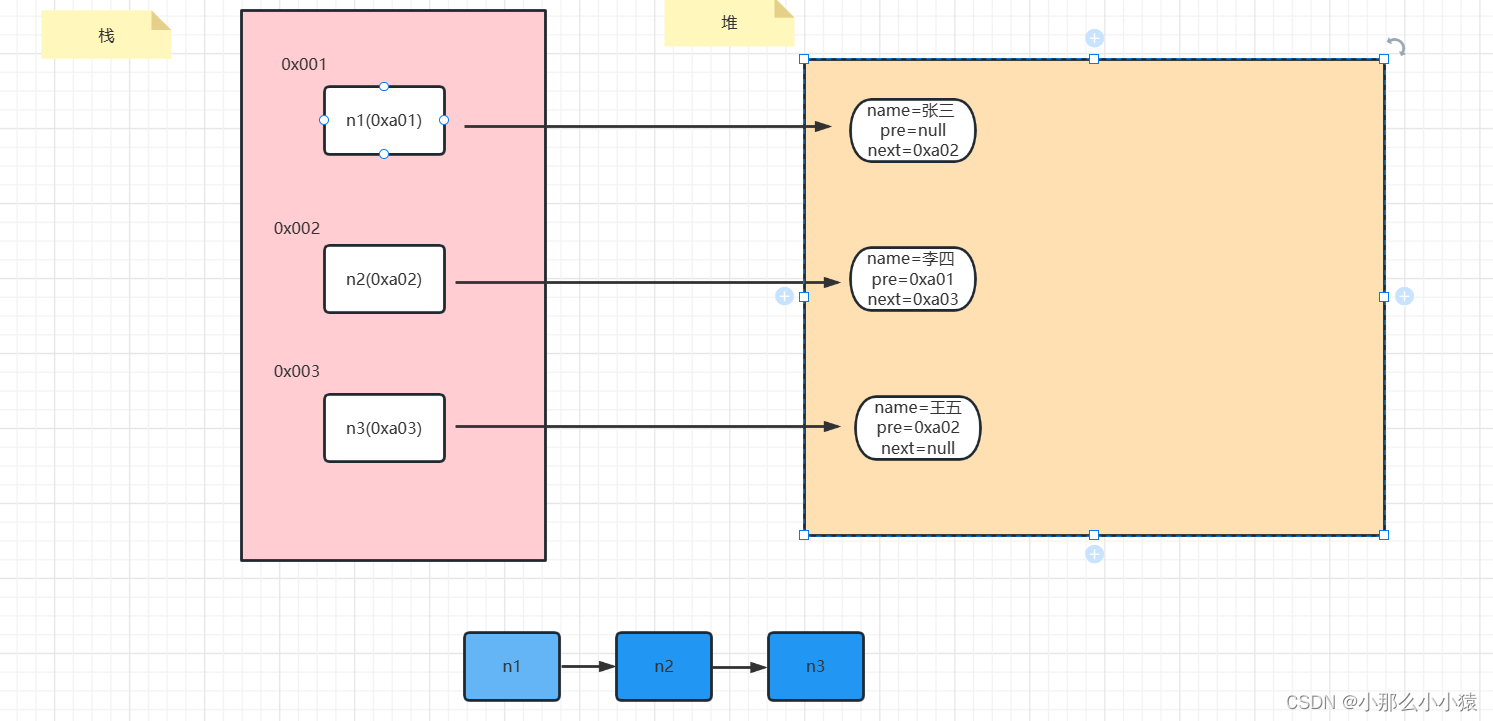
Après avoir supprimé le nœud n2 : nous savons déjà que n2 est une poubelle, mais contrairement à C, Java ne peut pas gérer manuellement l'espace de libération de la mémoire. Mais la JVM reconnaîtra automatiquement les ordures et les publiera pour nous.
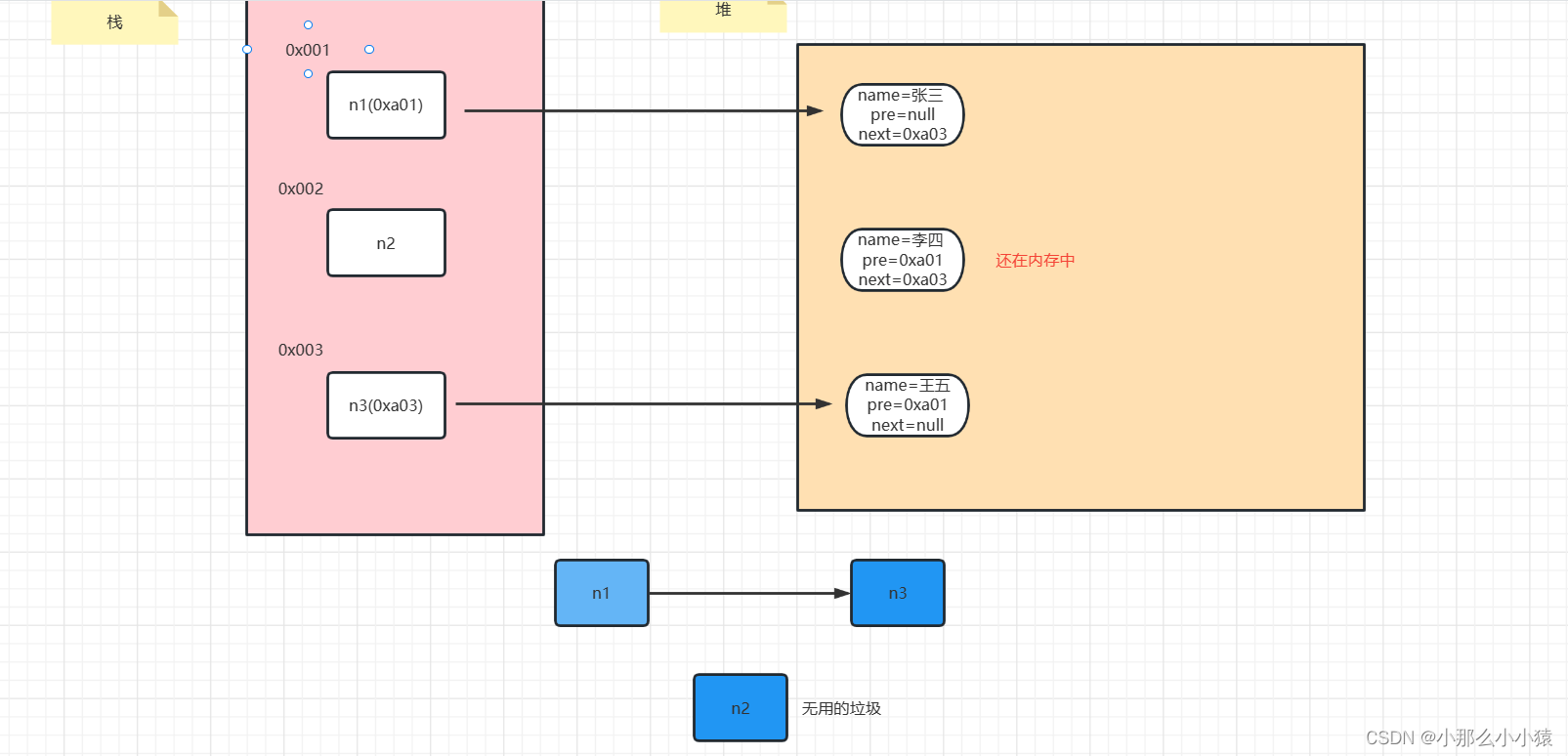
À ce moment, la JVM reconnaîtra que n2 est une poubelle via l'algorithme (analyse d'accessibilité), et finalement récupérera l'espace mémoire où il se trouve
La zone et la portée de la collecte des ordures
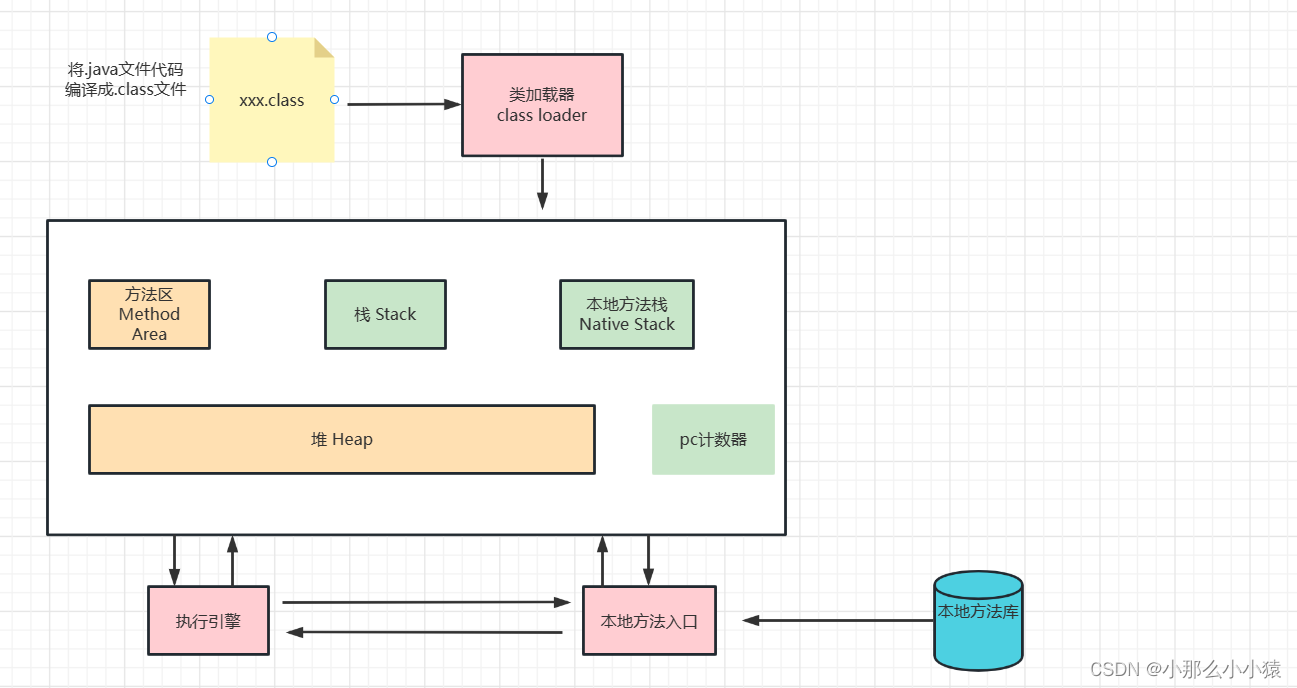
Comme le dit le dicton : la pile fonctionne, le tas stocke et le tas prend le plus de place. GC est responsable du ramasse-miettes de la zone de méthode et du tas, mais principalement du tas. D'autres zones occupent très peu d'espace et ne produiront pas de déchets.
Étant donné que le tas est l'endroit principal pour la collecte des ordures, ignorons d'abord une série de problèmes dans la collecte des ordures, puis introduisons la structure logique spécifique du tas et comment les ordures sont transportées dans le tas.
Collection générationnelle
Le ramasse-miettes GC est très susceptible d'être recyclé plus d'une fois, et la même zone de mémoire peut ne pas être ratée lors du premier ramasse-miettes, mais elle l'est lors du second. Comment analyser efficacement les ordures, supprimer efficacement les ordures et ne pas affecter le fonctionnement normal de la JVM autant que possible, GC divise logiquement l'espace de tas en trois générations (physiquement en mémoire), à savoir la nouvelle génération, l'ancienne génération et l'espace yuan (génération permanente avant JDK7). La JVM stockera les informations dans ces trois domaines d'une manière qui leur est propre en fonction des caractéristiques des domaines 分代管理. Par exemple: GC (YoungGC) est effectué dans la jeune génération et FullGC est effectué dans l'ancienne génération.
Il existe deux idées principales de collection générationnelle :
- La plupart des sujets vivent et meurent
- Les objets qui survivent à plus de récupérations de place sont moins susceptibles de devenir des ordures
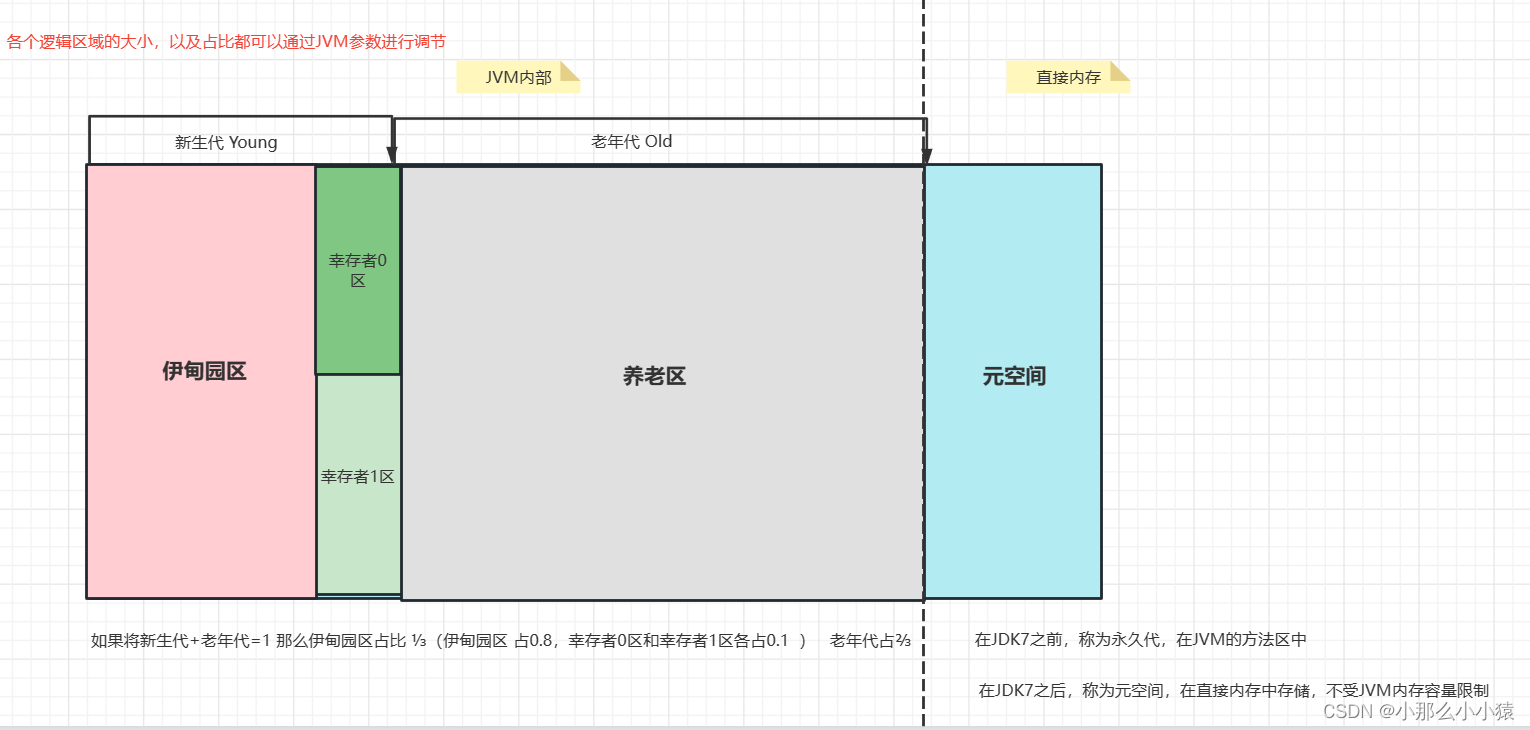
Ensuite, je décrirai comment ces zones se coordonnent et fonctionnent dans le ramasse-miettes réel et pourquoi elles sont divisées de cette manière : les
objets de classe que nous avons créés au début seront placés dans la zone Eden (Eden) au début, car les objets créés deviennent de plus en plus De plus, s'il n'y a pas d'espace pour stocker les objets nouvellement créés dans Eden, alors YoungGC sera déclenché. YongGC est déclenché pour la première fois : il va scanner toutes les ordures de la zone Eden et de la zone de départ du survivant (la zone de provenance est vide à ce moment-là), puis les transférer dans la zone de 不是垃圾destination 复制du zone de survivant, puis 清空Eden区toutes les données de la zone de survivant seront expérimentées en même temps. Après une analyse GC, l'âge du contenu jugé comme n'étant pas une poubelle est de +1.
Après le premier GC, l'état actuel de l'espace du tas : la zone Eden est vide et la zone à des survivants contient une petite quantité de données survivantes. L'âge de ces données est de +1 et la zone à est convertie en zone de départ. La zone est convertie en zone de destination et la zone de destination est vide à ce stade. Étant donné que l'espace est libéré après un GC, les objets nouvellement créés seront placés dans la zone Eden, et de plus en plus d'objets seront créés au fur et à mesure que le programme s'exécute. Lorsque Eden est à nouveau plein, le deuxième GC sera déclenché. (Remarque : et cette fois l'une des zones survivantes est vide, c'est-à-dire la zone vers) GC scannera la 和幸存者from区partie de la zone Eden qui n'est pas une poubelle, puis copiera cette partie dans une autre zone survivante vide vers la zone, et en même temps le temps ne fera pas vieillir les données de Garbage +1 à nouveau. Étant donné que l'espace est libéré après un GC, les objets nouvellement créés sont ensuite placés dans la zone Eden et le cycle se répète.
Jusqu'à un certain temps (au moins après 15 GCs), puisque l'âge de chaque donnée qui n'est pas considérée comme poubelle sera de +1, jusqu'à ce que l'âge de certaines données atteigne 15 ans (peut être modifié en configurant les paramètres JVM), à cette fois, les données qui ont atteint 15 ans ont déjà Après 15 GC, le système estime que ces données auront une faible probabilité de devenir des ordures à l'avenir, et il faut du temps et des efforts pour les déplacer d'avant en arrière à chaque fois, donc les données sont mises dans l'ancienne génération. Lorsque YoungGC est déclenché, l'ancienne génération n'est pas impliquée.
Le processus de la nouvelle génération est comme ça, le résumé est复制+1->清空->互换. Copiez les données qui ne sont pas des ordures dans la zone de survivant vide (en supposant que la zone 0, à ce moment la zone 0 est la zone à) et l'âge de ces données +1, puis effacez la zone Eden et la zone de survivant qui n'était pas vide avant copie (en supposant que la zone 1 , à ce moment la zone 1 est la zone de départ), puis échangez la zone de départ avec la zone de destination. À ce moment, la zone 0 est la zone de départ et la zone 1 est la zone de destination. Échangez à nouveau au prochain GC.
Ensuite, tournez-vous vers les données dont l'âge a atteint 15 fois dans l'ancienne zone. Chaque GC qui se produit dans la jeune génération ne sera pas affecté ici, mais il est possible que de nouvelles données soient ajoutées après le GC. Avec des GC fréquents, de nouvelles données sont constamment ajoutées, et le système prédira à l'avance si l'espace de l'ancienne génération sera plein (la valeur moyenne de chaque nouvelle donnée > l'espace restant dans l'ancienne génération), et quand il est prédit que l'espace dans l'ancienne génération peut être plein la prochaine fois, ce qui déclenchera Full GC. Analysez les déchets de l'ancienne génération et effacez-les pour libérer de l'espace mémoire dans l'ancienne génération.
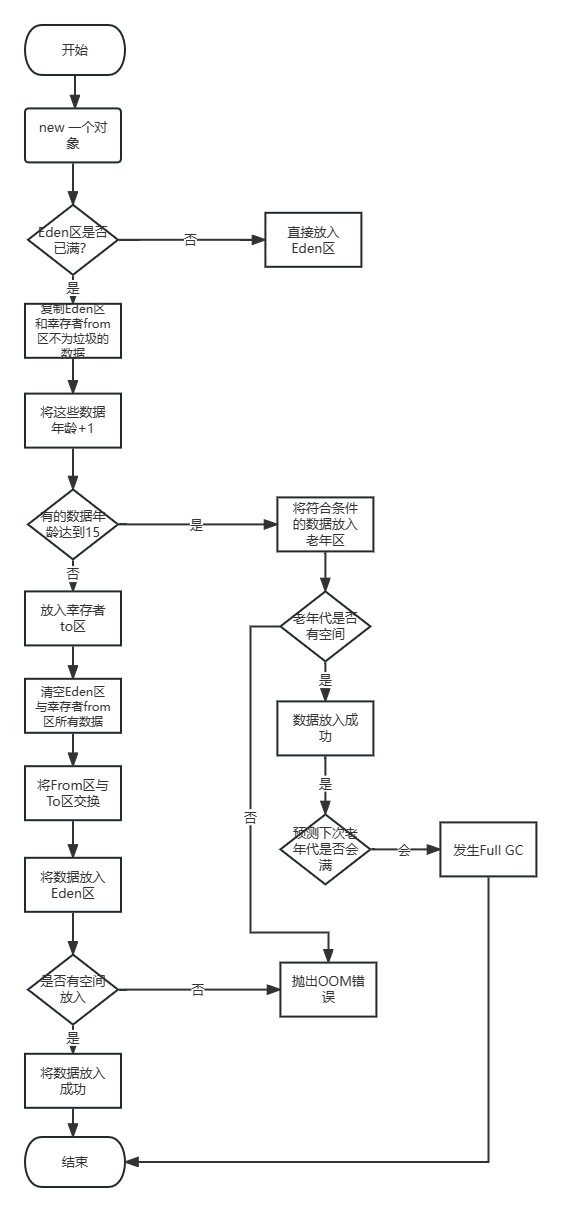
(Cette figure n'est qu'un flux général, ignorant de nombreux détails.)
Ensuite, nous présenterons le métaspace
JDK7 et avant. Le métaspace était la génération permanente, qui est l'implémentation de la zone de méthode, il est donc également appelé non- tas. Mais logiquement, il fait partie du tas (le tas est divisé en jeune génération, ancienne génération et génération permanente) et utilise physiquement le même morceau de mémoire. Il est lié à l'ancienne génération, et peu importe qui est plein, il déclenchera l'enlèvement des ordures dans l'ancienne génération et la génération permanente. De cette manière, il n'est pas nécessaire d'écrire séparément le code correspondant à la génération permanente et d'utiliser directement l'ancienne génération. La génération permanente stocke principalement 类信息, 普通常量, 静态常量, 编译器编译后的代码etc. Par exemple : l'objet que nous avons créé est créé en fonction de la classe, le modèle de cette classe est dans la génération permanente, et l'aiguille de classe dans les informations d'en-tête de l'objet pointera vers la classe de son instance dans la génération permanente. Après JDK7, le pool de constantes de chaîne a été déplacé vers le tas. Cependant, il y a toujours un problème. Étant donné que les données stockées dans la génération permanente sont différentes de celles du tas, il est difficile de déterminer la taille appropriée de la génération permanente. Par conséquent, la génération permanente sera déplacée vers le milieu JDK8et 直接内存renommée Metaspace (Metaspace), logiquement Up et physiquement séparé de l'ancienne génération.
De cette manière, le métaspace utilise la mémoire locale. L'espace maximum utilisé par défaut est la taille de la mémoire locale (la limite supérieure peut également être configurée), et les informations de classe peuvent être chargées librement en fonction de la situation réelle. Il a sa propre fréquence de collecte des ordures sans suivre l'ancienne génération. Le métaspace est l'implémentation de la spécification de zone de méthode au lieu de l'ancienne génération.
La plus grande différence entre la génération permanente et le métaspace est que le métaspace utilise la mémoire directe, et la taille n'a pas besoin d'être codée en dur
.
新创建的对象都会放入Eden区,但在扫描垃圾时,会将Eden区和不为空的幸存者区放在一起扫描。幸存者from区和幸存者to区大小永远一致- Tous les objets n'ont pas besoin d'avoir 15 ans pour entrer dans la zone des personnes âgées. Par exemple : certains gros objets ou la taille de l'espace survivant dans la zone Eden et la zone survivant De dépasse la moitié de la taille de la zone survivant à, etc. Ceux-ci sont directement placés dans l'ancienne zone.
- Il existe de nombreuses conditions qui déclenchent Full GC dans l'ancienne zone :
- Exécuté dans le code
System.gc(), rarement utilisé dans le code - Espace insuffisant dans l'ancienne génération
- La garantie d'attribution de l'espace échoue. Avant GC, calculez la taille moyenne de l'espace promu de la jeune génération à l'ancienne génération. Lorsque la taille dépasse l'espace restant de l'ancienne génération, FUll GC sera effectué.
- Le méta-espace dépasse le seuil. Par défaut, la taille du méta-espace est relative à la taille locale. Le GC complet sera effectué lorsque la taille totale du méta-espace dépasse le seuil.
- Exécuté dans le code
- Le temps STW causé par Full GC est trop long (STW est plus de 10 fois celui de GC), donc l'idée de réglage de GC est soit de réduire le nombre de Full GC, soit de réduire le temps STW de Full GC.
Réflexion : 既然从Eden区和幸存者区中扫描出不是垃圾的内容要放入另一个幸存者区,那这两个区的功能是固定好的吗?
Après la copie, il y a un échange. Celui qui est vide est la zone de destination
. Après le premier GC, celui qui est vide est la zone de destination. Parce que l'algorithme de copie est utilisé pour l'élimination des ordures dans la jeune génération. Scannez les pièces qui ne sont pas indésirables et détournez-les vers une autre destination. Qui est la destination n'est pas fixe. Si c'est le cas, on suppose que la zone survivante 1 sera toujours la zone de provenance, et la zone survivante 0 sera toujours la zone de destination : le premier GC copiera la partie non-garbage à la zone de destination, et la deuxième poubelle Recyclage doit scanner la zone Eden et la zone de destination, et l'endroit à copier ne peut pas être la zone de destination, il doit être la zone de départ. Étant donné que la zone de survie doit également être collectée, il doit y avoir une zone de destination, et la zone de départ et la zone de destination doivent pouvoir réaliser un échange logique.
Réflexion : 为什么在新生区清除垃圾时是复制有用的,而不是直接清除无用的?这样不是就不需要幸存者区,会更加节省空间了吗?
Selon les statistiques, 98 % des objets utilisés sont des objets temporaires, ce qui signifie que la majeure partie de la zone d'Eden est constituée d'ordures. Il est plus efficace de sélectionner les éléments utiles dans le dépotoir que de nettoyer les ordures une par une, de sorte que la nouvelle génération utilise la copie des parties utiles. Mais cette façon de copier nécessite de l'espace supplémentaire. Les données de l'ancienne génération ont une faible probabilité de devenir des ordures après 15 GC, vous n'avez donc qu'à effacer les parties inutiles.
Réflexion : 什么时候会触发GC?(GC通常指YoungGC)
GC se déclenche lorsque la zone Eden est pleine. Les objets sont stockés dans la zone Eden lorsqu'ils sont créés, et la zone du survivant ne participe pas directement au stockage des objets nouvellement créés.
Le processus de collecte des ordures a été brièvement présenté ci-dessus, donc d'un point de vue microscopique, comment le ramasse-miettes, qu'il s'agisse de la jeune génération ou de l'ancienne génération, identifie ceux qui sont des ordures ?
Comment identifier les déchets
Quel que soit le type d'algorithme, le cœur est de trouver l'adresse mémoire qui n'a pas de relation de référence dans le programme, car elle ne sera jamais utilisée dans le programme sans relation de référence, et elle sera recyclée.
comptage de références
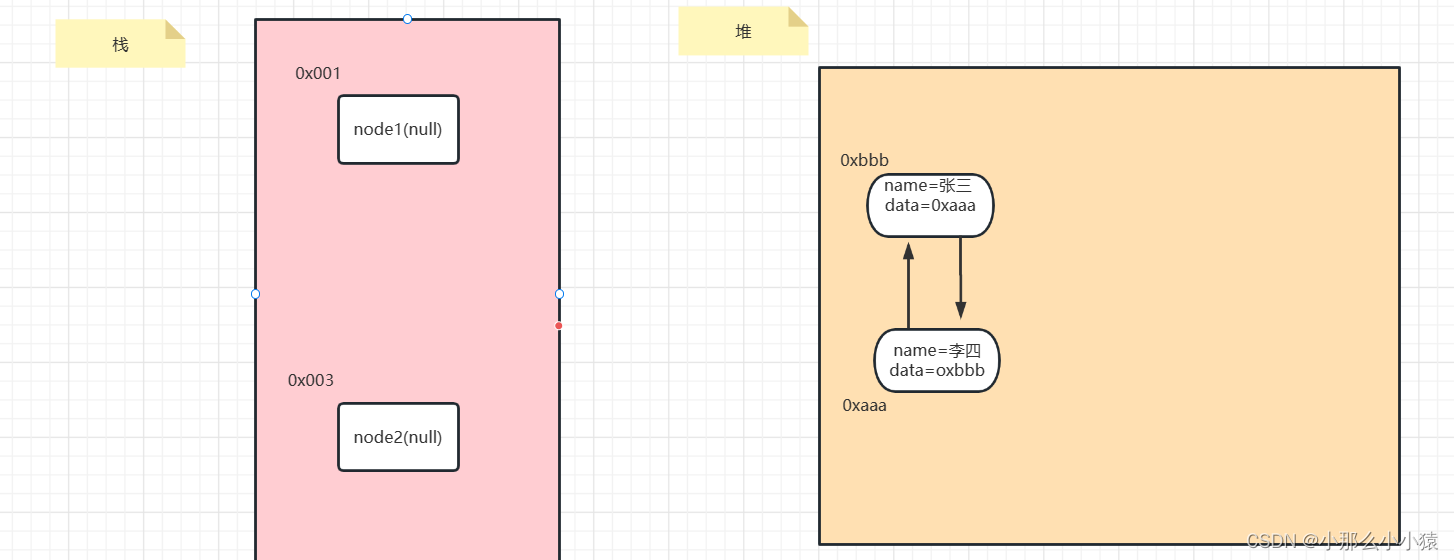
Le nombre de fois que les données dans la mémoire de tas sont référencées est +1, et le nombre de références est décrémenté de 1. Si le nombre de références à une donnée dans la mémoire de tas est 0, cela signifie qu'il n'y a pas de place pour référencer ces données et elles sont considérées comme des ordures.
Par exemple : il y a une classe Node, elle est référencée par node1, le nombre de références est 1->node1, node2 le référence tous, le nombre de références est 2->node1 le déréférence, le nombre de références est 1->node2 le déréférence , le compteur de références est 0, les données à cette adresse sont inutiles.
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2=node1;
System.out.println(node2);
node1=null;
System.out.println(node2);
node2=null;
}
}
Mais il y a un problème avec cette approche :循环引用问题
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
node1.setData(node2);
node2.setData(node1);
node1=null;
node2=null;
}
}
Prenez le nœud dont le nom est "Zhang San" comme exemple : référence node1, le nombre de références est 1->node2 data reference, le nombre de références est 2->node1 reference is invalid, the reference count is 1, but at this time parce que Node2 est déjà nul, ce nœud ne peut plus être utilisé dans le programme, et ce nœud est déjà poubelle, mais le nombre de références est 1 mais pas 0, donc il ne peut pas être reconnu comme poubelle. Il s'agit du problème de référence circulaire causé par la méthode de comptage de références.
Inconvénients du comptage de références :
- Chaque objet doit conserver un compteur de référence, ce qui entraîne une perte de performances
- traiter les références circulaires
En raison des lacunes importantes du comptage de références, la méthode de comptage de références n'est pratiquement pas utilisée actuellement, mais la méthode d'analyse d'accessibilité suivante est utilisée.
analyse d'accessibilité
À partir d'un objet pouvant être utilisé comme racine GC, suivez sa relation de référence et parcourez sa chaîne de référence. Tous les objets racines GC qui n'ont pas été traversés sont des ordures en mémoire, et les données à cette adresse ne sont plus utilisées dans le programme. Tout comme une grappe de raisin, commencez par la racine et descendez le cep. Les raisins que vous pouvez trouver doivent être dans la grappe. Seuls les raisins tombés ne seront pas traversés. Ce sont des ordures.
C'est encore un exemple qui ne peut pas être résolu en utilisant la méthode technique ci-dessus.
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
Node node3 = new Node("王五");
new Node("赵六");
node1.setData(node2);
node2.setData(node1);
node1=node3;
node2=null;
}
}
Le code ci-dessus peut être exprimé comme suit :
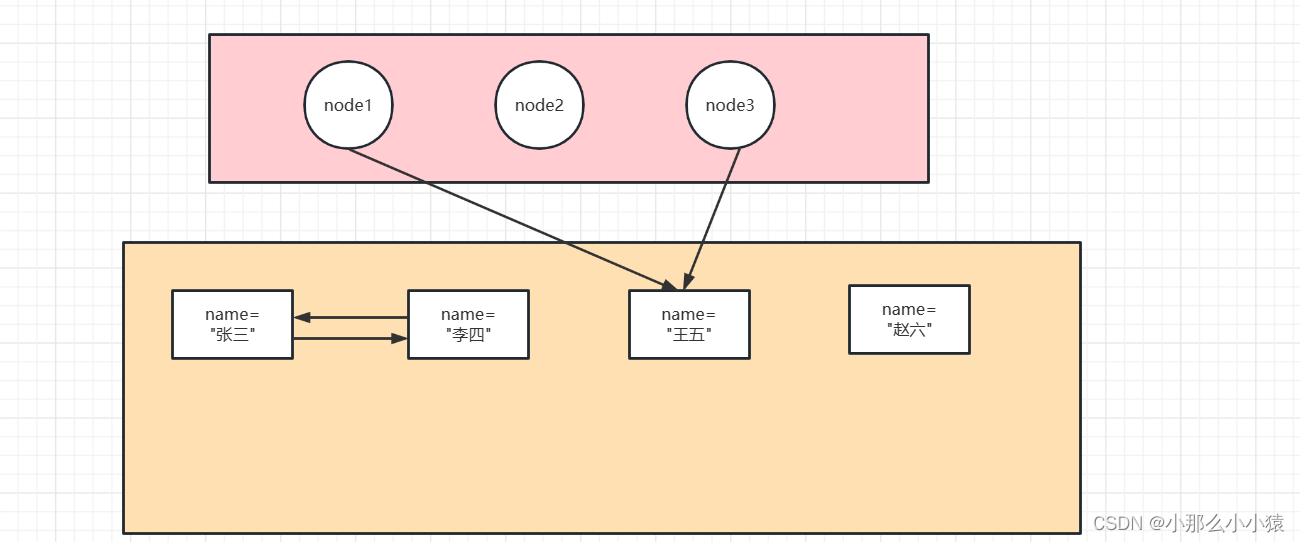
Si vous utilisez la méthode d'analyse d'accessibilité, node1, node2 et node3 peuvent tous être utilisés comme racines GC et commencer à parcourir sa relation de référence à partir de la troisième. En fin de compte, les trois nœuds nommés Zhang San, Li Si et Zhao Liu dans la mémoire n'ont pas été traversés, il a donc été déterminé que ces trois nœuds étaient des ordures et seraient recyclés.
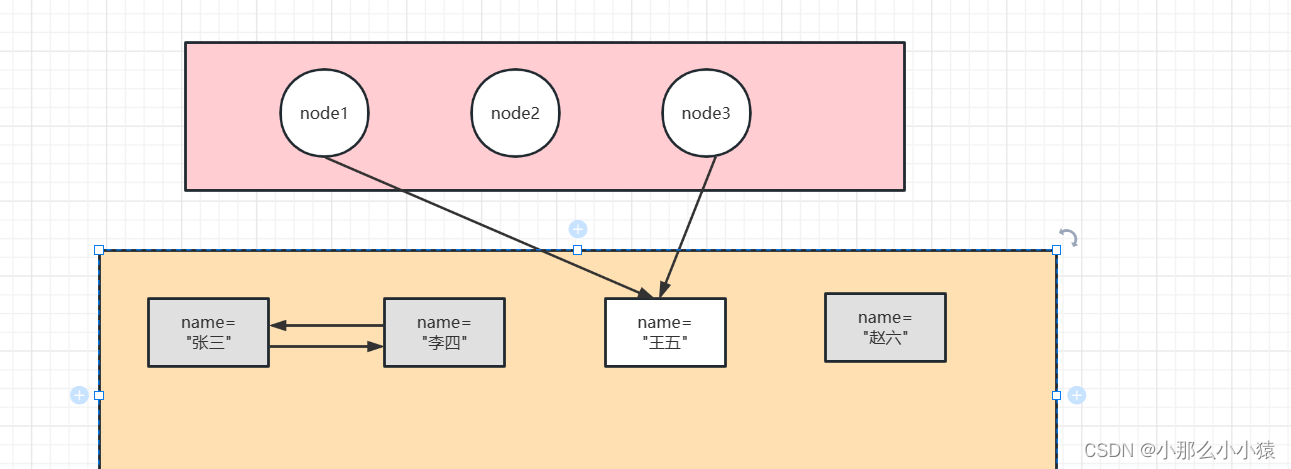
Étant donné que la relation de référence est traversée à partir de la collection d'objets racines GC, quels objets peuvent être utilisés comme racines GC ? Les racines GC sont une collection de quatre types d'objets
- Objets référencés par des variables locales sur la pile
- Objets référencés par des propriétés statiques dans la zone de méthode
- Objets référencés par des constantes dans la zone de méthode
- L'objet référencé par la pile de méthode native JNI
Dans l'exemple ci-dessus, tous les objets qui sont des racines GC sont de type 1.
Traverser des objets avec des relations de référence à partir des racines GC 不是一定不会en tant que déchets dépend de la situation de la mémoire à ce moment et de la relation de référence. Mais ceux sans relation de référence 一定会sont traités comme des ordures.
Il est déterminé lesquels sont des ordures en parcourant la relation de référence des objets racines GC, qui à son tour implique le type de relation référencé.
Quatre types de relations de référence : forte, douce, faible, virtuelle
La relation de référence entre les objets peut être divisée en quatre types, à savoir 强引用, 软引用, 弱引用, 虚引用. Les relations de référence que nous utilisons habituellement sont toutes des références fortes, et les trois méthodes restantes sont utilisées sous des fonctions spéciales.

Remplir:
- La JVM déclenchera GC lorsque l'espace dans la zone Eden est insuffisant ou l'espace dans l'ancienne génération est insuffisant.On peut aussi appeler manuellement le GC dans le code. L'utilisation
System.gc();de cette méthode est rare et n'est généralement utilisée que pour les tests. Et: utilisez cette façon GC est Full GC. - Par défaut, l'allocation minimale de mémoire de tas représente la mémoire totale du serveur
六十四分之一et la mémoire maximale représente la mémoire totale du serveur四分之一. La JVM démarre avec la mémoire minimale. Lorsque la mémoire n'est pas suffisante, elle s'ajuste jusqu'à ce qu'elle atteigne la mémoire maximale. Si ce n'est toujours pas suffisant, cela provoquera une erreur OOM. .
Vérification :
16 Go de mémoire native
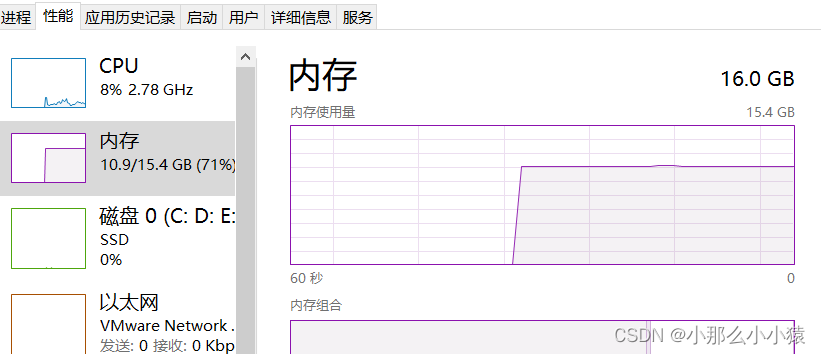
peuvent également être obtenus via le code :
public class Application {
public static void main(String[] args) {
OperatingSystemMXBean mem = (OperatingSystemMXBean) ManagementFactory.getOperatingSystemMXBean();
// 获取内存总容量
long totalMemorySize = mem.getTotalPhysicalMemorySize();
}
}
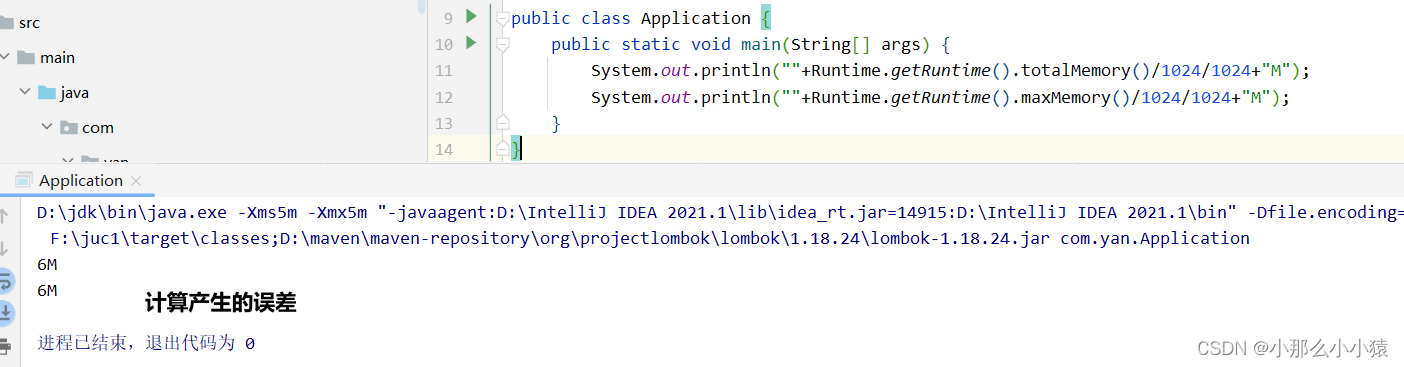
Afficher la mémoire de tas minimale et la taille de tas maximale dans la JVM
public class Application {
public static void main(String[] args) {
System.out.println(""+Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println(""+Runtime.getRuntime().maxMemory()/1024/1024+"M");
}
}

Satisfaire approximativement 默认la taille maximale de la mémoire du tas = taille totale de la mémoire / 4, 默认taille minimale de la mémoire du tas = taille totale de la mémoire / 64,
ces paramètres de taille par défaut peuvent être ajustés dans Idea (le serveur peut être ajusté en ligne de commande lors du démarrage du package jar) , généralement, afin d'éviter les fluctuations de la mémoire, ajustez l'espace mémoire de tas maximum à l'espace mémoire de tas minimum.
Par exemple : -Xms5m : 最小définissez l'espace mémoire du tas sur 5 M, -Xmx5m définissez l' 最大espace mémoire du tas sur 5 M et
configurez-le dans
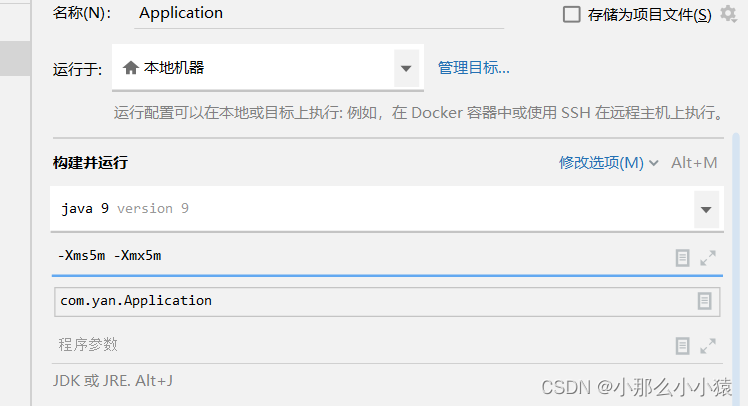
les résultats de vérification du code d'idée :
référence forte
Les références que nous utilisons habituellement sont des références fortes, et d'autres références doivent être marquées avec du code. Par exemple:
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
Node node3=node1;
}
}
Node1 et node3 font référence au nœud dont le nom est Zhang San, et node2 fait référence au nœud dont le nom est Li Si. Les trois références sont des références fortes.
La caractéristique des références fortes est que lorsque les racines GC sont accessibles, les références fortes ne seront jamais ramassées. Si la mémoire est insuffisante, elle ne sera pas recyclée et une exception OOM sera levée directement.
Référence logicielle SoftReference
Lorsque la mémoire est insuffisante, l'adresse d'espace de tas de la référence logicielle n'est pas valide et elle sera également récupérée.
Idées de test de code : testez le même code dans différents environnements (mémoire suffisante et mémoire insuffisante), si l'espace de tas sous uniquement des références logicielles sera traité comme une récupération de place
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
SoftReference<User> softReferenceU1 = new SoftReference<>(u1); // 软引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(softReferenceU1.get()); // 以软引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个软引用
System.gc(); // 经历了一次 Full GC
System.out.println(softReferenceU1.get()); // 测试 User("张三")是否被回收掉
}
}
@Data
@AllArgsConstructor
class User{
private String username;
}
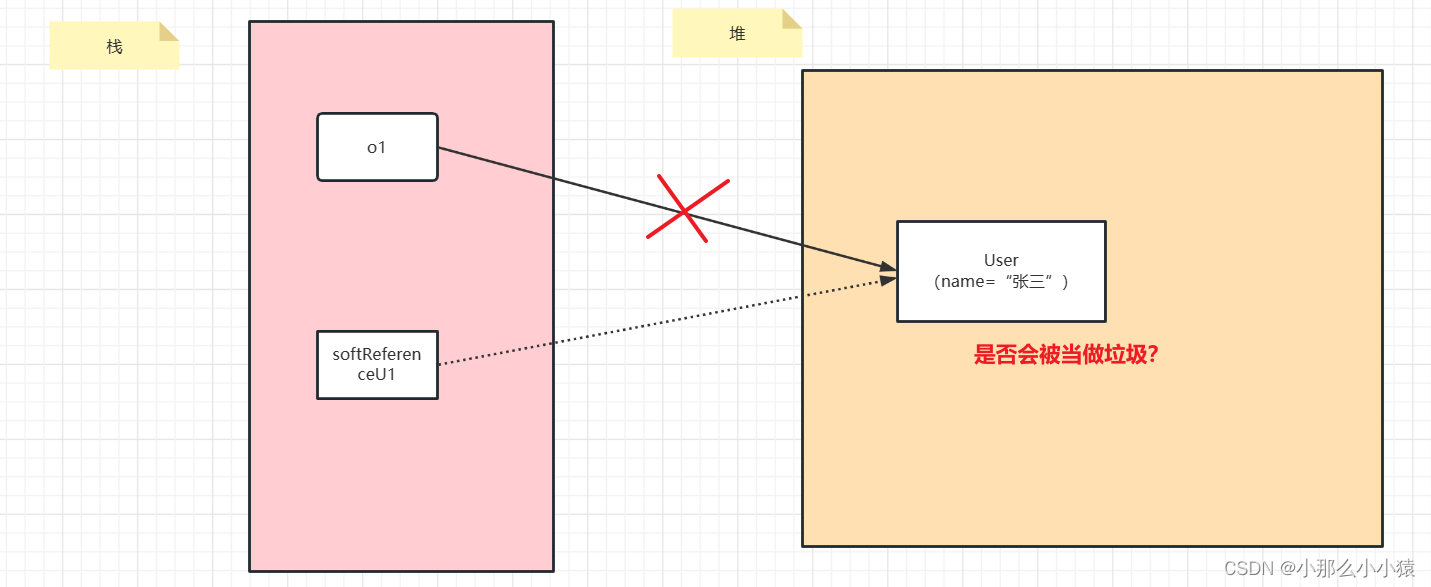
- Avec suffisamment de mémoire
Résultat :

De là on peut voir que :在内存充足时,由于堆内存中User(name=“张三”)仍有一个软引用,使得它没有被当做垃圾回收。
- En cas de mémoire insuffisante, définissez les paramètres JVM et définissez la mémoire maximale et minimale du tas JVM sur 5 Mo.
En raison d'une mémoire insuffisante, une erreur sera signalée directement. Ici, le code ci-dessus est modifié afin que l'instruction avec une mémoire insuffisante soit enveloppée dans try pour la sortie.
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
SoftReference<User> softReferenceU1 = new SoftReference<>(u1); // 软引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(softReferenceU1.get()); // 以软引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个软引用
try {
Byte[] load = new Byte[1024 * 1024 * 10];
// 直接开辟一个10M的内存空间 使得堆内存不足 这是检测是否会只有软引用是否会被当做垃圾回收
}catch (Exception e){
}
finally {
System.out.println(softReferenceU1.get()); // 测试 User("张三")是否被回收掉
}
}
}
résultat:

Référence faible WeakReference
Tant que le GC est déclenché, la référence logicielle sera invalide (l'espace qui n'est référencé que de manière douce sera traité comme une poubelle)
sans GC
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
WeakReference<User> weakReferenceU1 = new WeakReference<>(u1); // 弱引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(weakReferenceU1.get()); // 以弱引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个弱引用
System.out.println(weakReferenceU1.get());
}
}
@Data
@AllArgsConstructor
class User{
private String username;
}
Résultat : avant qu'il n'y ait pas de GC, si l'objet sous la référence peut encore être utilisé

Pensez à GC
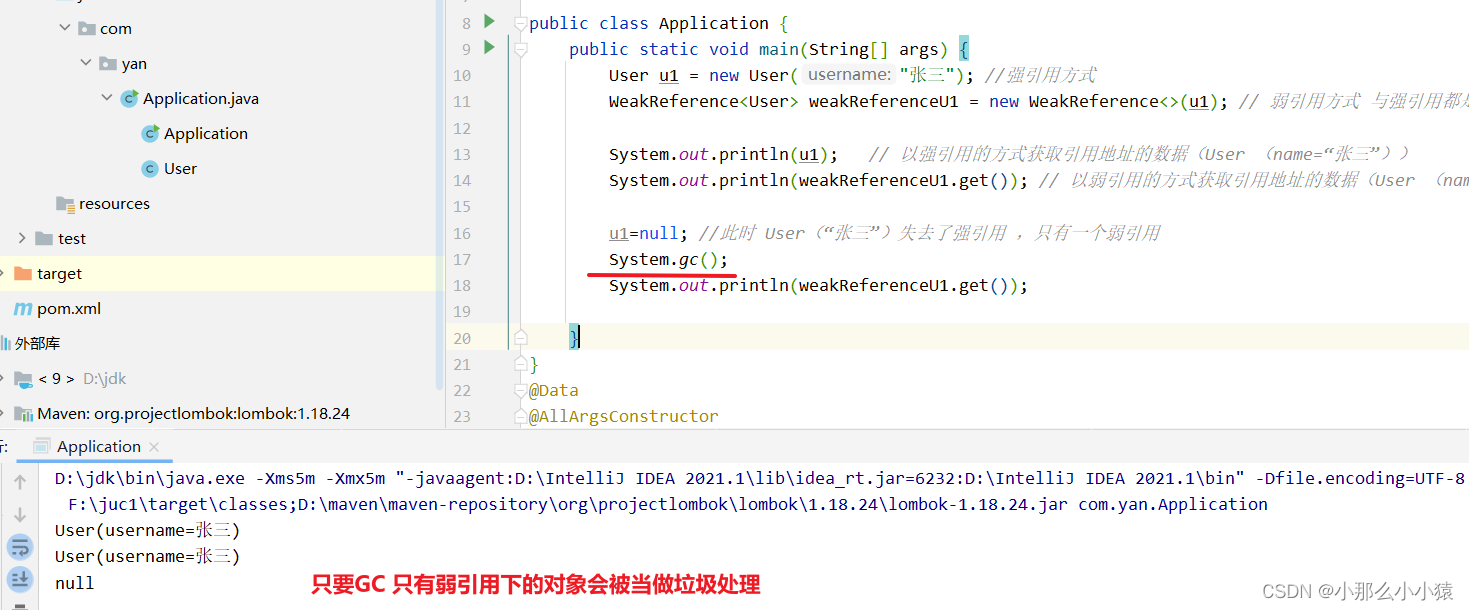
: pourquoi u1 devrait-il être défini sur null dans le code ?
L'utilisation de u1 est une référence forte. La caractéristique d'une référence forte est la suivante : en aucun cas, l'objet pointé par la référence forte ne sera jamais traité comme un déchet. Si vous ne déconnectez pas les références fortes lors du test des références logicielles, des références faibles et des références fantômes, vous ne pourrez pas voir les résultats.
WeakHashMap
Lorsque nous utilisons HashMap, Key est une relation de référence forte. Par exemple : j'ai créé un utilisateur u1=User (name="Zhang San") et je voulais ajouter une valeur attachée à l'objet u1. J'ai donc passé u1 comme clé du HashMap. Lorsque l'objet u1 est épuisé (la valeur attachée doit également disparaître), u1=null lorsque vous souhaitez libérer, mais à ce moment HashMap a toujours une référence forte pointant vers l'objet User. Cet objet ne peut pas être publié en tant que poubelle.
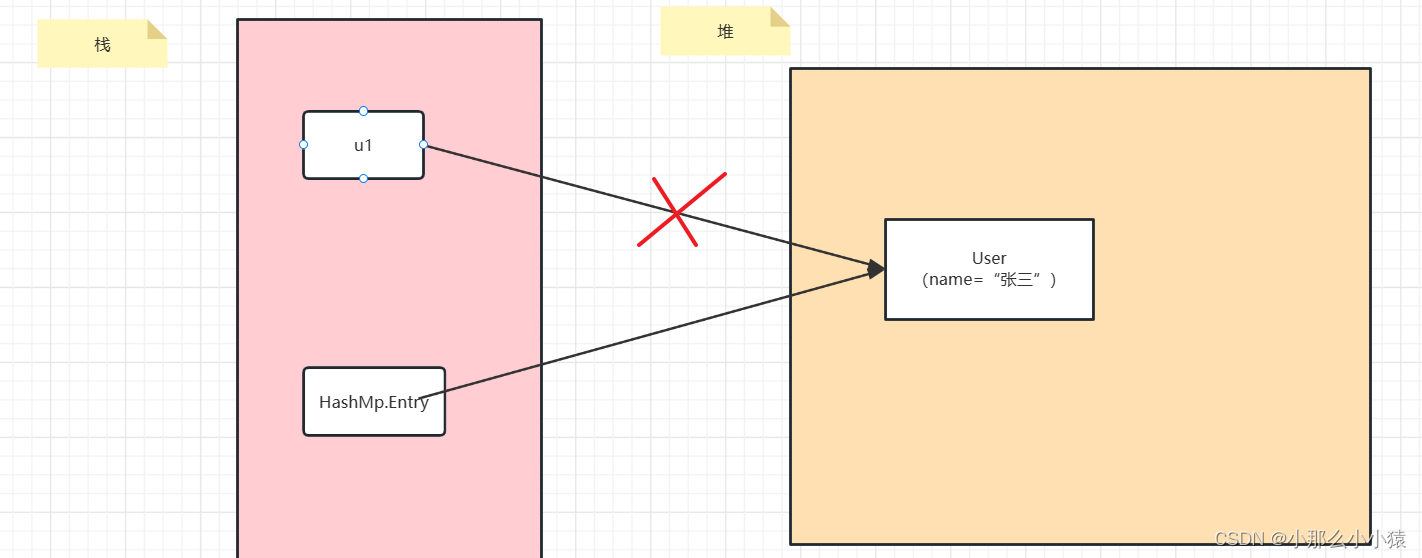
De cette façon, l'objet existera toujours pendant la récupération de place, ce qui gaspillera de la mémoire et causera des problèmes de MOO. L'
utilisation de WeakHashMap consiste à établir une relation de référence faible avec l'objet. Si vous voulez utiliser cet objet, vous ne voulez pas faire l'objet pas des ordures. Lorsque u1 est épuisé et que la référence forte est déconnectée, les ordures seront collectées pendant le GC et la référence dans WeakHashMap sera ignorée.
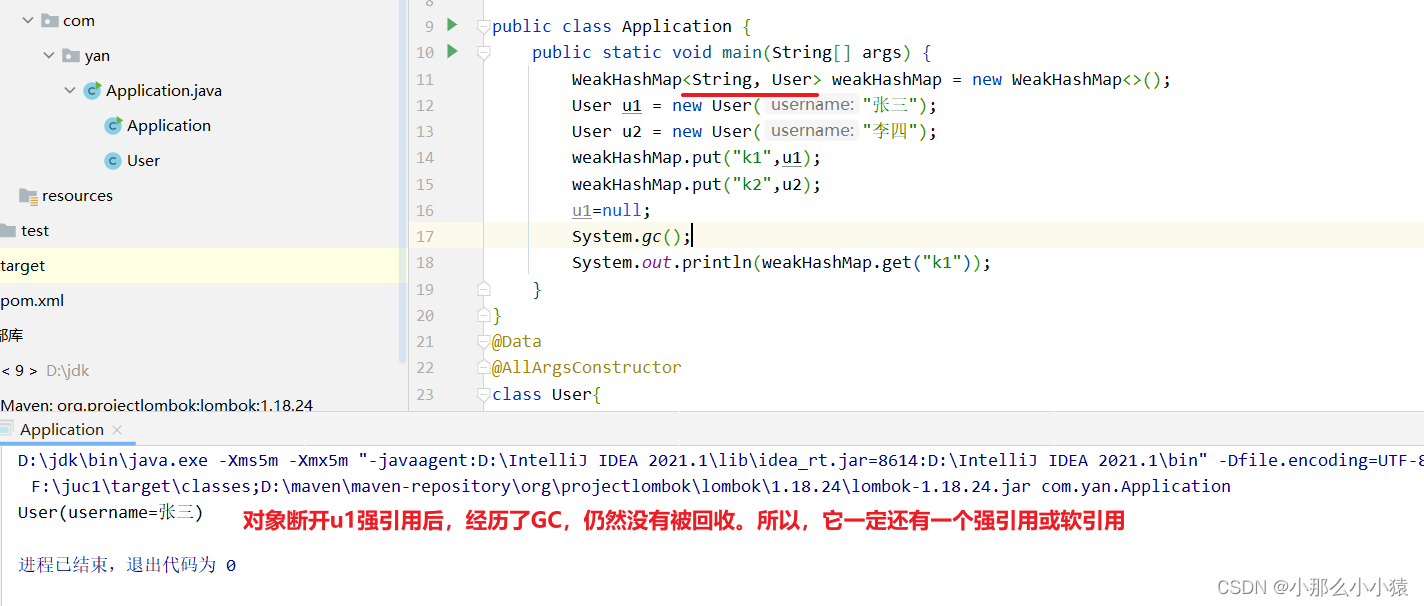
public class Application {
public static void main(String[] args) {
WeakHashMap<User, String> weakHashMap = new WeakHashMap<>();
User u1 = new User("张三");
User u2 = new User("李四");
weakHashMap.put(u1,"v1");
weakHashMap.put(u2,"v2");
u1=null; // User("张三")由于断开强引用,只有一个弱引用的WeakHashMap与之相连,在发生GC时会被回收
System.out.println(weakHashMap);
System.gc();
System.out.println(weakHashMap); // 判断只有WeakHashMap引用下的对象是否被释放
}
}
Résultat :

Mais lorsque l'objet est utilisé comme valeur, l'objet utilisateur casse la référence forte de u1 et l'objet existe toujours après GC, de sorte que la partie valeur de WeakHashMap peut être une référence forte. Comme indiqué sur l'image :
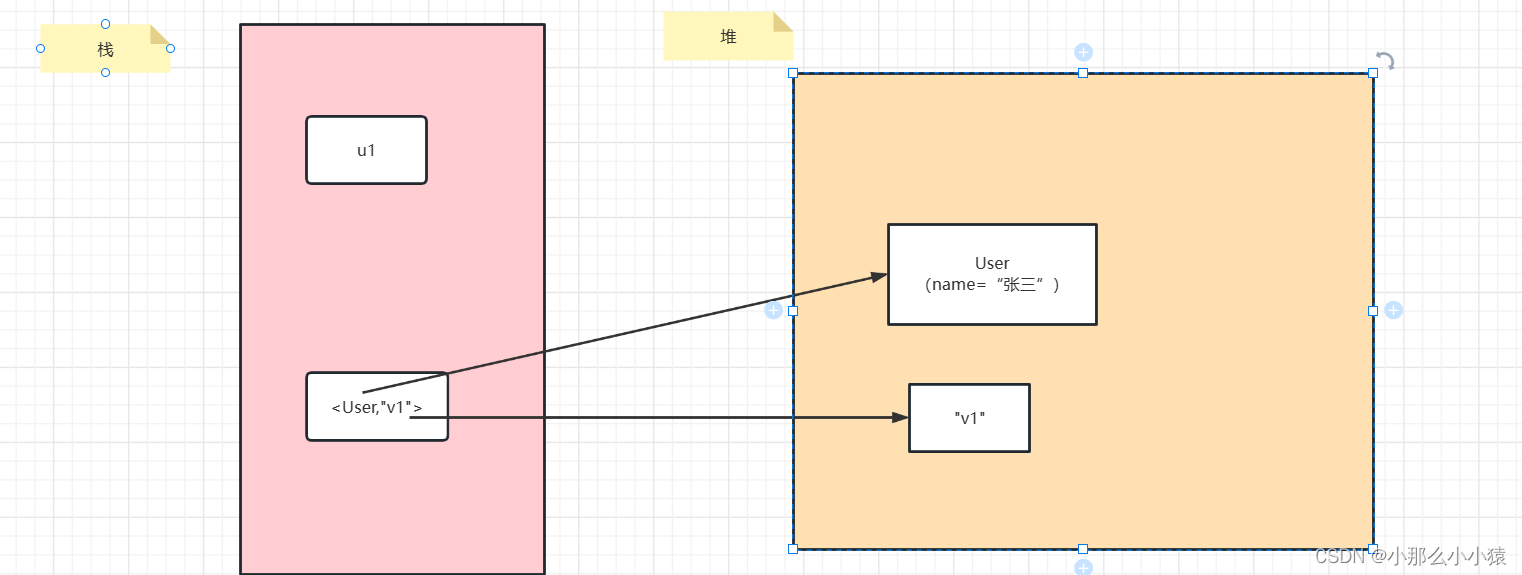
Réflexion : lorsque l'objet pointé par la clé est recyclé, qu'est-ce qui sera renvoyé lorsque la valeur sera obtenue via la clé de WeakHashMap ?
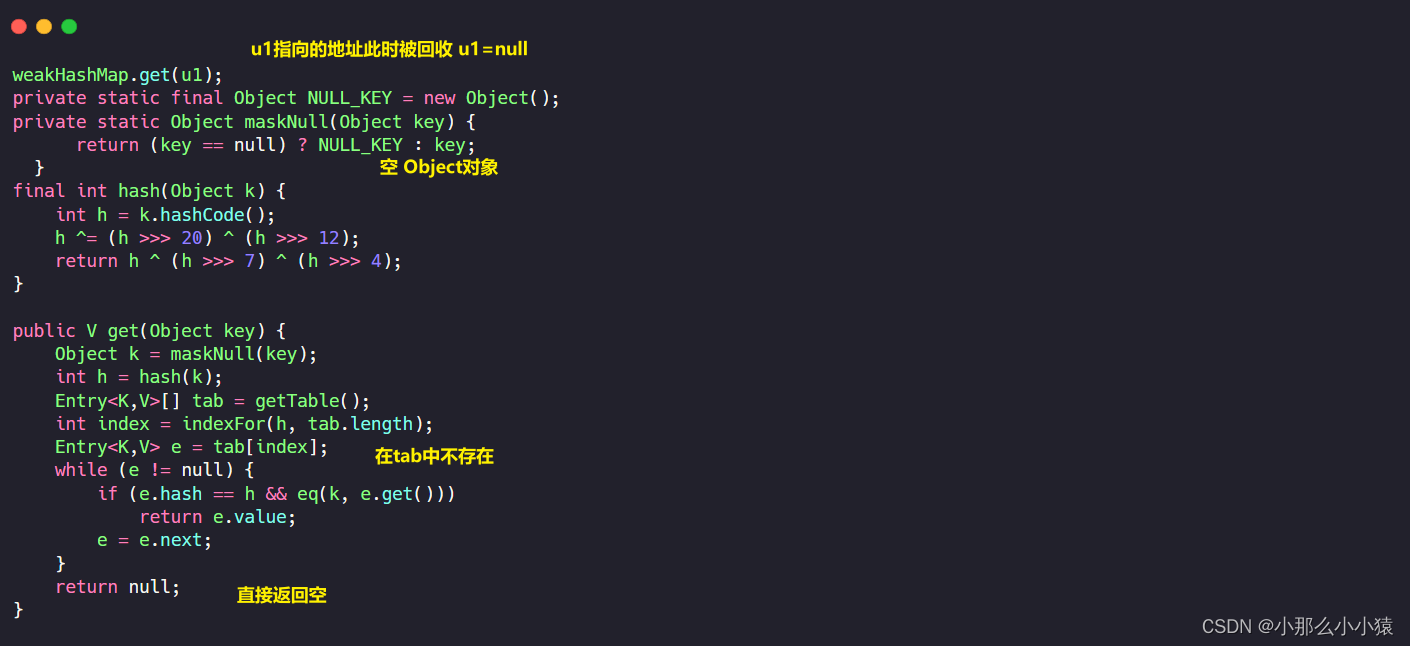
Réflexion : WeakHashMap peut être recyclé car la clé est une référence faible. Lorsque l'objet de référence n'a pas de référence forte, où va la valeur de WeakHashMap après le recyclage ?

Pensée :WeakHashMap<Object,Object>是否类似于HashMap<Reference<Object>,Object> ?
Supplément : J'ai vu cette idée d'utiliser des références faibles pour résoudre le problème de dépassement de mémoire ThreadLocal dans le code source de ThreadLocalMap :
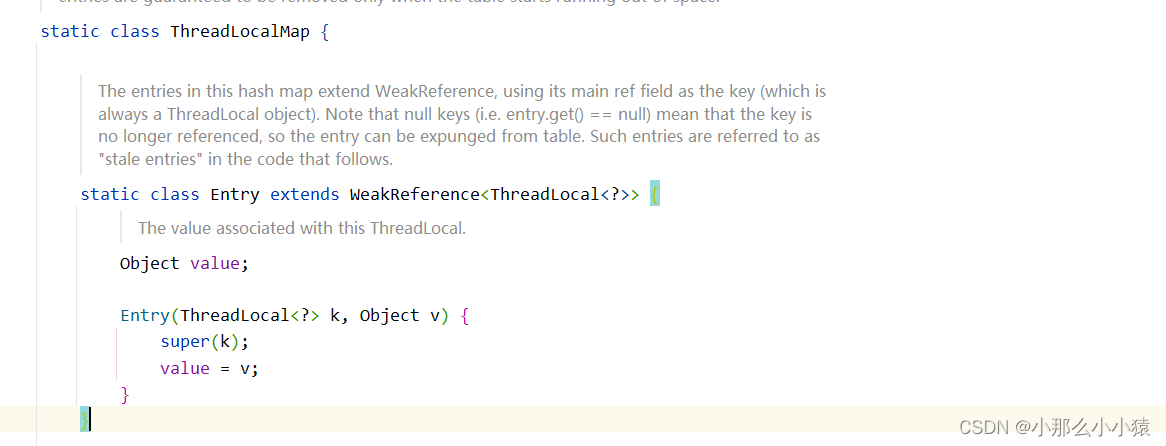
utilisez ThreadLocal comme clé, lorsque le ThreadLocal est détruit, les données concernant ce ThreadLocal dans la Map seront également libéré.
Scénarios d'utilisation des références logicielles et des références fantômes
Les références souples et les références faibles sont généralement utilisées conjointement avec des références fortes. Une référence logicielle est lorsque la référence forte est déconnectée et que l'espace d'adressage doit toujours être utilisé si la mémoire le permet. La référence logicielle signifie que lorsque la référence forte est déconnectée, il n'est pas nécessaire d'utiliser l'espace d'adressage. Elle est généralement associée à une collection. La méthode de libération du tas est gênante et elle est transmise au GC pour être libérée.
Par exemple : utiliser des références logicielles pour générer un cache
Lors de la lecture d'une image, si elle est lue à partir du disque à chaque utilisation, cela affectera les performances, et si elle est lue en une seule fois, il peut y avoir un débordement de mémoire. Comment gagner en efficacité sans provoquer de débordement mémoire ? A ce moment, il est nécessaire de maximiser l'utilisation de la mémoire et de libérer les images chargées dans la mémoire lorsque l'espace mémoire est insuffisant et qu'un OOM est sur le point de se produire. S'il y a suffisamment de mémoire pendant le fonctionnement, l'image en mémoire peut être utilisée tout le temps. HashMap<String, Reference<Byte>> hashMap = new HashMap<>()
Références fantômes et files d'attente de référence
L'utilisation de références fantômes doit être utilisée conjointement avec des files d'attente de référence, et l'utilisation de références fantômes sans files d'attente de référence n'aura aucun sens.
file d'attente de référence
Avant que l'objet référencé ne soit détruit, il sera placé dans la file d'attente d'importation. L'autre extrémité écoute cette file d'attente et peut effectuer un traitement ultérieur sur l'objet qui est sur le point d'être détruit. Les références logicielles, les références faibles et les références fantômes peuvent
toutes spécifier la file d'attente de référence lors de la construction. Les références fantômes doivent utiliser la file d'attente de référence spécifiée lors de leur construction.
Les références fantômes suivantes sont utilisées conjointement avec les files d'attente de référence :
public class Application {
public static void main(String[] args) throws InterruptedException {
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
User u1 = new User("张三");
WeakReference<Object> weakReference = new WeakReference<>(u1, referenceQueue);
u1=null;
new Thread(()->{
while (referenceQueue.poll()==null){
}
System.out.println("对象被销毁");
}).start();
System.gc();
TimeUnit.SECONDS.sleep(1);
}
}
rarement utilisé
Référence virtuelle PhantomReference
fantôme : les fantômes, les illusions, les références fantômes ne peuvent pas obtenir l'objet référencé, sa seule utilisation est de se combiner avec la file d'attente de référence, de sorte que l'objet référencé puisse être ajouté à la file d'attente de référence avant d'être détruit, de sorte qu'une certaine suite peut être faite à la l'autre extrémité de la file d'attente d'introduction. L'utilisation de références fantômes n'a pas d'impact supplémentaire sur la classe et est rarement utilisée.
public class Application {
public static void main(String[] args) throws InterruptedException {
User user = new User("张三");
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
PhantomReference<User> reference = new PhantomReference<>(user, referenceQueue); // 在创虚引用对象时就要指定消息队列
System.out.println(reference.get()); //尝试获取虚引用引用的对象
user=null;
new Thread(()->{
while (referenceQueue.poll()==null){
}
System.out.println("虚引用引用的对象被销毁");
}).start();
System.gc();
TimeUnit.SECONDS.sleep(1);
}
}
résultat:

Réflexion : d'autres files d'attente de référence peuvent-elles être ajoutées à la file d'attente de référence avant d'être détruites ?
Il ne peut être utilisé que rarement, mais la référence fantôme n'a que cette fonction, elle est donc spécialement introduite
Résumé : Quant à savoir si l'objet sera recyclé, il vous suffit de vérifier le nombre de références à cet objet et le mode de référence.
Comment identifier les ordures a été présenté ci-dessus, la prochaine étape est de savoir comment traiter les ordures une fois qu'elles ont été trouvées ?
algorithme de récupération de place
nombre de références
Si le compte est 0, c'est une ordures. S'il y a un compte de référence, ce sera +1, et s'il y a un compte d'invalidation de référence, ce sera -1.
Cet algorithme est combiné avec la méthode de comptage de références d'analyse des ordures, mais cette méthode présente le problème des références circulaires, qui est rarement utilisée, de sorte que la méthode algorithmique de comptage de références ne sera pas utilisée.
Copie Copie
Copiez la partie non indésirable de la zone A dans la zone B, puis effacez la zone A. Cette méthode convient à la jeune génération du tas, car la jeune génération n'est pas une minorité d'ordures et la quantité de mouvement est relativement faible. Copiez la partie de la zone d'Eden et de la zone de départ du survivant qui n'est pas une poubelle dans la zone de destination du survivant, puis effacez la zone d'Eden et la zone de départ du survivant.
Cette méthode est plus efficace, et la copie commence à partir de l'endroit où la zone de destination est entièrement vide, et le nettoyage consiste à effacer toute la zone d'Eden et la zone de départ du survivant, de sorte qu'il n'y aura pas de fragmentation de la mémoire.
Inconvénients de cette approche
- Un espace supplémentaire est requis, comme la zone de destination du survivant, qui doit être de la même taille que la zone de provenance, et la moitié de la mémoire de la zone de survivant est gaspillée à tout moment
- S'il y a une situation extrême, telle que 100% de la zone d'Eden n'est pas une poubelle, il faut du temps pour copier la partie utile, et cela fera exploser les survivants dans la zone. Il convient donc aux endroits à faible taux de survie (par défaut, zone Eden : survivant de zone : survivant à = 8 : 1 : 1)
Marquer Marquer-Balayer
Retrait de marque : divisé en deux parties 1. Traversez toutes les racines du GC pour marquer quelle partie est des ordures 2. Traversez tout le tas pour effacer les ordures. STW (stop the world) est tenu de suspendre l'intégralité de l'application lors du marquage des déchets et du nettoyage des déchets. Se produit dans l'ancienne génération, car la plupart des objets de l'ancienne génération ont subi 15 GC et la probabilité de redevenir des ordures est relativement faible.
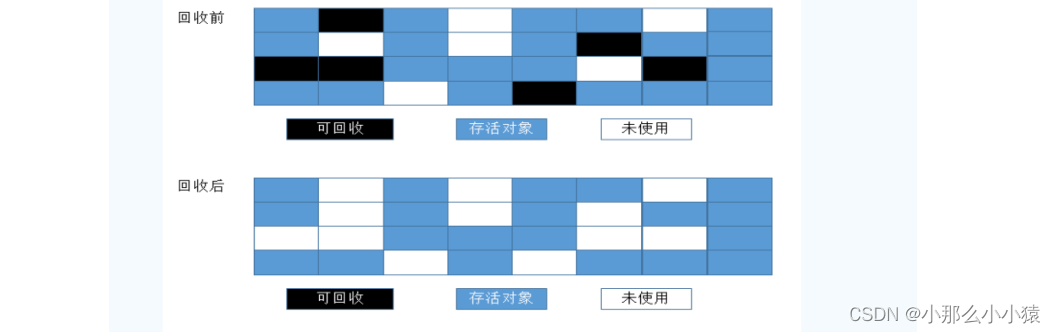
Il a deux inconvénients majeurs :
- Inefficace et nécessite de mettre en pause toute l'application
- L'effacement rend la mémoire discontinue, ce qui entraîne une fragmentation excessive de la mémoire. La JVM doit alors maintenir une liste libre de mémoire, ce qui représente une autre surcharge. De plus, lors de l'allocation d'objets de tableau (les gros objets se trouvent dans l'ancienne zone), un grand espace contigu est requis et il n'est pas facile de trouver un espace mémoire continu.
Marque-Compact
Marquez la finition : divisée en trois parties, 1. Traversez toutes les racines du GC pour marquer quelle partie est une poubelle 2. Traversez tout le tas pour éliminer les déchets. 3. Organisez la mémoire pour réduire la fragmentation. Par rapport à l'algorithme de marquage, il y a une étape de tri supplémentaire, qui résout le problème de la fragmentation de la mémoire, mais apporte également de nouveaux problèmes : il faut du temps et du CPU pour trier.
L'effacement des marques et l'effacement des marques se produisent dans l'ancienne génération, et les deux sont souvent combinés pendant l'utilisation.Après plusieurs effacements de marques, un effacement est effectué. Cela évite non seulement le marquage et le tri fréquents, chronophages et gourmands en performances, mais maintient également la fragmentation de la mémoire dans une plage raisonnable.
Chacun de ces trois algorithmes a ses propres avantages et inconvénients. Il n'y a pas d'algorithme parfait, et l'algorithme approprié doit être sélectionné en fonction du fleuve Yangtze approprié.
Quel algorithme ci-dessus est une idée pour résoudre le ramasse-miettes, et l'outil de mise en œuvre spécifique est le ramasse-miettes suivant.
Types de collecteurs de déchets
Divisez vraiment les outils mis en œuvre en fonction de l'algorithme et de la manière dont le ramasse-miettes recycle généralement en cinq catégories.
collectionneur en série
Un seul thread collecte et tous les threads utilisateur sont suspendus lorsque les déchets sont collectés. Convient aux scénarios à thread unique. Par exemple, pendant les cours, une seule femme de ménage vient faire le ménage. Si vous souhaitez continuer le cours, vous ne pouvez qu'attendre que la femme de ménage ait fini de nettoyer. Tous les threads utilisateur doivent faire une pause et attendre que ce thread termine le GC, ce qui est moins efficace.
Les implémentations spécifiques sont Serial(pour la jeune génération), Serial Old(pour l'ancienne génération)
collecteur parallèle
Par rapport au collecteur série, il n'y a plus un seul thread lors du recyclage, mais plusieurs threads participent ensemble. De cette façon, il n'est plus nécessaire d'attendre qu'une seule personne travaille et la quantité de tâches reste inchangée.Par rapport à une personne travaillant ensemble, plusieurs personnes peuvent réduire le temps d'attente des threads utilisateur.
Les implémentations spécifiques sont ParNew(pour la jeune génération), Parallel Scavenge(pour la jeune génération), Parallel Old(pour l'ancienne génération)
collecteur simultané
Le thread utilisateur et le thread de récupération peuvent fonctionner ensemble (bien qu'il y ait une pause, mais le temps est court), sa plus grande caractéristique est qu'il n'y a pas de longue pause, et il convient aux scénarios où l'utilisateur a une forte demande d'interaction . Étant donné que les utilisateurs ne veulent certainement pas de longues pauses soudaines lors de l'interaction, l'utilisation d'un ramasse-miettes simultané peut réduire le temps de réponse.
L'implémentation spécifique est CMS(pour l'ancienne génération)
G1
ZGC
Pensée : 什么是STW?
STW : Stop The Word signifie que lors du ramasse-miettes, tous les threads utilisateurs seront suspendus, provoquant un phénomène de freeze.
Réflexion : 复制算法也会到导致STW吗?为什么要GC时要STW?
Tous les éboueurs causeront STW, ce n'est qu'une question de temps. Parce que lorsque les ordures sont finalement confirmées, la cohérence doit être assurée, sinon le programme continuera à s'exécuter, la relation de référence continuera à changer et les résultats de l'analyse seront inexacts. S'il n'y a pas de pause pendant la copie, les objets créés pendant cette période ne seront pas marqués comme des objets survivants, et les survivants ne seront pas déplacés vers la zone des survivants mais seront effacés, les références fortes seront effacées et le programme ira mal . De plus, dans l'algorithme de copie et l'algorithme de marquage, l'adresse de l'objet référencé d'origine changera. Prévenir la confusion des citations.
Exemples de ramasse-miettes courants
nouvelle génération
En série
Seul 一个le thread utilise l'algorithme de copie dans la jeune génération pour copier tous les objets survivants dans le jardin d'Eden et la zone survivante de vers la zone survivante vers. STW est requis pendant le GC. Peut fonctionner avec le ramasse-miettes Serial Old.
Récupération parallèle
Démarrez 多个le fil et utilisez l'algorithme de copie dans la jeune génération pour copier tous les objets survivants dans le jardin d'Eden et la zone survivante de la zone survivante à. STW est requis pendant le GC. En raison de l'utilisation de plusieurs threads pour travailler ensemble, le temps de STW peut être plus court.
Le débit peut être défini par le paramètre XX:MaxGCPauseMillis et le paramètre -XX:GCTimeRatio qui contrôle directement le débit. Débit = temps d'exécution du programme / (temps d'exécution du programme + temps GC). L'amélioration du débit peut augmenter l'utilisation du processeur, mais cela n'a rien à voir avec la vitesse de réponse et n'améliore pas nécessairement l'expérience utilisateur.
Peut fonctionner avec CMS垃圾回收器.Parallel Old垃圾回收器
ParNouveau
C'est aussi GC avec plusieurs threads, ce qui est légèrement différent de Parallel (le débit ne peut pas être défini). peut CMS垃圾回收器travailler avec
ancienne génération
Ancienne série
Les déchets sont collectés d'une manière à un seul thread et tous les threads utilisateur sont suspendus pendant la collecte des déchets. Il est similaire au Serial dans la génération des jeunes ci-dessus, mais dans l'ancienne génération, l'algorithme de marquage et d'organisation est utilisé, ce qui ne provoquera pas de fragmentation de la mémoire.
Parallèle Vieux
La récupération des threads concurrents est similaire à celle de Parallel dans la jeune génération, mais l'algorithme de marquage adopté dans l'ancienne génération ne provoquera pas de fragmentation de la mémoire.
CMS
Le nom complet du CMS : concurrent mark sweep, la traduction est compensation simultanée.
CMS quatre étapes
初始标记: analysez toutes les racines GC, c'est-à-dire les nœuds racine, dans l'ancienne zone. Pendant cette période, le changement du nœud racine est suspendu, c'est donc STW, mais comme il y a relativement peu de racines GC, le temps STW est relativement court- Marquage simultané : étant donné que tous les nœuds racine ont été analysés au stade initial, à ce stade, il suffit d'analyser les objets qui ne peuvent pas être référencés le long du nœud racine et de les marquer comme des ordures. Pendant cette période, il est exécuté en parallèle avec le thread utilisateur. Comme il y a généralement plus de nœuds sous le nœud racine que sous le nœud racine, cela prend relativement du temps, mais comme il est exécuté en parallèle avec les threads utilisateur, il n'y a pas de STW. L'inconvénient est que ce nœud consomme plus de performances.
重新标记: Garbage peut être ajouté car le thread utilisateur analyse les déchets lors de l'exécution. Il s'agit de suspendre tous les threads utilisateurs pour un dernier nettoyage. Marquez à nouveau les ordures nouvellement ajoutées dans ce processus pour vous assurer que le nettoyage est complet et que les ordures générées en raison de la simultanéité ne peuvent pas être inconnues. Bien que cette étape soit STW, le temps est court car il y a moins de déchets ajoutés.- Effacement simultané : tous les déchets ont été marqués ici, et le reste est effacé (l'algorithme d'effacement utilise l'effacement des marques). Les threads nettoyés peuvent s'exécuter parallèlement aux threads utilisateur.
La plus grande caractéristique du CMS est que le STW est court et que le système se fige pendant une courte période pendant l'interaction, ce qui convient pour une utilisation lors de l'interaction avec les utilisateurs.
Mais le CMS a deux inconvénients majeurs :
- Dans le processus d'effacement simultané, étant donné que le thread utilisateur n'est pas suspendu, il est possible que de nouvelles données soient ajoutées à l'ancienne génération (comme des objets volumineux directement placés dans l'ancienne génération), de sorte qu'il n'est pas effacé lorsqu'il est plein , mais un certain espace est réservé . Par exemple, 10 %. Cependant, si les nouvelles données entrant dans l'ancienne génération dépassent 10 % de la valeur réservée pendant le processus de compensation simultanée, il n'y aura pas d'espace pour l'ancienne génération à ce moment-là, et elle sera déclenchée, puis le CMS dégénérera
Concurrent Mode Failureen un ancien ramasse-miettes en série. Suspendez tous les threads utilisateur et recyclez de manière monothread. Provoquer un sérieux décalage. Le grand espace réservé entraînera des GC complets fréquents, et le petit espace réservé entraînera l'échec du recyclage du CMS. - L'algorithme adopté par CMS est un algorithme d'effacement simultané, il générera donc une fragmentation de la mémoire. Lorsqu'il y a trop de fragments, le Serial GC sera déclenché et l'algorithme d'organisation des marques à thread unique sera utilisé pour effacer et défragmenter.
Réflexion : Pourquoi le CMS n'utilise-t-il pas d'algorithme de balisage pour résoudre le problème de fragmentation ?
Si l'algorithme de classement est utilisé, l'adresse de l'objet peut changer pendant le nettoyage simultané, nécessitant la suspension de tous les threads utilisateur.
jeune génération + ancienne génération
G1
Recommander la lecture de ce blog
En ce qui concerne la configuration et l'utilisation du ramasse-miettes GC, ainsi que certains paramètres et commandes de la JVM, le réglage de la JVM combiné à Linux sera présenté dans les blogs suivants. Si vous trouvez une erreur, bienvenue pour en discuter ensemble.