Convert various audio files (.wav, .mp3, .ogg) to wav files, support minute and second level segmentation
Requirements : Call the python script, input the source file path, target path, cutting duration, and the time unit of the cutting duration , and be able to cut the source audio file corresponding to the path into the target path according to the set cutting duration.
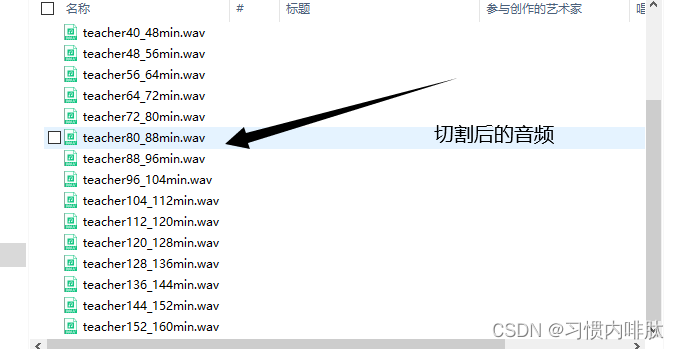
Final effect :
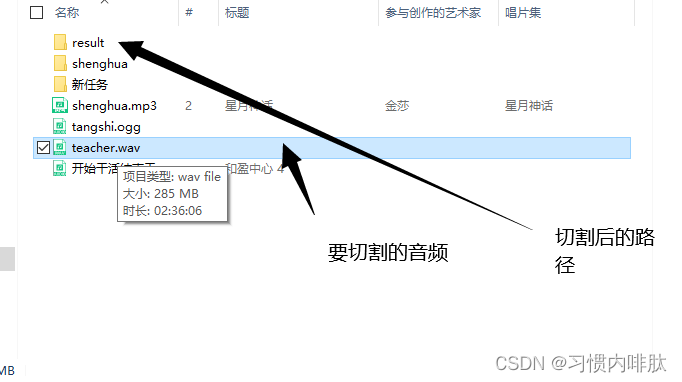
According to cutting every 8 minutes:

Note : If there is no corresponding dependency package, you need to download it yourself through the pip3 command (pydub, ffmpge)
[If you have similar problems, you can refer to this article]
(https://blog.csdn.net/baidu_38903149/article/details/ 105680450)
Code : audio_to_wav.py (multiple audios converted to wav audio)
import os
from pydub import AudioSegment
# 支持的格式
SUPPORTED_FORMATES = [".mp3", ".m4a", ".wav", ".flac", ".ogg", ".flv"]
def audios_to_wavs(src_path, res_path):
"""
src_path目录下的所有音频文件进行 ——> 常见音频格式转wav格式
:param src_path: 源音频存在的目录
:param res_path: 转换后的音频存储路径
:return:
"""
if(os.path.exists(src_path) == False or os.path.exists(res_path) == False):
print("路径出错,请确认src_path和res_path存在")
exit(-1)
# 支持的音频格式列表
supported_formats = SUPPORTED_FORMATES
# 记录转换的总文件数
count = 0
# 循环遍历文件夹中的所有音频文件
for audio_file in os.listdir(src_path):
# 检查文件是否为支持的音频格式
if audio_file.endswith(tuple(supported_formats)):
# 获取不带扩展名的文件名
file_name = os.path.splitext(audio_file)[0]
# 使用pydub读取音频文件
audio = AudioSegment.from_file(os.path.join(src_path, audio_file))
# 将音频文件导出为wav格式
audio.export(os.path.join(res_path, file_name + ".wav"), format="wav")
count = count + 1
print(count)
def audio_to_wav(src_path, res_path):
"""
单个文件 ——> 常见音频格式转wav格式
:param src_path: 源音频路径
:param res_path: 转换后的音频存储路径
:return:
"""
if(os.path.exists(src_path) == False or os.path.exists(res_path) == False):
print("路径出错,请确认src_path和res_path存在")
exit(-1)
# 支持的音频格式列表
supported_formats = SUPPORTED_FORMATES
# 检查文件是否为支持的音频格式
if src_path.endswith(tuple(supported_formats)):
# 获取不带扩展名的文件名
file_name = os.path.splitext(os.path.basename(src_path))[0]
# 使用pydub读取音频文件
audio = AudioSegment.from_file(src_path)
# 将音频文件导出为wav格式
audio.export(os.path.join(res_path, file_name + ".wav"), format="wav")
else:
print("目前仅支持" + supported_formats + "进行格式转换")
print(src_path + "转换完成~")
if __name__ == '__main__':
# audio目录下的所有音频文件,不包含子目录
audios_to_wavs("D:\\TAL\\音视频脚本测试数据\\audio\\", "D:\\TAL\\音视频脚本测试数据\\wav\\");
# audio_to_wav("D:\\TAL\\音视频脚本测试数据\\audio\\sent.mp3", "D:\\TAL\\音视频脚本测试数据\\wav");
Code : wav_split.py (wav audio cutting script)
import os.path
from pydub import AudioSegment
def wav_split(wav_path, part_path, split_time):
"""
音频切片,获取部分音频,单位秒
:param wav_path: 原音频文件路径
:param splitTime: 切割时长(s)
:param part_path: 截取后的音频路径
:return:
"""
if(os.path.exists(wav_path) == False or os.path.exists(part_path) == wav_path):
print("路径出错,请确认wav_path和part_path存在")
exit(-1)
file_name = os.path.splitext(os.path.basename(wav_path))[0] # wav文件名
dir_part_path = os.path.join(part_path, file_name) # 以file_name生成目录存放对应音频切割的文件
if(os.path.exists(dir_part_path) == False):
os.mkdir(dir_part_path)
sound = AudioSegment.from_wav(wav_path) # wav音频数据
duration = sound.duration_seconds # 音频时长(s)
nframes = duration // split_time if (duration % split_time == 0) else duration // split_time + 1 # 分割后的段数
for i in range(int(nframes)):
# 该段对应的起始时间
start = i * split_time
# 该段对应的结束时间
if (i != nframes - 1):
end = start + split_time
else:
end = duration
# 分割后的路径
tempPath = os.path.join(dir_part_path, file_name + "_" + str(i * split_time) + "_" + str((i + 1) * split_time) + "s.wav")
get_second_part_wav(wav_path, start, end, tempPath)
print(tempPath + "已切割成功!")
def wavs_split(wav_dir, part_path, split_time):
"""
音频切片,获取部分音频,单位秒
:param wav_dir: 音频目录
:param splitTime: 切割时长(s)
:param part_path: 截取后的音频路径
:return:
"""
if(os.path.exists(wav_dir) == False or os.path.exists(part_path) == False):
print("路径出错,请确认wav_dir和part_path存在")
exit(-1)
for src_wav in os.listdir(wav_dir):
filename = os.path.join(wav_dir, os.path.basename(src_wav))
wav_split(filename, part_path, split_time)
print(filename + "已切割完毕~")
def get_second_part_wav(main_wav_path, start_time, end_time, part_wav_path):
"""
音频切片,获取部分音频,单位秒
:param main_wav_path: 原音频文件路径
:param start_time: 截取的开始时间
:param end_time: 截取的结束时间
:param part_wav_path: 截取后的音频路径
:return:
"""
start_time = start_time * 1000
end_time = end_time * 1000
sound = AudioSegment.from_wav(main_wav_path)
word = sound[start_time:end_time]
try:
word.export(part_wav_path, format="wav")
except FileNotFoundError:
print("存储路径不存在!请使用正确的存储路径")
exit(-1)
if __name__ == '__main__':
# 单个文件切割
# wav_split('D:\\TAL\\音视频脚本测试数据\\wavs\\1.wav', 'D:\\TAL\\音视频脚本测试数据\\split_wav', 2)
# 目录文件切割
wavs_split('D:\\TAL\\音视频脚本测试数据\\wavs', 'D:\\TAL\\音视频脚本测试数据\\splits', 2)