Pytorch 기반 모델 구동을 위한 GPU 활용 방법 및 주의사항
1. pytorch 딥러닝을 기반으로 모델 학습 및 예측을 수행할 때 데이터 세트가 상대적으로 큰 경우가 많고 모델도 상대적으로 복잡할 수 있지만 직접 학습이 CPU를 실행하도록 호출하면 계산 속도가 매우 느려지므로 GPU는 모델 교육에 사용되며 예측은 매우 필요하며 실험 효율성을 크게 향상시킬 수 있습니다. 운영 환경을 구성하지 않은 경우 블로거는 아래 블로거의 기사를 참조할 수 있습니다.
1. 클릭하여 "딥 러닝을 위한 Windows 기반의 완전하고 간단한 버전의 Anaconda+Cudnn+Cuda+Pytorch+Pycharm 도구 및 구성 환경 구성 환경 구축" 기사를 열려면 클릭하십시오. 2. "로컬 또는 원격 서버 GPU 및 사용 방법 보기" 기사를 열려면 클릭하십시오. 파이토치 기반
"
2. 특정 방법은 두 부분(모델 및 데이터 세트)으로 나뉩니다.
- 먼저 모델 모델을 cuda 장치, 즉 GPU로 이동합니다. 참고: 이 큰 모델은 여러 하위 모델을 포함할 수 있으며 하위 모델을 반복적으로 GPU로 이동할 필요가 없습니다.
model = Net() # 举例模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # 移动举例模型到cuda
또는
model = Net() # 举例模型
device = torch.cuda.current_device() if args.cuda else torch.device('cpu')
model.to(device) # 移动举例模型到cuda
- 데이터셋(트레이닝셋과 테스트셋 그리고 포함된 레이블 데이터셋 포함)을 cuda 장치 즉, GPU로 옮기고 data set.cuda() 형태로 완성합니다.
drug_embeddings = drug_embeddings.cuda()
protein_embeddings = protein_embeddings.cuda()
effectives = effectives.cuda()
또는
drug_embeddings = drug_embeddings.to(device)
protein_embeddings = protein_embeddings.to(device)
effectives = effectives.to(device)
3. 문제점 및 방법
- 질문 1 : torch.FloatTensor와 torch.cuda.FloatTensor의 차이점
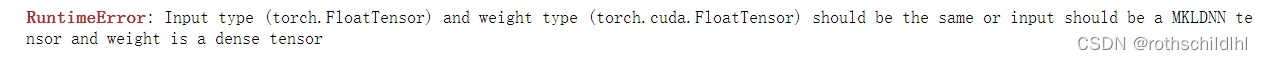
Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same or input should be a MKLDNN tensor and weight is a dense tensor
질문이 중국어로 번역되었습니다.
输入类型(torch.FloatTensor)和权重类型(torch.cuda.FloatTensor)应该相同,或者输入应该是MKLDNN张量,权重是密集张量
- 질문 2 : 데이터 계산 중 인터랙션이 필요한 경우 같은 기기에 있지 않음
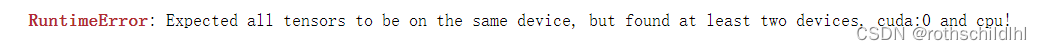
Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
질문이 중국어로 번역되었습니다.
预期所有张量都在同一设备上,但至少找到了两个设备,cuda:0 和 cpu !
-
문제 1과 문제 2에 대한 해결책(동일) : 먼저 오류 프롬프트에 따라 코드의 어느 데이터 줄에 문제가 있는지 찾은 다음 대상 방식으로 해결합니다.데이터 XR의 문제를 예로 들어 보겠습니다. , 두 가지 경우가 있습니다: 첫 번째 경우 는 데이터 XR이 구성을 통과하면 다음 으로
torch.FloatTensor(数据XR)변경할 수 있습니다. 두 번째 경우는 데이터 XR을 구성하지 않고 데이터 XR을 다른 하위 모델로 전송한 다음 직접 데이터 XR 뒤에 cuda를 추가하거나 " "만 추가하십시오.torch.cuda.FloatTensor(数据XR)数据XR.cuda()


-
문제 3 : CUDA 전송 메모리가 코드 실행 중에 할당하기에 충분하지 않습니다.

CUDA out of memory. Tried to allocate 490.00 MiB (GPU 0; 2.00 GiB total capacity; 954.66 MiB already allocated; 62.10 MiB free; 978.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
질문이 중국어로 번역되었습니다.
CUDA内存不足。尝试分配490.00 MiB(GPU 0;2.00 GiB总容量;954.66 MiB已分配;62.10 MiB可用;PyTorch总共保留978.00 MiB)如果保留内存>>已分配内存,请尝试设置max_split_size_mb以避免碎片。请参阅内存管理和PYTORCH_CUDA_ALLOC_CONF的文档
- 문제 3에 대한 해결책 : 컴퓨팅 메모리가 부족한 경우 두 가지 해결책이 있습니다.첫 번째 방법은 일반적으로 데이터 세트의 배치 크기를 줄이는 것, 즉 batch_size를 줄이는 것입니다.예를 들어 원래의 batch_size=256은 두 번째는 서버에서 코드를 실행하는 것, 즉 더 좋은 GPU로 교체해서 실행하는 것인데, 그래도 같은 문제가 발생한다면 이 두 가지 방법을 조합해서 사용하는 것이 가장 좋습니다.

- 앞으로도 새로운 이슈가 계속 업데이트 될 예정이니 많은 관심 부탁드립니다!