Chapitre 1 Présentation de HDFS
1.1 Contexte et définition de la sortie HDFS
Arrière-plan de la génération HDFS
Au fur et à mesure que la quantité de données devient de plus en plus grande, toutes les données ne peuvent pas être stockées dans un système d'exploitation, elles sont donc allouées à plusieurs disques gérés par le système d'exploitation, mais il est peu pratique à gérer et à entretenir, et un système est nécessaire de toute urgence pour gérer plusieurs machines Il s'agit du système de gestion de fichiers distribué. HDFS n'est qu'un type de système de gestion de fichiers distribué .
Définition HDFS
HDFS (Hadoop Distributed File System), qui est un système de fichiers, est utilisé pour stocker des fichiers et localiser des fichiers à travers des arborescences de répertoires ; deuxièmement, il est distribué et de nombreux serveurs sont combinés pour réaliser ses fonctions. Les serveurs du cluster ont leur propre Rôle.
Scénarios d'utilisation HDFS : adaptés aux scénarios d'écriture unique et de lecture multiple. Un fichier n'a pas besoin d'être modifié après sa création, son écriture et sa fermeture.
1.2 Avantages et inconvénients de HDFS
1.2.1 Avantages du HDFS
haute tolérance aux pannes
Les données sont automatiquement enregistrées en plusieurs copies. Il améliore la tolérance aux pannes en ajoutant des copies.
Une fois qu'une copie est perdue, elle peut être restaurée automatiquement.
Adapté à la gestion de données volumineuses
Échelle de données : capable de gérer des données avec des échelles de données atteignant des niveaux de Go, To ou même PB
Taille du fichier : il peut gérer le nombre de fichiers au-dessus d'une échelle d'un million , ce qui est assez volumineux.
Il peut être construit sur des machines bon marché et la fiabilité peut être améliorée grâce au mécanisme multicopie
1.2.2 Inconvénients du HDFS
Il n'est pas adapté pour un accès aux données à faible latence , comme le stockage de données en millisecondes, c'est impossible.
Il ne peut pas stocker efficacement un grand nombre de petits fichiers.
Si vous stockez un grand nombre de petits fichiers, il occupera une grande quantité de mémoire NameNode pour stocker le répertoire de fichiers et bloquer les informations. Ce n'est pas conseillé, car la mémoire du NameNode est toujours limitée.
Le temps de recherche pour le stockage de petits fichiers dépassera le temps de lecture, ce qui viole l'objectif de conception de HDFS.
L'écriture simultanée et la modification aléatoire des fichiers ne sont pas prises en charge .
Un fichier ne peut être écrit que par un seul, et plusieurs threads ne sont pas autorisés à écrire en même temps.
Prend uniquement en charge l'ajout de données (append) , ne prend pas en charge la modification aléatoire des fichiers
1.3 Structure HDFS
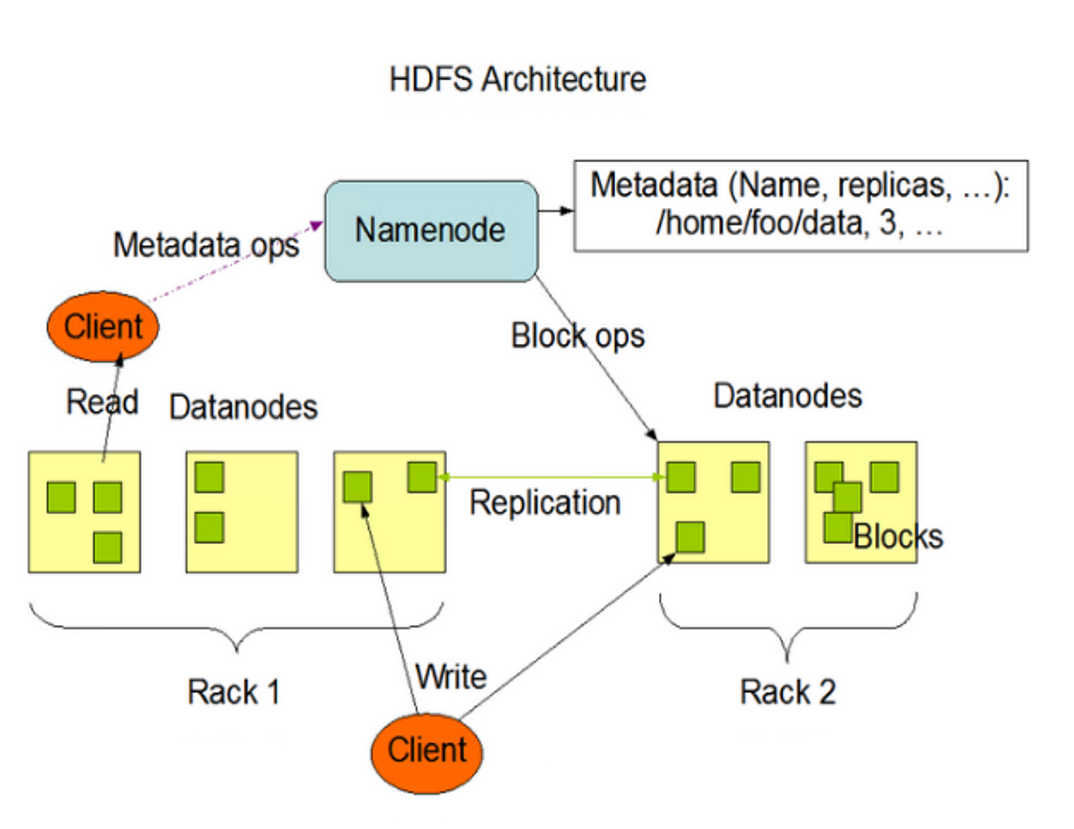
NameNode (nn) est le maître, qui est un superviseur et un gestionnaire.
Gérer les espaces de noms HDFS ;
stratégie de copie ;
Gérer les informations de mappage de bloc de données (bloc) ;
Gérer les demandes de lecture et d'écriture des clients.
DataNode : C'est un esclave. NameNode émet des commandes et DaaNode effectue les opérations réelles.
stocker le bloc de données réel
Effectuer des opérations de lecture/écriture sur des blocs de données.
Client : C'est le client.
Segmentation des fichiers. Lorsqu'un fichier est téléchargé sur HDFS, le client divise le fichier en blocs un par un, puis télécharge le fichier.
Interagissez avec NameNode pour obtenir les informations d'emplacement du fichier ;
Interagissez avec DaaNode, lisez ou écrivez des données ;
Le client fournit certaines commandes pour gérer HDFS, telles que le formatage NameNode ;
Le client peut accéder à HDFS via certaines commandes, telles que l'ajout, la suppression, la modification et l'interrogation de HDFS.
Secondaire NameNode : Ce n'est pas un Hot Standby de NameNode. Lorsque le NameNode raccroche, il ne peut pas immédiatement remplacer le NameNode et fournir des services.
Auxiliary NameNode partage son travail, comme fusionner régulièrement Fsiage et Edits et les pousser vers NameNode.
En cas d'urgence, il peut aider à récupérer le NameNode.
1.4 Taille du bloc de fichier HDFS (focus de l'interview)

penser:
Pourquoi la taille du bloc ne peut-elle pas être trop petite, ni trop grande ?
Le paramètre de bloc de HDFS est trop petit , ce qui augmentera le temps de recherche , et le programme a recherché la position de départ du bloc ;
Si le bloc est défini sur une taille trop grande , le temps de transfert des données depuis le disque sera considérablement plus long que le temps nécessaire pour localiser le début du bloc . En conséquence, le programme sera très lent lors du traitement de cette donnée
Résumé : Le paramètre de taille de bloc HDFS dépend principalement du taux de transfert du disque.
Chapitre 2 Fonctionnement du shell de HDFS
2.1 Syntaxe de base
hadoop fs [commande spécifique] OU hdfs dfs [commande spécifique]
deux sont identiques
2.2 Commandes communes
2.2.1 Télécharger
-moveFromLocal : couper et coller de local à HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo-copyFromLocal : copiez les fichiers du système de fichiers local vers le chemin HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo-put : Équivalent à copyFromLocal, l'environnement de production est plus habitué à utiliser put
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo-appendToFile : ajoute un fichier à la fin d'un fichier existant
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt2.2.2 téléchargement
-copyToLocal : copie de HDFS vers local
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./-get : équivalent à copyToLocal, l'environnement de production est plus habitué à utiliser get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt2.2.3 Fonctionnement direct HDFS
-ls : affiche les informations du répertoire
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo-cat : affiche le contenu du fichier
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt-chgrp, -chmod, -chown : même usage dans le système de fichiers Linux, modifier les permissions du fichier
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt-mkdir : créer un chemin
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo-cp : copie d'un chemin de HDFS vers un autre chemin de HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo-mv : déplace les fichiers dans le répertoire HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo-tail : affiche les 1 Ko de données de fin d'un fichier
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt-rm : supprimer un fichier ou un dossier
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt-rm -r : supprimer récursivement les répertoires et leur contenu
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo-du informations statistiques sur la taille du dossier
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo-setrep : définit le nombre de copies de fichiers dans HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt2.3 Fonctionnement de l'API de HDFS
2.3.1 Téléchargement de fichiers HDFS
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 上传文件
fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 关闭资源
fs.close();
2.3.2 Téléchargement de fichiers HDFS
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);
// 3 关闭资源
fs.close();
}
2.3.3 Priorité des paramètres
Tri par priorité des paramètres : (1) Valeur définie dans le code client > (2) Fichier de configuration défini par l'utilisateur sous ClassPath > (3) Puis configuration par défaut du serveur
Chapitre 3 Processus de lecture et d'écriture HDFS (focus de l'entretien)
3.1 Processus d'écriture de données HDFS
3.1.1 Ecriture du fichier d'analyse
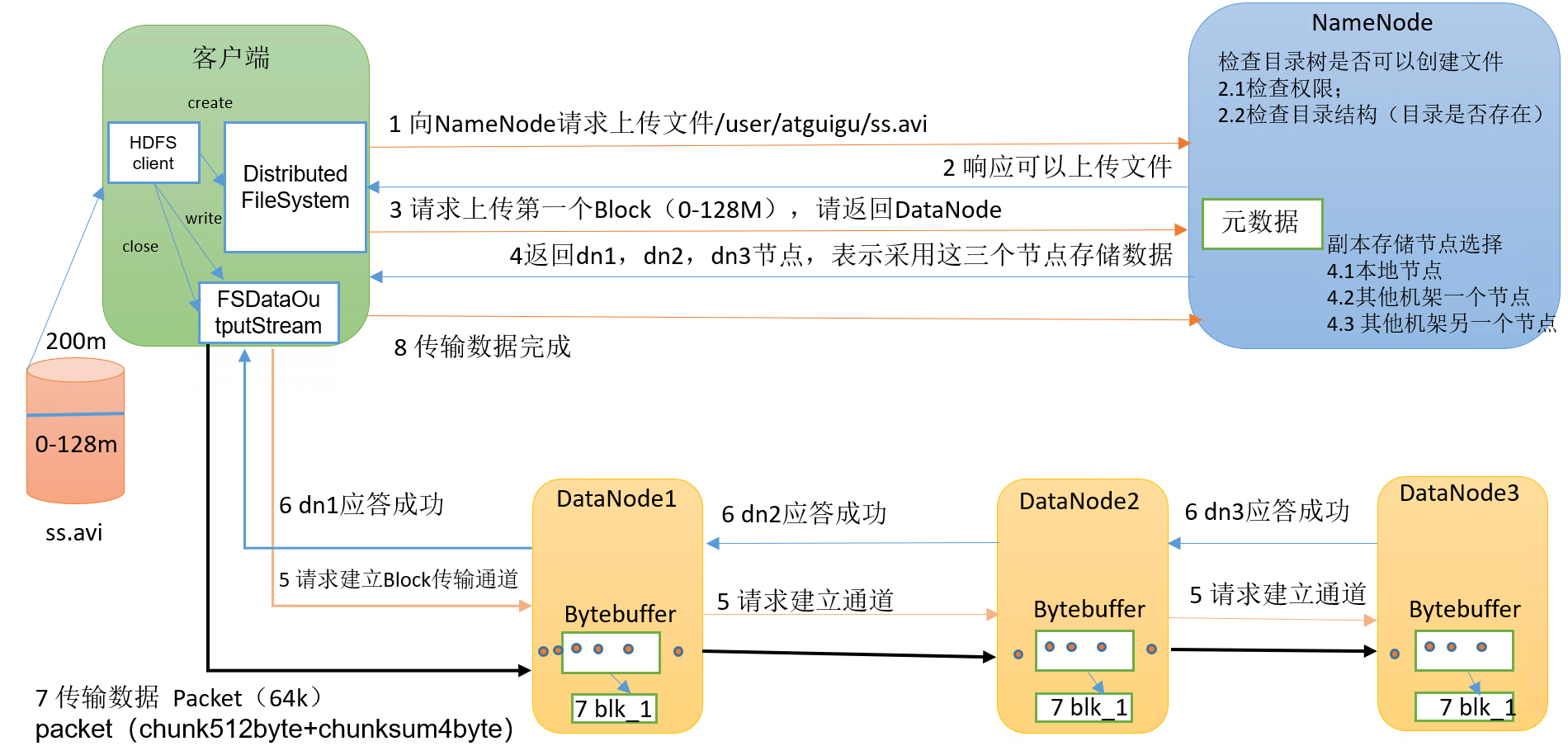
processus spécifique :
(1) Le client demande au NameNode de télécharger des fichiers via le module Distributed FileSystem, et le NameNode vérifie si le fichier cible existe et si le répertoire parent existe.
(2) NameNode renvoie s'il peut être téléchargé.
(3) Sur quels serveurs DataNode le client demande de télécharger le premier bloc.
(4) NameNode renvoie trois nœuds DataNode, à savoir dn1, dn2 et dn3.
(5) Le client demande à dn1 de télécharger des données via le module FSDataOutputStream Après avoir reçu la demande, dn1 continuera à appeler dn2, puis dn2 appellera dn3 pour terminer l'établissement du canal de communication.
(6) dn1, dn2 et dn3 répondent pas à pas au client.
(7) Le client commence à télécharger le premier bloc sur dn1 (lisez d'abord les données du disque et placez-les dans une mémoire cache locale), en prenant le paquet comme unité, dn1 transmettra un paquet à dn2 et dn2 le transmettra à dn3 ; dn1 Chaque fois qu'un paquet est transmis, il sera placé dans une file d'attente de réponse pour attendre la réponse.
(8) Lorsqu'une transmission de bloc est terminée, le client demande au NameNode de télécharger à nouveau le serveur du deuxième bloc. (Répétez les étapes 3 à 7).
3.1.2 Reconnaissance du rack (sélection du nœud de stockage de réplique)
Instructions de sensibilisation au rack
description officielle
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.Sélection du nœud de réplique Hadoop3.1.3
La première copie se trouve sur le nœud où se trouve le Client. Si le client est en dehors du cluster, sélectionnez-en un au hasard
La deuxième réplique se trouve sur un nœud aléatoire dans un autre rack
Le troisième réplica se trouve sur un nœud aléatoire sur le même rack que le deuxième réplica
3.2 Processus de lecture de données HDFS
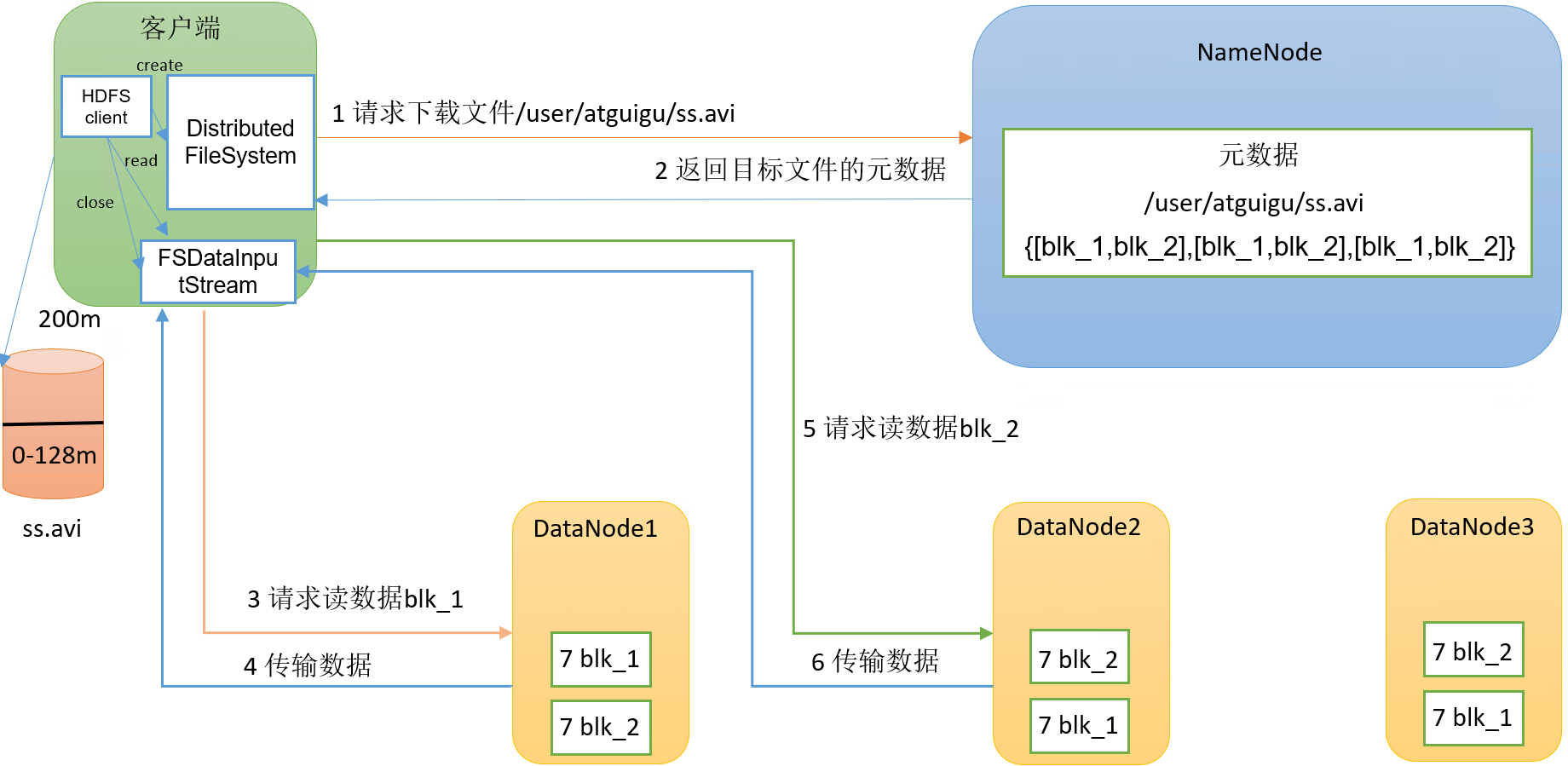
processus spécifique :
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
第4章 NameNode和SecondaryNameNode
4.1 NN和2NN工作机制

1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
4.2 Fsimage和Edits解析


4.3 oiv查看Fsimage文件
查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
基本语法
# fsimage
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
# edits file
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径4.4 CheckPoint时间设置
通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<!-- 单位:秒 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
第5章 DataNode
5.1 DataNode工作机制
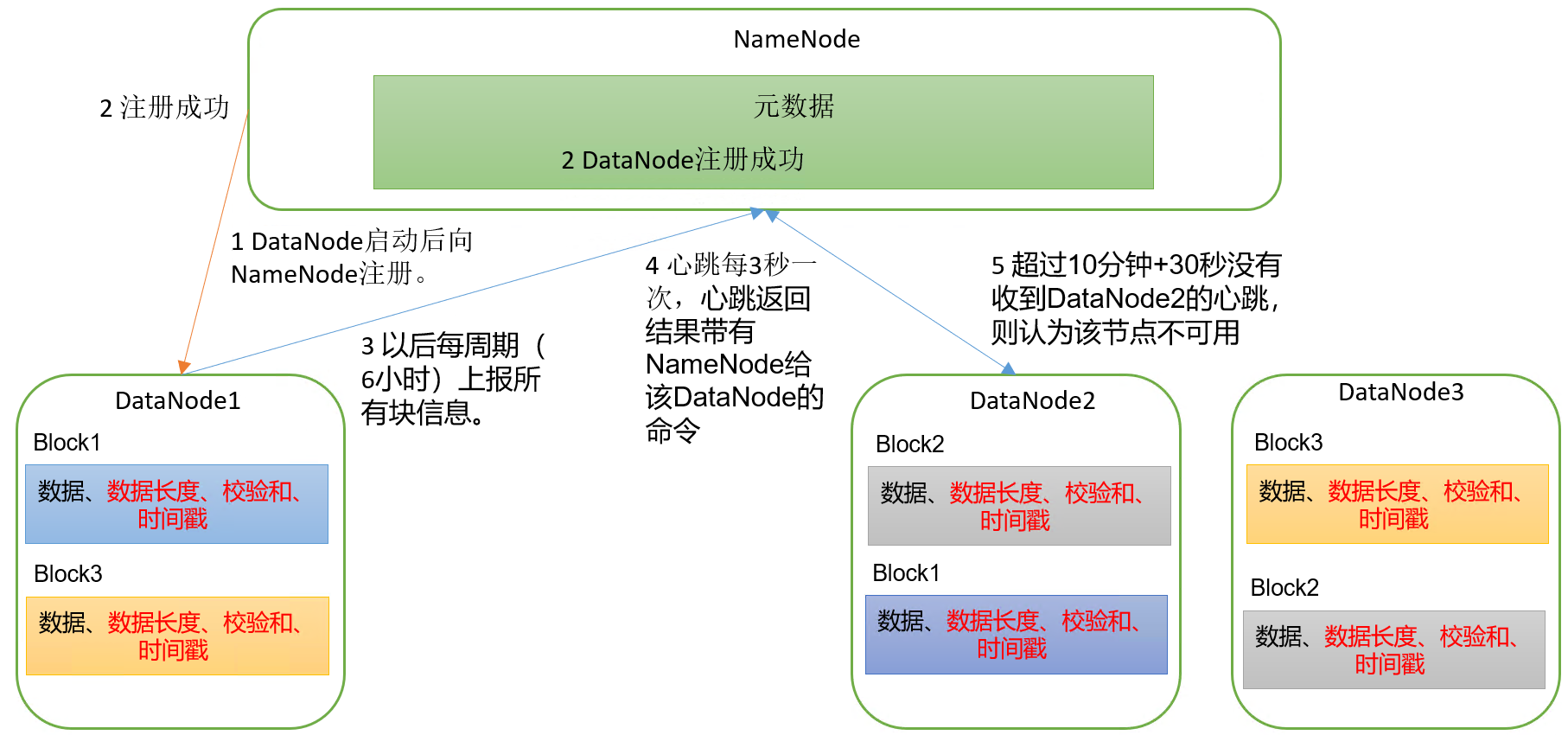
具体流程:
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟+30秒没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
5.2 DataNode 数据完整性
DataNode节点保证数据完整性的方法:
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)常见的校验算法crc(32),md5(128),sha1(160)。
(5)DataNode在其文件创建后周期验证CheckSum。
5.3 掉线时限参数设置
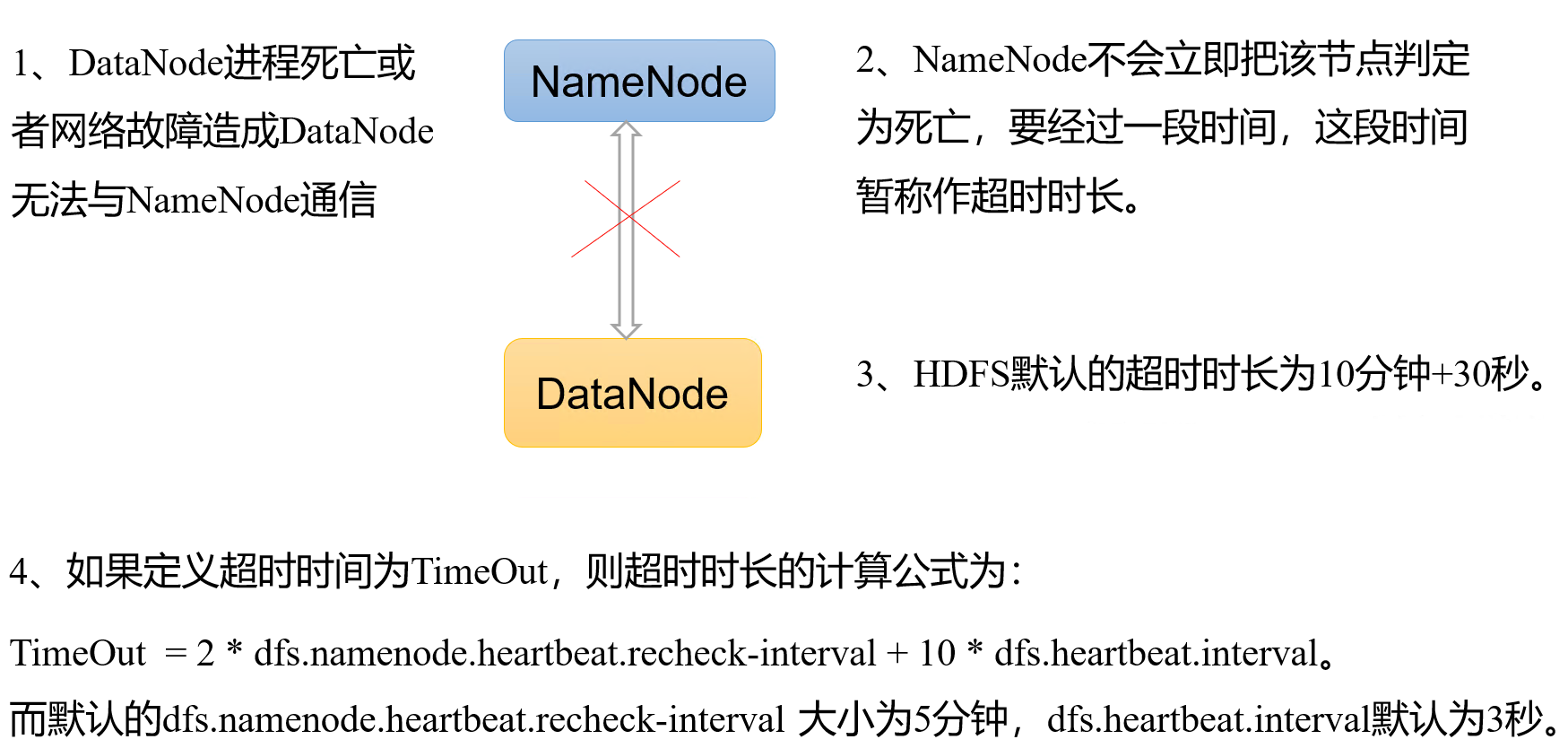
需要注意的是hdfs-site.xml 配置文件中的
heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>