Technologie de reconnaissance vocale Kaldi (7) ----- GMM
Annuaire d'articles
GMM de formation
Dans l'article précédent, nous avons parlé des avantages du GMM par rapport au DTW, alors comment obtient-on la formation GMM ?
Le processus de formation de GMM est le suivant :
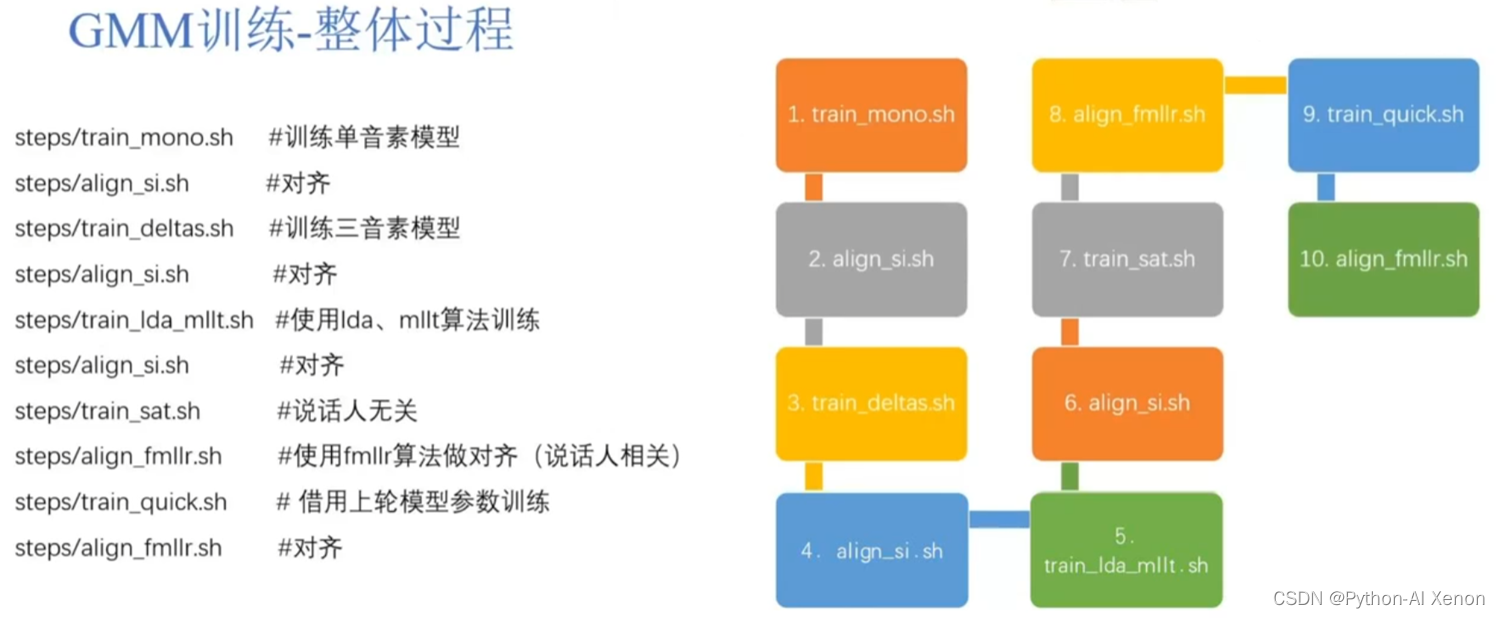
L'ensemble du processus est divisé en 10 liens, dont 5 sont liés à l'alignement. Pour la commodité de la compréhension, seuls 2 de ces 10 liens (train_mono modèle de formation à un facteur et align_si alignement) sont discutés, et les autres sont essentiellement effectués Optimisation, toutes les personnes impliquées dans ce domaine peuvent Baidu par elles-mêmes à l'avenir. Le processus général consiste à former d'abord un modèle gaussien, à utiliser le modèle gaussien pour aligner les données d'apprentissage, puis à utiliser les données alignées pour former un modèle gaussien. Par exemple (l'image de droite ci-dessus), entraînez d'abord un modèle monophone, puis utilisez le modèle monophone pour aligner les données d'entraînement, puis, sur la base de ces données alignées, entraînez un modèle triphone, puis utilisez le modèle triphone pour align Alignez les données de formation, puis utilisez lda, mllt et d'autres algorithmes pour réévaluer le modèle GMM, puis alignez les données de formation, puis effectuez des opérations indépendantes du locuteur et associées sur le modèle, et enfin alignez à nouveau les données de formation. L'ensemble du processus du modèle de formation GMM est comme ça. En général, plus le modèle est formé, plus l'alignement sera précis, ce qui améliorera la précision de la reconnaissance vocale.
Formation GMM—processus de formation mono
Voyons comment le modèle monophone est entraîné. Premièrement, pour entraîner un modèle, il doit y avoir un modèle de départ, puis un entraînement itératif sur ce modèle de départ. Kaldi appelle donc gmm-init-mono pour initialiser le modèle, qui utilise les caractéristiques des données d'apprentissage pour initialiser le modèle. Une fois le modèle initialisé, il est temps de créer un graphique. Il existe plusieurs entrées pour ce graphique, y compris le modèle initialisé, L.fst dans le fichier lang, et le texte dans le dictionnaire et les données d'apprentissage. Le résultat généré est un phrase jusqu'au niveau du phonème Paquet compressé (gz) du fst.
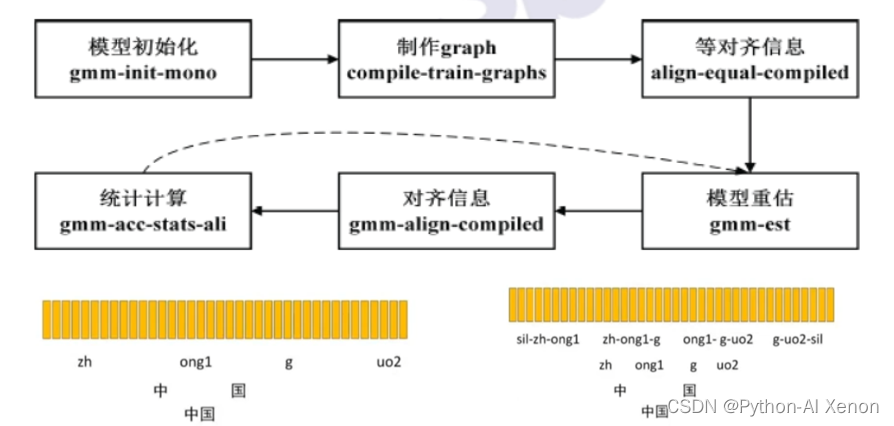
Après avoir terminé les deux premières étapes, la façon d'utiliser les entités que nous avons extraites pour correspondre à la carte FST que nous avons créée nécessite un alignement. La troisième étape utilise l'alignement uniforme (alignement égal sur la figure).Comme mentionné précédemment, FST divise la phrase du fichier d'étiquettes en mots, mots, phonèmes, puis l'état dans HMM.
Pour faciliter la compréhension, nous affinons uniquement les phonèmes de l'image, divisons le mot (Chine) en caractères (Zhongheguo), puis le divisons en phonèmes (zh, ong1, g, uo2), chaque mot a 2 phonèmes, un total de 4 phonèmes, les barres verticales jaunes ci-dessus représentent une caractéristique de trame (caractéristique MFCC), l'alignement uniforme ici consiste à supposer qu'il y a 4 phonèmes et 100 caractéristiques de trame, chaque phonème est divisé de manière égale en 25 caractéristiques de trame, respectivement Trouvez la moyenne et la variance de ces 25 caractéristiques de trame, et vous pouvez obtenir le modèle gaussien correspondant.
La partie inférieure de l'image est notre modèle de triphone (en tenant compte de la co-prononciation), le modèle de triphone a une grande quantité de données, donc le regroupement d'arbres de décision est utilisé dans kaldi pour regrouper certains phonèmes avec une prononciation similaire dans une catégorie, puis se concentrer sur la formation . Après un alignement uniforme, nous réévaluerons le modèle. Le modèle d'initialisation est sélectionné au hasard à partir d'une partie des données d'apprentissage. Maintenant, nous avons compté les caractéristiques de toutes les données audio et, grâce à un alignement uniforme, l'état et le saut correspondants de chaque fonction de trame probabilité de virage. Sur la base de ces informations, nous réévaluons le modèle. L'étape suivante consiste à aligner les données sur le modèle réévalué (étape 5). À ce stade, au lieu d'utiliser l'alignement uniforme, nous utilisons les statistiques après la réévaluation. Combiné avec le FST précédent pour générer de nouvelles informations d'alignement, ce processus peut être simplement compris comme un modèle décodant l'ensemble d'apprentissage, et mettre les caractéristiques correspondant à chaque trame de données dans le GMM correspondant à chaque phonème ou à chaque état pour calculer le probabilité , le phonème avec la probabilité la plus élevée est le phonème correspondant à cette trame. Comme nous l'avons dit précédemment, chaque phonème correspond à 25 trames. Après cette étape, le phonème correspondant change (en supposant que le premier phonème correspond à 20 trames). Sur la base de ces informations d'alignement, nous pouvons calculer statistiquement le rapport du nombre de sauts de chaque phonème au nombre total de sauts, de sorte que nous puissions réestimer la probabilité de saut de chaque état dans le réseau HMM, puis mettre à jour ces états. probabilités de transition et chaque Après les informations d'alignement d'une image, nous pouvons réévaluer notre modèle GMM (passer de l'étape 6 à l'étape 4). De cette façon, le modèle est réévalué à plusieurs reprises, de nouvelles informations d'alignement sont générées, la transition probabilité est calculée, puis le modèle est réévalué. Le nombre spécifique de fois comme celui-ci est défini par nous, et la valeur par défaut est de 40 fois.
train_mono.sh est utilisé pour former GMM
Voyons comment le modèle monophone est formé dans Kaldi en appelant le script train_mono.sh dans le dossier step. En particulier, si vous utilisez des paramètres multi-thread, le nombre de nj ne peut pas dépasser le nombre de haut-parleurs (spekerid), qui divise le nombre de threads en fonction du nombre de haut-parleurs.
Utilisation de train_mono.sh :
./steps/train_mono.sh
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>
e.g.: steps/train_mono.sh data/train.1k data/lang exp/mono
main options (for others, see top of script file)
--config <config-file> # config containing options
--nj <nj> # number of parallel jobs
--cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs.
Référence : Premiers pas avec Kaldi en détail train_mono.sh document officiel
Préparez d'abord l'environnement Kaldi
. ~/kaldi/utils/path.sh
mkdir H_learn
cd ~/kaldi/data
puis exécutez le script
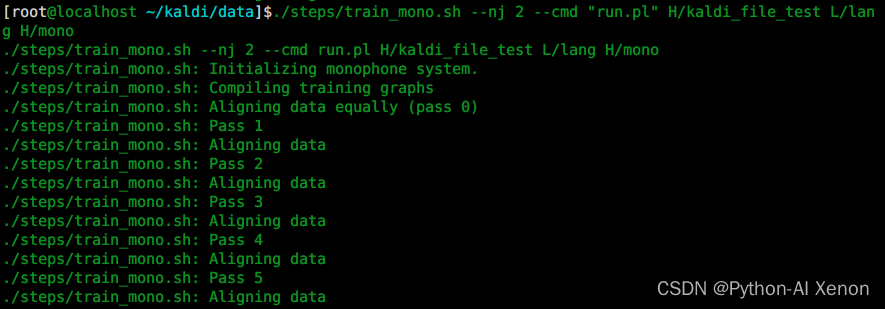
./steps/train_mono.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono
Explication détaillée des paramètres :
Le premier paramètre : –nj Plusieurs threads sont formés en parallèle ( note : si les caractéristiques de chaque locuteur sont extraites, le nombre de nj ne peut pas dépasser le nombre de locuteurs ) Le deuxième paramètre : run.pl exécute le troisième paramètres
locaux
: dossier de fonctionnalités (y compris les fonctionnalités cmvn et mfcc d'origine, voir la colonne cinq du blog)
quatrième paramètre : dossier lang (dossier lang dans le dossier L)
cinquième paramètre : dossier de données de formation GMM de sortie (modèle monophone)
Entraîner GMM—Générer des fichiers
Après avoir utilisé train_mono.sh pour entraîner le modèle monophone, nous avons généré ces fichiers. La première et la plus importante est le modèle (mdl, où 0.mdl représente le modèle initialisé ; 40.mdl représente le résultat de 40 itérations ; final.mdl représente le modèle final), suivi du fichier en fin d'occs, qui peut être compris simplement comme une statistique globale, comptant les informations de chaque phonème ou chaque phonème correspondant à plusieurs états. ali..gz est l'information d'alignement, et l'information d'alignement sera mise à jour à chaque itération du modèle. fst..gz est une information de grille, qui est une information FST que nous avons mentionnée plus tôt. tree est un arbre de décision, qui rassemble certains phonèmes avec une prononciation similaire dans une catégorie, ce qui est pratique pour le calcul. Le journal est le journal généré pendant le processus de formation. Si une erreur se produit pendant le processus de formation, vous pouvez essentiellement y trouver le message d'erreur correspondant.

*.mdl : le modèle 0.mdl représente le modèle initialisé ; 40.mdl représente le résultat de 40 itérations ; final.mdl représente le résultat final.
*.occs : le nombre d'occurrences de chaque pdf
ali.*.gz : informations d'alignement
fst.*.gz : grille d'informations
tree : arbre de décision
log : journal du processus de formation
Formation GMM—vue finale du modèle
Convertir final.mdlles données en texte et la sortie en final_mdl.txttexte (--binary=false signifie ne pas utiliser de données binaires)
gmm-copy --binary=false final.mdl final_mdl.txt
vim final_mdl.txt Ouvrez le fichier comme suit :
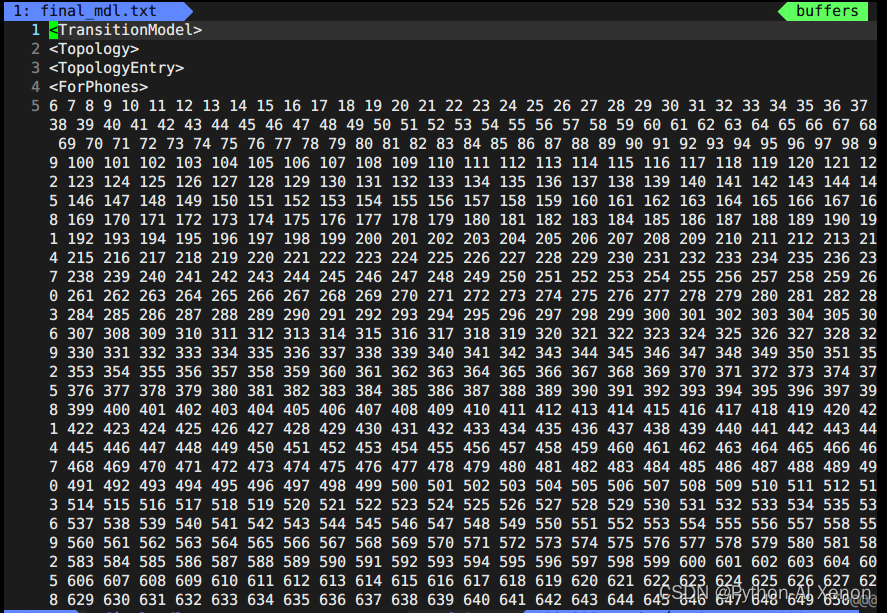
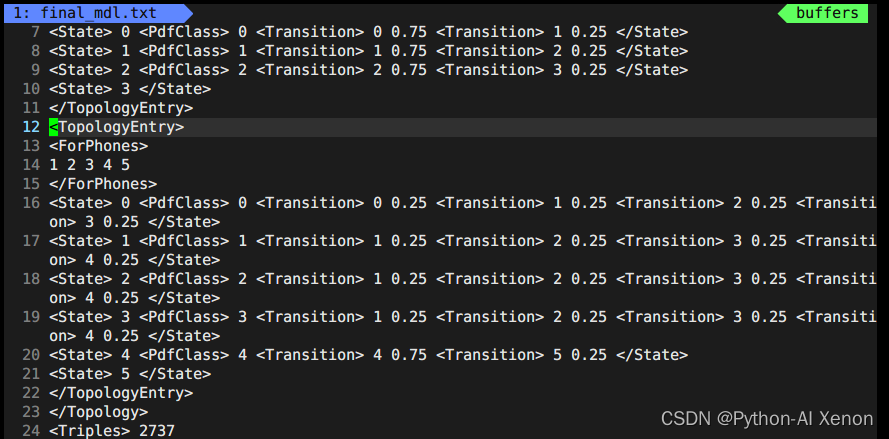
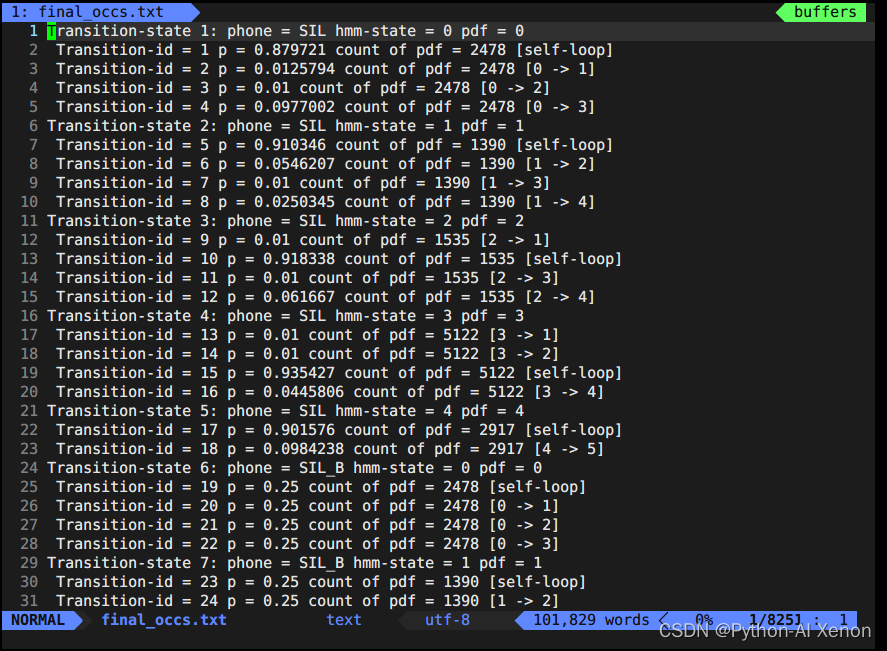
Cette partie de l'information se trouve dans le fichier topo généré lorsque nous avons généré G.fst avant les 23 premières lignes. Nous pouvons dessiner les états HMM correspondants, c'est-à-dire que les états 6 à 909 partagent un état HMM3 et 1 à 5 (phonèmes silencieux) partagent un état HMM 5. La 24e ligne 2727 représente le nombre de nos groupes d'arbres de décision. Dans les informations de l'arbre de décision : la première colonne est l'index de phonème (phone-id), la deuxième colonne est l'état HMM et la troisième colonne est l'index PDF (classe d'arbre de décision)
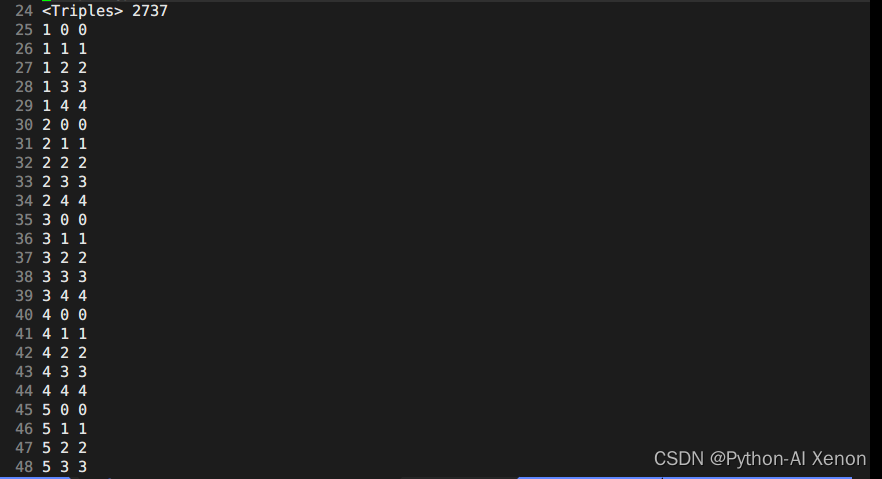
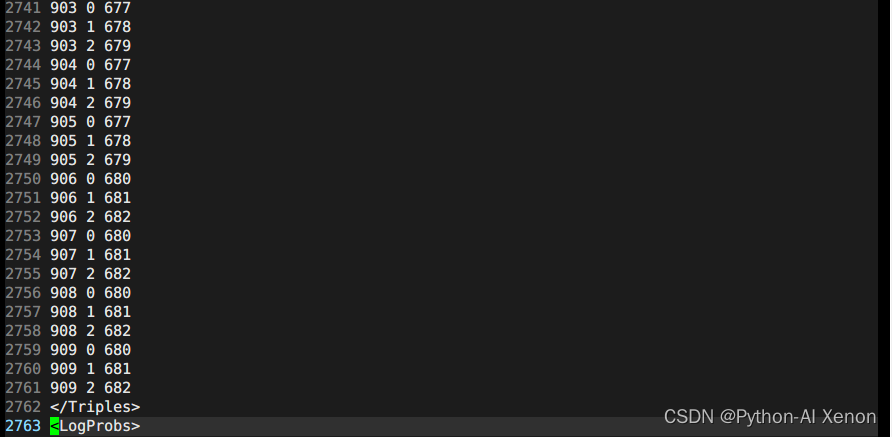
Nous pouvons voir que nos phonèmes ont un total de 909, alors pourquoi peuvent-ils être regroupés en 2737 catégories ? Comme on peut le voir sur la figure, de la ligne 25 à la ligne 49 dans la deuxième colonne de 25 lignes, ils appartiennent tous à des phonèmes muets (pourquoi ? Les numéros de série sont tous 0-4, 5 états, seuls les phonèmes muets ont 5 états) . Enfin, nous pouvons obtenir la formule du nombre de clusters comme suit :
Le nombre de classes d'arbre de décision = nombre de phonèmes silencieux * 5 + phonèmes non silencieux * 3


Étant donné qu'il existe de nombreuses autres informations dans l'arbre de décision, vous pouvez ouvrir les informations de l'arbre de décision local pour les afficher vous-même. Les informations dans <LogProbs> correspondent à la probabilité de transition de chaque classe et le nombre dans <dimension> correspond à 3 fois l'entrée. (MFCC). C'est parce que les entités d'entrée ont fait une différence de premier ordre et une différence de second ordre, plus l'entité d'origine est le nombre 39, <numpdfs> est le nombre de nos classes d'arbre de décision, et chaque classe peut correspondre à un modèle de mélange gaussien (GMM). Voici la description des 656 GMM dans la figure. La description d'un modèle gaussien n'a besoin que de la moyenne et de la variance (connaissez-les). S'il s'agit d'un gaussien mixte, plusieurs combinaisons gaussiennes sont nécessaires. Chacun Le poids du gaussien dans le gaussien mixte. Par exemple, il y a 2 poids dans le poids <poids> dans la figure ci-dessus, cela signifie que le gaussien mixte décrivant la probabilité de ce phonème est composé de 2 gaussiens simples. Les poids respectifs sont XXX, XXX, le moyenne a 39 colonnes, une gaussienne correspond à une moyenne à 39 dimensions et deux gaussiennes ont deux moyennes. De même, la variance est la même. En plus des poids, il existe également un hyperparamètre <gconsts>, qui est également un gaussien correspondant à un. Pas trop d'introduction en profondeur ici.
Formation GMM—vue final.occs
Ensuite, regardons le fichier final.occs, qui peut être simplement compris comme une statistique globale, qui compte des informations sur chaque phonème ou le nombre d'états auxquels chaque phonème correspond. C'est-à-dire une description de chaque réseau HMM. Nous avons mentionné précédemment que chaque phonème peut être subdivisé en BEIS (correspondant à plusieurs états), nous savons que le phonème muet HMM a 5 états (BEIS + 5 états de lui-même), et le phonème non muet BEI a 3 états. occs consiste à diviser chaque phonème et à faire des statistiques séparément. L'état de transition est une description de chaque état, où le nombre dans le décompte de pdf indique le nombre de fois que ce bord apparaît.
Statistiques de chaque phonème ou information de plusieurs états correspondant à chaque phonème
show-transitions phones.txt final.mdl final.occs > final_occs.txt
vim final_occs.txtOuvrez le fichier comme suit :
Formation GMM—Afficher les informations d'alignement
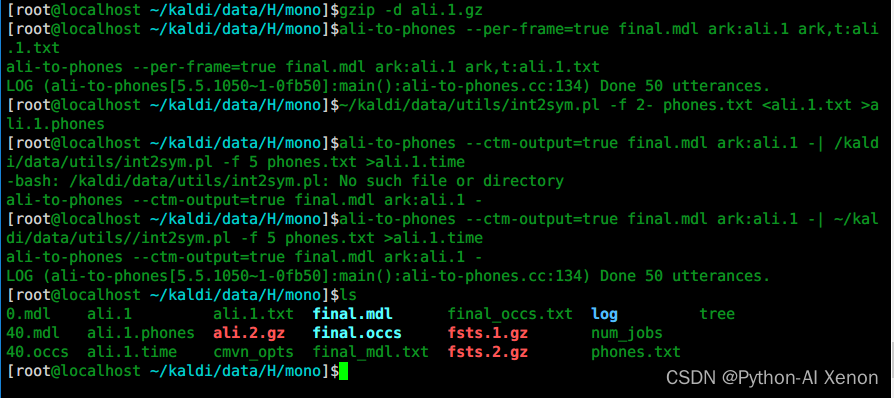
# 1 解压
gzip -d ali.1.gz
Les fonctionnalités sont mentionnées au niveau du cadre, et la formation est également formée au niveau du cadre. Quel est le résultat de la formation ? Vous pouvez utiliser la commande ali-to-phones pour vérifier quelles trames correspondent à quel phonème. Chaque numéro de la figure représente un ID de phonème. Pour faciliter la visualisation, nous devons convertir l'ID de phonème en phonème correspondant.
# 2 使用ali-to-phones进行查看
ali-to-phones --per-frame=true final.mdl ark:ali.1 ark,t:ali.1.txt
Quel est le phonème correspondant à chaque phone-id ? Utilisez le script int2sym.pl pour convertir l'identifiant du phonème en phonème correspondant, et nous pouvons voir les informations temporelles de chaque phonème.
# 3 将音素id转换为对应的音素
~/kaldi/data/utils/int2sym.pl -f 2- phones.txt <ali.1.txt >ali.1.phones
Combien de temps dure chaque phonème ? Par exemple, cette phrase "fixer vingt-neuf degrés", vous pouvez la vérifier via le logiciel de visualisation audio. Puisque nous utilisons un seul modèle d'entraînement de phonème, l'alignement peut ne pas être complètement précis, donc le modèle doit être entraîné à plusieurs reprises.
# 4 各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -| ~/kaldi/data/utils//int2sym.pl -f 5 phones.txt >ali.1.time
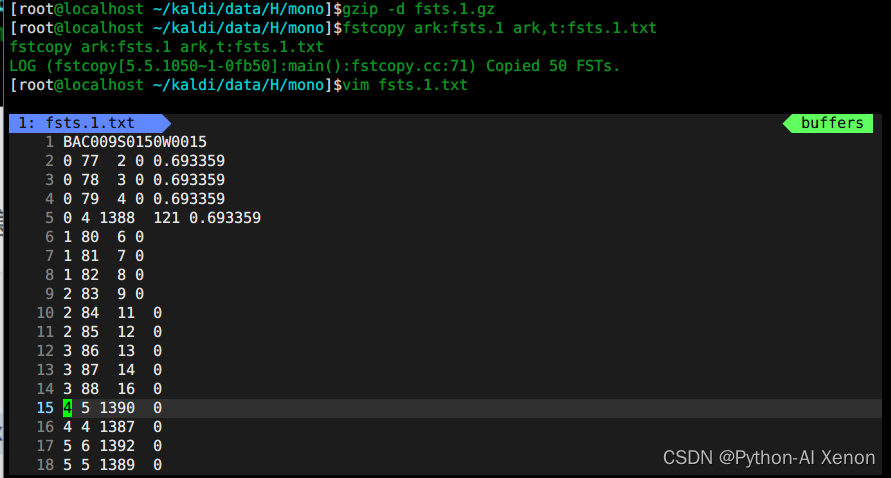
GMM de formation : vue fsts.*.gz
Ce qui est stocké ici est la première information de structure de réseau correspondant à chaque déclaration, donc je n'entrerai pas dans les détails ici.
# 1、解压
gzip -d fsts.1.gz
# 2、查看
fstcopy ark:fsts.1 ark,t:fsts.1.txt
vim fsts.1.txt
GMM de formation : arborescence de décision
- affichage
tree-info tree

num-pdfs 683 signifie : le nombre de classes d'arbre de décision, qui sont divisées en 683 classes au
total
. La position de l'arbre de décision est 0, s'il s'agit d'un 3 phonème, ici est 1 (central signifie le phonème du milieu, le devant est 0, et le dos est 2)
- arbre de décision visuel
draw-tree phones.txt tree | dot -Gsize=8,10.5 -Tps | ps2pdf - tree.pdf
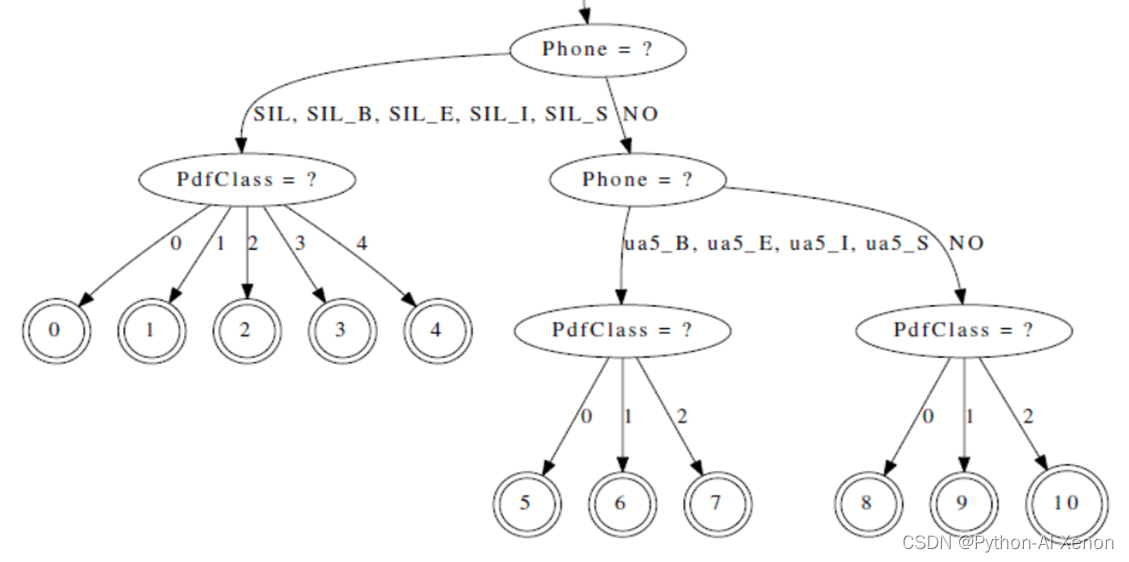
L'arbre de décision peut être dessiné visuellement grâce à la commande draw-tree. Étant donné que l'arbre de décision est très grand, seule une partie de celui-ci est interceptée ici, et il n'est pas entièrement affiché. Vous pouvez l'ouvrir en pdf pour le visualiser. Comme on peut le voir sur la figure ci-dessus, le phonème silencieux SIL est un nœud enfant, correspondant à 5 nœuds (0-4 nœuds), et le phonème ua5 correspond à 3 nœuds (5-7 nœuds), ce qui correspond à ce qui a été mentionné ci-dessus (5 états pour les phonèmes en sourdine, 3 états pour les phonèmes non en sourdine)
align_si.sh pour l'alignement
pour l'alignement
Une fois le modèle monophone formé, nous pouvons utiliser le modèle monophone pour aligner les données de formation. La commande d'alignement est align_si.sh, c'est la deuxième étape du modèle de formation GMM.
cd ~/kaldi/data
./steps/align_si.sh --nj 2 --cmd "run.pl" H/kaldi_file_test L/lang H/mono H/mono_ali
Explication détaillée des paramètres :
Le premier paramètre : –nj Plusieurs threads sont formés en parallèle ( note : si les caractéristiques de chaque locuteur sont extraites, le nombre de nj ne peut pas dépasser le nombre de locuteurs ) Le deuxième paramètre : run.pl exécute le troisième
localement
Paramètres : dossier de fonctionnalités (y compris les fonctionnalités cmvn et mfcc d'origine)
quatrième paramètre : dossier lang (dossier lang dans le dossier L) cinquième paramètre : dossier
de modèle de formation monophonique
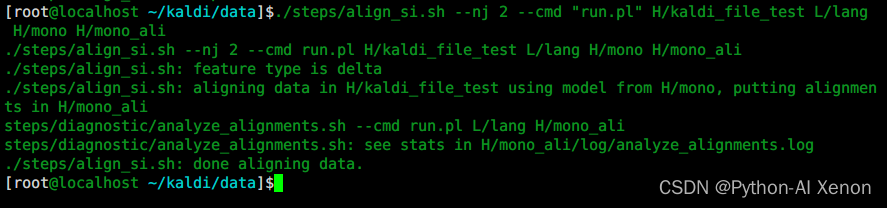
Formation GMM—voir le contenu généré par mono_ali.sh

# 1、解压
gzip -d ali.1.gz
# 2、生成各音素的对齐时间信息
ali-to-phones --ctm-output=true final.mdl ark:ali.1 -|~/kaldi/data/utils/int2sym.pl -f 5 phones.txt >ali.1.time
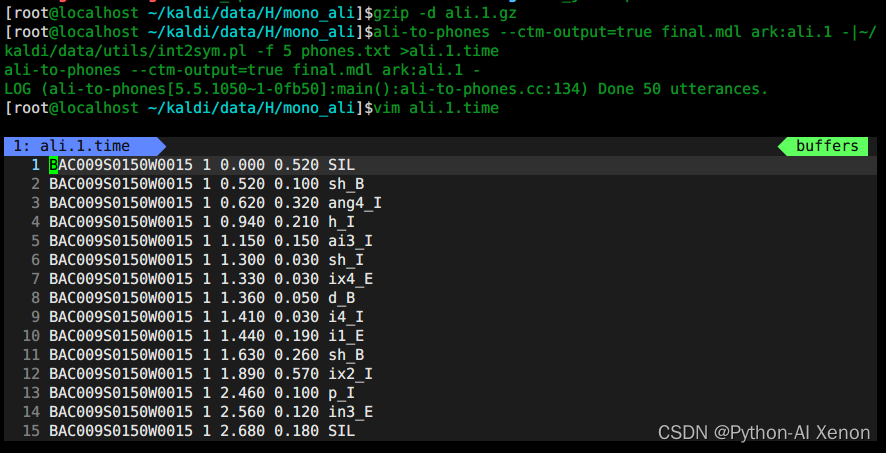
ps: De même, nous pouvons également utiliser la commande ali-to-phones pour afficher les informations d'alignement.
Formation GMM : comparaison des informations d'alignement mono et mono_ali
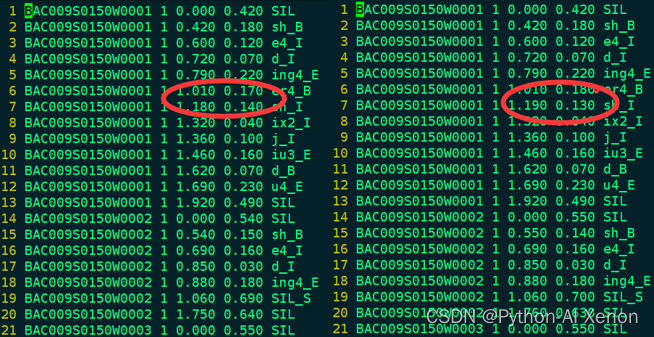
Nous pouvons comparer nos informations alignées avec les informations d'alignement lors de la formation Mono. On peut voir que le nombre total de lignes des deux fichiers n'est pas très différent, et la plupart des informations d'alignement ne sont pas très différentes, indiquant que la capacité d'alignement de le modèle monophone est comme ça, et il doit être changé. Nouvel algorithme pour améliorer la capacité d'alignement du modèle.