Bonjour à tous, l'article d'aujourd'hui a été traduit par ma bonne amie Alpha Rabbit. Elle est restée éveillée tard le matin pour étudier le GPT-4 lancé par OpenAI. Elle a essentiellement lu tous les points clés du contenu publié et l'a partagé avec tout le monde. un peu d'inspiration .
Auteur | OpenAI&TheVerge&Techcrunch
Traduction & Analyse |
01
points forts
* Cet article fait environ 6000 mots
GPT-4 peut accepter la saisie d'images et de texte, tandis que GPT-3.5 n'accepte que du texte.
GPT-4 atteint des performances de « niveau humain » sur divers critères professionnels et académiques. Par exemple, il a réussi l'examen du barreau simulé avec des scores parmi les 10 % des meilleurs candidats.
Il a fallu 6 mois à OpenAI pour ajuster à plusieurs reprises GPT-4 en utilisant l'expérience acquise grâce au projet de test contradictoire et à ChatGPT.
Dans le chat simple, la différence entre GPT-3.5 et GPT-4 peut être insignifiante, mais lorsque la complexité de la tâche atteint un seuil suffisant, la différence ressort, et GPT-4 est plus fiable et créatif que GPT-3.5 Force, capable de gérer des instructions plus subtiles.
GPT-4 peut illustrer et interpréter des images relativement complexes, comme identifier un adaptateur Lightning Cable à partir d'une image branchée sur un iPhone (image ci-dessous).
Les capacités de compréhension des images ne sont pas encore disponibles pour tous les clients d'OpenAI, qu'OpenAI teste avec son partenaire Be My Eyes.
OpenAI admet que GPT-4 n'est pas parfait et a toujours un sentiment de confusion concernant les problèmes de vérification des faits, certaines erreurs de raisonnement et un excès de confiance occasionnel.
Open-source OpenAI Evals, pour créer et exécuter des benchmarks qui évaluent des modèles tels que GPT-4 tout en vérifiant leurs performances échantillon par échantillon.
02
Document officiel
OpenAI a officiellement lancé GPT-4, qui est la dernière étape de l'expansion de l'apprentissage en profondeur d'OpenAI. GPT-4 est un grand modèle multimodal ( capable d'accepter des entrées de type image et texte, donnant une sortie texte ), bien que GPT-4 ne soit pas aussi capable que les humains dans de nombreux scénarios du monde réel, il peut être utilisé dans divers professionnels et académique Sur les points de repère, il présente des performances proches du niveau humain.
Exemple : GPT-4 a réussi un examen du barreau simulé avec des scores parmi les 10 % supérieurs de tous les candidats. En revanche, le score de GPT-3,5 est d'environ les 10 % inférieurs. Notre équipe a passé 6 mois à ajuster GPT-4 à plusieurs reprises en utilisant mon projet de test contradictoire et l'expérience connexe basée sur ChatGPT. Le résultat est que le GPT-4 obtient les meilleurs résultats jamais obtenus en termes de factualité, de maniabilité et de refus de sortir des garde-corps. Ce n'est pas encore parfait)
Au cours des deux dernières années, nous avons refactorisé l'ensemble de la pile d'apprentissage en profondeur et nous nous sommes associés à Azure pour co-concevoir un supercalculateur pour la charge de travail à partir de zéro. Il y a un an, OpenAI a formé GPT-3.5 comme premier "essai" de l'ensemble du système, en particulier, nous avons trouvé et corrigé quelques bogues et amélioré la base théorique précédente. En conséquence, notre GPT-4 s'entraîne, roule (en toute confiance : du moins pour nous !) d'une stabilité sans précédent et devient notre premier grand modèle dont les performances d'entraînement peuvent être prédites avec précision à l'avance. Alors que nous continuons à nous concentrer sur une mise à l'échelle fiable, un objectif intermédiaire est de perfectionner les méthodes pour aider OpenAI à continuer à prédire et à préparer l'avenir, ce qui, selon nous, est essentiel à la sécurité.
Nous publions des capacités de saisie de texte pour GPT-4 via ChatGPT et API (vous pouvez rejoindre WaitList), et nous travaillons en étroite collaboration avec nos partenaires pour prendre un bon départ afin de rendre les capacités de saisie d'image plus largement disponibles. Nous prévoyons d'ouvrir OpenAI Evals, qui est également notre cadre d'évaluation automatique des performances des modèles d'IA. N'importe qui peut suggérer des lacunes dans notre modèle pour l'aider à s'améliorer.
03
capacité
Il n'est peut-être pas facile de faire la différence entre GPT-3.5 et GPT-4 dans une simple conversation. Cependant, lorsque la complexité de la tâche atteint un seuil suffisant, leurs différences ressortent. Plus précisément, GPT-4 est plus fiable et créatif que GPT-3.5, capable de gérer des instructions plus fines.
Pour comprendre les différences entre les deux modèles, nous les avons testés sur une variété de points de repère, y compris des tests de simulation conçus à l'origine pour les humains. En utilisant le dernier test public (Olympiade, AP, etc.) et en incluant l'achat de la version 2022-2023 du test de pratique, nous n'avons pas spécialement formé le modèle pour ce type de test, bien sûr, il y a peu de problèmes dans le test est présent pendant le processus d'apprentissage du modèle, mais nous considérons que les résultats suivants sont représentatifs.
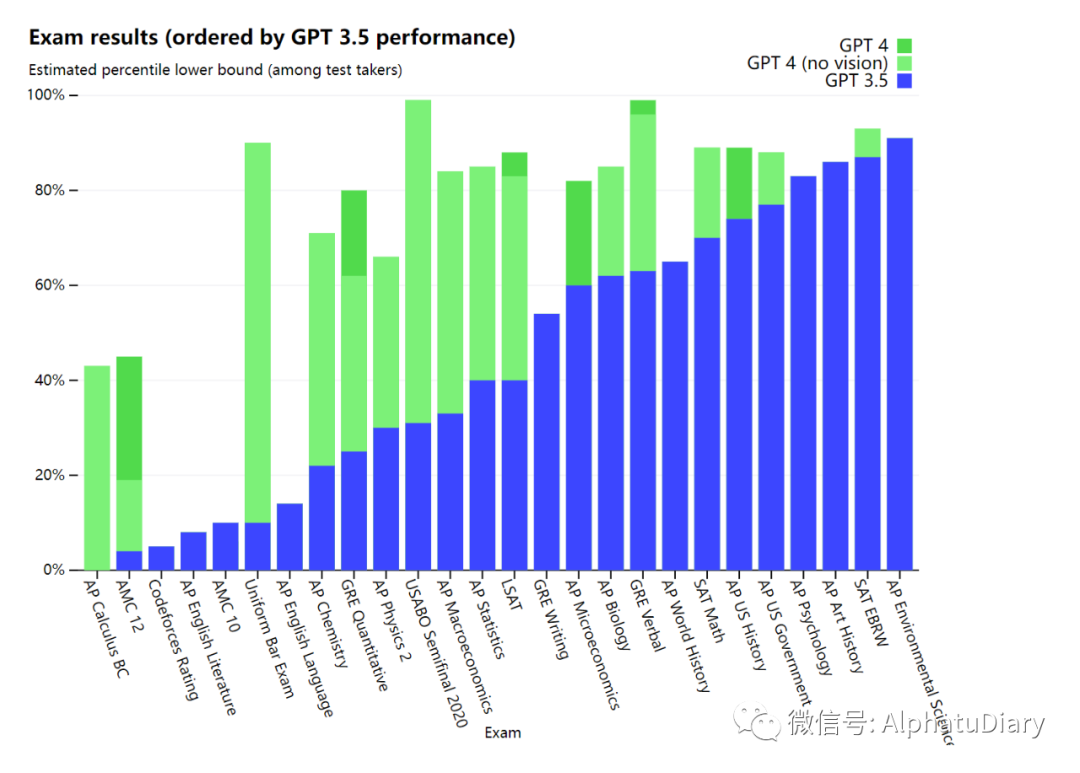
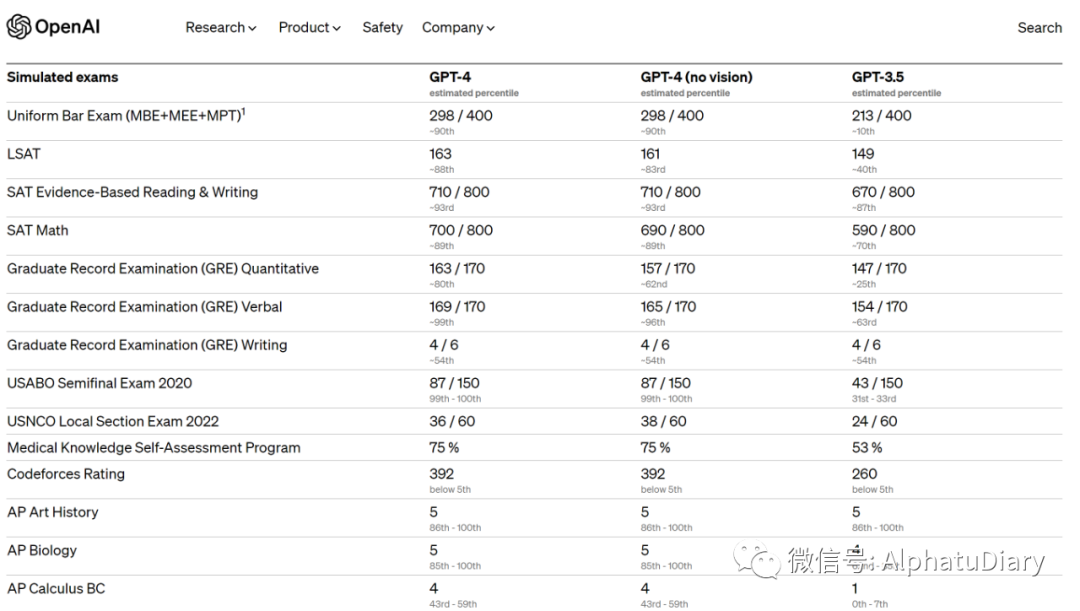
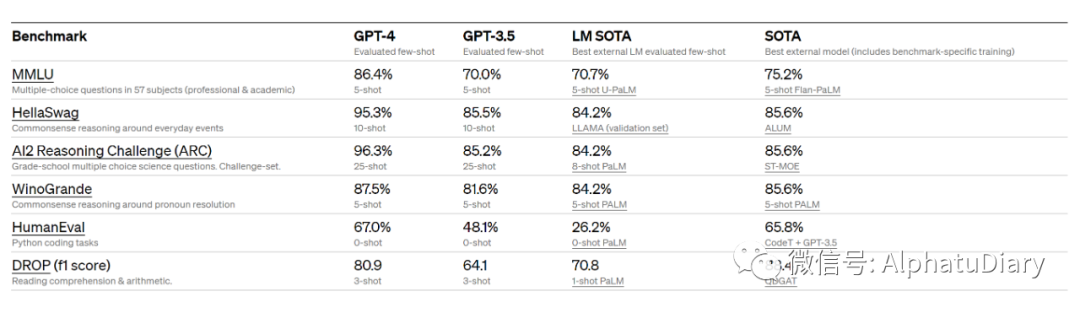
Nous évaluons également GPT-4 sur des benchmarks traditionnels conçus pour les modèles d'apprentissage automatique. GPT-4 surpasse considérablement les grands modèles de langage existants et est au coude à coude avec la plupart des modèles de pointe (SOTA) qui incluent des protocoles de formation spécifiques ou supplémentaires.
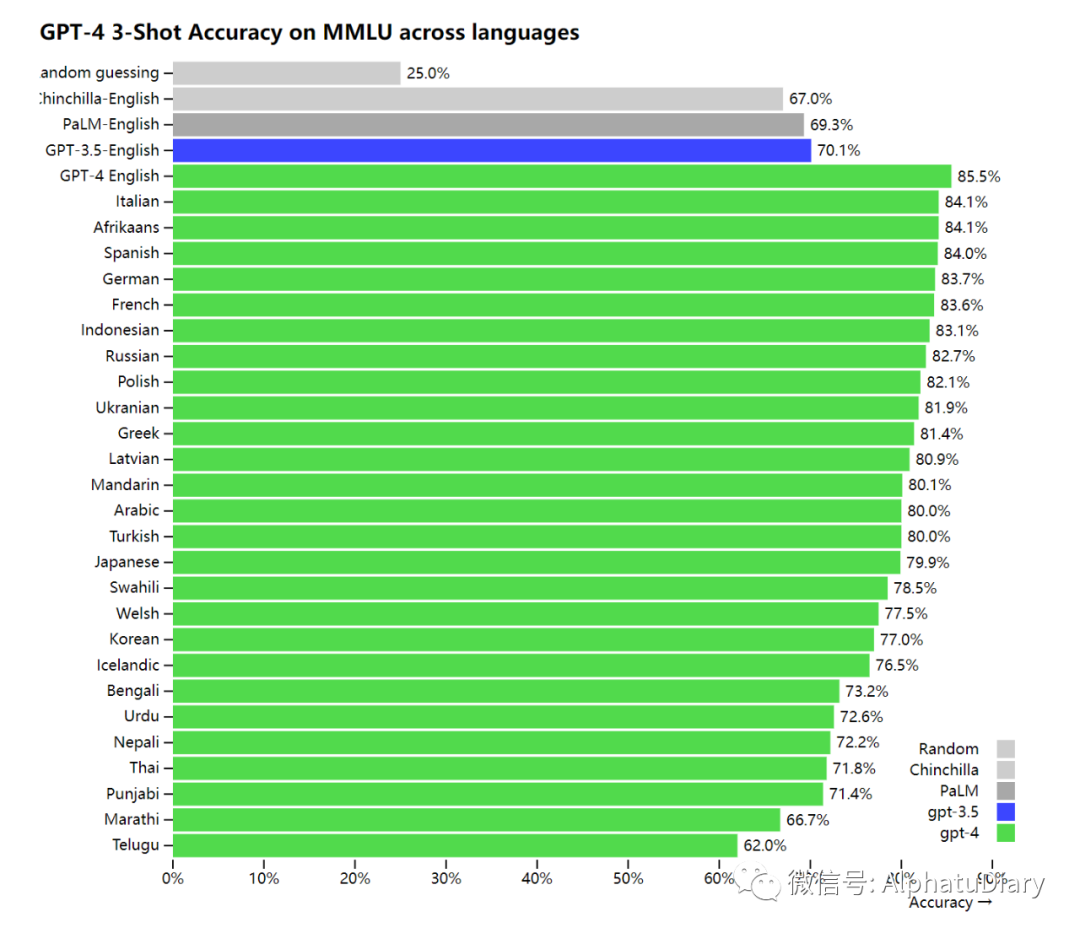
Étant donné que la plupart des benchmarks ML existants sont écrits en anglais, pour avoir un premier aperçu des fonctionnalités dans d'autres langues, nous avons utilisé Azure Translate pour traduire le benchmark MMLU : un ensemble de 14 000 questions à choix multiples couvrant 57 sujets, dans différentes langues. Dans 24 des 26 langues testées, le GPT-4 a surpassé le GPT-3.5 et d'autres grands modèles (Chinchilla, PaLM) en anglais, et cette excellence comprend également des langues comme le letton, le gallois, le sri-lankais, le vahili et plus encore.
Nous utilisons GPT-4 en interne et nous avons constaté qu'il avait un impact important sur des fonctions telles que l'assistance, les ventes, la modération de contenu et la programmation. Nous l'utilisons également pour aider les humains à évaluer les résultats de l'IA. Il s'agit de la deuxième phase de notre stratégie d'ajustement Start.
04
entrée visuelle
GPT-4 peut accepter des invites de texte et d'image, ce qui est parallèle à la configuration du texte uniquement. Par exemple, l'utilisateur peut spécifier n'importe quelle tâche visuelle ou linguistique, il peut générer une sortie de texte (langage naturel, code, etc.), l'entrée donnée comprend des documents avec du texte et des photos, des diagrammes ou des captures d'écran, GPT-4 montre les mêmes capacités similaires pour la saisie de texte brut. En outre, il peut également être appliqué à la technologie de temps de test développée pour le modèle de langage en texte brut, y compris quelques prises de vue et des invites CoT, mais l'entrée d'image actuelle est toujours un aperçu de recherche, et il n'y a pas de produit public comme le C- côté.
Les images suivantes montrent l'emballage d'un adaptateur "Lightning Cable" avec trois panneaux.


Panneau 1 : Un smartphone avec un connecteur VGA (le gros connecteur bleu à 15 broches généralement utilisé sur les écrans d'ordinateur) branché sur son port de charge.
Panneau 2 : Il y a une image du port VGA sur l'emballage de l'adaptateur « Lightning Cable ».
Panneau 3 : gros plan du connecteur VGA, se terminant par un petit connecteur Lightning (utilisé pour charger les iPhones et autres appareils Apple).
La nature hilarante de cette image vient du fait de brancher un grand connecteur VGA obsolète dans un petit port de chargement de smartphone moderne.
Prévisualisez GPT-4 en évaluant ses performances sur un ensemble restreint de critères de vision universitaires standard. Cependant, ces chiffres ne représentent pas l'étendue de ses capacités, car nous avons constaté que ce modèle est capable de gérer de nombreuses tâches nouvelles et passionnantes, et OpenAI prévoit de publier prochainement d'autres chiffres d'analyse et d'évaluation, ainsi que l'effet technique sur le test. Étudiez minutieusement les résultats.
05
IA contrôlable
Nous avons travaillé dur pour réaliser tous les aspects du plan décrit dans l'article sur la définition du comportement de l'IA, y compris la contrôlabilité de l'IA. Au lieu du discours, du ton et du style fixes des personnalités classiques de ChatGPT, les développeurs (et bientôt tous les utilisateurs de ChatGPT) peuvent désormais dicter le style et les tâches de leur propre IA en décrivant ces directions dans des messages "système". Les messages système permettent aux utilisateurs de l'API de personnaliser considérablement l'expérience utilisateur dans une certaine plage, et nous continuerons à nous améliorer.
06
limitation
Malgré ses capacités étonnantes, GPT-4 souffre de limitations similaires aux modèles GPT précédents. En plus de cela, il n'est toujours pas complètement fiable (par exemple, il peut "halluciner" des faits et faire des erreurs d'inférence). Lors de l'utilisation de la sortie d'un modèle de langage, en particulier dans des situations à enjeux élevés, une grande prudence doit être prise (par exemple, un examen humain est requis, l'utilisation à enjeux élevés doit être entièrement évitée) et elle doit être adaptée aux besoins de l'utilisation spécifique cas.
Alors que toutes sortes de choses existent encore, GPT-4 réduit considérablement les hallucinations (c'est-à-dire les illusions de réseau, dans ce cas de graves absurdités) par rapport aux modèles précédents (qui eux-mêmes s'améliorent constamment). Dans notre évaluation factuelle contradictoire interne, GPT-4 obtient un score de 40 % supérieur à notre GPT-3.5 à la pointe de la technologie.
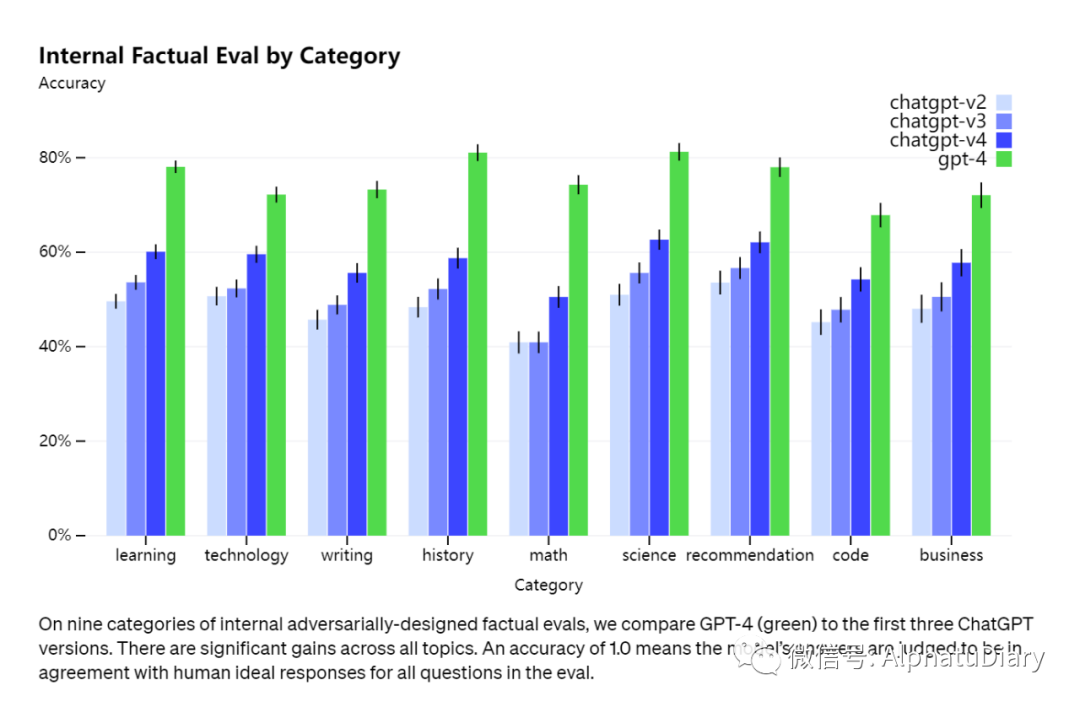
07
IA contrôlable
Le modèle de base de GPT-4 ne surpasse que légèrement GPT-3.5 sur cette tâche ; cependant, après la post-formation avec RLHF (en appliquant la même procédure que nous avons utilisée pour GPT-3.5), il y a un grand écart. Le modèle aura divers biais dans sa sortie, et nous avons fait des progrès dans ces domaines, mais il reste encore du travail à faire. Selon notre récent article de blog, notre objectif est de faire en sorte que les systèmes d'IA que nous construisons aient des comportements par défaut sensibles qui reflètent un large éventail de valeurs utilisateur, permettent à ces systèmes d'être personnalisés sur de larges plages et obtiennent l'avis du public sur ces plages.
Le GPT-4 manque généralement de connaissance des événements survenus après la coupure pour la grande majorité de ses données (septembre 2021), et n'apprendra pas de son expérience. Il fait parfois de simples erreurs de raisonnement qui ne semblent pas correspondre aux capacités de tant de domaines, ou est trop crédule dans les fausses déclarations évidentes des utilisateurs. Il échoue aussi parfois à des problèmes difficiles comme les humains, comme l'introduction de failles de sécurité dans le code qu'il produit. GPT-4 pourrait également se tromper en toute confiance dans ses prédictions.
08
Risques et atténuations
Nous avons itéré sur GPT-4 pour le rendre plus sûr et cohérent dès le début de la formation. Nos efforts incluent la sélection et le filtrage des données de pré-formation, l'évaluation, l'invitation d'experts à participer, l'amélioration de la sécurité du modèle, la surveillance et l'exécution.
GPT-4 présente des risques similaires aux modèles précédents, tels que la production de conseils nuisibles, un code erroné ou des informations inexactes. Cependant, les capacités supplémentaires de GPT-4 conduisent également à de nouvelles surfaces de risque. Pour clarifier les spécificités de ces risques, nous avons engagé plus de 50 experts dans les domaines des risques d'amarrage de l'IA, de la cybersécurité, des risques biologiques, de la confiance et de la sécurité et de la sécurité internationale pour mener des tests contradictoires du modèle. Leur participation nous permet de tester le comportement du modèle dans des domaines à haut risque qui nécessitent une expertise pour être évalués. Les commentaires et les données d'experts dans ces domaines ont éclairé nos modèles d'atténuation et d'amélioration. Par exemple, nous avons recueilli des données supplémentaires pour améliorer la capacité de GPT-4 à rejeter les demandes sur la façon de synthétiser des produits chimiques dangereux.
GPT-4 intègre un signal de récompense de sécurité supplémentaire dans la formation RLHF en entraînant le modèle à rejeter les demandes de ce type de contenu, réduisant ainsi la sortie nuisible (telle que définie par nos directives d'utilisation). Les récompenses sont fournies par le classificateur de GPT-4, qui est capable de juger de la façon dont les limites de sécurité et les indices liés à la sécurité sont effectués. Pour empêcher les modèles de rejeter les demandes valides, nous collectons divers ensembles de données provenant de différentes sources (par exemple, des données de production étiquetées, des équipes rouges humaines, des indices générés par le modèle) et appliquons des récompenses de sécurité sur les catégories Signal autorisées et non autorisées (présence d'une valeur positive ou négative).
Nos atténuations améliorent considérablement de nombreuses propriétés de sécurité de GPT-4 par rapport à GPT-3.5. Par rapport à GPT-3.5, nous avons réduit la propension du modèle à répondre aux demandes de contenu illégal de 82 %, tandis que GPT-4 a répondu 29 % plus souvent aux demandes sensibles, telles que les conseils médicaux et l'automutilation, conformément à notre politique %
Dans l'ensemble, nos interventions au niveau du modèle augmentent la difficulté d'induire un comportement indésirable, mais il y a toujours du "jailbreaking" pour produire du contenu qui enfreint nos directives d'utilisation. À mesure que les risques pour les systèmes d'IA augmentent, il deviendra essentiel d'atteindre une fiabilité extrême dans ces interventions. Ce qui est important maintenant, c'est de compléter ces limitations par des technologies de sécurité en temps de déploiement, telles que la recherche de moyens de surveillance.
GPT-4 et les modèles ultérieurs sont susceptibles d'avoir des impacts positifs ou négatifs sur la société, et nous travaillons avec des chercheurs externes pour améliorer notre compréhension et notre évaluation des impacts potentiels, ainsi que pour sensibiliser aux capacités dangereuses possibles dans les futurs systèmes Évaluer. Nous partagerons bientôt davantage de nos réflexions sur l'impact social et économique potentiel du GPT-4 et d'autres systèmes d'IA.
09
processus de formation
Comme le modèle GPT précédent, le modèle de base GPT-4 est formé pour prédire le mot suivant dans un document et est formé à l'aide de données accessibles au public (telles que des données Internet) ainsi que de données sous licence. Ces données sont tirées de corpus extrêmement volumineux et comprennent des solutions correctes et incorrectes à des problèmes mathématiques, des raisonnements faibles et forts, des déclarations contradictoires et cohérentes, ainsi qu'une grande variété d'idéologies et d'idées.
Ainsi, lorsqu'il est invité à poser une question, le modèle sous-jacent peut répondre de diverses manières qui peuvent être loin de ce que l'utilisateur voulait. Pour l'aligner sur l'intention de l'utilisateur, nous affinons le comportement du modèle à l'aide de l'apprentissage par renforcement avec rétroaction humaine (RLHF).
Notez que la capacité du modèle semble provenir principalement du processus de pré-entraînement, RLHF n'améliore pas les résultats des tests (il diminue en fait les résultats des tests sans effort actif). Mais le démarrage du modèle intervient dans le processus de post-formation, et le modèle de base a besoin de Prompt Engineering pour même savoir qu'il devrait répondre à la question.
dix
expansion prévisible
L'un des principaux objectifs du projet GPT-4 est de créer une pile d'apprentissage en profondeur qui évolue de manière prévisible. La raison principale est que pour les très grandes séries d'entraînement comme GPT-4, il n'est pas possible de faire beaucoup de réglages spécifiques au modèle. Nous avons développé et optimisé l'infrastructure pour avoir un comportement très prévisible à plusieurs échelles. Pour tester cette évolutivité, nous avons prédit avec précision à l'avance la perte finale de GPT-4 dans notre base de code interne (ne faisant pas partie de l'ensemble de formation) en déduisant à partir d'un modèle formé en utilisant la même méthode, mais en utilisant le calcul Le montant est 10000 fois moins .
Nous pensons que la capacité de l'apprentissage automatique à prédire avec précision l'avenir est un élément important de la sécurité qui a été sous-estimé par rapport à son impact potentiel (bien que nous ayons été encouragés par les efforts de plusieurs institutions). Nous étendons nos efforts pour développer des moyens de fournir à la société de meilleures orientations sur ce à quoi s'attendre des futurs systèmes, et nous espérons que cela deviendra un objectif commun dans le domaine.
11
Évaluation de l'IA ouverte
Nous sommes open-source OpenAI Evals, notre framework logiciel pour créer et exécuter des benchmarks qui évaluent des modèles comme GPT-4, tout en vérifiant leurs performances échantillon par échantillon. Nous utilisons Evals pour guider le développement de nos modèles (y compris l'identification des lacunes et la prévention des régressions), et nos utilisateurs peuvent l'appliquer pour suivre les performances des différentes versions de modèles (qui seront désormais déployées régulièrement) et l'évolution des intégrations de produits. Par exemple, Stripe utilise déjà Evals pour compléter ses évaluations humaines afin de mesurer la précision de ses outils de documentation alimentés par GPT.
Étant donné que le code est open source, Evals prend en charge l'écriture de nouvelles classes pour implémenter une logique d'évaluation personnalisée. Cependant, d'après notre propre expérience, de nombreux benchmarks suivent l'un des quelques "modèles", nous incluons donc également les modèles les plus utiles en interne (y compris un modèle pour "Model Grading Evals" - nous avons trouvé que GPT-4 avait un impressionnant Surpris par le possibilité de vérifier son propre travail). En général, le moyen le plus efficace de créer une nouvelle évaluation consiste à instancier l'un de ces modèles et à fournir les données. Nous sommes ravis de voir ce que d'autres peuvent créer avec ces modèles et évaluations plus largement.
Nous voulons qu'Evals soit un outil de partage et de crowdsourcing de benchmarks qui représentent au mieux un large éventail de modes de défaillance et de tâches difficiles. Comme exemple de suivi, nous avons créé une évaluation de puzzle logique avec dix indices que GPT-4 a échoué. Evals est également compatible avec l'implémentation de benchmarks existants ; nous avons inclus plusieurs cahiers implémentant des benchmarks académiques et quelques variantes intégrant CoQA (un petit sous-ensemble) à titre d'exemples.
Nous invitons tout le monde à tester nos modèles avec Evals et à soumettre vos exemples les plus intéressants. Nous pensons que Evals fera partie intégrante du processus d'utilisation et de développement de nos modèles, et nous accueillons les contributions directes, les questions et les commentaires.
12
ChatGPT Plus
Les utilisateurs de ChatGPT Plus obtiendront des autorisations GPT-4 limitées à l'utilisation sur chat.openai.com. Nous ajusterons le plafond d'utilisation exact en fonction de la demande réelle et des performances du système, mais nous nous attendons à ce que la capacité soit sévèrement limitée (bien que nous l'étendrons et l'optimisions au cours des prochains mois).
En fonction des modèles de trafic que nous observons, nous pouvons introduire un nouveau niveau d'abonnement pour une utilisation GPT-4 plus élevée, et nous espérons également offrir un certain nombre de requêtes GPT-4 gratuites à un moment donné, afin que les utilisateurs qui n'ont pas d'abonnement peut aussi essayer.
API
Pour obtenir l'API GPT-4 (utilisant la même API ChatCompletions que gpt-3.5-turbo), veuillez vous inscrire sur la liste d'attente officielle d'OpenAI.
13
en conclusion
Nous attendons avec impatience que GPT-4 devienne un outil précieux qui améliore la vie des gens en alimentant de nombreuses applications. Il reste encore beaucoup de travail à faire, et nous sommes impatients de développer, d'explorer et de contribuer au modèle grâce aux efforts collectifs de la communauté pour améliorer le modèle ensemble.
Texte / Republié de "Alpha Rabbit Research Notes"
les références:
1.https://openai.com/research/gpt-4
2.https://techcrunch.com/2023/03/14/openai-releases-gpt-4-ai-that-it-claims-is-state-of-the-art/
3.https://www.theverge.com/2023/3/14/23638033/openai-gpt-4-chatgpt-multimodal-deep-learning
Cliquez sur la carte de compte officielle ci-dessous pour me suivre
Dans la boîte de dialogue officielle du compte, répondez le mot-clé "1024"
Obtenez un tutoriel pratique gratuit sur la façon de gagner de l'argent avec des activités secondaires
