Table des matières
2. Plateforme de développement
3.1 Le statu quo du développement d'applications Android à l'étranger
3.2 Le statu quo du développement d'applications Android en Chine
3.3 Analyse de la cible de construction du système
3.4 Analyse de la fonction de construction du système
3.4.1 La structure globale du système
3.4.2 Modules de fonction système
3.4.3 Diagramme de planification des fonctions d'application
4.1 Conception détaillée du sous-système d'affichage des mots d'appui à la réception
4.1.1 Module de fonction de revue
4.1.2 Module de fonction Statistiques
4.1.3 Module fonction Dictionnaire
4.1.4 Réglage des modules de fonction
4.2 Conception détaillée du sous-système de gestion des données de base
5. Conception de la base de données
5.1.1 Tableau récapitulatif du tableau de la base de données
1. À propos de ce sujet
Cette conception est principalement un examen et une application consolidés du développement de la technologie Android, de la base de données et d'autres cours appris à l'université. Selon le livre de mots déterminé par l'utilisateur et la quantité d'apprentissage personnalisée dans les paramètres, cette conception nécessite que le système aide l'utilisateur à organiser la révision des mots chaque jour de manière planifiée ; l'utilisateur peut librement choisir de remplacer le livre de mots et de réinitialiser les enregistrements d'apprentissage ; il peut être fourni via l'API des principales plates-formes de traduction pour trouver des mots et des exemples de phrases, vous pouvez comprendre vos propres enregistrements d'apprentissage et votre mémoire, et vous pouvez personnaliser le thème du système ;
2. Plateforme de développement
La plateforme de développement de ce sujet est :
-
Système d'exploitation : Microsoft Windows 10
-
Langages de programmation : Java, XML
-
Outil IDE : AndroidStudio 4.1.1
-
Plugin IDE : Navigateur de base de données
-
Serveur de base de données : SQLite
-
Autres outils : smartphones ou émulateurs avec Android 7.0 ou supérieur
3. Analyse du système
Ce chapitre effectue principalement une analyse plus détaillée des exigences, une analyse des cibles et une analyse des fonctions sur la construction du système.
3.1 Le statu quo du développement d'applications Android à l'étranger
Selon l'enquête, le nombre d'internautes aux États-Unis en 2019 a atteint pas moins de 290 millions, le taux d'utilisation d'Internet a atteint 89,4 % et l'utilisation quotidienne moyenne des téléphones mobiles dépasse trois heures. Parmi les applications gratuites, les types les plus populaires sont les réseaux sociaux, les jeux, la bureautique et la vidéo en ligne ; parmi les applications payantes, les types les plus populaires sont les outils et les jeux en ligne. Sur la plate-forme Android, GooglePlay propose un grand nombre d'applications ; son nombre et ses téléchargements sont bien supérieurs à ceux de n'importe quel magasin d'applications national, ce qui montre que la vague d'utilisation d'applications mobiles à l'étranger est déjà arrivée, stimulant les besoins de développement de davantage d'applications mobiles. [17] Contrairement à la plupart des développeurs nationaux qui utilisent encore Java comme langage de développement dans le choix du langage de développement d'applications, la plupart des développeurs étrangers choisissent généralement Kotlin comme langage de développement. [18]
3.2 Le statu quo du développement d'applications Android en Chine
Le développement domestique d'Android est encore principalement basé sur le développement d'applications, qui est principalement divisé en trois catégories : le développement d'applications pour les entreprises, le développement de jeux et le développement d'applications générales.
- Les entreprises développent des applications, généralement demandées par les grandes entreprises, qui conçoivent principalement des solutions globales pour téléphones portables ou tablettes pour leurs propres marques ou d'autres marques.
- Il existe deux principales méthodes de profit pour développer des applications à usage général : externaliser le développement pour des entreprises étrangères, obtenir des parts de publicité grâce à des publicités intégrées et réaliser des bénéfices grâce à des achats payants[19].
- Le développement de jeux est actuellement similaire au deuxième type de développeur. De telles applications peuvent non seulement faire en sorte que les utilisateurs se sentent frais à propos de l'application, mais aussi faciliter le gain d'argent grâce à des achats payants en utilisant correctement les diverses psychologies de la plupart des utilisateurs.
3.3 Analyse de la cible de construction du système
Le développement de l'application de mémorisation de mots nécessite que les utilisateurs puissent exploiter les données de l'utilisateur à tout moment et ajuster automatiquement la fréquence des tâches quotidiennes et des mots qui apparaissent dans chaque mot, afin de répondre aux besoins des utilisateurs de réciter des mots efficacement ; Le calcul de La fréquence des mots est particulièrement importante.L'objectif de ce système est de maximiser l'efficacité de la récitation des mots par l'utilisateur en organisant la révision en fonction de la combinaison de la courbe d'oubli d'Ebbinghaus et de la familiarité de l'utilisateur [20]. En outre, l'application doit également fournir des statistiques intuitives sur la familiarité de l'utilisateur et des cartes d'état d'achèvement en temps réel :
- Réaliser la fréquence des mots de calcul de familiarité
La familiarité de chaque mot doit être sélectionnée par l'utilisateur lors de la révision du mot ; la familiarité comprend quatre options : mémorisation, compréhension, flou et oubli. Chaque familiarité sera jugée par le système et la révision sera organisée à nouveau sous la condition d'assurer la tâche d'aujourd'hui. Pour s'assurer que la mémoire de récitation de l'utilisateur le jour peut être plus consolidée et fiable.
- Réaliser la courbe d'oubli d'Ebbinghaus pour calculer la fréquence des mots
Cette application utilise pleinement la courbe d'oubli d'Ebbinghaus pour permettre aux utilisateurs de faire un examen raisonnable des tâches non quotidiennes ; la méthode de calcul de la courbe d'oubli d'Ebbinghaus ne dépend que de l'horodatage du système ; elle est conçue pour être examinée par l'utilisateur en raison de l'oubli d'Ebbinghaus courbe Le mot rafraîchira le taux d'oubli du mot (cela n'a rien à voir avec la familiarité de l'utilisateur); assurant ainsi que la mémoire de récitation de l'utilisateur des mots appris dans le passé est plus consolidée et fiable.
- Réaliser des statistiques d'apprentissage
Grâce aux statistiques de la base de données et à l'aide de l'API pour afficher visuellement l'utilisateur sous la forme d'un graphique. Les graphiques statistiques comprennent des graphiques de progression de l'apprentissage du vocabulaire actuel, des graphiques de courbe d'oubli d'Ebbinghaus et des graphiques d'état d'apprentissage ; parmi eux, les graphiques d'état d'apprentissage fournissent aux utilisateurs une connaissance claire de l'utilisateur, des plans restants et des collections de mots.
- Mettre en œuvre la manipulation des données utilisateur
Grâce aux paramètres de l'interface utilisateur, l'utilisateur peut personnaliser la quantité de tâches quotidiennes, l'utilisateur peut apprendre la gestion des tâches et les thèmes du système, etc., et améliorer encore l'expérience utilisateur et l'efficacité de l'apprentissage.
3.4 Analyse de la fonction de construction du système
3.4.1 La structure globale du système
Le système se compose de deux sous-systèmes : le sous-système d'affichage et de mémorisation de mots d'avant-plan et le sous-système de gestion de données d'arrière-plan. Dans le même temps, il comprend principalement deux types d'analyse de données JSON et un processus d'analyse de données XML : livre de vocabulaire de l'API de mot arrière fantôme et analyse des données de vocabulaire, analyse des données de l'API du dictionnaire iciba. Parmi eux, l'analyse des données de l'API de mot de mémorisation fantôme est la partie clé, et c'est la source de données de tout le vocabulaire associé.
3.4.2 Modules de fonction système
La réception affiche le sous-système de mémorisation des mots

Une brève description du sous-système de retour de mots affiché à la réception
- Module de révision : la fonction principale de l'application pour réciter des mots, organiser les utilisateurs pour réciter les mots correspondants, mettre à jour les informations de l'utilisateur et la base de données d'informations de vocabulaire ;
- Module statistique : affiche un graphique statistique en forme d'éventail des progrès d'apprentissage de l'utilisateur, un histogramme de l'état d'apprentissage de l'utilisateur et un graphique statistique linéaire des données oubliées d'Ebbinghaus ;
- Module de vocabulaire : modifier le vocabulaire anglais actuel, afficher le vocabulaire préféré et rechercher des mots ;
- Module de réglage : définissez le thème de l'application pour réciter des mots, la tâche quotidienne de réciter des mots et d'exploiter les données de l'utilisateur ;
- Module de barre de navigation : aidez les utilisateurs à basculer rapidement vers les modules fonctionnels correspondants et affichez le style de changement de module ;
Sous-système de gestion des données d'arrière-plan

Brève description du sous-système de gestion des données d'arrière-plan
- Initialisation des données utilisateur : initialise la base de données d'informations sur l'utilisateur actuel, y compris l'ID utilisateur, l'ID du dictionnaire utilisé par l'utilisateur, le volume des tâches utilisateur, la progression de la tâche de l'utilisateur aujourd'hui, l'horodatage et d'autres informations ;
- Initialisation des données de glossaire : initialise toutes les bases de données d'informations de vocabulaire, y compris les informations de demande de données de vocabulaire, l'ID de vocabulaire, la quantité de vocabulaire, s'il existe des données de vocabulaire, etc. ;
- Initialisation des données de vocabulaire : initialise toutes les bases de données d'informations de vocabulaire, y compris l'ID de vocabulaire, les informations de demande de données de vocabulaire, l'ID du livre de vocabulaire, les symboles phonétiques de vocabulaire, l'adresse de prononciation du vocabulaire, le nom du vocabulaire, la définition du vocabulaire, si le vocabulaire est enregistré, l'horodatage du vocabulaire, le niveau de mémoire du vocabulaire, vocabulaire Familiarité et vocabulaire phrases d'exemple et autres informations;
- Initialisation de la phrase d'exemple de vocabulaire : utilisez l'API iciba pour interroger la phrase d'exemple de mot du vocabulaire correspondant et mettre à jour la base de données d'informations sur le vocabulaire ;
3.4.3 Diagramme de planification des fonctions d'application
La planification fonctionnelle principale du système est illustrée à la figure 3-3. Ce qui est montré ici n'est qu'un lien général du processus principal du système. La description détaillée sera impliquée dans la conception détaillée des modules fonctionnels plus tard.

4. Conception du système
4.1 Conception détaillée du sous-système d'affichage des mots d'appui à la réception
4.1.1 Module de fonction de revue
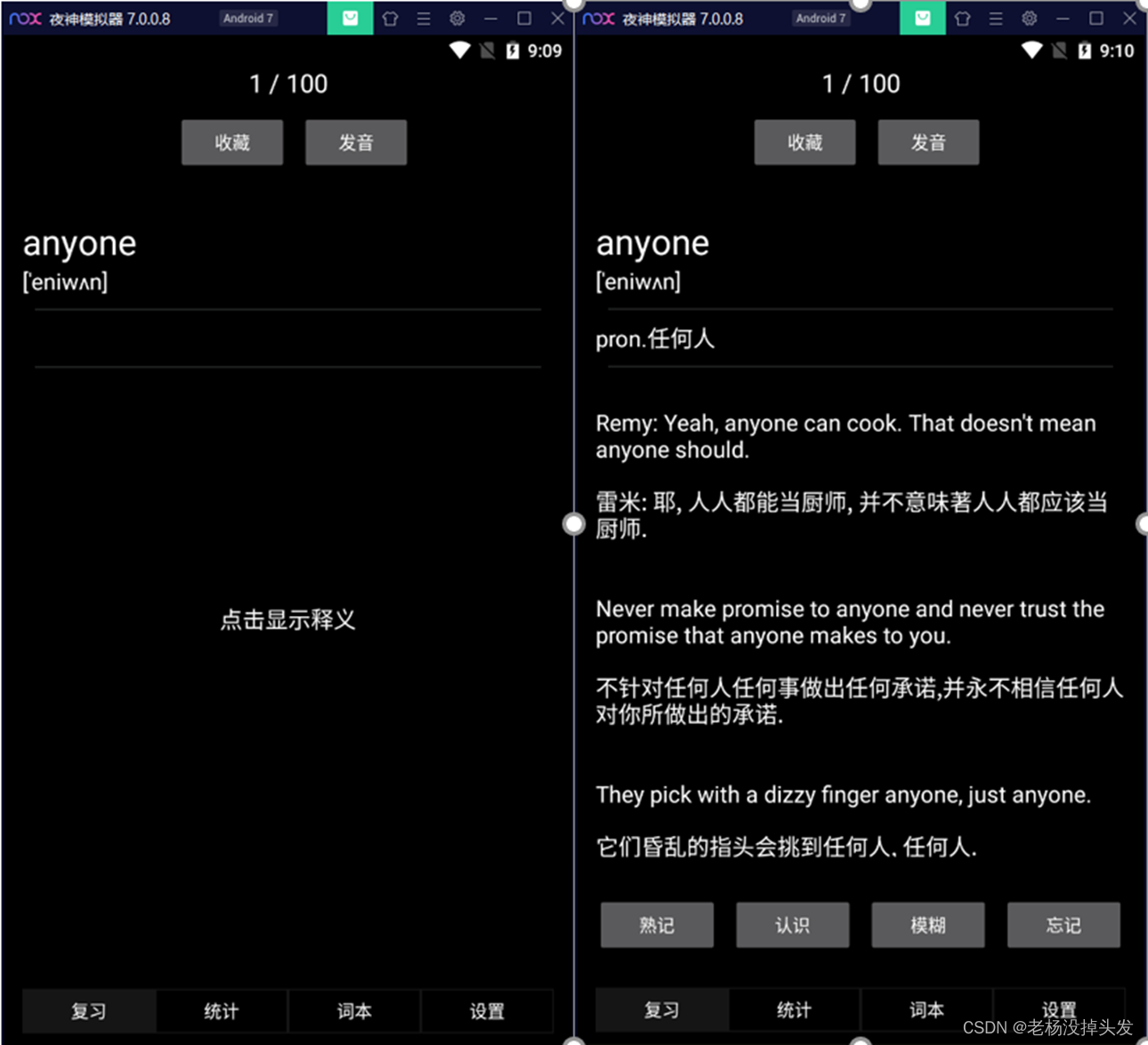
Le module de fonction de révision est le premier fragment montré à l'utilisateur. Son principe de fonctionnement et son interface utilisateur sont les parties les plus critiques de l'application de mémorisation de mots, qui jouent un rôle très important dans la motivation des utilisateurs à continuer à utiliser l'application. Par conséquent, la conception du module de fonction de révision doit prêter attention à l'expérience utilisateur et à la conception artistique, et en même temps, il doit être facile à utiliser et complet en informations. Dans le module de fonction de révision, le corps principal du fragment est divisé en trois cadres de haut en bas. Le premier cadre affiche la progression de l'utilisateur et les informations sur la tâche de mot pour la journée ; le second cadre est le cadre d'opération de l'utilisateur pour le mot actuel ( par exemple la collecte de mots, la prononciation des mots et la sélection de la familiarité, etc.); le troisième cadre est la définition des mots, les symboles phonétiques, les exemples de phrases et d'autres informations.
Pour la commodité de la description, nous commençons par l'introduction du deuxième cadre et du troisième cadre.
Pour l'utilisateur, si aucune opération n'est effectuée, les parties visibles du deuxième cadre et du troisième cadre ne comportent que des mots, des symboles phonétiques de mots, des prononciations de mots et des collections de mots. La partie du discours, la définition et les phrases d'exemple du mot et la partie de sélection de familiarité du mot sont complètement masquées. Ce projet définira l'événement de clic sur la phrase d'exemple de mot et la partie de mot du contrôle de la parole et cliquera sur le texte en y invitant. Une fois que l'utilisateur a effectué l'opération correspondante, la sélection de familiarité de l'utilisateur de la deuxième image et de la troisième image, le mot de la parole et l'exemple de phrase du mot seront affichés. Parmi eux, il existe quatre options pour la familiarité de l'utilisateur, qui sont la mémorisation, la compréhension, le flou et l'oubli. Les fonctions d'opération de mot et de sélection de familiarité sont les suivantes :
- Mémorisation : la table de données de vocabulaire de l'utilisateur enregistre l'indicateur de mémorisation pour le mot actuel, et il y a une possibilité de 0 % que le mot soit programmé pour une nouvelle révision, quelle que soit la charge de la tâche d'aujourd'hui.
- Reconnaissance : la table de données de vocabulaire de l'utilisateur enregistre l'indicateur de reconnaissance du mot actuel, et il y a une possibilité de 20 % que le mot soit à nouveau programmé pour une révision, quelle que soit la charge de la tâche d'aujourd'hui.
- Fuzzy : la table de données de vocabulaire utilisateur enregistre l'indicateur flou du mot actuel, et il y a une possibilité de 40 % que le mot soit à nouveau programmé pour une révision sans compter la charge de tâche d'aujourd'hui.
- Oublier : la table de données de vocabulaire de l'utilisateur enregistre l'indicateur d'oubli pour le mot actuel, et il y a 60 % de chances que le mot soit à nouveau programmé pour révision, quelle que soit la charge de la tâche d'aujourd'hui.
- Collection de mots : la table de données de vocabulaire de l'utilisateur enregistre le drapeau du mot actuel comme favori ou non préféré, et vous pouvez vérifier à nouveau les opérations préférées et non préférées dans "Mes favoris" dans le module de fonction de livre de mots.
- Prononciation des mots : jouez la prononciation de personnes réelles en fonction de l'adresse dans le tableau de données de vocabulaire ;
Lors de l'initialisation des données, l'application préparera wordList et hitList. Parmi eux, la wordList contient tous les mots que l'utilisateur doit compléter aujourd'hui, et la hitList contient tous les mots clés (ici, tous les mots qui doivent être revus en raison de la familiarité deviennent les mots clés, comme ci-dessous) . Les utilisateurs doivent choisir l'un de ces quatre niveaux de familiarité pour passer en revue le mot suivant. Lors de la préparation de l'organisation de la prochaine révision du mot, il y aura une probabilité de 50 % que le mot provienne de la liste de résultats ;
Les données de la progression d'aujourd'hui et des tâches quotidiennes dans le premier cadre proviennent toutes de la table de données utilisateur. Lorsque l'utilisateur effectue une sélection de familiarité et que le mot suivant provient de la liste de mots, la progression d'aujourd'hui est incrémentée de un. La valeur maximale de la progression d'aujourd'hui n'est pas supérieure au nombre de tâches quotidiennes, sinon le message indiquant que la tâche est terminée s'affichera. Lorsque l'utilisateur n'a pas terminé la tâche d'hier, la progression d'aujourd'hui sera réinitialisée à 1, mais lors de l'organisation de la révision, le calcul commencera toujours à partir du mot qui n'a pas été sélectionné pour la familiarité hier. Lorsque l'utilisateur réinitialise le montant de la tâche dans le module de fonction de réglage, il est divisé dans les situations suivantes :
- La quantité de tâches quotidiennes définie par l'utilisateur est supérieure à la quantité de tâches quotidiennes d'origine : le module de fonction de révision ajoutera un nouveau vocabulaire étendu à la liste de mots et mettra à jour la valeur de la quantité de tâches quotidiennes en fonction de la valeur nouvellement définie ;
- La quantité de tâches quotidiennes nouvellement définie par l'utilisateur est inférieure à la quantité de tâches quotidiennes d'origine : le module de fonction de révision supprimera les mots redondants dans la liste de mots de l'arrière vers l'avant dans l'ordre et mettra à jour la valeur de la quantité de tâches quotidiennes en fonction de la nouvelle valeur définie. Si la nouvelle valeur est inférieure à la progression d'aujourd'hui, réinitialisez la progression d'aujourd'hui au montant maximal de la tâche quotidienne et indiquez que la tâche d'aujourd'hui est terminée. Mais demain commencera toujours à compter à partir du mot qui n'a pas été sélectionné pour la familiarité.
Revoir la démo du module de fonction (thème jour et thème nuit)

4.1.2 Module de fonction Statistiques
Le module de fonction statistique est un fragment conçu pour refléter intuitivement la situation d'apprentissage de l'utilisateur, et ses données statistiques proviennent toutes de la base de données et sont mises à jour en temps réel. Par conséquent, à l'exception de certains événements de réponse au clic (tels que les graphiques statistiques en forme d'éventail qui peuvent pivoter sur place avec les gestes de l'utilisateur), les utilisateurs ne peuvent pas éditer ou modifier directement les graphiques statistiques. Il utilise le cadre de dessin graphique HelloChart, qui peut dessiner divers beaux graphiques statistiques. Grâce à HelloChart, ce module comprend un diagramme en éventail de la progression de l'apprentissage de l'utilisateur, un diagramme en courbes d'oubli d'Ebbinghaus et un diagramme à colonnes du statut d'apprentissage de l'utilisateur :
- Tableau statistique en forme d'éventail des progrès d'apprentissage : statistiques réalisées pour le vocabulaire actuel, y compris le vocabulaire prévu restant, le vocabulaire inachevé aujourd'hui, le vocabulaire terminé, de brèves informations sur le vocabulaire actuel et les progrès d'apprentissage ;
- Graphique linéaire des données d'oubli d'Ebbinghaus : le psychologue allemand Ebbinghaus a réalisé une étude systématique sur le phénomène de l'oubli. Il a utilisé des syllabes sans signification comme matériel de mémoire et a dessiné les données expérimentales dans une courbe, appelée courbe d'oubli d'Ebbinghaus. L'ordonnée de la courbe représente la quantité de rétention de la mémoire, ce qui montre une loi de développement de l'oubli : le processus d'oubli est déséquilibré. Au début de la mémorisation, l'oubli est très rapide, puis il ralentit progressivement. Après un certain temps de temps, il n'est presque plus oublié, c'est-à-dire que le développement de l'oubli est "rapide d'abord, puis lent". Chaque mot de ce projet a une valeur de mémoire correspondante et un horodatage lors de la révision, qui est utilisé pour représenter l'ordonnée de la courbe d'oubli d'Ebbinghaus. Il convient de noter que la valeur de l'ordonnée n'est liée qu'à son horodatage correspondant.
- Histogramme de l'état d'apprentissage : des statistiques sont faites pour tous les mots que l'utilisateur a appris. L'axe vertical est le nombre de mots et l'axe horizontal comprend les statistiques de familiarité de l'utilisateur, les mots favoris et le volume inachevé restant d'aujourd'hui.
Longue capture d'écran de la démonstration du module de fonction statistique (thème jour et thème nuit)

4.1.3 Module fonction Dictionnaire
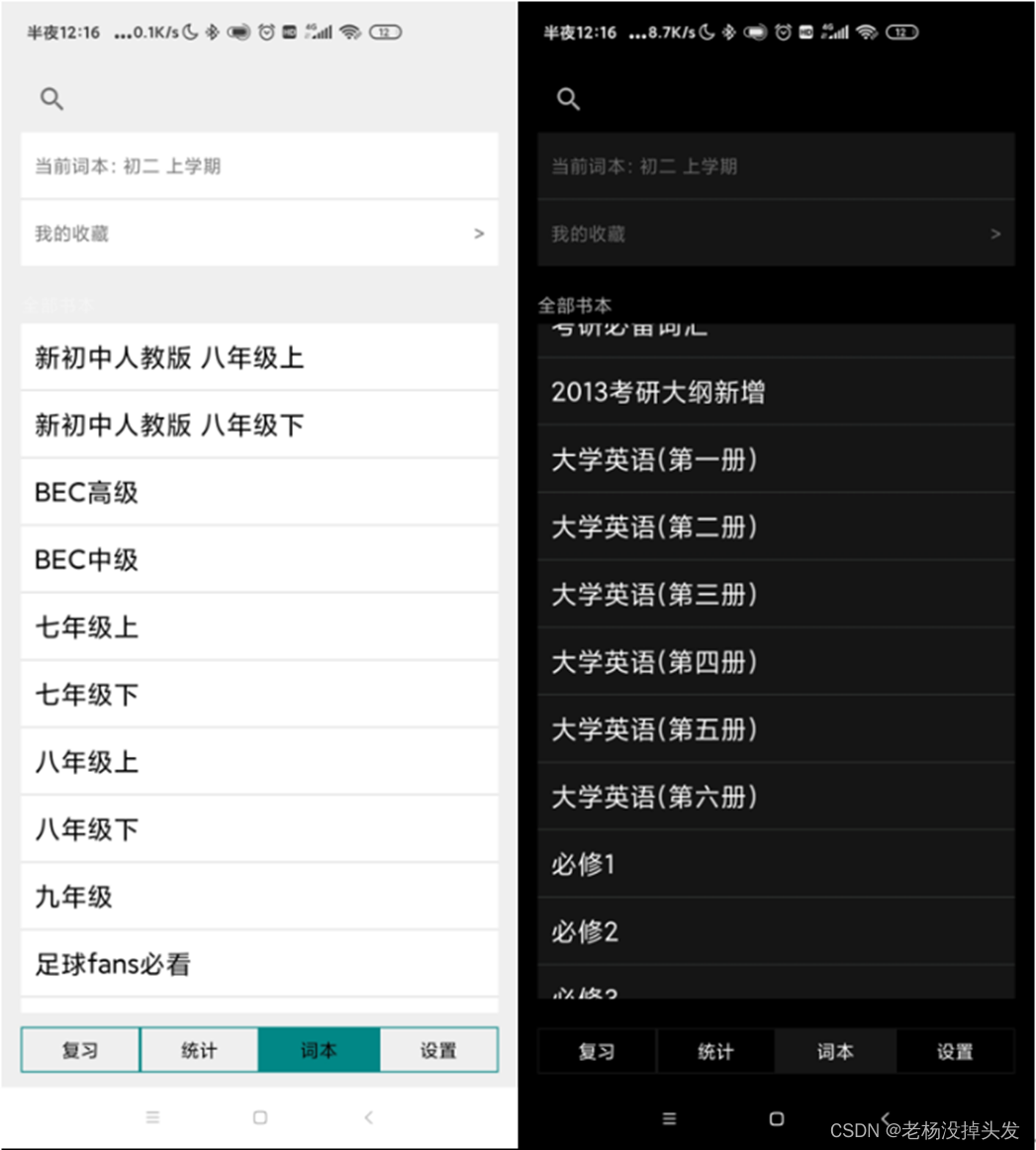
Le module de fonction de livre de mots est également l'un des modules de base de l'application de récitation de mots. Sa fonction principale est d'aider les utilisateurs à remplacer le livre de mots actuel. Après avoir effectué cette opération, revenez au module de fonction de révision et vous constaterez que les progrès d'aujourd'hui seront être réinitialisé, mais les tâches quotidiennes de l'utilisateur restent inchangées, et les données statistiques en forme d'éventail de la progression de l'apprentissage du vocabulaire actuellement appris dans le module de fonction statistique changent également. De plus, la fonction de livre de mots a également une option "Mes favoris" pour afficher tous les mots préférés et les utilisateurs peuvent annuler un mot à volonté. Il y a aussi une boîte de recherche pour interroger les mots liés dans la base de données et les requêtes du réseau. Ici, seuls les plus des mots de commutation importants sont introduits. Toutes les données du livre de mots sont préchargées et directement synchronisées avec la base de données et l'interface de l'application via AsyncTask, mais chaque livre de mots peut ne pas contenir de données de mots, car si toutes les données sont préchargées, des erreurs fréquentes d'accès à l'API se produiront. La solution finale est que l'utilisateur doit sélectionner un vocabulaire, puis AsyncTask synchronisera les données de vocabulaire dans le vocabulaire correspondant avec la base de données et examinera le fragment de module de fonction. Lorsque l'utilisateur utilise cette application pour la première fois, toutes les commandes du module de fonction de révision seront indisponibles et une invite de sélection de mots sera donnée, comme indiqué sur la figure ;

Il est également très simple de réaliser l'opération de sélection d'un vocabulaire par l'utilisateur. Toutes les colonnes du livre peuvent être glissées et il y a des événements de clic ; par conséquent, l'utilisateur n'a qu'à cliquer directement sur le nom du vocabulaire répertorié. À ce stade, l'interface du module de fonction affichera une invite indiquant le succès de la commutation. Bien entendu, les données correspondantes telles que mentionnées ci-dessus seront également automatiquement ajoutées et mises à jour dans la base de données et les principaux modules fonctionnels. L'interface du module de fonction de dictionnaire est illustrée dans la figure :
Sélection de Wordbook (thème de jour et thème de nuit)
4.1.4 Réglage des modules de fonction
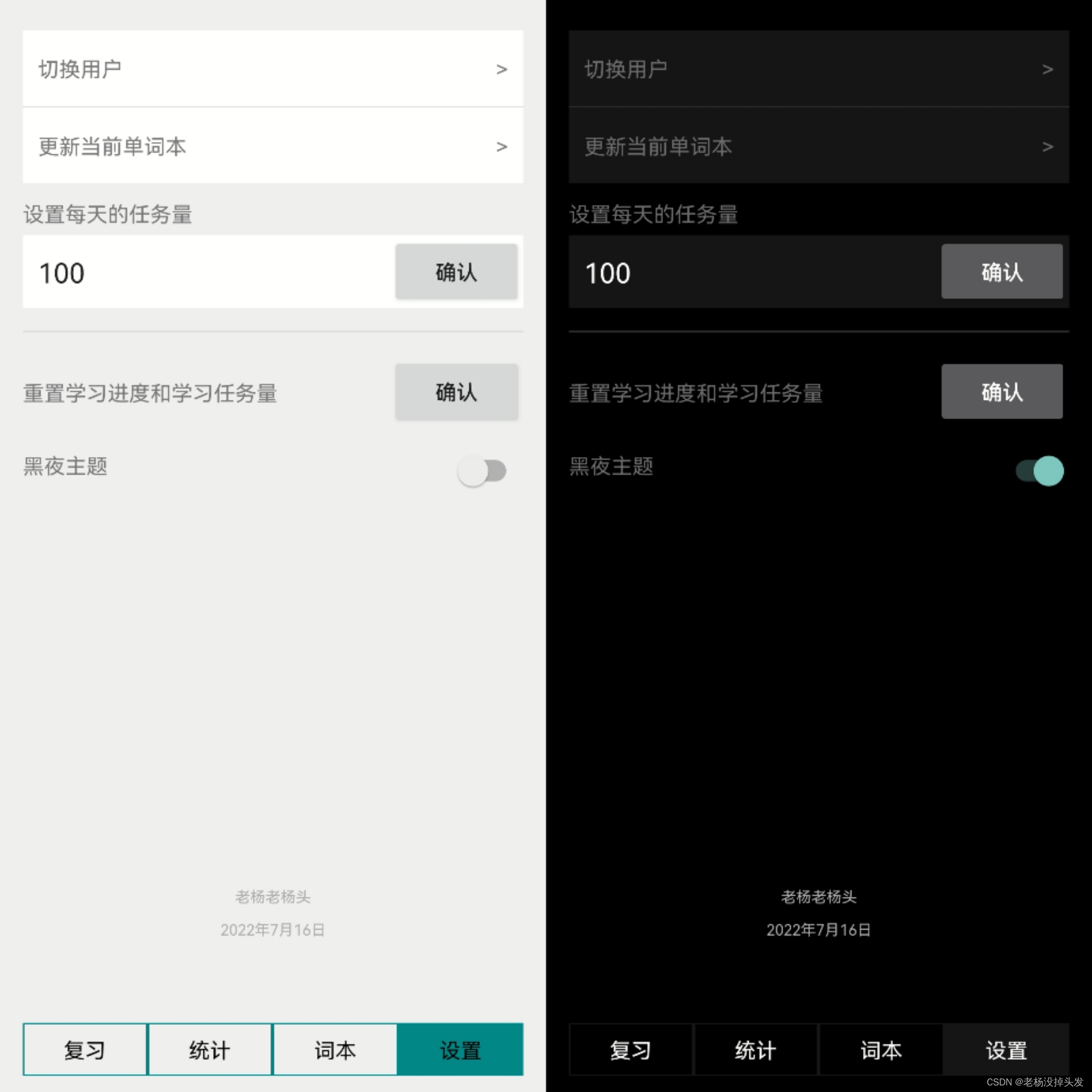
Les fonctions du module de fonction de réglage comprennent principalement le réglage des tâches quotidiennes de l'utilisateur, la réinitialisation des données de l'utilisateur et le changement de thème d'application, en plus des fonctions de changement d'utilisateur et de mise à jour du vocabulaire actuel ; leurs fonctions sont :
- Réglage de la tâche quotidienne de l'utilisateur : le réglage de la tâche de l'utilisateur est défini par l'utilisateur et constitue une base importante pour le fonctionnement du tableau de données de vocabulaire de l'utilisateur dans le module de fonction de révision ; sa fonction a été expliquée dans le module de fonction de révision, de sorte qu'elle ne sera pas répétée ici.
- Réinitialisation des données utilisateur : cette opération réinitialisera toutes les données de la table de données utilisateur et de la table de données de vocabulaire utilisateur. Après la réinitialisation, l'utilisateur n'aura plus d'enregistrements d'apprentissage comme un nouvel utilisateur, mais le contenu de la base de données correspondante n'a pas besoin à télécharger et à télécharger à nouveau. Les modifications de données pertinentes seront également synchronisées avec le module de données statistiques en temps réel, de sorte que la vérification du contenu du module de fonction statistique est également la base pour juger si les données utilisateur ont été réinitialisées.
- Changement de thème d'application : il existe deux thèmes, nuit et jour, disponibles. L'introduction du thème nuit répond à la tendance de développement du développement Android et aux besoins croissants des utilisateurs. La commutation de thème d'application est également un champ dans la table de données utilisateur, qui peut basculer automatiquement vers le thème correspondant en fonction des différents besoins de l'utilisateur.
- Changement d'utilisateur : étant donné que toutes les sources de données lexicales proviennent de l'API de données fantômes, l'ID utilisateur et la clé utilisateur fournis par l'API sont déjà très uniques et privés. Par conséquent, le compte utilisateur et le mot de passe sont directement configurés en tant qu'ID utilisateur et clé fournis par l'API. Comme mentionné dans la fonction du module de vocabulaire, vous pouvez utiliser le préchargement des données de vocabulaire. Lorsque vous l'utilisez pour la première fois, vous pouvez juger s'il y a un statut de connexion avant que l'activité principale n'utilise le fragment de chargement. S'il y a un statut de connexion, chargez directement divers fragments ; si ce n'est pas le cas, jugez si la connexion est réussie ou non en fonction des données renvoyées. S'il réussit, il sera enregistré dans la table de données de l'utilisateur et le fragment sera chargé ; sinon, la connexion sera refusée, et le fragment ne sera pas chargé, et il ne restera que sur la page de connexion de l'activité principale (Figure 4-7). Par conséquent, la fonction d'enregistrement de l'utilisateur n'est plus fournie.
- Mise à jour du vocabulaire actuel : cette opération supprime la table de données de vocabulaire utilisateur correspondant au vocabulaire utilisateur actuel, puis réapplique les données de l'API et réinitialise la table de données de vocabulaire utilisateur.
Définissez le schéma du module de fonction comme indiqué sur la figure (thème jour et thème nuit) :
Interface de connexion utilisateur :

Interface de code, pro-test correct 
4.2 Conception détaillée du sous-système de gestion des données de base
Réalisation de la courbe d'oubli d'Ebbinghaus
Il existe une formule recommandée pour la courbe d'oubli d'Ebbinghaus. Mais afin de rendre le système plus efficace, la courbe d'oubli d'Ebbinghaus est utilisée par la méthode de prise de points. Lors de la mise à jour de l'horodatage dans le sous-système de gestion des données d'arrière-plan, l'horodatage actuel sera comparé à l'horodatage d'origine. Si la différence atteint la valeur indiquée dans le tableau ci-dessous, il sera mis à jour avec l'horodatage actuel et la valeur de mémoire correspondante sera mise à jour. Le tableau 4-1 montre la méthode de traitement de la mise à jour des différences d'horodatage :
Tableau 4-1 Méthodes de traitement pour la mise à jour de la différence d'horodatage
| différence | juste | 15 min | 20 min | 1h | 8h | Un jour | 2 jours | 6 jours | 30 jours |
|---|---|---|---|---|---|---|---|---|---|
| valeur de la mémoire | 100 | 58 | 44 | 36 | 34 | 28 | 25 | vingt-et-un | 15 |
Dans le module de fonction de révision, sélectionnez d'abord les mots contenus dans le livre en cours, la valeur de mémoire est inférieure à 40 et supérieure à 0 (c'est-à-dire que les mots ont été appris et la valeur d'oubli est supérieure à 60), et la valeur d'oubli est passé à la fonction hit. Si le mot est touché, il sera mis dans la liste de mots ; de cette façon, le processus de révision de tous les mots appris dans le livre de vocabulaire actuel est réalisé en utilisant la courbe d'oubli d'Ebbinghaus.
5. Conception de la base de données


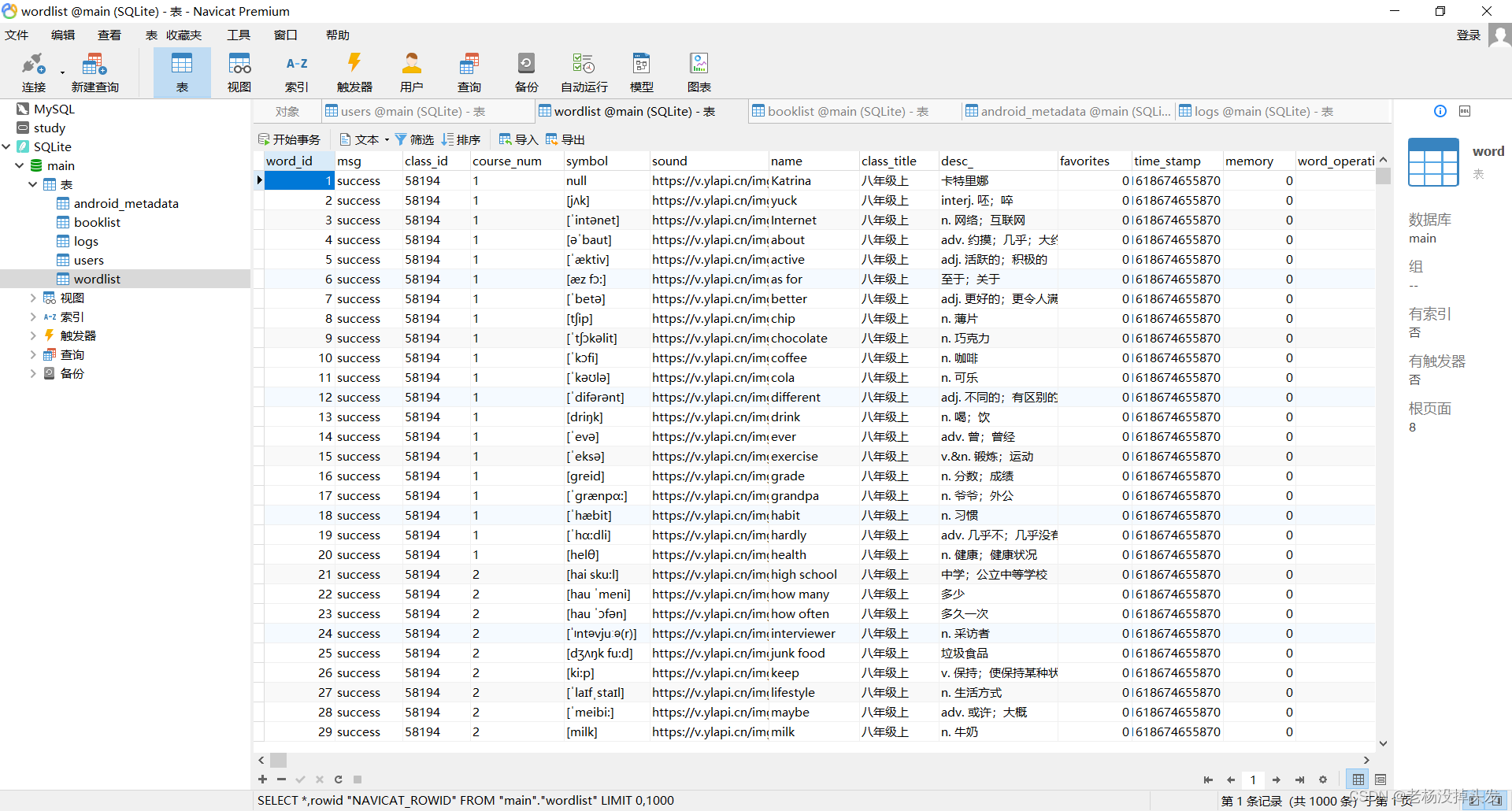
5.1 Résumé du tableau
5.1.1 Tableau récapitulatif du tableau de la base de données
| Nom de la table | Description de la fonction |
|---|---|
| journaux | Table du journal de connexion, enregistrement de réussite de la connexion de l'utilisateur |
| utilisateurs | Tableau d'informations sur l'utilisateur, enregistrer des informations spécifiques sur l'utilisateur |
| liste de mots | Table de données de vocabulaire utilisateur, qui enregistre les informations d'utilisation du vocabulaire utilisateur et les informations de vocabulaire |
| liste de livres | Table de données de vocabulaire utilisateur, qui enregistre les informations d'utilisation du vocabulaire utilisateur et les informations de vocabulaire |
5.2 Afficher les détails
table du journal de connexion
| Nom de la table | journaux | journaux |
|---|---|---|
| champ | type de données | illustrer |
| ID de l'utilisateur | entier | non vide |
| utilisateur | texte | non vide |
| clé d'application | texte | non vide |
| date_num | entier | date |
Formulaire d'informations utilisateur
| Nom de la table | utilisateurs | utilisateurs |
|---|---|---|
| champ | type de données | illustrer |
| ID de l'utilisateur | entier | PAQUET |
| utilisateur | texte | non vide |
| clé d'application | texte | non vide |
| identifiant de classe | texte | identifiant du livre |
| mot_position | entier | par défaut 100 |
| aujourd'hui_progrès | entier | par défaut 1 |
| date_num | entier | date |
| theme_night | entier | 1—thème sombre ; 0—thème jour ; 0 par défaut |
utilisateur
| Nom de la table | liste de livres | liste de livres |
|---|---|---|
| champ | type de données | illustrer |
| msg | texte | échec par défaut |
| titre | texte | titre de livre |
| identifiant de classe | texte | identifiant du livre |
| mot_num | entier | par défaut 0 |
| cours_num | entier | par défaut 0 |
| existence_item | entier | 1—les données lexicales existent ; 0—les données lexicales n'existent pas ; par défaut 0 |
Tableau de données de vocabulaire utilisateur
| Nom de la table | liste de mots | liste de mots |
|---|---|---|
| champ | type de données | illustrer |
| word_id | entier | PK, auto-incrémentation |
| msg | entier | échec par défaut |
| identifiant de classe | entier | identifiant du livre |
| cours_num | entier | par défaut 0 |
| symbole | texte | symboles phonetiques |
| son | texte | adresse de prononciation |
| nom | texte | vocabulaire anglais |
| discrimination | texte | paraphrase |
| favoris | entier | 1—mot favori ; 0—mot non préféré ;;par défaut 0 |
| horodatage | entier | Horodatage ; par défaut 1618674655870 |
| mémoire | entier | Valeur de mémoire, par défaut 0 |
| word_operation | entier | 3—mémoire ; 2—connaissance ; 1—flou ; 0—oubli ;;par défaut 0 |
| exemple_phrase | texte | Exemples de phrases |