Auteur : JD Retail Liu Huiqing
Introduction
La haute disponibilité des logiciels est un sujet courant. La "haute disponibilité" (High Availability) décrit généralement un système qui a été spécialement conçu pour réduire les temps d'arrêt tout en maintenant une haute disponibilité de ses services. La formule de calcul est la suivante : taux de disponibilité = ( temps total - temps d'indisponibilité ) / temps total.
Cet article se concentre sur la perspective de la pratique de mise en œuvre en tant que point d'entrée et amène tout le monde à montrer les étapes de mise en œuvre et les détails de mise en œuvre de la haute disponibilité du point de vue de l'efficacité de la collaboration, de la mise en œuvre de la technologie et des spécifications de fonctionnement. Afin de faciliter la compréhension, unifions d'abord le langage et le vocabulaire, et examinons les différentes étapes du processus de livraison du logiciel, comme le montre la figure suivante :
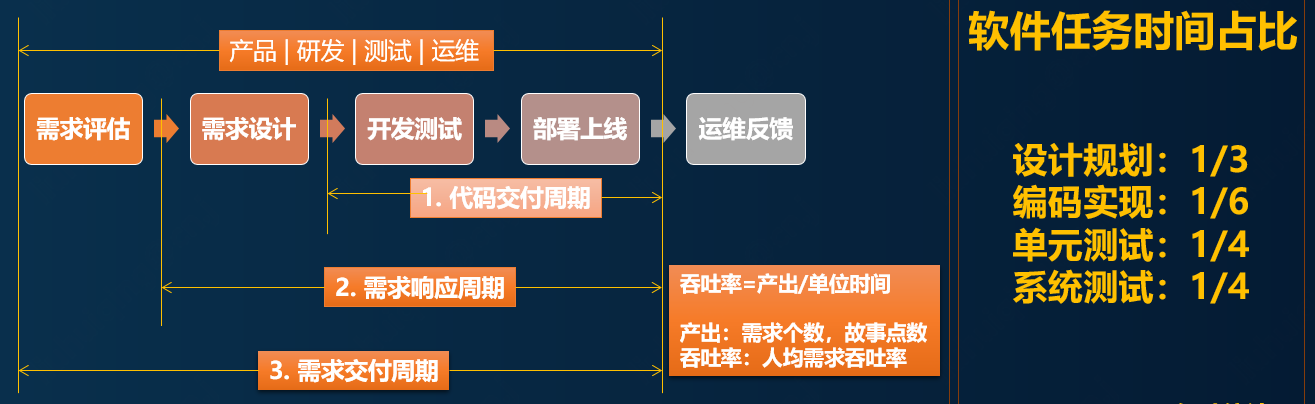
Pourquoi dites-vous que la haute disponibilité des logiciels est confrontée à de nombreux défis ?
En résumé, les problèmes spécifiques auxquels nous sommes confrontés sont les suivants :
2. Garantie d'efficacité de la collaboration
Incompréhension cognitive
À partir de l'ensemble du lien de livraison de la demande, nous pouvons constater qu'à mesure que le lien augmente pas à pas, plus il y aura de branches du lien de transmission d'informations et plus le niveau de transmission sera profond. Cela pose deux problèmes :
Le résultat final de ces deux problèmes est la réduction de l'efficacité de la collaboration.
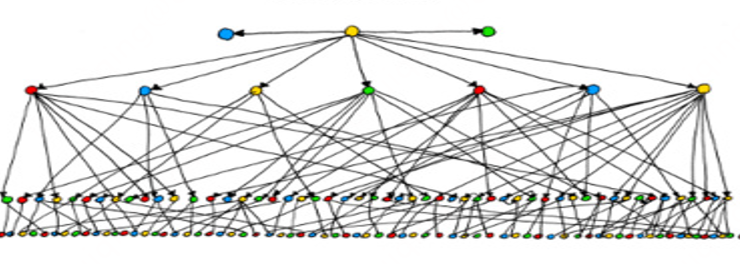
Un étudiant sans expérience pratique pensera souvent que l'augmentation du nombre de personnes améliorera l'efficacité de la livraison de la demande. En fait, cette idée n'est pas tout à fait correcte. Pour la relation spécifique, reportez-vous à la figure suivante :
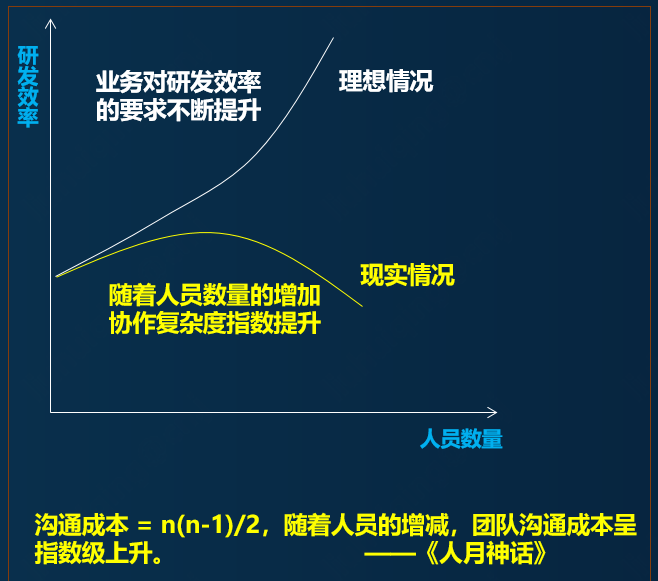
C'est comme construire un bâtiment : si une personne le construit étape par étape, cela prendra 100 jours. Si 100 personnes sont invitées à aider, la maison peut-elle être construite en 1 jour ? la réponse est négative.
Il y a des coûts de collaboration, tels que : la compréhension de l'équipe (concepteurs, maçons, maçons, plombiers), l'appariement des emplois, le contrôle des risques ;
Il existe des dépendances de processus, par exemple : la construction dépend de la conception, et la décoration douce vient toujours après la décoration dure ;
Il existe des budgets de coûts, tels que : le gradient des talents et l'échelle de l'ensemble de l'organisation (sous-traitants, agents, sous-traitants) ;
Tous les problèmes ci-dessus ne sont pas simplement résolus en mettant de la main-d'œuvre.
Spécification du processus
La logique sous-jacente de l'amélioration de l'efficacité de la collaboration est de réduire le niveau de lien de livraison et de raccourcir le lien de transmission de l'information, garantissant ainsi l'exactitude et l'efficacité de la transmission de l'information. (Le contenu du niveau de construction organisationnelle ne sera pas développé ici)
Cela nécessite la capacité de faire le travail d'aujourd'hui et de terminer le travail d'aujourd'hui. Au niveau organisationnel, cela s'appelle la spécification des processus, et au niveau personnel, cela s'appelle les méthodes de travail et le sens des responsabilités.
Essayez d'éviter de reporter l'affaire en cours au lien suivant, sinon cela affectera l'efficacité de la planification et de la livraison des liens suivants, et même des retouches peuvent se produire dans des cas extrêmes. Bref, réfléchissez bien et n'enterrez pas le trou. Les exigences du produit sont pour la R&D, la conception R&D est pour les tests et les cas de test sont pour chaque nœud de livraison tel que les produits. Les livrables doivent être fiables.
Garantie d'atterrissage de trois technologies
Dans le cycle de réponse à la demande, la mise en œuvre de haute qualité de la conception de l'architecture, de la mise en œuvre du codage, du lancement sécurisé, du déploiement et de l'exploitation et d'autres étapes de production est la prémisse et la base de la mise en œuvre d'un logiciel à haute disponibilité.
conception architecturale
La conception de l'architecture affecte souvent le coût de mise en œuvre précoce (ROI) du système et la difficulté d'exploitation et de maintenance ultérieures. Elle appartient à la conception de haut niveau du logiciel, qui comprend à la fois le schéma de conception macro et les contraintes de paradigme dans les détails de mise en œuvre. .
Invitez les architectes à participer : invitez les architectes à participer aux nœuds de transaction principaux et aux changements majeurs de la demande, ce qui est le moyen le plus direct et le plus efficace de fermer la fosse ;
Accent mis sur les documents de conception : Une description claire du schéma et l'approbation des parties prenantes concernées sont les conditions préalables pour marcher sur la bonne voie.
Conception de reprise après sinistre : Il est nécessaire de réserver une issue, de réfléchir clairement à l'avance et de faire un bon travail dans la conception de reprise après sinistre. Restauration, fusible, nouvelle tentative et rétrogradation possibles.
Conception robuste : conception sans état, conception anti-lourde, conception idempotente, conception de cohérence des données
Implémentation de l'encodage
Si la conception architecturale est le squelette, la mise en œuvre du codage concerne les nerfs, les vaisseaux sanguins et les muscles. Le premier détermine la stabilité et la durée de marche, tandis que le second détermine la vitesse et la distance que vous pouvez parcourir. Mis en œuvre au niveau du codage, c'est le degré de vieillissement et de corruption du code.
Mécanisme de revue de code : La revue de code n'est pas aussi simple que de trouver des problèmes dans le système. C'est un comportement à long terme et une forme et un support pour la mise en œuvre et l'héritage de la culture organisationnelle. Au cours du processus d'examen, les limites des responsabilités de l'entreprise, le consensus de conception et de codage et l'excellent consensus de recherche et développement axé sur les normes ont été clarifiés. Cela équivaut à donner des orientations précises à travers des cas concrets, qui sont les pierres angulaires pour assurer l'efficacité au combat de l'équipe.
De nombreux problèmes dans le processus de R&D peuvent être découverts et résolus grâce au mécanisme de revue de code, tels que :
en ligne en toute sécurité
70 % des pannes en ligne sont déclenchées par une sorte de changement, et une proportion considérable d'entre elles sont causées par une connexion irrégulière. Il est donc très important d'aller en ligne en toute sécurité.
opération de déploiement
Un moyen très important d'atteindre une haute disponibilité est la redondance de capacité. La direction et les idées sont données ci-dessous, ainsi que les détails et stratégies de mise en œuvre spécifiques, qui peuvent être étendus en fonction de situations spécifiques.
Garantie standard de quatre opérations
Spécifications de fonctionnement
plan d'urgence
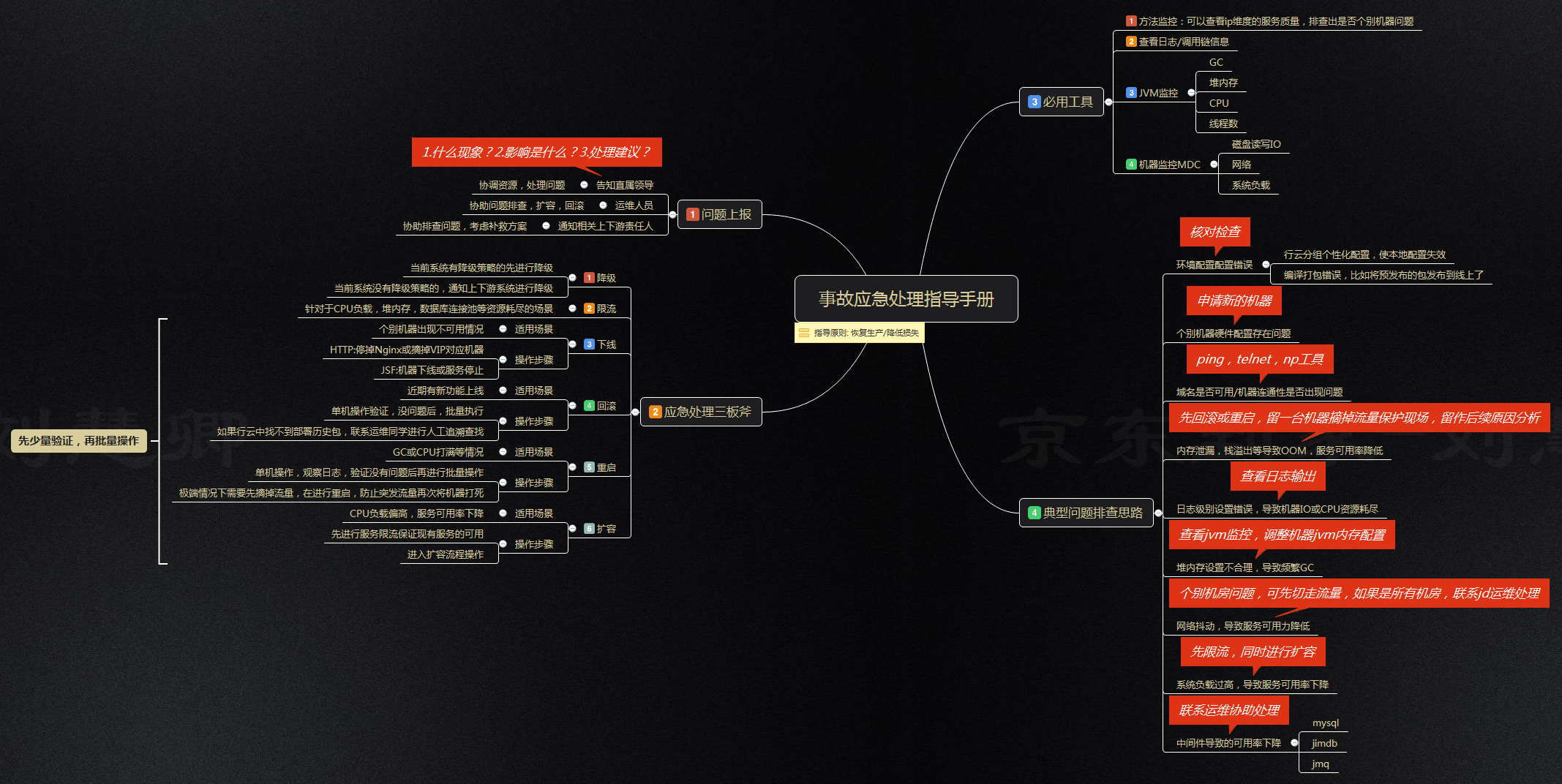
La haute disponibilité signifie une faible tolérance aux temps d'arrêt, signifie pas de temps pour le dépannage et la réparation, et pas de temps pour ouvrir le code pour le dépannage des vulnérabilités. Cela nous oblige à disposer d'un ensemble complet de plans d'urgence, qui peuvent résoudre la plupart des problèmes de défaillance prévisibles.
Pour le manuel détaillé de traitement d'urgence en cas d'accident, veuillez vous référer à la figure suivante :
Conformité aux normes
Peu importe la qualité du processus et des normes, il doit y avoir un mécanisme correspondant pour les mettre en œuvre, sinon ce sera une fleur dans le miroir, une lune dans l'eau, qui est belle mais qui est en fait inutile. Exécutable et mesurable sont les conditions préalables pour s'améliorer en fonction des objectifs. Voici donc un outil appelé "Tableau d'auto-inspection périodique de la haute disponibilité et de la conformité" pour aider à la mise en œuvre de la spécification.

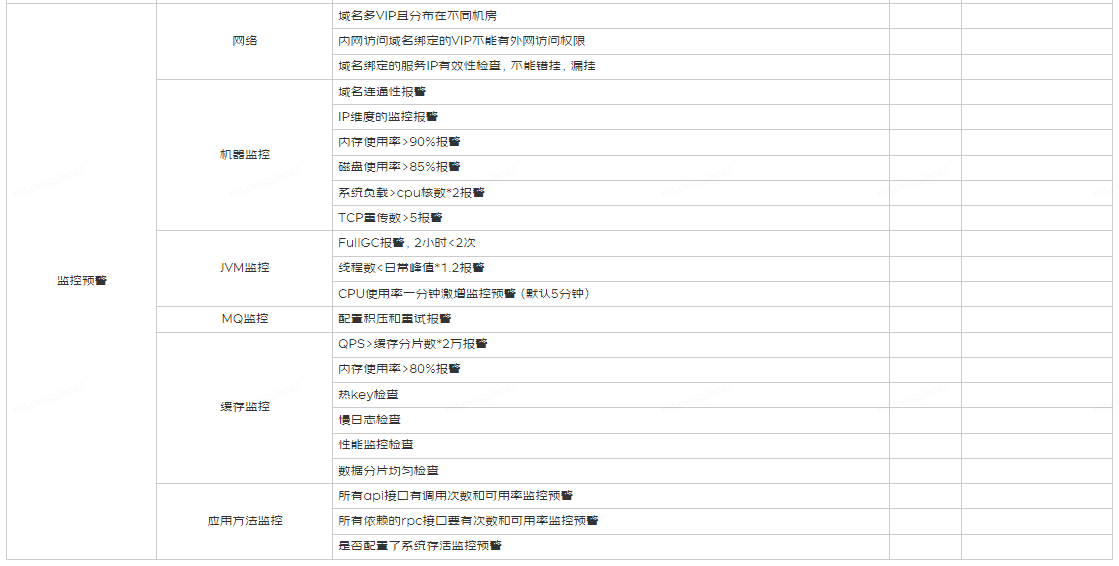
Cinq Résumé
Cet article traite de la question « Pourquoi la haute disponibilité représente-t-elle un grand défi ? », souligne l'importance de l'efficacité de la collaboration dans le processus de livraison de la demande et explique pourquoi il est nécessaire de suivre le principe de fonctionnement « Le travail d'aujourd'hui, le travail d'aujourd'hui ". Des aspects de la conception de l'architecture, de la mise en œuvre du codage, du lancement sécurisé, du déploiement et de l'exploitation, etc., il présente en détail les directives et les détails de mise en œuvre liés à la garantie de mise en œuvre de la technologie. Enfin, du point de vue de l'exploitation post-lancement, il donne des outils pratiques de garantie d'exploitation tels que plan d'urgence, tableau d'autocontrôle régulier, etc. J'espère que cela pourra aider les lecteurs.