Résumé : Le tri par fusion et le tri rapide sont deux algorithmes de tri légèrement compliqués. Ils utilisent tous deux l'idée de diviser pour mieux régner. Les codes sont implémentés par récursivité et le processus est très similaire. La clé pour comprendre le tri par fusion est de comprendre la formule de récursivité et la fonction de fusion merge().
Cet article est partagé par la communauté Huawei Cloud " Huit algorithmes de tri de manière simple ", auteur : Embedded Vision.
Le tri par fusion et le tri rapide sont deux algorithmes de tri légèrement compliqués. Ils utilisent tous deux l'idée de diviser pour régner, et le code est implémenté par récursivité. Le processus est très similaire. La clé pour comprendre le tri par fusion est de comprendre la formule de récursivité et la fonction de fusion merge().
Un, tri à bulles (Tri à bulles)
L'algorithme de tri est un type d'algorithme que les programmeurs doivent comprendre et connaître. Il existe de nombreux types d'algorithmes de tri, tels que : bouillonnement, insertion, sélection, rapide, fusion, comptage, cardinalité et tri par compartiments.
Le tri à bulles ne fonctionnera que sur deux données adjacentes. Chaque opération de bouillonnement comparera deux éléments adjacents pour voir s'ils répondent aux exigences de relation de taille, et si ce n'est pas le cas, laissez-les être échangés. Un bouillonnement déplacera au moins un élément là où il devrait être, et répétera n fois pour terminer le tri de n données.
Résumé : Si le tableau comporte n éléments, dans le pire des cas, n opérations de génération de bulles sont nécessaires.
Le code C++ de l'algorithme de base du tri à bulles est le suivant :
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}En fait, l'algorithme de tri des bulles ci-dessus peut également être optimisé. Lorsqu'une certaine opération de bulle n'effectue plus d'échange de données, cela signifie que le tableau est déjà en ordre et qu'il n'est pas nécessaire de continuer à effectuer les opérations de bulle suivantes. Le code optimisé est le suivant :
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
// 提前退出冒泡循环发标志位
bool flag = False;
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
flag = True; // 表示本次冒泡操作存在数据交换
}
}
if(!flag) break; // 没有数据交换,提交退出
}
}Caractéristiques de Bubble Sort :
- Le processus de bouillonnement n'implique que l'échange d'éléments adjacents et ne nécessite qu'un niveau constant d'espace temporaire, de sorte que la complexité de l'espace est O(1) O (1), qui est un algorithme de tri en place .
- Lorsqu'il y a deux éléments adjacents de même taille, on n'échange pas, et les données de même taille ne changeront pas l'ordre avant et après le tri, c'est donc un algorithme de tri stable .
- Le pire cas et la complexité temporelle moyenne sont tous deux O(n2) O ( n 2 ), et la meilleure complexité temporelle est O(n) O ( n ).
Deuxièmement, le tri par insertion (Insertion Sort)
- L'algorithme de tri par insertion divise les données du tableau en deux intervalles : l'intervalle trié et l'intervalle non trié. La plage triée initiale n'a qu'un seul élément, qui est le premier élément du tableau.
- L'idée centrale de l'algorithme de tri par insertion est de prendre un élément de la plage non triée, de trouver une position appropriée à insérer dans la plage triée et de s'assurer que les données de la plage triée sont toujours dans l'ordre.
- Répétez ce processus jusqu'à ce que les éléments d'intervalle non triés soient vides, puis l'algorithme se termine.
Le tri par insertion, comme le tri à bulles, comprend également deux opérations, l'une est la comparaison d'éléments et l'autre est le mouvement d'éléments .
Lorsque nous devons insérer une donnée a dans la plage triée, nous devons comparer la taille de a avec les éléments de la plage triée afin de trouver une position d'insertion appropriée. Après avoir trouvé le point d'insertion, nous devons également reculer d'un bit l'ordre des éléments après le point d'insertion, afin de faire de la place pour l'élément a à insérer.
L'implémentation du code C++ du tri par insertion est la suivante :
void InsertSort(int a[], int n){
if (n <= 1) return;
for (int i = 1; i < n; i++) // 未排序区间范围
{
key = a[i]; // 待排序第一个元素
int j = i - 1; // 已排序区间末尾元素
// 从尾到头查找插入点方法
while(key < a[j] && j >= 0){ // 元素比较
a[j+1] = a[j]; // 数据向后移动一位
j--;
}
a[j+1] = key; // 插入数据
}
}Fonctionnalités de tri par insertion :
- Le tri par insertion ne nécessite pas d'espace de stockage supplémentaire et la complexité de l'espace est O (1) O (1), de sorte que le tri par insertion est également un algorithme de tri en place.
- Dans le tri par insertion, pour les éléments de même valeur, nous pouvons choisir d'insérer les éléments qui apparaissent plus tard à l'arrière des éléments qui apparaissent avant, de sorte que l'ordre d'origine avant et arrière puisse être conservé inchangé, de sorte que le tri par insertion est un stable algorithme de tri.
- Le pire cas et la complexité temporelle moyenne sont tous deux O(n2) O ( n 2 ), et la meilleure complexité temporelle est O(n) O ( n ).
Trois, tri par sélection (Tri par sélection)
L'idée de mise en œuvre de l'algorithme de tri par sélection est quelque peu similaire au tri par insertion, et elle est également divisée en intervalles triés et en intervalles non triés. Mais le tri par sélection trouvera à chaque fois le plus petit élément de l'intervalle non trié et le placera à la fin de l'intervalle trié.
La complexité temporelle du meilleur cas, du pire cas et du cas moyen du tri par sélection est O(n2) O ( n 2), qui est un algorithme de tri en place et un algorithme de tri instable .
Le code C++ pour le tri par sélection est implémenté comme suit :
void SelectSort(int a[], int n){
for(int i=0; i<n; i++){
int minIndex = i;
for(int j = i;j<n;j++){
if (a[j] < a[minIndex]) minIndex = j;
}
if (minIndex != i){
temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
}Récapitulatif du tri de la sélection d'insertion de bulles
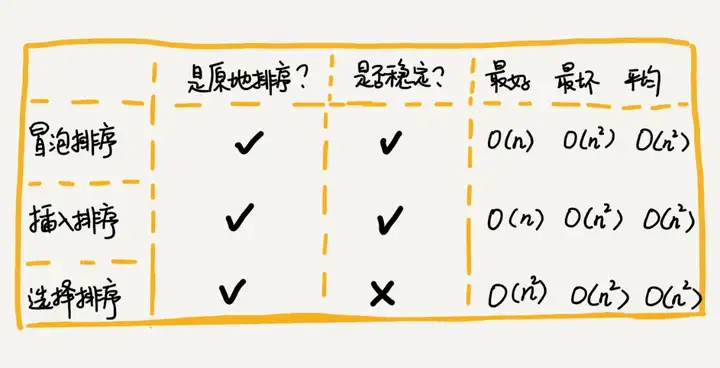
Les codes d'implémentation de ces trois algorithmes de tri sont très simples, et ils sont très efficaces pour trier des données à petite échelle. Cependant, lors du tri de données à grande échelle, la complexité temporelle est encore un peu élevée, il est donc plus enclin à utiliser un algorithme de tri avec une complexité temporelle de O(nlogn) O ( nlogn ).
Certains algorithmes dépendent de certaines structures de données. Les trois algorithmes de tri ci-dessus sont tous implémentés sur la base de tableaux.
Quatrièmement, tri par fusion (Merge Sort)
L'idée de base du tri par fusion est relativement simple. Si nous voulons trier un tableau, nous divisons d'abord le tableau en parties avant et arrière à partir du milieu, puis trions les parties avant et arrière séparément, puis fusionnons les deux parties triées ensemble , de sorte que l'ensemble du tableau soit en ordre.
Le tri par fusion utilise l'idée de diviser pour mieux régner. Diviser pour régner, comme son nom l'indique, consiste à diviser pour régner, en décomposant un gros problème en petits sous-problèmes à résoudre. Lorsque les petits sous-problèmes sont résolus, le gros problème est également résolu.
L'idée de diviser pour régner est quelque peu similaire à l'idée récursive, et l'algorithme de division pour régner est généralement implémenté avec la récursivité. Diviser pour régner est une idée de traitement pour résoudre des problèmes, et la récursivité est une technique de programmation, et les deux ne sont pas en conflit.
Sachant que le tri par fusion utilise la pensée diviser pour régner et que la pensée diviser pour régner est généralement implémentée à l'aide de la récursivité, l'objectif suivant est de savoir comment utiliser la récursivité pour implémenter le tri par fusion . La compétence d'écrire du code récursif consiste à analyser le problème pour obtenir la formule récursive, puis à trouver la condition de terminaison, et enfin à traduire la formule récursive en code récursif. Par conséquent, si vous voulez écrire le code pour le tri par fusion, vous devez d'abord écrire la formule récursive pour le tri par fusion .
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解,即区间数组元素为 1 Le pseudo-code pour le tri par fusion est le suivant :
merge_sort(A, n){
merge_sort_c(A, 0, n-1)
}
merge_sort_c(A, p, r){
// 递归终止条件
if (p>=r) then return
// 取 p、r 中间的位置为 q
q = (p+r)/2
// 分治递归
merge_sort_c(A[p, q], p, q)
merge_sort_c(A[q+1, r], q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}4.1, Analyse des performances du tri par fusion
1. Le tri par fusion est un algorithme de tri stable . Analyse : La fonction merge_sort_c() dans le pseudo-code ne fait que décomposer le problème et n'implique pas de déplacer des éléments et de comparer des tailles. La comparaison d'éléments réels et le déplacement de données se trouvent dans la partie fonction merge(). Dans le processus de fusion, l'ordre des éléments ayant la même valeur est garanti de rester inchangé avant et après la fusion. Le tri par fusion est un algorithme de tri stable.
2. L'efficacité d'exécution du tri par fusion n'a rien à voir avec le degré d'ordre du tableau d'origine à trier, sa complexité temporelle est donc très stable. Que ce soit le meilleur des cas, le pire des cas ou le cas moyen, le la complexité temporelle est O (nlogn) O ( nlogn ). Analyse : non seulement le problème de solution récursive peut être écrit sous forme de formule récursive, mais la complexité temporelle du code récursif peut également être écrite sous forme de formule récursive :

3. La complexité spatiale est O(n) . Analyse : La complexité spatiale du code récursif ne s'additionne pas comme la complexité temporelle. Bien que chaque opération de fusion de l'algorithme doive demander de l'espace mémoire supplémentaire, une fois la fusion terminée, l'espace mémoire temporairement ouvert est libéré. A tout moment, le CPU n'aura qu'une seule fonction en cours d'exécution, et donc un seul espace mémoire temporaire en cours d'utilisation. L'espace mémoire temporaire maximum ne dépassera pas la taille de n données, donc la complexité de l'espace est O(n) O ( n ).
Cinq, tri rapide (Quicksort)
L'idée du tri rapide est la suivante : si nous voulons trier un ensemble de données avec des indices de p à r dans le tableau, nous choisissons toutes les données entre p et r comme pivot (point de partition ) . Nous parcourons les données entre p et r, plaçons les données plus petites que le pivot à gauche, plaçons les données plus grandes que le pivot à droite et plaçons le pivot au milieu. Après cette étape, les données entre le tableau p et r sont divisées en trois parties. Les données entre p et q-1 à l'avant sont plus petites que le pivot, le milieu est le pivot et les données entre q+1 et r est supérieur au pivot.
Selon l'idée de diviser pour mieux régner et de récursivité, on peut trier récursivement les données avec des indices de p à q-1 et les données avec des indices de q+1 à r jusqu'à ce que l'intervalle soit réduit à 1, ce qui signifie que tout Les données sont toutes en ordre.
La formule de récurrence est la suivante :
递推公式:
quick_sort(p,r) = quick_sort(p, q-1) + quick_sort(q, r)
终止条件:
p >= rTri par fusion et résumé de tri rapide
Le tri par fusion et le tri rapide sont deux algorithmes de tri légèrement compliqués. Ils utilisent tous deux l'idée de diviser pour régner, et le code est implémenté par récursivité. Le processus est très similaire. La clé pour comprendre le tri par fusion est de comprendre la formule de récursivité et la fonction de fusion merge(). De la même manière, la clé pour comprendre le tri rapide est de comprendre la formule récursive, ainsi que la fonction de partition partition().
En plus des 5 algorithmes de tri ci-dessus, il existe 3 algorithmes de tri linéaire dont la complexité temporelle est O(n) O ( n ) : tri par compartiments, tri par comptage et tri par base. Les performances de ces huit algorithmes de tri sont résumées dans la figure suivante :
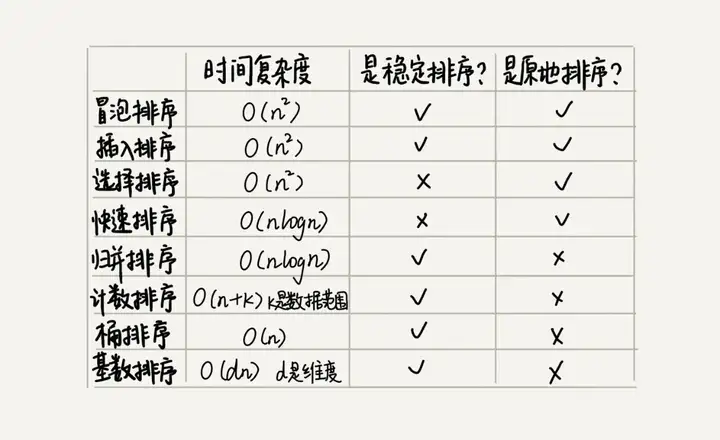
Les références
- Tri (Partie 1) : Pourquoi le tri par insertion est-il plus populaire que le tri à bulles ?
- Tri (ci-dessous) : Comment trouver le Kème plus grand élément de O(n) avec l'idée de tri rapide ?