
Auteur | La pierre qui flotte comme un rêve
guide
Avec la large application de la technologie informatique en temps réel dans les mégadonnées, la rapidité des données a été considérablement améliorée, mais dans les scénarios d'application réels, en plus de la rapidité, elle est également confrontée à des exigences techniques plus élevées.
Cet article combine l'exploration et la pratique de la technologie de calcul en temps réel du niveau d'eau dans l'entrepôt de données intégré par lots, en se concentrant sur le concept de la technologie du niveau d'eau et les pratiques théoriques connexes, en particulier les caractéristiques, la définition des limites et l'application du niveau d'eau en temps réel. -temps systèmes informatiques, et enfin se concentre sur la description Une conception améliorée et la mise en œuvre de niveau d'eau précis est présentée. L'architecture technique est actuellement mature et stable dans les scénarios commerciaux réels de Baidu, et je voudrais la partager avec vous, en espérant être une valeur de référence pour tout le monde.
Le texte intégral est de 7118 mots et le temps de lecture prévu est de 18 minutes.
01 Contexte commercial
Afin d'améliorer l'efficacité du développement de produits, de l'itération de la stratégie, de l'analyse des données et de la prise de décision opérationnelle, les entreprises ont des exigences de plus en plus élevées en matière d'actualité des données.
Bien que nous ayons réalisé très tôt la construction d'un entrepôt de données temps réel basé sur le calcul temps réel, il ne peut toujours pas remplacer l'entrepôt de données hors ligne.Le coût de développement et de maintenance d'un ensemble d'entrepôts de données temps réel et hors ligne est élevé, et la chose la plus importante est que le calibre de l'entreprise ne peut pas être aligné à 100 %. Par conséquent, nous nous sommes engagés à construire un entrepôt de données intégré par lots, qui peut non seulement accélérer l'efficacité globale du traitement des données, mais également garantir que les données sont aussi fiables que les données hors ligne et peuvent prendre en charge des scénarios commerciaux à 100 %. afin d'obtenir une réduction globale des coûts et une amélioration de l'efficacité.
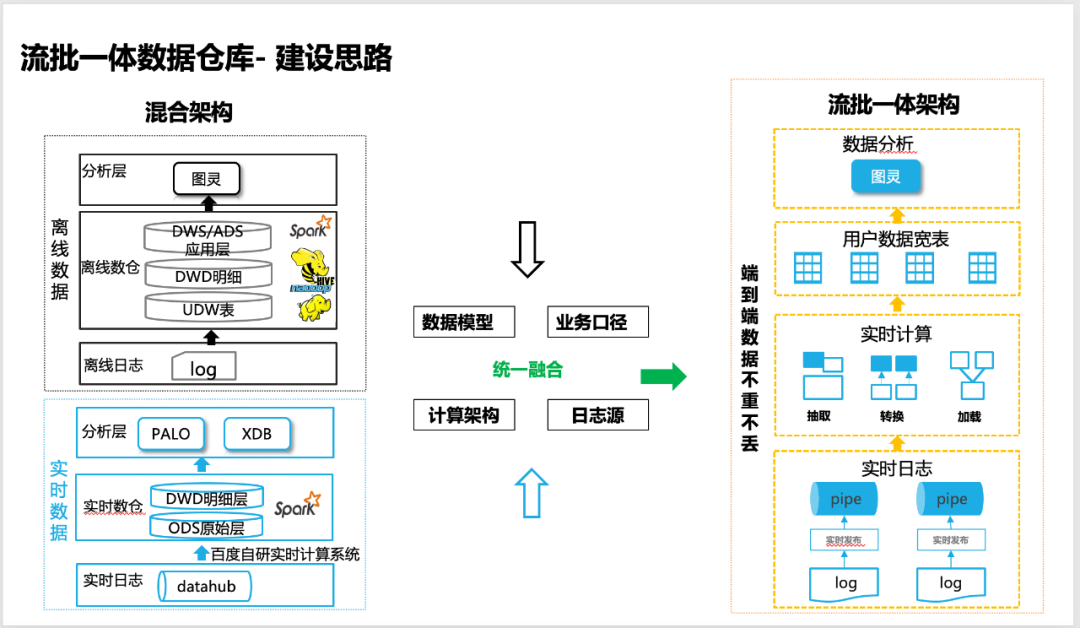
△L'idée de construire un entrepôt de données intégré stream-batch
02 Difficultés techniques de l'entrepôt de données intégré Stream-Batch
Afin de réaliser l'entrepôt de données de flux et de lots intégré de bout en bout, en tant que système informatique en temps réel de l'architecture technique sous-jacente, il est confronté à de nombreuses difficultés et défis techniques :
1. Les données de bout en bout ne sont strictement pas répétées ou perdues pour assurer l'intégrité des données ;
2. La fenêtre de données en temps réel et la fenêtre de données hors ligne, y compris les données, sont alignées (99,9 % ~ 99,99 %) ;
3. Le calcul en temps réel doit prendre en charge le calcul précis de la fenêtre pour garantir l'effet précis de la stratégie anti-triche en temps réel ;
4. Le système informatique en temps réel est intégré à l'écologie interne des mégadonnées de Baidu, et il existe une pratique réelle de fonctionnement stable en ligne à grande échelle.
Les points 2 et 3 ci-dessus nécessitent tous un mécanisme de niveau d'eau hautement fiable pour assurer la connaissance des progrès et la segmentation précise des données en temps réel.
Par conséquent, cet article partage avec vous l'exploration et l'expérience pratique du niveau d'eau précis dans l'entrepôt de données intégré stream-batch.
03 État actuel du concept de niveau d'eau et mise en œuvre générale
3.1 Nécessité du niveau d'eau
Avant d'introduire le concept de Watermark, deux concepts doivent être insérés :
-
Heure de l'événement, l'heure à laquelle l'événement s'est produit. Nous l'entendons généralement comme l'heure à laquelle le comportement réel de l'utilisateur s'est produit et correspond spécifiquement à l'horodatage auquel le comportement de l'utilisateur s'est produit dans le journal.
-
Temps de traitement, temps de traitement des données. Nous le comprenons généralement comme le temps nécessaire au système pour traiter les données.
Quelle est l'utilisation spécifique du filigrane ?
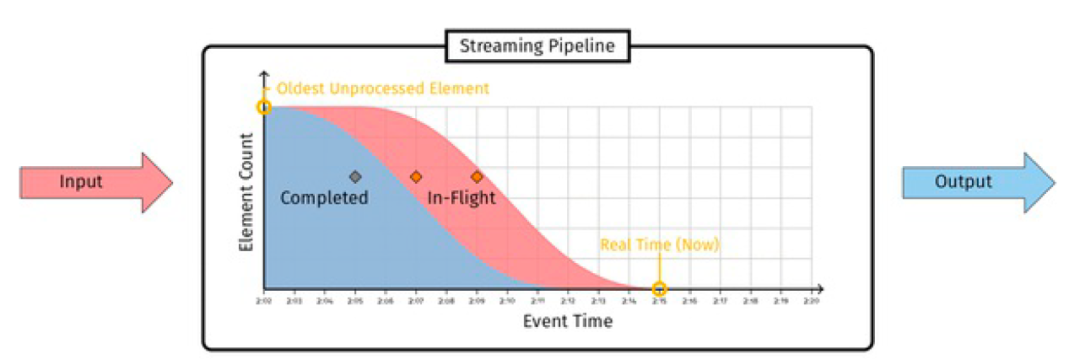
Dans le processus de traitement de données en temps réel, les données sont illimitées (Unbounded), donc le calcul de fenêtre basé sur Window ou d'autres scénarios similaires est confronté à un problème pratique :
Comment savez-vous que les données d'une certaine fenêtre sont complètes ? Quand la fenêtre compute() peut-elle être déclenchée ?
Dans la plupart des cas, nous utilisons Event Time pour déclencher les calculs de fenêtre (ou le fractionnement de la partition de données et l'alignement hors ligne). Cependant, la situation réelle est que les journaux en temps réel ont toujours des degrés de retard différents (dans les étapes de collecte, de transmission et de traitement des journaux), c'est-à-dire, comme le montre la figure ci-dessous, l'inclinaison du filigrane sera en fait se produire (c'est-à-dire que les données apparaîtront dans le désordre). Dans ce cas, le mécanisme Watermark est nécessaire pour assurer l'intégrité des données.
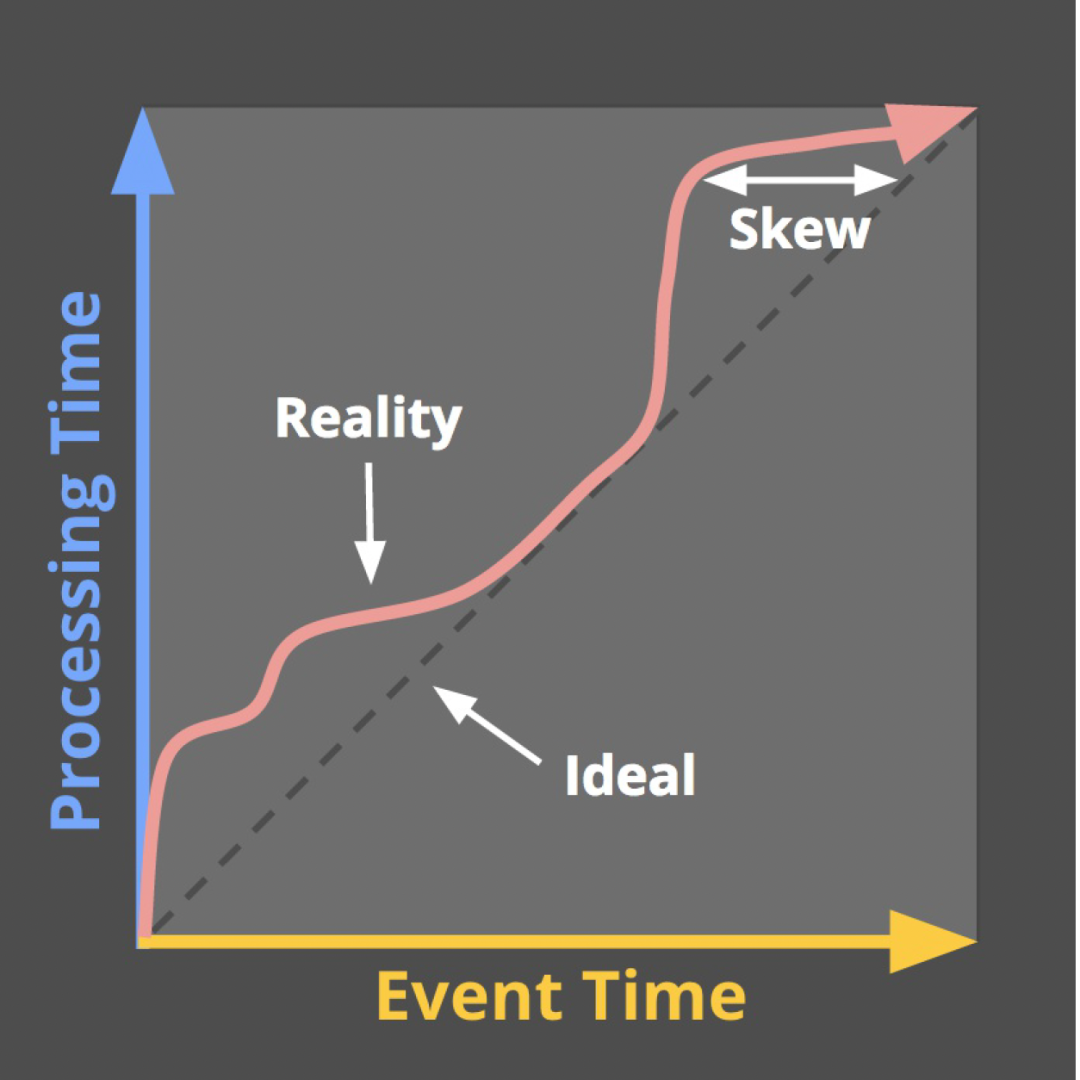 △Phénomène d'inclinaison du niveau d'eau
△Phénomène d'inclinaison du niveau d'eau
3.2 Définition et caractéristiques du plan d'eau
La définition de filigrane (filigrane) n'est actuellement pas uniforme dans l'industrie.Combinée à la définition du livre ** Streaming Systems ** (l'auteur est l'équipe R&D de Google Dataflow), je pense personnellement qu'elle est plus précise :
Le filigrane est un horodatage croissant de manière monotone du travail le plus ancien non encore terminé.
À partir de la définition, nous pouvons résumer les deux caractéristiques fondamentales du niveau d'eau :
-
Le niveau d'eau augmente continuellement (non retournable)
-
Le niveau d'eau est un horodatage
Cependant, dans le système de production réel, comment calculer le niveau d'eau et quel est l'effet réel ? Combiné avec différents systèmes informatiques en temps réel dans l'industrie, le support des niveaux d'eau est encore différent.
3.3 État actuel du niveau d'eau et défis
Dans les systèmes informatiques en temps réel actuels de l'industrie, tels qu'Apache Flink (une implémentation open source de Google Dataflow) et Apache Spark (uniquement limité au framework Structured Streaming), ils prennent tous en charge les niveaux d'eau. Apache Flink dans la communauté. Indiquez le mécanisme de mise en œuvre du niveau d'eau :

Cependant, le mécanisme de mise en œuvre et l'effet du niveau d'eau au-dessus, dans le cas d'une grande zone de transmission de journal retardée à la source du journal, le niveau d'eau sera toujours mis à jour (les nouvelles et anciennes données sont transmises dans le désordre) et avancer, ce qui entraînera des données incomplètes dans la fenêtre correspondante et un calcul de fenêtre inexact. . Par conséquent, au sein de Baidu, nous avons exploré un mécanisme de niveau d'eau amélioré et relativement précis basé sur le système de collecte et de transmission de journaux et le système informatique en temps réel pour garantir que les données en temps réel sont calculées dans la fenêtre et l'atterrissage des données (évier vers AFS /Hive) et autres scénarios applicatifs Ensuite, la problématique de l'intégrité des données de la fenêtre est de répondre aux exigences de réalisation de l'entrepôt de données intégré stream-batch.
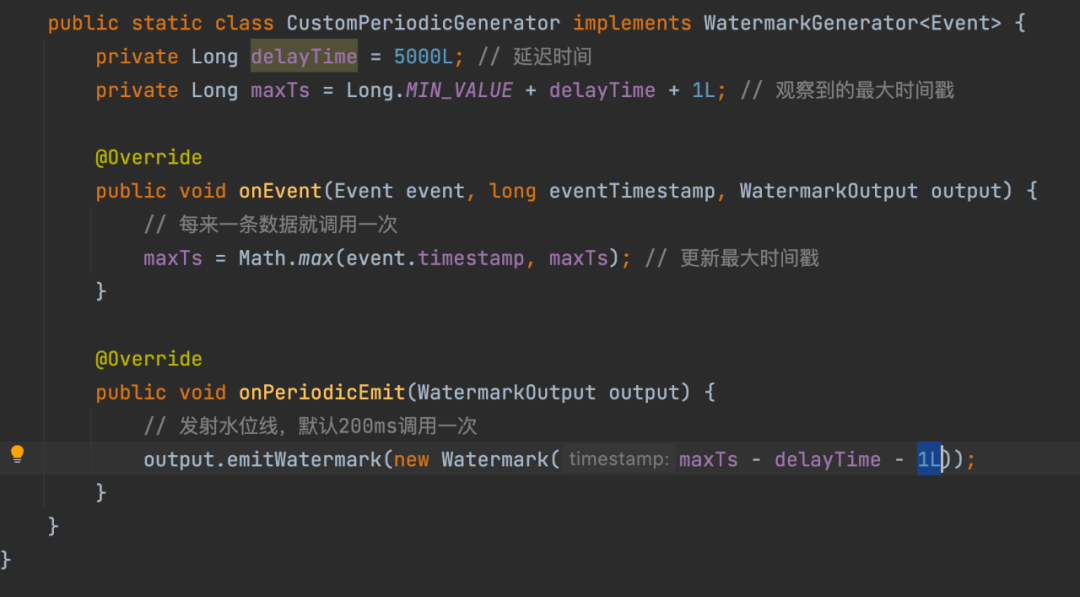
△Stratégie de génération de niveau d'eau Flink
PARLER DE GEEK
04 Conception et application du niveau d'eau global
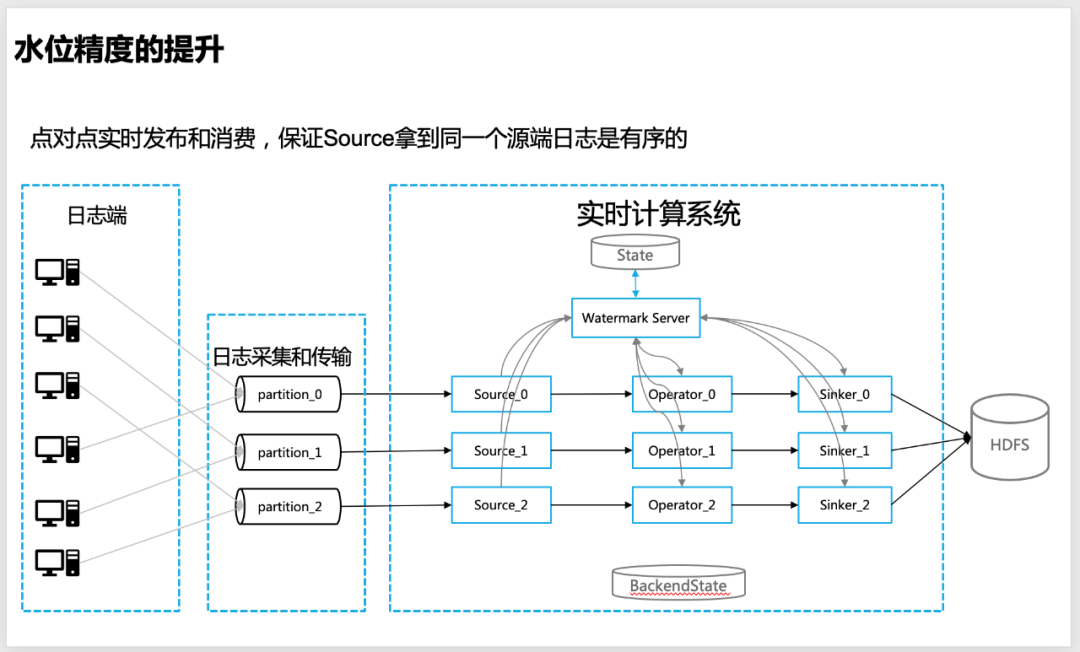
4.1 Conception de la gestion centralisée des niveaux d'eau
Afin de rendre le niveau d'eau plus précis dans le calcul en temps réel, nous avons conçu une idée de gestion centralisée du niveau d'eau, c'est-à-dire que chaque nœud de calcul en temps réel, y compris la source, l'opérateur, le plomb, etc., signalera le niveau d'eau informations calculées par lui-même au Watermark Server global, la gestion unifiée des informations sur le niveau d'eau est effectuée par Watermark Server.
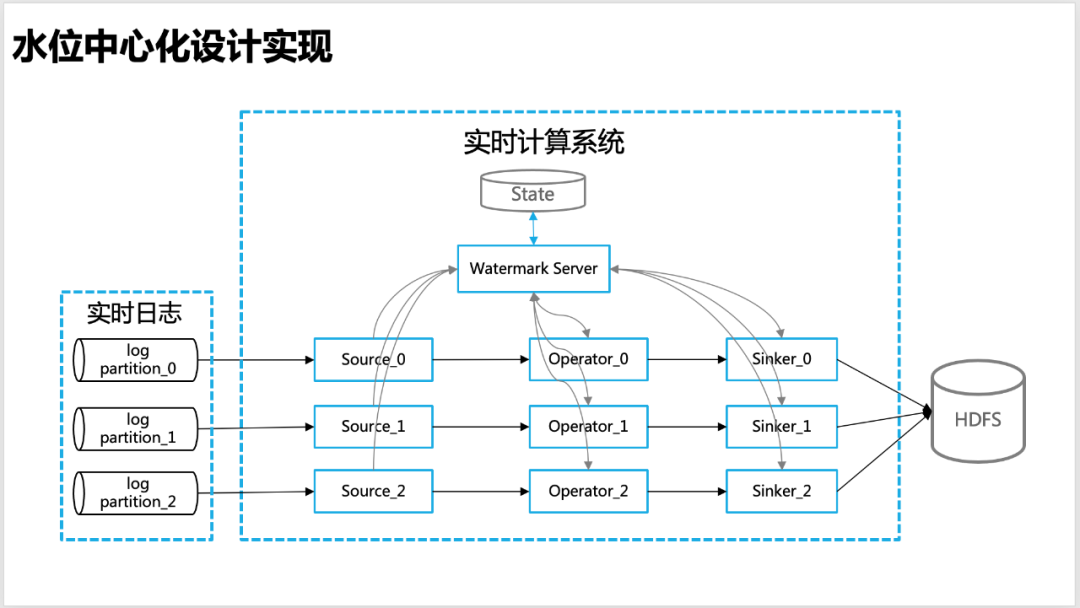
△ Conception centralisée du niveau d'eau
Watermark Server : maintient une table d'informations sur le niveau d'eau (hash_table), qui contient les informations sur le niveau d'eau correspondant à chaque niveau de l'information de topologie globale (Source, Opérateur, Sinker, etc.) du programme de calcul en temps réel (APP), ainsi Afin de faciliter le calcul du niveau d'eau global (comme le niveau d'eau bas), Watermark Server interagit régulièrement avec l'état pour s'assurer que les informations sur le niveau d'eau ne sont pas perdues.
Client Watermark : le client de mise à jour du niveau d'eau, dans les opérateurs en temps réel tels que la source, le travailleur et le plomb, est chargé de signaler et de demander des informations sur le niveau d'eau (telles que le niveau d'eau en amont ou global) au serveur Watermark, et de demander un rappel via baidu-rpc service.
Low watermark (niveau d'eau bas) : Low watermark est un horodatage utilisé pour marquer l'heure des données non traitées les plus anciennes (les plus anciennes) dans le processus de traitement des données en temps réel (Low watermark, qui tente de manière pessimiste de capturer l'heure de l'événement des données non traitées les plus anciennes enregistrement dont le système a connaissance. ). Il promet qu'aucune donnée future n'arrivera avant cet horodatage. Le calcul du temps ici est généralement basé sur l'heure de l'événement, c'est-à-dire l'heure à laquelle l'événement se produit, comme l'heure à laquelle le comportement de l'utilisateur dans le journal se produit, et le temps de traitement des données (temps de traitement, qui peut également être utilisé dans certains scénarios ) est moins utilisé. La formule de calcul du filigrane est (de Google MillWheel Thesis ):
Filigrane bas de A = min (travail le plus ancien de A, filigrane bas de C : sorties C vers A)
Cependant, dans la conception réelle du système, le filigrane bas peut être distingué en fonction de la limite de traitement de l'opérateur comme suit :
-
Input Low Watermark : le travail le plus ancien n'a pas encore été envoyé à cette étape de diffusion.
InputLowWatermark (étape) = min { OutputLowWatermark (étape') | Stage' est en amont de Stage}
Entrez le niveau d'eau le plus bas, qui peut être compris comme le filigrane qui sera entré dans l'opérateur actuel, c'est-à-dire les données traitées par l'opérateur en amont.
-
Output Low Watermark : Le travail le plus ancien n'est pas encore terminé par cette étape de streaming.
OutputLowWatermark (étape) = min { InputLowWatermark (étape), OldestWork (étape) }
Sortir le niveau d'eau le plus bas, qui peut être compris comme le niveau d'eau le plus ancien (le plus ancien) des données non traitées par l'opérateur actuel, c'est-à-dire le niveau d'eau des données traitées.
Comme le montre la figure ci-dessous, la compréhension sera plus claire.
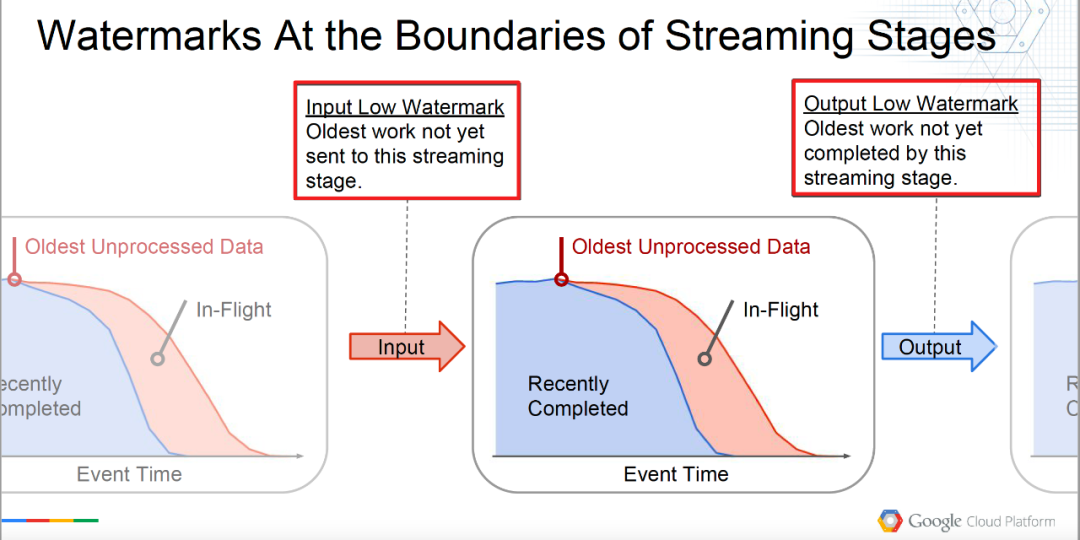 Définition des limites de △Low watermark
Définition des limites de △Low watermark
4.2 Comment obtenir un niveau d'eau précis
4.2.1 Conditions préalables pour un niveau d'eau précis
À l'heure actuelle, dans les scénarios d'application des systèmes informatiques en temps réel dans les entrepôts de données en temps réel, nous utilisons tous le low watermark pour déclencher le calcul de la fenêtre (car il est plus fiable).D'après la définition du low watermark en 3.1, nous pouvons savoir que : le niveau d'eau bas est calculé par itération hiérarchique, et la précision du niveau d'eau dépend de la précision du niveau d'eau le plus en amont (c'est-à-dire la source). Ainsi, afin d'améliorer la précision du calcul du niveau d'eau à la source, nous avons besoin de prérequis :
-
Les journaux sont produits séquentiellement en fonction de l'heure (event_time) sur un seul serveur côté serveur
-
Lorsque le journal est collecté, en plus du journal de comportement réel de l'utilisateur, il doit également contenir d'autres informations, telles que la balise du serveur (nom d'hôte) et l'heure du journal (msg_time), comme illustré dans la figure suivante

△ Informations sur l'empaquetage des journaux
-
Le journal est publié dans la file d'attente de messages en temps réel point à point pour garantir qu'au sein d'une seule partition de la file d'attente de messages, les journaux d'un seul serveur sont strictement ordonnés
△Le journal source est publié point à point dans la file d'attente des messages pour garantir que le journal à partition unique est ordonné
4.2.2 Méthode de calcul du niveau d'eau
1、Serveur de filigrane
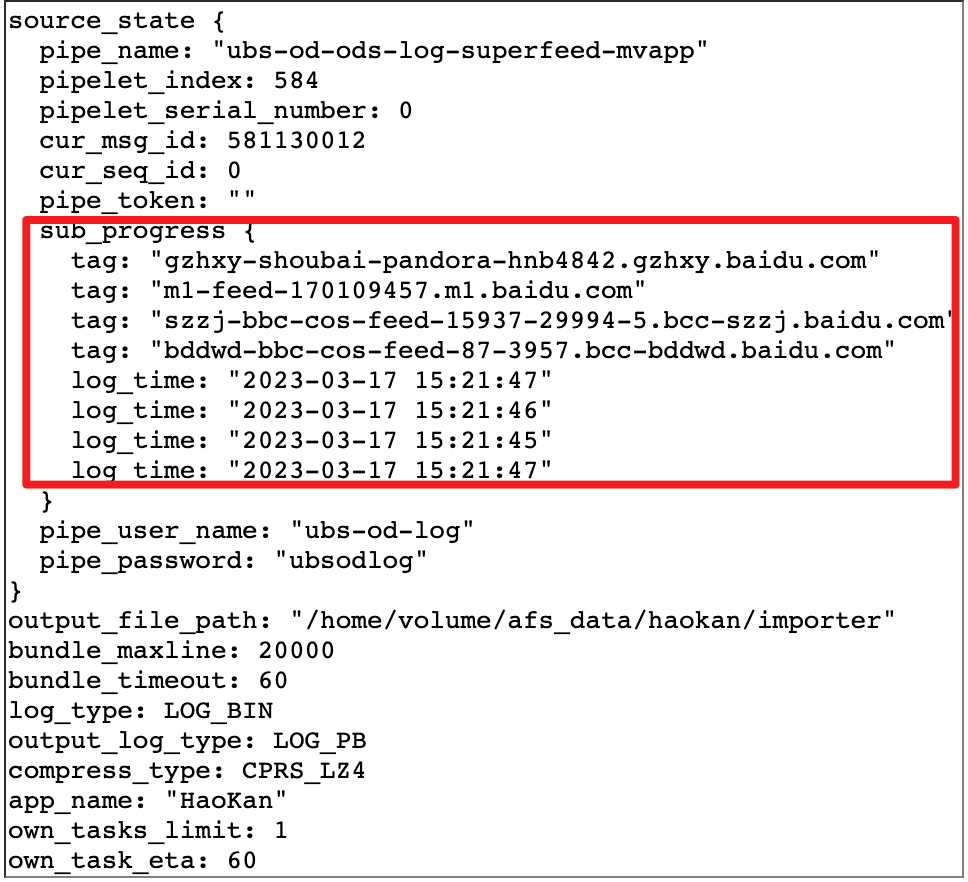
Initialiser :
D'abord commencé comme un thread séparé (thread). Selon le BNS (Baidu Naming Service, service de nom Baidu, qui fournit un mappage du nom du service à toutes les instances en cours d'exécution du serveur) de la tâche de transmission de journal configurée, la liste des serveurs (liste des noms d'hôte) de la source du journal est analysée ; selon la relation de topologie APP configurée, le filigrane est initialisé Table d'informations et Table d'écriture persistante (moteur de stockage kv distribué Baidu).
Mise à jour des informations sur le niveau d'eau ordinaire : recevez les informations sur le niveau d'eau du client et mettez à jour le niveau d'eau de la granularité correspondante (granularité du processeur ou granularité du groupe de clés), et mettez à jour le niveau d'eau local
Calcul précis du niveau d'eau :
En réalité, si le journal à la source doit arriver à 100% avec précision, cela entraînera des retards fréquents ou des retards trop longs (si la logique globale Low watermark est utilisée pour la distribution). La raison est la suivante : dans le cas d'un trop grand nombre d'instances de serveur côté journal (par exemple, nous avons en fait 6 000 à 10 000 instances de journaux), il y aura toujours un retard dans le téléchargement en temps réel des journaux dans les instances de services en ligne câblés. , cela doit donc être fait dans Faites un compromis entre l'intégrité des données et l'actualité, comme le contrôle précis du nombre d'instances qui autorisent des retards sous forme de pourcentages (par exemple, configurez 99,9 % ou 99,99 % pour définir la proportion qui permet à la source journaux à retarder ), pour contrôler avec précision la précision du niveau d'eau à la source même.
Le niveau d'eau précis nécessite une configuration spéciale. La marque d'eau basse de sortie de la source est calculée en fonction de la relation de mappage entre le serveur et la progression du journal signalée par la source en temps réel, et du ratio configuré d'instances de retard autorisées.
Calculer le Low Watermark global : un niveau d'eau minimum global sera calculé et restitué à la demande du client
Persistance de l'état : écrivez périodiquement la persistance des informations sur le niveau d'eau mondial dans un stockage externe pour une récupération facile de l'état
2、Client de filigrane
Fin de la source : analysez le package de journaux et obtenez des informations telles que le nom de la machine et le journal d'origine dans le package de journaux. Une fois le journal d'origine traité par ETL et le dernier horodatage (event_timestamps) obtenu en fonction du journal d'origine, Source signale périodiquement la table de relations de mappage résolue en nom d'hôte et le dernier horodatage (event_timestamps) via l'API Watermark Client (actuellement configuré 1000 ms) au serveur Watermark.
△Source La relation de mappage de progression du serveur et du journal obtenue en analysant le journal
Côté opérateur :
Calcul du filigrane bas d'entrée : obtenez le filigrane bas de sortie de l'amont (en amont) comme filigrane bas d'entrée pour déterminer s'il faut déclencher le calcul de la fenêtre et d'autres opérations ;
Calcul du filigrane bas de sortie : calculez votre propre filigrane bas de sortie en fonction du journal, de l'état (état) et d'autres progrès de traitement (travail le plus ancien), et signalez-le au serveur de filigrane pour qu'il soit utilisé par les opérateurs en aval (processeur de téléchargement).
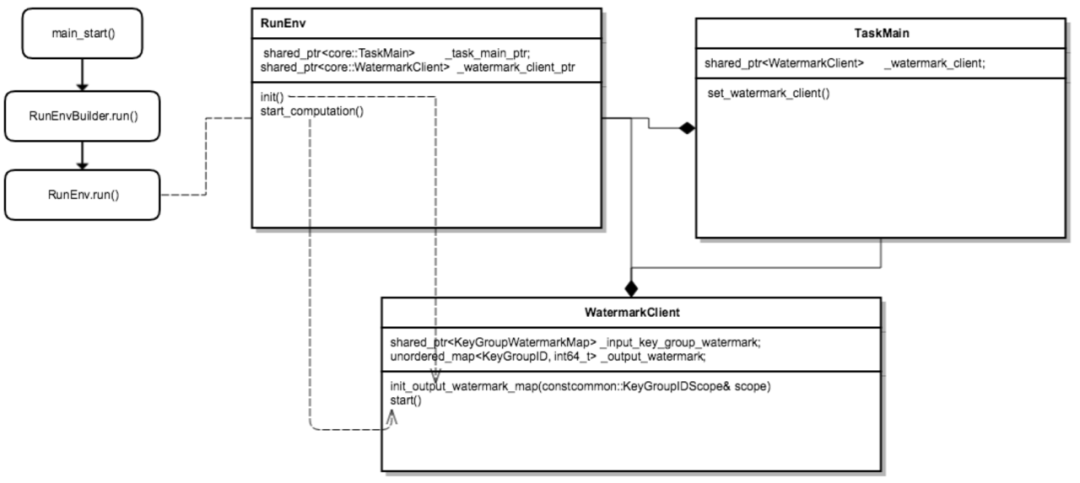
△ Flux de travail du client Watermark
Côté plomb :
Le côté plomb est le même que l'opérateur en temps réel ordinaire ci-dessus (opérateur), il calculera le filigrane bas d'entrée et le filigrane bas de sortie pour mettre à jour son propre niveau d'eau,
De plus, un Low Watermark global doit être demandé pour déterminer si la fenêtre de sortie des données est fermée.
4.3 Transmission du niveau d'eau précis entre les systèmes
La nécessité du transfert de niveau d'eau
Dans de nombreux cas, les systèmes en temps réel ne sont pas isolés et il existe une interaction de données entre plusieurs systèmes informatiques en temps réel. La manière la plus courante est que deux systèmes de traitement de données en temps réel sont en amont et en aval.
La performance spécifique est : deux systèmes de traitement de données en temps réel implémentent le transfert de données via des files d'attente de messages (comme Apache Kafka dans la communauté), donc dans ce cas, comment obtenir un transfert précis du niveau d'eau ?
Les étapes spécifiques de mise en œuvre sont les suivantes :
1. La source de journal du système informatique en temps réel en amont garantit que le journal est publié point à point, ce qui peut garantir la précision du niveau d'eau global (le rapport spécifique est réglable);
2. À l'extrémité de sortie du système de calcul en temps réel en amont (plongeur/exportateur vers l'extrémité de la file d'attente des messages), il est nécessaire de s'assurer que la marque d'eau basse globale est émise. Actuellement, nous utilisons les informations sur le niveau d'eau global à imprimer. sur chaque journal pour réaliser la livraison ;
3. À l'extrémité source du système de calcul de données en temps réel en aval, il est nécessaire d'analyser le champ d'information sur le niveau d'eau transporté par le journal (du système de calcul en temps réel en amont) et de commencer à l'utiliser comme entrée de le niveau d'eau (Input Low Watermark), et lancer le calcul itératif du niveau d'eau couche par couche et le calcul du niveau d'eau global ;
4. Du côté opérateur/plomb du système informatique de données en temps réel en aval, l'heure de l'événement du journal peut toujours être utilisée pour réaliser une segmentation de données spécifique en tant qu'entrée du calcul de la fenêtre, mais le mécanisme de déclenchement du calcul de la fenêtre est toujours basé sur les données globales renvoyées par Watermark Server Low Watermark prévaudra pour garantir l'intégrité des données.
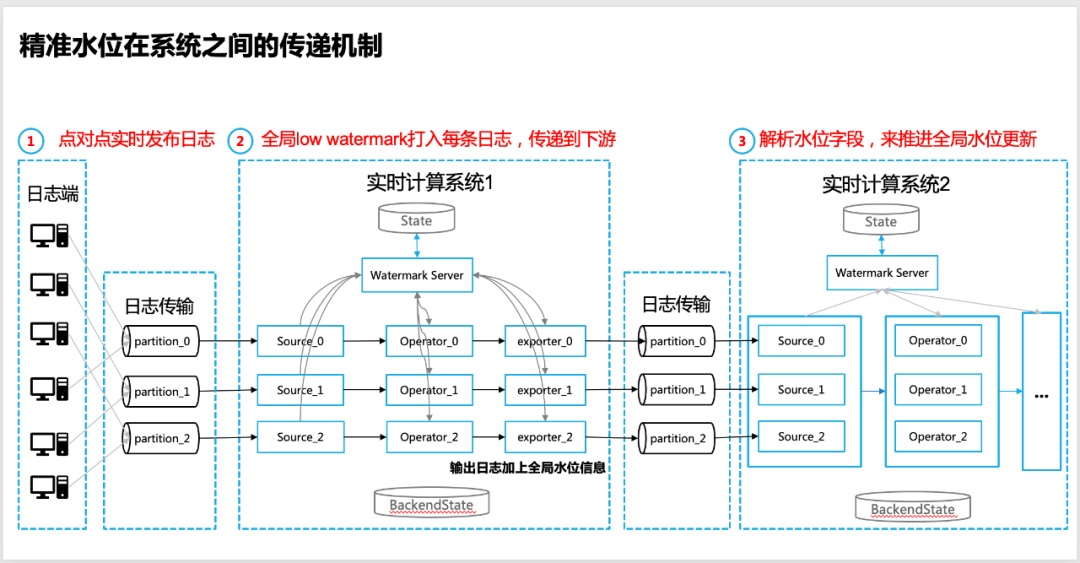
△Mécanisme de transfert du niveau d'eau précis entre les systèmes informatiques en temps réel
05 Effets réels et perspectives de suivi
5.1 Effet en ligne réel
5.1.1 Effet mesuré (exhaustivité) des données sur les débarquements
Le test en ligne réel adopte un niveau d'eau précis (la précision du niveau d'eau configuré est de 99,9 %, c'est-à-dire que seul un millième du retard de l'instance source est autorisé), et lorsqu'il n'y a pas de retard dans le journal, les données d'atterrissage en temps réel et les données hors ligne sont dans la même fenêtre temporelle (heure de l'événement) La comparaison des effets est la suivante (essentiellement tous en dessous de 100 000 points) :

△L'effet de l'intégrité des données lorsque le journal source n'est pas retardé
Lorsque le journal source est retardé (<= 0,1 % de l'instance du journal source est retardée, le niveau d'eau continuera d'être mis à jour), l'effet global de différence de données est essentiellement d'environ 1/1 000 (sous réserve de la possibilité que le point source du journal -to-point log lui-même Influence de l'inhomogénéité des données):

Dans le cas d'une grande zone de retard dans le journal source (> 0,1 % du retard de l'instance du journal source), en raison de l'utilisation d'un mécanisme de niveau d'eau précis (précision du niveau d'eau 99,9 %), le niveau d'eau global sera ne sera pas mise à jour, et les données en temps réel seront écrites dans l'AFS La fenêtre ne sera pas fermée, et la fenêtre ne sera fermée qu'après avoir attendu l'arrivée des données retardées et la mise à jour du niveau d'eau global pour assurer l'intégrité du Les résultats réels des tests sont les suivants (entre 1,1 et 1,2 pour mille, sous réserve de la source du journal L'instance elle-même a pour effet d'inégalité) :
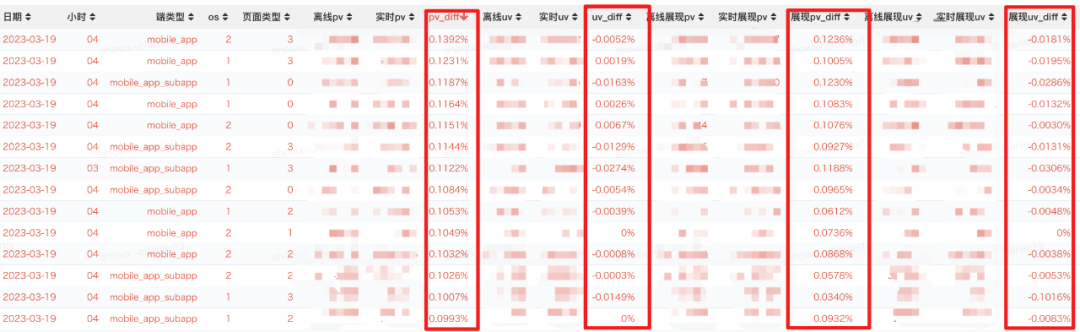
5.2 Résumé et présentation
Après des recherches sur le niveau d'eau précis réel et l'application en ligne réelle, l'entrepôt de données en temps réel basé sur le niveau d'eau précis améliore non seulement la rapidité, mais dispose également d'un mécanisme de précision des données plus élevé et flexible.Après l'optimisation de la stabilité, il est en fait complètement Au lieu des précédents systèmes d'entrepôt de données hors ligne et en temps réel, un véritable entrepôt de données intégré en flux continu est réalisé.
Dans le même temps, basé sur le mécanisme centralisé du niveau d'eau, il devra également relever les défis de l'optimisation des performances, de la haute disponibilité (amélioration du mécanisme de récupération des pannes), et d'une granularité plus fine et précise du niveau d'eau (sous le mécanisme de déclenchement du calcul de la fenêtre).
--FIN--
les références:
[1] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom et S. Whittle. Millwheel : traitement de flux tolérant aux pannes à l'échelle d'Internet. Proc. VLDB Endow., 6(11):1033–1044, août 2013.
[2] T. Akidau, R. Bradshaw, C. Chambers, S. Chernyak, RJ Fernández-Moctezuma, R. Lax, S. McVeety, D. Mills, F. Perry, E. Schmidt, et al. Le modèle de flux de données : une approche pratique pour équilibrer l'exactitude, la latence et le coût dans le traitement de données à grande échelle, illimité et désordonné. Actes de la dotation VLDB, 8(12):1792–1803, 2015.
[3] T. Akidau, S. Chernyak et R. Lax. Systèmes de diffusion en continu. O'Reilly Media, Inc., 1ère édition, 2018.
[4] "Filigranes - Mesure du temps et de la progression dans les pipelines de streaming", Slava Chernyak , Google Inc
[5] P. Carbone, A. Katsifodimos, S. Ewen, V. Markl, S. Haridi et K. Tzoumas. Apache flink : traitement par flux et par lots dans un seul moteur. Bulletin du comité technique de l'IEEE Computer Society sur l'ingénierie des données, 36(4), 2015.
Lecture recommandée:
Solution technique de modèle de texte dans le scénario de montage vidéo
Parler de l'application de l'algorithme de graphe dans la scène d'activité dans l'anti-triche
Méthode de décomposition d'action dans une application d'animation d'images
Performance Platform Data Acceleration Road
Montage de la pratique d'arrangement du processus de production vidéo AIGC