1 Pré-connaissance
1.1 Introduction au cil
Cilium est un plugin Kubernetes CNI basé sur la technologie eBPF. Cilium positionne le produit comme « eBPF-based Networking, Observability, Security » sur son site Web officiel et s'engage à fournir une mise en réseau, une observabilité et une sécurité basées sur eBPF pour les charges de travail de conteneurs une gamme de solutions. En insérant dynamiquement une logique de contrôle dans Linux à l'aide de la technologie eBPF, Cilium peut être appliqué et mis à jour sans modifier le code d'application ou la configuration du conteneur, permettant ainsi des fonctions liées à la mise en réseau, à l'observabilité et à la sécurité.
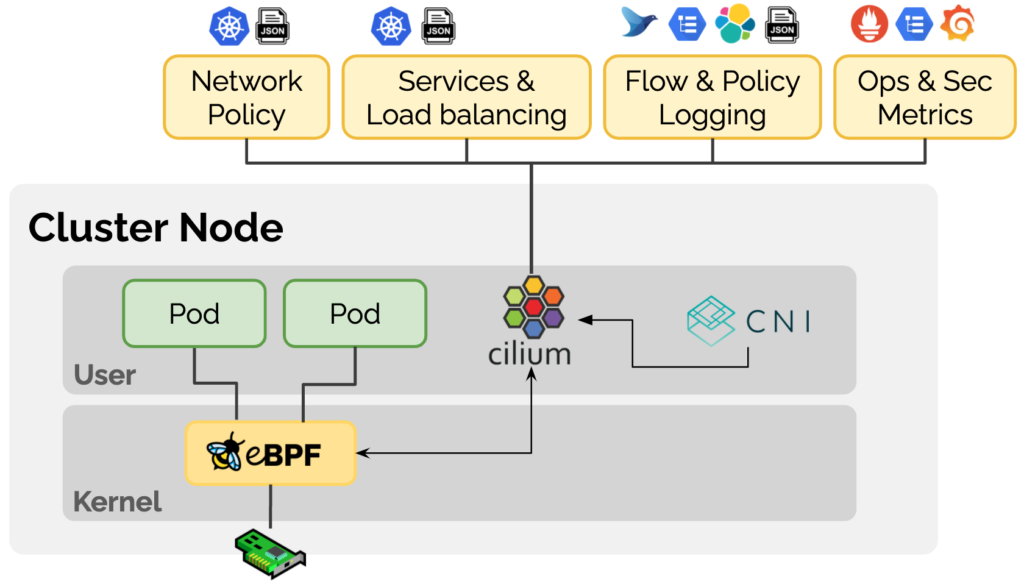
1.2 Introduction à Cilium BGP
BGP (Border Gateway Protocol, Border Gateway Protocol) est un protocole de routage dynamique utilisé entre AS (Autonomous System, système autonome). Le protocole BGP fournit des stratégies de contrôle de routage riches et flexibles et était principalement utilisé pour l'interconnexion entre les AS Internet au début. Avec le développement de la technologie, le protocole BGP a également été largement utilisé dans les centres de données.Les réseaux de centres de données modernes sont généralement basés sur l'architecture spine-leaf, dans laquelle BGP peut être utilisé pour propager les informations d'accessibilité des terminaux.
La couche feuille se compose de commutateurs d'accès qui agrègent le trafic des serveurs et se connectent directement à la colonne vertébrale ou au cœur du réseau. Les commutateurs vertébraux sont interconnectés avec tous les commutateurs feuilles dans une topologie entièrement maillée.
Avec l'application croissante de Kubernetes dans les entreprises, ces points de terminaison peuvent être des pods Kubernetes.Afin de permettre au réseau en dehors du cluster Kubernetes d'obtenir dynamiquement les routes des pods accédés via le protocole BGP, il est évident que Cilium devrait introduire le support du Protocole BGP. .
Dans Cilium, BGP a été introduit pour la première fois dans la version 1.10. En attribuant un service de type LoadBalancer aux applications et en se combinant avec MetalLB, les informations de routage sont annoncées aux voisins BGP.

Cependant, à mesure que l'utilisation d'IPv6 continue de croître, il est clair que Cilium a besoin de capacités BGP IPv6, y compris Segment Routing v6 (SRv6). MetalLB a actuellement un support limité pour IPv6 via FRR et est encore expérimental. L'équipe de Cilium a évalué diverses options et a décidé de passer au GoBGP plus riche en fonctionnalités [1] .

Dans la dernière version de Cilium 1.12, l'activation de la prise en charge de BGP ne nécessite que la configuration de --enable-bgp-control-plane=trueparamètres , et un nouveau CRD CiliumBGPPeeringPolicypermet une configuration plus fine et extensible.
- La même configuration BGP peut être appliquée à plusieurs nœuds à l'aide de la sélection de
nodeSelectorparamètres par étiquette. - Lorsque le
exportPodCIDRparamètre est défini sur true, tous les CIDR de pod peuvent être annoncés dynamiquement sans spécifier manuellement les préfixes de route à annoncer. neighborsLes paramètres sont utilisés pour définir les informations de voisinage BGP, généralement des périphériques réseau en dehors du cluster.
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack0
spec:
nodeSelector:
matchLabels:
rack: rack0
virtualRouters:
- localASN: 65010
exportPodCIDR: true
neighbors:
- peerAddress: "10.0.0.1/32"
peerASN: 65010
1.3 Introduction au genre
Kind [2] (Kubernetes dans Docker) est un outil qui utilise des conteneurs Docker comme nœuds Node pour exécuter des clusters Kubernetes locaux. Nous avons juste besoin d'installer Docker et nous pouvons créer rapidement un ou plusieurs clusters Kubernetes en quelques minutes. Afin de faciliter l'expérience, cet article utilise Kind pour créer un environnement de cluster Kubernetes.
1.4 Présentation de Containerlab
Containerlab [3] fournit une solution simple, légère et basée sur des conteneurs pour orchestrer des expériences de réseau, prenant en charge divers systèmes d'exploitation de réseau conteneurisé, tels que Cisco, Juniper, Nokia, Arista, etc. Containerlab peut lancer des conteneurs et créer des connexions virtuelles entre eux pour créer des topologies de réseau définies par l'utilisateur basées sur des profils définis par l'utilisateur.
name: sonic01
topology:
nodes:
srl:
kind: srl
image: ghcr.io/nokia/srlinux
sonic:
kind: sonic-vs
image: docker-sonic-vs:2020-11-12
links:
- endpoints: ["srl:e1-1", "sonic:eth1"]
L'interface de gestion du conteneur est connectée au réseau Docker de type pont nommé clab, et l'interface métier est connectée via les règles de liens définies dans le fichier de configuration. Cela ressemble aux modes de gestion hors bande et intrabande correspondant à la gestion du réseau dans le centre de données.

Containerlab nous fournit également une multitude de cas expérimentaux, qui peuvent être trouvés dans les exemples de laboratoire [4] . Nous pouvons même créer une architecture réseau au niveau du centre de données via Containerlab (voir tissu Clos en 5 étapes[5] )

2 Prérequis
Veuillez sélectionner la méthode d'installation appropriée en fonction de la version du système d'exploitation correspondant :
- Installez Docker : https://docs.docker.com/engine/install/
- Installez Containerlab : https://containerlab.dev/install/
- Type d'installation : https://kind.sigs.k8s.io/docs/user/quick-start/#installing-with-a-package-manager
- Installer Helm : https://helm.sh/docs/intro/install/
Les fichiers de configuration utilisés dans cet article peuvent être obtenus sur https://github.com/cr7258/kubernetes-guide/tree/master/containerlab/cilium-bgp .
3 Démarrer un cluster Kubernetes avec Kind
Préparez un fichier de configuration Kind et créez un cluster Kubernetes à 4 nœuds.
# cluster.yaml
kind: Cluster
name: clab-bgp-cplane-demo
apiVersion: kind.x-k8s.io/v1alpha4
networking:
disableDefaultCNI: true # 禁用默认 CNI
podSubnet: "10.1.0.0/16" # Pod CIDR
nodes:
- role: control-plane # 节点角色
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.1.2 # 节点 IP
node-labels: "rack=rack0" # 节点标签
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.2.2
node-labels: "rack=rack0"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.3.2
node-labels: "rack=rack1"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: 10.0.4.2
node-labels: "rack=rack1"
Exécutez la commande suivante pour créer un cluster Kubernetes via Kind.
kind create cluster --config cluster.yaml
Vérifiez l'état du nœud du cluster. Puisque nous n'avons pas installé le plug-in CNI, l'état du nœud est NotReady.
kubectl get node

4 Démarrer Containerlab
Définissez le fichier de configuration de Containerlab, créez l'infrastructure réseau et connectez-vous au cluster Kubernetes créé par Kind :
- router0, tor0, tor1 sont des périphériques réseau en dehors du cluster Kubernetes et définissent les informations d'interface réseau et la configuration BGP dans le paramètre exec. router0 établit des voisins BGP avec tor0, tor1, tor0 établit des voisins BGP avec server0, server1, router0 et tor1 établit des voisins BGP avec server2, server3, router0.
- La configuration de Containerlab
network-mode: container:<容器名>peut partager l'espace de noms réseau des conteneurs démarrés en dehors de Containerlab et définir les conteneurs server0, server1, server2, server3 pour se connecter aux 4 nœuds du cluster Kubernetes créé par Kind dans la section 3 respectivement.
# topo.yaml
name: bgp-cplane-demo
topology:
kinds:
linux:
cmd: bash
nodes:
router0:
kind: linux
image: frrouting/frr:v8.2.2
labels:
app: frr
exec:
- iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
- ip addr add 10.0.0.0/32 dev lo
- ip route add blackhole 10.0.0.0/8
- touch /etc/frr/vtysh.conf
- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
- usr/lib/frr/frrinit.sh start
- >-
vtysh -c 'conf t'
-c 'router bgp 65000'
-c ' bgp router-id 10.0.0.0'
-c ' no bgp ebgp-requires-policy'
-c ' neighbor ROUTERS peer-group'
-c ' neighbor ROUTERS remote-as external'
-c ' neighbor ROUTERS default-originate'
-c ' neighbor net0 interface peer-group ROUTERS'
-c ' neighbor net1 interface peer-group ROUTERS'
-c ' address-family ipv4 unicast'
-c ' redistribute connected'
-c ' exit-address-family'
-c '!'
tor0:
kind: linux
image: frrouting/frr:v8.2.2
labels:
app: frr
exec:
- ip link del eth0
- ip addr add 10.0.0.1/32 dev lo
- ip addr add 10.0.1.1/24 dev net1
- ip addr add 10.0.2.1/24 dev net2
- touch /etc/frr/vtysh.conf
- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
- /usr/lib/frr/frrinit.sh start
- >-
vtysh -c 'conf t'
-c 'frr defaults datacenter'
-c 'router bgp 65010'
-c ' bgp router-id 10.0.0.1'
-c ' no bgp ebgp-requires-policy'
-c ' neighbor ROUTERS peer-group'
-c ' neighbor ROUTERS remote-as external'
-c ' neighbor SERVERS peer-group'
-c ' neighbor SERVERS remote-as internal'
-c ' neighbor net0 interface peer-group ROUTERS'
-c ' neighbor 10.0.1.2 peer-group SERVERS'
-c ' neighbor 10.0.2.2 peer-group SERVERS'
-c ' address-family ipv4 unicast'
-c ' redistribute connected'
-c ' exit-address-family'
-c '!'
tor1:
kind: linux
image: frrouting/frr:v8.2.2
labels:
app: frr
exec:
- ip link del eth0
- ip addr add 10.0.0.2/32 dev lo
- ip addr add 10.0.3.1/24 dev net1
- ip addr add 10.0.4.1/24 dev net2
- touch /etc/frr/vtysh.conf
- sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons
- /usr/lib/frr/frrinit.sh start
- >-
vtysh -c 'conf t'
-c 'frr defaults datacenter'
-c 'router bgp 65011'
-c ' bgp router-id 10.0.0.2'
-c ' no bgp ebgp-requires-policy'
-c ' neighbor ROUTERS peer-group'
-c ' neighbor ROUTERS remote-as external'
-c ' neighbor SERVERS peer-group'
-c ' neighbor SERVERS remote-as internal'
-c ' neighbor net0 interface peer-group ROUTERS'
-c ' neighbor 10.0.3.2 peer-group SERVERS'
-c ' neighbor 10.0.4.2 peer-group SERVERS'
-c ' address-family ipv4 unicast'
-c ' redistribute connected'
-c ' exit-address-family'
-c '!'
server0:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:control-plane
exec:
- ip addr add 10.0.1.2/24 dev net0
- ip route replace default via 10.0.1.1
server1:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker
exec:
- ip addr add 10.0.2.2/24 dev net0
- ip route replace default via 10.0.2.1
server2:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker2
exec:
- ip addr add 10.0.3.2/24 dev net0
- ip route replace default via 10.0.3.1
server3:
kind: linux
image: nicolaka/netshoot:latest
network-mode: container:worker3
exec:
- ip addr add 10.0.4.2/24 dev net0
- ip route replace default via 10.0.4.1
links:
- endpoints: ["router0:net0", "tor0:net0"]
- endpoints: ["router0:net1", "tor1:net0"]
- endpoints: ["tor0:net1", "server0:net0"]
- endpoints: ["tor0:net2", "server1:net0"]
- endpoints: ["tor1:net1", "server2:net0"]
- endpoints: ["tor1:net2", "server3:net0"]
Exécutez la commande suivante pour créer l'environnement expérimental Containerlab.
clab deploy -t topo.yaml

La topologie créée est illustrée ci-dessous. Actuellement, seules les connexions BGP sont établies entre les périphériques tor0, tor1 et router0. Étant donné que nous n'avons pas défini la configuration BGP du cluster Kubernetes via CiliumBGPPeeringPolicy, les connexions BGP entre tor0, tor1 et le nœud Kubernetes n'ont pas été établi.

Exécutez les commandes suivantes respectivement pour vérifier l'état d'établissement actuel du voisin BGP de tor0, tor1, router0 trois périphériques réseau.
docker exec -it clab-bgp-cplane-demo-tor0 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-tor1 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 summary wide"

Exécutez la commande suivante pour afficher les entrées de route BGP apprises par router0.
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 wide"
Il existe actuellement un total de 8 entrées de routage, et le routage lié au pod n'a pas encore été appris.

Afin d'aider les utilisateurs à comprendre la structure du réseau de l'expérience de manière plus intuitive, Containerlab fournit des graphcommandes pour générer la topologie du réseau.
clab graph -t topo.yaml

Entrez http://<host IP>:50080 dans le navigateur pour afficher la carte topologique générée par Containerlab.
5 Installer Cil
Dans cet exemple, Helm est utilisé pour installer Cilium, et les paramètres de configuration de Cilium que nous devons ajuster sont définis dans le fichier de configuration values.yaml.
# values.yaml
tunnel: disabled
ipam:
mode: kubernetes
ipv4NativeRoutingCIDR: 10.0.0.0/8
# 开启 BGP 功能支持,等同于命令行执行 --enable-bgp-control-plane=true
bgpControlPlane:
enabled: true
k8s:
requireIPv4PodCIDR: true
Exécutez les commandes suivantes pour installer Cilium 1.12 et activer la prise en charge BGP.
helm repo add cilium https://helm.cilium.io/
helm install -n kube-system cilium cilium/cilium --version v1.12.1 -f values.yaml
Après avoir attendu que tous les pods Cilium démarrent, vérifiez à nouveau l'état du nœud Kubernetes et vous pouvez voir que tous les nœuds sont déjà à l'état Prêt.

6 nœuds Cilium configurent BGP
Ensuite, configurez CiliumBGPPeeringPolicy pour les nœuds Kubernetes sur rack0 et rack1 respectivement. Rack0 et rack1 correspondent respectivement aux étiquettes de Node, qui sont définies dans le fichier de configuration de Kind à la section 3.
Le nœud de rack0 établit une relation de voisinage BGP avec tor0, et le nœud de rack1 établit une relation de voisinage BGP avec tor1, et annonce automatiquement le Pod CIDR au voisin BGP.
# cilium-bgp-peering-policies.yaml
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack0
spec:
nodeSelector:
matchLabels:
rack: rack0
virtualRouters:
- localASN: 65010
exportPodCIDR: true # 自动宣告 Pod CIDR
neighbors:
- peerAddress: "10.0.0.1/32" # tor0 的 IP 地址
peerASN: 65010
---
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: rack1
spec:
nodeSelector:
matchLabels:
rack: rack1
virtualRouters:
- localASN: 65011
exportPodCIDR: true
neighbors:
- peerAddress: "10.0.0.2/32" # tor1 的 IP 地址
peerASN: 65011
Exécutez la commande suivante pour appliquer CiliumBGPPeeringPolicy.
kubectl apply -f cilium-bgp-peering-policies.yaml
La topologie créée est illustrée ci-dessous. Maintenant, tor0 et tor1 ont établi des voisins BGP avec Kubernetes Node.

Exécutez les commandes suivantes respectivement pour vérifier l'état d'établissement actuel du voisin BGP de tor0, tor1, router0 trois périphériques réseau.
docker exec -it clab-bgp-cplane-demo-tor0 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-tor1 vtysh -c "show bgp ipv4 summary wide"
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 summary wide"

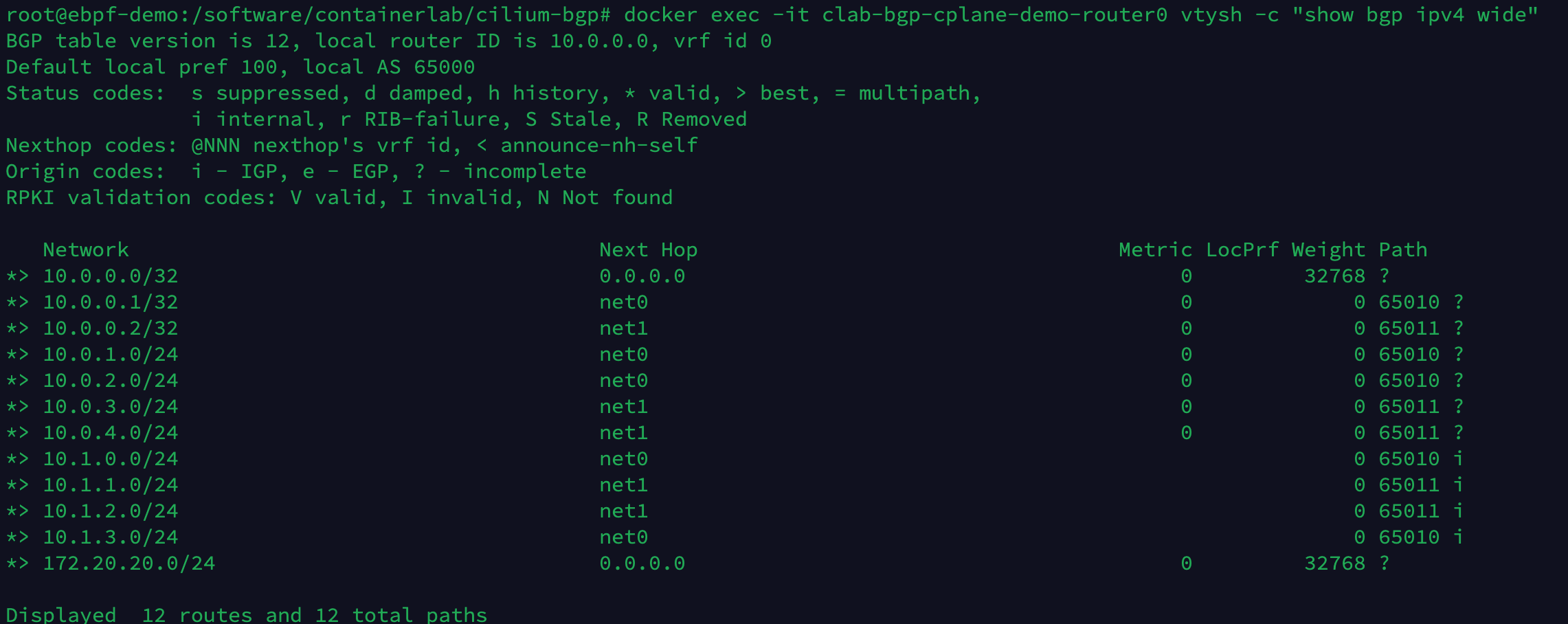
Exécutez la commande suivante pour afficher les entrées de route BGP apprises par router0.
docker exec -it clab-bgp-cplane-demo-router0 vtysh -c "show bgp ipv4 wide"
Il existe actuellement un total de 12 entrées de route, et les 4 routes supplémentaires sont les routes du segment de réseau 10.1.x.0/24 apprises des 4 nœuds de Kubernetes.
7 Essai de validation
Créez un pod sur les nœuds où se trouvent rack0 et rack1 pour tester la connectivité du réseau.
# nettool.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nettool-1
name: nettool-1
spec:
containers:
- image: cr7258/nettool:v1
name: nettool-1
nodeSelector:
rack: rack0
---
apiVersion: v1
kind: Pod
metadata:
labels:
run: nettool-2
name: nettool-2
spec:
containers:
- image: cr7258/nettool:v1
name: nettool-2
nodeSelector:
rack: rack1
Exécutez les commandes suivantes pour créer 2 pods de test.
kubectl apply -f nettool.yaml
Affichez l'adresse IP du pod.
kubectl get pod -o wide
Le pod nettool-1 est situé sur clab-bgp-cplane-demo-worker (server1, rack0), l'adresse IP est 10.1.2.185 ; le pod nettool-2 est situé sur clab-bgp-cplane-demo-worker3 (server3 , rack1), l'adresse IP est L'adresse est 10.1.3.56.

Exécutez la commande suivante pour essayer d'envoyer un ping au pod nettool-2 à partir du pod nettool-1.
kubectl exec -it nettool-1 -- ping 10.1.3.56
Vous pouvez voir que le pod nettool-1 peut accéder normalement au pod nettool-2.

Ensuite, utilisez la commande traceroute pour observer la direction des paquets réseau.
kubectl exec -it nettool-1 -- traceroute -n 10.1.3.56

Le paquet est envoyé depuis le pod nettool-1 et passe par :
- 1. L'interface cilium_host du serveur1 : La route par défaut du Pod dans le réseau Cilium pointe vers le cilium_host local. cilium_host et cilium_net sont un dispositif de paire veth. Cilium utilise des tables ARP codées en dur pour forcer le prochain saut du trafic Pod à être détourné vers le côté hôte de la paire veth.


- 2. L'interface net2 de tor0 .
- 3. L'interface lo0 de router0 : les trois périphériques réseau tor0, tor1 et router0 établissent une relation de voisinage BGP via l'interface de bouclage local lo0. Cela peut améliorer la robustesse du voisin BGP dans le cas de plusieurs sauvegardes de liens physiques. La relation de voisinage est affecté en cas de défaillance d'une interface physique.
- 4. L'interface lo0 de tor1 .
- 5. L'interface net0 de server3 .

8 Nettoyer l'environnement
Exécutez les commandes suivantes pour nettoyer l'environnement expérimental créé par Containerlab et Kind.
clab destroy -t topo.yaml
kind delete clusters clab-bgp-cplane-demo
9 Références
- [1] GoBGP : https://osrg.github.io/gobgp/
- [2] Genre : https://kind.sigs.k8s.io/
- [3] conteneurlab : https://containerlab.dev/
- [4] Exemples de laboratoire : https://containerlab.dev/lab-examples/lab-examples/
- [5] Tissu Clos en 5 étapes : https://containerlab.dev/lab-examples/min-5clos/
- [6] BGP AVEC CIL : https://nicovibert.com/2022/07/21/bgp-with-cilium/
- [7] CONTINAERlab + Kind déploient le cluster K8 sur le réseau en quelques secondes : https://www.bilibili.com/video/BV1Qa411d7wm?spm_id_from=333.337.search-card.all.click&vd_source=1c0f4059dae237b29416579c3a5d326e
- [8] Présentation du réseau Cilium : https://www.koenli.com/fcdddb4a.html
- [9] Plan de contrôle BGP Cilium : https://docs.cilium.io/en/stable/gettingstarted/bgp-control-plane/#cilium-bgp-control-plane
- [10] Cilium 1.12 – Ingress, Multi-Cluster, Service Mesh, Charges de travail externes, et bien plus : https://isovalent.com/blog/post/cilium-release-112/#vtep-support
- [11] Cilium 1.10 : WireGuard, prise en charge BGP, passerelle IP de sortie, nouvelle CLI Cilium, équilibreur de charge XDP, intégration Alibaba Cloud et plus : https://cilium.io/blog/2021/05/20/cilium-110/
- [12] Life of a Packet in Cilium : exploration sur le terrain du chemin de transfert Pod-to-Service et de la logique de traitement BPF : https://arthurchiao.art/blog/cilium-life-of-a-packet-pod-to-service - fr/