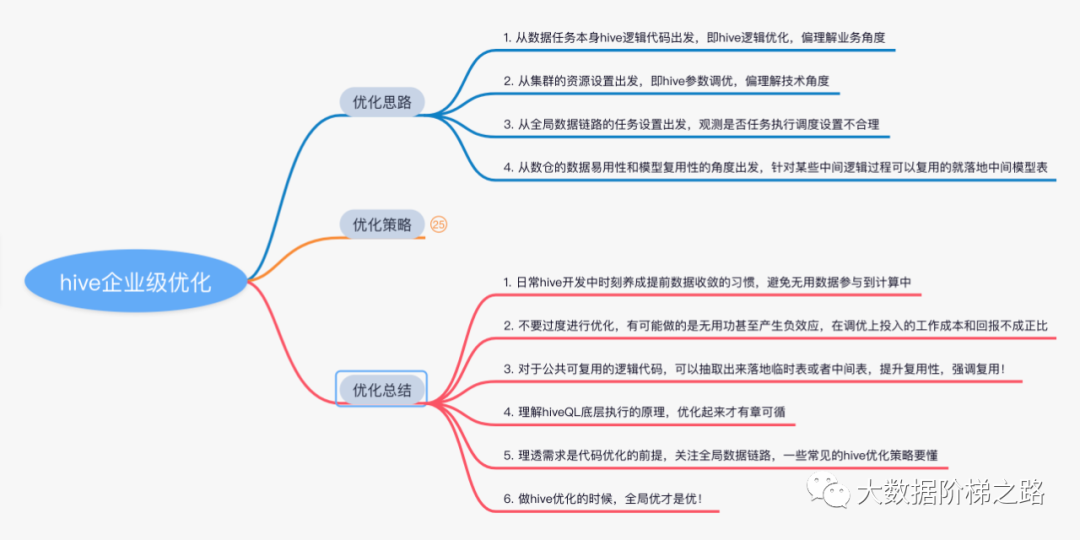
1. Hintergrund des Problems
Die Hive-Offline-Data-Warehouse-Entwicklung stellt eine gute Datenaufgabe dar. Ihre Laufzeit liegt im Allgemeinen in einem angemessenen Bereich.Wenn festgestellt wird, dass die Indikatordaten der Berichtsanwendungsschicht immer verzögert ausgegeben werden, stellt sich heraus, dass einige Aufgaben länger ausgeführt wurden als 10 Stunden. Es ist definitiv unvernünftig. Zu diesem Zeitpunkt sollten wir darüber nachdenken, wie wir die Datenaufgabenverknüpfung optimieren können, hauptsächlich aus den folgenden Perspektiven, um das Problem zu lösen :
-
Ausgehend vom Hive-Logikcode der Datenaufgabe selbst, d. h. Optimierung der Hive-Logik, und teilweises Verständnis der Geschäftsperspektive
-
Ausgehend von den Ressourceneinstellungen des Clusters, also dem Hive Parameter Tuning, verstehe ich lieber die technische Sichtweise
-
Beobachten Sie ausgehend von den Aufgabeneinstellungen der globalen Datenverbindung, ob die Einstellungen für die Zeitplanung der Aufgabenausführung unangemessen sind
-
Aus Sicht der Benutzerfreundlichkeit der Daten und der Wiederverwendbarkeit von Modellen in Data Warehouses werden Zwischenmodelltabellen implementiert, die für einige Zwischenlogikprozesse wiederverwendet werden können.
Anbei ein Screenshot eines Teils der Mindmap des persönlichen Kämmens und der Zusammenfassung
Lassen Sie uns zuerst einige gängige Hive-Optimierungsstrategien teilen~ 会附带案例实践帮助理解
hive Artikelgliederung optimieren
Spaltenbereinigung und Partitionsbereinigung
Frühe Datenkonvergenz
Prädikat-Pushdown (PPD)
Mehrere Ausgaben, wodurch die Anzahl der Tabellenlesevorgänge reduziert und mehrere Ergebnistabellen geschrieben werden
Angemessene Auswahl sortieren
Join-Optimierung
Angemessene Wahl des Dateispeicherformats und der Komprimierungsmethode
Lösen Sie das Problem zu vieler kleiner Dateien
unterscheiden und gruppieren nach
Parameterabstimmung
Lösen Sie das Problem der Datenverzerrung
Zweitens, Hive-Optimierung
1. Spaltenbereinigung und Partitionsbereinigung
裁剪 顾名思义就是不需要的数据不要多查。
Column Clipping, versuchen Sie, select * from tabledie direkte Operation zu reduzieren, erstens ist die Lesbarkeit nicht gut, und Sie wissen nicht, welche Spalten Sie verwenden sollen, und zweitens erhöht die Auswahl von mehr Spalten die IO-Übertragung;
Partition Clipping ist zu beachten zum Hinzufügen zur Partitionstabelle Partitionsfilterbedingungen, wie z. B. eine Tabelle mit Zeit als Partitionsfeld, müssen Partitionsfilter hinzufügen.
2. Fortschrittliche Datenkonvergenz
In der Unterabfrage können einige Bedingungen zuerst gefiltert werden, so weit wie möglich in der Unterabfrage zuerst filtern, um die Menge der von der Unterabfrage ausgegebenen Daten zu reduzieren.
-- 原脚本
select
a.字段a,a.字段b,b.字段a,b.字段b
from
(
select 字段a,字段b
from table_a
where dt = date_sub(current_date,1)
) a
left join
(
select 字段a,字段b
from table_b
where dt = date_sub(current_date,1)
) b
on a.字段a = b.字段a
where a.字段b <> ''
and b.字段b <> 'xxx'
;
-- 优化脚本 (数据收敛)
select
a.字段a,a.字段b,b.字段a,b.字段b
from
(
select 字段a,字段b
from table_a
where dt = date_sub(current_date,1)
and 字段b <> ''
) a
left join
(
select 字段a,字段b
from table_b
where dt = date_sub(current_date,1)
and 字段b <> 'xxx'
) b
on a.字段a = b.字段a
;3. Prädikat-Pushdown
Was ist Prädikat-Pushdown? PPD, kurz PPD, bezieht sich darauf, den Filterausdruck so nah wie möglich an die Datenquelle zu verschieben, ohne die Datenergebnisse zu beeinflussen, sodass irrelevante Daten direkt während der tatsächlichen Ausführung übersprungen werden können , damit die Filterbedingungen in der Karte ausgeführt werden können -seitige Datenausgabe spielt eine Rolle bei der Datenkonvergenz, reduziert die auf dem Cluster übertragene Datenmenge, spart Cluster-Ressourcen und verbessert die Aufgabenleistung .
Standardmäßig aktiviert hive das Prädikat-Pushdown, das durch diesen Parameter festgelegt wird. Das hive.optimize.ppd=true
sogenannte Pushdown bedeutet, dass die Prädikatfilterung auf der Map-Seite durchgeführt wird, das sogenannte Nicht-Pushdown bedeutet, dass die Prädikatfilterung auf der Reduce-Seite durchgeführt wird.
In Bezug auf die Regeln des Prädikat-Pushdowns ist es hauptsächlich in On-Condition-Filter-Pushdown von Join und Where-Condition-Filter-Pushdown unterteilt.Ich habe ein Bild zum einfachen Verständnis zusammengestellt.

Kernbeurteilungslogik: Die on-bedingte Filterung von Join kann nicht auf die reservierte Zeilentabelle heruntergeschoben werden; die where-bedingte Filterung kann nicht auf die Null-Ergänzungstabelle heruntergedrückt werden.
-- 举例说明:以下脚本 on后面的a表条件过滤没有下推至map端运行而是在reduce端运行,where后面的b表条件过滤则有下推至map端运行
select
a.字段a,a.字段b,b.字段a,b.字段b
from table_a a
left join table_b b
on a.字段a <> '' -- a表条件过滤
where a.字段b <> 'xxx' -- a表条件过滤
;
Prädikat-Pushdown-Hinweis:
Wenn ein Ausdruck eine unbestimmte Funktion enthält, wird das Prädikat für den gesamten Ausdruck nicht nach unten verschoben. Im folgenden Skript wird beispielsweise die gesamte bedingte Filterung auf der Reduce-Seite ausgeführt:
select a.*
from a join b
on a.id = b.id
where a.ds = '2019-10-09'
and a.create_time = unix_timestamp()
;Da die obige unix_timestamp()Funktion eine unbestimmte Funktion ist, kann sie zur Kompilierzeit nicht bekannt sein, sodass der gesamte Ausdruck nicht nach unten verschoben wird, d. h. ds='2022-07-04' wird nicht im Voraus gefiltert. Ähnliche unsichere Funktionen sind rand()Funktionen und so weiter.
Anbei sind 2 detaillierte Fallanalyse-Erklärungen zum Prädikat-Pushdown
! Gehen Sie zum Link, kopieren Sie ihn und besuchen Sie ihn selbst :
① https://cloud.tencent.com/developer/article/1616687
② https://cloud.tencent.com/developer/article/1616689
4. Mehrere Ausgänge
Bei 使用一次查询,多次插入einigen Szenarien können wir die Multi-Output-Schreibmethode verwenden, um die Anzahl der Tabellenlesevorgänge zu reduzieren und die Leistung zu optimieren.
-- 读取一次源表,同时写入多张目标表
from table_source
insert overwrite table table_a
select *
where dt = date_sub(current_date,1)
and event_name = '事件A'
insert overwrite table table_b
select *
where dt = date_sub(current_date,1)
and event_name = '事件B'
insert oveewrite table table_c
select *
where dt = date_sub(current_date,1)
and event_name = '事件C'
;Hinweise zu Mehrfachausgängen:
Unter normalen Umständen unterstützt eine SQL bis zu 128 Ausgabekanäle, und es wird ein Fehler gemeldet, wenn mehr als 128 Kanäle unterstützt werden.
Beim Einfügen mehrerer Teile in verschiedene Partitionen derselben Partitionstabelle ist es nicht zulässig, sowohl Einfügen Überschreiben als auch Einfügen in in mehrere Ausgaben in einer SQL einzufügen, und die Operation muss vereinheitlicht werden.
5. Angemessene Auswahlsortierung
-
order by
全局排序,只走一个reducer, wenn die Datenmenge in der Tabelle groß ist, wird es leicht nicht berechnet, und es wird mit Vorsicht verwendet, wenn die Leistung schlecht ist.Im strikten Modus muss ein Limit hinzugefügt werden -
Sortieren nach
lokaler Sortierung, um sicherzustellen, dass die Ergebnisse in einer einzelnen Reduzierung in Ordnung sind, aber es gibt keine Möglichkeit, global zu sortieren. -
Verteilen durch
按照指定的字段把数据划分输出到不同的reducer中,是控制数据如何从map端输出到reduce端, Hive führt eine Hash-Verteilung gemäß den Feldern nach Verteilen durch und der Anzahl der entsprechenden Reduzierer durch -
cluster by
hat die Fähigkeit zu verteilen nach und hat auch die Fähigkeit zu sortieren nach,所以可以理解cluster by是 distrubute by+sort by
Im Folgenden finden Sie ein Beispiel für die Sortieroptimierung, wobei die Informationen der Top-100-Benutzer nach Alter in der Benutzerinformationstabelle (1 Milliarde Datenvolumen) verwendet werden :
以下案例实现也体现了一个大数据思想,分而治之,大job拆分小job。
-- 原脚本
select *
from tmp.user_info_table
where dt = '2022-07-04'
order by age -- 全局排序,只走一个reduce
limit 100
;
-- 优化脚本
set mapred.reduce.tasks=50; -- 设置reduce个数为50
select *
from tmp.user_info_table
where dt = '2022-07-04'
distribute by (case when age<20 then 0
when age >=20 and age <= 40 then 1
else 2
end
) -- distribute by主要是为了控制map端输出的数据在reduce端中是如何划分的,防止map端数据随机分配到reduce。这里字段做case when判断是因为用户年龄的零散值会导致分布不均匀,起太多reduce本身也耗时浪费资源
sort by age -- 起多个reduce排序,保证单个reduce结果有序
limit 100 -- 取前100,因为是按照年龄局部排序过,所以前100个也一定是年龄最小的
;Zusammenfassung der Sortiermöglichkeiten:
Reihenfolge durch globale Sortierung, aber nur ein Reducer wird ausgeführt, ist leicht zu berechnen, wenn die Datenmenge groß ist, verwenden Sie es mit Vorsicht
Sortieren nach lokaler Sortierung, ein einzelner Reduzierer wird geordnet und die Kartenseite wird zur Ausführung zufällig auf die Reduziererseite verteilt. Wenn Sie eine globale Sortierung erreichen und die Optimierungsanforderungen mehrerer Reduzierer erfüllen möchten, können Sie eine Ebene in der äußeren verschachteln layer
例如:select * from (select * from 表名 sort by 字段名 limit N) order by 字段名 limit N, sodass es 2 Jobs gibt, einer ist die lokale Sortierung der inneren Schicht und der andere die globale Sortierung der äußeren SchichtPer Can-Hash verteilen und die Daten gemäß dem angegebenen Feld zur Ausführung an den entsprechenden Reducer verteilen
当分区字段和排序字段相同时可以使用cluster by来简化distribute by+sort by的写法, aber der Cluster nach Sortierung kann nur in aufsteigender Reihenfolge sortiert werden, und die Sortierregel kann nicht als ASC oder DESC angegeben werden
6. Join-Optimierung
Der von hive in der Phase „Reduzieren“ abgeschlossene Join ist der allgemeine Join, und der in der Map-Phase abgeschlossene Join ist der Map-Join.
-
Konvergieren der Datenmenge im Voraus, um sicherzustellen, dass nutzlose Daten nicht an der Zuordnung teilnehmen, bevor die Join-Zuordnung erfolgt.
Dies kann mit dem vorherigen Datenkonvergenzmodul und Prädikat-Pushdown-Modul kombiniert werden, hauptsächlich um die Datenmenge im Voraus zu konvergieren, nicht nur im Join-Szenario, aber vor anderen komplexen Berechnungen. Dasselbe gilt. -
Das Anwendungsszenario des linken Semi-Joins
left semi joinzu Beginn ist eigentlich eine effiziente Implementierung, um das Problem zu lösen, dass hive die Unterabfrage in/exists nicht unterstützt: Obwohl der linke Semi-Join left enthält, behält er nicht alle Daten in der linken Tabelle Der Effekt ähnelt dem Join, aber das Endergebnis nimmt nur die Spalten in der linken Tabelle auf, und das Endergebnis unterscheidet sich in einigen Szenarien vom Join-Ergebnis.
select a.*
from
(
select 1 as id,'a' as name
union all
select 2 as id,'b' as name
) a
left semi join
(
select 1 as id,'b' as name
union all
select 1 as id,'c' as name
) b
on a.id = b.id
-- 你猜left semi join结果是?
id name
1 a
-- 而如果上面的脚本是join呢,结果?
id name
1 a
1 aHinweise für Left Semi Join:
Der bedingte Filter der rechten Tabelle kann nur nach on geschrieben werden, nicht nach where
Das Endergebnis kann nur die Spalten der linken Tabelle anzeigen, und die Spalten der rechten Tabelle können nicht angezeigt werden
Der Unterschied zwischen Left Semi Join und Join besteht hauptsächlich darin, dass bei doppelten Daten in der rechten Tabelle der Left Semi Join überspringt, nachdem er ein Datenelement in der rechten Tabelle durchlaufen hat, und nur ein Datenelement verwendet, während Join den gesamten Weg durchquert letztes Datenstück in der rechten Tabelle, das ist auch zu beachten, ob die eigentliche Datenszene wiederholt wird und ob sie beibehalten werden soll
-
Szenario "Große Tabelle mit kleiner Tabelle
verbinden" Wenn eine große Tabelle mit einer kleinen Tabelle verbunden wird要把小表放在左边,大表放在右边, liegt dies daran, dass die Join-Operation in der Reduzierungsphase stattfindet Vor der Version hive2.x wird die Tabelle auf der linken Seite in den Speicher geladen, falls dies der Fall ist eine große Tabelle, platzieren Sie sie auf der linken Seite. Wenn sie in den Speicher geladen wird, besteht die Gefahr eines Speicherüberlaufs , aber nach der hive2.x-Version wurde dieser Teil optimiert, Sie müssen nicht darauf achten, die untere Ebene hilft wir optimieren dieses Problem. -
Wenn Mapjoin aktiviert ist
mapjoin就是把join的表直接分发到map端的内存中,即在map端来执行join操作, ist es nicht erforderlich, in der Reduzierphase beizutreten, was die Ausführungseffizienz verbessert. Wenn die Tabelle relativ klein ist, ist es am besten, Mapjoin zu aktivieren, und hive aktiviert standardmäßig automatisches Mapjoin.
set hive.auto.convert.join = true;
-- 大表小表的阈值设置(默认25M一下认为是小表)
set hive.mapjoin.smalltable.filesize=26214400;-
Szenario für die Verknüpfung großer Tabellen mit großen Tabellen
Angenommen, Tabelle a enthält Daten mit vielen Nullwerten und Tabelle b enthält Daten, die keine Nullwerte enthalten.
-- 不做优化时的原始hql
select a.id
from a left join b
on a.id = b.id1、空key过滤,过滤空key的数据
Der Assoziationsprozess besteht darin, dass die Daten, die demselben Schlüssel entsprechen, an denselben Reduzierer gesendet werden. Wenn zu viele leere Schlüssel vorhanden sind, wird der Speicher nicht ausreichen, was zu einer Zeitüberschreitung bei der Verbindung führt. Daher, wenn Sie solche leeren nicht benötigen Schlüsseldaten können Sie diese anormalen Daten zunächst herausfiltern.
-- 做空key过滤优化时的hql,利用子查询先处理掉后再关联
select a.id
from (select * from a where id is not null) a
join b
on a.id = b.id2、空key转换,转换key的数据进行关联时打散key
Natürlich sind manchmal die Daten mit Nullwerten nicht unbedingt anormale Daten und müssen trotzdem beibehalten werden, aber einem Reducer werden zu viele leere Schlüssel zugewiesen.Auf diese Weise kommt es, selbst wenn kein Speicherüberlauf auftritt, zu einer Datenverzerrung Wenn die Daten schief sind Aus Sicht der Nutzung von Cluster-Ressourcen ist es äußerst ungünstig: Wir können den leeren Schlüssel in eine Zufallszahl virtualisieren, müssen aber sicherstellen, dass es nicht derselbe leere Schlüssel ist, wodurch die Wahrscheinlichkeit verringert wird Obwohl dies den zugeordneten Schlüssel verarbeitet, erhöht sich insgesamt die Ausführungszeit, aber die Belastung des Reduzierers wird verringert.
-- 做空key转换优化时的hql,利用case when判断加随机数
select a.id
from a.left join b
on case when a.id is null then concat('hive'+rand()) else a.id end = b.id-
Vermeiden Sie kartesische Produkte
Versuchen Sie, kartesische Produkte zu vermeiden, das heißt, vermeiden Sie das Hinzufügen von Bedingungen oder ungültige Bedingungen beim Beitritt, da Hive nur einen Reduzierer verwenden kann, um kartesische Produkte zu vervollständigen, aber Hive wird es durch den strikten Modus daran erinnern Die Integration erfolgt im strikten Modus.
7. Angemessene Auswahl des Dateispeicherformats und der Komprimierungsmethode
Diesbezüglich habe ich einen Artikel geschrieben, um verschiedene gängige Speicherformate und Komprimierungsmethoden von Hive vorzustellen. Für Details können Sie zu diesem Artikel gehen, den ich letztes Mal geschrieben habe
! Link : https://mp.weixin.qq .com/s/RndQKF5y9Mto7QfgiiAOvQ
8. Lösen Sie das Problem zu vieler kleiner Dateien
-
Lassen Sie uns zuerst darüber sprechen, was eine kleine Datei ist und wie sie entsteht
顾名思义,小文件就是文件很小的文件,小文件的产生一定是发生在向hive表导入数据的时候, zum Beispiel:
-- 第①种导入数据方式
insert into table A values(); -- 每执行一条语句hive表就产生一个文件,但这种导入数据方式生产环境少见;
-- 第②种导入数据方式
load data local path '本地文件/本地文件夹 路径' overwrite into table A; -- 导入文件/文件夹`,即有多少个文件hive表就会产生多少个文件
-- 第③种导入数据方式
insert overwrite table A select * from B; -- 通过查询的方式导入数据是生产环境最常见的Wenn in MR reduce 有多少个就输出多少个文件,文件数量 = reduce数量 * 分区数einige einfache Jobs keine Reduce-Phase haben und nur eine Map-Phase haben, dann ist das 文件数量 = map数量 * 分区数. Aus der Formel bestimmen die Anzahl der Reduzierungen und die Anzahl der Partitionen letztendlich die Anzahl der Ausgabedateien, sodass Sie die Anzahl der Reduzierungen und die Anzahl der Partitionen anpassen können, um die Anzahl der Dateien in der Hive-Tabelle zu steuern.
-
Welche Auswirkung haben
首先第一点从HDFS底层来看zu viele kleine Dateien? Zu viele kleine Dateien belasten den Cluster-Namenode, d. h. die Namenode-Metadaten belegen viel Speicherplatz und beeinträchtigen die Leistung第二点从hive来看von HDFS. Bei der Abfrage wird jede kleine Datei als a Block, und eine Map wird gestartet Die Aufgabe ist abgeschlossen, und die Zeit zum Starten und Initialisieren einer Map-Aufgabe ist viel länger als die Zeit für die logische Verarbeitung, was eine Menge Ressourcenverschwendung verursacht. -
So beheben Sie zu viele kleine Dateien
1、使用hive自带的 concatenate 命令,来合并小文件
Beachten Sie jedoch, dass der concatenate-Befehl nur das hive-Tabellenspeicherformat orcfile oder rcfile unterstützt und diese Methode die Angabe der Anzahl der zusammengeführten Dateien nicht unterstützt
-- 对于非分区表
alter table test_table concatenate;
-- 对于分区表
alter table test_table partition(dt = '2022-07-16') concatenate;2、调整参数减少Map数
-
Stellen Sie die Karteneingabe so ein, dass kleine Dateien zusammengeführt werden
-- 102400000B=102400KB=100M
-- 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=102400000;
-- 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=102400000;
-- 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=102400000;
-- 前3行设置是确定合并文件块的大小,>128M的文件按128M切块,>100M和<128M的文件按100M切块,剩下的<100M的小文件直接合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- map执行前合并小文件-
Legen Sie die Kartenausgabe fest und reduzieren Sie die Ausgabe, um kleine Dateien zusammenzuführen
-- 设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
-- 设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
-- 设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000;
-- 当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; 3、调整参数减少Reduce数
-- hive中的分区函数 distribute by 正好是控制MR中partition分区的,然后通过设置reduce的数量,结合分区函数让数据均衡的进入每个reduce即可。
-- 直接设置reduce个数
set mapreduce.job.reduces=10;
-- 执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
解释:如设置reduce数量为10,则使用 rand(), 随机生成一个数x % 10,这样数据就会随机进入 reduce 中,防止出现有的文件过大或过小9. count(distinct) und gruppieren nach
Bei der Berechnung des Deduplizierungsindex, beispielsweise der Anzahl der Benutzer in verschiedenen Altersgruppen, wird dieser im Allgemeinen count(distinct user_id)direkt berechnet. Wenn die Datenmenge in der Tabelle nicht groß ist, ist die Auswirkung nicht signifikant, aber wenn die Datenmenge groß ist, Count Distinct wird viel Leistung verbrauchen, da es nur von einer Reduce-Aufgabe ausgeführt wird, wodurch die Daten auf der Reduce-Seite leicht verzerrt werden können.Normalerweise wird 里层group by age然后再外层count(user_id)stattdessen eine Optimierung verwendet.
Zu beachten:
Ob die Verwendung里层group by age然后再外层count(user_id)dercount(distinct user_id)direkten Deduplizierungsberechnung definitiv den Optimierungseffekt erzielt, hängt auch von der Situation ab, da die Menge der Tabellendaten nicht besonders groß ist, kann es sein, dass es in manchen Fällen里层group by age然后再外层count(user_id)nicht besser ist. Daher ist es besser, spezifische Geschäftsszenarien im Detail zu analysieren.Optimierung ist nie eine Frage der lokalen, sondern der globalen Betrachtung.count(distinct user_id)
Paarweise Optimierungen wurden der hive3.x-Version hinzugefügt:
count(distinct )Durch dieset hive.optimize.countdistinctKonfiguration können selbst verzerrte Daten automatisch optimiert und die Logik der SQL-Ausführung automatisch geändert werden.
里层group by age然后再外层count(user_id)Diese Methode generiert 2 Job-Tasks, die mehr I/O-Ressourcen des Plattennetzwerks verbrauchen
10. Parameterabstimmung
-
Für die Abfrage von partitionierten Tabellen müssen wo Partitionseinschränkungen hinzugefügt werden
-
Bei Verwendung von order by global sorting muss limit hinzugefügt werden, um die Anzahl der Datenabfragen zu begrenzen
-
Eingeschränkte kartesische Produktabfragen
-
set hive.optimize.countdistinct=trueAutomatische Optimierung der Anzahl aktivieren (eindeutig) -
set hive.auto.convert.join = true;Aktivieren Sie automatische Mapjoin-set hive.mapjoin.smalltable.filesize=26214400;Schwellenwerteinstellungen für große und kleine Tabellen (der Standardwert ist 25 Millionen, was als kleine Tabelle betrachtet wird). -
set hive.exec.parallel=true;Öffnen Sie Aufgaben, umset hive.exec.parallel.thread.number=16;dieselbe SQL parallel auszuführen, um den maximalen Grad an Parallelität zu ermöglichen, der Standardwert ist 8. Standardmäßig führt Hive jeweils nur eine Phase aus. Wenn die parallele Ausführung aktiviert ist, werden die Phasen, die in einer SQL-Anweisung nicht voneinander abhängig sind, parallel ausgeführt, was die Ausführungszeit des gesamten Jobs verkürzen kann. Verbessern Sie die Auslastung der Cluster-Ressourcen, aber natürlich hat dies einen Vorteil, wenn die Systemressourcen relativ ungenutzt sind, da sonst keine Ressourcen vorhanden sind und Parallelität nicht möglich ist. -
set hive.map.aggr=true;Der Standardwert ist "true". Wenn die Option auf "true" gesetzt ist, ist derset hive.groupby.skewindata = ture;Standardwert zum Aktivieren der teilweisen Aggregation auf der Kartenseite "false". Bei einer Datenverzerrung wird ein Lastenausgleich durchgeführt. Der generierte Abfrageplan hat zwei MapReduce-Aufgaben . In der erster MR-Job, Die Ausgabeergebnisse der Map werden zufällig auf die Reduces verteilt.Jedes Reduce führt partielle Aggregationsoperationen durch und gibt die Ergebnisse aus.Das Ergebnis dieser Verarbeitung ist, dass der gleiche Group By Key an verschiedene Reduces verteiltwerden kann um den Zweck des Lastausgleichs zu erreichen; Der zweite MR-Job wird dann gemäß den vorverarbeiteten Datenergebnissen gemäß Group By Key an Reduce verteilt (dieser Prozess kann sicherstellen, dass derselbe Group By Key an denselben Reduce verteilt wird) und schließlich schließt den letzten Aggregationsvorgang ab -
set hive.mapred.mode=strict;Setzt den strengen Modus, der Standardwert ist der nicht strenge nicht strenge Modus. Im strikten Modus werden die folgenden drei Arten von unangemessenen Abfragen verboten, d. h. die folgenden drei Fälle melden einen Fehler -
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;Stellen Sie die Kartenseite so ein, dass kleine Dateien vor der Ausführung zusammengeführt werden -
set hive.exec.compress.output=true;Legen Sie fest, ob die Abfrageergebnisausgabe von hive komprimiert werden soll. Legenset mapreduce.output.fileoutputformat.compress=true;Sie fest, ob die Komprimierung für die Ergebnisausgabe des MapReduce-Jobs verwendet werden soll -
set hive.cbo.enable=false;Deaktivieren Sie die CBO-Optimierung und der Standardwert ist wahr. Es kann automatisch die Reihenfolge mehrerer JOINs in HQL optimieren und den geeigneten JOIN-Algorithmus auswählen.
11. Lösen Sie das Problem der Datenverzerrung
-
Was ist eine Datenverzerrung
数据倾斜是大量的相同key被partition分配到同一个reduce里,造成了'一个人累死,其他人闲死'的情况, die gegen die ursprüngliche Absicht des parallelen Rechnens verstößt, und wenn andere Knoten berechnet haben, müssen sie auf die Berechnung dieses beschäftigten Knotens warten, und die Effizienz wird verringert. -
Offensichtliche Manifestation einer Datenverzerrung
任务进度长时间维持在99%, überprüfen Sie die Aufgabenüberwachungsseite und stellen Sie fest, dass nur eine kleine Anzahl (eine oder mehrere) Unteraufgaben zum Reduzieren nicht abgeschlossen sind. Weil die Datenmenge, die es verarbeitet, zu unterschiedlich von anderen Reduzierern ist -
Was ist die Hauptursache für Datenverzerrung?
Ungleichmäßige Schlüsselverteilung, ungleichmäßige Verarbeitung reduzierter Daten -
So vermeiden Sie Datenverzerrung so weit wie möglich
Die gleichmäßige Verteilung von Daten auf jede Reduzierung ist der grundlegende Grund zur Vermeidung von Datenverzerrung. Zum Beispiel die folgenden zwei typischen Fälle, etwa die Datenverzerrung und Lösung der Join-Operation:就在文章上面的第六点join优化【大表join大表场景】, und eine Lösung, um die Anzahl der Karten vernünftig festzulegen und zu reduzieren. -
Stellen Sie die Anzahl der Karten vernünftig ein und reduzieren Sie sie
1、Map端优化
Normalerweise generiert Job über das Eingabeverzeichnis einen oder mehrere Zuordnungsaufgaben.Ab map数主要取决与input的文件总个数,文件总大小,集群设置的文件块大小。
Hadoop 2.7.3 beträgt die Standardblockgröße von HDFS 128 MB. Jede Hive-Tabelle entspricht einer Datei auf hdfs. Beim Ausführen einer Aufgabe ist jede 128 MB große Datei ein Block, und jeder Block wird durch eine Zuordnungsaufgabe vervollständigt. Wenn die Datei 128 MB überschreitet, wird sie in Blöcke unterteilt. Wenn sie kleiner als ist 128M, es wird unabhängig in einen Block. 那么:①当小文件过多怎么办?
Die Antwort ist, dass die Anzahl der Zuordnungsaufgaben zunimmt und die Start- und Initialisierungszeit der Zuordnungsaufgaben viel länger ist als die Verarbeitungszeit der Ausführungslogik, wodurch Ressourcen im Cluster verschwendet werden. ②是不是让每个文件都接近128M大小就毫无问题了呢?
Die Antwort ist unmöglich: Angenommen, eine Datei hat eine Größe von 127 MB, aber die Tabelle hat nur ein oder zwei Felder und die Dateigröße wird um mehrere zehn Millionen Datensätze erweitert Ausführen einer Kartenaufgabe. ③是不是map数越多越好?
Die Antwort ist, dass diese Aussage einseitig ist. Die Erhöhung der Anzahl von Maps ist förderlich für die Verbesserung des Parallelitätsgrades. Allerdings ist die Start- und Initialisierungszeit einer Map viel länger als die Verarbeitungszeit der Ausführungslogik. Je mehr Maps gestartet und initialisiert werden, desto größer ist die Verschwendung von Cluster-Ressourcen.
减少map数量,降低资源浪费,如何做?
Folgendes entspricht dem Zusammenführen kleiner Dateien zu großen Dateien (alles in einem)
-- 102400000B=102400KB=100M
-- 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=102400000;
-- 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=102400000;
-- 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=102400000;
-- 前3行设置是确定合并文件块的大小,>128M的文件按128M切块,>100M和<128M的文件按100M切块,剩下的<100M的小文件直接合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- map执行前合并小文件Manchmal, wenn Hive optimiert wird, gibt es möglicherweise keine große Verbesserung der Ausführungszeit, aber es gibt eine große Verbesserung der Rechenressourcen.
增大map数量,分担每个map处理的数据量提升任务效率,如何做?
Das Folgende entspricht dem Zusammenführen kleiner Dateien in große Dateien (eine Teilung und mehr)
Gemäß der Formel von mapreduce slicing: computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))ist aus der Formel ersichtlich, dass das Anpassen des Maximalwerts von maxSize und das Setzen des Maximalwerts von maxSize auf einen niedrigeren Wert als blocksize die Anzahl der Maps erhöhen kann.
mapreduce.input.fileinputformat.split.minsize(切片最小值), der Standardwert = 1, wenn der Parameter größer als die Blockgröße eingestellt wird, kann der Slice größer als die Blockgröße gemacht werden, wodurch die Anzahl der Karten reduziert wird mapreduce.input.fileinputformat.split.maxsize(切片最大值), der Standardwert = die Blockgröße der Blockgröße, wenn der Parameter kleiner als die Blockgröße angepasst wird, wird der Slice kleiner gemacht, wodurch die Anzahl der Maps erhöht wird
2、Reduce端优化
Wenn die Anzahl von Reduce zu groß eingestellt ist, werden auch viele kleine Dateien generiert, was sich auf den Namenode auswirkt, und die ausgegebenen kleinen Dateien werden gelegentlich als Eingabe für die nächste Aufgabe verwendet, was zu dem Problem zu vieler kleiner Dateien führt Eine zu kleine Einstellung führt dazu, dass die verarbeiteten Daten um eine einzelne Reduzierung reduziert werden.Wenn die Menge zu groß ist, tritt eine OOM-Ausnahme auf.
Wenn nicht angegeben, führt hive die Berechnung standardmäßig gemäß der Berechnungsformel durch hive.exec.reducers.bytes.per.reducer(die von jeder Reduzierungsaufgabe verarbeitete Datenmenge, die Standardeinstellung ist 1G) und hive.exec.reducers.max(die maximale Anzahl von Reduzierungen pro Aufgabe, die Standardeinstellung ist 1009) min(hive.exec.reducers.max值,总输入数据量/hive.exec.reducers.bytes.per.reducer值)und die Das Ergebnis bestimmt die Anzahl der Reduzierer. Die Anzahl der Reduzierer kann also durch Anpassen von Parameter 1 und Parameter 2 angepasst werden, aber am einfachsten ist es, die Anzahl der Reduzierer direkt über die folgenden Parameter zu steuern.
-- 手动指定reduce个数
set mapred.reduce.tasks=50;
-- 设置每一个job中reduce个数
set mapreduce.job.reduces=50;那么:①reduce数是不是越多越好?
Die Antwort ist falsch: Wie bei der Anzahl der Maps braucht es Zeit und Ressourcen, um mit dem Reduzieren und Initialisieren zu beginnen, und zu viele Reduzieren erzeugen mehrere Dateien, was auch das Problem kleiner Dateien verursacht.②什么情况下当设置了参数指定reduce个数后还是只有单个reduce在跑?
-
Die Menge der Eingabedaten selbst beträgt weniger als 1 GB
-
Bei der Überprüfung der Menge der gemessenen Daten wurde keine gruppenweise Zusammenfassung hinzugefügt. zum Beispiel
select count(1) from test_table where dt = 20201228; -
Sortieren nach Reihenfolge nach
-
Descartes-Produkt
Eine Zusammenfassung der vernünftigen Einstellung der Anzahl von Karten und Reduzierungen:
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;//Das Standardformat des Systems, das so eingestellt ist, dass kleine Dateien vor der Kartenausführung zusammengeführt werden, reduziert die Anzahl der Karten
set mapreduce.input.fileinputformat.split.maxsize = 100;// Passen Sie den maximalen Slice-Wert so an, dass der maxSize-Wert kleiner als die Blockgröße ist, um die Anzahl der Karten zu erhöhenGemäß der Formel von mapreduce slice:
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))ist aus der Formel ersichtlich, dass der Maximalwert von maxSize so angepasst wird, dass der Maximalwert von maxSize kleiner als die Blockgröße ist, sodass der Slice kleiner wird, und die Anzahl der Maps kann erhöht werden.
3. Zusammenfassung
-
Entwickeln Sie bei der täglichen Hive-Entwicklung immer im Voraus die Gewohnheit der Datenkonvergenz, um zu vermeiden, dass nutzlose Daten an der Berechnung teilnehmen
-
Überoptimieren Sie nicht, es kann nutzlos sein oder sogar negative Auswirkungen haben, der Arbeitsaufwand beim Tuning steht nicht im Verhältnis zur Rendite
-
Für öffentlich wiederverwendbare Logikcodes können temporäre Tabellen oder Zwischentabellen extrahiert werden, um die Wiederverwendbarkeit zu verbessern.
强调复用! -
Verstehen Sie das Prinzip der zugrunde liegenden Ausführung von hiveQL und optimieren Sie es, um den Regeln zu folgen
-
Das Verständnis der Anforderungen ist die Prämisse der Codeoptimierung, achten Sie auf die globale Datenverknüpfung und verstehen Sie einige gängige Hive-Optimierungsstrategien
-
Bei der Hive-Optimierung sollten Sie bei der Parameteroptimierung vorsichtig sein, z. B. bei der Vorrangigkeit aller Speicheranwendungen, um zu vermeiden, dass Ihre eigene Aufgabenoptimierung die Ressourcenzuweisung anderer Aufgaben im gesamten Cluster beeinflusst.
全局优才是优!